
“…他要把羊分别出来,好像牧人把绵羊和山羊分别出来一样…” 马太福音25:32 (Douay-Rheims版)
1. 引文
我们可以根据许多不同的分类法来分割被动DNS流量中看到的域名。例如:
- 传统ICANN的通用顶级域(gTLDs)与国家顶级域(ccTLDs)与新的通用顶级域(new gTLDs)
- 传统的LDH(字母/数字/连字符)等仅含ascii字符的域名与国际化域名
- 最近第一次看到的域名与建立很久的使用频繁的域名
今天我们将探讨一种不同的域名分类方法:
- 有常规或真正语义的域名:这些域名被人手动创建,通常指的是一个地点、一个企业、一个产品或服务、一个爱好或运动、一个表演者或乐队、或其他一些定义完整的人/地方/事/概念,通常表现为“可辨认的字”域名的一部分。这些域名通常相对较短,容易记住并输入到浏览器中。它们通常被购买用于可预见的未来,或至少多年的使用。我们现在对这些普通或真实的域名不感兴趣。
- 散列的DNSSEC相关的伪域名:我们对第二类伪域名也不感兴趣,它们是与DNSSEC NSEC3/RRSIG记录相关联的看似随机的域名,实际上它们是与其他域名相关联的散列值。
- 例如:
- $ dnsdbq -r 0vkcr4bccrjhivmsodse7h90d9ns9851.com/RRSIG -A1d -l 1
;; record times: 2019-03-16 05:19:46 .. 2019-03-20 05:20:42
;; count: 6593; bailiwick: com.
0vkcr4bccrjhivmsodse7h90d9ns9851.com. RRSIG NSEC3 8 2 86400 1553318330 1552709330 16883 com. fCRQh2uMY29qtm75l5t3lTjnTLMxjP2ptz2OX6oZImHW+hkKmJvK4B+9 pSZHtudReziEUmkJnUKl6ZLLe07nSTXRxcNvkjM5rImW7eQH9rkpv2cd I0ajdLESUrkisB4zWrBJvDWXKyR1SGTtdftXcInPHn23Exd/flaR1WcK 6hk= - 虽然这是一个真正的RRSIG记录,但是在被动DNS中你不会找到对应的a/AAAA/CNAME记录,在Whois中也不会找到任何记录。我们今天对散列的NSEC3/RRSIG域名不感兴趣。
- 长的类随机算法域名:我们对第三类域名感兴趣——它们是合成域名,通常通过计算机算法生成,而不是由人或DNSSEC相关操作的结果造成的一对二的情况。
- 这些算法或合成域名比普通域名长,看起来是随机的,由字母和数字排列成不太可能的组合构成,这通常是人类不可能记住的,这对于常规地手工输入到web浏览器或其他客户机中是非常乏味的。
- 要注意的是,我们讨论的不是完全限定域名,其预期要注册的域名除了前面有一个奇怪的主机名之外看起来比较正常。我们感兴趣的是非DNSSEC相关的但看起来随机的情况,这些域名是即将会被注册的域名。这些名称可能是为了使用而注册,也可能是为了防止其他人(如僵尸主机)注册和使用这些域名而预先注册的。也就是说,我们不会深入探讨算法域名为什么而创建。今天,我们的重点是在远视(Farsight Security, Inc)的安全信息交换系统(Security Information Exchange,SIE)的204频道的流量中找到这些域名。
- 其他域名:还有一些其他的域名不符合上述三个类别中的任何一个,我们将这个剩余类别称为其他类别。一个例子是通过将多个英语单词连接在一起来创建的算法域名,如:scuba-snowshovel-saute-snapdraggon.com。
2. 超越“我们看到他们的时候才知道他们”
当涉及到识别算法域名时,大多数分析师一看到它们就知道它们是什么。如果你只是浏览一个很短的域名列表,还是可以的,但是当你面对成千上万的候选域名时,就无法处理了。需要一种检测算法来实现流程的自动化。类随机的域名通常不包括可读的英语单词。因此,发现算法域名的一个启发式方法的核心是寻找包含零嵌入式英语单词的域名。
很明显,在使用这种经验法则时,我们将忽略其他可想到的算法域名类型,比如我们刚才提到的的scuba- snowshovel-sautesnapdraggon.com域名。这种域名虽然是算法域名,但显然不能被我们的域名中没有英文单词的启发式算法检测到。我们可以创建另一种启发式方法,它将能够识别由英语单词连接在一起创建的域名,但现在,我们只关注不包含英语单词的随机算法域,而忽略其他构造算法的算法域名。
我们可以进一步细化我们的启发式算法的核心。例如:
- 算法域名通常比普通域名长。因此,我们可以考虑排除长度小于6、7或8的域名。
- 算法域名通常具有异常高的香农熵(可能为3.5+)。这里需要非常小心,我们可能会排除那些香农熵很低的算法域名。
- 算法域名的字母、数字和破折号的分布也可能有异常,比如远超正常数量的数字或破折号。
我们将在本文后面探讨其中的一些内容。
我们还应该认识到,围绕用于检测域名生成算法(DGAs)的算法已经进行了大量正式的学术研究。我们无意与那些正式的工作竞争,也无意将我们发现的域名与特定的DGA联系起来。
相反,我们今天的目标只是演示一种实用的方法,在真实的流量中寻找类算法域名,如远视(Farsight Security, Inc)的安全信息交换系统(Security Information Exchange,SIE)的204频道的流量。
3. 英语单词列表
为了识别嵌入的单词,我们需要一个英语单词的词汇表。英语单词的一个来源是SCOWL( Spell Checker Oriented Word Lists and Friends)。我们将使用web接口来创建实际使用的列表:
图1 – 我们下载单词列表的设置
成功下载我们刚刚创建的列表后,进行解压缩,并检查它包含多少单词:
$ tar xfv SCOWL-wl.tar.gz
$ cd SCOWL-wl
$ wc -l words.txt
123601 words.txt查看word .txt文件中的单词时,我们注意到文件中包含带撇号的单词,还有一些单词(例如专有名词)是混合大小写的。由于域名不能包含带撇号的单词,所以我们删除了所有带撇号的单词。由于域名对大小写不敏感,我们强制所有单词只使用小写字母,从而简化之后的比较。在整理和统一剩下的单词后,我们的单词列表缩减到了大约8.8万字:
$ grep -v "'" words.txt > words2.txt <-- double quote, tick mark, double quote
$ tr '[:upper:]' '[:lower:]' < words2.txt | sort -u > words.txt
$ wc -l words.txt
87881 words.txt据报道,一个典型的20岁美国人知道大约42000个单词,所以我们希望这个列表包括最常用的英语单词。如果这个列表包含的内容太多(或者不足),显然你可以调整web表单中的SCOWL 大小变量,可以得到一个更大或更小的列表,以满足你的偏好。我们还用一组常见的因特网/计算/网络相关的行话术语,以及一组常见的缩写和首字母缩写来补充这个列表。
4. 查找不包含英文单词的域名
除了英语单词列表,我们还需要一个程序来实际查找文本中的单词。尽管我们需要根据自己的独特需求修改算法,但这篇文章还是提供了一个很好的概念起点。为了满足我们的特殊需要,我们的Python程序需要:
- 从<标准输入>中读取一系列域名进行评估
- 根据公共后缀列表(PSL)删除域名的有效顶级域
- 将读入的域名强制转换为小写
- 只检查有效的二级域部分,以获得可识别的单词。 例如,没有有效顶级域的有效二级域。单词的要求长度至少为三个字符,且我们只会将单词列表中的条目视为单词,所以a、an、 at、be、 to等都不会算入单词。
- 最后,我们的输出为:
- 在有效的二级域中发现的可识别的3个字符及以上的单词的数量
- 二级域名的有效二级标签部分的字符长度
- 有效的二级标签
- 有效顶级域标签
- 包含在有效的二级标签(如果存在)中的单词列表
哪些域名可能是超出范围的和需要过滤的?
- 跳过所有流行域名,以避免误报。
- 跳过任何没有二级标签的有效顶级域名(比如tk或 co.uk)。
- 跳过任何国际化域名(例如,包含xn--的域名)。
- 跳过任何ip6.arpa 或in-addr.arpa 域名。
- 跳过任何具有全数字的二级域,例如,00112233445566778899.tk
例如,处理后,在域名bellsouthyahoo.com中发现的单词是:
9, 14, bellsouthyahoo, com, bell, bells, ell, ells, out, sou, south, thy, yahoo
域名bellsouthyahoo.com看起来不像一个随机算法域名,尽管它有14个字符长,但它从二级域中提取了9个可识别的单词。
相比之下,一个名字看起来确实是随机的,且没有发现可识别的单词:
0, 34, aa625d84f1587749c1ab011d6f269f7d64, com
你可以在附录1中看到我们编写的执行这个功能的代码。
5. 防止误报:将流行域名列入白名单
尽管我们希望找到没有英文单词的算法域名,但我们也希望谨慎地避免误报任何流行的真实域名。这样做可以使我们避免大部分潜在的假阳性:
|
|
是算法域名 |
不是算法域名 |
|
检测是算法域名 |
正确的结果 |
假阳性 |
|
检测不是算法域名 |
假阴性 |
正确的结果 |
图2 – 假阳性和假阴性
完整定义的流行域名是位于某个域名排名的前N列表中的域名,比如Alexa的前100万域名、Majestic的前100万域名或Domcop的前1000万域名。
文章Alexa、Majestic和Domcop的百万站点比较很好地列出了如何从这些列表中检索和提取域名。
从这些原始列表中准备一个合并的白名单
- 将这三个列表中的域名简化为它们的有效顶级域
- 使用排序和唯一性组合和删除列表元素
这个组合列表有8650286个域名,我们将把它们定义为豁免,以避免被标记为类随机算法域名。这是否让我们有可能错过一个真正的随机算法域名,而这个域名不知何故也在流行列表中?是的,有这种可能。在这个组合列表中肯定有一些非常随机的域名,但是我们相信防止意外错误的价值超过了拥有假阳性的风险。
6. 构建测试语料库
开发用于查找至少一类算法域名的代码之后,现在需要在一些实际数据(我们的测试语料库)上测试我们的代码和白名单。
为了构建用于初始评估的测试语料库,我们登录到安全信息交换系统(Security Information Exchange, SIE)的服务器,该服务器可以访问204频道。然后,我们使用以下命令提取1000万个RRname和RRtype:
$ time nmsgtool -C ch204 -c 10000000 -J - | jq --unbuffered -r '"\(.message.rrname) \(.message.rrtype)"' > ten-million-domains-to-test.txt因为204频道是一个相当繁忙的频道,所以只花了5分钟多一点的时间来提取这些样本,时间命令报告:
real 5m11.123s
