随着同黑产对抗的升级,对己方数据进行挖掘成为防守一方的重要武器,机器学习也随之成为防守方的制胜法宝。
机器学习在风控中的应用同一般的应用场景有所不同,主要体现在以下几个方面:
- 标注标签成本较高,导致标签较少甚至无标签
- 坏人会主动改进作弊策略,导致原有模型失效
- 需要实时或近实时的返回结果
- 场景多种多样:撞库盗号、黄牛领券、积分墙、反爬虫等
下文将从三个具体的例子来阐述我们(小米帐号安全)是如何利用机器学习解决帐号风控面临的具体问题。
一、规则太多,如何减轻维护负担?
对于风控系统而言,规则往往会产生立竿见影的效果,辅之以专家经验,可以在很长的时间内发挥重要作用。但是随着时间的推移,越来越多的规则被加入系统中,越来越多的边际条件需要权衡,甚至会出现牵一发而动全身的情况。如何更好的维护这些历史规则?
通过分析这些历史规则,我们发现规则实际是对异常的一种人肉归纳量化,例如:如果某IP每分钟访问次数大于50次且都是登陆失败比例大于90%,就ban掉该IP。那么更好的维护规则这一问题就变成了:在给定样本及特征后,如何量化异常?我们面临的初步问题是这样的:
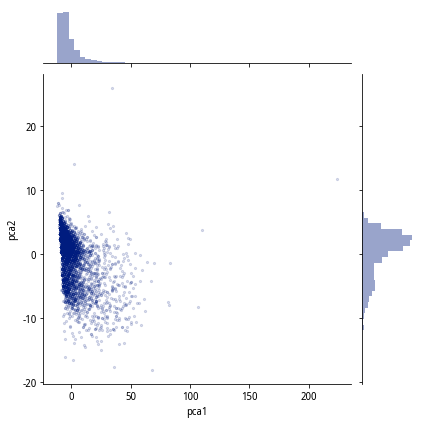
考虑到无标签和坏人的“主动性”,我们可以选择无监督的异常发现模型来区分异常。这其中孤立森林模型算是效果较好的了。它可以达到如下效果:
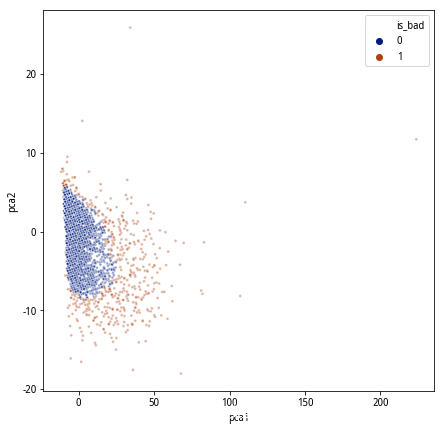
但是考虑到线上情况的复杂性,我们希望给样本的异常程度进行打分,以便结合历史数据进行策略回溯,灵活的确定阈值,从而达到最佳准召,因此最终会输出异常得分,从而达到量化异常的效果:
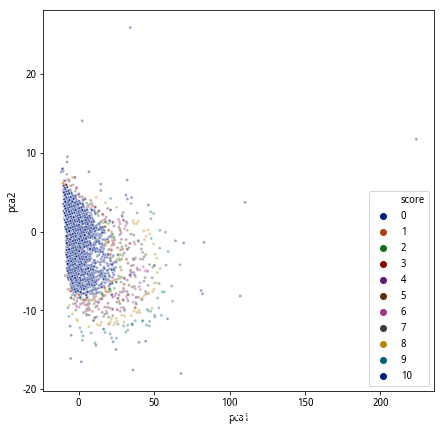
最终我们实现了对异常的量化,从而实现了对线上规则的改进,这样一来,对规则的维护变成了对特征的维护。只要能够产生特征及同模型相关的特征组合,就可以得到相应的异常量化模型,从而实现了灵活的线上规则管理。同原来的规则拦截相比,模型的覆盖率达到了规则拦截的80%+,召回率则提升了70%+。
二、无感知验证码
随着对抗的升级,验证码用于区分人/机器已经越来越显得力不从心。攻击方采用的验证码破解手段也早已由人肉打码升级到了深度学习打码,普通人面对验证码也不得不感叹:这样的验证码真的有人能答对吗?可能只有机器能答对吧。

