
前言
最近分析了2个漏洞,分别是FreeBSD 内核中的CVE-2020-7454 ,Netgear路由器中的ZDI-20-709。虽然这2个漏洞所涉及的厂商设备不同,但是对其Root Cause 分析,可以得到这2个漏洞出现的根本原因是他们都使用了一种错误的编程范式—使用多个变量表示同一个状态。本文侧重对漏洞根因的分析,目的是能够举一反三,在别的厂商设备中找到根因相同的漏洞。PS:本文不包含对漏洞利用的详细叙述。
CVE-2020-7454
官方公布的漏洞的原因是libalias库中的函数对UDP包的header访问之前,并没有对其数据长度进行验证,最终导致了一个OOB的越界的读或者写漏洞。
libalias(3) packet handlers do not properly validate the packet length before
accessing the protocol headers. As a result, if a libalias(3) module does
not properly validate the packet length before accessing the protocol header,
it is possible for an out of bound read or write condition to occur.
这个漏洞出现在FreeBSD内核的libalias库中,这个库的主要作用是对IP包进行aliasing和dealiasing,以实现NAT功能,同时libalias库还实现了一些和协议转换相关的功能。具体包含漏洞的源码为
AliasHandleUdpNbtNS(...)
{
/*...省略....*/
/* Calculate data length of UDP packet */
uh = (struct udphdr *)ip_next(pip);
nsh = (NbtNSHeader *)udp_next(uh);
p = (u_char *) (nsh + 1);
pmax = (char *)uh + ntohs(uh->uh_ulen); /* <--- (1) */
/* ... 省略... */
if (ntohs(nsh->ancount) != 0) {
p = AliasHandleResource(
ntohs(nsh->ancount),
(NBTNsResource *) p,
pmax,
&nbtarg
);
}
/* ... 省略... */
}
AliasHandleResource(..., char *pmax, ...)
{
/* ... 省略... */
switch (ntohs(q->type)) {
case RR_TYPE_NB:
q = (NBTNsResource *) AliasHandleResourceNB(
q,
pmax,
nbtarg
);
break;
/* ... 省略... */
}
在注释1的地方,内核直接从payload中读取UDP包的header,获得UDP数据包的length字段。注意这个地方很重要,payload是攻击者可控的,UDP包的长度也是攻击者可以修改的,UDP header中的length字段标识了UDP的负载和头的总长度。
