
作者:donky16@360云安全
本文主要讨论,利用waf和后端程序对multipart/form-data的解析差异,造成对waf的bypass。
背景介绍
传统waf以规则匹配为主,如果只是无差别的使用规则匹配整个数据包,当规则数量逐渐变多,会造成更多性能损耗,当然还会发生误报情况。为了能够解决这些问题,需要对数据包进行解析,进行精准位置的规则匹配。
正常业务中上传表单使用普遍,不仅能够传参,还可以进行文件的上传,当然这也是一个很好的攻击点,waf想要能够精准拦截针对表单的攻击,需要进行multipart/form-data格式数据的解析,并针对每个部分,如参数值,文件名,文件内容进行针对性的规则匹配拦截。
虽然RFC规范了multipart/form-data相关的格式与解析,但是由于不同后端程序的实现机制不同,而且RFC相关文档也会进行增加补充,最终导致解析方式各不相同。对于waf来说,很难做到对各个后端程序进行定制化解析,尤其是云waf更加无法实现。
由于篇幅有限,此文分为上下两个部分,第一部分主要介绍multipart/form-data中boundary的格式与解析规范,并分析不同程序对boundary解析的异同,和一些造成waf解析失败或和后端解析产生差异的方法;第二部分会介绍Content-Disposition/Content-Type/Content-Transfer-Encoding的内容,介绍多种绕过waf解析的方式,并对Content-Disposition中的参数和boundary参数的解析进行比较,分析其解析不同的原因。
multipart/form-data相关RFC:
- 基于表单的文件上传: RFC1867
- multipart/form-data: RFC7578
- Multipart Media Type: RFC2046#section-5.1
解析环境
Flask/Werkzeug解析环境:docker/httpbin
Java解析环境:Windows10 pro 20H2/Tomcat9.0.35/jdk1.8.0_271/commons-fileupload
Java输出代码:
String result = "";
DiskFileItemFactory factoy = new DiskFileItemFactory();
ServletFileUpload sfu = new ServletFileUpload(factoy);
try {
List<FileItem> list = sfu.parseRequest(req);
for (FileItem fileItem : list) {
if (fileItem.getName() == null) {
result += fileItem.getFieldName() + ": " + fileItem.getString() + "\n";
} else {
result += "filename: " + fileItem.getName() + " " + fileItem.getFieldName() + ": " + fileItem.getString() + "\n";
}
}
} catch (FileUploadException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
PHP解析环境:Ubuntu18.04/Apache2.4.29/PHP7.2.24
PHP输出代码:
<?php
var_dump($_FILES);
var_dump($_POST);
基础格式
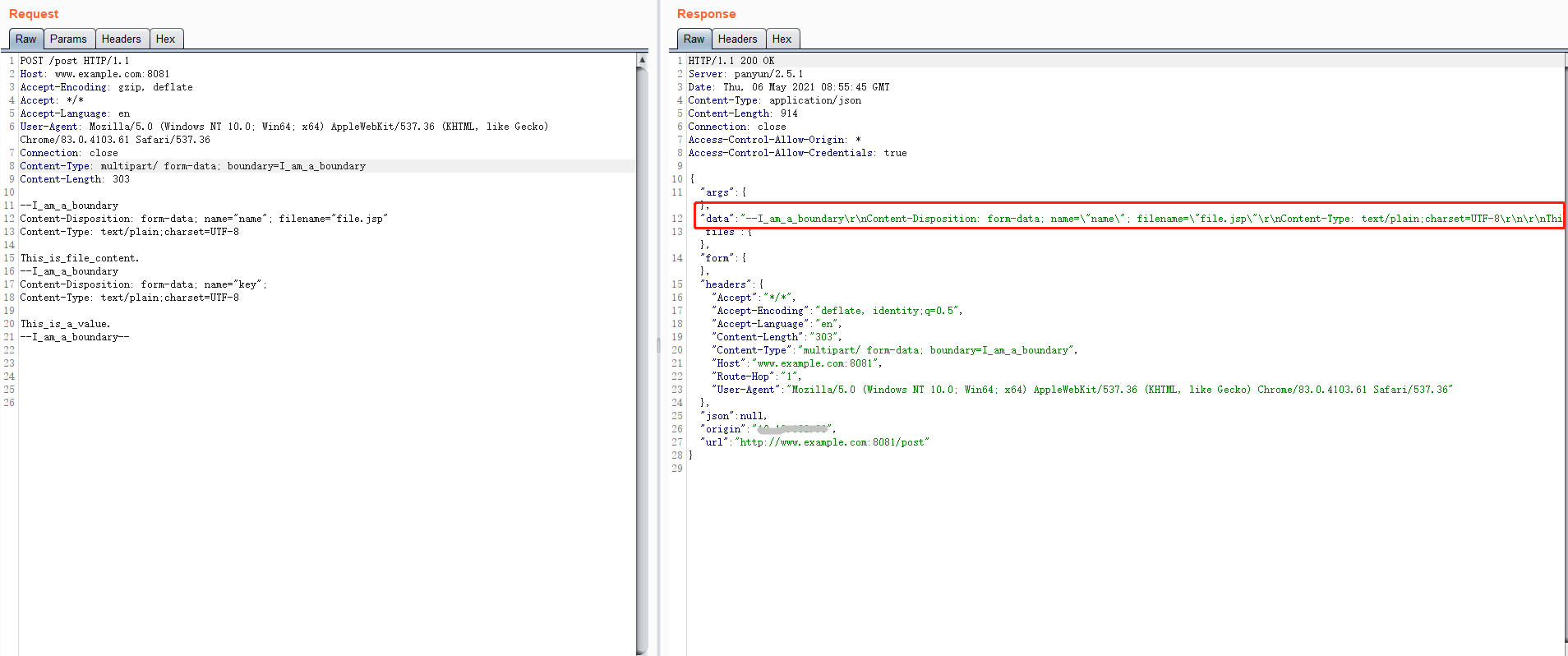
POST /post HTTP/1.1
Host: www.example.com:8081
Accept-Encoding: gzip, deflate
Accept: */*
Accept-Language: en
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36
Connection: close
Content-Type: multipart/form-data; boundary=I_am_a_boundary
Content-Length: 303
--I_am_a_boundary
Content-Disposition: form-data; name="name"; filename="file.jsp"
Content-Type: text/plain;charset=UTF-8
This_is_file_content.
