
书接前文,本文介绍 Go 语言二进制文件中的
<Interface, type>映射表和字符串信息,以及如何定位并解析它们。
传送门:
9. Interface 映射表(itab_link)
9.1 概念介绍
在 Go 语言的规范中,Interface(接口) 用来定义一组行为(Interface Methods),所有实现了这一组行为的其他类型,都可称之为实现了这个接口。Go 语言中 Interface 的用法还算是有些难点的,比如空接口的用法、以及更复杂一些的基于 Interface 实现的面向对象的多态特性。
前文《Go二进制文件逆向分析从基础到进阶——数据类型》中已经阐述过 Interface 类型的底层定义:
type interfaceType struct {
rtype
pkgPath name // import path
methods []imethod // sorted by hash
}
type imethod struct {
name nameOff // name of method
typ typeOff // .(*FuncType) underneath
}
其实,在 Go 二进制文件中,还保留了 Interface 与实现 Interface 的其他类型之间的映射关系。每一组映射关系,叫 itab(Interface Table),itab 的结构如下:
// Interface table
// Refer: https://golang.org/src/runtime/runtime2.go
type itab struct {
inter *interfacetype
_type *_type
hash uint32 // copy of _type.hash. Used for type switches.
_ [4]byte
fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter.
}
其中有 3 个关键字段:
- 第 1 个 inter,指向一个 Interface 类型的定义;
- 第 2 个 _type,指向一个普通数据类型的定义信息,这个 _type 实现了上面指定的 Interface;
- 第 5 个 fun,指向一组方法,是上面第 2 个字段 _type 中具体实现的 Interface 中定义的方法。
9.2 itab 实例
在 IDAPro 中,go_parser 解析好的一个 itab 项如下:
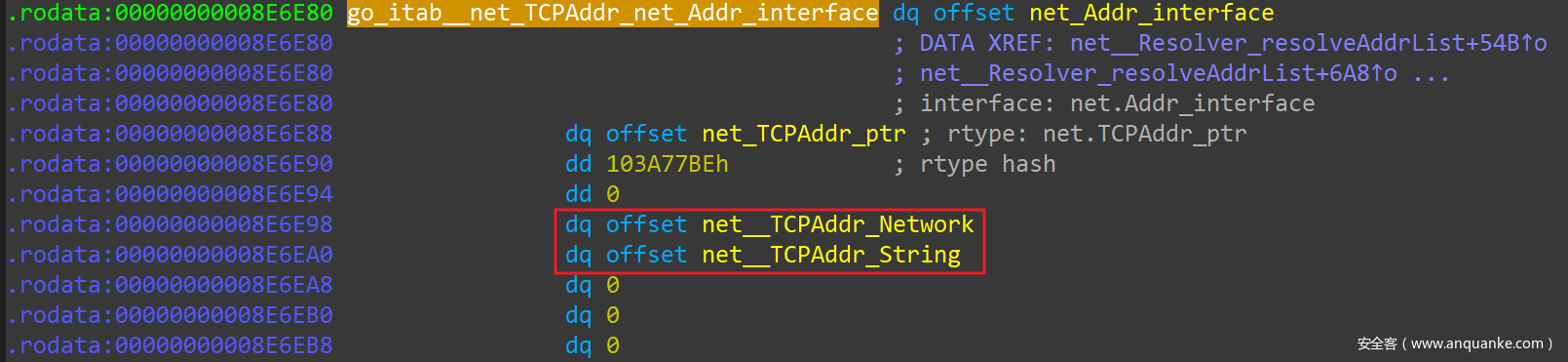
上图表明,package net 中定义了一个 Addr Interface,其中包含 2 个方法:Addr.Network() 和 Addr.String():
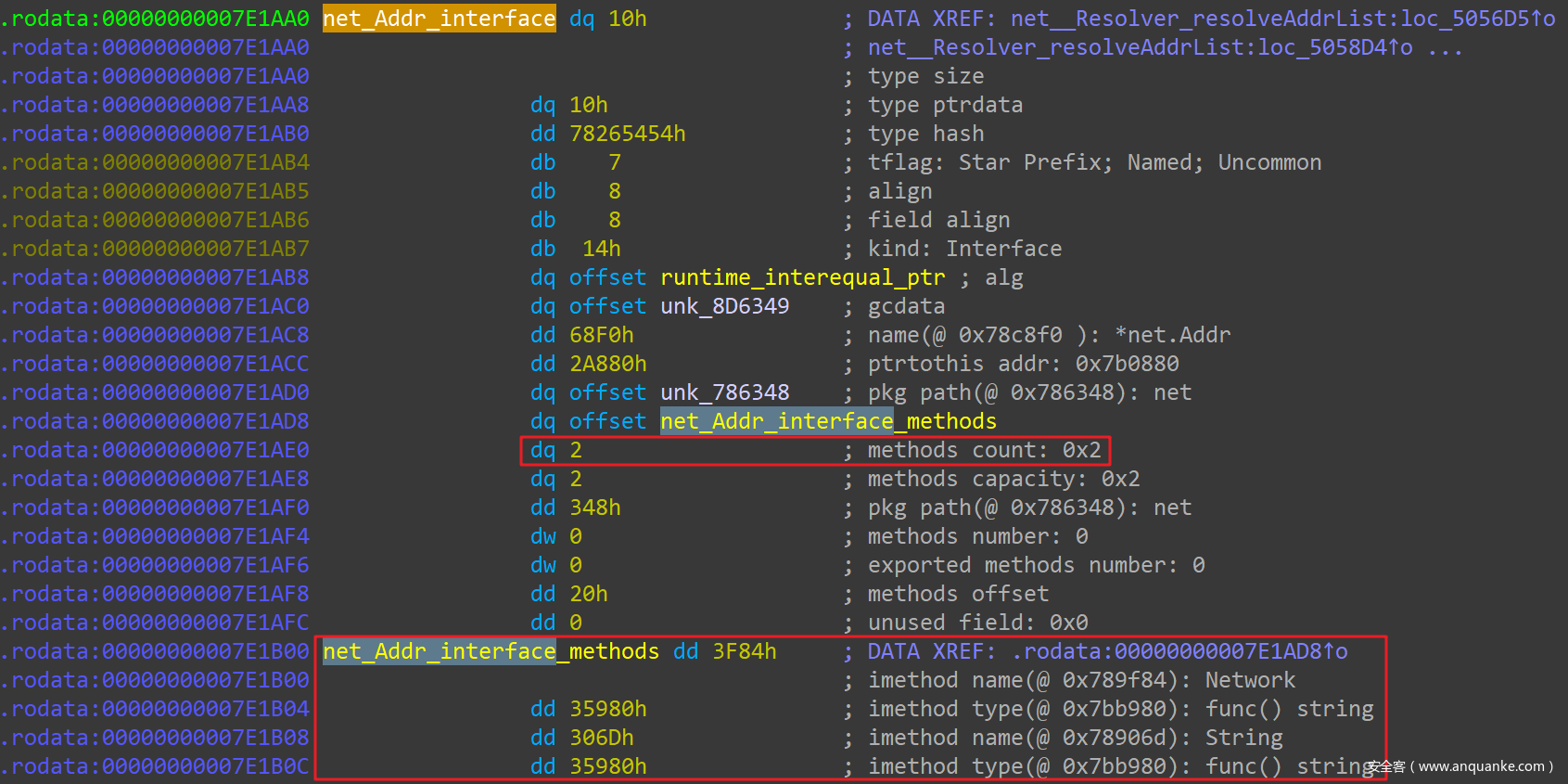
在 IDAPro 中,go_parser 解析好的 Addr Interface 定义如下:
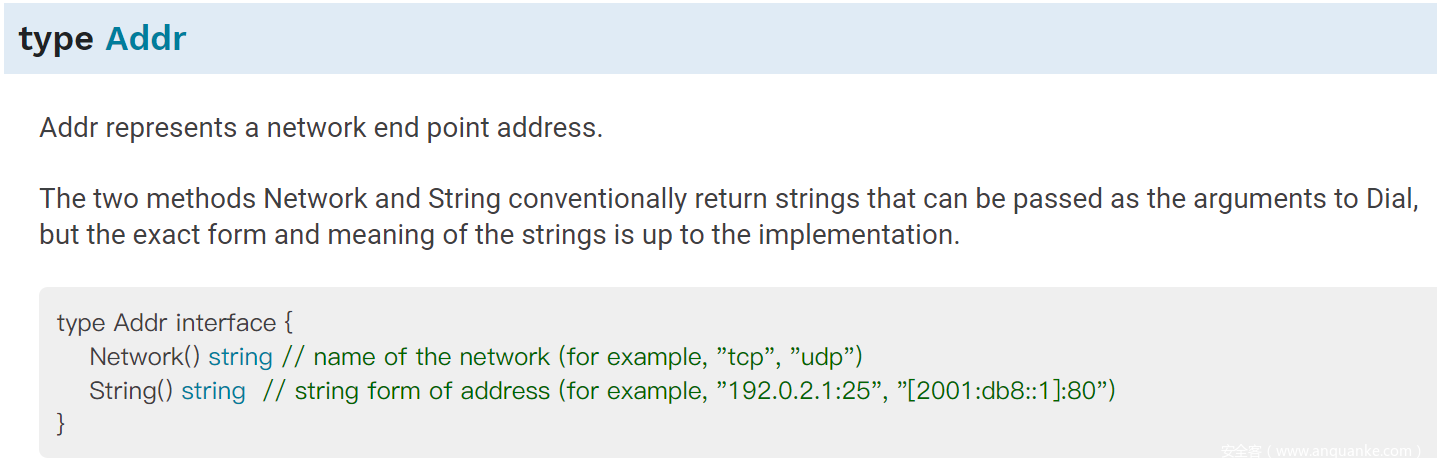
相应地,package net 中另一个数据结构 TCPAddr 实现了上述 Addr Interface。官方文档如下:

在 IDAPro 中,go_parser 解析好的 net.TCPAddr 类型定义如下:
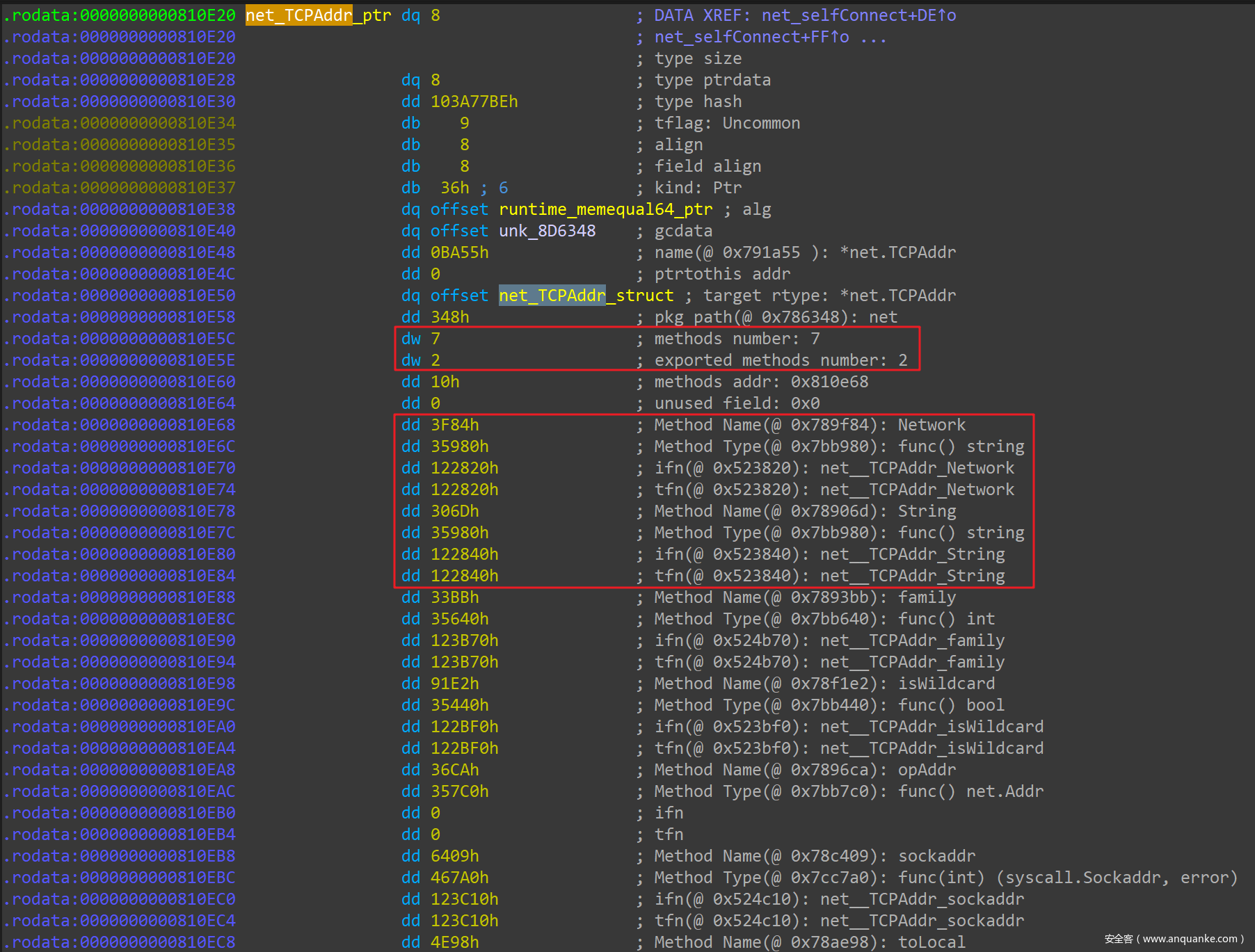
可以看到,net.TCPAddr 这个数据类型绑定了 7 个方法,其中 2 个可导出的方法分别是 Network() 和 String() ,正是这两个方法实现了 net.Addr Interface。
至于 itab 在 Go 二进制文件中是如何使用的?既然有了具体类型的定义,直接用具体类型不就可以了吗,为什么还要绕一圈映射一下实现的 Interface?如果有这类疑问,建议在 IDAPro 中打开一个 Go 二进制文件,找到某个 itab 结构的定义,以及通过交叉引用在 IDAPro 中这个 itab 是如何被调用的,再结合 Go 源码对照着看一下,应该能有所收获。
