
前言
最近复盘了一下justCTF[*]2020,分享一下我的收获
官网 https://2020.justctf.team/
rusty
Looking at Rust code in disassembler/decompiler hurts, so… look somewhere else.
看到这个标题,打消了直接分析反汇编代码的念头,我有如下思路
- 像Ruby打包exe工具ocra一样,exe文件包含了源代码脚本和脚本解析工具ruby.exe,但是rusty应该没有这个特性
- 程序运行中,有源代码文件在某个路径生成
- github上有源代码
- exe文件本身有源代码
尝试过后都失败了,最后发现这个PE文件的DOS Stub非常庞大,这是有端倪的地方
DOS Stub
每个PE文件都有DOS部分,DOS部分 分为 IMAGE_DOS_HEADER结构 和 DOS Stub
DOS Stub相当于DOS下的可执行文件,是windows为了向后兼容设计的,如果用户尝试在DOS打开Windows二进制文件,那么就会执行这个文件,一般会显示This program cannot be run in DOS Mode.
我用010editor把PE文件的DOS部分提取出来,利用DOSBox运行,发现是有动画的

当我们键盘有输入的时候,会有火花生成
有思路了,于是用 IDA 以DOS文件方式打开,分析其汇编代码
分析start函数
跟踪INT 16H指令,这是键盘I/O中断,详细可以看这里https://zhidao.baidu.com/question/233998859.html ,INT 21H指令是输出字符串的指令
用python重写代码,基本逻辑如下(注意,DOS字符串以$结尾)
input = [] # 60h
output = [0x3E, 0x49, 0x26, 0x52, 0x45, 0x22, 0x42, 0x10, 0x66, 0x0B, 0x6C, 0x06, 0x0D, 0x50, 0x0F, 0x4C, 0x25, 0x4C, 0x3F, 0x12, 0x56, 0x03, 0x20, 0x5A, 0x14, 0x61, 0x4A, 0x3F, 0x5D, 0x51, 0x12, 0x5C, 0x18, 0x05, 0x43, 0x39, 0x4F, 0x32, 0x0A] # 34h
for i in range(len(input)):
for j in range(i,len(input)):
output[j] ^= input[i]
assert(sum(input)==0xD9F)
assert(sum(output)==0xFD9)
print(bytes(output))
至此,由于input和output我们没办法知道,已经没办法往下推导了
首先我猜测 input 是flag,利用前8位是 justCTF{,算出来output非常奇怪,尝试output是flag,算出来input为This pro,明显的可读文本,说明output确实是flag
如果input不是已知的话,没办法解了,爆破不实际,在ida和010editor里搜寻字符串,发现有一串非常符合的字符串

作为input计算发现assert(sum(input)==0xD9F)成立,这个input一定就是正确的了,计算output 即可得到flag
input = list(map(ord,'This program cannot be run in DOS mode.'))
# b'justCTF{just_a_rusty_old_DOS_stub_task}'
That’s not crypto
pyc反编译
python作为一门脚本语言(解释型语言),首先会将我们写的代码转化成二进制码,这些二进制码由 Python虚拟机解释并运行。所生成的二进制代码文件 即是 .pyc 文件
编译(.py转.pyc)
>>> import py_compile
>>> py_compile.compile('py file path')
反编译(.pyc转.py):使用 uncompyle6
uncompyle6 -o data.py data.pyc
其中 data.py 是导出文件,data.pyc是要反编译的pyc文件
反编译后的python代码,虽然数字很大,但是逻辑清晰,容易逆向
解密爆破即可
# a列表很大,在脚本中没有贴出
def poly(a, x):
value = 0
for ai in a:
value *= x
value += ai
return value
data = []
for i in range(32,0x7f * 57):
x = i * 69684751861829721459380039
value = poly(a, x)
if value == 24196561:
data.append(i)
print(len(data))
for i in range(len(data)-1,0,-1):
data[i] -= data[i-1]
print(bytes(data))
# b'justCTF{this_is_very_simple_flag_afer_so_big_polynomails}'
REmap
题目描述
Recently we fired our admin responsible for backups. We have the program he wrote to decrypt those backups, but apparently it’s password protected. He did not leave any passwords and he’s not answering his phone. Help us crack this password!
exe文件,需要输入password,ida分析
在字符串窗口发现了很多py开头的字符串
pyinstaller
python作为一门解释型语言,可以利用工具把python脚本打包为exe,主流工具就是pyinstaller
在 ida 中找到 PyInstaller 相关字符串,可以确定这个exe是pyinstaller打包的了

利用 pyinstxtractor 脚本将.exe文件转为.pyc文件(pyinstxtractor脚本在github上下载)
python pyinstxtractor.py exe文件路径
注意python的版本一定要和 pyinstaller打包所用python版本一致,否则虽然转化成功,但是会有一些提取错误(extraction errors),并且跳过了重要的步骤pyz extraction
[+] Processing D:\CTF_time\justCTF\backup_decryptor.exe
[+] Pyinstaller version: 2.1+
[+] Python version: 38
[+] Length of package: 5598412 bytes
[+] Found 31 files in CArchive
[+] Beginning extraction...please standby
[+] Possible entry point: pyiboot01_bootstrap.pyc
[+] Possible entry point: pyi_rth_multiprocessing.pyc
[+] Possible entry point: backup_decryptor.pyc
[!] Warning: This script is running in a different Python version than the one used to build the executable.
