周末没事的时候看了下ctftime上的比赛,正好有个 Insomni’hack teaser 2019的比赛,于是花了点时间做了下逆向的2道题,有点意思,学到了很多知识。
beginner_reverse
A babyrust to become a hardcore reverser.
看题目意思很明显了,是个硬核的rust逆向题,关于rust语言,自己没有了解,Google了一下,大致是一种着重于安全开发的系统编程语言。
直接上手
首先用file命令查看下文件特性。
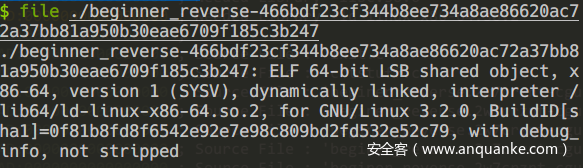
很庆幸,是带符号的动态编译的文件。于是暴力就完事了,直接用ida打开,如下图所示。
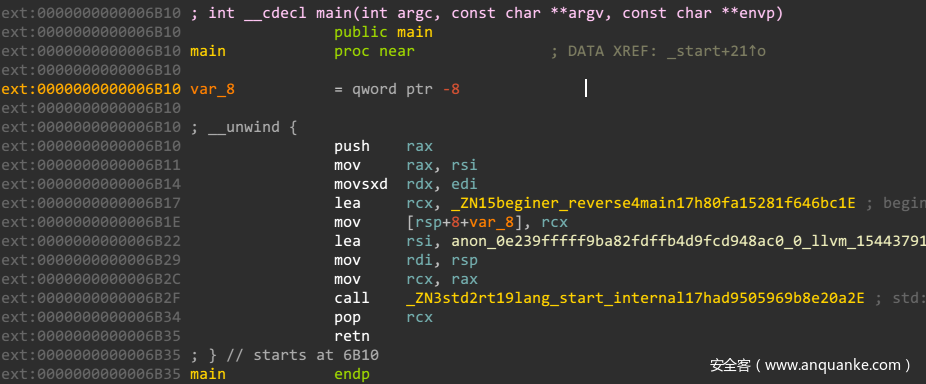
这里和一般的C逆向不一样的是,rust运行时环境的初始化过程。由于自己不熟悉rust语言的特性,按照惯性思维,认为start最后返回之前的函数一般为主函数,而开头的函数一般为运行时初始化函数,导致一开始函数分析错误,这也同样导致了ida的反编译F5功能失败。
int __cdecl main(int argc, const char **argv, const char **envp)
{
int result; // eax
std::rt::lang_start_internal::had9505969b8e20a2();
return result;
}
如果我们跟进这个lang_start_internal函数的话,就会发现找不到我们实际的主函数在什么地方,而一般情况下,主函数肯定是在初始化后才执行的,所以这里会卡住,迷失了方向。
写个demo
为了弄清rust加载运行时环境的流程,自己装上了rust的编译环境,同时写了个简单的demo进行编译测试。源代码如下:
fn main() {
println!("hello world");
}
编译代码如下:
rustc main.rs
运行结果就是输出hello world,但我们关心的是输出文件,为此,我使用ida载入文件并分析。可以看到,和题目类似的格式。

为了定位主函数的位置,我直接使用搜索字符串的方法,查找交叉引用。如下图所示。

然后我们可以进一步查找该处的交叉引用,就能定位到主函数的位置。
void main::main::hfe98083a4c87500f()
{
char v0; // [rsp+8h] [rbp-30h]
core::fmt::Arguments::new_v1::h9482ffdd5f1340ab(&v0, &ptrHelloworld, 1LL, off_23170, 0LL);
std::io::stdio::_print::h46f3f0db7dd4cd21();
}
关于这个主函数所引用的位置,我们可以看到如下所示的情况。
lea rdi, _ZN4main4main17hfe98083a4c87500fE ;
mov [rsp+8+var_8], rsi
mov rsi, rax
mov rdx, [rsp+8+var_8]
call _ZN3std2rt10lang_start17hd1a40614a9e43128E
也就是说在rust中,rust编译器通过使用寄存器指向主函数地址,作为函数指针,作为lang_start_internal函数的参数,供rust运行时来初始化程序状态。更多关于rust的主函数加载情况,参看Rust Runtime Services。
分析主函数
解决了这个问题,我们就能找到主函数了,下面我们就跟进beginer_reverse::main::h80fa15281f646bc1()这个函数(其实从名字也能看出来,上文基本解释了原因)函数首先载入了一大段密文,很容易猜测这个是密文了,或者通过交叉引用也能看出来,然后从命令行读取输入。

