
在本文中,我们将讨论创建和访问数据的方式可能对应用程序性能的影响。
介绍
JavaScript是一种非常高级的语言,在使用JavaScript开发的时候不必对存储器中的数据存储方式作过多的考虑。在本文中,我们将探讨数据如何存储在内存中,以及JavaScript中分发和访问数据的方式将如何影响CPU和内存的性能。
浪漫三角
当计算机需要进行一些计算任务时,计算机处理单元(CPU)需要数据进行处理,因此,根据手中的任务,它将发送请求到内存以通过总线获取待处理的数据,就像下面这样:
这就是我们的浪漫三角
CPU->总线->内存
浪漫三角需要第四个元素来保持稳定
由于CPU比内存快得多,因此从CPU->总线->内存->总线->CPU这样的处理方式就浪费了很多计算时间,因为查找内存时,CPU处于空闲状态而无法执行其他操作。
缓存的出现有效的缓解了这个问题。在本文中我们不会详细讨论缓存的技术细节和类型,我们只需要知道缓存可以作为CPU的一个内部存储空间。
当CPU接收到要运行的命令时,它将首先在高速缓存中搜索目标数据,如果没有搜索到目标数据,它再通过总线发起请求。
然后,总线将请求的数据加上一部分内存,将其存储在高速缓存中以供CPU快速调用。
这样一来,CPU就能够有效的处理数据,而不会浪费时间等待内存返回。
高速缓存的引用也可能导致新的问题
基于上面的架构,我们在处理大量数据时可能会出现一种名为”高速缓存未命中”的错误。
高速缓存未命中意味着在计算期间,CPU发现高速缓存中没有必要的数据,因此需要通过常规通道(即已知的慢速存储器)来请求此数据。
上图是一个很好的实例,在处理组中数据是,由于计算的数据超出了缓存限制的数据,就导致了缓存未命中。
可是这跟我作为JavaScript程序员有什么关系呢?
好问题,大多数情况下,我们JavaScript开发人员不必关心这个问题。但是随着越来越多的数据涌入Node.js服务器甚至富客户端,所以当使用JavaScript遍历大型数据集时就容易遇见缓存未命中的问题。
一个经典的例子
接下来让我们以一个例子作为说明。
这是一个叫做Boom的类:
class Boom {
constructor(id) {
this.id = id;
}
setPosition(x, y) {
this.x = x;
this.y = y;
}
}
此类(Boom)仅具有3个属性:id,x和y。
现在,让我们创建一个填充x和y的方法。
让我们构建设置:
const ROWS = 1000;
const COLS = 1000;
const repeats = 100;
const arr = new Array(ROWS * COLS).fill(0).map((a, i) => new Boom(i));
现在,我们将在一种方法中使用此设置:
function localAccess() {
for (let i = 0; i < ROWS; i++) {
for (let j = 0; j < COLS; j++) {
arr[i * ROWS + j].x = 0;
}
}
}
本地访问的作用是线性遍历数组并将x设置为0。
如果我们重复执行此功能100次(请查看设置中的重复常数),则可以测量运行时间:
function repeat(cb, type) {
console.log(`%c Started data ${type}`, 'color: red');
const start = performance.now();
for (let i = 0; i < repeats; i++) {
cb();
}
const end = performance.now();
console.log('Finished data locality test run in ', ((end - start) / 1000).toFixed(4), ' seconds');
return end - start;
}
repeat(localAccess, 'Local');
日志输出是这样的:
丢失缓存要付出的代价
现在,根据上面的了解,如果我们处理迭代过程中距离较远的数据,则会导致缓存丢失。远处的数据是不在相邻索引中的数据,如下所示:
function farAccess() {
for (let i = 0; i < COLS; i++) {
for (let j = 0; j < ROWS; j++) {
arr[j * ROWS + i].x = 0;
}
}
}
在这里发生的是,在每次迭代中,我们都处理上次迭代距ROWS的索引。因此,如果ROWS为1000(在我们的例子中),我们将得到以下迭代:[0,1000,2000,…,1,1001,2001,…]。
让我们将其添加到速度测试中:
repeat(localAccess, 'Local');
setTimeout(() => {
repeat(farAccess, 'Non Local');
}, 2000);
这是最终结果:
非本地迭代速度几乎慢了4倍。随着数据量的增加,这种差异将越来越大。发生这种情况的原因是由于高速缓存未命中,CPU处于空闲状态。
那么您要付出的代价是什么?这完全取决于您的数据大小。
好吧,我发誓我永远不会那样做!