user 6m4.932s
sys 0m29.812s
我们程序的输出包括一个完全限定域名和相关记录类型的列表:
$ more ten-million-domains-to-test.txt
phaodaihotel.com.vn. A
cleancarpetandduct.com. SOA
phaodaihotel.com.vn. NS
cleancarpetandduct.com. NS
imap.klodawaparafia.org. CNAME
app.link. AAAA
villamarisolpego.com. NS
www.synapseresults.com.cdn.cloudflare.net. A
roadvantage.com. SOA
plefbn59gl6bvbdp21haguljb51mbp7c.nl. NSEC3
i6pangjmmi77sn4bt560edcnft2877a7.by. NSEC3
i6pangjmmi77sn4bt560edcnft2877a7.by. RRSIG
plefbn59gl6bvbdp21haguljb51mbp7c.nl. RRSIG
gamamew-org.cf. NS
egauger.com. NS
[etc]注意,在上面的示例中,一些类随机域名实际上是第1节所述的散列的DNSSEC相关记录(NSEC3和RRSIG记录类型)。我们通过以下方式排除NSEC3记录和RRSIG记录:
$ grep -v " NSEC3" ten-million-domains-to-test.txt | grep -v " RRSIG" > ten-million-domains-to-test-without-dnssec.txt
$ wc -l ten-million-domains-to-test-without-dnssec.txt
8573184 ten-million-domains-to-test-without-dnssec.txt出于严谨,有435709条NSEC3记录和991107条RRSIG记录被过滤掉。
我们还将排除国际化域名,国际化域名使用国际化域名编码方式,以xn--开头。我们还将删除以\.arpa\.结尾的域名,这个结尾过滤器用于捕获任何ipv6 .arpa.或in-addr.arpa.条目。我们也可以删除记录类型列,因为我们不再需要它来过滤NSEC3或RRSIG记录:
$ grep -v "xn--" ten-million-domains-to-test-without-dnssec.txt | grep -v "\.arpa\. " | awk '{print $1}' > ten-million-domains-to-test-without-dnssec-idn-or-arpas.txt
$ wc -l ten-million-domains-to-test-without-dnssec-idn-or-arpas.txt
8032040 ten-million-domains-to-test-without-dnssec-idn-or-arpas.txt共有41101个国际化域名和500043个以\.arpa\结尾的域名。
然后,我们将使用一个名为2nd-level-dom-large的流行perl脚本将剩下的域名简化到只有它们的委托点,这些脚本逐个记录地读取和处理这些域名,如www.example.com 变为 example.com。(参见附录2)
$ 2nd-level-dom-large < ten-million-domains-to-test-without-dnssec-idn-or-arpas.txt > ten-million-domains-to-test-2nd-level.txt在删除完全限定域名的主机名部分之后,我们现在可能有重复的条目。我们将通过排序和统一来消除这些重复的域名:
$ sort ten-million-domains-to-test-2nd-level.txt > ten-million-domains-to-test-2nd-level-sorted.txt
$ uniq < ten-million-domains-to-test-2nd-level-sorted.txt >
sorted-and-uniqed-ten-million.txt
$ wc -l sorted-and-uniqed-ten-million.txt
3566037 sorted-and-uniqed-ten-million.txt
7. 在测试语料库中运行程序查找英语单词
我们之后开始准备测试查找单词的程序。附录1中的Python代码被设置为只测试字符长度等于或大于3的英语单词,还进行了一些额外的过滤,详情可以参阅find-words.py代码。这使得我们用于分析的有效域名数减少到只有3131227个域名:
$ ./find-words.py < sorted-and-uniqed-ten-million.txt > ten-million-output.txt
$ gsort -t',' -k1n -k2nr < ten-million-output.txt > sorted-ten-million-output.txt
$ uniq sorted-ten-million-output.txt > sorted-and-uniqed-ten-million-output.txt
$ wc -l sorted-and-uniqed-ten-million-output.txt