然后会进行很多检测,首先检测长度,再检测输入的最后一位是否正常。

之后会遍历每一个输入,然后进行检测,判断范围等等操作,然后再将每个值拷贝到栈中缓存。由于rust十分注重安全性检测,所以这里的工作有点复杂,自己是用动态调试配合硬件断点的方式直接跳过这段检查了。
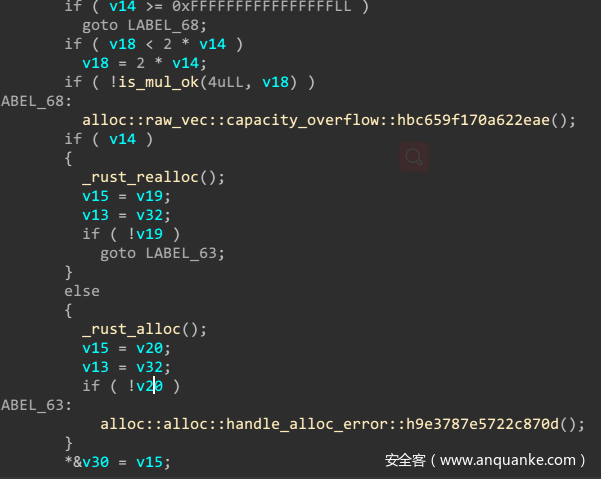
比如我输入aptx4869就会变成这样,如下图所示。

在下一次断点断下的时候,我们就会看到常见的循环+相等判断,估计就是解密所在的位置了。找到伪代码对应的位置,如下图所示:

对比看汇编,此时的明文和密文分别由r14和r15寄存器的首地址所指向,我们直接查看即可。

这和我们最开始看到的数据是相匹配的,不同的是,在程序载入后,修改了最后的2个数据,所以我们直接dump下这段密文,然后根据上面所示的判断方法来计算,就能得到flag了。
cipher = [0x0000010E, 0x00000112, 0x00000166, 0x000001C6, 0x000001CE, 0x000000EA, 0x000001FE, 0x000001E2, 0x00000156, 0x000001AE, 0x00000156, 0x000001E2, 0x000000E6, 0x000001AE, 0x000000EE, 0x00000156, 0x0000018A, 0x000000FA, 0x000001E2, 0x000001BA, 0x000001A6, 0x000000EA, 0x000001E2, 0x000000E6, 0x00000156, 0x000001E2, 0x000000E6, 0x000001F2, 0x000000E6, 0x000001E2, 0x000001E6, 0x000000E6, 0x000001e2, 0x000001de, 0x00000000, 0x00000000]
cipher = ''.join(map(lambda x: chr((x>>2) ^ 0xa), cipher))
print cipher
总结
- 总体来说这题不算很难,也说不上是硬核题,主要是语言不熟悉,导致了对语言的特性不清楚,在这点上浪费了很多时间。
- 同时由于rust语言采用大量的安全检测来保证后续的计算正常,在静态分析上出现了些麻烦,但能通过动态调试进行很好的解决。
- 程序不是静态链接的,分析起来有字符串可以参考,函数名也有理有据,对逆向有很多帮助,同时最后的算法也很简单,完全不需要逆向,正向计算即可。
Junkyard
Wall-E got stuck in a big pile of sh*t. To protect him from feeling too bad, its software issued an emergency lock down. Sadly, the software had a conscience and its curiosity caused him to take a glance at the pervasive filth. The filth glanced back, and then…Please free Wall-E. The software was invented by advanced beings, so maybe it is way over your head. Please skill up fast though, Wall-E cannot wait for too long. To unlock it, use the login `73FF9B24EF8DE48C346D93FADCEE01151B0A1644BC81” and the correct password.
第二题难度比较大,如题所述,整个题目中充斥了很多的垃圾指令,导致程序流程异常复杂,对分析产生了很多困扰。
首先进入主函数,很明显,如果输入参数不是3个,就会调用一个函数,估计是退出,我将其命名为exit,然后对第二个参数进行判断,不满足条件又会调用exit,再对第三个参数进行判断,不满足也会调用exit。最后如果情况都满足,则在最后调用一个函数来判断,同时将2个参数传入进去,这是很明显最后的check函数,也称为主逻辑。