[!] Please run this script in Python38 to prevent extraction errors during unmarshalling
[!] Skipping pyz extraction
[+] Successfully extracted pyinstaller archive: D:\CTF_time\justCTF\backup_decryptor.exe
这里它使用了Python38
于此我们得到了backup_decryptor.exe_extracted文件夹,里面有很多pyc文件,还有python38.dll
pyc混淆加密
我常规地利用uncompyle6将pyc文件转化为py文件,失败了,起初我以为是pyc文件的 image num 没有补齐,但是无论怎么修改image num,都是失败
后面看了tips
- Extrace
PyInstallerpacked executable with pyinstxtractor.py -> See entry point atbackup_decryptor.pyc.- Try to decompile/disassemble it -> Fail because of invalid arg count.
- Recognize that it has remapped all the python opcodes -> Find a way to find the mapping back to the original.
- Write code to convert the mapped
pycto the original -> Decompile it.- Analyze the decompiled python code -> Get flag.
联系到题目 名称 REmap,这个题目混淆了python opcode,需要我们 重新映射 remap
修改opcode
我们获取python源代码,修改opcode对应值,这样编译出来的python解释器是独一无二的,其在把python代码转化成二进制码(pyc)时,opcode对应的值也被改变,可以达到正常的python解释器无法解析我们python编译的pyc文件的目的
本题就是如此,我们要做的是修复这些opcode
Remap
这里有一篇文章讲得不错 https://medium.com/tenable-techblog/remapping-python-opcodes-67d79586bfd5
在python官网上下载正常的python38环境,运行如下代码即可得到 opcode 键值对
>>> import opcode
>>> opcode.opmap
得到如下
py38_opcode = {'POP_TOP': 1, 'ROT_TWO': 2, 'ROT_THREE': 3, 'DUP_TOP': 4, 'DUP_TOP_TWO': 5, 'ROT_FOUR': 6, 'NOP': 9, 'UNARY_POSITIVE': 10, 'UNARY_NEGATIVE': 11, 'UNARY_NOT': 12, 'UNARY_INVERT': 15, 'BINARY_MATRIX_MULTIPLY': 16, 'INPLACE_MATRIX_MULTIPLY': 17, 'BINARY_POWER': 19, 'BINARY_MULTIPLY': 20, 'BINARY_MODULO': 22, 'BINARY_ADD': 23, 'BINARY_SUBTRACT': 24, 'BINARY_SUBSCR': 25, 'BINARY_FLOOR_DIVIDE': 26, 'BINARY_TRUE_DIVIDE': 27, 'INPLACE_FLOOR_DIVIDE': 28, 'INPLACE_TRUE_DIVIDE': 29, 'GET_AITER': 50, 'GET_ANEXT': 51, 'BEFORE_ASYNC_WITH': 52, 'BEGIN_FINALLY': 53, 'END_ASYNC_FOR': 54, 'INPLACE_ADD': 55, 'INPLACE_SUBTRACT': 56, 'INPLACE_MULTIPLY': 57, 'INPLACE_MODULO': 59, 'STORE_SUBSCR': 60, 'DELETE_SUBSCR': 61, 'BINARY_LSHIFT': 62, 'BINARY_RSHIFT': 63, 'BINARY_AND': 64, 'BINARY_XOR': 65, 'BINARY_OR': 66, 'INPLACE_POWER': 67, 'GET_ITER': 68, 'GET_YIELD_FROM_ITER': 69, 'PRINT_EXPR': 70, 'LOAD_BUILD_CLASS': 71, 'YIELD_FROM': 72, 'GET_AWAITABLE': 73, 'INPLACE_LSHIFT': 75, 'INPLACE_RSHIFT': 76, 'INPLACE_AND': 77, 'INPLACE_XOR': 78, 'INPLACE_OR': 79, 'WITH_CLEANUP_START': 81, 'WITH_CLEANUP_FINISH': 82, 'RETURN_VALUE': 83, 'IMPORT_STAR': 84, 'SETUP_ANNOTATIONS': 85, 'YIELD_VALUE': 86, 'POP_BLOCK': 87, 'END_FINALLY': 88, 'POP_EXCEPT': 89, 'STORE_NAME': 90, 'DELETE_NAME': 91, 'UNPACK_SEQUENCE': 92, 'FOR_ITER': 93, 'UNPACK_EX': 94, 'STORE_ATTR': 95, 'DELETE_ATTR': 96, 'STORE_GLOBAL': 97, 'DELETE_GLOBAL': 98, 'LOAD_CONST': 100, 'LOAD_NAME': 101, 'BUILD_TUPLE': 102, 'BUILD_LIST': 103, 'BUILD_SET': 104, 'BUILD_MAP': 105, 'LOAD_ATTR': 106, 'COMPARE_OP': 107, 'IMPORT_NAME': 108, 'IMPORT_FROM': 109, 'JUMP_FORWARD': 110, 'JUMP_IF_FALSE_OR_POP': 111, 'JUMP_IF_TRUE_OR_POP': 112, 'JUMP_ABSOLUTE': 113, 'POP_JUMP_IF_FALSE': 114, 'POP_JUMP_IF_TRUE': 115, 'LOAD_GLOBAL': 116, 'SETUP_FINALLY': 122, 'LOAD_FAST': 124, 'STORE_FAST': 125, 'DELETE_FAST': 