概述
Java 作为业务建设的主流语言,广泛应用在互联网、金融等企业中,Java 社区和开发者们提供的大量开源程序也帮助提高了开发效率,所以在业务工程中经常可以看到开源程序。但近些年,开源程序陆续爆出安全漏洞,轻则影响用户体验,重则业务应用沦陷。大量的业务应用以及每天数千次的迭代,使得自动检测和治理第三方开源程序成为企业安全建设的必要一环。如何来建设这一环呢?SCA(软件成分分析),本文将介绍 58 安全平台部在 SCA 建设中检测 Java 依赖安全风险的实践,意在抛砖引玉。
需求
SCA 的用户是业务部门的研发/安全 BP 和安全部门的运营人员,业务部门关注结果、解决方案和用户体验,安全部门关注能力、流程、运营和自动化。具体如下:
| 需求来源 | 需求内容 |
|---|---|
| 业务部门 | 工程里引用的依赖存在哪些漏洞 |
| 哪些依赖我需要修复 | |
| 修复方案是什么 | |
| 安全部门 | 增量和存量工程有哪些漏洞 |
| 部分漏洞受版本和利用条件影响(如 Fastjson),SAST 无法确定可利用性,需要 SCA 辅助判断 | |
| 某个漏洞在公司内部有多少业务应用受影响 | |
| 数据可运营 | |
| 检测、治理流程自动化 |
对安全部门的第二个需求补充说明,SAST 只能通过代码层面判断是否存在漏洞,常规的 SQL 注入、XXE 等是可以直接检测的,而 Fastjson、XStream 反序列化这类组件漏洞跟版本强相关,而且可能需要利用条件,SAST 只能看到调用链,漏洞是否存在还需要判断该组件的版本是否安全,组件版本不安全的情况下利用条件是否完备,这些信息是无法得知的。
SCA 为什么可以解决这个问题呢?以 XStream CVE-2021-29505 举例看一下判断过程:
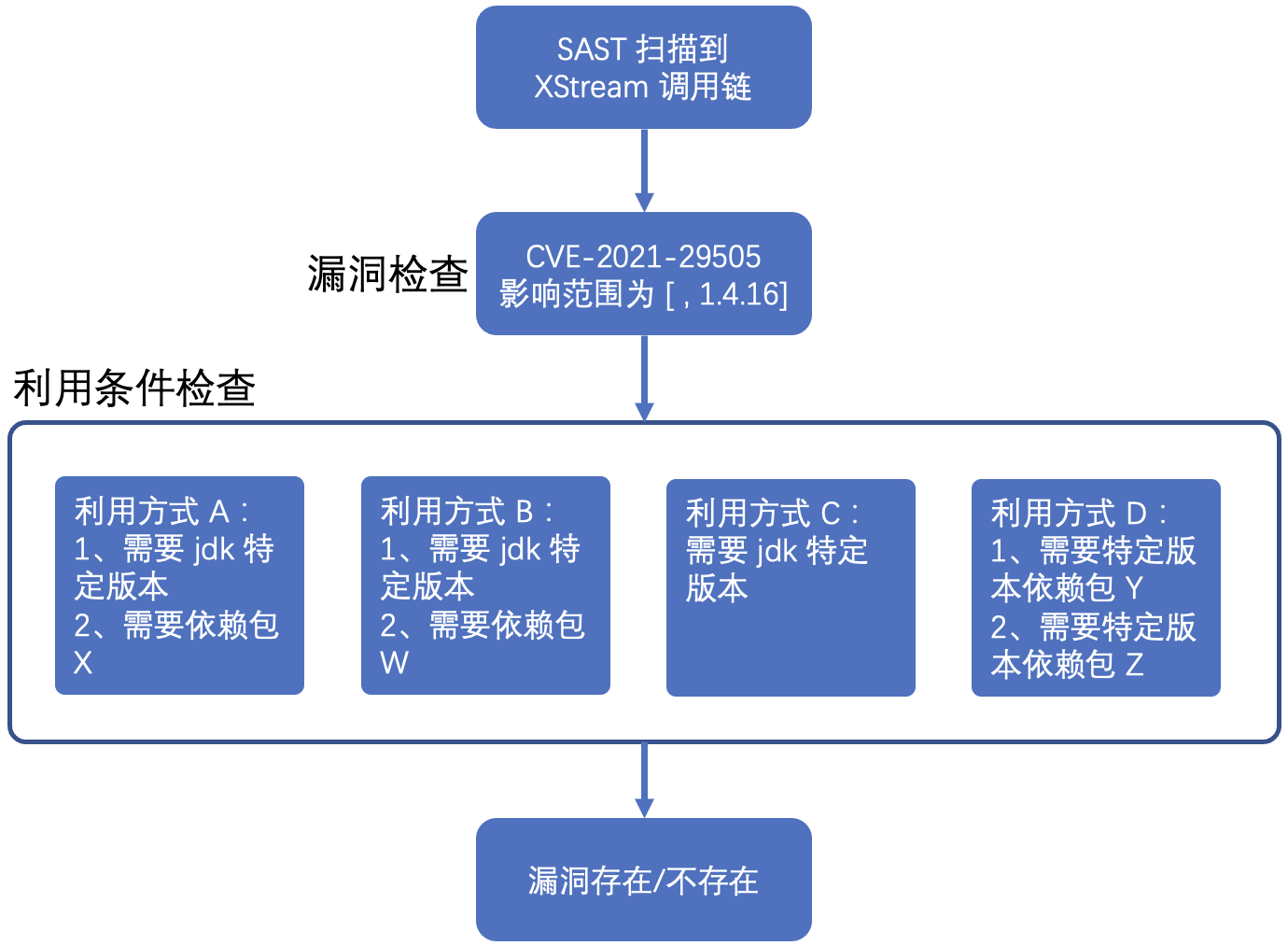