9.3 查找并解析 itab
上文介绍了单个 itab 的概念与结构解析,而一个 Go 二进制文件中可能存在几百甚至上千组 Interface 与具体数据类型的映射关系,即几百甚至上千个 itab 结构,如何把它们都找出来并一一解析呢?
首先需要说明的是,解析 itab 这个工作,依赖于前文介绍的解析所有数据类型定义的结果。解析了每一个数据类型的定义之后,才能知道每个 itab 结构中的 Interface 和具体数据类型的定义。
在本系列第二篇 《Go二进制文件逆向分析从基础到进阶——MetaInfo、函数符号和源码文件路径列表》中介绍 firstmoduledata 这个结构时,提到过这个结构里的一个字段: itab_link,并解释说 itab_link 指向 Go 二进制文件中的 Interface 映射表。分析过 Go 二进制文件的师傅可能注意过,itab_link 这个结构通常会在 ELF 文件中一个单独的 Section,就叫 .itablink 。然而我前文也说过,通过文件头中的 Section 来定位 Go 二进制文件中的关键数据并不靠谱,尤其是面对 ELF/PE/MachO 以及 PIE 这些不同文件类型的复杂情况,甚至 Section 信息被篡改甚至抹除时,更是如此。最靠谱的方式就是通过 firstmoduledata 中的字段来按图索骥,定位到各个关键数据结构的位置。
从 firstmoduledata 结构中 itab_link 字段定位到的 itablink,其实就是一个 itab 结构的地址列表,go_parser 解析好的 itablink 如下(一部分):
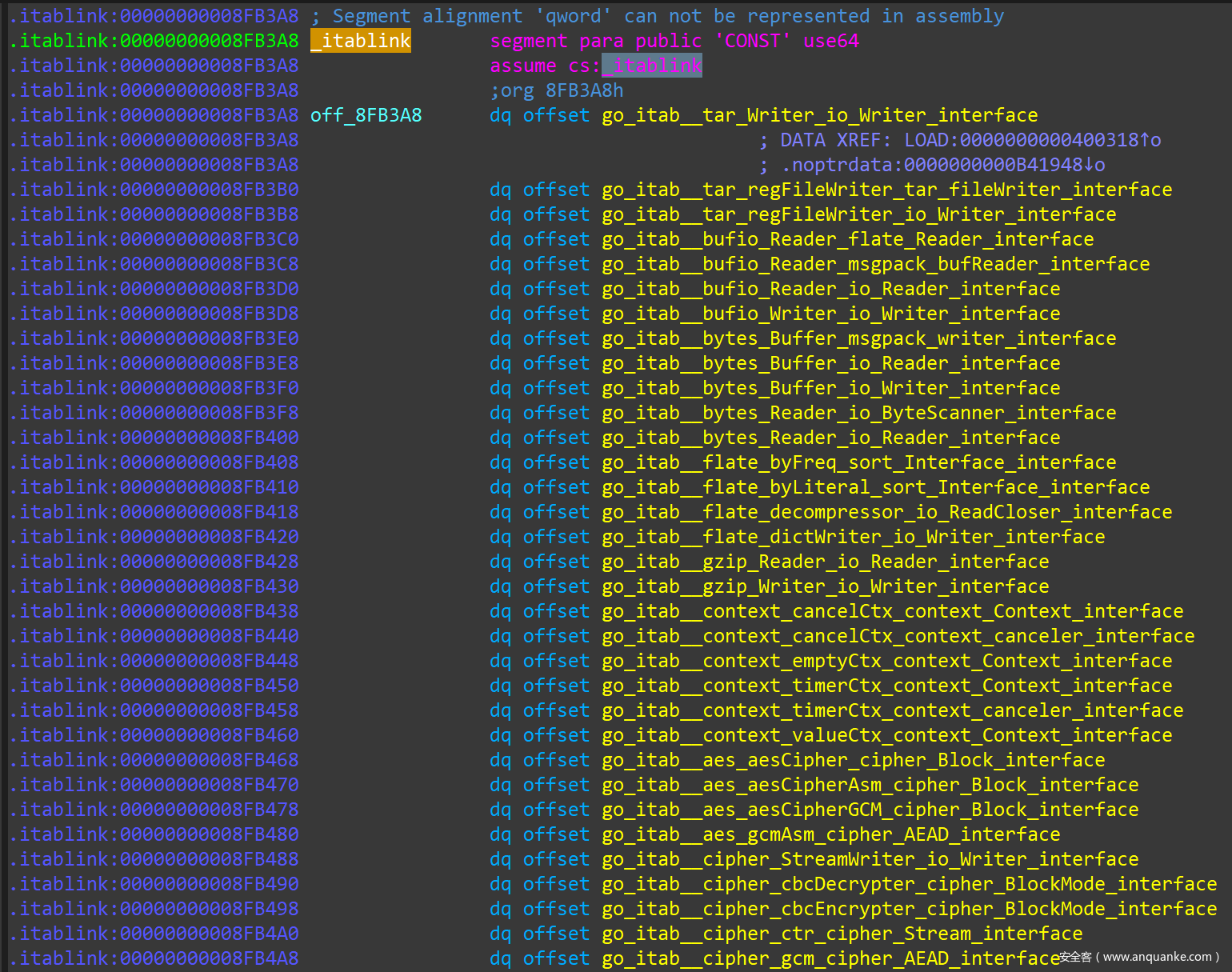