3131227 sorted-and-uniqed-ten-million-output.txt仅用有效二级域标签的字符长度度量的3131227个二级域长度的分布如下:
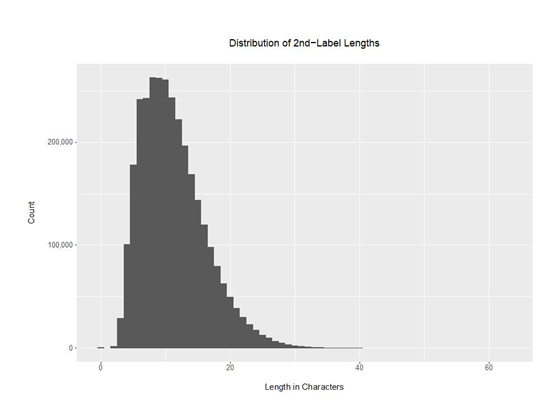
图3 – 二级域长度的分布
用于创建该图形的R程序的脚本可以在附录3中找到。
每个有效的二级域所发现的单词数的分布是衡量单词列表包容性的一个很好的方法。如果我们的单词列表能够很好地捕捉到人们在创建域名时使用的所有单词,那么除了看起来非常随机的垃圾域名,我们应该会看到相对较少的零单词域名。我们还希望,至少在一些域名中能够发现相当多的单词。
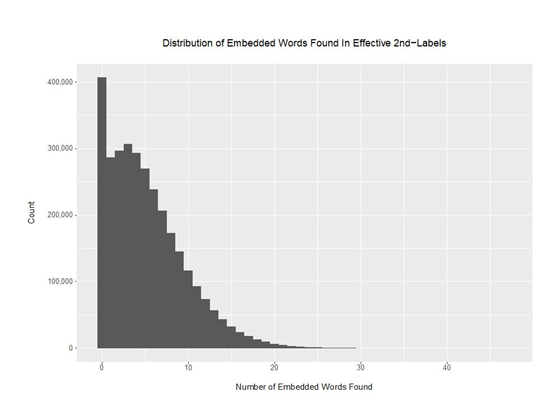
图4 – 在有效的二级域中发现的嵌入单词数量分布
以下是我们从运行的英语单词(English words-only)的3131227行输出文件中选择截取的部分列表:
# of Words Starting Cumulative % Words In % of
Found On Line of Complete List This “Slice” Complete List
0 1 0% 406,841 12.99%
1 406,842 12.99% 286,664 9.16%
2 693,506 22.15% 297,230 9.49%
3 990,736 31.64% 307,051 9.81%
4 1,297,787 41.45% 293,268 9.37%
5 1,591,055 50.81% 270,360 8.63%
6 1,861,415 59.45% 238,653 7.62%
7 2,100,068 67.07% 206,452 6.59%
8 2,306,520 73.66% 173,525 5.54%
9 2,480,045 79.20% 145,115 4.63%
10 2,625,160 83.84% 384,083 12.26%
15 3,009,243 96.10% 98,280 3.13%
20 3,107,523 99.24% 19,508 0.62%
25 3,127,031 99.87% 3,522 0.11%
30 3,130,553 99.98% 656 0.02%
40 3,131,209 99.999% 18 0%
47 (max) 3,131,227 100.00%
被发现的嵌入词最多的有47个,二级域donaldtrumpsaythesethingsandnotgethospitalized的发音听起来很模糊,且带有威胁性
47, 53, howdoesdonaldtrumpsaythesethingsandnotgethospitalized, com, ali, and, doe, does, don, dona, donald, ese, ethos, get, gsa, hes, hing, hings, hos, hosp, hospital, hospitalize, hospitalized, how, ing, ital, liz, not, pit, pita, rum, rump, rumps, san, sand, say, set, seth, spit, tali, the, these, thin, thing, things, tho, trump, trumps, ump, umps, zed在sorted-and-uniqed-ten-million-output.txt中,深入研究这3131227个观察结果,我们可以看到,我们的代码成功地识别了许多零嵌入英语单词的算法域名,包括:
0, 20, 3194df72cec99745647d, date
0, 20, 4cb619a293b854c7269a, date
0, 20, 58e20e431fd16ecea0cc, date
0, 20, 5cac157ee96e87a7bb59, date
0, 20, 605b4274b01e6840e84b, date
0, 20, 65a0163dddfbd7030f48, date
0, 20, 65v1d7rixqtu6ixg65hm, ws
0, 20, 6d69c6ff6eb7e8facf18, date
0, 20, 88f0289c6f7e1f0b3cf9, date
0, 20, 9111304db6c05e5473a8, date
0, 20, 99990002188338d9dc5e, date
0, 20, 9ee08f9b1e36e1a3f880, date
0, 20, ab032283869929420167, win
0, 20, ab032302933987702253, win上面观察结果的解释:
- 上面显示的每一行的前两个值是找到的单词数量和二级域标签的长度。对于这个最新的样本块,找到的嵌入单词的数量始终为零,二级域标签的长度始终为20。
- 第三和第四个值表示实际的二级域和有效的顶级域。
- 通常,第四个值后面会跟着一个找到的嵌入单词列表,但在本例中显然没有。
我们可以使用dnsdbq来确认这些域确实存在于DNSDB中。例如,只请求3194df72cec99745647d.date的单个A记录(RRset):
$ dnsdbq -r 3194df72cec99745647d.date/A -l 1
;; record times: 2018-03-08 00:40:40 .. 2019-03-06 13:09:49
;; count: 425; bailiwick: 3194df72cec99745647d[dot]date.
