
一、摘要
现在iot安全已经是一个热点了,嵌入式设备固件的逆向分析也成了师傅们比较关心的一个话题。
如果是普通的可执行文件,或者是动态链接库文件(例如路由器安全研究的情形下我们拿到了完整的文件系统),它们都是标准的二进制格式(比如elf),丢进IDA后,IDA就把工作统统给我们做好了。
但是有的时候我们拿到的固件压根就不是标准的二进制格式,IDA不知道它的架构和指令集。架构可以通过查芯片文档得知,因此我们可以在IDA最初的配置界面选择对应的反汇编处理器,但是问题是IDA并不知道固件的加载基址,也就无法建立正确的交叉引用,我们再逆起来就会很砍脑壳。
我们要做的就是尝试编写一个工具来自动判定固件的加载基址。咱们就针对32bit小端序的ARM固件来聊一下。
二、原理
用的原理是北京理工大学朱瑞瑾博士的论文《arm设备固件装载基址定位的研究》第三章介绍的方法,并在其基础上做了一些改进和优化。
这篇论文个人感觉写的蛮好的,第三章介绍的方法是基于函数入口表的基址定位方法,这个北理的师傅在论文里讲的已经很详细了,因此我们下面就简单的概括一下就好:
(1)基本思路
首先什么是个函数入口表呢?就我个人的理解,这是论文里自己定义的一个概念,其实说白了就是把一堆函数的内存地址(绝对地址,不是相对偏移)放了个表里,或者是放了一个结构体数组中各结构体的某个固定成员变量中。这种例子其实我们很熟悉,比如GOT表中的函数地址、中断向量表中的函数地址,都是这样存储的。
嵌入式设备的ARM固件中就有很多这种入口表,虽然里面的函数地址不一定全都是“很漂亮的函数”,但是很大一部分都是“很漂亮的函数”。漂亮的函数意思就是它的汇编代码的前几条指令,是典型的规范的序言指令,在x86架构下是push ebp/mov ebp,esp,在arm架构下,arm模式常常是STMFD,thumb模式常常是PUSH,这个如果有什么疑问百度了解一下ARM指令集即可。
值得注意的是,入口表放的是绝对地址啊。也就是说如果加载基址错误,那表中地址跳过去第一条指令大概率就不会是STMFD或PUSH。
那反过来想,如果说我们先假设一个加载基址,然后按入口表中的地址去看对应位置的第一条指令,如果入口表中大部分的地址的第一条指令都正好是STMFD或PUSH,那就说明这个假设的加载基址很可能就是正确的基址。
这样已经得到了一个猜测疑似基址的手段,那如果一个入口表在用多个假设基址去判断的时候,发现出现了多个疑似基址,那该选哪一个呢?论文给的解决方法是,用所有的入口表挨个去找疑似基址,然后比比在各个入口表找到的疑似基址中,哪个基址出现的最多,哪个就是我们要的。
(2)具体实施方法
基本思路中抛出了两个我们需要解决的问题:1、怎么得到咱们要的入口表 2、怎么去匹配序言指令
1、找入口表
论文设计了一个FIND-FET算法,不是很难。原理就是定了三条规则,满足三条规则就认为这是个入口表。
规则一:根据统计分析,一个入口表中的入口地址分布都比较紧凑,因此我们给一个地址差的范围,最高地址和最低地址差值应当小于一个界限。
规则二:地址不能重复(这个不用多说,很显然)
规则三:地址应当是4的整数倍或奇数,因为ARM模式指令地址是4的整数倍,THUMB模式指令地址是奇数。
注意:pc寄存器置值后,会判断最低位是否为1,为1则表示开启thumb模式,因此存的函数地址是奇数,但是存对应指令的地址还是偶数的(奇数减1)。