其中每一项,都是一个 itab 结构的地址。每个 itab 结构体的命名规则,都是 (前缀)go_itab + 实际类型名 + Interface 名。最后, firstmoduledata 中也标明了 itablink 结构中 itab 地址的数量,所以根据 itablink 的起始地址和数量,依次解析相应的 itab 即可。
10. 字符串
10.1 字符串简介
Go 语言中,string 类型是 值类型(相对于 引用类型),是 Go 支持的基础类型之一。一个字符串是一个不可改变的字节序列,字符串可以包含任意的数据,但是通常是用来包含可读的文本,字符串是 UTF-8 字符的一个序列(当字符为 ASCII 码表上的字符时则占用 1 个字节,其它字符根据需要占用 2-4 个字节)。
Go 中字符串底层由两个元素来定义:字节序列的地址 和 字节序列的长度,而不是像 C 语言那样以一个起始地址和 0x00 结尾就能表示一个字符串。在 Go 二进制文件中,操作一个字符串也要同时引用这两个元素。比如某函数需要一个字符串类型的参数,传参时就要在栈上的参数空间留两个位置,一个位置把相应字节序列的地址传进去,另一个位置把字节序列的长度传进去。字符串类型的返回值操作同理。
在静态逆向分析 Go 二进制文件时,把 Go 二进制文件加载到 IDAPro 中查看反汇编出来的代码时,在操作字符串的汇编代码片段中,最多只能看到目标字符串的长度,而字符串还是处于未分析的原始字节序列的状态。大量的字符串处于这种状态时,会使逆向分析变得很费劲,很大程度上拉低逆向分析的效率。所以我们要想办法把这些字符串尽量都解析出来,然后在引用这个字符串的汇编代码处打 Comment 或者加上 Data Reference,就会让逆向工作的效率提升一个台阶。
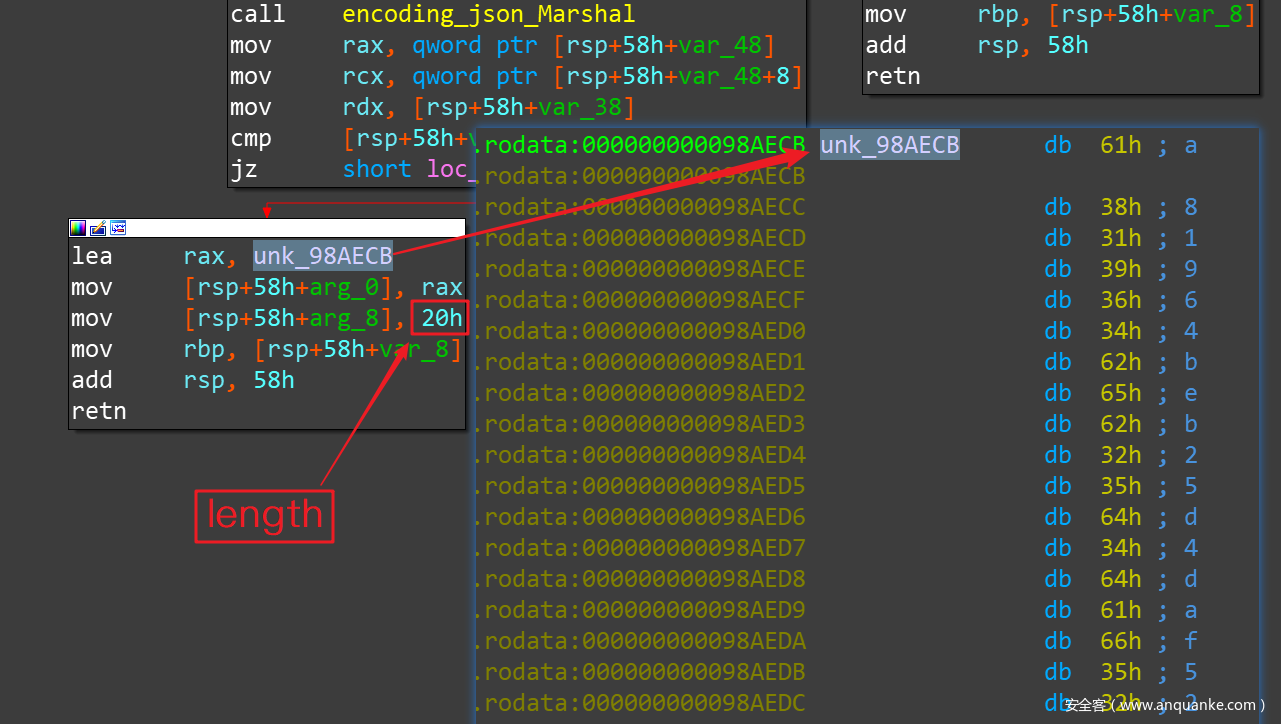
刚加载进 IDAPro 中的 Go 二进制文件,引用未解析的字符串字面量的汇编代码片段如下:
经过 go_parser 的解析,效果就会很直观了:
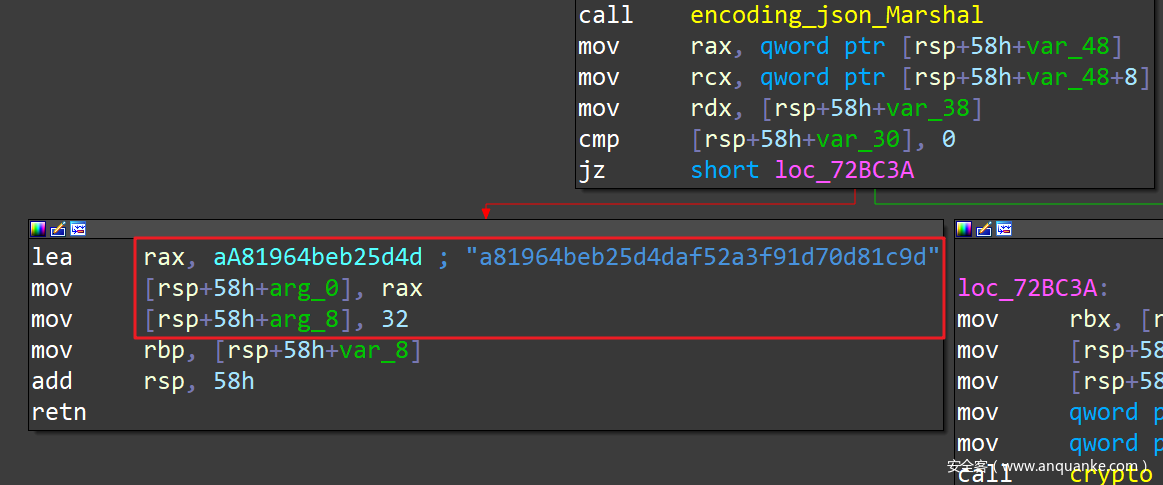