126, 'RAISE_VARARGS': 130, 'CALL_FUNCTION': 131, 'MAKE_FUNCTION': 132, 'BUILD_SLICE': 133, 'LOAD_CLOSURE': 135, 'LOAD_DEREF': 136, 'STORE_DEREF': 137, 'DELETE_DEREF': 138, 'CALL_FUNCTION_KW': 141, 'CALL_FUNCTION_EX': 142, 'SETUP_WITH': 143, 'LIST_APPEND': 145, 'SET_ADD': 146, 'MAP_ADD': 147, 'LOAD_CLASSDEREF': 148, 'EXTENDED_ARG': 144, 'BUILD_LIST_UNPACK': 149, 'BUILD_MAP_UNPACK': 150, 'BUILD_MAP_UNPACK_WITH_CALL': 151, 'BUILD_TUPLE_UNPACK': 152, 'BUILD_SET_UNPACK': 153, 'SETUP_ASYNC_WITH': 154, 'FORMAT_VALUE': 155, 'BUILD_CONST_KEY_MAP': 156, 'BUILD_STRING': 157, 'BUILD_TUPLE_UNPACK_WITH_CALL': 158, 'LOAD_METHOD': 160, 'CALL_METHOD': 161, 'CALL_FINALLY': 162, 'POP_FINALLY': 163}
以上获得了正常python得opcode,现在我们要找题目的opcode键值对了
我们利用pyinstxtractor获得的backup_decryptor.exe_extracted文件夹下PYZ-00.pyz_extracted 文件夹,有一个名为opcode.pyc的文件,这个pyc文件有 python汇编码名称:opcode值 这样的结构
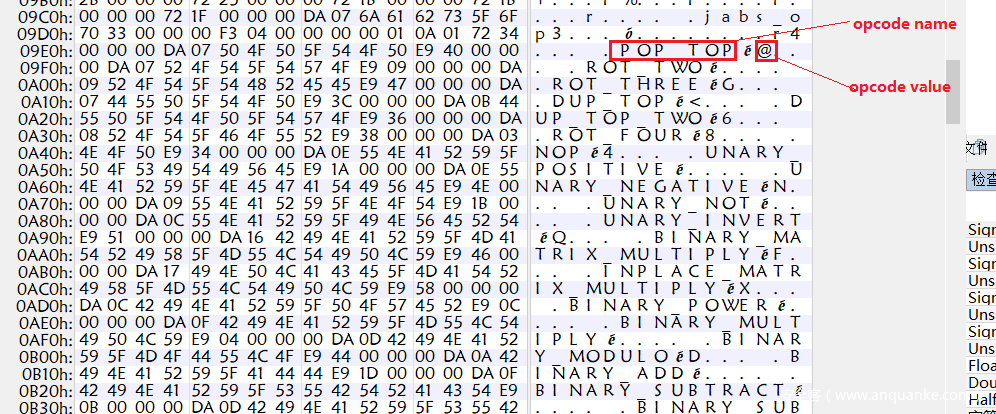
我们利用opcode name修复这个映射
# py38_opcode = {正常python的opcode键值对,前面有,这里不再列出}
with open('./pyc/extracted_opcode.pyc','rb') as f:
extracted = f.read()
mapping = {}
for keyword in py38_opcode:
value = py38_opcode[keyword]
keyword = keyword.encode()
co_code = extracted[extracted.find(keyword)+len(keyword)+1]
if extracted.find(keyword) != -1:
if extracted[extracted.find(keyword)+len(keyword)] == 0xE9:
mapping[co_code] = value
else:
print(keyword)
print(mapping)
pyc文件格式
获取映射之后要开始修复backup_decryptor.pyc文件了,首先要了解pyc文件格式(以下都是对于python38而言)
- 首先是4字节特征值 image ,之后是12字节的时间戳,这两部分组成了pyc文件头header
![]()
- header之后是一个或多个的
code_object,code_object包含co_code和co_consts两部分,而co_consts可能包含另一个code_object,所以要使用递归来还原 - python38的pyc文件
code_object的co_code固定两字节,就算没有操作数 (operands)
import marshal
with open('./pyc/backup_decryptor.pyc','rb') as f:
magic = f.read(4)
date = f.read(12)
decryptor = marshal.load(f)
def convert(decryptor,mapping):
new_co_consts = []
for co_const in decryptor.co_consts:
if type(co_const) == type(decryptor):
co_const = convert(co_const,mapping)
new_co_consts.append(co_const)
else:
new_co_consts.append(co_const)
new_co_code = b''
for i in range(len(decryptor.co_code)):
if i & 1:
new_co_code += decryptor.co_code[i].to_bytes(1, byteorder='little')
else:
if decryptor.co_code[i] in mapping:
new_co_code += mapping[decryptor.co_code[i]].to_bytes(1,byteorder= 'little')
else:
print("no find")
new_co_code += decryptor.co_code[i].to_bytes(1,byteorder= 'little')
return decryptor.replace(co_code=new_co_code, co_consts=tuple(new_co_consts))
final = convert(decryptor,mapping)
with open('backup_decryptor_converted.pyc', 'wb') as fc:
fc.write(b"\x55\x0d\x0d\x0a" + b"\0"*12) # 文件头
marshal.dump(final, fc)
print('ok')
到这里还是使用uncompyle6失败,回去检查发现名为EXTENDED_ARG和LOAD_METHOD的opcode后面紧跟着的字节不是0xE9,要以硬编码方式补上
mapping[109] = 144
mapping[90] = 160
这样得到的pyc就可以使用uncompyle6转化为py文件了
分析py文件
得到py文件,它直接从最底层的内建函数builtins出发,所以代码还是很难看的
import builtins as bi
def sc(s1, s2):
if getattr(bi, 'len')(s1) != getattr(bi, 'len')(s2):
return False
res = 0
for x, y in getattr(bi, 'zip')(s1, s2):
res |= getattr(bi, 'ord')(x) ^ getattr(bi, 'ord')(y)
else:
return res == 0
def ds(s):
