
前言
angr是有名的一个二进制分析框架。官方文档关于二进制静态分析部分的介绍比较少。本文不会详细介绍静态分析的原理,只是简单地介绍如何用angr来实现一些基本的静态分析功能,比如后向切片,遍历调用图计算距离等等的操作。
概述
二进制研究的很多应用都离不开二进制的静态分析。比如符号执行、模糊测试等技术可以利用静态分析的结果用来进行进一步的优化。
angr内部实现了很多静态分析功能,本文先从最基本的一些图来展开介绍,比如控制流图、控制依赖图、数据依赖图等等。至于angr内置的一些数据流分析方法,后续有时间会更新一下。因此,本文大体上分为以下这几个部分:
1.控制流图
2.调用图
3.后向切片
需要注意本文的代码是基于angr 9.0.10576这个版本写的。早期版本可能会有部分api的名字变了。比如下文的anyaddr参数,在早期版本的名字是any。
控制流图
在二进制上最基础的分析应该就是生成一个控制流图(Control Flow Graph)。控制流图的节点是基本块,基本块可以理解为是一段以跳转指令或者分支指令为结尾的汇编代码。基本块具有原子性,也就是不可分割,基本块内的代码要么全部执行,要么不执行。控制流图的边则表示跳转或者分支指令的流向。
angr中有两种控制流图,一种是静态的CFGFast,另一种是用符号执行实现的动态的CFGEmulated。CFGFast基于静态实现,所以能够恢复地比较全,而且生成得比较快。但是有些控制流关系只能在运行时才能确定,因此静态的CFGFast可能无法恢复这部分的关系。CFGEmulated基于符号执行实现,考虑了上下文关系,也能够恢复更准确的CFG,但缺点在于比较慢才能生成,并且因为系统调用、硬件特征模拟上的精度问题,导致控制流图可能恢复得不完整。二者的区别整理为下表。
| 区别 | CFGFast | CFGEmulated |
|---|---|---|
| 实现 | 静态分析实现 | 动态符号执行实现 |
| 考虑上下文 | 未考虑 | 考虑了 |
| 特点 | 更全 | 更精准 |
| 生成时间 | 快 | 慢 |
angr文档中也提到,如果不知道用哪个CFG,就先用CFGFast。
在angr中生成控制流图的代码如下:
import angr
# 对要分析的二进制生成一个project对象
p = angr.Project("/bin/ture",load_options={'auto_load_libs': False})
# 生成静态的CFG
cfg_fast = p.analyses.CFGFast()
# 生成动态的CFG,keep_state参数表示保留状态
cfg_emulated = p.analyses.CFGEmulated(keep_state=True)
文档中提到angr的CFG的核心是基于NetworkX构建的,也就意味着所有NetworkX的API都可以使用。一开始没觉得这句话有啥,直到我看了下NetworkX的文档,才发现一下子格局就打开了。
NetworkX提供了很多图算法的接口,包括基础的DFS,BFS遍历,也包括一些最短路径的算法,比如A*,dijkstra等。这就意味着,我们可以很容易地利用NetworkX的API来实现控制流图的遍历和分析,甚至还可以和community包结合来实现louvain这种社区发现算法来发现CFG里的内部关系。
下面给出一个例子来介绍如何结合networkx来对angr生成的控制流图进行分析。
比如说,我们要获取某个节点的BFS遍历顺序,可以用networkx包里的shortest_path方法。
shortest_path(G, source=None, target=None, weight=None, method=”dijkstra”):
其中G表示networkx的图,source表示最短路径的起点,target表示最短路径的终点,最后返回一个最短路径列表。
需要注意下面的例子中除了用angr外,还使用了angrutils和networkx这两个包,需要安装才能运行下面的脚本。
安装networkx:pip install networkx
angrutils用于可视化,安装可以参考:https://github.com/axt/angr-utils
为方便测试,写了个小程序
#include<stdio.h>
void error(char *error)
{
puts(error);
}
void alpha()
{
puts("alpha");
error("alpha!");
}
void beta()
{
puts("beta");