--I_am_a_boundary
Content-Disposition: form-data; name="key";
Content-Type: text/plain;charset=UTF-8
This_is_a_value.
--I_am_a_boundary--
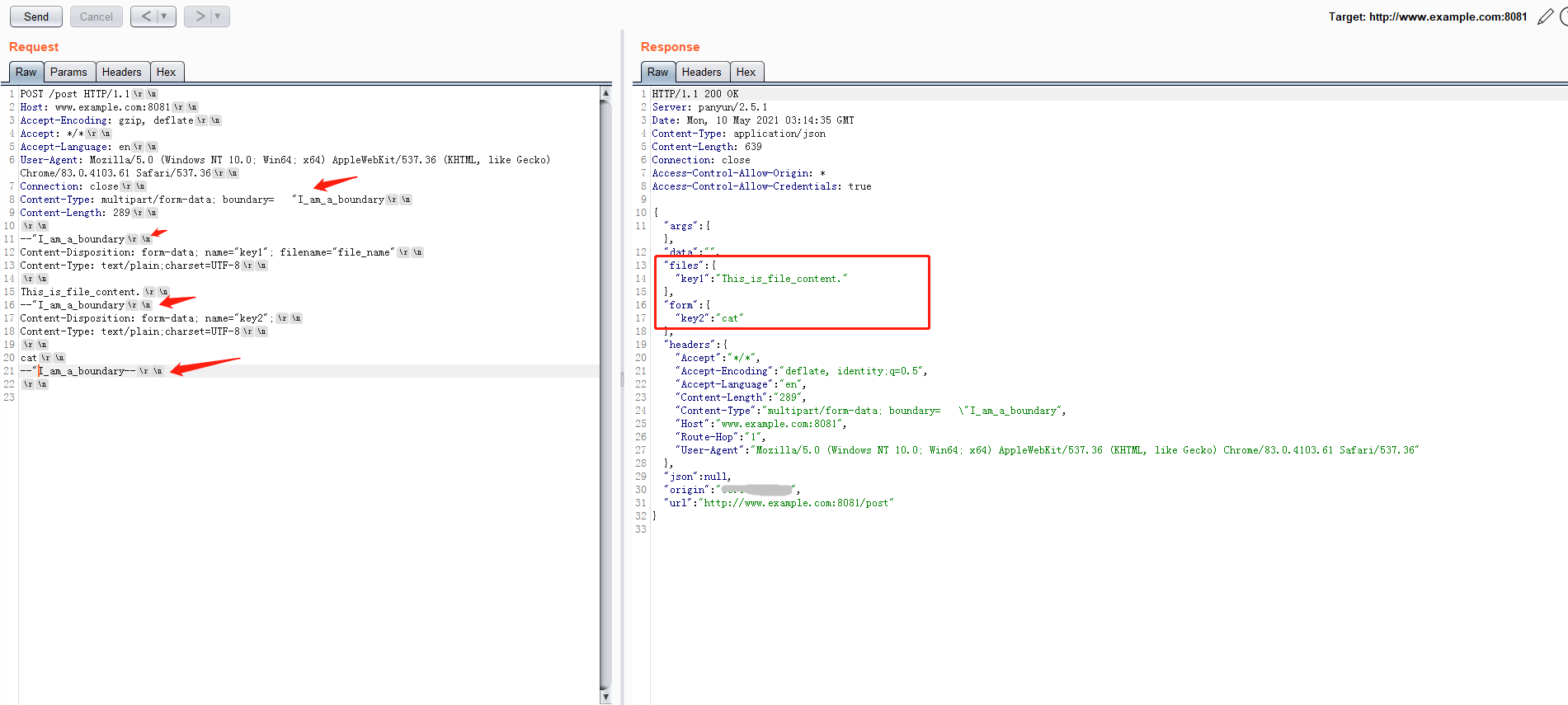
此表单数据含有一个文件,name为name,filename为file.jsp,file_content为This_is_file_content.,还有一个非文件的参数,其name为key,value为This_is_a_value.。
httpbin解析结果
{
"args": {},
"data": "",
"files": {
"name": "This_is_file_content."
},
"form": {
"key": "This_is_a_value."
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "deflate, identity;q=0.5",
"Accept-Language": "en",
"Content-Length": "303",
