
很早之前写了largebin attack的利用方式之一的lctf2017的2ez4u的wp,但是过去了很久,都忘了。以前对于源码了解的也不够清楚,只知道个大概,并且0ctf2018的heapstorm2出现了largebin attack的第二种姿势,一直想抽时间把largebin分配与释放的过程再好好看看,把这两种方式再好好的总结下,以免后面还是忘掉。
largebin attack的方式大致有两种:
- 在申请largebin的过程中,伪造largebin的
bk_nextsize,实现非预期内存申请。 - 在largebin插入的过程中,伪造largebin的
bk_nextsize以及bk,实现任意地址写堆地址。
前者典型的例题是2ez4u,后者典型的例题是heapstorm2以及rctf2019的babyheap。接下来会结合源码与题目,尝试将原理与利用姿势总结清楚。
largebin管理机制
源码中,以不在smallbin范围中的chunk称之为largebin,smallbin的定义相关是:
#define in_smallbin_range(sz)
((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE)
#define NSMALLBINS 64
#define SMALLBIN_WIDTH MALLOC_ALIGNMENT
#define SMALLBIN_CORRECTION (MALLOC_ALIGNMENT > 2 * SIZE_SZ)
#define MIN_LARGE_SIZE ((NSMALLBINS - SMALLBIN_CORRECTION) * SMALLBIN_WIDTH)
因此在64位的系统里面大于MIN_LARGE_SIZE为64*0x10即0x400的chunk为largebin,而32位系统中大于MIN_LARGE_SIZE为64*0x8即0x200的chunk位largebin。
后面的分析过程中,主要还是基于64位的系统,所以源码分析就不再提32位了,有需要的可以借鉴64位的自行分析。
与smallbin不同的是,largebin中不再是一个index只对应一个大小的size,而是存储等差数列变化的chunk块。其相关定义如下:
#define largebin_index_64(sz)
(((((unsigned long) (sz)) >> 6) <= 48) ? 48 + (((unsigned long) (sz)) >> 6) :
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :
126)
可以看到大小为0x400对应的chunk其对应的index为(0x400>>6)+48即64,而index为64对应的范围是[0x400, 0x400+1>>6)即[0x400, 0x440),在这个级别index中,size的范围为0x40(1<<6),依次类推size与index对应的关系是:
| size | index |
|---|---|
| [0x400 , 0x440) | 64 |
| [0x440 , 0x480) | 65 |
| [0x480 , 0x4C0) | 66 |
| [0x4C0 , 0x500) | 67 |
| [0x500 , 0x540) | 68 |
| 等差 0x40 | … |
| [0xC00 , 0xC40) | 96 |
| [0xC40 , 0xE00) | 97 |
| [0xE00 , 0x1000) | 98 |
| [0x1000 , 0x1200) | 99 |
| [0x1200 , 0x1400) | 100 |
| [0x1400 , 0x1600) | 101 |
| 等差 0x200 | … |
| [0x2800 , 0x2A00) | 111 |
| [0x2A00 , 0x3000) | 112 |
| [0x3000 , 0x4000) | 113 |
| [0x4000 , 0x5000) | 114 |
| 等差 0x1000 | … |
| [0x9000 , 0xA000) | 119 |
| [0xA000 , 0x10000) | 120 |
| [0x10000 , 0x18000) | 121 |
| [0x18000 , 0x20000) | 122 |
| [0x20000 , 0x28000) | 123 |
| [0x28000 , 0x40000) | 124 |
| [0x40000 , 0x80000) | 125 |
| [0x80000 , …. ) | 126 |
largebin管理的是一个范围区间的堆块,此时fd_nextsize与bk_nextsize就派上了用场。
大小对应相同index中的堆块,其在链表中的排序方式为:
- 堆块从大到小排序。
