
最近有幸捡了个漏,修了个有13 年历史的 Linux 内核 bug,相关修复已经合并到 Linux 主线版本 5.14-rc3。发现新的 Linux 内核 bug 的机会不总是有,在客户现场进行调试和诊断往往会受到各种限制以致于不得不使用一些“土法”,因此写个博客日志一下,以供备忘与交流。
我们在一个用户环境中首次发现了这个bug:用户使用我们的产品后,发现我们的产品生成了一个不断消耗 CPU 的僵尸进程,要求我们将他们的业务系统复原,并给出异常的排查结果与修复方案。


登陆用户宿主机进行调试,发现该僵尸进程的线程组包含两个线程:5543 和 5552。其中 5543 是进程组根线程,目前处于已经退出的 Zombie 状态;而 5552 处于 Running 状态。它们父进程是 1 号进程,显然作为最终的 subreaper 它也无法回收这个进程。尝试使用 kill -9 5552 指令发送 SIGKILL 信号,发现并没有任何效果,因此可以断定 5552 task 在内核态死循环而无法被回收。
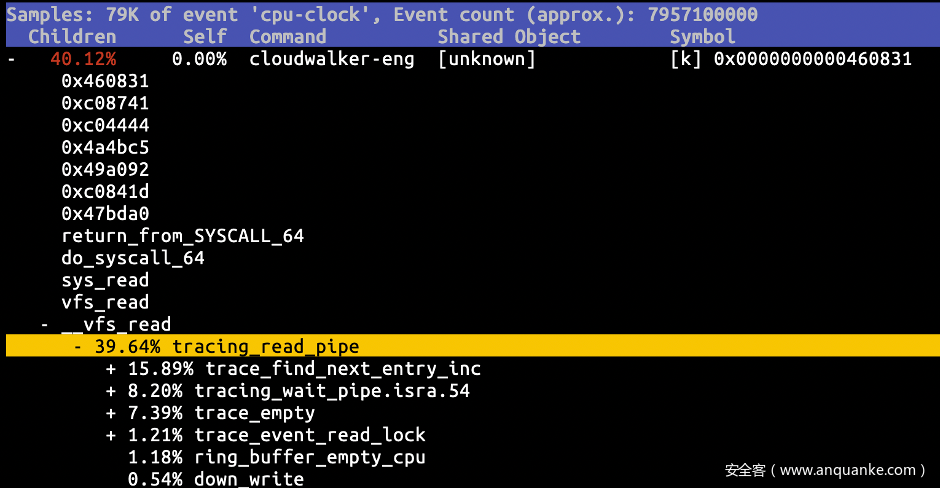
为了获悉当前5552 线程在内核态的执行状态,尝试执行 cat /proc/5552/stack,不料返回Running。幸好用户预装了perf 指令,使用 perf record -a -g 抓取系统全局的 callgrind,发现该进程似乎卡在了 trace_pipe 的读取函数(tracing_read_pipe)中。
先前已知社区报告过的和tracing_read_pipe 相关的死循环有一个是因为seq_buf_to_user() 函数错误使用可能会溢出的 seq_buf.len导致的,针对该问题的修复已经在Linux 主线版本 4.5 合并了。而出现问题的主机通过 uname -r 获取的版本号为 4.6.0-1.el7.elrepo.x86_64,通过反汇编/proc/kcore 中的 load2 节,查看 seq_buf_to_user 的实现发现确实包含了该修复。因此我们怀疑 tracing_read_pipe 中仍然有未修复的 bug,且用户的宿主机成功地触发了这个 bug。
为了创建更易于调试的环境,尝试让测试同事在内部测试环境安装部署该内核版本的发行版,并安装我们的产品,但无法复现该bug,说明该 bug 的复现条件可能比较复杂或者需要长时间运行才会复现,不适合当前情景下的问题排查。而在用户宿主机上该 bug 比较稳定且没有自动恢复的迹象,因此经过沟通后用户表示可以在用户宿主机上直接排查,但这台机器上虽然存在该 bug 但其部分业务仍然运行着,因此希望能在不能重启该机器的前提下进行排查,并尽可能给出不重启计算机就恢复系统的方案。
“土法”之使用perf跟踪执行流
我们知道调试linux 内核的一种有效的方式是使用 kgdb。而我们一般通过 kgdboc 来使用 kgdb:首先配置虚拟机的串口配置,使得另一台主机或者当前虚拟化平台可以通过串口与该宿主机通信,并设置 gdboc 的参数为被开放的串口;然后获取待调试宿主机的解压映像 vmlinux,为了方便调试还会获取当前内核的源码和调试信息;最后在待调试宿主机上通过 echo g > /proc/sysrq-trigger 发起内核态调试中断,然后远程主机启动 gdb 并连接到待调试宿主机的串口上进行调试。
但是这种调试方法在实际用户环境(特别是ToB 产品中的客户环境)中基本行不通:首先与我们对接提供远程的用户只能提供 SSH 连接访问,并没有权限修改当前宿主机的配置;其次我们也了解到用户的云主机提供商也没有提供串口配置的能力;再然后由于当前我们没有获取到任何信息,需要经常发起调试中断甚至单步调试来获取到有效信息,而每次发生调试中断都会导致宿主机整体被冻结,影响其正在运行的业务的连续性。
我们先前在排查的时候,发现用户在这台机器上安装了perf 指令,它最广为人知的一点是可以抓取用户态和内核态的执行流采样,并通过 perf report 等指令对抓取到的数据进行聚合,输出性能日志等报告用于诊断和优化等用途。而用户进行分析时往往会使用动态的过滤条件,因此 perf 抓取并持久化的是大量的采样数据,通过 perf script 等指令可以将采样数据输出为字符流形式。
我们最为熟悉的perf record 指令执行时会设置一个指定频率的计时器,每当计时器超时即会发出一个中断并执行 perf 抓取现场的中断处理函数,这种采样方式具有随机性,执行足够长时间就会形成覆盖主要执行流的“采样点云”,有点蒙特卡洛方法的意味;此外 perf record 还可以指定 -e mem:<addr>:x,设置某个调试寄存器DRx 的值为 <addr> 使得该地址被“执行访问”时产生调试中断(这一方法又被称为硬件断点)并进行抓取,而由于其抓取行为的确定性,主要用来针对“采样点云”覆盖不到但又对分析十分关键的地方进行采样。
由开头我们通过perf record -a -g 抓取的结果来看,tracing_read_pipe 是第一个调用了多个其他函数的函数,而从 5552 进程的表现来看,不妨大胆猜测由于 5552 进程执行系统调用时 tracing_read_pipe 函数发生了死循环以致该函数一直不返回并消耗大量 CPU。因此我们不妨先从 tracing_read_pipe 函数开始排查。
通过反汇编可以获悉tracing_read_pipe 函数在当前内核线性地址的 ffffffff811520e0~ffffffff811523fa 范围内。执行 perf record -a -I 周期性采样并在每次采样时抓取处理器现场,并执行 perf script –tid=5552 -F comm,pid,ip,iregs | sort | uniq 对采样数据进行去重和展示,筛选落在范围 ffffffff811520e0~ffffffff811523fa 内的数据,如下:
cloudwalker-eng 5552 ffffffff811521c9 ABI:2 AX:0xfffffffffffffff0 BX:0xfff CX:0xffff8804e7fc5098 DX:0x0 SI:0xc0002bc000 DI:0xffff8804e7fc6098 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff811521c9 FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff811521df ABI:2 AX:0x1 BX:0xfff CX:0xff0 DX:0x0 SI:0xffff8804acbcf940 DI:0x286 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff811521df FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff811521e8 ABI:2 AX:0x1 BX:0xfff CX:0xff0 DX:0x0 SI:0xffff8804acbcf940 DI:0x286 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff811521e8 FLAGS:0x202 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152204 ABI:2 AX:0xfff BX:0xfff CX:0xff0 DX:0x0 SI:0xffff8804acbcf940 DI:0x286 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152204 FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152208 ABI:2 AX:0xfff BX:0xfff CX:0xff0 DX:0x0 SI:0xffff8804acbcf940 DI:0xffff8804e7fc5098 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152208 FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152211 ABI:2 AX:0xfff BX:0xfff CX:0xff0 DX:0x0 SI:0xffff8804acbcf940 DI:0xffff8804e7fc5098 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152211 FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff8115221c ABI:2 AX:0xfff BX:0xfff CX:0xff0 DX:0x1060 SI:0xffff8804acbcf940 DI:0xffff8804e7fc5098 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff8115221c FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152230 ABI:2 AX:0xfff BX:0xfff CX:0xff0 DX:0x1060 SI:0xffff8804acbcf940 DI:0xffff8804e7fc5098 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152230 FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff8115223a ABI:2 AX:0x0 BX:0xfff CX:0x107 DX:0x1060 SI:0xffff8804acbcf940 DI:0xffff8804e7fc58c0 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff8115223a FLAGS:0x10246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff8115223a ABI:2 AX:0x0 BX:0xfff CX:0x117 DX:0x1060 SI:0xffff8804acbcf940 DI:0xffff8804e7fc5840 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff8115223a FLAGS:0x10246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff8115223a ABI:2 AX:0x0 BX:0xfff CX:0x127 DX:0x1060 SI:0xffff8804acbcf940 DI:0xffff8804e7fc57c0 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff8115223a FLAGS:0x10246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
... // 忽略约 20 条产生自 ffffffff8115223a 的记录,此时在进行 memset