3194df72cec99745647d.date. A 104.28.6.141
3194df72cec99745647d.date. A 104.28.7.141这个类随机域名目前正好托管在Cloudflare上。
8. 注意存在潜在问题的领域
a) 原始顶级域
DNSDB数据可以包含只有一个标签的名称(例如,一个顶级域),或者有两个标签的域名(如一个普通的委托点),以及三个或更多标签的域名(通常是完全限定域名)。
我们观察到850个原始的有效顶级域名,可以通过标记每个相关行开头为0, 0, ,来很容易地识别它们,例如,缺少二级域或者二级域为零长度,很明显,我们不会在一个零长度的二级域中找到任何嵌入的单词。
[...]
0, 0, , asia
0, 0, , asn.au
0, 0, , associates
0, 0, , at
0, 0, , attorney
0, 0, , auction
0, 0, , audio
0, 0, , auto
0, 0, , avianca
0, 0, , aw
0, 0, , ax
0, 0, , az
0, 0, , azure
[etc]b) 具有极低香农(Shannon)熵值的域名
虽然大多数不包含单词的域名看起来确实是随机的,但也有一些不包含单词的域名具有便于人类分析人员识别的非随机模式,比如单字符模式。这些域名的香农熵很低。为了处理这个问题,我们修改了Python代码,以便计算并将香农熵值与二级域关联到每一行,见附录4。例如:
[Shannon Entropy, Words Found, second-level label length, 2nd-level label, TLD]
0, 0, 7, jjjjjjj, cn
0.6500224216483541, 0, 6, 55555f, com
0.8112781244591328, 0, 8, z666z666,com
0.9709505944546686, 0, 5, ggvvg, cn
香农熵值小于1对于二级域是很少见的,至少在我们的样本中是这样的。
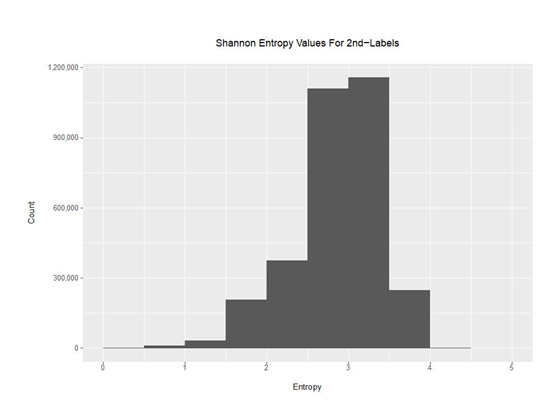
图5 实验语料库二级域的香农熵分布
c) 带有破折号的域名
我们还注意到一些带大量破折号的域名,如:
2.766173466363126, 0, 62, 1-2-3-4-5-6-7-8-9-10-11-12-13-14-15-16-17-18-19-20-21-22-23-24, com
1.191501106916491, 0, 54, 0-0-0-0-0-0-0-0-0-0-0-0-0-33-0-0-0-0-0-0-0-0-0-0-0-0-0, info
1.228538143953528, 0, 54, 0-0-0-0-0-0-0-0-0-0-0-0-0-53-0-0-0-0-0-0-0-0-0-0-0-0-0, info
2.6081816167087406, 0, 23, h-e-r-n-a-n-c-o-r-t-e-s, com
2.695138138447871, 0, 23, f-i-v-e-d-i-a-m-o-n-d-s, com
2.5358577759182794, 0, 19, t-i-p-o-g-r-a-f-i-a, ru
2.641120933813016, 0, 19, m-y-w-e-b-p-o-k-e-r, eu
2.395998870534841, 0, 17, p-o-r-t-f-o-l-i-o, ru
2.5580510765444573, 0, 17, b-o-o-m-e-r-a-n-g, com
2.5580510765444573, 0, 17, p-r-e-j-u-d-i-c-e, com
1.9237949406953985, 0, 16, i--n--s--u--r--e, com
2.4956029237290123, 0, 14, ip-167-114-114, net
2.495602923729013, 0, 14, ip-144-217-111, net
2.495602923729013, 0, 14, ip-167-114-116, net
2.556656707462823, 0, 14, ip-144-217-114, net
2.610577243331642, 0, 14, ip-217-182-228, eu
2.6384600665861555, 0, 14, ip-167-114-119, net
2.6384600665861564, 0, 14, ip-149-202-222, eu这些模式显然表明,统计域名中破折号数量可以作为启发式方法的一个过滤值,或者将破折号剥离作为预处理的一个步骤。
检查数据并将包含可能正常破折号数量的域名排除(例如,0到3个破折号),我们看到域名的分布如下:
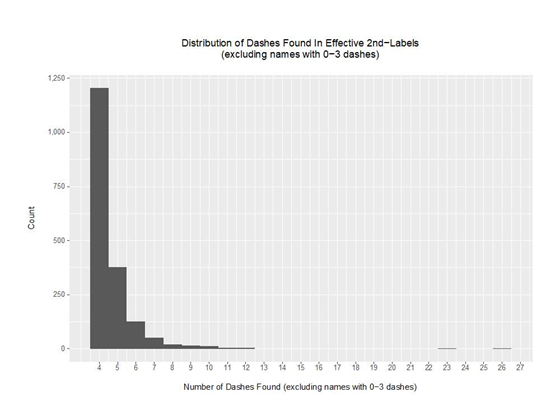
图6 在有效的二级域中发现破折号的分布(不包括含有0-3个破折号的域名)
考虑到使用这种非典型破折号的域名的存在,我们可以设想一个预处理规则,在进行搜索转换后的域名中单词之前删除所有破折号,尽管我们目前没有这样做。
d) 非英语单词
在其他情况下,对输出结果的检查清楚地表明,如果我们将英语以外的其他语言的词典包括进来,我们就可以检测到非英语单词。例如:
0, 23, trikolor-tv-elektrougli, ru
0, 20, muehlheim-aerztehaus, de
0, 16, ce-vogfr-aulnoye, fr