尝试运行程序,发现运行时间非常长,平均要好几秒才运行完毕,而且根据情况的不同会打印出不同的提示字符串。比如,如果我就输入一个参数会打印出Usage: ./chall user pass等等,这些情况包括:
I don't like your name
Is that a password?
Maybe they're hiring at mc donald's? :/
Computing stuff...
Usage: ./chall user pass
根据这种情况,我猜测是程序对字符串进行了动态解密,于是先找到字符串解密的地方,就能对程序指向流程有个整体的把握。而很明显,字符串解密的地方就在exit这个函数中,因为这个函数被大量引用,且符合上文所述的参数个数不一致问题所打印的提示信息。
解密字符串
下面跟进exit这个函数,发现其只做了一件事,即将一些常量作为参数来调用另一个函数,我将其命名为calcMsg。

对这些字符串并不能得到很多有用的信息,于是继续跟进calcMsg这个函数,我将其中的垃圾指令擦除后,可以看的更清晰些,如下图所示。

其中能看到md5的字样,估计是调用了md5函数进行hash计算,而其中的sub296b伪代码如下:
_BYTE *__fastcall sub_296B(const char *a1, __int64 a2, unsigned int a3, __int64 a4)
{
v7 = a3;
v6 = a4;
v10 = strlen(a1);
v9 = 0;
v8 = 0;
while ( v7 > v9 )
{
v4 = sub_275F(*(v8 + a2));
*(v9 + v6) = (16 * v4 + sub_275F(*(v8 + 1LL + a2))) ^ a1[v9 % v10];
v8 += 2;
++v9;
}
result = (v9 + v6);
*result = 0;
return result;
}
__int64 __fastcall sub_275F(unsigned __int8 a1)
{
if ( a1 > '/' && a1 <= '9' )
return a1 - 48;
if ( a1 <= '9' )
return a1;
return a1 - 'W';
}
简单来说,这段代码就是将输入的字符串转成十六进制值,同时每一位和一个密钥进行循环异或,综合前一个函数的调用情况,简单来说做了这些事情:
- 初始化一个密钥,其值是10000。
- 将密钥打印到一个数组中,同时将其作为参数调用另一个函数,该函数将原函数的参数作为序号,将常量字符串转换成相应的十六进制值,同时和密钥进行异或。
- 将异或的值进行md5计算,将结果和序号所指定的hash值对比,如果相等则退出,否则进行循环,将密钥加一,重复操作。
至此,我们大致分析完了整个字符串解密的过程,这也能大致解释为什么这个程序运行的这么慢,主要是密钥的初始值太小,只有10000,或者说作者将指定的密钥设计的太大。而在这个程序中,经过自己调试,发现当密钥的值是13371337时满足条件,即可进行解密。完整idapython脚本如下所示,注意自己已经将密钥的初始化值设置为13371336,防止计算时间太慢。
from idaapi import *
from idc import *
from idautils import *
import hashlib
def getMd5(src):
m1 = hashlib.md5()
m1.update(src)
return m1.hexdigest()
secret = 0x8b80
md5hash = 0x8be0
iv = 13371336
ivs = [0,1,3,4,5,6,7,8]
for i in ivs:
init = GetString(Qword(secret + 8*i)).decode('hex')
hash = GetString(Qword(md5hash + 8*i))
#print init
while True:
key = str(iv)
t = ''
for i in xrange(len(init)):
t += chr(ord(init[i]) ^ ord(key[i%len(key)]))
#print t
if getMd5(t) == hash:
#print key
print t
break
iv += 1
运行结果如下图所示。