- 对于相同大小的堆块,最先释放的堆块会成为堆头,其
fd_nextsize与bk_nextsize会被赋值,其余的堆块释放后都会插入到该堆头结点的下一个结点,通过fd与bk链接,形成了先释放的在链表后面的排序方式,且其fd_nextsize与bk_nextsize都为0。 - 不同大小的堆块通过堆头串联,即堆头中
fd_nextsize指向比它小的堆块的堆头,bk_nextsize指向比它大的堆块的堆头,从而形成了第一点中的从大到小排序堆块的方式。同时最大的堆块的堆头的bk_nextsize指向最小的堆块的堆头,最小堆块的堆头的fd_nextsize指向最大堆块的堆头,以此形成循环双链表。
具体编程体验下laigebin的管理机制,首先是堆块从大到小的排序,以[0x400, 0x440)为例,源码如下:
#include<stdio.h>
int main()
{
char *gap;
char *ptr0=malloc(0x400-0x10); //A
gap=malloc(0x10);
char *ptr1=malloc(0x410-0x10); //B
gap=malloc(0x10);
char *ptr2=malloc(0x420-0x10); //C
gap=malloc(0x10);
char *ptr3=malloc(0x430-0x10); //D
gap=malloc(0x10);
free(ptr2);
free(ptr3);
free(ptr0);
free(ptr1);
malloc(0x440); //trigger that sort largebin from unsorted bin to largebins
return 0;
}
堆块最初释放都是在unsorted bin中,在申请堆块时会对unsorted bin进行整理,会将堆块释放到相应的largebin中,所以在最后有一个malloc(0x440)来将堆释放到large bin中。
上述代码,最后形成的堆块的图示如下:
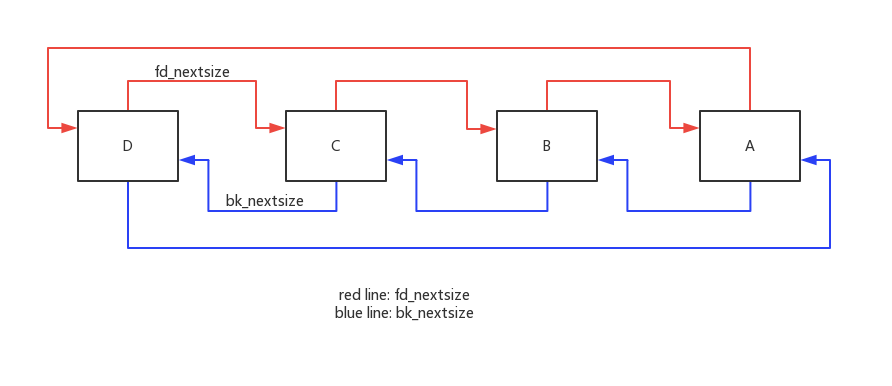
可以看到即使打乱了堆块,largebin最终的排序方式仍然是从大到小排序,形成了D->C->B->A的排序。
再看相同大小的堆块的管理方式,源码如下:
#include<stdio.h>
int main()
{
char *gap;
char *ptr0=malloc(0x400-0x10); //A
gap=malloc(0x10);
char *ptr1=malloc(0x400-0x10); //B
gap=malloc(0x10);
char *ptr2=malloc(0x400-0x10); //C
gap=malloc(0x10);
char *ptr3=malloc(0x400-0x10); //D
gap=malloc(0x10);
free(ptr2); //C
free(ptr3); //D
free(ptr0); //A
free(ptr1); //B
malloc(0x440); //trigger that sort largebin from unsorted bin to largebins
return 0;
}
其排序示意图如下,可以看到对于相同大小的堆块,先释放的堆块C为堆头,由于不存在比它大或比它小的堆块,因此它的fd_nextsize和bk_nextsize都是指向自己。同时其余释放的堆块按释放的顺序插入到链表的第二个节点中,且它们的fd_nextsize和bk_nextsize均为0,它们通过fd与bk进行链接,但我们这里关心的是fd_nextsize和bk_nextsize,因此未将fd与bk进行表示,最终形成C->B->A->D的双链表。
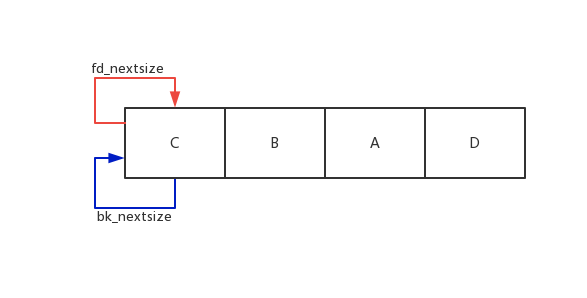
最后是既存在相同大小的堆块又存在不同大小的堆块管理示例,根据前面两个示例,我们知道了相应的链接方式为:堆头fd_nextsize指向比它小的堆头,bk_nextsize指向比它大的堆头,相同大小的堆块则由堆头进行链接,其fd_nextsize和bk_nextsize为0。源码如下:
#include<stdio.h>
int main()
{
char *gap;
char *ptr0=malloc(0x400-0x10); //A
gap=malloc(0x10);
char *ptr1=malloc(0x410-0x10); //B
gap=malloc(0x10);
char *ptr2=malloc(0x420-0x10); //C
gap=malloc(0x10);
char *ptr3=malloc(0x430-0x10); //D
gap=malloc(0x10);
char *ptr4=malloc(0x400-0x10); //E
gap=malloc(0x10);