首先已知 CVE-2021-29505 的影响范围为 [ , 1.4.16],再根据已知的 payload(如 ysoserial) 可以得到多种利用方式的利用条件,这类条件一般是 jdk 版本、其他 jar 包。首先判断工程的 xstream 版本是否命中了该漏洞,再判断是否满足至少一种利用方式的全部条件。该漏洞其中一种利用方式有两个利用条件,一是 jdk 需支持 jndi 注入,也即是 jdk 版本需要在 [11 ,11.0.1)、[1.8, 1.8.0.191)、[1.7, 1.7.0.201)、[1.6, 1.6.0.211) 范围内,二是需要引入版本在 [1.7.0,2.3.11] 范围内的 org.codehaus.groovy:groovy 包。SAST 要确定该工程是否有 CVE-2021-29505 漏洞就成了 XStream 版本匹配和利用条件版本匹配,也正是 SCA 的核心功能之一,故 SCA 维护一个组件漏洞库和漏洞利用条件规则库,SAST 扫到依赖漏洞时,带着工程的信息到 SCA 确认,SCA 返回给 SAST 该漏洞是否存在,若存在利用条件是什么。
设计
SCA 属于基础安全能力,又有检测增量工程的需求,故需要将 SCA 嵌入到 SDL 流程中。在设计时,首先根据需求找到 SCA 在 SDL 中的定位,根据上下游的控制流和数据流来考虑 SCA 的内部功能和流程,以及在提供能力时所需要的其他能力和基础设施。
在 SDL 中的定位
根据安全部门的前两个需求可知,SCA 在构建阶段和运行阶段释放能力。在构建阶段,SCA 检测发布上线工程的依赖的漏洞,实现增量检测需求,同时辅助 SAST 判断部分漏洞的利用条件;在运行阶段,SCA 检测在线上运行的依赖的漏洞,实现存量检测需求,这里需要资产库提供正在服务器上运行的 jar 包数据。SCA 嵌入 SDL 流程后如图:
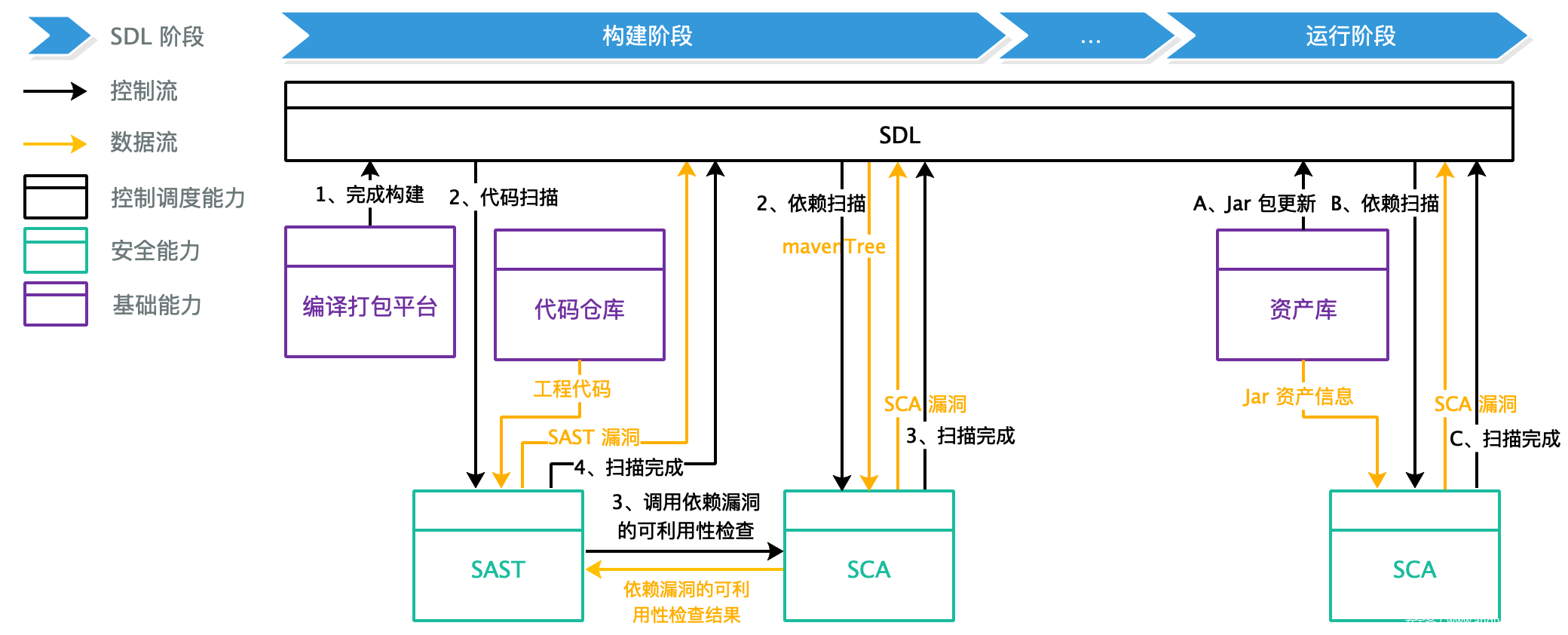