cloudwalker-eng 5552 ffffffff8115223d ABI:2 AX:0x0 BX:0xfff CX:0x0 DX:0x1060 SI:0xffff8804acbcf940 DI:0xffff8804e7fc60f8 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff8115223d FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152258 ABI:2 AX:0x0 BX:0xfff CX:0x0 DX:0x1060 SI:0xffff8804acbcf940 DI:0xffff8804e7fc60f8 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152258 FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152260 ABI:2 AX:0x0 BX:0xfff CX:0x0 DX:0x0 SI:0xffff8804acbcf940 DI:0xffff8804e7fc60f8 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152260 FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152273 ABI:2 AX:0x0 BX:0xfff CX:0x0 DX:0x43 SI:0x0 DI:0xffff8808189d14e8 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152273 FLAGS:0x212 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152280 ABI:2 AX:0xffff8808189d14e8 BX:0xfff CX:0x0 DX:0x0 SI:0x0 DI:0xffff8808189d14f0 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152280 FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152290 ABI:2 AX:0xffffffff81c7db20 BX:0xfff CX:0x0 DX:0x0 SI:0x0 DI:0xffffffff81c7db20 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152290 FLAGS:0x202 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff811522bb ABI:2 AX:0xffff8807ef7abfc0 BX:0xfff CX:0x0 DX:0x0 SI:0x0 DI:0xffffffff81c7c1a0 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff811522bb FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff8115232d ABI:2 AX:0xffff8807ef7abfc0 BX:0xfff CX:0x0 DX:0x0 SI:0x0 DI:0xffffffff81c7c1a0 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff8115232d FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152335 ABI:2 AX:0x0 BX:0xfff CX:0x0 DX:0x4 SI:0x4 DI:0xffff88081f00a390 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152335 FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152364 ABI:2 AX:0xffffffff81c7c1a0 BX:0xfff CX:0x0 DX:0xffffffff00000001 SI:0x4 DI:0xffffffff81c7c1a0 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152364 FLAGS:0x257 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152369 ABI:2 AX:0xffffffff81c7db20 BX:0xfff CX:0x0 DX:0x1 SI:0x4 DI:0xffffffff81c7db20 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152369 FLAGS:0x257 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152386 ABI:2 AX:0xfffffff0 BX:0xfff CX:0x0 DX:0x1000 SI:0xc0002bc000 DI:0xffff8804e7fc6098 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152386 FLAGS:0x287 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff81152393 ABI:2 AX:0xfffffffffffffff0 BX:0xfff CX:0x0 DX:0x0 SI:0xc0002bc000 DI:0xffff8804e7fc6098 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff81152393 FLAGS:0x287 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff811523b6 ABI:2 AX:0xfffffffffffffff0 BX:0xfff CX:0xffff8804e7fc5098 DX:0x0 SI:0xc0002bc000 DI:0xffff8804e7fc6098 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff811523b6 FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff811523c1 ABI:2 AX:0xfffffffffffffff0 BX:0xfff CX:0xffff8804e7fc5098 DX:0x0 SI:0xc0002bc000 DI:0xffff8804e7fc6098 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff811523c1 FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff811523d3 ABI:2 AX:0xfffffffffffffff0 BX:0xfff CX:0xffff8804e7fc5098 DX:0x0 SI:0xc0002bc000 DI:0xffff8804e7fc6098 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff811523d3 FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0x2 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000
cloudwalker-eng 5552 ffffffff811523d3 ABI:2 AX:0xfffffffffffffff0 BX:0xfff CX:0xffff8804e7fc5098 DX:0x0 SI:0xc0002bc000 DI:0xffff8804e7fc6098 BP:0xffff8807babdbe18 SP:0xffff8807babdbdb0 IP:0xffffffff811523d3 FLAGS:0x246 CS:0x10 SS:0x18 R8:0x3 R9:0x0 R10:0xffff8808189d14e8 R11:0x0 R12:0xffffffffffffffff R13:0xffff8804e7fc60e0 R14:0xffff8804e7fc60c8 R15:0xffff8804e7fc4000通过对数据的观察,可以发现所有采样数据均落在了范围ffffffff811521a3~ffffffff811523dd 内,这是一个比 ffffffff811520e0~ffffffff811523fa 要小得多的范围,这也进一步为我们先前的 tracing_read_pipe 可能存在死循环的猜测提供了支持,tracing_read_pipe 的完整源码可以在 Bootlin 上找到。
static ssize_t
tracing_read_pipe(struct file *filp, char __user *ubuf,
size_t cnt, loff_t *ppos)
{
// ffffffff811520e0: 55 push %rbp
...
waitagain:
// ffffffff811521a3
...
if (sret == -EBUSY)
goto waitagain;
out:
mutex_unlock(&iter->mutex);
return sret;
// ffffffff811523fa: c3 retq
}最小的能包含所有采样数据的循环块位于waitagain 和 out 之间,满足 sret == -EBUSY 条件时通过 goto waitagain 发生循环。在函数入口 ffffffff811520e0 通过 perf record -e mem:0xffffffff811520e0:x -a -I 插入硬件断点抓取采样,发现没有捕捉到任何采样;同样的方法在函数出口 ffffffff811523fa 插入硬件断点也没有抓取到任何采样;而在 waitagain 开头 ffffffff811521a3 插入硬件断点却可以获得大量采样。这证明了 tracing_read_pipe 在标签 waitagain 和 out 之间发生了死循环,5552 进程进行的系统调用无法返回,从而导致 5552 进程一直处于 Running 状态无法被回收。
static int tracing_wait_pipe(struct file *filp)
{
struct trace_iterator *iter = filp->private_data;
int ret;
while (trace_empty(iter)) {
...
}
return 1;
}
static ssize_t
tracing_read_pipe(struct file *filp, char __user *ubuf,
size_t cnt, loff_t *ppos)
{
struct trace_iterator *iter = filp->private_data;
...
waitagain:
sret = tracing_wait_pipe(filp);
if (sret <= 0)
goto out;
/* stop when tracing is finished */
if (trace_empty(iter)) {
sret = 0;
goto out;
}
...
while (trace_find_next_entry_inc(iter) != NULL) {
/*
ffffffff8115232d: 4c 89 ff mov %r15,%rdi
ffffffff81152330: e8 1b e5 ff ff callq 0xffffffff81150850
ffffffff81152335: 48 85 c0 test %rax,%rax
ffffffff81152338: 75 91 jne 0xffffffff811522cb
*/
// cloudwalker-eng 5552 ffffffff81152335 ABI:2 AX:0x0
sret = trace_seq_to_user(&iter->seq, ubuf, cnt);
...
if (sret == -EBUSY)
goto waitagain;
/*
ffffffff811523d3: 48 83 f8 f0 cmp $0xfffffffffffffff0,%rax
ffffffff811523d7: 0f 84 ec fd ff ff je 0xffffffff811521c9
*/
// cloudwalker-eng 5552 ffffffff811523d3 ABI:2 AX:0xfffffffffffffff0
out:
...
}使用perf 追踪执行流的方式,我们抓取了一系列随机采样和硬件断点采样进行了分析,我们最后发现了 tracing_read_pipe 死循环的原因如下:
- trace_empty 函数持续返回 0 表示当前 tracing 实例非空,让 tracing_read_pipe 函数认为自己一直有数据可读;
- trace_find_next_entry_inc 又因为未知原因一直返回 0,导致tracing_read_pipe 函数无法消费并序列化任何数据;
- 最后承载了序列化后需要返回给用户的数据的&iter-seq 一直为空,trace_seq_to_user 一直返回 -EBUSY,一直重复这个死循环。
很显然trace_empty 函数和 trace_find_next_entry_inc 函数的返回值是矛盾的,若 tracing_read_pipe 函数的实现是正确的话(至少从读代码的角度没有发现不对的地方),它们之间的实现至少有一个是错误的,但单从它们在 tracing_read_pipe 函数中的表现无法得知存在何种错误,因此我们继续追踪和分析 trace_empty 函数和 trace_find_next_entry_inc 函数的实现。
int trace_empty(struct trace_iterator *iter)
{
...
for_each_tracing_cpu(cpu) {
buf_iter = trace_buffer_iter(iter, cpu);
if (buf_iter) {
...