您通常可能不这么认为,但在某些情况下,您可能会希望使用非线性(例如1,2,3,4,5)或非偶然性。比如( for (let i = 0; i < n; i+=1000))
例如,您从服务或数据库中获取数据,并需要通过某种复杂的逻辑对数据进行排序或过滤。这可能导致访问数据的方式与farAccess函数中显示的方式类似。
如下所示:
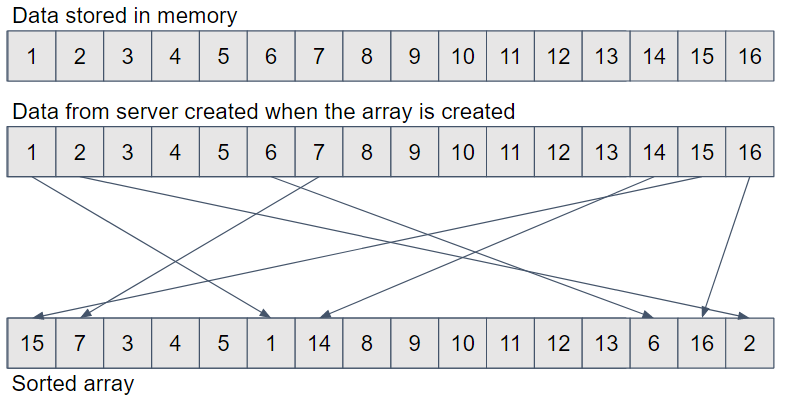
查看上图,我们看到了存储在内存中的数据(顶部灰色条)。在下面,我们看到了当数据从服务器到达时创建的数组。最后,我们看到排序后的数组,其中包含对存储在内存中各个位置的对象的引用。
这样,对排序后的数组进行迭代可能会导致在上面的示例中看到的多个缓存未命中。
请注意,此示例适用于小型阵列。高速缓存未命中与更大的数据有关。
在当今世界中,您需要在前端使用精美的动画,并且可以在后端(无服务器或其他服务器)中为CPU的每毫秒时间计费(这很关键)。
不好了!都没了!!!

并不是,有多种解决方案可以解决此问题,现在您已经知道造成性能下降的原因,您可以自己考虑解决方案。比如只需要将处理在一起的数据更紧密地存储在内存中。
这种技术称为数据局部性设计模式。
让我们继续我们的例子。假设在我们的应用程序中,最常见的过程是使用farAccess函数中显示的逻辑来遍历数据。我们希望对数据进行优化,以使其在最常见的for循环中快速运行。
我们将像这样排列相同的数据:
const diffArr = new Array(ROWS * COLS).fill(0);
for (let col = 0; col < COLS; col++) {
for (let row = 0; row < ROWS; row++) {
diffArr[row * ROWS + col] = arr[col * COLS + row];
}
}
所以现在在diffArr中,原始数组中索引为[0,1,2,…]的对象现在被设置为[0,1000,2000,…,1,1001,2001,…,2, 1002,2002,…]。数字表示对象的索引。这模拟了对数组进行排序的方法,这是实现数据局部性设计模式的一种方法。
为了方便测试,我们将稍微更改farAccess函数以获得一个自定义数组:
function farAccess(array) {
let data = arr;
if (array) {
data = array;
}
for (let i = 0; i < COLS; i++) {
for (let j = 0; j < ROWS; j++) {
data[j * ROWS + i].x = 0;
}
}
}
现在将场景添加到我们的测试中:
repeat(localAccess, 'Local');
setTimeout(() => {
repeat(farAccess, 'Non Local')
setTimeout(() => {
repeat(() => farAccess(diffArr), 'Non Local Sorted')
}, 2000);
}, 2000);
我们运行它,我们得到:
我们已经优化了数据,以适应需要查看的更常见的方式。
完整示例参见https://yonatankra.com/performance/memory/liveExamples/objectPool2/index.html
摘要
在本文中,我们演示了数据局部性设计模式。从本质上讲,我们表明以未优化的方式访问数据结构可能会降低性能。然后,我们优化了数据以适合我们的处理方式-并且看到了它如何提高性能。
数据局部性设计模式曾经是游戏开发人员的领域,他们必须处理许多需要多次迭代的实体。在上面的结果中,我们看到即使在像JavaScript这样的高级语言中,数据局部性仍然很重要-不仅在游戏中。
如今,随着大量数据在服务器之间传输,甚至被推送到浏览器中,应用程序开发人员应考虑曾经是游戏开发人员日常工作的设计模式-服务器端还是客户端。