在 SDL 流程中,通过消息来调度各安全能力,上图以数字编号描述了构建阶段的增量扫描流程和包含了 SCA 辅助 SAST 判断依赖漏洞可利用性的 SAST 扫描流程,以字母编号描述了运行阶段的存量扫描流程。构建阶段,SCA 扫描由工程构建完成消息触发,数据流 mavenTree 的输入由 SCA 从 SDL 获取,完成扫描后返回漏洞信息给 SDL,SCA 的可利用性检查能力通过和 SAST 之间自建的消息队列异步提供给 SAST。运行阶段,SCA 扫描由资产库更新的消息触发,SCA 从资产库查询 Jar 包的 maven 坐标检测漏洞,检测之后输出给 SDL。
主要功能
根据 SDL 流程中的数据流和需求,SCA 的主要功能为漏洞检测和漏洞影响范围查询。
漏洞检测功能分为检测 jar 包存在的漏洞和检测漏洞可利用性两部分,前者的输入为 maven 坐标,输出为漏洞条目,后者的输入为漏洞条目和工程信息(mavenTree,jdk),输出为漏洞是否存在,如果利用条件完整还会输出条件信息。
要检测 jar 包存在的漏洞,首先要有准确且足够全的漏洞库,最好能够契合 maven 坐标。NVD 漏洞最全,但以 cpe 格式标识漏洞的影响软件,使得建立 cpe 和 maven 坐标的对应关系比较麻烦,基于 NVD 漏洞库 star 超过三千的开源 SCA 工具 DependencyCheck(https://github.com/jeremylong/DependencyCheck) 通过计算相似度来关联依赖和 cpe,不可避免的会存在误报和漏报。Snyk 公司维护并公开了一个三方包的漏洞库(https://snyk.io/vuln),如下:
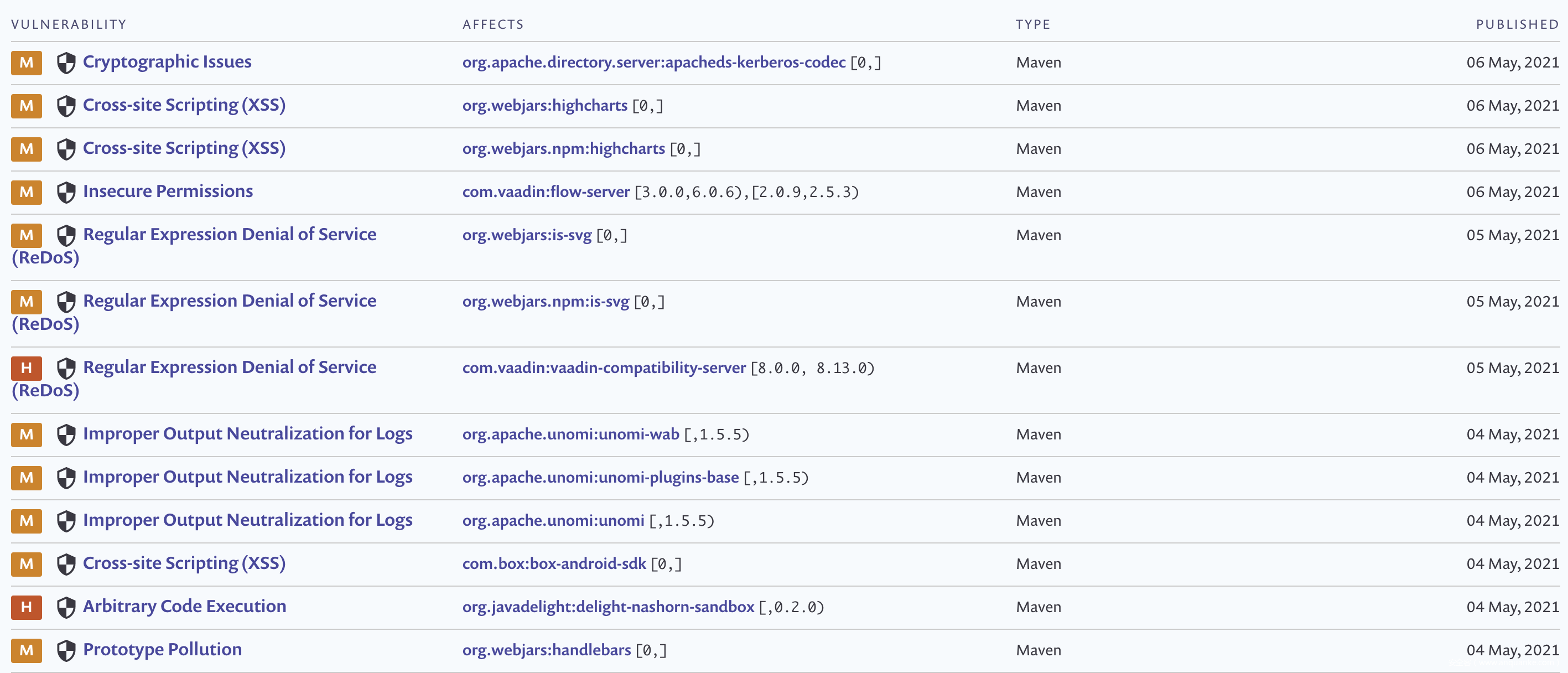