} else {
if (!ring_buffer_empty_cpu(iter->trace_buffer->buffer, cpu))
return 0;
/*
ffffffff811513fb: 49 8b 54 24 10 mov 0x10(%r12),%rdx
ffffffff81151400: 89 c6 mov %eax,%esi
ffffffff81151402: 48 8b 7a 08 mov 0x8(%rdx),%rdi
ffffffff81151406: e8 c5 74 ff ff callq 0xffffffff811488d0 <ring_buffer_empty_cpu>
ffffffff8115140b: 84 c0 test %al,%al
ffffffff8115140d: 74 42 je 0xffffffff81151451
ffffffff81151451: 5b pop %rbx
ffffffff81151452: 41 5c pop %r12
ffffffff81151454: 31 c0 xor %eax,%eax
ffffffff81151456: 5d pop %rbp
ffffffff81151457: c3 retq
*/
// cloudwalker-eng 5552 ffffffff81151402 ABI:2 AX:0x0 BX:0x0 CX:0x0
// cloudwalker-eng 5552 ffffffff81151402 ABI:2 AX:0x1 BX:0x1 CX:0x0
// cloudwalker-eng 5552 ffffffff81151402 ABI:2 AX:0x2 BX:0x2 CX:0x0
// cloudwalker-eng 5552 ffffffff81151451 ABI:2 BX:0x2
}
}
return 1;
}通过对抓取到的采样进行分析,我们发现执行流在trace_empty 函数中我们发现我们依序访问了 CPU#0、CPU#1 和 CPU#2 的 trace buffer,并且可以看出当访问 CPU#2 时,!ring_buffer_empty_cpu(iter->trace_buffer->buffer, 2) 返回真导致函数返回,这也就意味着 trace_empty 一直返回 0 是 CPU#2 的 trace buffer “非空”的结果。
static struct trace_entry *
peek_next_entry(struct trace_iterator *iter, int cpu, u64 *ts,
unsigned long *lost_events)
{
struct ring_buffer_event *event;
struct ring_buffer_iter *buf_iter = trace_buffer_iter(iter, cpu);
if (buf_iter)
...
else
event = ring_buffer_peek(iter->trace_buffer->buffer, cpu, ts,
lost_events);
if (event) {
...
}
iter->ent_size = 0;
return NULL;
}
static struct trace_entry *
__find_next_entry(struct trace_iterator *iter, int *ent_cpu,
unsigned long *missing_events, u64 *ent_ts)
{
struct ring_buffer *buffer = iter->trace_buffer->buffer;
...
for_each_tracing_cpu(cpu) {
if (ring_buffer_empty_cpu(buffer, cpu))
continue;
ent = peek_next_entry(iter, cpu, &ts, &lost_events);
if (ent && (!next || ts < next_ts)) {
next = ent;
...
}
}
...
return next;
}
void *trace_find_next_entry_inc(struct trace_iterator *iter)
{
iter->ent = __find_next_entry(iter, &iter->cpu,
&iter->lost_events, &iter->ts);
if (iter->ent)
trace_iterator_increment(iter);
return iter->ent ? iter : NULL;
}而有了对trace_empty 的分析,甚至可以只通过读代码对 trace_find_next_entry_inc 进行分析。
当访问CPU#2 时,peek_next_entry(iter, 2, &ts, &lost_events) 被调用,我们已知 trace_find_next_entry_inc 返回了 NULL,这就意味着 peek_next_entry(iter, 2, &ts, &lost_events) 也必须返回 NULL 才会符合我们观察到的现象。
注意到peek_next_entry 也有一个与 trace_empty 中类似的与 trace_buffer_iter 的返回值相关的分支。已知 trace_empty 中调用 trace_buffer_iter(iter, cpu) 返回 NULL,这也就意味着采用同样的参数 peek_next_entry 的两个分支最终会采用 ring_buffer_peek 所在分支,最终调用 ring_buffer_peek(iter->trace_buffer->buffer, 2, ts, lost_events) 并返回了 NULL。
因此下一步应该对ring_buffer_empty_cpu(iter->trace_buffer->buffer, 2) 和 ring_buffer_peek(iter->trace_buffer->buffer, 2, ts, lost_events) 在给定参数时的执行流进行分析。
bool ring_buffer_empty_cpu(struct ring_buffer *buffer, int cpu)
{
struct ring_buffer_per_cpu *cpu_buffer;
...
cpu_buffer = buffer->buffers[cpu];
local_irq_save(flags);
...
ret = rb_per_cpu_empty(cpu_buffer);
...
local_irq_restore(flags);
return ret;
}
struct ring_buffer_event *
ring_buffer_peek(struct ring_buffer *buffer, int cpu, u64 *ts,
unsigned long *lost_events)
{
/*
ffffffff81148900: 55 push %rbp
...
ffffffff81148906: 49 89 d7 mov %rdx,%r15
ffffffff81148909: 48 63 d6 movslq %esi,%rdx
ffffffff8114890c: 89 f6 mov %esi,%esi
...
*/
struct ring_buffer_per_cpu *cpu_buffer = buffer->buffers[cpu];
/*
ffffffff81148919: 48 8b 47 48 mov 0x48(%rdi),%rax
ffffffff8114891d: 48 89 4d d0 mov %rcx,-0x30(%rbp)
ffffffff81148921: 4c 8b 34 d0 mov (%rax,%rdx,8),%r14
*/
// cloudwalker-eng 5552 ffffffff81148925 ABI:2 DX:0x2 R14:0xffff880814b9f200
...
again:
local_irq_save(flags);
...
event = rb_buffer_peek(cpu_buffer, ts, lost_events);
...
local_irq_restore(flags);
...
}但是在继续深入跟踪和调试ring_buffer_empty_cpu 和 ring_buffer_peek 函数时却犯了难,这两个函数执行时均会通过执行 local_irq_save 关闭中断,待执行完 rb_per_cpu_empty 函数和 rb_buffer_peek 函数后再恢复中断。而 perf 需要依赖中断才能完成采样的抓取,从结果上看我们也没有抓取到任何位于 rb_per_cpu_empty 和 rb_buffer_peek 内部的采样,我们只能通过别的方法继续进行调试了。
我们在ring_buffer_peek 函数内也抓到了位于 ffffffff81148925 的采样,其 R14 寄存器亦即 cpu_buffer(或buffer->buffers[2])的值为0xffff880814b9f200。而rb_per_cpu_empty 和 rb_buffer_peek 的操作对象均为 cpu_buffer,我们后续的跟踪与分析会使用该值。
“土法”之抓取内存与模拟执行
通过前一章的分析,我们发现ring_buffer_empty_cpu 和 ring_buffer_peek 最终会执行 rb_per_cpu_empty 和 rb_buffer_peek 函数,但在执行之前均会关闭中断以避免读操作被其他进程的执行流抢占。关闭中断之后采用 perf 跟踪执行流的方式即行不通了,需要采取其他方法来继续调试。
我们观察到rb_per_cpu_empty 和 rb_buffer_peek 分别为 cpu_buffer 所对应数据结构上的读操作和写操作,我们甚至可以大胆作出假设:若我们能读取出 cpu_buffer 及其关联子对象的内存,并利用读取的内存拼接成对应的内核对象,“离线”执行 rb_per_cpu_empty 和 rb_buffer_peek 的源代码,那么“离线”执行结果和执行流将会与用户宿主机上的一致,利用这个特点我们可以有效定位发生异常的代码。
我们知道/proc/kcore 本质上是 proc 文件系统虚拟的内核内存转储文件(或称 core 文件),我们知道内存转储文件是一个 ELF 格式的文件,它会包含多个 Program Header,而使用内存转储文件时 loader 会根据 Program Header 文件的内容从内存转储文件的给定偏移量处拷贝给定大小的连续数据片,并加载到当前 Program Header 要求的虚拟地址处。
那么反过来,我们要获取一段内核中大小为size 的内存 addr,只需要在/proc/kcore 中找到某个 Program Header prog,使得prog.Vaddr <= addr 且 addr+size <= prog.Vaddr+prog.Filesz,随后在/proc/kcore 中 seek 文件偏移 prog.Off+addr-prog.Vaddr 并读取大小为 size 的内存,其中 prog.Vaddr 是当前 Program Header 的虚拟地址,prog.Off 是当前 Program Header 在文件中的偏移,prog.Filesz 是当前 Program Header 在文件中的大小。
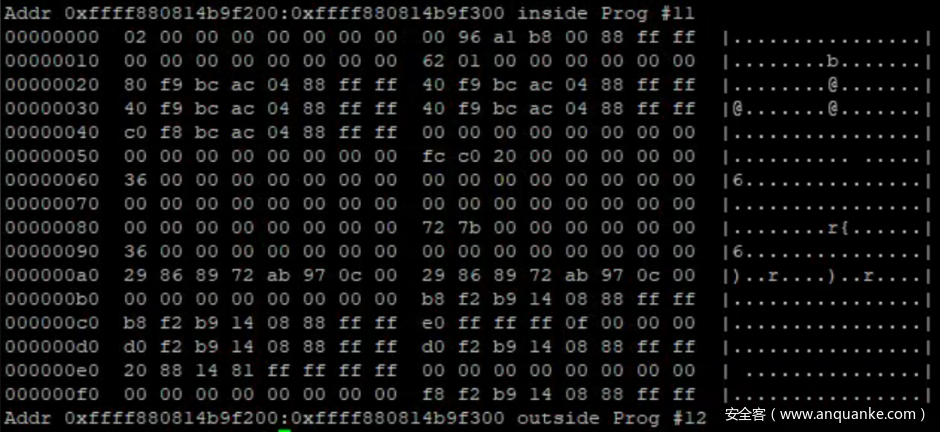
基于这个原理我们编写了一个小程序并抓取了位于0xffff880814b9f200 亦即 cpu_buffer 的开头 256 字节内存。
struct ring_buffer_per_cpu {
int cpu; // 0x00
...
struct list_head *pages; // 0x20
struct buffer_page *head_page; // 0x28
struct buffer_page *tail_page; // 0x30
struct buffer_page *commit_page; // 0x38
struct buffer_page *reader_page; // 0x40
unsigned long lost_events; // 0x48
unsigned long last_overrun; // 0x50
local_t entries_bytes; // 0x58
local_t entries; // 0x60
local_t overrun; // 0x68
local_t commit_overrun; // 0x70
local_t dropped_events; // 0x78
local_t committing; // 0x80
local_t commits; // 0x88
unsigned long read; // 0x90
unsigned long read_bytes; // 0x98
u64 write_stamp; // 0xa0
u64 read_stamp; // 0xa8
...