error("beta!");
}
void main(int argc,char * argv[])
{
if(argv[1]=="a"){
alpha();
beta();
}else{
beta();
}
}
用gcc编译后,用下面的angr脚本先画个CFG图看看。
import angr
from angrutils import *
proj = angr.Project("testcase/call",load_options={'auto_load_libs': False})
#从符号表获取main函数对象
main = proj.loader.main_object.get_symbol("main")
#生成起点从main函数开始的cfg
cfg = proj.analyses.CFGEmulated(starts=[main.rebased_addr])
# 调用angrutils的方法来画图
plot_cfg(cfg,"cfg",format='png', asminst=True,remove_imports=True)
这里我们截取部分的CFG图,假设我们要计算main函数的基本块到alpha函数中(0x400695)的最短路径。
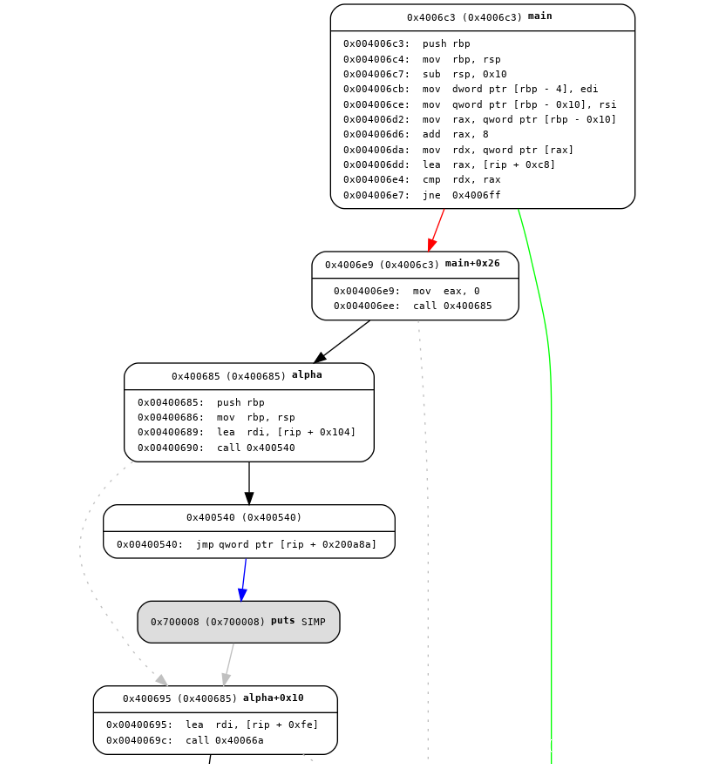
我们就可以在之前的代码上添加如下几行:
from networkx import shortest_path
# 根据地址获取cfg图的节点对象
source_node = cfg.model.get_any_node(main.rebased_addr)
target_node = cfg.model.get_any_node(0x400695)
# 调用shortest_path方法
path = shortest_path(G=cfg.graph,source=source_node,target=target_node)
>>> [<CFGENode main 0x4006c3[38]>, <CFGENode main+0x26 0x4006e9[10]>, <CFGENode alpha 0x400685[16]>, <CFGENode alpha+0x10 0x400695[12]>]
可以发现最后输出的路径也很容易从这部分的图上看出来。至于其他的networkx的api的用法就不一一演示了。原理上是相同的,只要是networkx对象,就都可以用它的api来实现图的分析。
至于可视化的地方,当然也可以直接用networkx将图导出为dot文件,再用其他可视化dot文件的工具来可视化,这样做更灵活,可以可视化一些图里的子图。
另外,补充一点,上面根据地址获取cfg图的节点对象的代码中,如果我们的地址是基本块中间的地址,而不是基本块开始的地址,我们需要加个参数anyaddr=True,如下:
target_node = cfg.model.get_any_node(0x400689,anyaddr=True)
调用图
控制流图是以基本块为粒度,而调用图则是以函数为粒度,是一种更粗的粒度。所以,有时候在考虑性能开销的情况下,用调用图分析会比CFG要快得多。
调用图的可视化,也可以用angr-util来实现,具体代码如下:
import angr
from angrutils import *
proj = angr.Project("testcase/call",load_options={'auto_load_libs': False})
main = proj.loader.main_object.get_symbol("main")
cfg = proj.analyses.CFGEmulated(starts=[main.rebased_addr])
callgraph = cfg.kb.callgraph
plot_cg(cfg.kb,"call_graph",format='png')
画出的调用图如下所示:
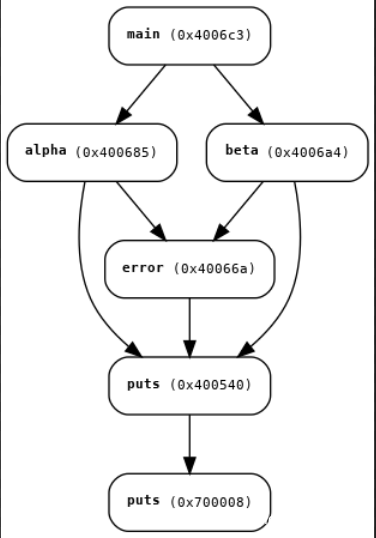
angr生成的调用图也是networkx对象,所以networkx的API同样也能对调用图来使用。这里就简单列几个比较常用的。
MultiDiGraph.nodes #返回一个节点列表
MultiDiGraph.has_node(n)#是否有n节点
MultiDiGraph.predecessors(n)#返回节点n的前继节点列表
MultiDiGraph.successors(n)#返回节点n的后继节点列表