该漏洞库以 groupId:artifactId 作为软件名称,以版本区间的方式表示影响范围,测试了部分数据结果准确,近乎完美地解决了这个问题,SCA 在检测漏洞时,仅需要从 mavenTree 中取出 jar 包版本与漏洞库中的版本区间作比较即可,版本匹配已经有很成熟的方法,这里就不赘述,在本文最后小节会提到一些特殊情况的比较办法。
检查漏洞可利用性在需求部分进行了阐述,这里以 Fastjson 举例说明,Snyk 官方的库中只有两条记录:
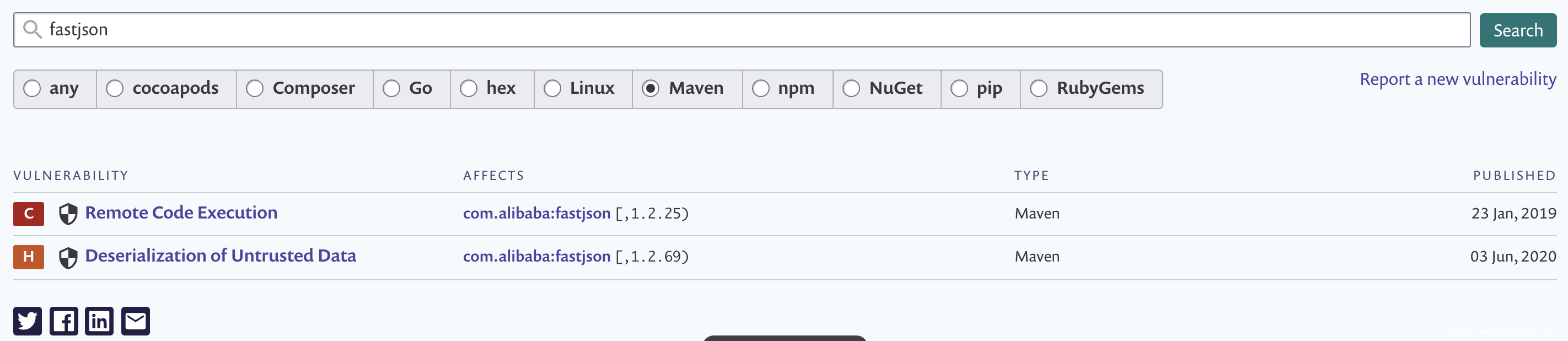
对于 SAST 来说并没有区别,都是在没有开启 safeMode 的条件下,从外部输入走到 JSON.parse/JSON.parseObject 方法,而实际漏洞利用的方法则有很多种,比如在开启 autoType 条件下的很多黑名单 payload,所以我们就需要在 snyk 库中补充,比如在 Fastjson 1.2.61 加入黑名单之一的 com.oracle.ojdbc:ojdbc8,可以在 snyk 中新增一条影响范围为 [ , 1.2.61) 的漏洞。收集了公开的利用方式之后(不一定全),最终 snyk 漏洞库中 Fastjson 的漏洞条目如下:
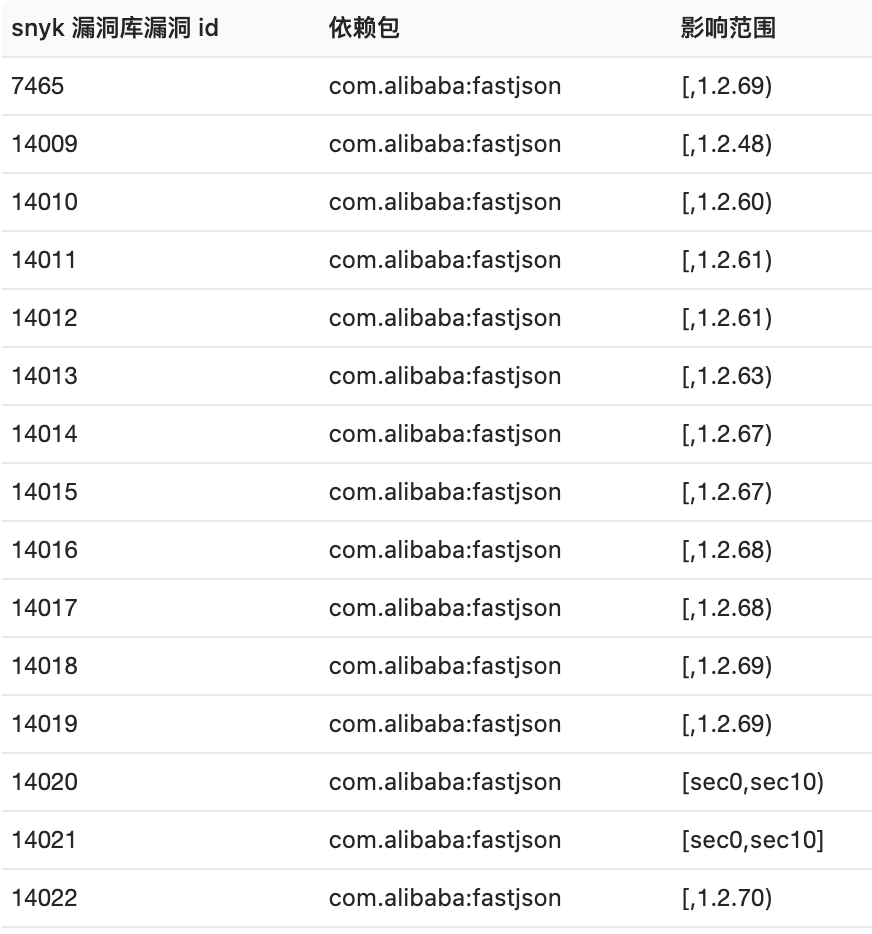
这些条目有些影响范围相同,但利用方式和条件不一样。然后,在利用条件规则库中添加这些漏洞条目的利用条件,下图展示了上图部分条目的利用条件:

精确识别所需要的漏洞和利用条件已经准备好了,判断的过程如下图:
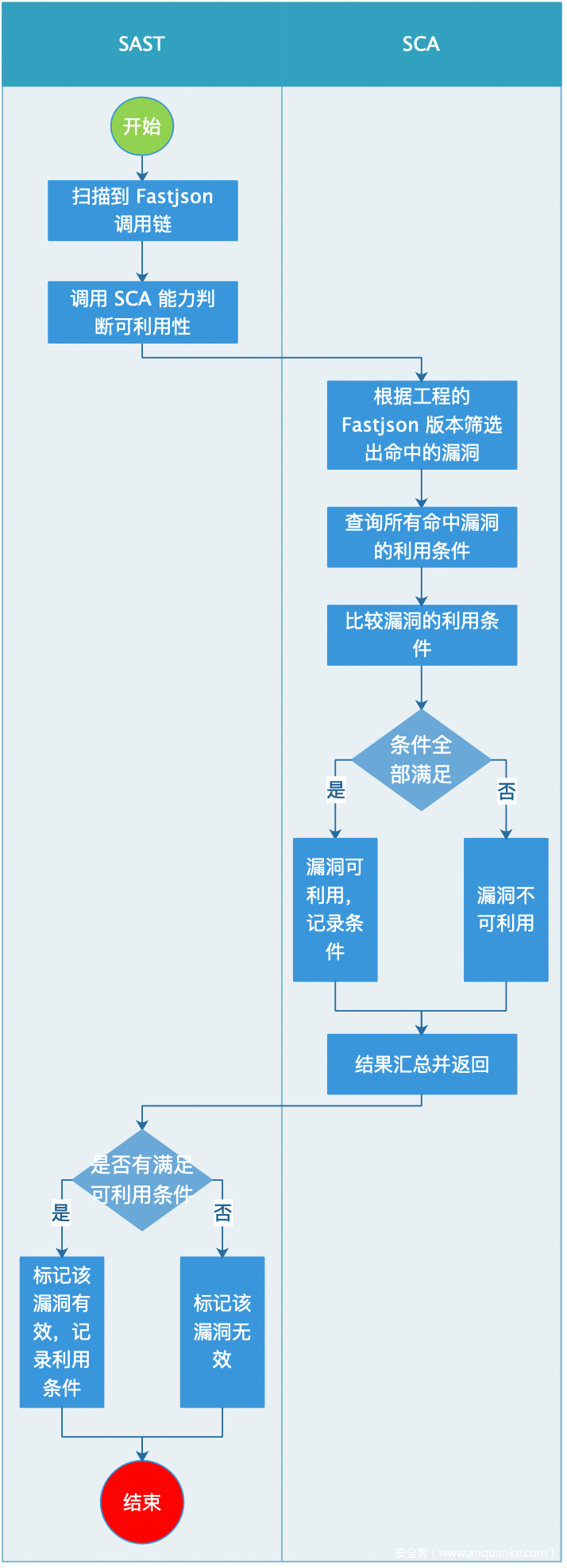
实际扫描某个工程的结果示例:

上图中工程 id 字段表示该工程,snyk 漏洞库漏洞 id 字段也即是 snyk 库中漏洞条目的编号,7465、14009 为 Fastjson 的漏洞,14658、14587 为 XStream 的漏洞,漏洞组件版本字段表示该工程引入对应漏洞的依赖版本,XStream 版本为 1.4.15,Fastjson 版本为 1.2.24。