"Content-Type": "multipart/form-data; boundary=I_am_a_boundary",
"Host": "www.example.com:8081",
"Route-Hop": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
},
"json": null,
"origin": "10.1.1.1",
"url": "http://www.example.com:8081/post"
}
详细解析
1. Content-Type
Content-Type: multipart/form-data; boundary=I_am_a_boundary
对于上传表单类型,Content-Type必须为multipart/form-data,并且后面要跟一个边界参数键值对(boundary),在表单中分割各部分使用。
倘若multipart/form-data编写错误,或者不写boundary,那么后端将无法准确解析这个表单的每个具体内容。
2. Boundary
boundary: RFC2046
boundary需要按照以下BNF巴科斯范式

简单解释就是,boundary不能以空格结束,但是其他位置都可以为空格,而且字符长度在1-70之间,此规定语法适用于所有multipart类型,当然并不是所有程序都按照这种规定来进行multipart的解析。
从前面介绍的multipart基础格式可以看出来,真正作为表单各部分之间分隔边界的不仅是Content-Type中boundary的值,真正的边界是由--和boundary的值和末尾的CRLF组成的分隔行,当然为了能够准确解析表单各个部分的数据,需要保证分隔行不会出现在正常的表单中的文件内容或者参数值中,所以RFC也建议使用特定的算法来生成boundary值。
flask解析结果
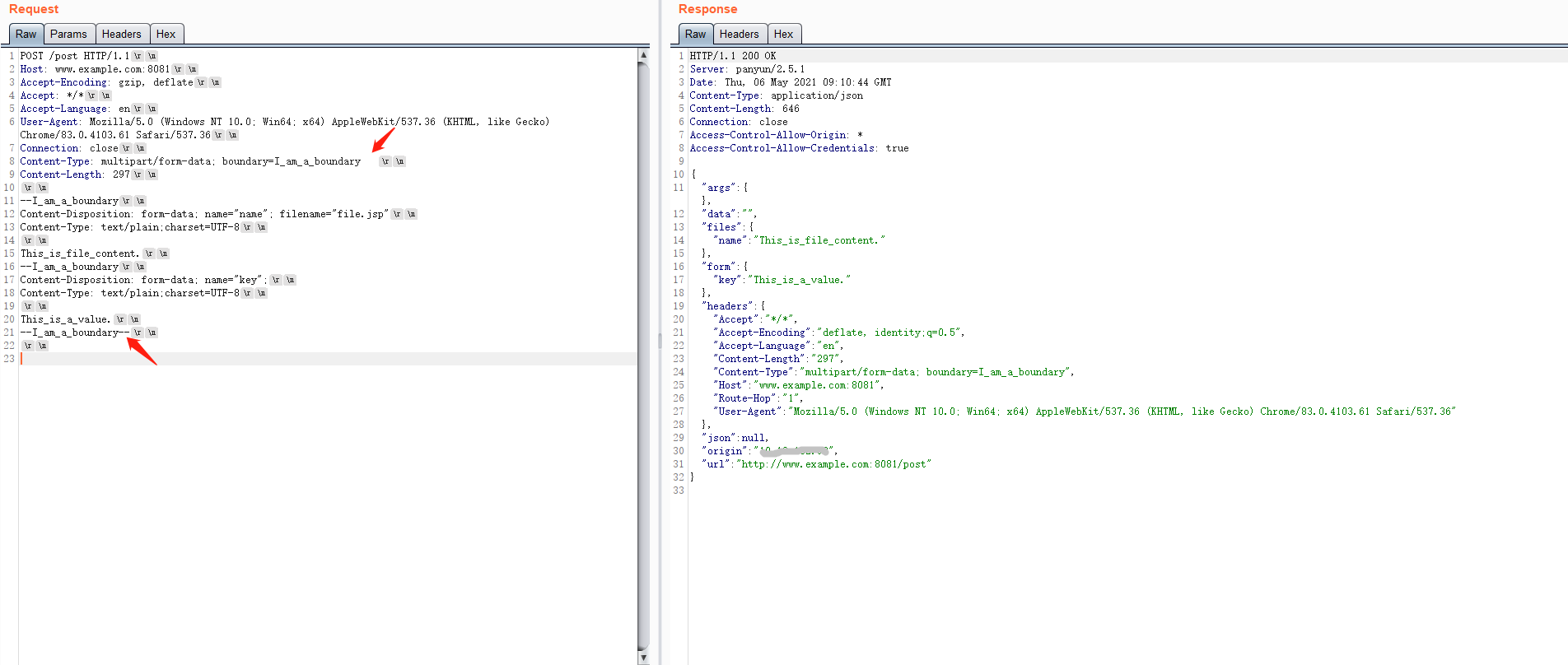
这里需要注意两个点,第一,最终表单数据最后一个分隔边界,要以--结尾。第二,RFC规定原文为

也就是说,整体的分隔边界可以含有optional linear whitespace。
空格
注:本文使用空格的地方[\r\n\t\f\v ]都可以代替使用,文中只是介绍了使用空格的结果,大家可以测试其他的,waf或者后端程序在解析\n时,会产生很多不同结果,感兴趣可自行测试。
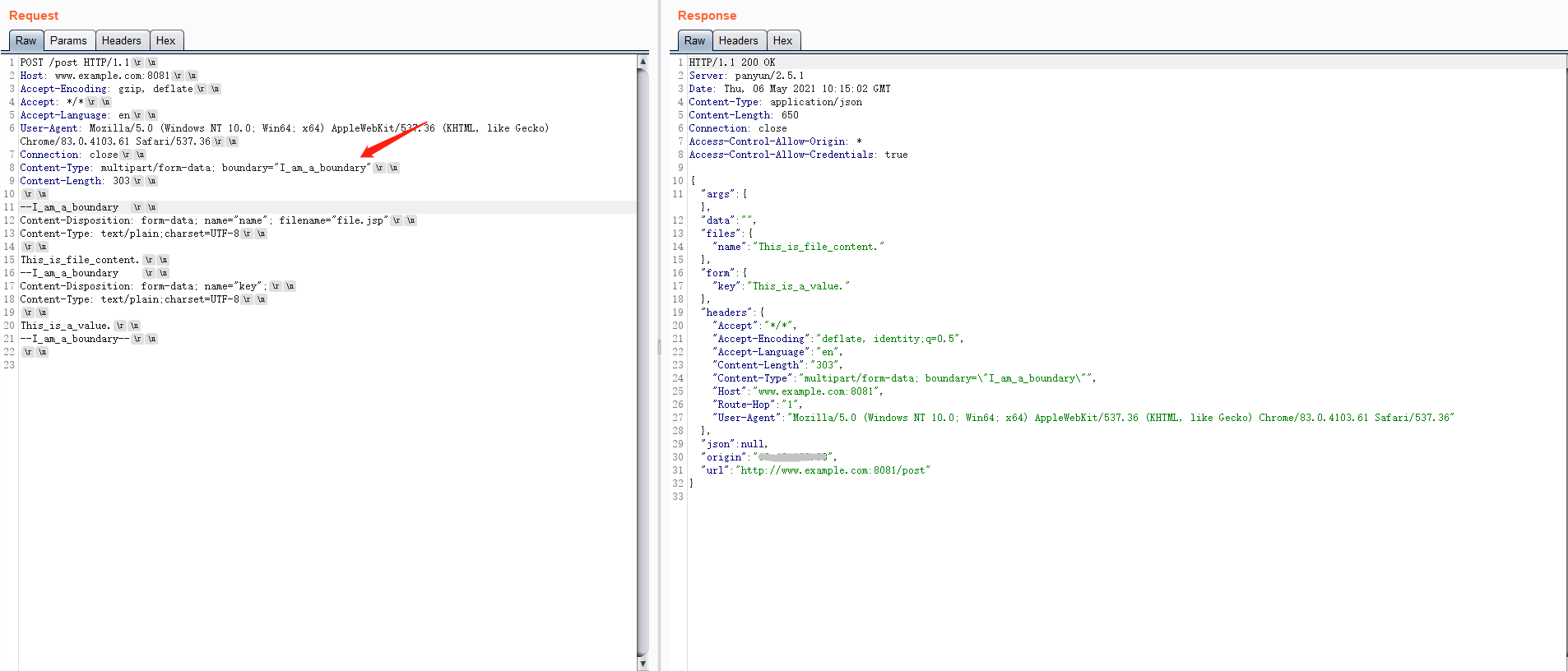