char *ptr5=malloc(0x410-0x10); //F
gap=malloc(0x10);
char *ptr6=malloc(0x420-0x10); //G
gap=malloc(0x10);
char *ptr7=malloc(0x430-0x10); //H
gap=malloc(0x10);
free(ptr2); //C
free(ptr3); //D
free(ptr0); //A
free(ptr1); //B
free(ptr7); //H
free(ptr6); //G
free(ptr5); //F
free(ptr4); //E
malloc(0x440); //trigger that sort largebin from unsorted bin to largebins
return 0;
}
最终形成的链表如图所示,可以看到不同的size会形成堆头,通过堆头的fd_nextsize与bk_nextsize指向比它大或小的堆头,而相同的堆块则会链入到相应的堆头之中。
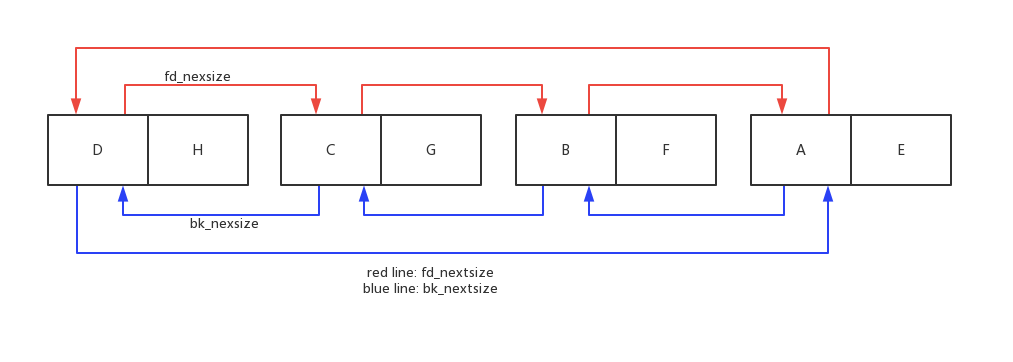
到这里可以看到设置fd_nextsize与bk_nextsize的作用:由于largebin中存在不同大小的堆块,通过堆头的fd_nextsize与bk_nextsize字段,如果想要申请特定堆块,可以通过快速的遍历比当前堆块大或小的堆块,以增加查找速度,实现性能的提升。
接下来具体看源码中是如何实现将largebin chunk从unsorted bin中取下来放入到largebin中的。
/* place chunk in bin */
if (in_smallbin_range (size))
{
... // chunk为smallbin,放入到smallbin中
}
else
{
victim_index = largebin_index (size);//第一步,获取当前要插入的chunk对应的index
bck = bin_at (av, victim_index); //当前index中最小的chunk
fwd = bck->fd; //当前index中最大的chunk
/* maintain large bins in sorted order */
if (fwd != bck)
{ // 该chunk对应的largebin index中不为空
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert ((bck->bk->size & NON_MAIN_ARENA) == 0);
if ((unsigned long) (size) < (unsigned long) (bck->bk->size)) //第三步,如果要插入的chunk的size小于当前index中最小chunk的大小,则直接插入到最后面。
{
fwd = bck;
bck = bck->bk;
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize;
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
}
else
{
assert ((fwd->size & NON_MAIN_ARENA) == 0);
while ((unsigned long) size < fwd->size) //第四步,如果插入的chunk不为最小,则通过`fd_nextsize`从大到小遍历chunk,找到小于等于要插入chunk的位置
{
fwd = fwd->fd_nextsize;
assert ((fwd->size & NON_MAIN_ARENA) == 0);
}
if ((unsigned long) size == (unsigned long) fwd->size)
/* Always insert in the second position. */
fwd = fwd->fd; //第五步,如果存在堆头,则插入到堆头的下一个节点
else
{ //第六步,否则这个chunk将会成为堆头,`bk_nextsize`和`fd_nextsize`将被置位
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;
}
bck = fwd->bk;
}
}
else //第二步,chunk对应的largebin index中为空
victim->fd_nextsize = victim->bk_nextsize = victim;
}
mark_bin (av, victim_index);
//设置fd与bk完成插入
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;
...