这里主要说 Fastjson 的这两条结果,1.2.24 是很低的版本,会命中除 sec 版本之外所有的 Fastjson 漏洞。7465 这个漏洞表示 [ ,1.2.68] 版本的 autoType 绕过,利用方式是结合 MysqlJDBC 反序列化完成攻击,利用方式是 jdk8u20 的 gadget,利用条件是 jdk 在 [1.7,1.7.0_41],[1.8,1.8.0_20] 在范围内,并且工程引入了版本范围在 [5.1.11,5.1.49] 区间的 mysql:mysql-connector-java 包,该工程的编译时 jdk 版本为 1.8.0_20 且引入了版本为 5.1.38 的 mysql:mysql-connector-java 包,满足利用条件。14009 这个漏洞表示 [ ,1.2.47] 版本的 autoType 绕过,利用条件是启动应用的 jdk 支持 jndi 注入,也即是 jdk 版本在 [11 ,11.0.1)、[1.8, 1.8.0.191)、[1.7, 1.7.0.201)、[1.6, 1.6.0.211) 范围内。其他 Fastjson 漏洞的利用条件不完全具备,故可以利用这两条漏洞的 payload 攻击该工程的业务。
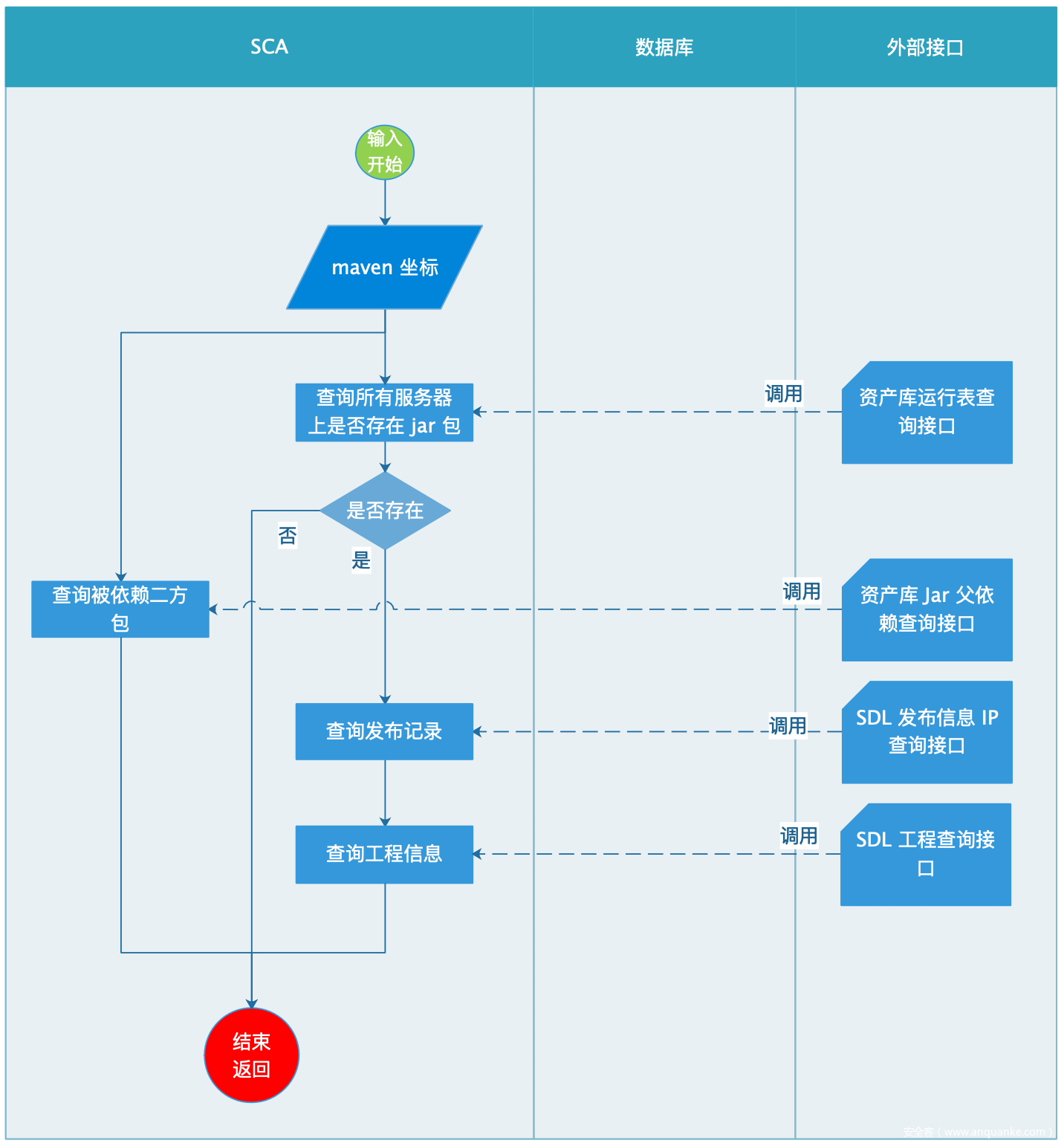
依赖包在爆出新漏洞时往往需要知道该漏洞在企业内部的影响范围,影响范围由在服务器磁盘上的 jar 包和依赖了该 jar 包的二方包组成。前者体现了当前实际的影响范围,后者体现了由二方包引入该漏洞可能的影响范围。查询二方包的目的是这部分包实现了公司的业务基础功能,在开发中难以替代,提醒二方包开发者更新依赖版本,可以降低引入该漏洞的概率。
从资产库可查询当前所有服务器上的 jar 包,从工程仲裁前的 mavenTree 中可获得依赖了该 jar 包的二方包,为了给业务线更好的体验,还要追溯到 git 工程。