};通过查看源码我们可知cpu_buffer 的类型为 struct ring_buffer_per_cpu,并且通过分析源码获得了该结构体中一些关键字段的偏移。
通过比对抓取的内存与给定的结构体,我们可以获悉当前cpu 的值为 2,与预期的需要访问CPU#2 的 cpu_buffer 相符。同时我们知道了 reader_page 为 0xffff8804acbcf8c0,而head_page、tail_page 和 commit_page 均为 0xffff8804acbcf940,entries 和 read 均为 0x36 而 overrun 和 commit_overrun 为 0x0。
static inline unsigned rb_page_commit(struct buffer_page *bpage)
{
//return local_read(&bpage->page->commit);
return bpage->page->commit;
}
static bool rb_per_cpu_empty(struct ring_buffer_per_cpu *cpu_buffer)
{
struct buffer_page *reader = cpu_buffer->reader_page;
//struct buffer_page *head = rb_set_head_page(cpu_buffer);
struct buffer_page *head = cpu_buffer->head_page;
struct buffer_page *commit = cpu_buffer->commit_page;
/* In case of error, head will be NULL */
if (unlikely(!head))
return true;
return reader->read == rb_page_commit(reader) &&
(commit == reader ||
(commit == head &&
head->read == rb_page_commit(commit)));
}我们不妨先来看rb_per_cpu_empty 的实现,其完整实现可以在 Bootlin 上找到。通过读代码我们可知 rb_per_cpu_empty 获取的变量名为 reader、head 和 commit 的 buffer_page,并基于其中的read 和 page->commit 等字段进行运算和比较,最终输出当前 struct ring_buffer_per_cpu 结构体是否为空的结论。
值得注意的是,在获取变量名为head 的 buffer_page 时,其采用了一个比较复杂的 rb_set_head_page 函数,从实现上看它会检查当前的 cpu_buffer->head_page 是否为满足 head page 条件的页面,如果不满足会不断获取下一个页面直到找到 head page,同时更新 cpu_buffer->head_page 字段。其内部逻辑比较复杂,而且我们后来尝试重复多次获取 cpu_buffer 对应内存的内容并未发现任何变化,因此为了简化我们大胆假设当前 cpu_buffer->head_page 就是 rb_set_head_page(cpu_buffer) 会返回的结果。适当的简化对于我们后续的模拟执行十分有帮助。
同样地,local_read 是一个原子读操作,而由于我们观察到 bpage->page->commit 的值未被修改过,因此我们可以大胆地将其替换成直接返回 bpage->page->commit。
struct buffer_data_page {
u64 time_stamp; /* page time stamp */ // 0x00
local_t commit; /* write committed index */ // 0x08
unsigned char data[]
RB_ALIGN_DATA; /* data of buffer page */ // 0x10
};
struct buffer_page {
struct list_head list; /* list of buffer pages */ // 0x00
local_t write; /* index for next write */ // 0x10
unsigned read; /* index for next read */ // 0x18
local_t entries; /* entries on this page */ // 0x20
unsigned long real_end; /* real end of data */ // 0x28
struct buffer_data_page *page; /* Actual data page */ // 0x30
};同样地,对struct buffer_page 和 struct buffer_data_page 结构体进行些许分析,可以得出这些结构体中对应字段的偏移量。
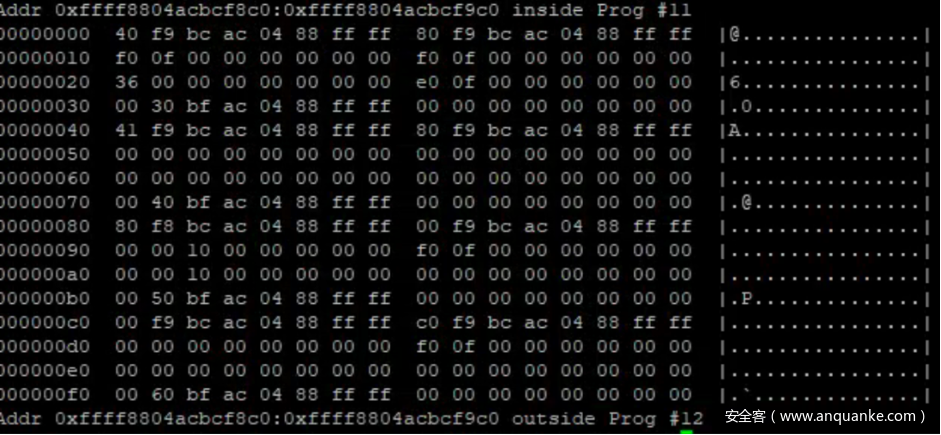
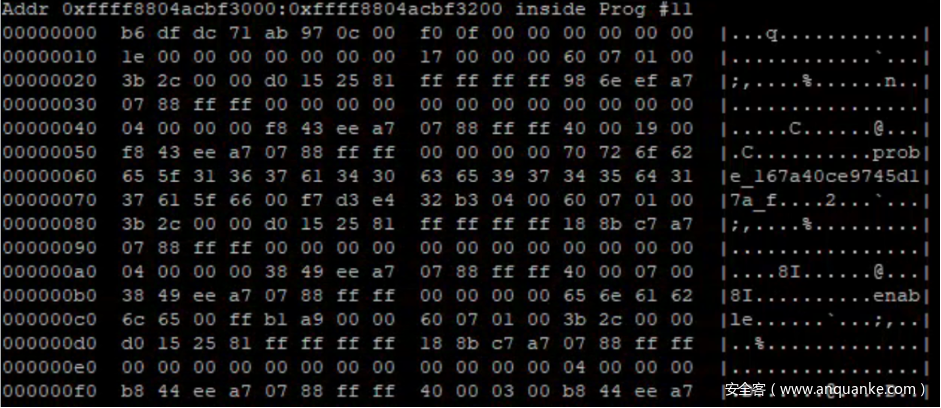
我们抓取了cpu_buffer->reader_page 亦即 0xffff8804acbcf8c0 开头的 256 字节数据,并依据 struct buffer_page 的结构收集了数据。同时据此知道了 cpu_buffer->reader_page->page 的地址为 0xffff8804acbf3000,同样地依据struct buffer_data_page 的结构收集了数据。注意 data 的数据是变长的,包含了实际抓取的 tracing 采样,我们暂时忽略这些数据。
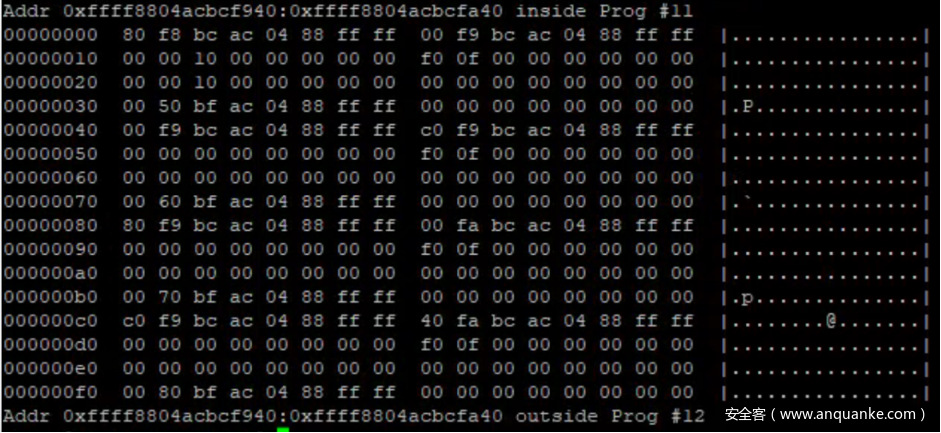
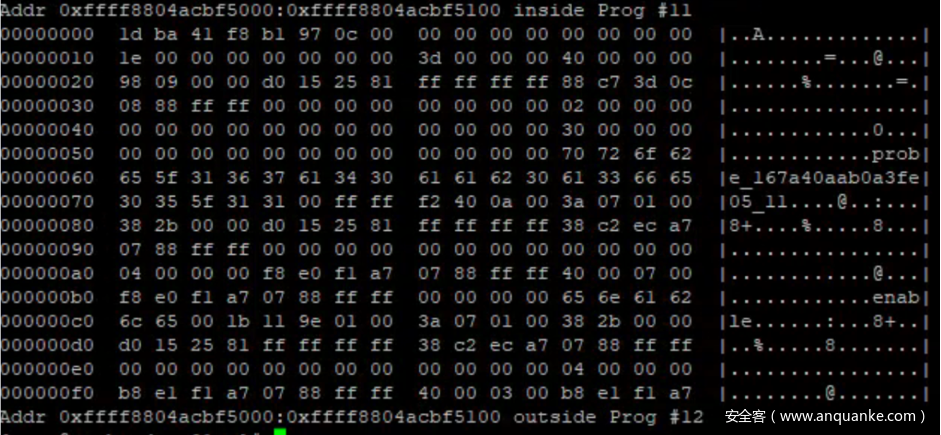
我们抓取了cpu_buffer->commit_page 亦即 0xffff8804acbcf940 开头的 256 字节数据,并依据 struct buffer_page 的结构收集了数据。同时据此知道了 cpu_buffer->commit_page->page 的地址为 0xffff8804acbf5000,同样地依据struct buffer_data_page 的结构收集了数据。
struct buffer_data_page reader_data = {
.time_stamp = 0x000c97ab71dcdfb6,
.commit = 0x0ff0,
};
struct buffer_page reader_buffer = {
.write = 0x0ff0,
.read = 0x0ff0,
.entries = 0x0036,
.real_end = 0x0fe0,
.page = &reader_data,
};
struct buffer_data_page commit_data = {
.time_stamp = 0x000c97b1f841ba1d,
.commit = 0x0000,
};
struct buffer_page commit_buffer = {
.write = 0x100000,
.read = 0x000ff0,
.entries = 0x100000,
.real_end = 0x0,
.page = &commit_data,
};
struct ring_buffer_per_cpu cpu_buffer = {
.cpu = 2,
.head_page = &commit_buffer,