注意整个解密过程是不包括偏移量是2的那个字符串的,因为他是真正的flag加密的字符串,可以用交叉引用来证明,同时该字符串是使用aes进行加密,和这里无关。
主check逻辑
在完成字符串解密后,我们只能通过字符串引用的位置大致推测每一段check的作用是什么,比如第一个check就是判断输入参数是不是3个,第二个check判断输入长度是否满足大于15并且小于等于63。在满足这个条件的情况下,程序会输出Computing stuff...然后进入真正的check逻辑,下面开始分析。
如下图所示,首先滤去垃圾指令,在函数开头计算2个参数的长度,因为上文的检测,所以肯定满足小于等于63的条件,然后进入change1这个函数进行变换。

change1这个函数中又调用了另一个函数,如下图所示:

很明显这是用来进行素数判断的,将从零到某个数字范围内的所有素数都求出来,然后返回到这个集合。然后在change1中,求出字符串长度和64之间的差值,然后进行循环,将素数集合作为index,求出字符串对应index下的值,添加到字符串末尾,然后结束。

然后取出字符串中2个特定位置上的值,对其进行操作,这里由于参数1是指定的,所以我们可以进行部分化简,我的注释也标在图上了。

要注意的是,这里还定义了一个655大小的数组,也是变相进行混淆,然后程序还定义了一张表,从A到S,是为了映射用的,如下图所示,之后进行了一段很难理解的计算。
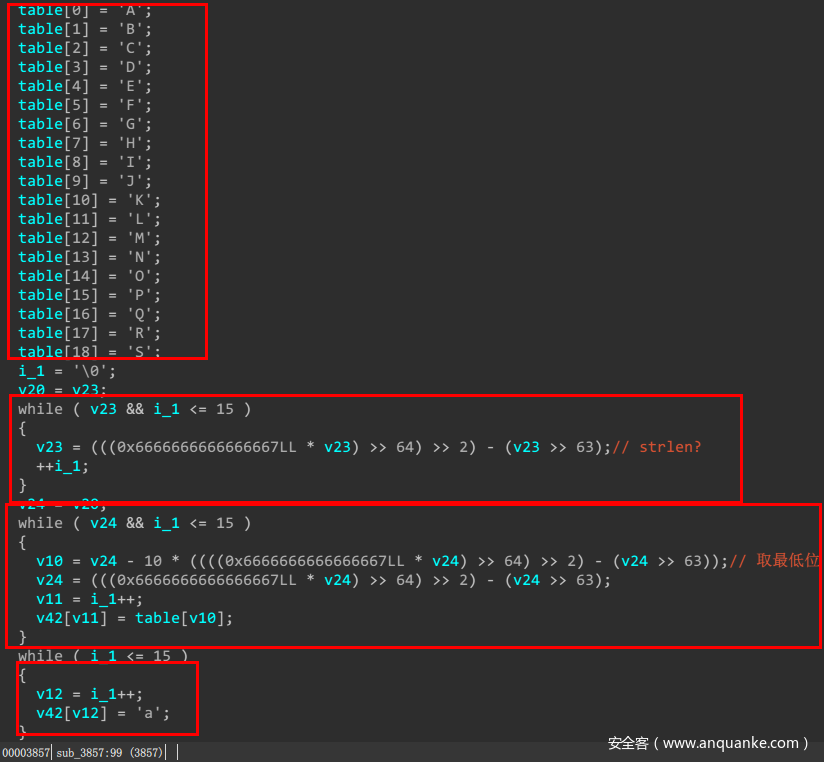
这段计算代码如下所示,如果真的是这样看的话,自己很难理解其中的意思,其真正的作用是计算十进制数的位数,之前在29c3 ctf中也有类似的题目解析。
while ( v23 && i_1 <= 15 )
{
v23 = (((0x6666666666666667LL * v23) >> 64) >> 2) - (v23 >> 63);
++i_1;
}
那么第二段何其类似的代码也能理解了,就是取整数的最低位,然后次低位这样,然后再映射到A到S的表中。
while ( v24 && i_1 <= 15 )
{
v10 = v24 - 10 * ((((0x6666666666666667LL * v24) >> 64) >> 2) - (v24 >> 63)); // 取最低位
v24 = (((0x6666666666666667LL * v24) >> 64) >> 2) - (v24 >> 63);
v11 = i_1++;
v42[v11] = table[v10];
}
最后再用a来填充,对齐到16的倍数。比如上面计算出来的结果是123,那么3对应D,2对应C,1对应B,依次添加,最后的结果就是123DCBaaaaaaaaaa。
while ( i_1 <= 15 )
{
v12 = i_1++;
v42[v12] = 'a';
}
最后一步操作就是转成十六进制,然后取其5-8位,进行md5的计算,如果和给定的常量相同就算成功?