调用图的粒度是以函数为单位。而angr中也内置了一个函数管理器cfg.kb.functions来管理函数。
#获取main函数的函数对象
# 1. 先从符号表获取main函数的地址
# 2. 再用地址从函数管理器获取main函数对象
main = proj.loader.main_object.get_symbol("main")
main_func = cfg.kb.functions[main.rebased_addr]
# 直接从函数名获取函数对象
main_func = cfg.kb.functions.function(name='main')
一个函数对象有非常多对分析有用的属性,这里列几个我觉得比较重要的,关于更多的属性,可以去看angr源码的function部分
func.name :函数名字
func.is_plt:是否是外部库函数
func.addr:函数入口地址
func.binary_name:函数所在的二进制
func.is_syscall:是否是系统调用
func.block_addrs:属于函数的基本块的地址集合
func.transition_graph :函数内部的控制流图,类似在ida里看到的一样
func.get_call_sites():获取函数的调用点
在实际应用的过程中,我遇到了一个问题:知道某个指令的地址,怎么求出其所在的函数地址?
我的思路是分为以下两步:
1.将指令地址转换为基本块地址
2.遍历函数管理器,看基本块地址是否在函数内
# 1.将指令地址addr转为cfg节点对象target_node
target_node = cfg.model.get_any_node(addr,anyaddr=True)
# 2.遍历函数管理器,看基本块地址是否在函数内,若在,则说明指令属于该函数
target_func = None
for _,func in self._cfg.kb.functions.items():
if block_addr in func.block_addrs:
target_func = func
break
print(target_func.name)
同样的,如果已知指令地址和其所在的基本块,获取指令在基本块的索引,可以用下面的代码来实现:
# 从指令地址addr挖出指令在基本块的索引
def find_index(addr):
# 1.获取指令所在的基本块
node = cfg.model.get_any_node(addr,anyaddr=True)
# 2.遍历基本块的指令地址,找到指令对应的索引
for idx,instruction_addr in enumerate(node.instruction_addrs):
if instruction_addr == addr:
return (node.addr,idx)
# 没找到,则返回None
return (node.addr,None)
后向切片
可以发现angr的后向切片函数的参数包括控制流图cfg,控制依赖图cdg,数据依赖图ddg,以及切片开始的起点target。
BackwardSlice(cfg, cdg=cdg, ddg=ddg, targets=[ (target_node, -1) ])
其中数据依赖图可以用基于cfg构建的数据依赖图或者基于值集分析的VFG。target参数存着是一个列表,列表中包含一个元组(基本块节点,指令在基本块中的索引)。
下面的代码是官方的样例,实现了从exit函数开始做的后向切片。
>>> import angr
# Load the project
>>> b = angr.Project("examples/fauxware/fauxware", load_options={"auto_load_libs": False})
# 要基于CFG生成数据依赖图的话,需要在生成CFG的时候添加下面两个选项
# 1. 保留所有状态 keep_state=True
# 2. 保存内存、寄存器和临时变量的访问angr.options.refs option
>>> cfg = b.analyses.CFGEmulated(keep_state=True,
... state_add_options=angr.sim_options.refs,
... context_sensitivity_level=2)
# 生成控制依赖图
>>> cdg = b.analyses.CDG(cfg)
# 生成数据依赖图,或者用angr的vsa生成VFG,也可以传入切片的ddg参数中去
>>> ddg = b.analyses.DDG(cfg)