}
整个流程可以总结为:
- 找到当前要插入的chunk对应的largebin的index,并定位该index中的最小的chunk
bck和最大的chunkfwd。 - 如果
fwd等于bck,表明当前链表为空,则直接将该chunk插入,并设置该chunk为该大小堆块的堆头,将bk_nextsize和fd_nextsize赋值为它本身。 - 如果
fwd不等于bck,表明当前链表已经存在chunk,要做的就是找到当前chunk对应的位置将其插入。首先判断其大小是否小于最小chunk的size,(size) < (bck->bk->size),如果小于则说明该chunk为当前链表中最小的chunk,即插入位置在链表末尾,无需遍历链表,直接插入到链表的末尾,且该chunk没有对应的堆头,设置该chunk为相应堆大小堆的堆头,将bk_nextsize指向比它大的堆头,fd_nextsize指向双链表的第一个节点即最大的堆头。 - 如果当前chunk的size不是最小的chunk,则从双链表的第一个节点即最大的chunk的堆头开始遍历,通过
fd_nextsize进行遍历,由于fd_nextsize指向的是比当前堆头小的堆头,因此可以加快遍历速度。直到找到小于等于要插入的chunk的size。 - 如果找到的chunk的size等于要插入chunk的size,则说明当前要插入的chunk的size已经存在堆头,那么只需将该chunk插入到堆头的下一个节点。
- 如果找到的chunk的size小于当前要插入chunk的size,则说明当前插入的chunk不存在堆头,因此该chunk会成为堆头插入到该位置,设置
fd_nextsize与bk_nextsize。
通过源码分析可以与之前的排序方式对应上,接下来我们再看largebin是如何被申请出来的。
相关源代码如下:
/*
If a large request, scan through the chunks of current bin in
sorted order to find smallest that fits. Use the skip list for this.
*/
if (!in_smallbin_range (nb))
{
bin = bin_at (av, idx); //找到申请的size对应的largebin链表
/* skip scan if empty or largest chunk is too small */
if ((victim = first (bin)) != bin &&
(unsigned long) (victim->size) >= (unsigned long) (nb)) //第一步,判断链表的第一个结点,即最大的chunk是否大于要申请的size
{
victim = victim->bk_nextsize;
while (((unsigned long) (size = chunksize (victim)) <
(unsigned long) (nb))) //第二步,从最小的chunk开始,反向遍历 chunk size链表,直到找到第一个大于等于所需chunk大小的chunk退出循环
victim = victim->bk_nextsize;
/* Avoid removing the first entry for a size so that the skip
list does not have to be rerouted. */
if (victim != last (bin) && victim->size == victim->fd->size) //第三步,申请的chunk对应的chunk存在多个结点,则申请相应堆头的下个结点,不申请堆头。
victim = victim->fd;
remainder_size = size - nb;
unlink (av, victim, bck, fwd); //第四步,largebin unlink 操作
/* Exhaust */
if (remainder_size < MINSIZE) //第五步,如果剩余的空间小于MINSIZE,则将该空间直接给用户
{
set_inuse_bit_at_offset (victim, size);
if (av != &main_arena)
victim->size |= NON_MAIN_ARENA;
}
/* Split */
else
{
remainder = chunk_at_offset (victim, nb); //第六步,如果当前剩余空间还可以构成chunk,则将剩余的空间放入到unsorted bin中。
/* We cannot assume the unsorted list is empty and therefore
have to perform a complete insert here. */
bck = unsorted_chunks (av);
fwd = bck->fd;
if (__glibc_unlikely (fwd->bk != bck))
{
errstr = "malloc(): corrupted unsorted chunks";
goto errout;
}
remainder->bk = bck;
remainder->fd = fwd;
bck->fd = remainder;
fwd->bk = remainder;
if (!in_smallbin_range (remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