在 Go 二进制文件中,字符串整体上是按照长度依次存放在一个特定区域的。然而这个区域的起始地址、长度等属性没有固定的索引,所以无法像定位其他结构一样定位到所有字符串并一一解析。能用的办法,就是分析调用、操作字符串的的汇编指令片段的 Pattern,然后从所有汇编指令中暴力检索可能操作字符串的位置,提取到相应字符串的地址与长度进而解析能够查找到的字符串。
Go 二进制文件中的字符串,按照存放和引用方式,可以分为三种:
- 字符串字面量,通常来说字符串常量(包括命名常量和未命名的字面常量)都会用这种形式;
- 字符串指针,字符串变量和一部分字符串常量会用这种形式。
- 字符串数组/切片
这三种类型的字符串存取方式,从操作字符串的汇编代码片段来看,Pattern 不同,解析方法也不同,下文一一介绍。
10.2 字符串字面量
上面 10.1 小节的截图中介绍的例子,就是字符串字面常量。操作字符串字面量的汇编代码,会直接引用字节序列的地址,然后把字符串的长度当作汇编指令的一个立即数来使用。不过,根据不同的 CPU 位数、目标寄存器的不同,这样的汇编代码片段的 Pattern 有多种。 go_parser 中可以解析的 x86 汇编指令 Pattern 如下:
mov ebx, offset aWire ; "wire" # Get string
mov [esp], ebx
mov dword ptr [esp+4], 4 # String length
mov ebx, offset unk_8608FD5 # Get string
mov [esp+8], ebx
mov dword ptr [esp+0Ch], 0Eh # String length
mov ebx, offset unk_86006E6 # Get string
mov [esp+10h], ebx
mov dword ptr [esp+14h], 5 # String length