0, 15, buetler-elektro, ch
0, 15, cipriettigiulia, it显然,我们最初只关注英语单词可能是不恰当的。互联网是国际化的,它的用户依赖于法语、德语、意大利语、葡萄牙语、俄语、西班牙语以及任何你能想到的其他语言。
我们能找到哪些外来词表?我们首先只需要的是罗马/拉丁单词列表,不是阿拉伯文字单词列表,不是中文/日文/汉古文字单词列表,不是西里尔字母单词列表等等。
一个潜在的丰富的罗马化外文单词的来源是用密码破解软件编制的用于审核密码实践的外文单词清单。例如,请参阅此处的20多个外语单词列表,我们假设你已下载并合并这些单词列表,从组合列表中删除包含字母/数字/连字符以外字符的任何单词。
在添加新单词列表并使用新的英语加外国单词的列表重新运行find-words.py脚本之后,我们发现嵌入的单词要多得多,这反映在只有少量单词的FEWER域名中。
如下表所示,当我们在域名中只查找英语单词时,有406841个域名没有找到单词。但将单词列表更改为英语和外语单词的组合,突然之间,我们只剩下94011个没有嵌入单词的域名,也就是类随机算法域名 。
Words ENGLISH WORDS ONLY COMBINED LANGUAGE LIST
Found Starting On % of Lines Starting On % of Lines DIFFERENCE
0 1 0% 1 0%
1 406,842 12.99% 94,012 3.00% 9.99%
2 693,506 22.15% 213,816 6.83% 15.32%
3 990,736 31.64% 329,519 10.52% 21.12%
4 1,297,787 41.45% 455,640 14.55% 26.90%
5 1,591,055 50.81% 566,168 18.08% 32.73%
6 1,861,415 59.45% 677,469 21.64% 37.81%
7 2,100,068 67.07% 807,436 25.79% 41.28%
8 2,306,520 73.66% 929,783 29.69% 43.97%
9 2,480,045 79.20% 1,062,576 33.93% 45.27%
10 2,625,160 83.84% 1,196,525 38.21% 45.63%
15 3,009,243 96.10% 1,822,685 58.21% 37.89%
20 3,107,523 99.24% 2,311,625 73.82% 25.42%
25 3,127,031 99.87% 2,648,053 84.57% 15.30%
30 3,130,553 99.98% 2,862,546 91.42% 8.56%
40 3,131,209 99.999% 3,060,974 97.76% 2.24%
47 3,131,227 100.00% 3,106,213 99.20% 0.80%
50 3,115,421 99.50% 0.50%
60 3,127,871 99.89% 0.11%
70 3,130,530 99.98% 0.02%
80 3,131,044 99.99% 0.01%
90 3,131,185 99.999% 0.001%
100 3,131,213 99.999% 0.001%
116 (max) 3,131,227 100% 0%
相对于只使用英语的单词列表,这是一个显著的改进。请看下图中的绿色阴影区域
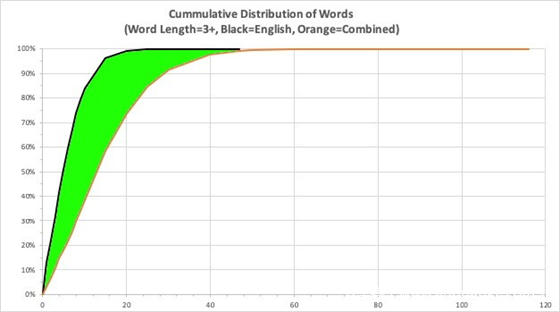
图7 – 提高对单词的识别能力,只使用英语单词列表与使用组合语言单词列表
对于严谨的人来说,包含英语或外语单词最多的域名是:
116, 59, escuelaprimariaurbanacrescenciocarrilloyanconaturnomatutino, com, acr, acre, acres, ana, anac, anc, anco, ancon, ancona, apr, apri, aprimar, ari, aria, arr, arri, atu, atut, aur, ban, bana, banac, car, carr, carri, carril, carrillo, cen, cenci, cencio, cio, con, cona, conatu, cre, cresce, cue, ela, enc, esc, esce, escuela, iau, iaur, ill, illo, ima, imar, imari, ino, ioc, ioca, lap, llo, loy, mar, mari, maria, mat, matu, matuti, matutino, nac, nacre, nacres, nat, natu, natur, nci, nco, nom, noma, oca, oma, omat, ona, onatu, oya, pri, prim, prima, primar, primari, primaria, rba, res, ria, riau, ril, rill, rim, rima, rimar, rimari, rno, rri, sce, scen, scu, tin, tino, tur, turn, turno, tut, tuti, tutin, uel, urb, urba, urban, urbana, urn, uti, utino, yan
9. 最终的类算法域名是什么样子的?