具体算法是用了滑动窗口,两个参数wnd和gap_max分别表示窗口大小(表项数)和一个表项中除了函数地址外剩余成员变量的最大个数(也就是两个函数地址间的最大间隔数)。
从头遍历偏移作为窗口起始地址,定下窗口起始地址后依次尝试gap为0~gap_max,然后判定窗口是否符合三个规则,不符合就增加gap再试,符合就滑动窗口找出一个完整的入口表。找到一个入口表后,就把偏移的遍历位置设到找出的表后面的位置,继续遍历寻找。
2、匹配序言
先对入口表都排序去重,假设最小值为fet[0]最大为fet[n-1],那么加载基址显然位于fet[n-1]-file_size ~ fet[0]这个范围内,然后就遍历这个范围内的每个值作为假设的基址base,入口地址 – base就得到一个文件偏移,然后读文件相应偏移处的hex来判断是不是STMFD和PUSH的机器码。
注意:1.奇数匹配thumb的push,偶数匹配arm的stmfd 2.上面说过了,thumb时入口表中地址值是奇数,但是存储指令的实际地址是偶数,别忘了考虑上。
push机器码第二个字节是0xb5,stmfd机器码的二三字节是0x2d和0xe9
三、改进和优化
按照原文中的方法设计出来,在具体运行的时候还是有诸多局限性,我们对以下方面做了优化:
· 滑动窗口遍历机制
· 候选基址的选择
· 入口地址紧凑度
· 候选基址遍历范围
(1)滑动窗口遍历机制:粗糙模式/精细模式
原文中,如果一个滑动窗口匹配上了三条规则,并滑动至三条规则匹配失败为止,就算找出一个完整的入口表了。
而当找出一个完整的入口表后,按原文给出的算法,将不再尝试其它gap值,并且,找下一个入口表时,用的滑动窗口的起始地址也是直接移动到了刚刚找出的表的后面,而不再尝试其之间的文件偏移位置。
而我自己做实测的时候发现,这样做会造成遗漏。这种遗漏在固件二进制文件较小时,非常容易造成最终判断结果的错误。
因此我在实现时做了修改,修改后仍会尝试未尝试的gap值和未尝试的文件偏移,效果更加精确。
但是这样改动的同时用时也会剧增,因此最终方案是设置了一个开关参数来由调用者决定扫描模式。
(2)候选基址的选择:简洁模式
实际上,多数固件加载基址的第三位hex一般都是0,也就是以000结尾,而原算法会一股脑全部输出。
改动后调用者可以选择开启简洁模式,只扫描000结尾的候选基址,初次扫描建议开启这个选项。
(3)入口地址紧凑度
即规则一中的差值界限。论文推荐的值是0x10000,我改成了0x1000,感觉效果更好一点。
(4)候选基址遍历范围
论文中遍历范围是fet[n-1]-file_size ~ fet[0],这个扫描范围是从fet[n-1]-file_size开始的。
但是实际实验中发现,有很大一部分情况下fet[n-1]-file_size为负值,这显然是不合理的,会使无用的耗时剧增,还可能会造成内存泄露(这倒还好,主要C可以负索引,但是换了别的语言可能要抛异常)。我的改进是判定为负时改为从0偏移开始扫。
此外,我们新增了一个boot模式,或者叫上电模式。Cortex-M/R核心的arm固件有一个特性,0偏移位置的dword是SP上电值,4偏移位置的dword则是PC寄存器的上电值,也就是上电后执行的第一条指令的地址。显然,加载基址是不可能大于这个值的。因此我们增加了boot模式,在能预先人工确定这个上电值的情况下可以使用这个模式,此时遍历范围的最大值将取min(pc_boot_value , fet[0]),以缩短遍历用时。