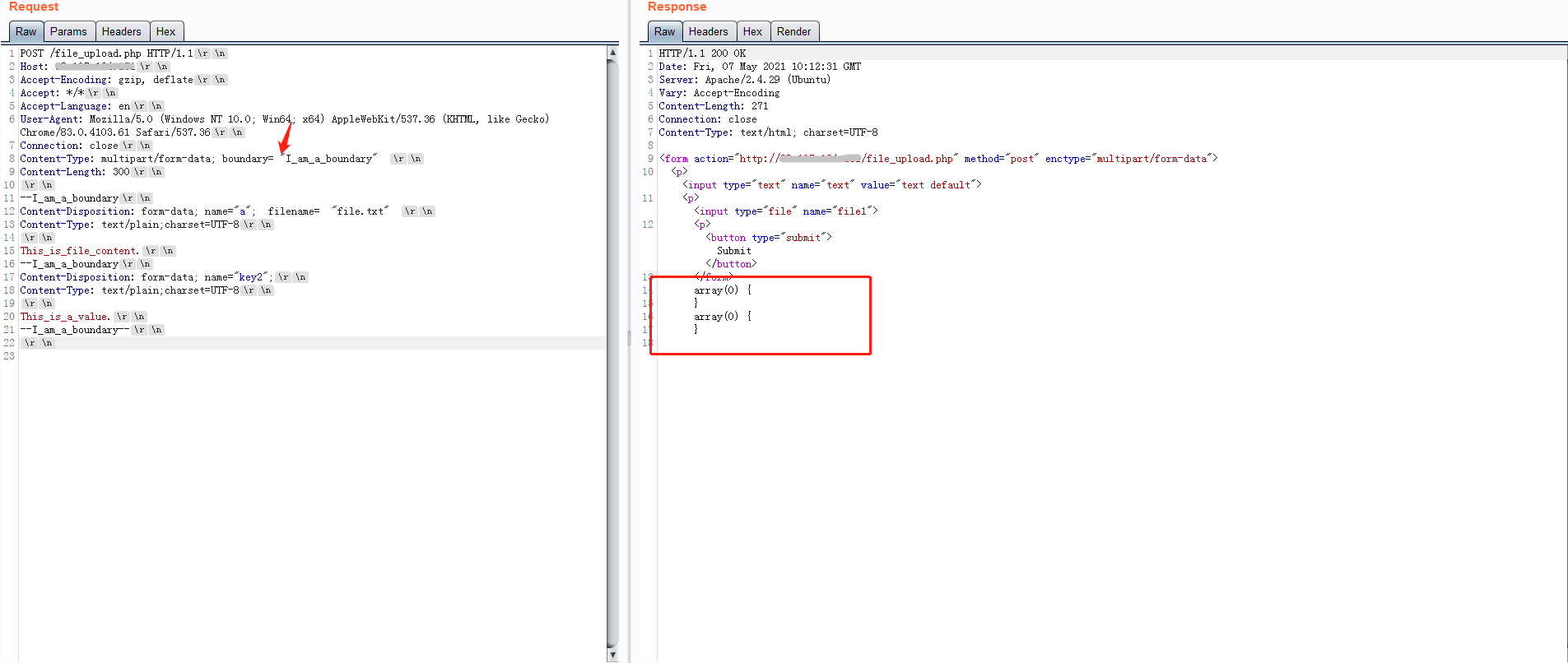
首先使用boundary的值后面加空格进行测试,flask和php都能够正常的解析出表单内容。
php解析结果
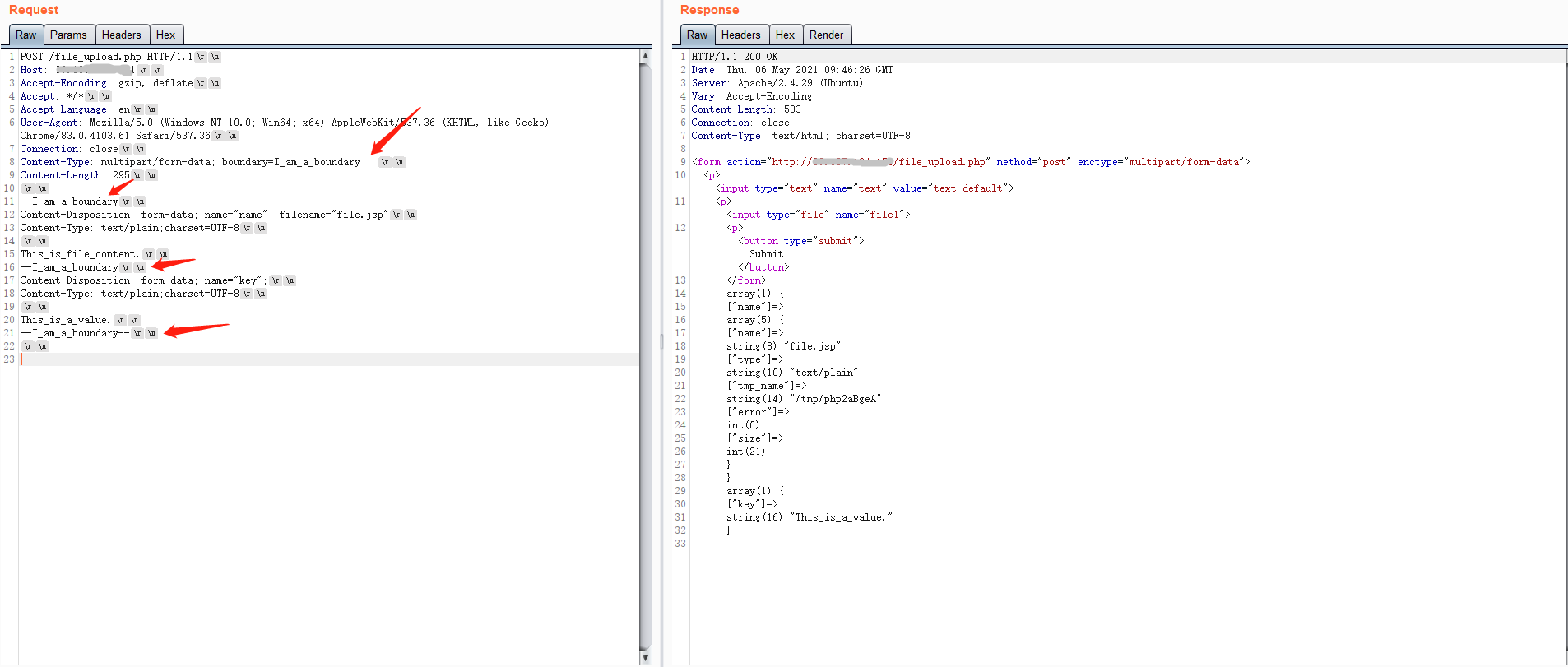
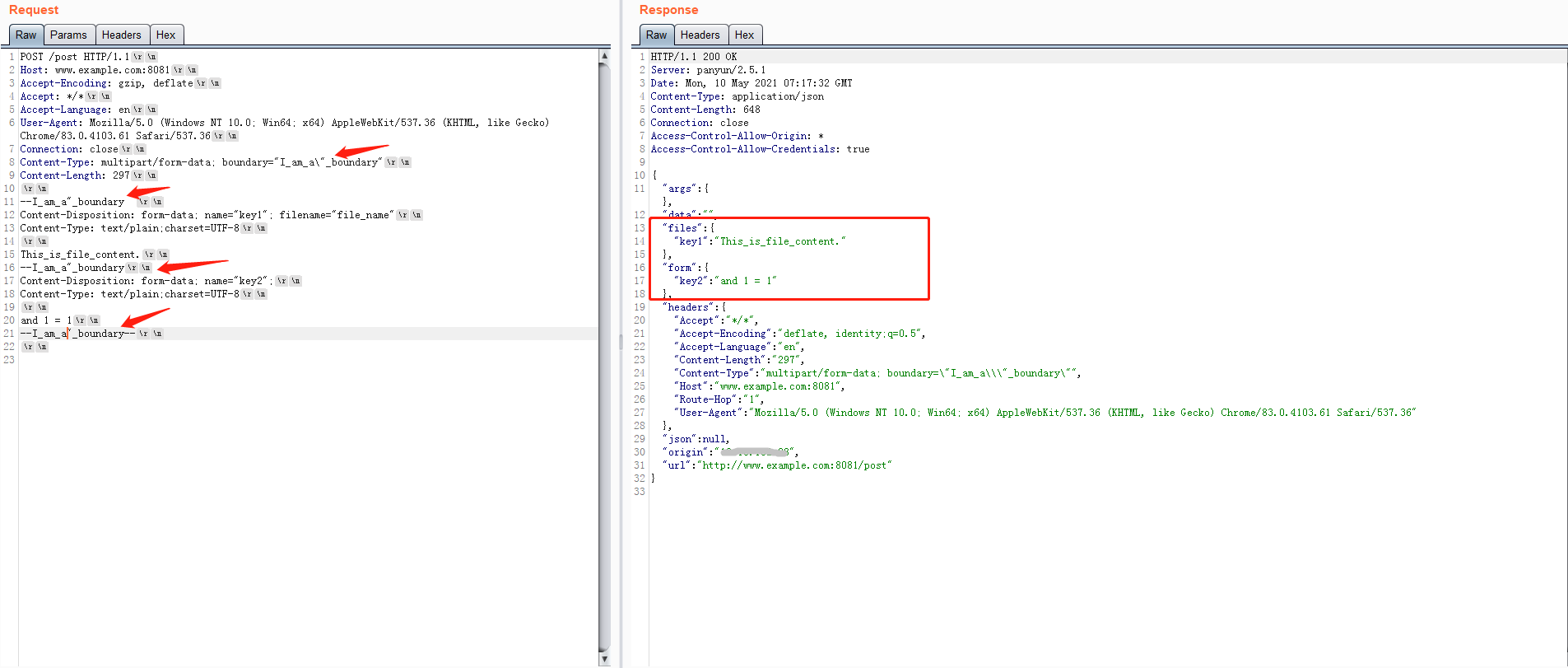
虽然boundary的值后面加了空格,但是在作为分隔行的时候并没有空格也可以正常解析,但是经测试发现如果按照RFC规定那样直接在分隔行中加入空格,效果就会不一样。
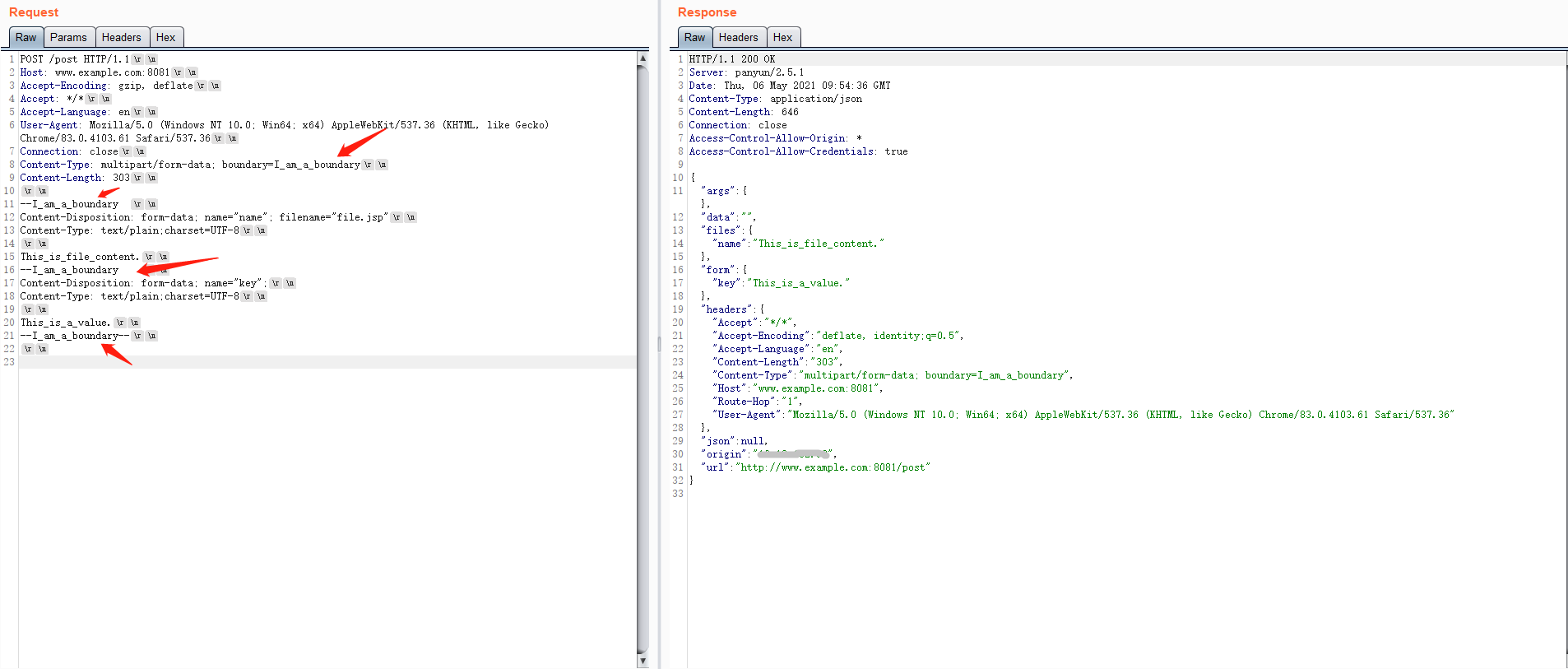
对于flask来说是按照了RFC规定实现,无论Content-Type中boundary的值后面是不加空格还是加任意空格,在表单中非结束分隔行里都可以随意加空格,都不影响表单数据解析,但是需要注意的就是,在最后的结束分隔行中,加空格会导致解析失败,下文阐述具体原因。
很有意思的是php解析过程中,在非结束分隔行中不能增加空格,而在结束分隔行中增加空格,却不会影响解析。
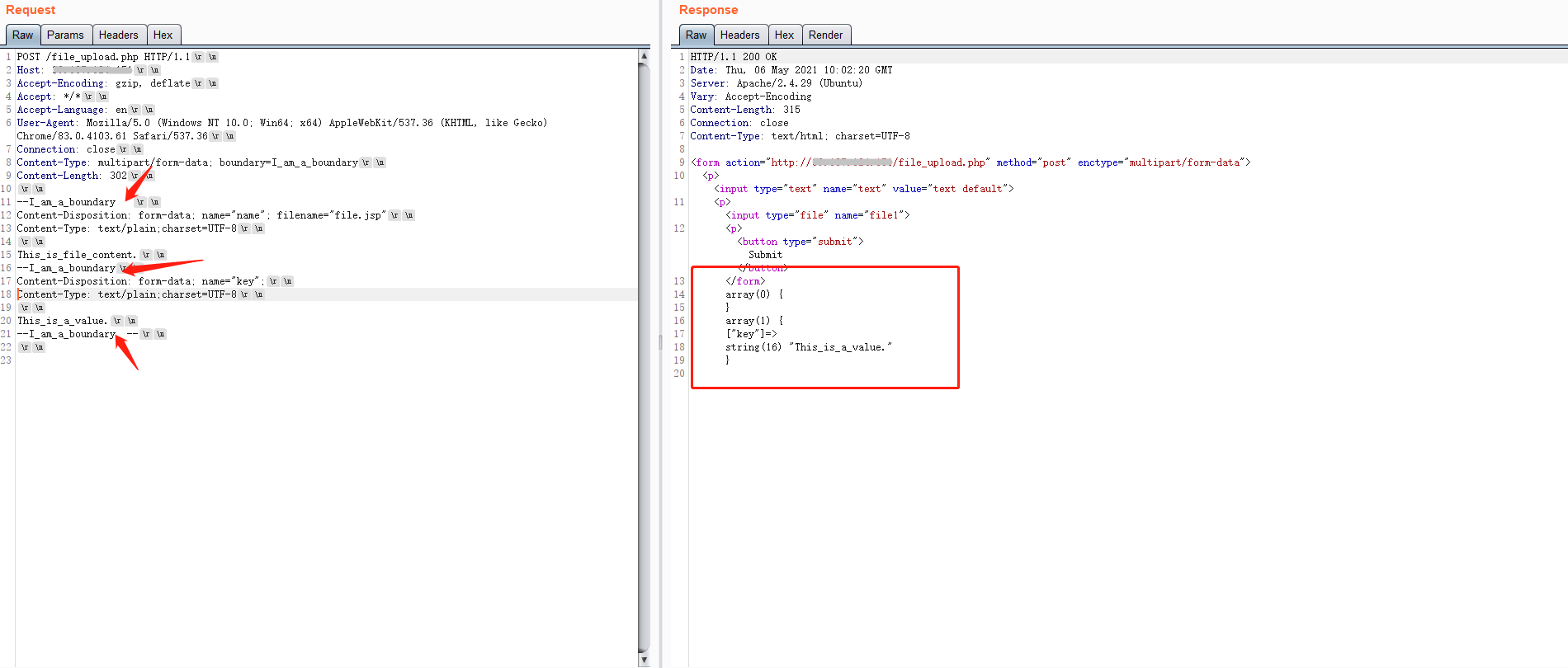