mov ebx, 861143Ch
mov dword ptr [esp+0F0h+var_E8+4], ebx
mov [esp+0F0h+var_E0], 19h
# Found in newer versions of golang binaries
lea rax, unk_8FC736 ; str bytes addr
mov [rsp+38h+var_18], rax
mov [rsp+38h+var_10], 1Dh ;str len
lea rdx, unk_8F6E82 ; str bytes addr
mov [rsp+40h+var_38], rdx
mov [rsp+40h+var_30], 13h ; str len
lea eax, unk_82410F0 ; str bytes addr
mov [esp+94h+var_8C], eax
mov [esp+94h+var_88], 2 ; str len
如此一来,就看一参考如上代码片段的 Pattern,暴力搜索所有代码中符合以上 Pattern 的代码片段,并尝试解析字符串信息。go_parser 的 string 解析模块,大部分代码从 golang_loader_assist 移植而来,目前只支持 x86 架构的二进制文件。如果有师傅有兴趣实现一下 ARM/MIPS/PPC 等架构二进制文件的字符串解析功能,欢迎提 PR。
10.3 字符串指针
Go 二进制文件中的字符串指针则是另一种形式,在 IDAPro 中看,主要有 3 点特征:
- 汇编代码中引用字符串时,不会直接引用字符序列的地址,而是会引用存放字符串地址的地址(字符串指针);
- 汇编代码中可能会用到字符串的长度,但不会把字符串的长度作为汇编指令的立即数,而是把字符串长度的数值存到一个位置,汇编代码只引用存放字符串长度的地址;
- 字符串长度的地址,紧挨着字符串指针后面存放。
下面是 go_parser 解析好的一个字符串指针的用法:
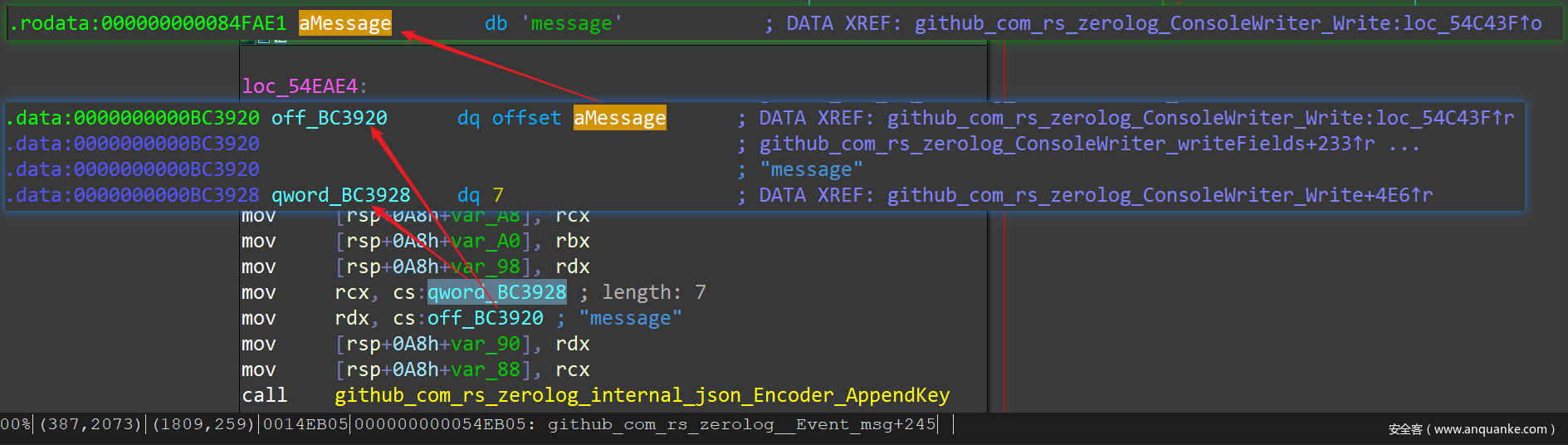
上面那种形式,可以用 IDAPython 在 IDAPro 中暴力搜索并解析如下 Pattern 的汇编指令片段来解析:
mov rcx, cs:qword_BC2908 ; str len
mov rdx, cs:off_BC2900 ; str pointer
mov [rsp+0A8h+var_90], rdx
mov [rsp+0A8h+var_88], rcx
call func
而还有一种方式,Pattern 不明显,不便自动化解析。举个例子,如下是 package bufio 中 Reader 的 fill() 方法:
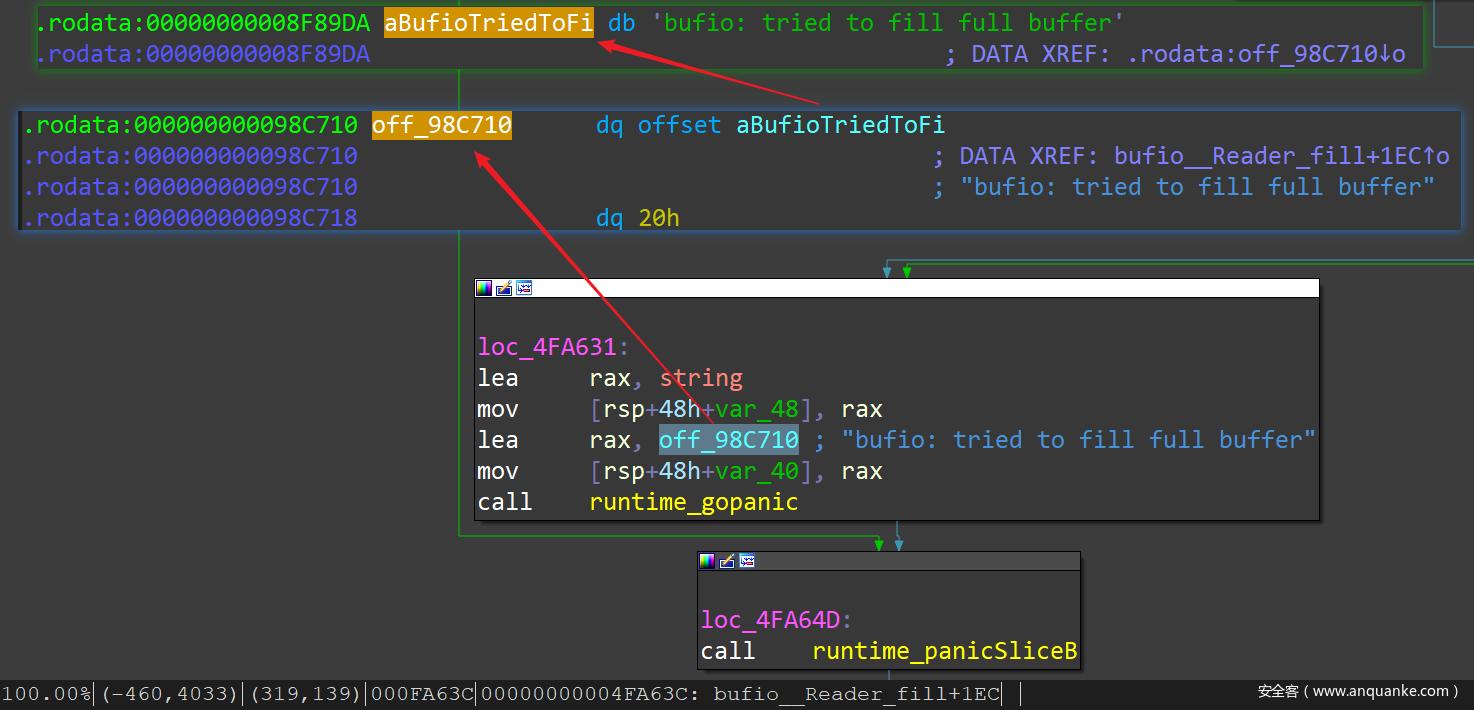
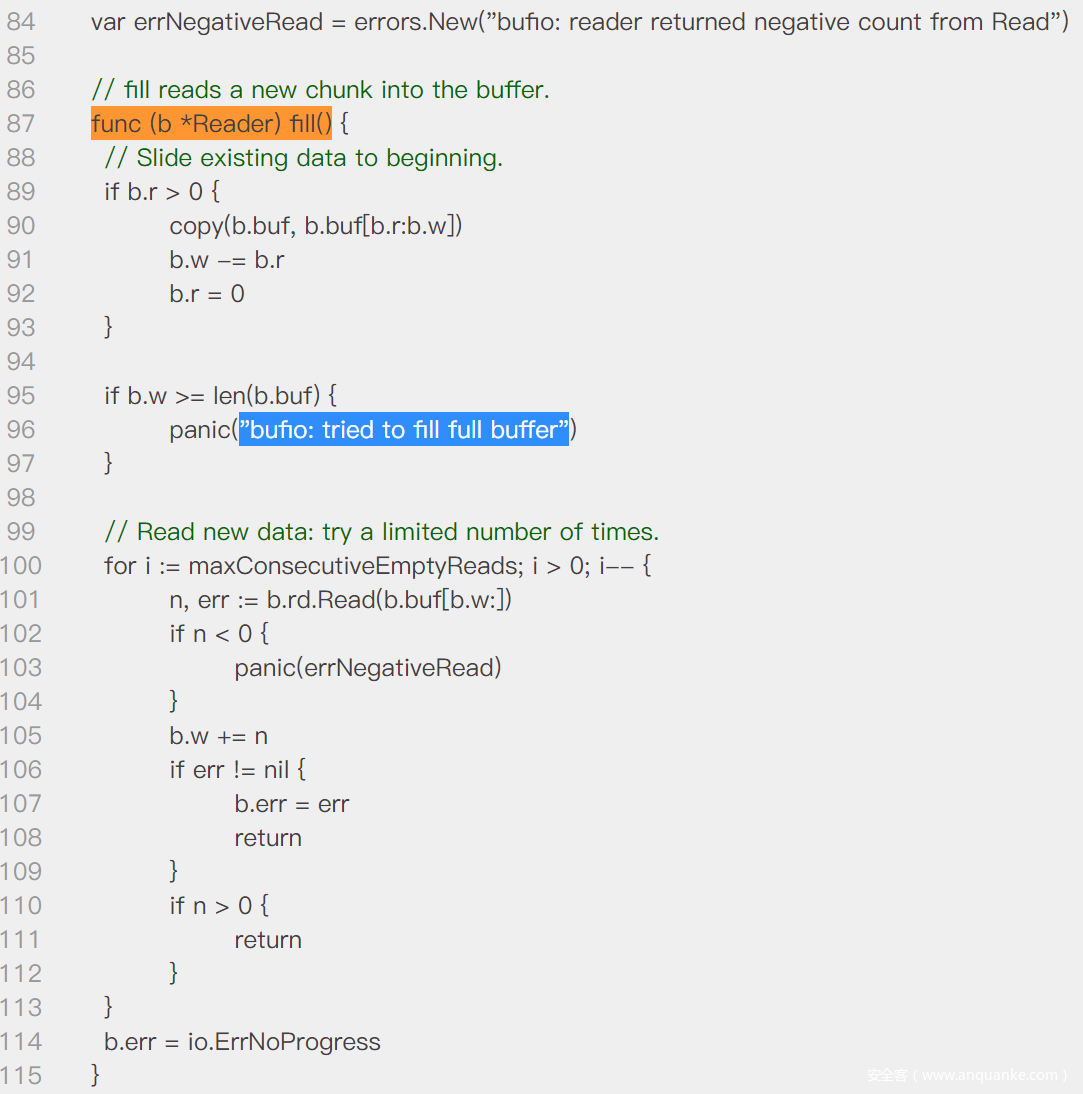
可以发现 runtime_gopanic() 函数调用字符串的时候传入了一个 string 类型,和字符序列的地址,并未指定字符串的长度。对应的源码实现如下,可以对比着看一下 :
对于这种形式的字符串指针,只好另寻他法。好在 Go 二进制文件中的字符串指针也是集中存放在一个固定区域中的。如下,是这一块区域的开头部分:
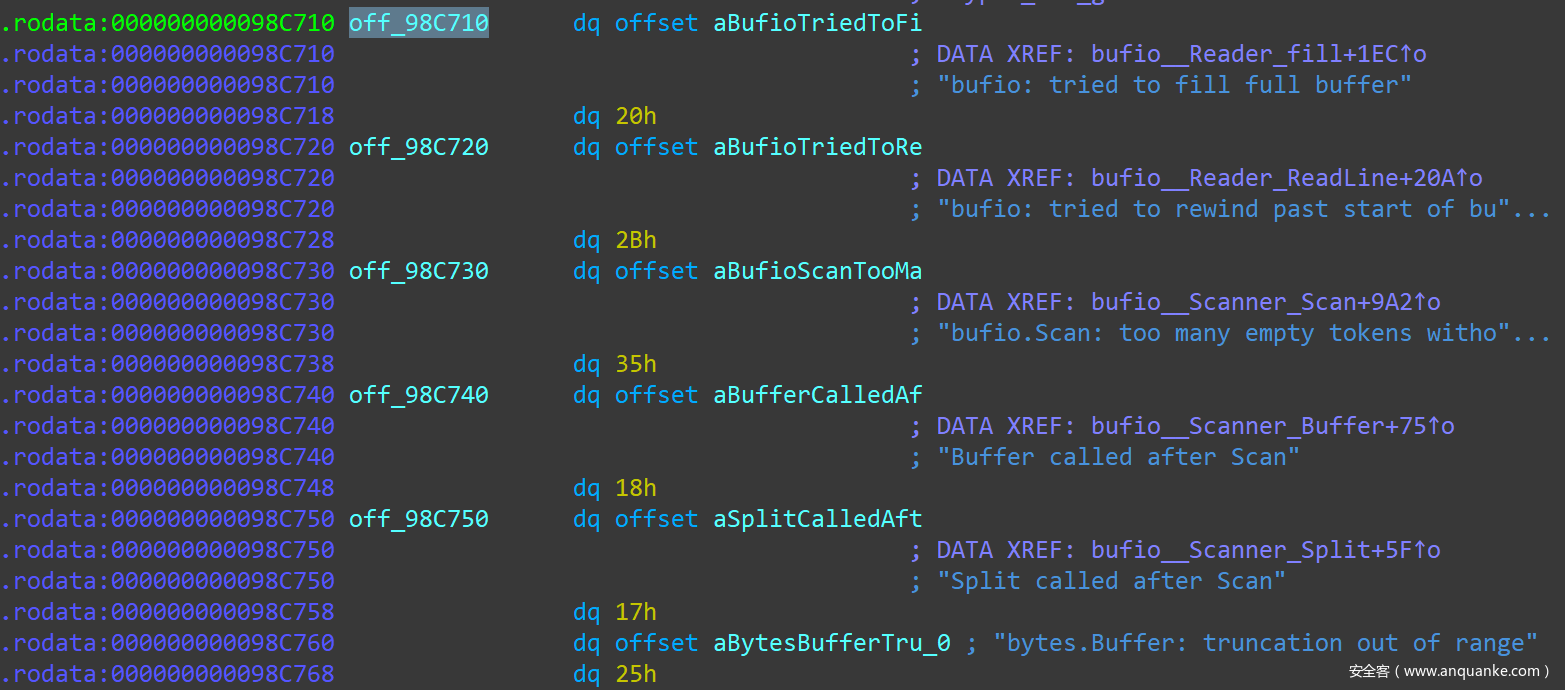
我们可以手动在 IDAPro 中找到这一块区域的起始地址、终止地址,然后手动执行以下 IDAPython 脚本,即可批量把所有字符串指针解析出来。如果是用 IDAPro v7.2 及以上版本,那么 IDAPro 会自动为这些字符串指针引用的指令加上 Data Reference。IDAPython 脚本如下:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''
go_parser.py:
IDA Plugin for Golang Executable file parsing.