set_foot (remainder, remainder_size);
}
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}
可以将整个流程总结为:
- 找到当前要申请的空间对应的largebin链表,判断第一个结点即最大结点的大小是否大于要申请的空间,如果小于则说明largebin中没有合适的堆块,需采用其他分配方式。
- 如果当前largebin中存在合适的堆块,则从最小堆块开始,通过
bk_nextsize反向遍历链表,找到大于等于当前申请空间的结点。 - 为减少操作,判断找到的相应结点(堆头)的下个结点是否是相同大小的堆块,如果是的话,将目标设置为该堆头的第二个结点,以此减少将
fd_nextsize与bk_nextsize赋值的操作。 - 调用
unlink将目标largebin chunk从双链表中取下。 - 判断剩余空间是否小于MINSIZE,如果小于直接返回给用户。
- 否则将剩余的空间构成新的chunk放入到unsorted bin中。
再看下unlink的源码:
/* Take a chunk off a bin list */
#define unlink(AV, P, BK, FD) {
if (__builtin_expect (chunksize(P) != (next_chunk(P))->prev_size, 0))
malloc_printerr (check_action, "corrupted size vs. prev_size", P, AV);
FD = P->fd;
BK = P->bk;
if (__builtin_expect (FD->bk != P || BK->fd != P, 0))
malloc_printerr (check_action, "corrupted double-linked list", P, AV);
else {
FD->bk = BK;
BK->fd = FD;
if (!in_smallbin_range (P->size)
&& __builtin_expect (P->fd_nextsize != NULL, 0)) {
if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0)
|| __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0))
malloc_printerr (check_action,
"corrupted double-linked list (not small)",
P, AV);
if (FD->fd_nextsize == NULL) {
if (P->fd_nextsize == P)
FD->fd_nextsize = FD->bk_nextsize = FD;
else {
FD->fd_nextsize = P->fd_nextsize;
FD->bk_nextsize = P->bk_nextsize;
P->fd_nextsize->bk_nextsize = FD;
P->bk_nextsize->fd_nextsize = FD;
}
} else {
P->fd_nextsize->bk_nextsize = P->bk_nextsize;
P->bk_nextsize->fd_nextsize = P->fd_nextsize;
}
}
}
}
再看看largebin的unlink检查,从代码中可以看到,就是多了fd_nextsize和bk_nextsize俩个位置的检查,原理和fd和bk的检查一致。但是需要注意的是对于存在多个满足空间的堆块来说,申请出来的是堆头的下一个结点,它的fd_nextsize和bk_nextsize为空。也就是说即使它是largebin chunk,但是它的fd_nextsize也为空,即不满足条件__builtin_expect (P->fd_nextsize != NULL, 0),对于此类chunk的unlink,只会像smallbin的unlink一样检查fd与bk,而不会对fd_nextsize与bk_nextsize进行检查与操作。
至此largebin链表的形成以及申请largebin都已经阐述清楚。再小结下,对于largebin的链表的插入,双链表是从大到小的chunk排序,相同大小的chunk会有一个堆头,只有堆头的fd_nextsize与bk_nextsize会被赋值,其余堆块的该字段为0。插入的遍历是通过fd_nextsize从大到小进行的,如果该插入的chunk存在对应堆头,则插入到该堆头的下一个结点,否则的话该chunk会成为堆头插入到链表中。
对于largebin的申请,通过判断双链表的第一个结点(最大结点)的大小来判断是否存在满足的堆块,如果有则从小到大通过bk_nextsize反向遍历双链表,找到最小的满足申请需求的堆块,如果该堆头下一个结点的大小也满足则将该结点作为目标分配给用户,以此减少链表的fd_nextsize与bk_nextsize操作,提高效率。对于双链表的unlink,需要注意的就是fd_nextsize与bk_nextsize检查,特别需要注意的是当结点是堆头的下一个结点时,它的fd_nextsize与bk_nextsize为0,此时unlink操作与smallbin的unlink操作一致,没有fd_nextsize与bk_nextsize的检查与操作。
largebin attack