.tail_page = &commit_buffer,
.commit_page = &commit_buffer,
.reader_page = &reader_buffer,
.lost_events = 0,
.last_overrun = 0,
.entries_bytes = 0x20c0fc,
.entries = 0x36,
.overrun = 0,
.commit_overrun = 0,
.dropped_events = 0,
.committing = 0,
.commits = 0x7b72,
.read = 0x36,
.read_bytes = 0,
.write_stamp = 0x0c97ab72898629,
.read_stamp = 0x0c97ab72898629,
};首先我们把这些收集到的数据给单独“抄出来”,因为我们暂时不知道这些结构体中哪些数据要用到,我们把已知结构体中所有数据都抄上。对于这些结构体引用的指针(譬如 cpu_buffer->pages,(struct buffer_page*)bpage->list_head 的两个链表指针),我们可以先置为 NULL,若后续模拟执行时访问到这些指针,势必会产生一个段错误,这时我们再去获取这些指针的内容(后来的模拟执行证明了只需要这些数据就能产生我们原先看到的结果)。
然后我们把rb_per_cpu_empty 亦即 rb_buffer_peek 的实现给抄过来,这两个函数均定义于 ring_buffer.c 文件里,完整源码可以在 Bootlin 上找到。每次抄完一个函数之后,使用 gcc 编译一下,即会告诉你哪些类型、函数和宏未定义,这个时候再依次把未定义的结构体、函数和宏定义抄过来即可。
...
#include <stdio.h>
int main(int argc, char** argv) {
printf("rb_per_cpu_empty: %d\n",
rb_per_cpu_empty(&cpu_buffer));
u64 ts; unsigned long lost_events;
printf("rb_buffer_peek: %lx\n",
rb_buffer_peek(&cpu_buffer, &ts, &lost_events));
return 0;
}最后待所有rb_per_cpu_empty 和 rb_buffer_peek 函数依赖的类型、函数和宏都定义,抄写的文件得以在 gcc 编译通过之后,我们加上一个 main 函数,并执行编译后的程序,它很快就打印了两个函数调用返回值均为 0,并没有产生任何其他错误就退出了,这也就验证了“离线”运行 cpu_buffer 的数据结构也能产生一样的结果的猜想,同时我们可以直接用 gdb 跟踪这个本地编译的函数,看下经历了怎么样的运算产生了我们看到的结果。
跟踪到rb_per_cpu_empty 函数返回 0 的最终原因是 commit == head 条件被满足,但是 head->read 的值为 0xff0,但rb_page_commit(commit) 亦即 commit->page->commit 为 0x0,head->read == commit->page->commit 为假故当前 cpu_buffer 非空。
static inline unsigned long
rb_num_of_entries(struct ring_buffer_per_cpu *cpu_buffer)
{
//return local_read(&cpu_buffer->entries) -
// (local_read(&cpu_buffer->overrun) + cpu_buffer->read);
return cpu_buffer->entries -
(cpu_buffer->overrun + cpu_buffer->read);
}
static struct buffer_page *
rb_get_reader_page(struct ring_buffer_per_cpu *cpu_buffer)
{
struct buffer_page *reader = NULL;
...
again:
...
/* check if we caught up to the tail */
reader = NULL;
if (cpu_buffer->commit_page == cpu_buffer->reader_page)
goto out;
/* Don't bother swapping if the ring buffer is empty */
if (rb_num_of_entries(cpu_buffer) == 0)
goto out;
...
out:
...
return reader;
}
static struct ring_buffer_event *
rb_buffer_peek(struct ring_buffer_per_cpu *cpu_buffer, u64 *ts,
unsigned long *lost_events)
{
struct ring_buffer_event *event;
struct buffer_page *reader;
...
reader = rb_get_reader_page(cpu_buffer);
if (!reader)
return NULL;
...
}跟踪到rb_buffer_peek 函数返回 NULL 的原因是 rb_buffer_peek 最终执行到 rb_get_reader_page 函数时,rb_num_of_entries(cpu_buffer) == 0 为真,它基于 cpu_buffer->entries – (cpu_buffer->overrun + cpu_buffer->read) 进行运算(我们这里依旧略去了 local_read 的原子操作),0x36 – (0x0 + 0x36) 最后求得 0。
这样我们通过抓取内存并模拟执行的方式,知道了cpu_buffer 中存在的一对矛盾:
- cpu_buffer->header_page == cpu_buffer->commit_page 但是 cpu_buffer->header_page->read != cpu_buffer->commit_page->commit,所以cpu_buffer 非空而应该有数据可读;
- 是cpu_buffer->entries – (cpu_buffer->overrun + cpu_buffer->read) 为 0 所以 cpu_buffer 为空而应该没有数据可读。
显然cpu_buffer 不可能同时为空和非空,这两组字段的处理至少有一组是错误的,但是我们尚不知道哪组字段的处理是错误的,或者我们可能不得不承认到目前为止我们都不知道 cpu_buffer 这堆处理实际的语义是什么。不仅如此,我们也不知道要经历什么样的步骤才能在用户异常宿主机以外的地方复现该问题。
“土法”之主动构造法
我不知道分析和修复一个bug 应不应该是一个稳定的过程,哪怕对于体现在代码执行流上的 bug 亦是如此。但是我可以肯定的是,对于代码执行流上的 bug,只要你能知道如何百分百稳定复现一个 bug,就一定能知道如何修复它;反过来假设你能修复一个 bug,就一定知道怎么百分百稳定复现它。
通过阅读ring_buffer.c 的代码,我们发现与 cpu_buffer 上的操作有关的代码足有 5007 行,而且我们不知道这些操作中哪些操作是对最终的 bug 有贡献的,抑或是不是所有操作都会对最终的 bug 有贡献。如果单纯地靠读代码就能发现原来代码中存在这样的 bug,那我们想象一下这段代码曾经经过 Linus Torvalds 的评审,我们有理由相信他比我们更有可能靠读代码发现这样的 bug。