既然验证码又不能防机器,又阻碍了正常用户,那是否有更加用户友好的手段可以代替验证码呢?这里我们引入了人机识别,采用手机传感器在用户无感知的情况下完成人机区分。
智能手机中存在多类传感器,如加速度传感器、角速度传感器(陀螺仪)、重力传感器、磁场传感器等,在手机运行的每时每刻,这些传感器都在以成百上千Hz的频率将其收集到的X/Y/Z轴数据传递给手机的操作系统。那么这些传感器数据是否足以区分人/机呢?我们假定坏人可以通过操纵手机API或外力让手机产生物理行为从而产生运动状态的传感器数据,对坏人而言可选的操作包括:静止时、手机震动时和手机置于摇摆装置中。我们分别收集了这几个场景产生的传感器数据,可以对以下4张图片做肉眼的对比:

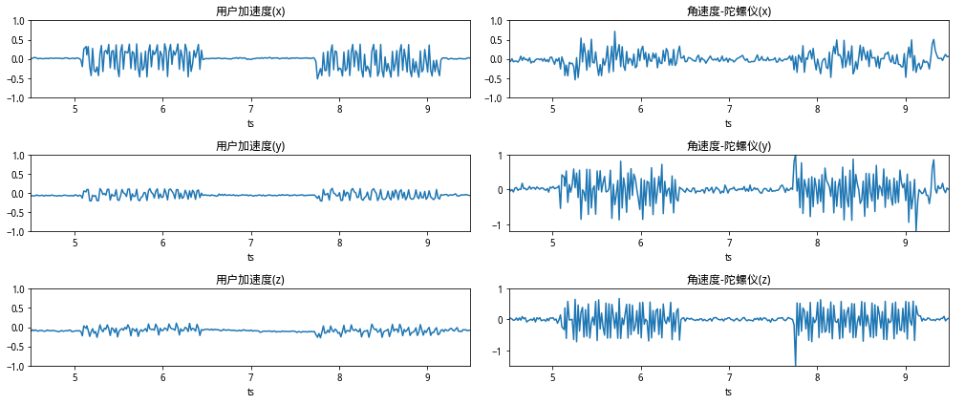
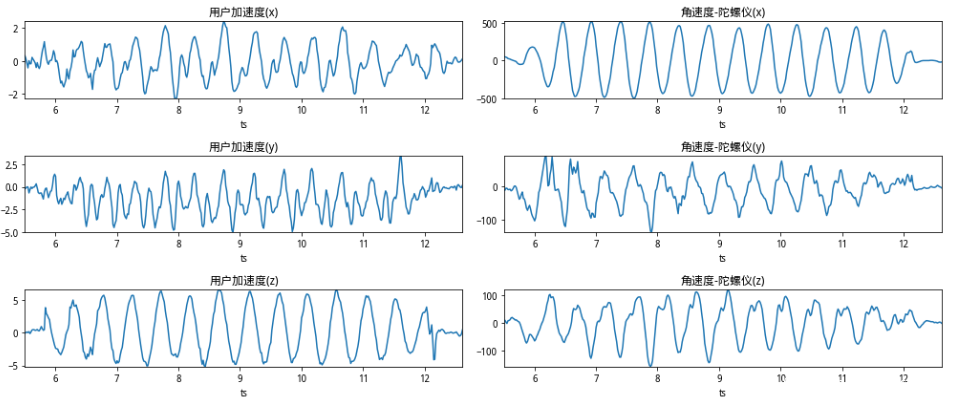
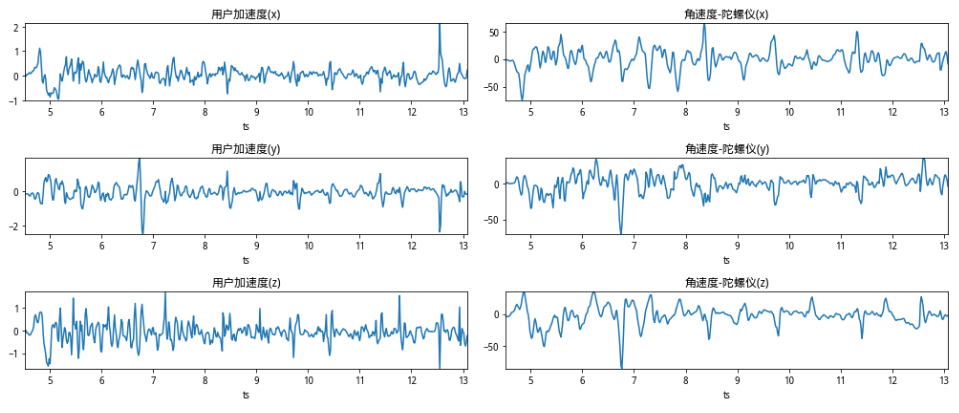
图中从上至下依次对应的操作是:手机静止、手机震动、手机摇摆和正常点击操作。从上图可以看出,静止时传感器仍然存在轻微的抖动,震动时的传感器的波动更有规律性,摇摆中的传感器数据像极了正弦波,而正常的点击操作由于手指的点触操作会带来加速度的陡升/陡降。从这里可以看出,要区分传感器数据是否由人类产生,更准确的说:某次滑动或点击的交互操作时否由当前传感器产生,正是很适合由机器学习来判断的二分类问题。
最终产出是人机识别模型,可以判断SDK采集的传感器数据是否由人类产生。从线上的拦截效果来看,整体准确率在97.3%,好人误拦率为1.8%。

从对抗的角度来说,人机识别的主要目的是降低了好人的进入门槛,而提升坏人作恶门槛只是辅助和次要目标,因为人机识别的安全性强依赖于SDK的安全性,一旦SDK被破解,坏人会很容易伪造合法输入。所以在实践中,我们会在SDK中加入多个特征进行采集,从而使其起到探针的作用,将主战场拉回到后端。
三、事后预警机制
通常将风控分为事前、事中和事后三个部分。出于实时性考虑,事前和事中的拦截很难达到高召回。但是即使在事后,如果能够尽可能早的以高准召率发现异常并形成拦截策略,仍然是有意义的。
我们知道坏人的行为经常表现出聚集性,可能是设备、IP等的聚集,也可能是行为上的同步性:一批UID同时干同一件事。这一聚集性和同步性很像传染病爆发时感染者属性的聚集和行为的同步:都居住在某特定区域,都去过某个公共场所。而风控场景的及时事后预警,也很像公共卫生机构在面临新冠病毒这样的传染病时的问题:如何及时发现疫情正在爆发,并且及时锁定到尽可能多的被感染者?