largebin attack是在largebin双链表的插入与取下的过程中出现问题,导致可以被申请出非预期内存的情形。总的来说存在两种攻击方式:
- 在申请largebin的过程中,伪造largebin的
bk_nextsize,实现非预期内存申请。 - 在largebin插入的过程中,伪造largebin的
bk_nextsize以及bk,实现任意地址写堆地址。
下面结合源码和实例具体看这两种攻击方式。
伪造伪造largebin的bk_nextsize
原理分析
此利用方式是在申请largebin的过程中出现的。回到申请largebin的源码中去看,它先判断当前双链表中存在满足申请需求的堆块(判断第一个堆块的大小),然后通过bk_nextsize反向遍历双链表找到第一个大于申请需求的堆块,申请该堆头对应的堆块。
if ((victim = first (bin)) != bin &&
(unsigned long) (victim->size) >= (unsigned long) (nb)) //判断链表的第一个结点,即最大的chunk是否大于要申请的size
{
victim = victim->bk_nextsize;
while (((unsigned long) (size = chunksize (victim)) <
(unsigned long) (nb))) //从最小的chunk开始,反向遍历 chunk size链表,直到找到第一个大于等于所需chunk大小的chunk退出循环
victim = victim->bk_nextsize; //漏洞点,伪造bk_nextsize
if (victim != last (bin) && victim->size == victim->fd->size) //申请的chunk对应的chunk存在多个结点,则申请相应堆头的下个结点,不申请堆头。
victim = victim->fd;
remainder_size = size - nb;
unlink (av, victim, bck, fwd); //largebin unlink 操作
...
return p;
问题出现在通过bk_nextsize反向遍历双链表的过程,如果能够伪造某个堆头结点中的bk_nextsize,将其指向非预期的内存地址,构造好数据使得非预期内存地址在通过unlink的检查之后,会将该空间返回给用户,最终使得可以申请出非预期的内存。最常见的就是用它来构造overlap chunk。
至于绕过unlink的检查,我认为最好的方式就是伪造的内存空间将fd与bk按照smallbinunlink的利用方式设置,而将bk_nextsize和fd_nextsize设置成0,这样就不会对这两个字段进行操作了。
典型的应用场景为:存在四个堆ABCD,largebin中存在链表A->B,其中A为0x420,B为0x400,C为0x410,C未释放。将B的bk_nextsize伪造指向C,同时将C的fd与bk构造好,将C的fd_nextsize与bk_nextsize赋值为0,当再次申请0x410大小的内存E时,遍历B->bk_nextsize会指向C,且C的大小满足需求,因此会调用unlink将C从双链表取下,因此申请出来的堆块E的地址会为C的地址,即E和C为同一内存块,实现overlap chunk的构造。
实例—lctf2017—2ze4u
题目是经典的菜单题,有创建、编辑、删除、打印四个功能。 漏洞是UAF漏洞,即在删除堆块后并没有将存储指针的全局变量清空,还能够重复的编辑,如何使用这一点拿到shell就是这道题的考点。
首先是泄露堆地址,程序开启了PIE,在输出的时候,输出的位置是从分配堆块的0x18的位置开始的,而正常堆块的fd与bk俩个指针在前0x10字节,因此无法通过常规的泄露fd与bk来得到地址,此时就想要了前面提到过的fd_nextsize和bk_nextsize俩个字段。构造俩个large bin chunk,大小在同一个bins中,将其释放后,此时俩个chunk会被释放到unsorted bin中,再申请一个大小大于这俩个chunk的块,此时这俩个chunk会被放到相应的large bin中,同时fd_nextsize与bk_nextsize会被赋值,指向彼此。因此利用UAF输出即可得到堆块地址。
接着是泄露libc地址,如何泄露libc地址就需要使用largebin attack的姿势构造overlap chunk来进行泄露与利用,利用UAF修改largebin中的bk_nextsize指向伪造的堆的地址,同时将伪造的堆的地址fd与bk赋值,将fd_nextsize与bk_nextsize清0以绕过unlink,最终将伪造的堆块申请出来。使得伪造的largebin中包含smallbin,释放两个同大小的smallbin,利用smallbin的申请来绕过输入0的截断,最终泄露出libc地址。
最终的利用则是利用fastbin attack将top chunk指向__free_hook-0xb58,然后修改__free_hook为system地址,再次触发free拿到shell。
伪造largebin的bk_nextsize以及bk
原理分析
此利用方式是在将unsorted bin中的chunk取下插入到largebin中出现的。回到largebin形成的代码中,关键代码如下:
...//将largebin从unsorted bin中取下
unsorted_chunks (av)->bk = bck;
bck->fd = unsorted_chunks (av);
...