可以看到,加了空格的分隔行内的文件内容数据没有被正确解析,而没加空格的非文件参数被解析成功,而且结束分隔行中也添加了空格。
测试的时候偶然发现在如果在multipart/form-data和;之间加空格,如Content-Type: multipart/form-data ; boundary="I_am_a_boundary",flask会造成解析失败,php解析正常。
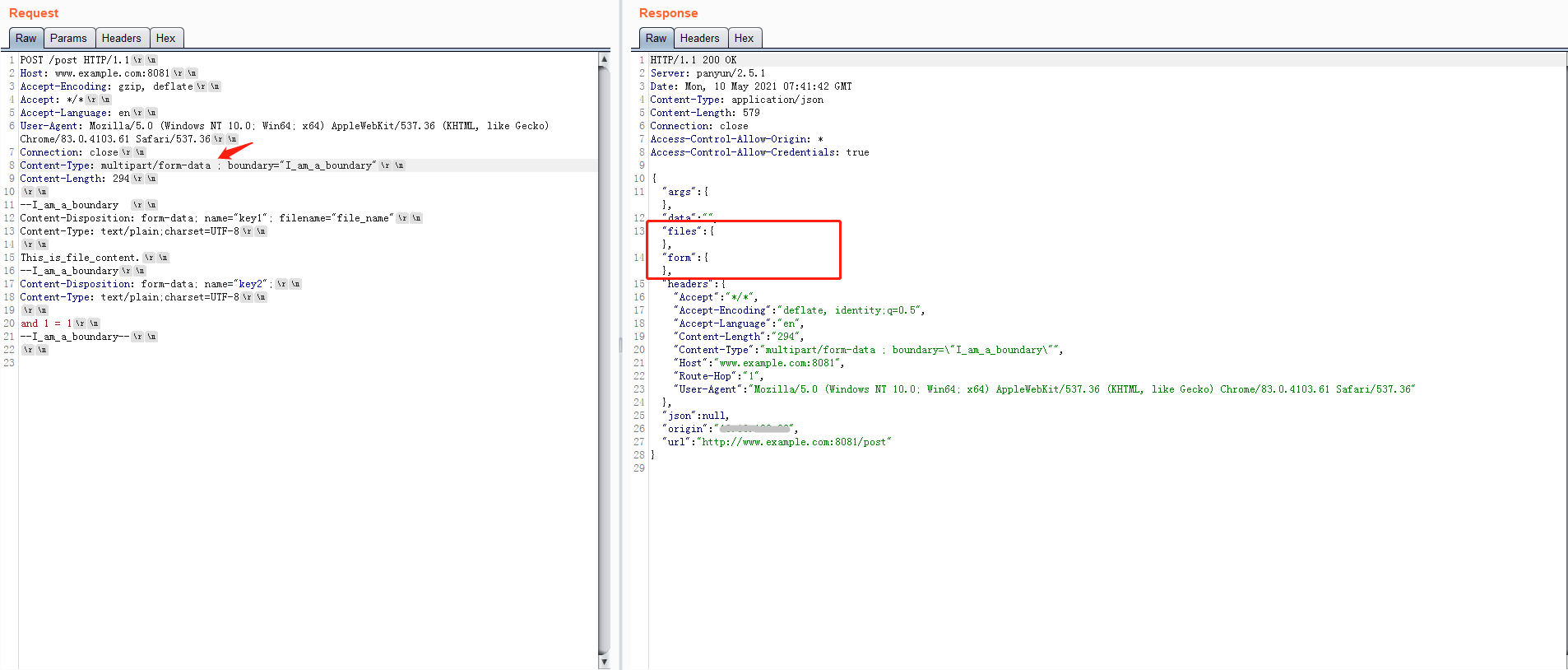
正常来说,通过正则进行匹配解析的flask应该不会这样,具体实现在werkzeug/http.py:L406。
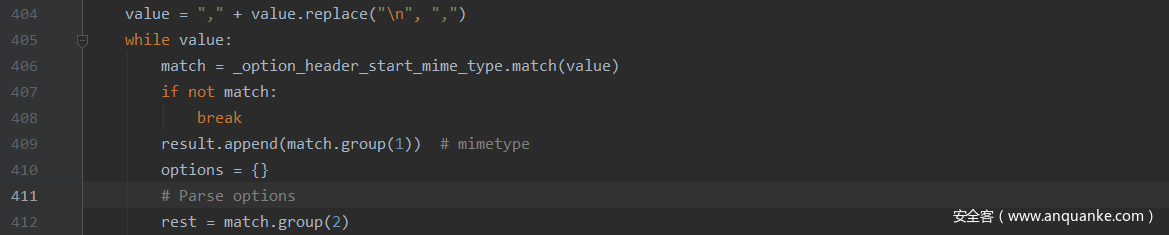
简单来说就是将Content-Type: multipart/form-data ; boundary="I_am_a_boundary"进行正则匹配,然后将第一组匹配结果当作mimetype,第二组作为rest,由后面处理boundary取值,看下这个正则。
_option_header_start_mime_type = re.compile(r",\s*([^;,\s]+)([;,]\s*.+)?")
为了看着美观,使用regex101看下。