我们假设卫生机构收集到了如下的患者就诊信息(部分):
| 姓名 | 性别 | 症状 | 居住社区 | 工作地点 | 就诊时间 |
| 张三 | 男 | 感冒 | 1号街道 | 蔬菜市场 | 2020/1/4 |
| 李四 | 女 | 肺炎 | 22路 | 海鲜市场 | 2020/1/5 |
| 王五 | 男 | 肺炎 | 长江家属院 | 瓜果市场 | 2020/1/5 |
| 赵六 | 女 | 肺炎 | 黄河村 | 海鲜市场 | 2020/1/6 |
| 钱七 | 男 | 肺炎 | 江汉路 | 海鲜市场 | 2020/1/6 |
可以采取的前置步骤是,建立历史基线,对比当前统计分布和历史分布,找到异常的统计项。例如,当2020W1的肺炎患者激增,要定位到这一异常项,需要统计出历史同一时期(上周、上月、上年)的相同指标项,采用统计检验(Chi-square test / Fisher exact test等)判定当前指标同历史指标的差异(p值),可以看到在我们假定的数据中,2020W1的肺炎患者明显多于历史同期水平,第一步骤完成。
| 时间 | 呼吸患者总人数 | 肺炎患者 | p-value |
| 2019W1 | 100 | 8 | 0.0193 |
| 2019W48 | 120 | 8 | 0.0052 |
| 2019W52 | 160 | 15 | 0.0187 |
| 2020W1 | 200 | 40 | 1 |
发现异常指标项后,我们还希望能够定位到传染源头和密切接触人群。在传染病学中,当然需要的是流行病学调查,它的关键是找到传染源和传播途径。对风控来说则需要找到坏人的有效特征以便形成封禁规则。考虑到坏人之间千丝万缕的联系,我们通常会假定:与坏人联系越密切的,越可能是坏人。
对于这种问题,理所当然的我们会想到图相关技术。在传染病场景,图技术可以将密切接触者以海鲜市场为中心圈出来,在风控场景我们同样可以通过图关联分析将坏人之间暴露出的蛛丝马迹进行推导,从而找到相应的作恶社群。在实践中,我们发现Louvain社区发现算法不需要数据标注,运行速度快,结果准确,有着较好的效果。
总的来说,借助于机器学习算法,防守方将从已方拥有的海量数据中挖掘出越来越多的洞见和认知,在防守中占据更加主动的位置。