//否则这个chunk将会成为堆头,`bk_nextsize`和`fd_nextsize`将被置位
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize; //由于fwd->bk_nextsize可控,因此victim->bk_nextsize可控
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim; //victim->bk_nextsize可控,因此实现了往任意地址写victim的能力
}
bck = fwd->bk; //由于fwd->bk可控,因此bck可控
...
mark_bin (av, victim_index);
//设置fd与bk完成插入
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim; //bck可控,因此实现了往任意地址写victim的能力
...
}
该攻击方式可实现两次往任意的地址写堆地址的能力,设任意地址为evil_addr,问题出现在当前的largebin插入为堆头的过程,在此过程中假设我们可控largebin中的bk_nextsize与bk。
一次是:控制fwd->bk_nextsize指向evil_addr-0x20。执行完victim->bk_nextsize = fwd->bk_nextsize后,victim->bk_nextsize也为evil_addr-0x20,接着执行victim->bk_nextsize->fd_nextsize = victim即实现了往evil_addr-0x20->fd_nextsize写victim,即往evil_addr写victim地址。关键两行代码如下:
victim->bk_nextsize = fwd->bk_nextsize; //由于fwd->bk_nextsize可控,因此victim->bk_nextsize可控
...
victim->bk_nextsize->fd_nextsize = victim; //victim->bk_nextsize可控,因此实现了往任意地址写victim的能力
另一次是:控制fwd->bk指向evil_addr-0x10,执行完bck = fwd->bk后,bck为evil_addr-0x10,接着执行bck->fd = victim即往evil_addr-0x10->fd写victim,即往evil_addr写victim地址。关键两行代码如下:
bck = fwd->bk; //由于fwd->bk可控,因此bck可控
...
bck->fd = victim; //bck可控,因此实现了往任意地址写victim的能力
这样利用伪造在largebin中的bk_nextsize与bk,我们获得了两次任意地址写堆地址的能力。
至于往何处写,一个比较好的目标是写global_max_fast,使得可以将其覆盖成很大的值,具体如何利用可以参考堆中global_max_fast相关利用。
house of storm
利用伪造在largebin中的bk_nextsize与bk,我们获得了两次任意地址写堆地址的能力。除了覆盖global_max_fast之外,另一种用法则是house-of-storm,与unsorted bin attack的结合可以使得该利用方法变成任意可以内存申请的攻击方式。
A=malloc(0x400-0x10) //A
malloc(0x10) //gap
B=malloc(0x420-0x10) //B
malloc(0x10) //gap
free(A) //free A into unsorted bin.
malloc(0x500) //sort A into largebin.
free(B) //free B into unsorted bin.
A+0x18=evil_addr-0x20+8-5 //A->bk_nextsize=evil_addr-0x20+8-5.
A+0x8=evil_addr+8 //A->bk=evil_addr+8.
B+0x8=evil_addr //B->bk=evil_addr
malloc(0x48) //evil_addr are malloced out here.
攻击代码场景如上所示,设我们想要申请的内存地址(如__free_hook)为evil_addr。攻击之前我们在largebin中布置一个堆块A,在unsorted bin中布置一个堆块B,其中B的size大于A的size,这样在插入到largebin时才会触发相应代码。
如上所示,我们将A的bk_nextsize改成了evil_addr-0x20+8-5,将A的bk改成了evil_addr+8,且将B的bk改成了evil_addr。
当执行malloc(0x48)时,程序会遍历unsorted bin并将unsorted bin中的chunk取下插入到相应的块中,首先将B取下,此时unsorted bin attack触发,B的bk指向evil_addr,将B从unsorted bin中取下之后,unsorted bin的bk指向了evil_addr。
bck = victim->bk; 伪造该bk指向`evil_addr`
...