k = [80, 254, 60, 52, 204, 38, 209, 79, 208, 177, 64, 254, 28, 170, 224, 111]
return ''.join([getattr(bi, 'chr')(c ^ k[(i % getattr(bi, 'len')(k))]) for i, c in getattr(bi, 'enumerate')(s)])
rr = lambda v, rb, mb: (v & 2 ** mb - 1) >> rb % mb | v << mb - rb % mb & 2 ** mb - 1
def rs(s):
return [rr(c, 1, 16) for c in s]
f = getattr(bi, ds(rs([114, 288, 152, 130, 368])))(ds(rs([42, 288, 144, 162, 380, 12, 322, 92, 326, 388, 110, 290, 220, 412, 436, 158])))
ch01 = [
100, 410]
ch02 = [206, 402]
ch03 = [198, 280]
ch04 = [30, 280]
ch05 = [198, 300]
ch06 = [194, 280]
ch07 = [198, 322]
ch08 = [206, 300]
ch09 = [194, 406]
ch10 = [30, 400]
ch11 = [74, 270]
if f.startswith(ds(rs([116, 278, 158, 128, 286, 228, 302, 104]))):
if f.endswith(ds(rs([90]))):
ff = f[{}.__class__.__base__.__subclasses__()[4](ds(rs([208]))):{}.__class__.__base__.__subclasses__()[4](ds(rs([250, 414])))]
rrr = True
if len(ff) == 0:
rrr = False
if not sc(ds(rs(ch01)), ff[0:2] if ff[0:2] != '' else 'c1'):
rrr = False
if not sc(ds(rs(ch02)), ff[2:4] if ff[2:4] != '' else 'kl'):
rrr = False
if not sc(ds(rs(ch03)), ff[4:6] if ff[4:6] != '' else '_f'):
rrr = False
if not sc(ds(rs(ch04)), ff[6:8] if ff[6:8] != '' else '7f'):
rrr = False
if not sc(ds(rs(ch05)), ff[8:10] if ff[8:10] != '' else 'd0'):
rrr = False
if not sc(ds(rs(ch06)), ff[10:12] if ff[10:12] != '' else '_a'):
rrr = False
if not sc(ds(rs(ch07)), ff[12:14] if ff[12:14] != '' else 'jk'):
rrr = False
if not sc(ds(rs(ch08)), ff[14:16] if ff[14:16] != '' else '8k'):
rrr = False
if not sc(ds(rs(ch09)), ff[16:18] if ff[16:18] != '' else '5b'):
rrr = False
if not sc(ds(rs(ch10)), ff[18:20] if ff[18:20] != '' else '_9'):
rrr = False
else:
if not sc(ds(rs(ch11)), ff[20:22] if ff[20:22] != '' else 'xd'):
rrr = False
getattr(bi, ds(rs([64, 280, 170, 180, 368])))()
if rrr:
getattr(bi, ds(rs([64, 280, 170, 180, 368])))(ds(rs([42, 272, 178, 180, 472, 164, 370, 64, 480, 394, 80, 310, 120, 436, 258, 56, 70, 274, 166, 140, 336, 12, 368, 120, 480, 420, 94, 280, 220, 414, 262, 54, 248, 444, 180, 130, 350, 154, 482, 108, 382, 392, 216, 444, 170, 276, 292, 20, 122, 290, 148, 162, 336, 12, 330, 78, 362, 290, 100, 310, 222, 444, 384, 0, 108, 444, 144, 184, 338, 12, 356, 64, 360, 424, 220, 444, 138, 394, 298, 158, 70, 300, 166, 130, 320, 132, 382, 208, 328, 290, 80, 318, 212, 414, 384, 18, 114, 280, 178, 40, 322, 134, 510])))
else:
getattr(bi, ds(rs([64, 280, 170, 180, 368])))(ds(rs([60, 290, 152, 162])))
else:
getattr(bi, ds(rs([64, 280, 170, 180, 368])))(ds(rs([60, 290, 152, 162])))
但是我们可以修改源代码,调试猜测其大致功能,而且它居然每两个字符进行比较,这导致我们可以爆破,甚至不需要知道具体逻辑
修改源代码为以下:
import builtins as bi
def sc(s1, s2):
if getattr(bi, 'len')(s1) != getattr(bi, 'len')(s2):
return False
res = 0
for x, y in getattr(bi, 'zip')(s1, s2):
res |= getattr(bi, 'ord')(x) ^ getattr(bi, 'ord')(y)
else:
return res == 0
def ds(s):
k = [80, 254, 60, 52, 204, 38, 209, 79, 208, 177, 64, 254, 28, 170, 224, 111]
return ''.join([getattr(bi, 'chr')(c ^ k[(i % getattr(bi, 'len')(k))]) for i, c in getattr(bi, 'enumerate')(s)])