因此我们一开始的目标就不应该冲着读代码然后从代码的字里行间找出可能存在bug 的地方去,那样会消耗调试者的大量精力,“妙手”偶得几个认为是 bug 的地方,结果可能并不存在 bug。我们认为一开始的目标应该是冲着如何构造能触发这个 bug 的条件去,要注意我们在前两章的操作中已经知道了一旦产生 bug,cpu_buffer 将会长成的样子,我们现在唯一不知道的是能通过什么样的操作让它长成那个样子。
当然无论是读代码找bug 还是构造触发 bug 的条件,如果不了解对应的算法的基本原理,很可能大部分工作都是无用功,因此在动手之前应该先尝试理解与 cpu_buffer 有关的算法的原理。
文档ring-buffer-design.rst 描述了与 cpu_buffer 有关的 Ring Buffer 数据结构及其有关算法,Ring Buffer 由一系列页面组成,而其上的算法主要包含主要页内读写和页间读写两部分:
- 初始化时会依据tracefs 下诸如 buffer_size_kb 等配置分配一系列页面,初始化一系列 struct buffer_page 类型结构体并使得它们指向分配的页面,这些结构体通过 (struct buffer_page*)bpage->list 字段构成循环链表,一开始 head_page、tail_page 和 commit_page 均指向循环链表的表头;同时分配和初始化单一页面,初始化 struct buffer_page 并使 reader_page 指向该结构体,reader_page->page 指向分配的单一页面。
- 当tracing 事件发生并采集到数据后,将会往当前 cpu_buffer 写入数据,写入分为保留写入页面和提交/放弃写入页面两步,当前 CPU 上的写者可以被抢占导致同一 CPU 上出现多个写者。当需要保留的缓冲大小能被当前页面的剩余空间放下时,在当前页面分配缓冲供后续写入并更新当前页面的 tail_page->write 字段;当需要保留的缓冲大小大于当前剩余空间时,会更新 tail_page 的链表指针为 tail_page 的下一页面。
- 写者写入完数据之后需要提交/放弃写入,以告知当前读者有数据可读。考虑因抢占导致存在的多个写者的情况,此时应该是抢占的写者先写完,而被抢占的写者后写完,若一个写者写入时被多次抢占,则他们按照后进先出的原则进行写入。当最初保留空间的写者(也就是最初被抢占的写者)提交或放弃写入时,会依次修改 commit_page->page->commit 字段为 commit_page->write 字段,直到 commit_page 追及 tail_page。
- 当tracing 从一个非空的 tracing 实例读取数据时,首先会通过页内读取算法尝试读取当前 reader_page 中剩余的数据,这可以通过比较 reader_page->read 和 reader_page->page->commit 字段(正如我们在 rb_per_cpu_empty 中看到的那样),若不相同则代表由数据可读。
- 若当前reader_page 中的数据已经读完,并且 head_page 中有数据可读,则需要通过一个无锁算法,将当前 reader_page 和当前 head_page 实现“互换”,同时 head_page 指向当前 head_page 的下一个页面。值得注意的是,这样会产生一个特殊的情况,就是当被交换的页面就是最后有数据写入的页面时,reader_page、commit_page 和 tail_page 会指向同一个页面,这个页面的下一个页面指向 head_page。
再依据这个算法的原理去考察我们在上一章中获得的数据,首先从reader_page->read == reader_page->page->commit 依据规则 #4 可知当前 cpu_buffer 的 reader_page 应该处于被读完的状态;然后 rb_per_cpu_empty 中进行了一个判断,发现 head_page == commit_page 而 commit_page->read != commit_page->page->commit 依据规则 #5 应该执行 Ring Buffer 的无锁算法交换 head_page 和 reader_page 并读取其上的数据,而这个无锁算法极有可能在 rb_buffer_peek(及其调用的函数)中执行的。可是根据已有的观察,我们得知rb_buffer_peek 认为 head_page 无数据可读而不应该被 reader_page 替换掉。
同时从ffff8804acbf5000 获取到的数据,检查后发现它具有合法的 ring_buffer_event 结构,可知 head_page->page 可能含有有效的数据并且等待读取。尽管不知道为什么 head_page->page->commit 为 0,以及为什么cpu_buffer->entries == cpu_buffer->overrun + cpu_buffer->read 成立。因此我们不妨从头开始,观察一下这套算法的各个步骤在 cpu_buffer 数据结构上会产生什么样的效果。
由于我自己的宿主机上没有别的使用tracing 的进程在跑,因此我决定直接在 /sys/kernel/debug/tracing/trace 上进行观察和验证。
由前面的观察我们知道当我们cat /sys/kernel/debug/tracing/trace_pipe 时,会先通过 trace_empty 验证 trace_pipe 上是否有可读内容,而 trace_empty 最终会通过 ring_buffer_empty_cpu 中的 cpu_buffer = buffer->buffers[cpu] 获取到当前 CPU 的 cpu_buffer,这也是我们观察的起点。
在/proc/kallsyms 文件中我得知我宿主机上 ring_buffer_empty_cpu 函数的地址为 ffffffff8e58abf0,查看/proc/kcore 的 load2 节的反汇编并进行一些跟踪,最终我发现在 ffffffff8e58ab70 处执行了 mov (%rax,%rsi,8),%r13 指令。
因此通过perf record -a -I -e ‘mem:0xffffffff8e58ab74:x’ 在这条指令执行完成的下一条指令插入硬件断点。执行 cat /sys/kernel/debug/tracing/trace_pipe 即可触发该硬件断点。为了简化我们只关心 CPU#0 的 cpu_buffer,可知它为0xffff99237e40aa00。

可以发现cpu_buffer 的结构与用户机器上获取到的略有不同。我的宿主机上的 Linux 内核版本为 5.0.0-38-generic,查看内核源码可知struct ring_buffer_per_cpu 比起用户的 4.6.0-1.el7.elrepo.x86_64 的对应结构体多了一些字段。重新计算了一下可知 pages 字段的偏移量应该变成了 0x30。
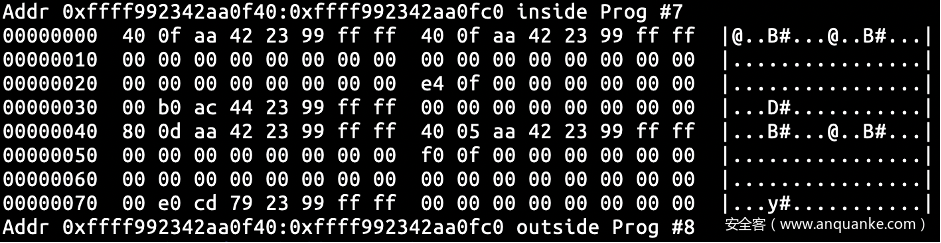
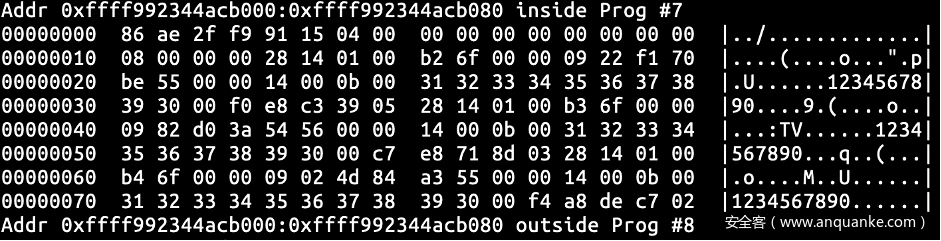
获取reader_page 及 reader_page->page 的内存状态。由先前获取的数据可知 reader_page 的地址为 ffff992342aa0f40,通过reader_page 的内存数据可知 reader_page->page 的地址为 ffff992344acb000。初始状态下reader_page 和 reader_page->page 中的关键字段(如 write 和 commit 等字段)置 0,其他字段被垃圾值填充。