具体流程如下:
运营
需要运营的数据
SCA 依赖 Snyk 的漏洞数据和漏洞利用条件数据,SCA 自身还会产生工程的漏洞数据,这三部分数据都需要运营。
Snyk 提供了三方包的公开漏洞信息,未公开的漏洞信息需要人工补充,比如 Fastjson,仅有 1 个 CVE,在 Snyk 漏洞库中也仅有两条数据,实际公网可以找到的 Fastjson 不同利用条件的 payload 多达数十种。漏洞是突发性的,可以将漏洞公开后到支持版本检测的时间窗口作为运行指标,此外,二方包自身的漏洞也需要挖掘然后入库,可以将二方包的覆盖率作为运营指标。
部分漏洞曝光时没有详情,随着补丁或分析文章的出现,漏洞的触发过程和利用条件也清晰了,需要补充到漏洞利用条件库中,这类数据也无法定量,难以归纳运营指标。
SCA 扫出来的漏洞,不是全都要修,需要修的漏洞也分轻重缓急。根据漏洞的利用条件是否具备、是否有 poc 两方面确定是否必修,根据依赖使用频次、风险等级两方面将漏洞分阶段(长短期)推修,漏洞推修的覆盖率和必须漏洞的修复率作为运营指标。
新漏洞的运营流程
部分依赖爆发新漏洞(例如 XStream CVE-2021-29505)后需要立即具备检测能力,过程如下:
1、验证漏洞;测试漏洞 poc,输出漏洞的影响范围和漏洞利用条件。
2、查询影响范围;利用范围查询接口即可知道影响范围。
3、增加 SCA 规则;规则分为 snyk 漏洞信息和利用条件两部分,前者的关键内容是 maven 坐标,其中版本是影响范围,用于识别工程引入的依赖是否在风险版本区间,后者的关键内容是其他依赖的 maven 坐标或者 jdk 版本,用于辅助 SAST 对该漏洞的可利用性检查。在上一步中已经全部得知,录入之后测试。
4、编写 SAST 插件;编写 SAST 插件和 benchmark 并测试之后,更新到线上环境,至此就具备了对该漏洞的检测能力。补充一点,在 SCA 运营流程中编写 SAST 的插件,看起来是侵入了 SAST 的业务领域,但漏洞本身是由依赖引起的,SCA 有辅助 SAST 判断漏洞可利用性的职责,SAST 的扫描插件放在 SCA 也是合理的。