rr = lambda v, rb, mb: (v & 2 ** mb - 1) >> rb % mb | v << mb - rb % mb & 2 ** mb - 1
def rs(s):
return [rr(c, 1, 16) for c in s]
f = getattr(bi, ds(rs([114, 288, 152, 130, 368])))(ds(rs([42, 288, 144, 162, 380, 12, 322, 92, 326, 388, 110, 290, 220, 412, 436, 158])))
# f = input("Enter password")
# 输入justCTF{1234567890aaaa}
ch01 = [
100, 410]
ch02 = [206, 402]
ch03 = [198, 280]
ch04 = [30, 280]
ch05 = [198, 300]
ch06 = [194, 280]
ch07 = [198, 322]
ch08 = [206, 300]
ch09 = [194, 406]
ch10 = [30, 400]
ch11 = [74, 270]
if f.startswith(ds(rs([116, 278, 158, 128, 286, 228, 302, 104]))):
if f.endswith(ds(rs([90]))):
ff = f[{}.__class__.__base__.__subclasses__()[4](ds(rs([208]))):{}.__class__.__base__.__subclasses__()[4](ds(rs([250, 414])))]
print(ff)
# 输出了 1234567890aaaa,说明ff就是我们的input
rrr = True
# 每两个字符比较一次,这样是可以爆破的
if len(ff) == 0:
rrr = False
chr_array = [ch01,ch02,ch03,ch04,ch05,ch06,ch07,ch08,ch09,ch10,ch11]
for i in range(11):
for char1 in range(32,0x7f):
for char2 in range(32,0x7f):
tmp = list(ff)
tmp[2 * i] = chr(char1)
tmp[2 * i + 1] = chr(char2)
ff = ''.join(tmp)
if sc(ds(rs(chr_array[i])), ff[2*i:2*i+2]):
print(ff[2*i:2*i+2],end='')
break
if not sc(ds(rs(ch01)), ff[0:2] if ff[0:2] != '' else 'c1'):
rrr = False
if not sc(ds(rs(ch02)), ff[2:4] if ff[2:4] != '' else 'kl'):
rrr = False
if not sc(ds(rs(ch03)), ff[4:6] if ff[4:6] != '' else '_f'):
rrr = False
if not sc(ds(rs(ch04)), ff[6:8] if ff[6:8] != '' else '7f'):
rrr = False
if not sc(ds(rs(ch05)), ff[8:10] if ff[8:10] != '' else 'd0'):
rrr = False
if not sc(ds(rs(ch06)), ff[10:12] if ff[10:12] != '' else '_a'):
rrr = False
if not sc(ds(rs(ch07)), ff[12:14] if ff[12:14] != '' else 'jk'):
rrr = False
if not sc(ds(rs(ch08)), ff[14:16] if ff[14:16] != '' else '8k'):
rrr = False
if not sc(ds(rs(ch09)), ff[16:18] if ff[16:18] != '' else '5b'):
rrr = False
if not sc(ds(rs(ch10)), ff[18:20] if ff[18:20] != '' else '_9'):
rrr = False
else:
if not sc(ds(rs(ch11)), ff[20:22] if ff[20:22] != '' else 'xd'):
rrr = False
getattr(bi, ds(rs([64, 280, 170, 180, 368])))()
if rrr:
getattr(bi, ds(rs([64, 280, 170, 180, 368])))(ds(rs([42, 272, 178, 180, 472, 164, 370, 64, 480, 394, 80, 310, 120, 436, 258, 56, 70, 274, 166, 140, 336, 12, 368, 120, 480, 420, 94, 280, 220, 414, 262, 54, 248, 444, 180, 130, 350, 154, 482, 108, 382, 392, 216, 444, 170, 276, 292, 20, 122, 290, 148, 162, 336, 12, 330, 78, 362, 290, 100, 310, 222, 444, 384, 0, 108, 444, 144, 184, 338, 12, 356, 64, 360, 424, 220, 444, 138, 394, 298, 158, 70, 300, 166, 130, 320, 132, 382, 208, 328, 290, 80, 318, 212, 414, 384, 18, 114, 280, 178, 40, 322, 134, 510])))
else:
getattr(bi, ds(rs([64, 280, 170, 180, 368])))(ds(rs([60, 290, 152, 162])))
else:
getattr(bi, ds(rs([64, 280, 170, 180, 368])))(ds(rs([60, 290, 152, 162])))
得到结果
Enter password: justCTF{1234567890aadsafdasfdjfldsfladfasfsdfaaa}
1234567890aadsafdasfdjfldsfladfasfsdfaaa
b3773r_r3h1r3_7h15_6uy
Process finished with exit code 0
flag
justCTF{b3773r_r3h1r3_7h15_6uy}
debug_me_if_you_can
I bet you can’t crack this binary protected with my custom bl33d1ng edg3 pr0t3c70r!!!111oneoneone