四、工具的开发实现
我用的是C语言做的实现,代码量不大,不到200行。下面是关键的几个函数:
1、找入口表
PFET find_fet(char * bin, int start, int filesize, int wnd, int gap_max) {
int pos = start;
int end = start + filesize;
int gap,
head,
table_size,
off;
PFET fet_list = (PFET) malloc(sizeof(FET));
fet_list - >next = NULL;
PFET fet_l_ptr = fet_list;
while (pos >= start && pos < end) {
for (gap = 0; gap <= gap_max; gap++) {
off = 0;
if (rule_match(bin, pos, off, gap, wnd)) {
head = pos;
table_size = wnd;
off += wnd;
while (rule_match(bin, pos, off, gap, wnd)) {
table_size += wnd;
off += wnd;
}
if (F_ROUGH == 1) pos += table_size * (gap + 1) * 4 - 1; //CTL2.1: 粗略模式
fet_l_ptr - >next = (PFET) malloc(sizeof(FET));
fet_l_ptr = fet_l_ptr - >next;
fet_l_ptr - >head = head;
fet_l_ptr - >gap = gap;
fet_l_ptr - >table_size = table_size;
fet_l_ptr - >next = NULL;
if (F_ROUGH == 1) break; //CTL2.2: 粗略模式
}
}
pos++;
}
return fet_list;
}2、匹配/输出加载基址(非boot模式)
void dbmfet(char * bin, int filesize, pone_tbl tbl, float T) {
int n = tbl - >num;
unsigned int * tb = tbl - >addr;
unsigned int guess_base;
int i,
start;
int thumb = 0,
arm = 0;
int debug = 0;
if (tb[n - 1] < (unsigned int) filesize) {
start = 0;
} else {
start = tb[n - 1] - filesize;
}
for (guess_base = start; guess_base <= tb[0]; guess_base++) { //CTL3: 非上电模式
if (guess_base % 0x1000 == 0 || F_CLEAR == 0) { //CTL4: 简洁模式
for (i = 0; i < n; i++) {