效果
Fastjson 检测
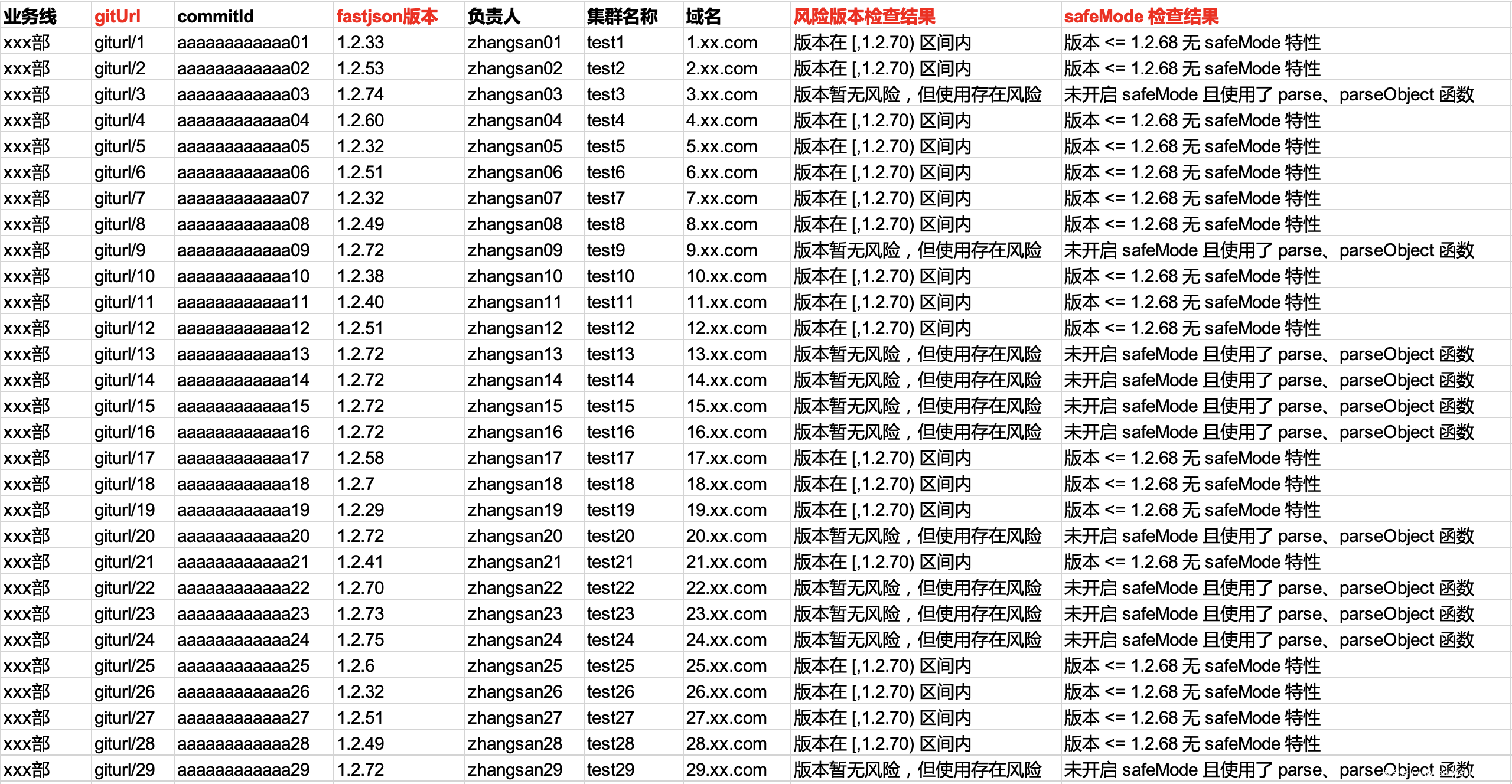
58 集团在去年制定了 Fastjson 治理方案,要求升级版本到 1.2.70 及以上并开启 safeMode,在 SCA 上线之前各业务线的整改进度是人工统计,低效且容易出现错误,在 SCA 的漏洞检测功能上线后,可自动化周期检测整改情况并输出数据。因为 Fastjson 还可以通过启动参数和配置文件的方式开启 safeMode,所以 SCA 在规则检测的基础上额外增加了逻辑。报告部分数据脱敏后如下:
XStream CVE-2021-29505 应急
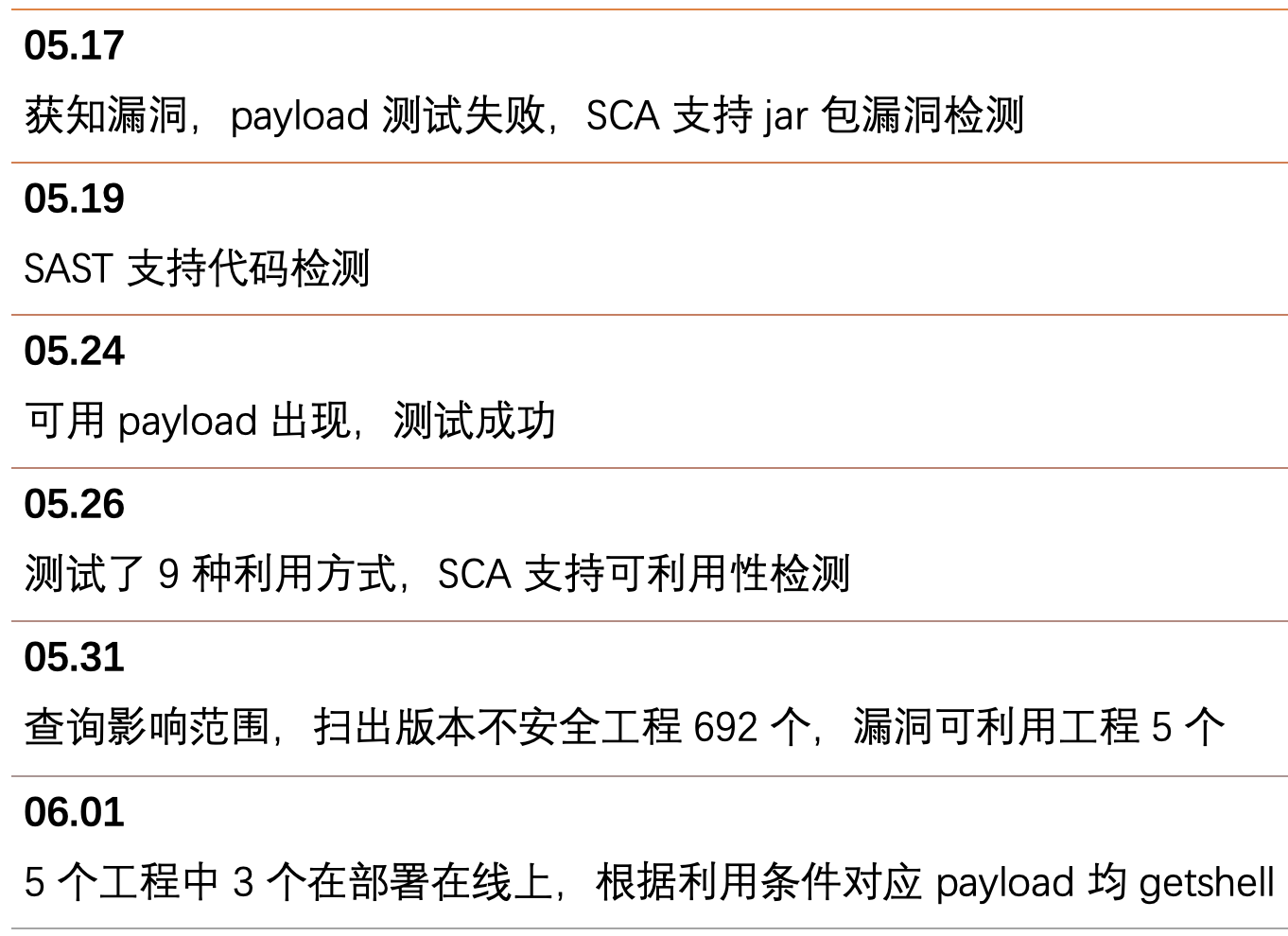
在该漏洞公开之后,立即按照新漏洞的运营流程开始应对,由于当前 SCA 和资产库还没有对接,所以运营流程的第二步(查询影响范围)无法进行,但 SCA 每周会对公司全量工程进行扫描,故从这部分数据里查询了影响范围作为替代,完成该漏洞应急的时间线如下:
一些特殊情况
特定影响范围
在翻阅 snyk 库的 maven 类型数据中,发现大量奇怪的版本范围,比如 [,1.1.1.Android]、[,1.2.68sec9],研究了 [,1.1.1.Android] 和 [,1.2.68sec9] 对应的漏洞之后发现,[,1.1.1.Android] 对应的漏洞仅影响 Android 版本,[,1.2.68sec9] 所对应的漏洞还会影响 sec 版本的 [sec0, sec9]。
分析之后,将 1.2.68 命名为主版本,sec9/Android 命名为副版本,可将版本比较分为 4 种类型:
| 比较主体\是否排除其他漏洞 | 不排除其他漏洞 | 排除其他副版本不同的漏洞 |