# See where we wanna go... let’s go to the exit() call, which is modeled as a
# SimProcedure.
>>> target_func = cfg.kb.functions.function(name="exit")
# 获取一个CFG的节点实例
>>> target_node = cfg.model.get_any_node(target_func.addr)
# 获取切片
# targets是一个列表,每个元素是CodeLocation对象或者是一个元组包含CFGNode节点和语句ID。
# ID是-1表示CFGNode的节点的开始,由于一个simprocedure是没有任何语句的,所以需要设置为-1
>>> bs = b.analyses.BackwardSlice(cfg, cdg=cdg, ddg=ddg,control_flow_slice=True, targets=[ (target_node, -1) ])
# 使用切片
# 输出控制流切片的结果,如果可视化CFG图看的话,会发现这个切片的结果基本上就是从reject一路推回main函数的CFG节点
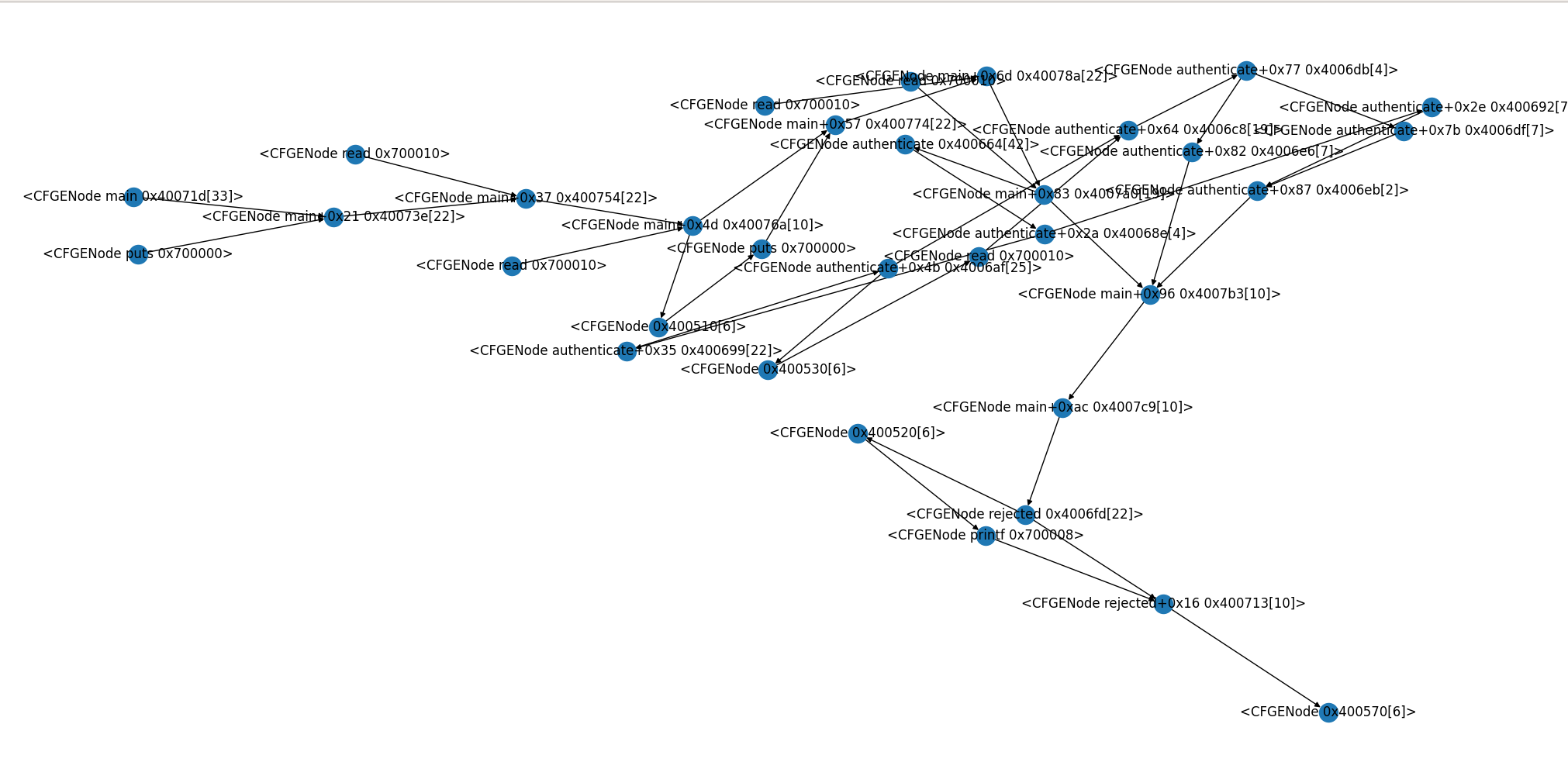
>>> print([hex(node.addr) for node in bs.cfg_nodes_in_slice])
['0x400713', '0x400570', '0x4006fd', '0x700008', '0x400520', '0x4007c9', '0x4007b3', '0x4007a0', '0x4006eb', '0x4006e6', '0x4006db', '0x4006c8', '0x4006af', '0x700010', '0x400530', '0x400699', '0x40068e', '0x400664', '0x40078a', '0x700010', '0x400774', '0x700010', '0x40076a', '0x700000', '0x400510', '0x400754', '0x700010', '0x40073e', '0x700010', '0x40071d', '0x700000', '0x400692', '0x4006df']