附录4中为只考虑有效的二级域的最终代码,过滤器为:
- RRSIG和NSEC3伪域名
- 在处理过的白名单中找到的域名
- 国际域名(xn--)
- ip6.arpa和 in-addr.arpa 域名
- 带有四个或更多破折号的域名
- 二级域全部是数字的域名
- 包含一个或多个英语或外语单词的域名
- 二级域的香农熵小于等于1的域名
- 二级域的长度不小于7的域名
除此之外,看看还剩下什么,对域名利用香农熵进行排序,我们发现了5337个域名:
4.133 6r5re2zfxghh3z-yf4um-w6-k9 site
4.031 5mc6xkw738bw77ggk5ff5crx8u9xsd33 biz
4.005 54re3kz9j-da5pjcf9x2ez work
3.962 r723f875e51fe4a1ec905d6bd2a42363be ws
3.94 r21037c6a95b8642e87adfb4a8c30f3302 ws
3.925 xc397b28a0e906415526a5d248760516fd ws
3.903 v316bf9146c5a89b21a40f8e43de502e1a ws
3.902 9dyfa9us3wo9exdw2di3966ypq download
3.856 w4fb1843f970915bd98e2a76d7f56e99ae to
3.856 ta0f52cf79107c18dcddb2bb113a641c7e ws
3.856 jb1f8dd9ec2e548025b132cf7a91ef11a0 ws
3.855 mt425nf-s9w3s9m-b79em2ea site
3.852 l3b01f3b6ea53dc7df1b8a57013e44c91b ws
3.844 te736da94645b8f25d92d868044157c8d2 ws
3.843 f73ac86f4014845e5edd0d81cb339cc2 top
3.83 tde595bfc08466e174bf33b445671b0a58 ws
3.827 u2a1376gf-43ty-245c com
3.822 z67c9434a799a225e6937b835da0eb06c8 ws
3.822 r8f49056003f8ceddf9d83952b56097a74 ws
[…]
2.406 88826cne com
2.406 7hx444at com
2.406 7hs1333m xyz
2.406 788js8f2 cn
2.406 73jdyyyl com
2.406 68333cne com
2.406 666024xc com
2.406 63a87770 com
2.406 617yl888 com
2.406 58333vns com
2.406 518988cp com
2.406 444360cp com
[…]
1.061 gb333333 com
1.061 cy888888 com
1.061 av888888 com
1.061 889-8888 com
1.061 666ht666 com
1.061 500w0000 com
1.061 444444kj com我们现在可以在这些域名之间寻找共同点,比如共享主机ip、公共名称服务器、通过相同的注册器注册等等。在本系列文章的第2部分中,我们将深入研究已经发现的域名。
10. 结论
现在你已经看到了一个初步的模型,尽管它可能很粗糙,但仍然可以帮助我们找到算法域名。可以做的更好么?我们已经暗示了一些我们可以尝试的东西,但是你必须等到本系列的下一部分才能看到对这些部分的分析会把我们带到哪里。
附录1
find-words.py (Python 2)
#!/usr/local/bin/python2
import string
import sys
import re
import tldextract
## read in the dictionary
## we will compare words found in stdin against words in this "dictionary"
dictionary = set(open('words.txt','r').read().split())
max_len = max(map(len, dictionary))
## read in the combined list of popular domains we want to avoid
protected = set(open('combined-millions-unique.txt','r').read().split())
max_len_p = max(map(len, protected))
## ensure the TLD extractor knows to obey the Public Suffix List
extract = tldextract.TLDExtract(include_psl_private_domains=True)
extract.update()
## read in candidate domain names for processing
for line in sys.stdin:
## create an initial empty set
mydomainnames = set()
justfound = line.lower().rstrip()
is_not_whitelisted = not(justfound in protected)
is_not_an_idn_name = (justfound.find("xn--") == -1)
is_not_an_ip6_arpa_name = (justfound.find("xn--") == -1))
is_not_an_in_addr_arpa_name = (justfound.find("in-addr.arpa") == -1)
if (is_not_whitelisted and
is_not_an_idn_name and
is_not_an_ip6_arpa_name and
is not_an_in_addr_arpa_name):
extracted = tldextract.extract(justfound)
justfound = extracted.domain.replace(" ","")
if (justfound.isdigit() == False):
justfound_length = len(justfound)
if (justfound_length >= 8):
efftld = extracted.suffix
words_found = set() #set of words found, starts empty
for i in xrange(len(justfound)):
chunk = justfound[i:i+max_len+1]
for j in xrange(1,len(chunk)+1):
word = chunk[:j] #subchunk
if word in dictionary:
if len(word) > 2: words_found.add(word)
words_found = sorted(words_found)
number_of_words = len(words_found)
print str(number_of_words)+", "+str(justfound_length)+",",
if number_of_words > 0:
print justfound+", "+efftld+",",
else:
print justfound+", "+efftld
if number_of_words > 0:
print str(words_found).replace("[","").replace("]","").replace("'","")