if (tb[i] % 2 == 1) {
if (bin[tb[i] - guess_base] == (char) 0xb5) thumb++;
} else {
if (bin[tb[i] - guess_base + 2] == (char) 0x2d && bin[tb[i] - guess_base + 3] == (char) 0xe9) arm++;
}
}
if (((float) arm + (float) thumb) / (float) n > T) printf("OUTPUT: %p========%fn", guess_base, ((float) arm + (float) thumb) / (float) n);
thumb = 0,
arm = 0;
}
}
}3、匹配/输出加载基址(boot模式)
void dbmfet_boot(char * bin, int filesize, pone_tbl tbl, float T, unsigned int boot_pc) {
int n = tbl - >num;
unsigned int * tb = tbl - >addr;
unsigned int guess_base;
int i,
start;
int thumb = 0,
arm = 0;
int debug = 0;
if (tb[n - 1] < (unsigned int) filesize) {
start = 0;
} else {
start = tb[n - 1] - filesize;
}
for (guess_base = start; guess_base <= (boot_pc <= tb[0] ? boot_pc: tb[0]); guess_base++) { //CTL3: 上电模式
if (guess_base % 0x1000 == 0 || F_CLEAR == 0) { //CTL4: 简洁模式
for (i = 0; i < n; i++) {
if (tb[i] % 2 == 1) {
if (bin[tb[i] - guess_base] == (char) 0xb5) thumb++;
} else {
if (bin[tb[i] - guess_base + 2] == (char) 0x2d && bin[tb[i] - guess_base + 3] == (char) 0xe9) arm++;
}
}
if (((float) arm + (float) thumb) / (float) n > T) printf("OUTPUT: %p========%fn", guess_base, ((float) arm + (float) thumb) / (float) n);
thumb = 0,
arm = 0;
}
}
}4、主函数
void find_load_base(char * filename, int wnd, int gap, float T, unsigned int f_gap_m, int f_rough, unsigned int boot, int f_clear) {
F_GAP_MAX = f_gap_m;
F_ROUGH = f_rough;
F_CLEAR = f_clear;