'''
__author__ = "JiaYu"
__license__ = "MIT"
__version__ = "1.0"
__email__ = ["jiayu0x@gmail.com"]
import idc, idaapi
idaapi.require("common") # common module in go_parser
START_EA = 0x98C710
END_EA = 0x990F58
curr_addr = START_EA
while curr_addr <= END_EA:
curr_str_addr = common.read_mem(curr_addr)
curr_str_len = common.read_mem(curr_addr + common.ADDR_SZ)
if curr_str_addr > 0 and curr_str_addr != idc.BADADDR and curr_str_len > 1:
if idc.MakeStr(curr_str_addr, curr_str_addr + curr_str_len):
idaapi.autoWait()
curr_str = str(idc.GetManyBytes(curr_str_addr, curr_str_len))
print("@ 0x%x: %s" % (curr_str_addr, curr_str))
curr_addr += 2 * common.ADDR_SZ
Note:
上面这段代码已同步到 go_parser 的 Github Repo:
https://github.com/0xjiayu/go_parser/blob/master/str_ptr.py
另外一个可以考虑的思路,是遍历上面提到的 string 类型定义的交叉引用,然后看看有没有如上的汇编指令片段的 Pattern。如果一段汇编代码中拿 string 类型定义去解析一个字符串,那么就可以顺藤摸瓜找到字符串指针,字符串指针的地址后面紧挨着就是字符串的长度,这样也可以把字符串解析出来。感兴趣的师傅可以验证一下。
10.4 字符串数组
字符串数组,在 Go 二进制文件里的展示方式,比上面的情况要再多“跳转”一步:整个数组用元素起始地址和数组长度 两个元素来表示,而元素的起始地址处则依次存放了每一个字符串的地址和长度。语言描述不易理解,且看实例。以 package mime 中的 initMimeUnix() 函数为例,源代码如下:
var typeFiles = []string{
"/etc/mime.types",
"/etc/apache2/mime.types",
"/etc/apache/mime.types",
}
func initMimeUnix() {
for _, filename := range typeFiles {
loadMimeFile(filename)
}
}
而在 IDAPro 中来看,就是如下的样子:
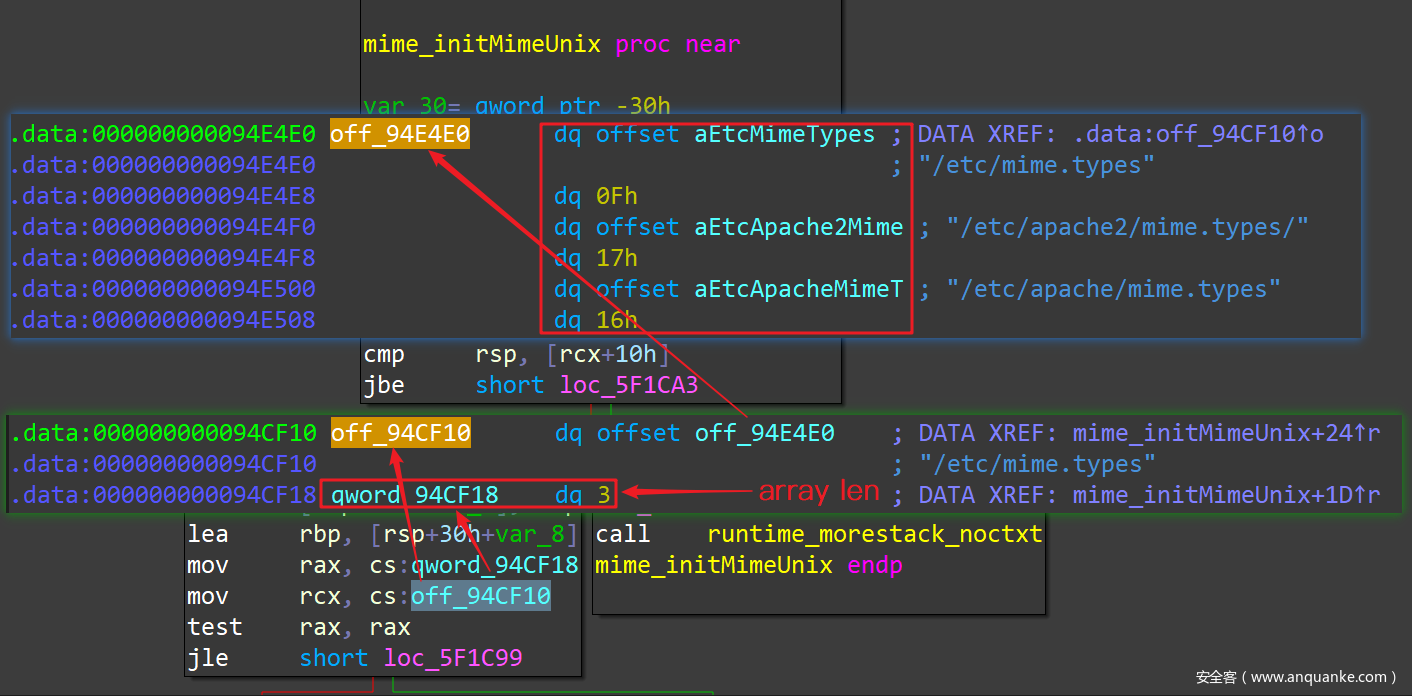
Go 语言二进制文件中,所有的数组,无论数组中元素是什么类型,都是集中存放的,很难从这些存放数组元素的数据块中区分出哪些书字符串数组,哪些是别的类型的数组(比如 int 类型的数组)。而汇编代码中引用字符串数组的代码片段又没有很强的 Pattern,所以难以自动化地把这些字符串数组都解析好并在 IDAPro 中友好地展示出来。
可以考虑上面半自动化解析字符串指针的做法,在 IDAPro 中手动定位到一批字符串数组的位置,然后写几行 IDAPython 脚本将这些字符串数组批量解析。有兴趣的师傅不妨动手试一试。
至此,我们就可以把 Go 二进制文件中的字符串,在 IDAPro 中部分自动化的解析、部分半自动化地解析出来。之后再去看汇编代码,涉及字符串的操作就会一目了然。
参考资料:
- https://github.com/0xjiayu/go_parser
- https://golang.org/src/mime/type_unix.go
- https://golang.org/src/bufio/bufio.go
- https://www.anquanke.com/post/id/214940
- https://www.anquanke.com/post/id/215419
- https://www.anquanke.com/post/id/215820
- https://golang.org/pkg/net/
- https://github.com/strazzere/golang_loader_assist