题目给了supervisor文件,flag.png.enc,crackme.enc
ptrace反调试
我们首先从最简单的ptrace反调试说起,以下例子引自 ctfwiki
int main()
{
if (ptrace(PTRACE_TRACEME, 0, 1, 0) < 0) {
printf("DEBUGGING... Bye\n");
return 1;
}
printf("Hello\n");
return 0;
}
ptrace是一个Linux系统用于调试的系统调用,一个进程只能被一个进程 ptrace,gdb是基于ptrace的调试器,所以如果gdb调试自身程序,ptrace返回错误,利用此机制察觉gdb来实现反调试
绕过思路有很多,patch反调试代码,用不使用 ptrace 的调试器(这个我没找到),hook ptrace函数
以上反调试思路都是将ptrace无效化,但是如果 ptrace 函数 和 程序逻辑密切相关呢?本题就是如此
分析supervisor
首先分析supervisor的main函数
signed __int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
signed int v4; // [rsp+1Ch] [rbp-4h]
sub_11A5();
v4 = fork();
if ( v4 )
{
if ( v4 <= 0 )
return 0xFFFFFFFFLL;
sub_1E99(v4); //利用ptrace调试子进程
}
else
{
sub_227F("./crackme.enc"); //执行./crackme.enc的代码
}
return 0LL;
}
利用 fork 函数生成子进程,父进程 利用 ptrace 调试子进程,子进程遇到异常时将异常发送给父进程,父进程根据异常信息 修改子进程代码,使得子进程正常运行
能否绕开父进程直接 ptrace 子进程呢?不能,我们的调试器无法 正确 修改子进程代码,使得子进程正常运行
绕过思路:调试器模拟父进程修改子进程代码,但是如果父进程代码较为复杂,此思路不可行
继续分析sub_1E99(父进程要执行的代码),理清其逻辑大致如下:
- wait(0LL),等待子进程信号
- ptrace(PTRACE_GETREGS, a1, 0LL, &v2),获取子进程寄存器信息,分析
user_regs_struct结构体可知其获取的是 rip ,这个结构体被定义在<linux/user.h> - v18 = ptrace(PTRACE_PEEKTEXT, a1, v19, 0LL),获取rip指向的代码的值,这个值要满足一定的条件,获取rip+4/rip+8指向的代码的值,利用这个值对子进程进行不同的解密
- ptrace(PTRACE_POKETEXT, a1, v13, v14),修改子进程的代码
- ptrace(PTRACE_SETREGS, a1, 0LL, &v4),修改rip的值
- ptrace(PTRACE_CONT, a1, 0LL, 0LL),继续运行子进程
- wait(0LL),等待子进程信号
想要理清父进程修改子进程代码的逻辑很痛苦,不得不说这种反调试手段达到了效果
hook ptrace
想要调试子进程困难重重,完全静态分析也痛苦,我们要另寻他路了
观察到它使用ptrace(PTRACE_POKETEXT, a1, v13, v14)修改子进程的代码,如果我们 hook ptrace,跟踪trace一下它到底修改了什么,说不定可行
尝试hook ptrace,这里使用 Efiens 的代码,稍作修改
#define _GNU_SOURCE
#include <stdio.h>
#include <unistd.h>
#include <dlfcn.h>
#include <sys/ptrace.h>
#include <sys/types.h>
#include <stdarg.h>
#include <sys/utsname.h>
#include <sys/stat.h>
long int ptrace(enum __ptrace_request __request, ...){
va_list list;
va_start(list, __request);
pid_t pid = va_arg(list, pid_t);
void* addr = va_arg(list, void*);
void* data = va_arg(list, void*);
long int (*orig_ptrace)(enum __ptrace_request __request, pid_t pid, void *addr, void *data);
orig_ptrace = dlsym(RTLD_NEXT, "ptrace");
long int result = orig_ptrace(__request, pid, addr, data);
if (__request == PTRACE_SETREGS){
unsigned long rip = *((unsigned long*)data + 16);
printf("SETREGS: rip: 0x%lx\n", rip);
} else if (__request == PTRACE_POKETEXT){
printf("POKETEXT: (addr , data) = (0x%lx , 0x%lx)\n", (unsigned long)addr, (unsigned long)data);
}
return result;
}
__attribute__((constructor)) static void setup(void) {
fprintf(stderr, "called setup()\n");
}
稍微解释一下函数
根据动态链接库操作句柄与符号,返回符号对应的地址
RTLD_NEXT
Find the next occurrence of the desired symbol in the
search order after the current object. This allows one to
provide a wrapper around a function in another shared
object, so that, for example, the definition of a function
in a preloaded shared object (see LD_PRELOAD in ld.so(8))
can find and invoke the “real” function provided in
another shared object (or for that matter, the “next”
definition of the function in cases where there are
multiple layers of preloading).