FILE * fid = fopen(filename, "rb");
fseek(fid, 0, SEEK_END);
long size = ftell(fid);
rewind(fid);
char * bin = (char * ) malloc(size + 1);
fread(bin, 1, size, fid);
PFET fet = find_fet(bin, 0, size, wnd, gap); //CTL5: 窗口 和 gap PFET ptr = fet->next; pone_tbl p_tbl; int i=0,j; do{ p_tbl = get_tbl(bin,ptr); if (boot == 0) dbmfet(bin,size,p_tbl,T); //CTL6: 阈值 else dbmfet_boot(bin,size,p_tbl,T,boot); //CTL6: 阈值 free(p_tbl->addr); free(p_tbl); ptr = ptr->next; i++; }while(ptr); printf("%dn", i); puts("end"); }
其他工作:
弄了dll,最开始想用swig转成python库,转的时候崩了。。。
最后用的ctypes导的dll,弄了个python模块。。GitHub链接放文末了。
五、工具运行测试
Ⅰ. 扫描论文中给的固件
论文作者测试用的固件有16个,我找的好苦,16个我一共找到两个懒得再找了
1、Sony SBH52固件
该固件就符合boot模式的要求,在ida中是这样:
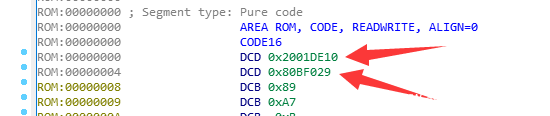
可见芯片上电时PC寄存器的初始值为0x80bf029,因此我们:
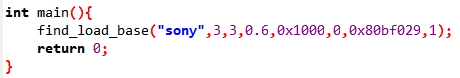
运行结果如下:
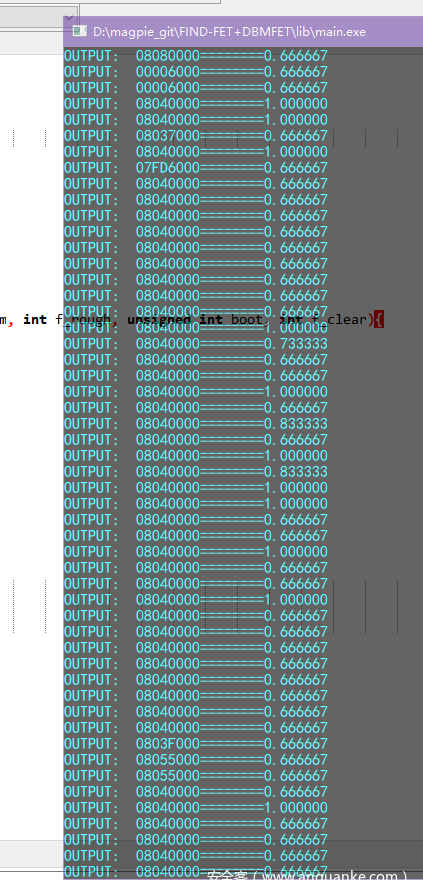
可见基址为0x8040000(上千个结果,但是往下翻也是这个画风),与论文中的正确结果一致。
2、iAudio 10 MP3固件
该固件不符合boot模式要求。而且体积较大,因此我们开启粗糙模式,并将匹配率阈值设为0.9:

运行结果如下:
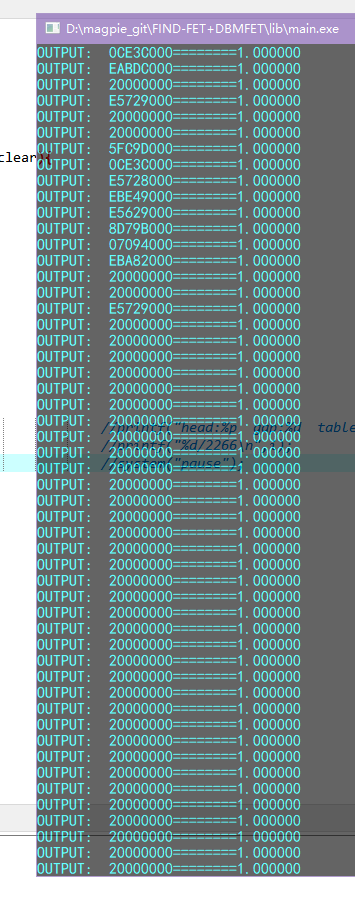
可见,固件加载基址为0x20000000,与论文中的正确结果一致。
Ⅱ.扫描其他文件
我自个儿找了俩文件,都是ida自己能处理的标准elf文件,好像都是路由器里的程序:
第一个:

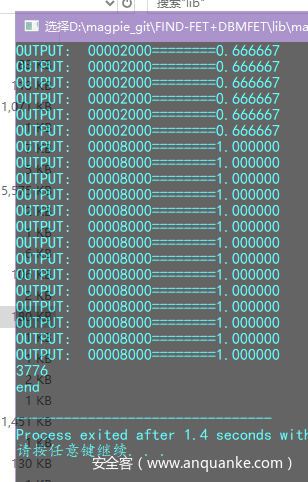
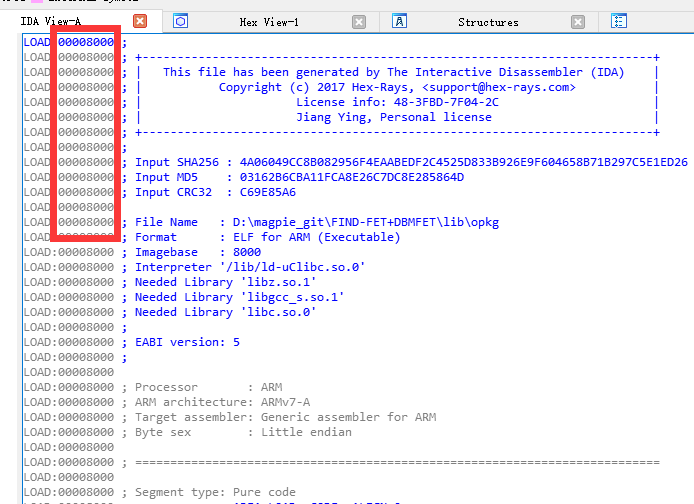
判定的基址为0x8000,载入ida确认:
第二个:

文件体积太小,匹配阈值0.6扫不出来,所以改成了0.3:
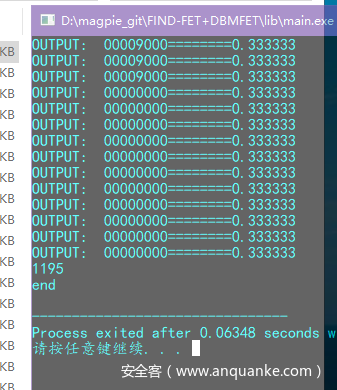
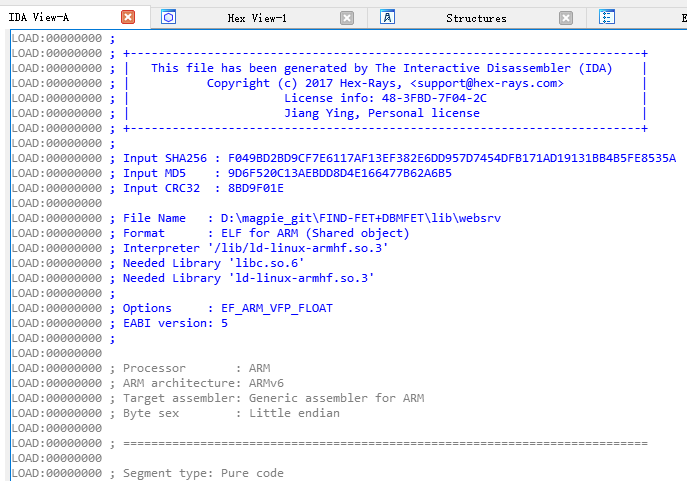
可见,加载基址就是0,丢ida验证:
后来又试了好几个elf,就一个失败了,失败的那个elf应该是因为太小了,只有10KB…
所以说大一点的文件效果会好一点,这也是统计特性决定的。