附录2
2nd-level-dom-large
#!/usr/bin/perl
use strict;
use warnings;
use IO::Socket::SSL::PublicSuffix;
my $pslfile = '/usr/local/share/public_suffix_list.dat';
my $ps = IO::Socket::SSL::PublicSuffix->from_file($pslfile);
while (my $line = <STDIN>) {
chomp($line);
my $root_domain = $ps->public_suffix($line,1);
printf( "%s\n", $root_domain );
}
附录3
生成单词长度分布的R语言脚本
#!/usr/local/bin/Rscript
mydata <- read.table(file="word-length-counts.txt",header=T)
pdf("word-length-distribution.pdf", width = 10, height = 7.5)
library("ggplot2")
library("scales")
mytitle <- paste("\nDistribution of 2nd-Label Lengths\n", sep = "")
theme_update(plot.title = element_text(hjust = 0.5))
p <- ggplot(mydata, aes(length)) +
geom_histogram(breaks=seq(-0.5, 63.5, by = 1)) +
labs(title=mytitle, x="\nLength in Characters", y="Count\n") +
scale_y_continuous(labels = function(x) format(x, big.mark = ",",
scientific = FALSE)) +
theme(plot.margin=unit(c(0.5,0.5,0.5,0.5),"in"))
print(p)
附录4
组合英语单词与香农熵的find-words.py (Python 3)
#!/usr/local/bin/python3
import string
import sys
import re
import tldextract
import math
def entropy(s):
string_length = len(s)
lc = {letter: s.count(letter) for letter in set(s)}
temp=0.0
for i in lc:
temp=temp+((lc[i]/string_length) * math.log2(lc[i]/string_length))
if temp == 0.0:
return 0
else:
return -temp
## read in the dictionary
## we will compare words found in stdin against words in the dictionary
dictionary = set(open('combined-word-list.txt','r').read().split())
max_len = max(map(len, dictionary))
## read in the combined list of popular domains we want to avoid
protected = set(open('combined-millions-unique.txt','r').read().split())
max_len_p = max(map(len, protected))
## ensure the TLD extractor knows to obey the Public Suffix List
extract = tldextract.TLDExtract(include_psl_private_domains=True)
extract.update()
## read in candidate domain names for processing
mydomainnames = set()
for line in sys.stdin:
## ensure name is lowercase and is whitespace free
justfound = line.lower().rstrip()
## only process stuff NOT found in the whitelist
if not(justfound in protected):
## ANY of the following hit? Don't process it
## note that at this point the TLD is still there
## Start by checking for punycoded domains
if ((justfound.find("xn--") == -1) and
## and .arpa domains
(justfound.find("ip6.arpa") == -1) and
(justfound.find("in-addr.arpa") == -1) and
## and anything like ip-12-34-56
(not(re.search("ip-*-*-*",justfound))) and
## any names with 4 or more dashes
(justfound.count('-') <= 3)):
## now pull just the 2nd-label
extracted = tldextract.extract(justfound)
justfound = extracted.domain.replace(" ","")
## only keep 2nd-labels that have at least one non-numeric
if justfound.isdigit() == False:
## how long is the 2nd-label?
justfound_length = len(justfound)
## what's the 2nd-label's shannon entropy?
shan_ent = entropy(justfound)
efftld = extracted.suffix
words_found = set() #set of words found, starts empty
for i in range(len(justfound)):
chunk = justfound[i:i+max_len+1]
for j in range(1,len(chunk)+1):
word = chunk[:j] #subchunk
if word in dictionary:
if len(word) > 2: words_found.add(word)
words_found = sorted(words_found)
number_of_words = len(words_found)
## these should be our highly random names
if ((number_of_words == 0) and (shan_ent > 1) and
(justfound_length >= 8)):
rounded_shan=round(shan_ent,3)
print(rounded_shan, justfound, efftld)