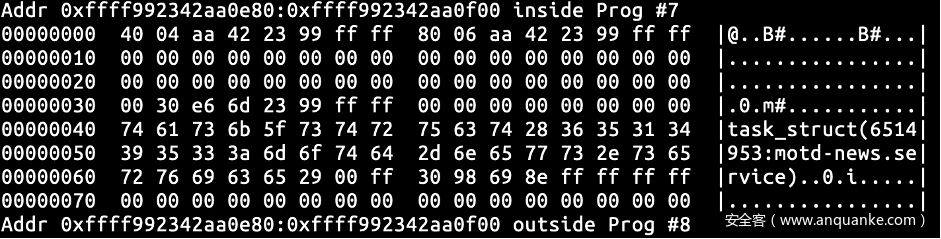

类似地获取head_page 及 head_page->page 的内存状态,由先前获取的数据可知 head_page 的地址为 ffff992342aa0e80,通过head_page 的内存状态可知 head_page->page 的地址为 ffff99236de63000。head_page 与 reader_page 有类似的初始化状态。
#define _GNU_SOURCE
#include <sys/types.h>
#include <sched.h>
#include <stdio.h>
#include <errno.h>
#include <unistd.h>
void tracepoint(char* content) {
printf("input content: %s\n", content);
}
int main(int argc, char** argv) {
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(0, &cpuset);
if(sched_setaffinity(getpid(), sizeof(cpuset), &cpuset) < 0) {
perror("sched_setaffinity");
return -1;
}
if(sched_yield() < 0) {
perror("sched_yield");
return -1;
}
tracepoint(argv[1]);
return 0;
}然后编写一个简单的程序往CPU#0 的 cpu_buffer 里填充数据,通过往 tracepoint 添加 UProbe,执行该程序即可产生 tracing 事件并填充数据。为了确保数据能稳定地填充到 CPU#0 的 cpu_buffer,我们通过sched_setaffinity 设置了 CPU 关联性;同时为了确保填充数据的大小可控,我们接收进程命令行的第一个参数并把它作为 tracepoint 的传入参数。

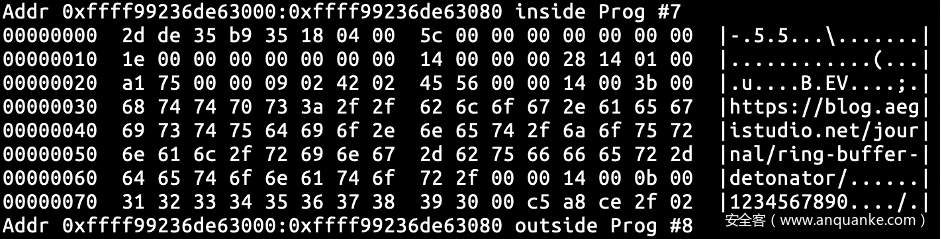
执行该程序并指定https://blog.aegistudio.net/journal/ring-buffer-detonator/ 为参数(原谅我加点水印),可以看见 head_page 的内容发生了变化,其中 write 和 page->commit 变成了 0x5c,且缓冲数据中填入了我们先前输入的字符串。

执行cat /sys/kernel/debug/tracing/trace_pipe 消费缓冲区里的已有数据,然后查看 cpu_buffer,可以看到tail_page、commit_page 和 reader_page 均指向了 ffff992342aa0e80,而head_page 指向了 ffff992342aa0440 亦即原来 head_page 的下一个节点,符合规则 #5。
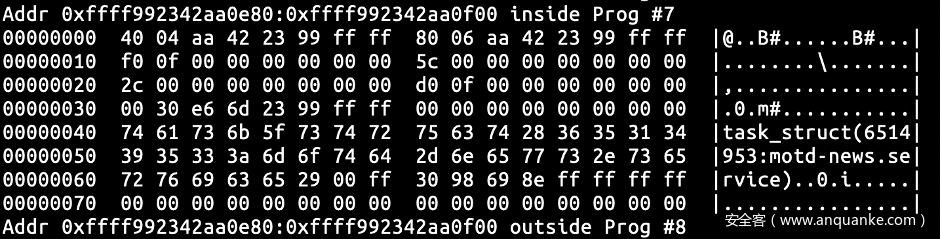


试下把当前页面填满并消费。手动循环填充事件,并且观察ffff992342aa0e80 的 write 字段,直到它不再增长,说明此时当前页面已经写满。再通过 cat /sys/kernel/debug/tracing/trace_pipe 消费缓冲区,依据已知算法可知 ffff992342aa0e80 将会归还到缓冲区中。
当页面归还到缓冲区中时,我们可以发现当前页面的write 和 page->commit 字段被置为 0,但是read 字段仍为其原来的值即 0xff0。这和我们先前观察到的现象很相似,难道说我们在这里就重新了原来的bug 了?这似乎有点过于容易复现了。
依据cpu_buffer 是一个循环缓冲的事实,只需往缓冲中填充数据直到填满,最后将写入到一开始的页面,此时再消费所有数据也会回到开头。于是我们在 bash 里写一个 while 循环,执行填充数据的进程直到 cpu_buffer 被填满。通过观察 /sys/kernel/debug/tracing/trace 中 #entries-in-buffer/entries-written: … 即可知道当前缓冲是否被填充完成。
于是等到缓冲填充完成后,我们再通过cat /sys/kernel/debug/tracing/trace_pipe 所有数据都消费了。假设我们这就发现了 bug 的话,理论上在消费完成的那一刻即会触发死循环。当然正如大多数读者所料到的那样,通过这么简单的步骤并不能重现这个 bug(否则这个 bug 应该一早就被修复了),我们只得继续深入探索并寻求原因。
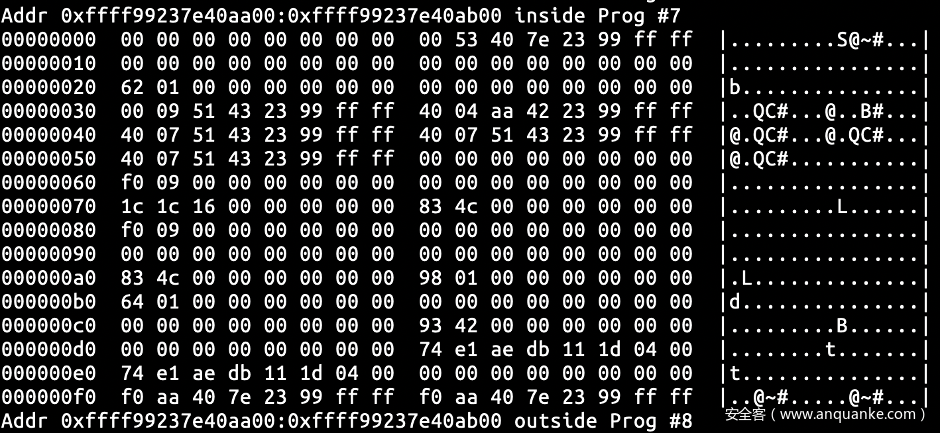
不妨来观察下当我们完成上一个操作时cpu_buffer 的状态,通过重新获取内存可知当前处于 tail_page、commit_page 和 reader_page 指向同一页面的状态,而 rb_per_cpu_empty 函数在判断当然 cpu_buffer 是否为空时,由于 commit_page == reader_page 将会返回 true。而我们在客户处观察到的现象为commit_page 和 head_page 为同一页面,而不是现在这种状况。
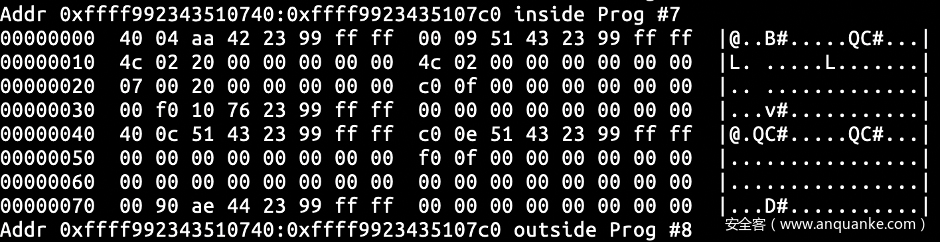

再来观察下当前的reader_page 和 head_page,我们发现head_page 中仍有先前读者留下的 read 字段的垃圾值。那我们再尝试用原来的方式进行填充直到刚好有记录写到 head_page。
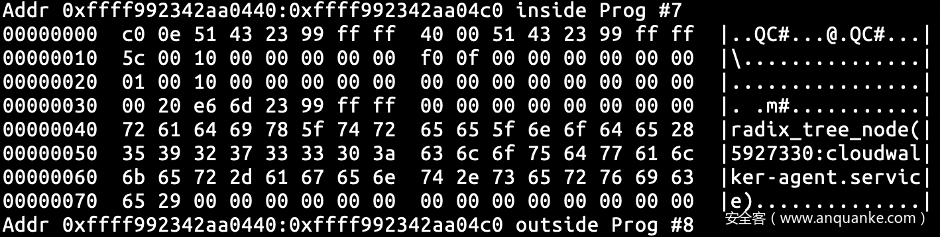
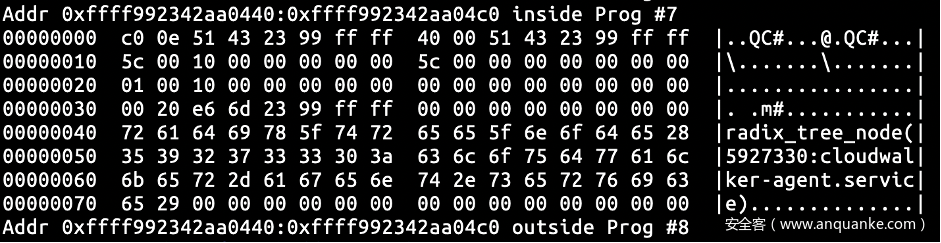
先填充到有数据写入head_page,此时有大小为0x5c 的数据写入并提交到了 head_page,而head_page->read 仍为垃圾值。而当使用 cat /sys/kernel/debug/tracing/trace_pipe 读取数据后,head_page->read 的数据变成了 0x5c,说明当head_page 和 reader_page 进行交换后,应该对 reader_page->read 进行了清零处理,这样看若 rb_per_cpu_empty 不走 head_page == commit_page 的分支,read 中的垃圾值是不会造成算法的异常的。
所以到这里我们的思路就很明确了:想办法让head_page == commit_page 并且 head_page->page->commit 为 0,但head_page->read 为垃圾值。
要使head_page == commit_page 很简单,由我们前面的观察就知道若原来 reader_page 和 commit_page 为同一页面时,往页面中填充足够的数据直到数据要写入到下一个缓冲页,写者就会更新指针并写入到 head_page,因为head_page 是 reader_page 的下一页。同时写者并不会去修改 read 的值,因此它将一直保持为垃圾值的状态。
但head_page->page->commit 等于 0 怎么构造呢?得找一个更新了 commit_page 和 tail_page 指针但却不往其中写入数据的方法。回忆了一下算法,cpu_buffer 的写者似乎除了提交数据之外,还有一个对应的放弃数据的操作。搜了一下源代码,还真有一个叫 ring_buffer_discard_commit 的函数。