继续分析代码,如果满足了一定的限制条件就可以进入到AliasHandleResource这个子函数的处理分支,进而可以到达AliasHandleResourceNB函数,这个函数是直接触发了OOB漏洞的函数。下面是AliasHandleResourceNB的部分源码
AliasHandleResourceNB(..., char *pmax, ...)
{
/* ... 省略 ... */
while (nb != NULL && bcount != 0) {
if ((char *)(nb + 1) > pmax) { /* <--- (2) */
nb = NULL;
break;
}
if (!bcmp(&nbtarg->oldaddr, &nb->addr, sizeof(struct in_addr))) { /* <--- (3) /
/* ... snip ... */
nb->addr = nbtarg->newaddr; /* <--- (4) */
}
/* ... 省略 ... */
nb = (NBTNsRNB *) ((u_char *) nb + SizeOfNsRNB);
}
}
pmax的值就是从udp header中读取的UDP length与upd头的指针相加得到的偏移,简言之就是假设的udp的尾部,之所以说是假设的,因为有两种方式可以索引这个udp的尾部,第一种就是上述的方法,利用udp头的偏移和udp length之和索引。另一种方式就是通过ip包索引,ip header偏移与ip length之和也是索引的udp的尾部。如果udp包头的header length没有被恶意更改的情况下,这两种方式的索引都是可以的,但是如果udp 包的头部被恶意修改了,那么就会造成两种索引方式的不同步,udp包头的索引方式就是错误的。
而AliasHandleResourceNB这个子函数就是使用了错误的索引方式,以udp header偏移和udp length之和作为udp尾部的索引。标注2处是循环的终止条件,就是一直处理直到达到pmax位置,如果udp length被恶意改成很大的值,那么就会造成pmax位置已经超出了udp包payload,最终造成越界访问。标注3出现了一次越界读取,标注4则出现了越界写。
分析这个漏洞产生的根本原因就是有两种方式可以索引udp的尾部状态,如果对两种索引方式进行混用,那么一旦没有保持两种索引方式的同步,就会导致危险。
笔者分析了这个根因之后,也试图直接再在FreeBSD的源码中搜索采用两种方式索引UDP尾部的代码,期望能够找到类似的漏洞。经过搜索共发现了15个文件中34处出现通过UDP header索引的方式的代码。
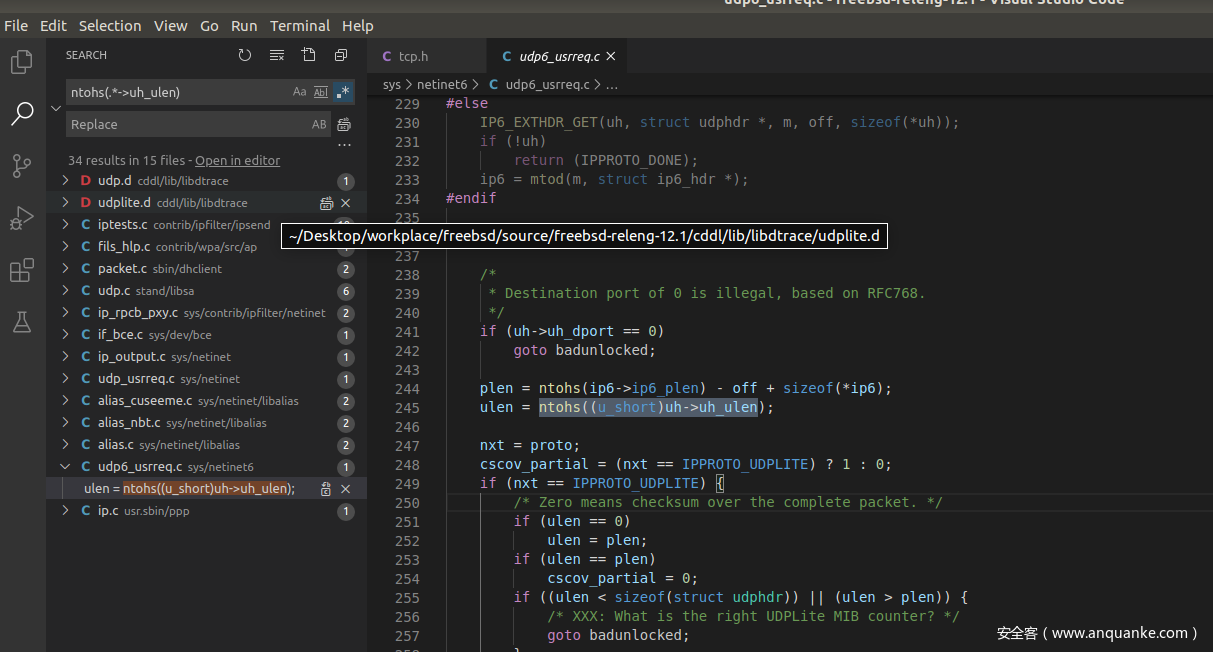
经过简单分析,除了已经爆出的alias库中的漏洞,还有udp6_usrreq.c中出现了混用
/*
* Destination port of 0 is illegal, based on RFC768.