# 输出切片中每个基本块里选的指令
# 由于我们选择的是exit函数作为target,exit的参数是常数,也就没有数据依赖,所以chosen_statements这个结果应该是空集合。
# 但由于我们加上了control_flow_slice=True,所以会输出如下结果:
>>> print(bs.chosen_statements)
{4195696: True, 4196115: True, 7340040: True, 4195616: True, 4196093: True, 4196297: True, 4196275: True, 4196070: True, 4196059: True, 4196040: True, 7340048: True, 4195632: True, 4196015: True, 4195993: True, 4195982: True, 4195940: True, 4196256: True, 4196234: True, 4196212: True, 7340032: True, 4195600: True, 4196202: True, 4196180: True, 4196158: True, 4196125: True, 4196075: True, 4196063: True, 4195986: True}
# 问题来了,这里输出的结果是28个基本块,而上面cfg_nodes_in_slice的结果是33个基本块。
# 将这两个列表求差集,发现差集为空集。
# 实际上,可以发现cfg_nodes_in_slice中有许多重复的基本块。而chosen_statements是放在字典中的,自动做了个去重的操作。
# 因此,求控制流切片的话,两个接口都可以用的。
>>> print(bs.chosen_statements.keys())
['0x400570', '0x400713', '0x700008', '0x400520', '0x4006fd', '0x4007c9', '0x4007b3', '0x4006e6', '0x4006db', '0x4006c8', '0x700010', '0x400530', '0x4006af', '0x400699', '0x40068e', '0x400664', '0x4007a0', '0x40078a', '0x400774', '0x700000', '0x400510', '0x40076a', '0x400754', '0x40073e', '0x40071d', '0x4006eb', '0x4006df', '0x400692']