|---|---|---|
| 主版本 | A | B |
| 副版本 | C | D |
A、以主版本为主,先比较主版本范围,再比较副版本范围,比较时不需要排除其他副版本不同的漏洞
B、以主版本为主,先比较主版本范围,再比较副版本范围,比较时需要排除其他副版本不同的漏洞
C、以副版本为主,仅比较副版本范围,比较时不需要排除其他副版本不同的漏洞
D、以副版本为主,仅比较副版本范围,比较时需要排除其他副版本不同的漏洞
根据上述模型,对 Snyk 漏洞库增加版本关键字和比较类型字段,关键字默认为空字符串,属于 A 类型。比如 XStream 反序列化漏洞 CVE-2021-29505,影响范围为 [,1.2.17)。某浏览器插件漏洞仅影响 Android 版的范围 [,1.1.1.Android],关键字为 Android,该漏洞属于 B 类型。Fastjson 漏洞绕过 autoType 漏洞的影响范围为 [,1.2.68] 和 [,1.2.68sec9],前者关键字为空字符串,属于 A 类型,后者关键字为 sec,属于 D 类型。在版本匹配的时候,先检查工程引用的依赖版本中是否命中了该依赖所有漏洞的关键字,再根据类型筛选出需要检查的漏洞,然后进行版本范围比较。
jar 包复制其他 jar 包源码
在运营过程中发现某个工程调用了 parse() 函数,mavenTree 中却没有 Fastjson,审计代码发现某个三方包复制了 Fastjson 的源码,命名空间仍然是 com.alibaba.fastjson。此种情况如果开发者再通过 pom 引入 fastjson,业务代码在调用 fastjson 的方法时,可能还会调用复制代码部分的方法,在检测时产生误报和漏报。这种情况,误报无法解决,只能识别出复制的 fastjson 版本,手动添加一条该 jar 的漏洞信息,解决版本匹配的漏报,但辅助 SAST 检测利用条件仍然会漏报。