*/
if (uh->uh_dport == 0)
goto badunlocked;
plen = ntohs(ip6->ip6_plen) - off + sizeof(*ip6);
ulen = ntohs((u_short)uh->uh_ulen);
nxt = proto;
cscov_partial = (nxt == IPPROTO_UDPLITE) ? 1 : 0;
if (nxt == IPPROTO_UDPLITE) {
/* Zero means checksum over the complete packet. */
if (ulen == 0)
ulen = plen;
if (ulen == plen) ---------------->1
cscov_partial = 0;
if ((ulen < sizeof(struct udphdr)) || (ulen > plen)) {
/* XXX: What is the right UDPLite MIB counter? */
goto badunlocked;
}
if (uh->uh_sum == 0) {
/* XXX: What is the right UDPLite MIB counter? */
goto badunlocked;
}
}
虽然出现了混用,但是可以看到代码在一开始就对这两种索引方式进行了同步,所以这个地方也是不存在漏洞的。所以很遗憾笔者没有再找到别的漏洞,但是ZDI博文中的作者利用这种方法找到了FreeBSD中的另外一处相同原因的漏洞。
AliasHandleCUSeeMeIn(...)
{
/* ... 省略 ... */
end = (char *)ud + ntohs(ud->uh_ulen); /* <--- untrusted UDP header length */
if ((char *)oc <= end) {
/* ... 省略 ... */
if (ntohs(cu->data_type) == 101)
/* Find and change our address */
for (i = 0; (char *)(ci + 1) <= end && i < oc->client_count; i++, ci++)
if (ci->address == (u_int32_t) alias_addr.s_addr) { /* <--- OOBR */
ci->address = (u_int32_t) original_addr.s_addr; /* <--- OOBW */
break;
}
}
}
官方对此漏洞修复方式为:

即增加对UDP包头的验证,确保这两种对UDP尾部的索引方式是相同的。
ZDI-20-709
这个漏洞是一个无需认证的漏洞,发现者在追踪数据流的时候,发现在正常的认证逻辑之前存在一个无需认证的逻辑分支
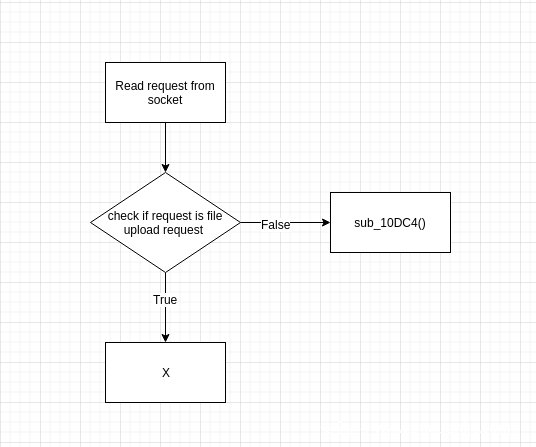
这个无需认证的分支是一个文件上传的请求分支,这种无需认证的分支是安全审计的重点环节。在这个逻辑中存在一个漏洞,可以导致堆溢出。其原型就是
buffer = malloc(attacker_control_size)
memcpy(buffer, file_content, file_content_size)
这个漏洞根因也是由于有两种方式表示一个上传文件的长度,第一种方式是根据POST请求中文件字段的长度计算出来的,第二种是通过Content-Length字段计算出来的。一般情况下这二者是相同的,但是作者通过在URL中添加Content-Length字段,最终导致了二者的不同步。
当发现malloc的长度变量和memcpy中的长度变量并不是由一个变量而来的,而本来这两个变量应该是同步的,最好是同一个变量。
小结
除了这种常见的多个变量表示同一个长度信息造成的不同步,其他信息的不同步也同样可以导致漏洞,比如一个经典漏洞,OpenSolaris内核中的CVE-2008-568,它是由于设置了两种error状态的返回方式,一种是通过函数返回值返回错误信息,一种是通过全局变量返回错误信息,但是在一些逻辑中会造成二者的不同步,最终导致越界读写等。如果单纯的分析漏洞的表面原因,很难将这些漏洞联系起来,如果将这些漏洞原因深层思考,得到漏洞的Root Cause,就可以抽象出一种经常出现的漏洞原型-多个变量表示同一状态。