unsorted_chunks (av)->bk = bck; //unsorted -> bk指向evil_addr
bck->fd = unsorted_chunks (av);
接着就是把B插入到相应的largebin 链表中,在开启PIE的程序中,堆地址一般为0x56或0x55开头。因此我们可以利用一次写堆地址的能力往evil_addr+0x8-5的地址写堆的地址,使得该地址的size位为0x55或0x56。接着利用另一次写堆地址的能力往evil_addr+0x18的地址写堆的地址,使得该地址的bk位为堆地址,形成了如下的chunk:
heap &__free_hook
$1={
prev_size = xxxxxxxxxx,
size = 0x56,
fd = 0x0,
bk = 0x56xxxxxxxxxxxx,
fd_nextsize = 0,
bk_nextsize = 0
}
再次调用for循环取下unsorted bin时,就会取出evil_addr,且此时的evil_addr->bk为堆地址,因此可以绕过bck->fd = unsorted_chunks (av)限制,而evil_addr的大小刚好为0x56或0x55,为0x48所对应的size,所以就会被申请出来,实现了任意可写地址申请。
house of storm是一个任意可写地址申请漏洞。利用largebin两次写堆地址伪造出来了一个堆块,同时利用unsorted bin attack将该伪造的堆块链接到unsorted bin中,实现任意地址申请,非常的巧妙。
实例—0ctf2018—heapstorm2
程序提供了申请、编辑、释放、打印的功能,且打印只有在满足一定条件的情况下才会进行,默认时无法进行打印的。程序调用了mallopt(1, 0)使得程序没有fastbin,且通过mmap出来的内存地址0x13370800管理堆块,漏洞只有在编辑函数中存在一个off-by-null的漏洞。
可以使用off-by-null漏洞构造overlap chunk,但是无法泄露地址,只有一个已知的地址0x13370800,因此可以利用house of storm实现任意地址申请,将0x13370800申请出来,将该处内存块申请出来以后,我们就可以修改相应数据来实现可以打印,后续也可修改指针来实现任意地址读写,最后修改__free_hook为system拿到shell。
有一点需要注意的是程序使用的calloc申请的内存,其中存在以下一段代码,要求程序chunk_is_mmapped,其定义为#define chunk_is_mmapped(p) ((p)->mchunk_size & IS_MMAPPED),#define IS_MMAPPED 0x2,因此伪造的堆的地址只能为0x56,而不能为0x55。因此exp可能需要多跑几次才会成功。
mem = _int_malloc (av, sz);
assert (!mem || chunk_is_mmapped (mem2chunk (mem)) ||
av == arena_for_chunk (mem2chunk (mem)));
实例—rctf2019—babyheap
这题当时比赛的时候我用的是unsoted bin attack改写的global_max_fast,当时也做出来了,但是步骤会复杂很多,使用house of storm就会简单不少。
程序提供了申请、编辑、释放、打印的功能,使用了mmap的内存来管理堆块。同时调用了prctl使得无法调用execve相关的系统调用,即无法get shell。程序在编辑函数中存在off-by-null漏洞。
可以使用off-by-null漏洞构造overlap chunk,可以利用overlap chunk来泄露堆地址以及libc地址。如果可以get shell的话,只需要unsorted bin attack覆盖global_max_fast,然后fastbin attack把__malloc_hook申请出来,然后get shell就可以了。
但是由于无法get shell,必须要ROP或者shellcode去读flag才行。因此使用的方法是使用house of storm把__free_hook申请出来,然后修改__free_hook为setcontext+53(为什么要+53,因为存在fldenv [rcx],要求rcx可写),同时将堆块赋值为ucontext_t结构(使用pwntools的SigreturnFrame即可),将ucontext_t结构设置为如下内容:
frame = SigreturnFrame()
frame.rdi=heap_base&0xfffffffffffff000
frame.rsi=0x1000
frame.rdx=7
frame.rip=mprotect_addr
frame.rsp=heap_addr+len(str(frame))
调用free去执行setcontext,最终调用mprotect将堆地址改为可执行,同时将栈迁移到了堆上,最终执行shellcode去读flag。
小结
本文首先介绍了largebin的管理机制,对largebin的形成与分配进行了介绍。而后对largebin attack的两种攻击方式进行了相应的阐述并结合题目对攻击原理进行了实践。
伪造largebin的bk_nextsize可以申请出非预期的内存,但是需要在非预期的内存中构造好数据以绕过基本的size检查以及unlink检查。而利用largebin的插入过程可以往任意的两个地址写堆地址,结合unsorted bin attack形成的house of storm可以实现任意可写地址的申请,威力更是强大。
阅读代码对漏洞的原理了解帮助很大,没事还是多读代码吧。
相关文件以及脚本链接