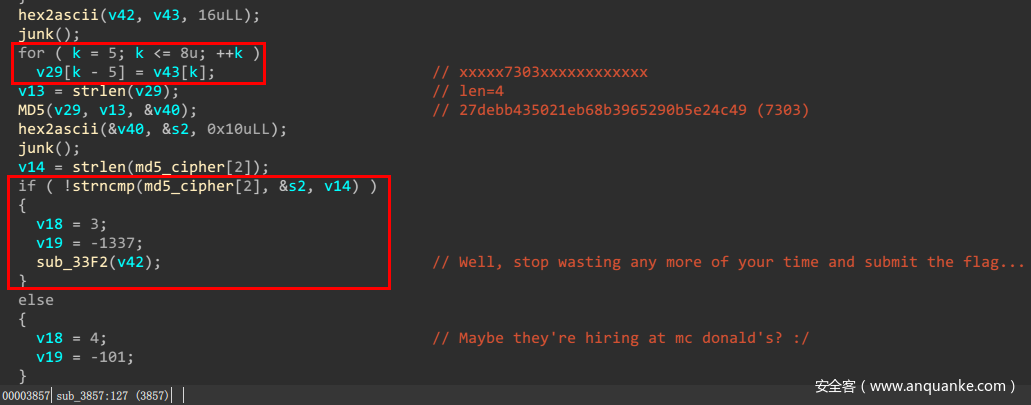
求解过程
首先md5的原象只有4位,在很容易爆破,容易得到27debb435021eb68b3965290b5e24c49的原象是7303,那么我们需要的就是字符串5-8位是7303。idapython脚本如下:
from idaapi import *
from idc import *
from idautils import *
from string import maketrans
k = maketrans("0123456789", "ABCDEFGHIJ")
cipherTable = []
ans = []
for i in xrange(655):
cipherTable.append(Dword(0x8140 + 4*i))
def getflag(x, y):
sum1 = x - 0x30 + 634 + cipherTable[y] + 892360
#print sum1
s = map(lambda x: sum1 + x, cipherTable)
t = str(s[155 - x])
p = t + t[::-1].translate(k)
if p.encode('hex')[5:9] == '7303':
ans.append(chr(x) + 'a' * 0x29 + chr(y))
for i in xrange(0x20, 0x7f):
for j in xrange(0x20, 0x7f):
getflag(i, j)
但是一共会得到90种不同的解,肯定不是每个解都对的,这里其实还有一个问题,因为flag是通过aes解密出来的,可能会存在数据错误,导致异常产生,我的办法就是一个一个试了,可以通过pwntools来实现自动化测试。
from pwn import *
#context.log_level = "debug"
name = "73FF9B24EF8DE48C346D93FADCEE01151B0A1644BC81"
p = process(argv=["./junkyard", name, ans])
p.recv()
最后得到正确的输入是2aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaC,输入就能解密得到flag。

总结
- 对于垃圾指令很多的情况,需要找出垃圾指令填充的规律,然后就能略去很大无用的代码。
- 对于整体的解密思路还存在宏观把握不够的情况,具体表现在求素数那部分,其实那部分之后并没有用到,因为最后只用到了输入的其中2位,然后进行爆破就行了,所以还是多分析了很多部分,浪费了很多时间。
- 学到了加密常量字符串的新方法,通过指定循环次数来进行哈希运算,可以对字符串进行保护,同时要进行哈希运算,加大了运行时间,减少了爆破的机会。