假设我们下一次写入数据时,将需要分配一个新的页面来存放数据。根据规则#2,当有一个写者有数据要写入时,势必会更新 tail_page 指针。而稍微读一下 ring_buffer_commit_discard 函数及其调用的函数的代码,会发现它和正常的提交流程一样,都会调用 rb_set_commit_to_write 函数,这个函数将会更新 commit_page 指针为 tail_page,以满足规则#3。
在Bootlin 上搜索 ring_buffer_discard_commit 的调用者,发现只有一个真实的调用者 __trace_event_discard_commit,这个函数在call_filter_check_discard 和 __event_trigger_test_discard 中被调用,均至少需要满足两个条件:一个是某个叫 struct trace_event_call 的结构体里 flags 字段包含 TRACE_EVENT_FL_FILTERED;另一个是产生的事件不满足当前设置的过滤条件(从函数名上看)。

于是我先手动填充reader_page 缓冲到再产生一个事件就会触发 tail_page 的移动,这里我手贱误操作了一下(不得不说 Ctrl+R 有时真的挺坑人的),新的 reader_page 为 ffff992343510680。我不知道产生事件时所需要的flags 字段会不会有 TRACE_EVENT_FL_FILTERED 标志,但是我们不妨假设它有试试。于是我设置过滤条件为匹配空字符串,并用一个足够长的载荷触发这个事件,再获取当然 reader_page 的状态,发现其没有任何变化。
通过/proc/kallsyms 得知 ring_buffer_discard_commit 函数的地址为 ffffffff8e58b3d0,ring_buffer_lock_reserve 函数的地址为 ffffffff8e589dd0,在他们上面分别通过perf 插入硬件断点并执行产生事件的程序,发现二者均未能捕获到任何采样。这说明在产生了事件之后,它的调用者进行了一些处理,使得不需要在 cpu_buffer 中保留写者空间即可完成对事件的过滤。
通过一番(略痛苦的)代码的阅读与检索后,我们最终锁定了一个名为trace_event_buffer_lock_reserve 的函数,其完整源代码可以见 Bootlin。这个函数内做了一些优化,当产生事件之后会先使用trace_buffered_event 的 per-CPU 变量存储数据,若事件要被写入再在 __buffer_unlock_commit 提交事件。查找 /proc/kallsyms 中获得 trace_event_buffer_lock_reserve 的地址为 ffffffff8e58d900,插入硬件断点后执行产生事件的程序,能捕获采样,验证了我们的猜想。
而trace_event_buffer_lock_reserve 中使用 trace_buffered_event 有一个前提为 !ring_buffer_time_stamp_abs(*current_rb),或者说我们只需要让这个条件不成立即可关闭当前trace_event_buffer_lock_reserve 使用 trace_buffered_event 的优化。
通过读代码可知ring_buffer_time_stamp_abs 返回了当前 ring_buffer 的 time_stamp_abs 字段,并且只有 ring_buffer_set_time_stamp_abs 会修改它,而要关闭优化需要 time_stamp_abs 字段的值为 true 。
一直向上追溯可以发现所有 ring_buffer_set_time_stamp_abs 的调用者均来自于 trace_events_hist.c 文件,而将 time_stamp_abs 设为 true 的地方只有一个,那就是在 tracing 的 trigger 里指定启用时间戳的 hist,详见 Bootlin。
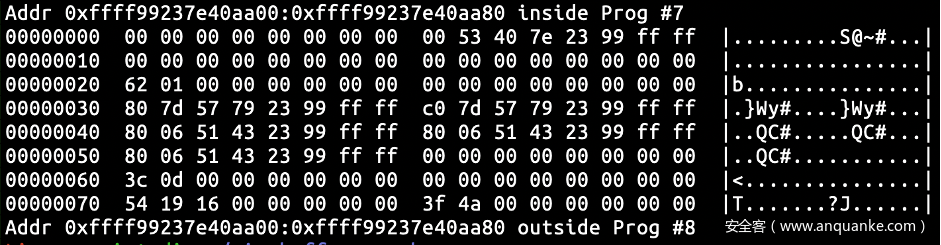
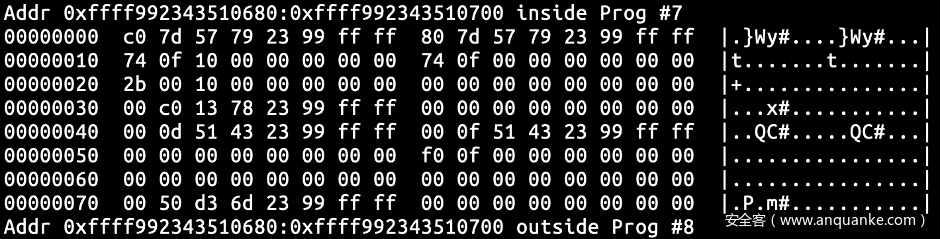

阅读了一下相关的文档和代码,要达到上述目的的一个比较简单的方法是指定hist:key=common_timestamp 为我们关心的事件的 trigger。执行之后发现它把我们的缓冲直接清了,因此我重头开始构造一遍前文所述的状态。
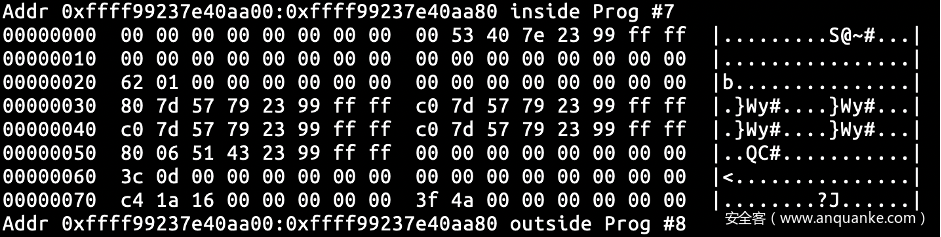
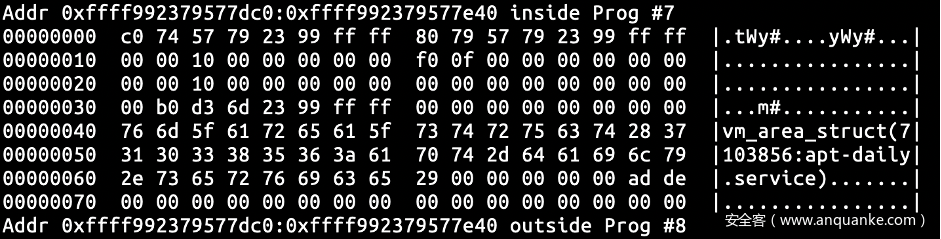

设置过滤器为仅接收空字符串,并执行我们的程序创建一个较大的载荷。可以看到执行完之后head_page,commit_page 和 tail_page 指向了原来的 head_page,head_page->read 为垃圾值而 head_page->page->commit 为 0。
事不宜迟让我们尝试执行一下cat /sys/kernel/debug/tracing/trace_pipe,执行后cat 进程占用的 CPU 占到了 100%,并且没有办法通过简单的 Unix 信号将其杀死,显然我们现在已经能稳定地复现这一内核 bug 了,这个复现方法也被我放到了 RingBufferDetonator 仓库里。并且证明了其不止在 Linux 4.6 上有,在更新版本的 Linux 上也有,乃至最后确认了到最新版本的 Linux 仍未修复这个 bug。
而bug 的具体原因与修复方案在我们明白如何稳定复现这个 bug 的时候也呼之欲出了:显然 rb_per_cpu_empty 在 head_page == commit_page 时错误地判断了当前 cpu_buffer 是否为空的状态,原因是 head_page 莫名其妙地使用可能为垃圾值的 read 与 page->commit 进行比较,而经过观察当 head_page == commit_page 时只需判断 page->commit 是否为 0 即可。这也是最后被合进 Linux 主线的修复方案。
关于恢复用户的系统的方法,在我调试这个bug 的时候发现只需要执行 truncate 操作截断掉当前 tracing 实例的 trace 文件即可,这个信息迅速同步给了用户。后来我们采取了绕行的方式来规避了这个 bug,并为用户更新了相应的补丁包。
后记
尽管最后呈现出来有效修复仅有一行,但为了找出这一行着实花了很长的时间。而发掘这些“土法”之前,面对完全不知从何下手的问题现场是很让人痛苦的,可能一直支撑着我发掘排查方法并走完排查流程的,是“这就是一个新的内核 bug”的信念吧。
第一次写这么长的文章去记录这么一段经历,编写的过程也很让我纠结。写得过于简略的话,大多数人可能并不能跟上行文思路;写得过于详细的话,又会让文章显得啰嗦,阅读体验极差。因此花了比较长的时间进行编辑,删了又写。
最后我认为作为一个程序员有机会完成这些事情,并获得技术上的提升,和一个允许成员花时间攻克难题,具有良好技术氛围的团队脱离不了关系。在此我邀请对技术有追求,喜欢刨根问底和热爱挑战的同学加入我们的团队。我们的团队在开发一款下一代的主机安全产品,主机安全能力的提升离不开对操作系统和系统应用原理的深入了解,亦即离不开一个专业的系统编程团队。
若您有系统编程或内核编程相关(Linux、Windows 等)的经验,或者想在接下来的职业生涯里有相关经历,且有意加入我们的团队,请发邮件到 lhr242257@alibaba-inc.com,我会协助进行内推,校招和社招均可。
另外感谢Librazy 等人对本文的审稿与纠错工作。