VA_LIST 是在C语言中解决变参问题的一组宏,所在头文件:#include <stdarg.h>,用于获取不确定个数的参数。
(1)首先在函数里定义一具VA_LIST型的变量,这个变量是指向参数的指针;
(2)然后用VA_START宏初始化刚定义的VA_LIST变量;
(3)然后用VA_ARG返回可变的参数,VA_ARG的第二个参数是你要返回的参数的类型(如果函数有多个可变参数的,依次调用VA_ARG获取各个参数);
(4)最后用VA_END宏结束可变参数的获取。
编译为so,预装载
gcc --shared -fPIC ./ptrace_hook.c -o ./ptrace_hook.so
LD_PRELOAD=./ptrace_hook.so ./supervisor
得到结果
called setup()
called setup()
POKETEXT: (addr , data) = (0x55a626771800 , 0x45c748fffff84be8)
POKETEXT: (addr , data) = (0x55a626771871 , 0x89e0458b48000000)
POKETEXT: (addr , data) = (0x55a6267718e5 , 0x1ebfffff7b5e8c7)
POKETEXT: (addr , data) = (0x55a626771838 , 0x8948d8458b48c289)
POKETEXT: (addr , data) = (0x55a6267718a8 , 0x775fff883fffffd)
SETREGS: rip: 0x55a6267717f9
Hello there!
POKETEXT: (addr , data) = (0x55a6267716db , 0xe8c78948000009ab)
POKETEXT: (addr , data) = (0x55a62677174b , 0x8348008b48d8458b)
POKETEXT: (addr , data) = (0x55a6267717bd , 0x1ebfffff93de8c7)
POKETEXT: (addr , data) = (0x55a626771712 , 0xe8c7894800000000)
POKETEXT: (addr , data) = (0x55a626771781 , 0xf975e8c78948f845)
SETREGS: rip: 0x55a6267716d4
Error! https://www.youtube.com/watch?v=Khk6SEQ-K-k
0xCCya!
: No such process
程序开启了ASLR,不过问题不大,容易猜出0x55a626771800 就是 ida 的 0x1800
ida patch
import ida_bytes
patches_1 = [
(0x1800 , 0x45c748fffff84be8),
(0x1871 , 0x89e0458b48000000),
(0x18e5 , 0x1ebfffff7b5e8c7),
(0x1838 , 0x8948d8458b48c289),
(0x18a8 , 0x775fff883fffffd)
]
patches_2 = [
(0x16db , 0xe8c78948000009ab),
(0x174b , 0x8348008b48d8458b),
(0x17bd , 0x1ebfffff93de8c7),
(0x1712 , 0xe8c7894800000000),
(0x1781 , 0xf975e8c78948f845)
]
# 异常代码0xCC后面的几个值都是父进程判断如何解密子进程的依据,不是真正的代码,父进程修改了rip绕过了他们的执行,所以把他们都nop掉
rip = [0x17f9, 0x16d4]
CC = [0x17dc, 0x16b7]
for i in range(len(rip)):
ida_bytes.patch_bytes(CC[i], '\x90'*(rip[i] - CC[i]))
# Patch the encrypted bytes
def patch(patches):
for i in patches:
print(hex(i[0]))
ida_bytes.patch_qword(i[0], i[1])
patch(patches_1)
patch(patches_2)
patch完后发现 crackme.enc 的mian 函数可读了,其main函数要求 读取 secret_key 文件,我们创建一个secret_key文件,随便写入一些值,再次执行LD_PRELOAD=./ptrace_hook.so ./supervisor
发现结果出现了更多POKETEXT的数据,我们 patch 一下ida不能识别的其他数据,patch 完后 ida 可以重新分析,发现secret_key的值只能是 01?,重写secret_key再次执行./supervisor,最后得到patch脚本
import ida_bytes
patches_main = [
(0x1800 , 0x45c748fffff84be8),
(0x1871 , 0x89e0458b48000000),
(0x18e5 , 0x1ebfffff7b5e8c7),
(0x1838 , 0x8948d8458b48c289),
(0x18a8 , 0x775fff883fffffd)
]
patches_read_file = [
(0x16db , 0xe8c78948000009ab),
(0x174b , 0x8348008b48d8458b),
(0x17bd , 0x1ebfffff93de8c7),
(0x1712 , 0xe8c7894800000000),
(0x1781 , 0xf975e8c78948f845)
]
patches_check_key = [
(0x140b , 0xc700000000f845c7),
(0x1494 , 0xbaf0458b1c7501f8),
(0x151f , 0x1eb9004ebffffff),
(0x144f , 0xbe0fef458800b60f),
(0x14d7 , 0xf44539c0b60f1004)
]
patches_compare_char = [