# 如果将runs_in_slice的图的节点和边与cfg_nodes_in_slice的图进行比较,二者的节点和边的集合都是相同的。
# 可以理解为runs_in_slice是cfg_nodes_in_slice的去重版本。
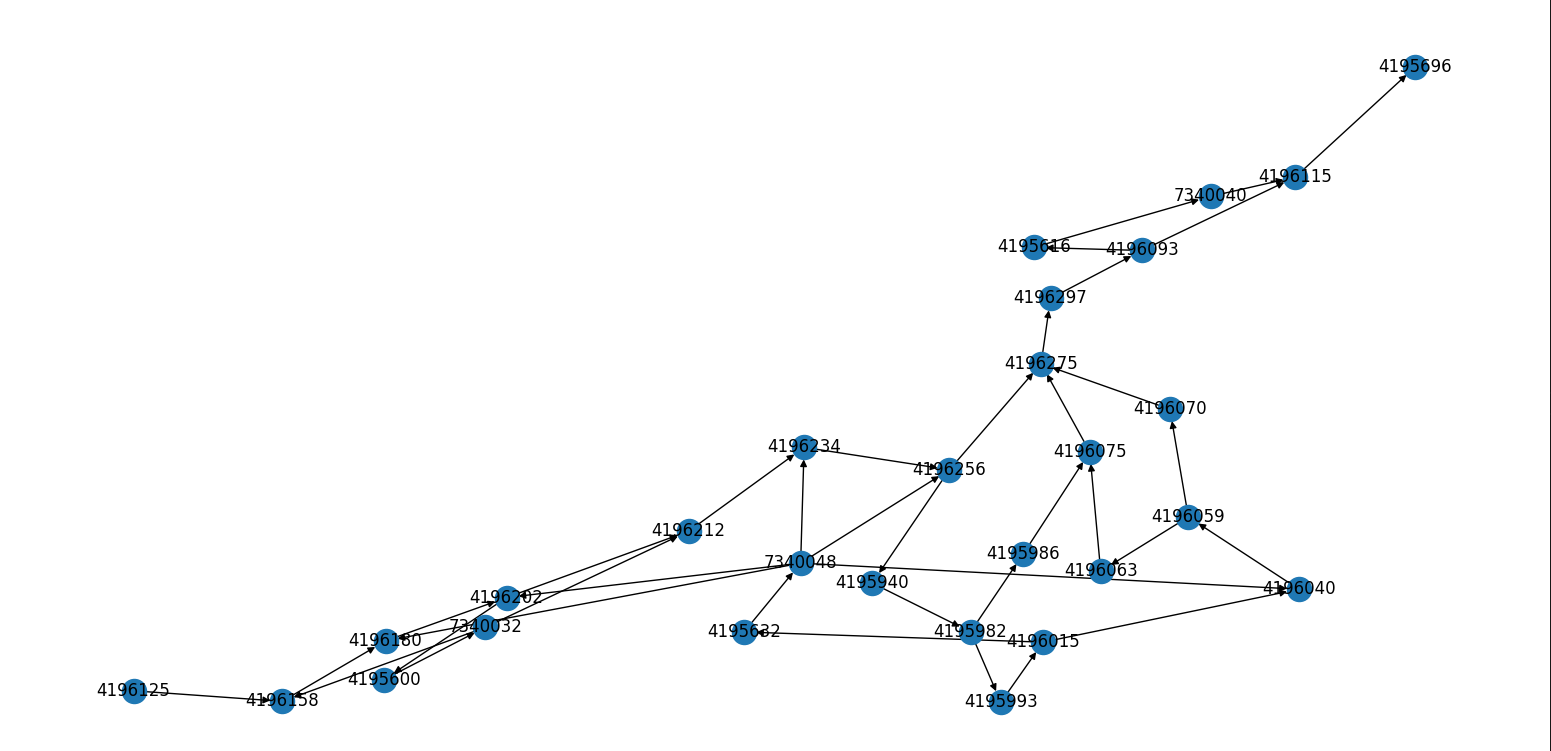
>>> print([hex(item) for item in bs.runs_in_slice])
['0x400713', '0x400570', '0x4006fd', '0x700008', '0x400520', '0x4007c9', '0x4007b3', '0x4007a0', '0x4006eb', '0x4006e6', '0x4006db', '0x4006c8', '0x4006af', '0x700010', '0x400530', '0x400699', '0x40068e', '0x400664', '0x40078a', '0x400774', '0x40076a', '0x700000', '0x400510', '0x400754', '0x40073e', '0x40071d', '0x400692', '0x4006df']
此外,如果可视化runs_in_slice和cfg_nodes_in_slice,也能很明显地看出二者的节点类型不一样,但图的拓扑结构差不多。
runs_in_slice的每个节点都是基本块的地址。
cfg_nodes_in_slice的每个节点都是CFG节点实例。
很遗憾没有找到比较好的例子来说明分析数据依赖的切片。实际用数据流切片中,我发现使用chosen_statements会打印出如下的字典,字典的键为基本块的地址,值为基本块内的索引,也就是第几条指令。可以发现索引中出现了大量的-2,推测指的是跳转指令上面的那一条指令。

总结
本文只是很粗浅地介绍了angr的静态分析功能的基本使用,如果要实现文章中没介绍的功能,还是要深入angr的源码去看这些对象有哪些属性和方法。angr的大部分的静态分析的源码都在angr/angr/analyses目录下,也有一些关于cfg,function的信息是在angr/angr/knowledge_plugins下。
此外,如果觉得看源码还是看不懂API是怎么用的,也可以直接去看angr/tests目录下有没有对应API的测试脚本。
希望这篇文章对大家有所帮助,后续有机会的话,将继续更新关于angr内置的其他静态分析功能,比如循环、Reach Definition Analysis等。