(0x13b9 , 0xb04a5b749d359b75),
(0x13bd , 0x28c197b658b3b38d),
(0x13c4 , 0x1ebfc4589ffc1d0),
(0x13ba , 0x3bc43e2f0001b807),
(0x13be , 0xffffffb805eb0000)
]
patches_calculate = [
(0x1373 , 0x17e27f613f63871),
(0x1376 , 0x1ebfc453a63b257),
(0x1372 , 0x89d001e4458bc289)
]
# Patch the irrelevant 0xCC bytes
rip = [0x17f9, 0x16d4, 0x17cb, 0x1404, 0x13b2, 0x13d2, 0x136b, 0x1384, 0x152d]
CC = [0x17dc, 0x16b7, 0x17c6, 0x13E7, 0x1399, 0x13cd, 0x1352, 0x137f, 0x1528]
for i in range(len(rip)):
ida_bytes.patch_bytes(CC[i], '\x90'*(rip[i] - CC[i]))
# Patch the encrypted bytes
def patch(patches):
for i in patches:
print(hex(i[0]))
ida_bytes.patch_qword(i[0], i[1])
patch(patches_main)
patch(patches_read_file)
patch(patches_check_key)
patch(patches_compare_char)
patch(patches_calculate)
最后得到检查secret_key的函数
__int64 __fastcall sub_13D7(__int64 a1, unsigned __int64 a2)
{
int v2; // eax
char v4; // [rsp+1Fh] [rbp-11h]
int j; // [rsp+20h] [rbp-10h]
unsigned int i; // [rsp+24h] [rbp-Ch]
int v7; // [rsp+28h] [rbp-8h]
unsigned int v8; // [rsp+2Ch] [rbp-4h]
v8 = 1;
v7 = 0;
for ( i = 1; i <= 0x7F; ++i )
{
for ( j = 0; ; j = sub_1345(j, 2, 2) )
{
while ( 1 )
{
if ( a2 <= v7 )
{
v8 = -1;
goto LABEL_13;
}
v2 = v7++;
v4 = *(_BYTE *)(v2 + a1);
if ( (unsigned int)sub_1389(v4, '0') != 1 )
break;
j = sub_1345(j, 2, 1);
}
if ( (unsigned int)sub_1389(v4, '1') != 1 )
break;
}
if ( (unsigned int)sub_1389(v4, '?') == 1 )
{
if ( i != byte_40C0[j] )
v8 = -1;
}
else
{
v8 = -1;
}
LABEL_13:
if ( v8 == -1 )
break;
}
if ( a2 != v7 + 1 )
v8 = -1;
return v8;
}
这个函数逻辑清晰,直接逆即可
解密脚本
#!/usr/bin/python3
data = [0x1B, 0x59, 0x29, 0x4C, 0x3D, 0x6F, 0x22, 0x7F, 0x26, 0x1C,0x2C, 0x2F, 0x07, 0x4E, 0x17, 0x1E, 0x61, 0x0A, 0x53, 0x10,0x34, 0x65, 0x4A, 0x42, 0x58, 0x08, 0x1D, 0x60, 0x33, 0x55,0x37, 0x44, 0x52, 0x39, 0x2E, 0x72, 0x0F, 0x6E, 0x7E, 0x3F,0x32, 0x47, 0x5A, 0x13, 0x19, 0x06, 0x7A, 0x51, 0x18, 0x1A,0x63, 0x48, 0x02, 0x77, 0x3E, 0x54, 0x35, 0x16, 0x04, 0x5E,0x4F, 0x49, 0x30, 0x03, 0x15, 0x71, 0x4D, 0x11, 0x38, 0x12,0x05, 0x45, 0x27, 0x68, 0x3A, 0x75, 0x09, 0x20, 0x01, 0x40,0x69, 0x23, 0x6A, 0x3B, 0x41, 0x5F, 0x7B, 0x57, 0x3C, 0x1F,0x66, 0x56, 0x5C, 0x0C, 0x36, 0x73, 0x2D, 0x67, 0x43, 0x5D,0x4B, 0x28, 0x76, 0x78, 0x7D, 0x31, 0x6D, 0x25, 0x14, 0x74,0x5B, 0x6B, 0x0D, 0x50, 0x70, 0x64, 0x0E, 0x62, 0x2B, 0x0B,0x46, 0x2A, 0x7C, 0x79, 0x6C, 0x24, 0x21]
index = []
for i in range(1,0x80):
index.append(data.index(i))
print(index)
def reverse(num):
key = ""
while 1:
if num == 0:
break
elif num % 2 == 0:
num -= 2
num //= 2
key += "1"
elif num % 2 == 1:
num -= 1
num //= 2
key += "0"
key = key[::-1]
key += "?"
return key
print(reverse(12))
total_key = ""
for i in index:
total_key += reverse(i)
total_key += '\n'
f = open('./secret_key','w')
f.write(total_key)
最后运行./supervisor,终于得到这张漂亮的图片