很明显,由于第一组匹配非空字符,所以到空格处就停了,但是第二组必须是[;,]开头,导致第二组匹配值为空,无法获取boundary,最终解析失败。
双引号
boundary的值是支持用双引号进行编写的,就像是表单中的参数值一样,这样在写分隔行的时候,就可以将双引号内的内容作为boundary的值,php和flask都支持这种写法。使用单引号是无法达到效果的,这也是符合上文提到的BNF巴科斯范式的bcharsnospace的。
测试一下让重复多个双引号,或者含有未闭合的双引号或者双引号前后增加其他字符会发生什么。
Content-Type: multipart/form-data; boundary=a"I_am_a_boundary"
Content-Type: multipart/form-data; boundary= "I_am_a_boundary"
Content-Type: multipart/form-data; boundary= "I_am_a_boundary"a
Content-Type: multipart/form-data; boundary=I_am_a_boundary"
Content-Type: multipart/form-data; boundary="I_am_a_boundary
Content-Type: multipart/form-data; boundary="I_am_a_boundary"aa"
Content-Type: multipart/form-data; boundary=""I_am_a_boundary"
对于php来说相对简单,因为只要出现第一个字符不是双引号,就算是空格,都会将之作为boundary的一部分,所以前四种解析类似,当第一个字符为双引号时,会找与之对应的闭合的双引号,如果找到了,那么就会忽略之后的内容直接取双引号内内容作为boundary的值。
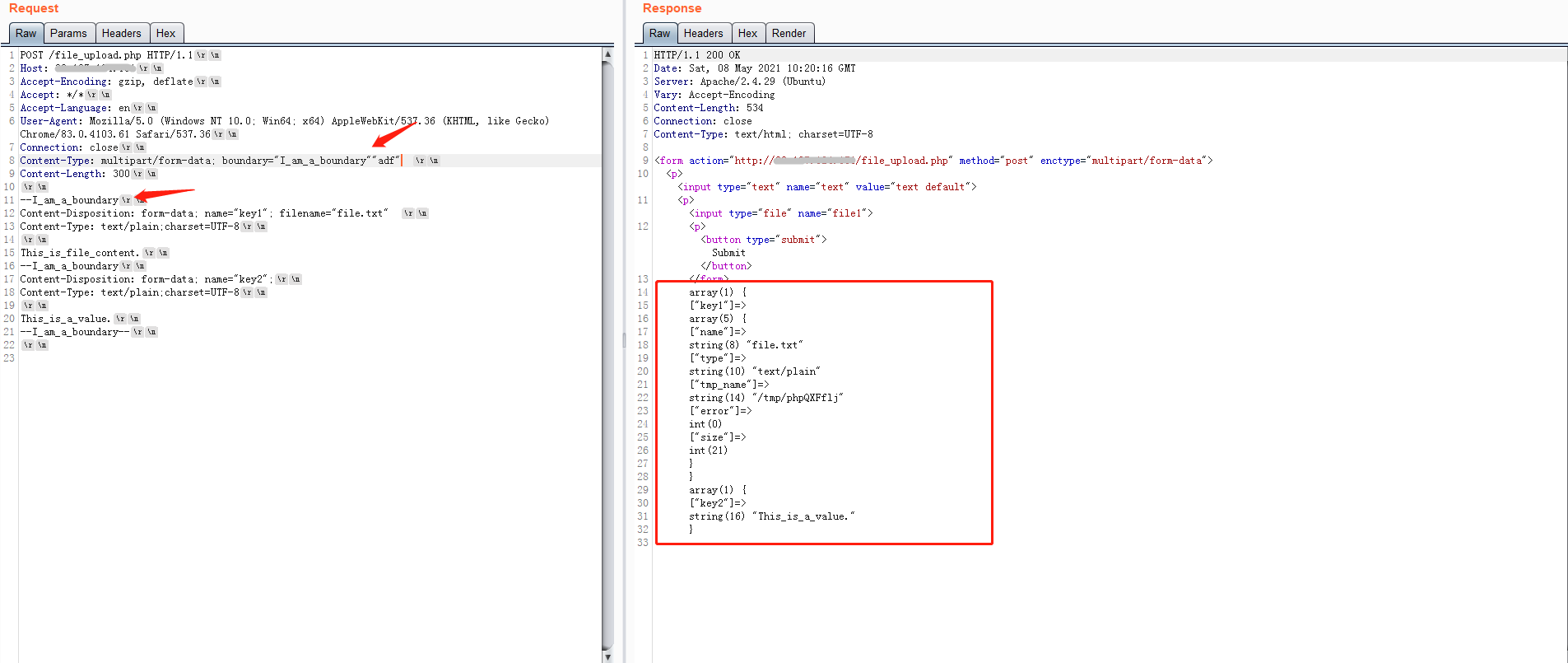
然而如果没有找到闭合双引号,就会导致boundary取值失败,无法解析multipart/form-data。
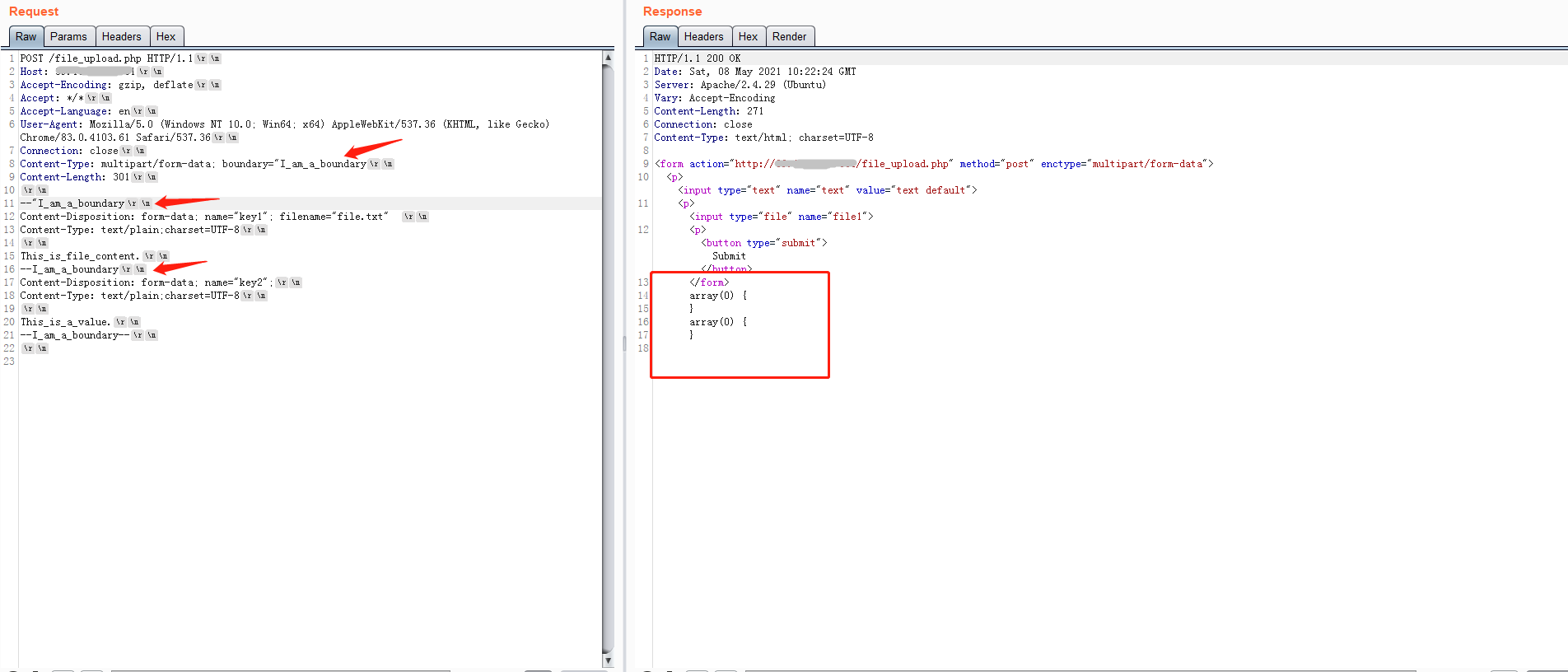
当然对于最后一种情况,会取一个空的boundary值,我也以为会解析失败,但是很搞笑的是,竟然boundary值为空,php也可以正常解析,当然也可以直接写成Content-Type: multipart/form-data; boundary=。
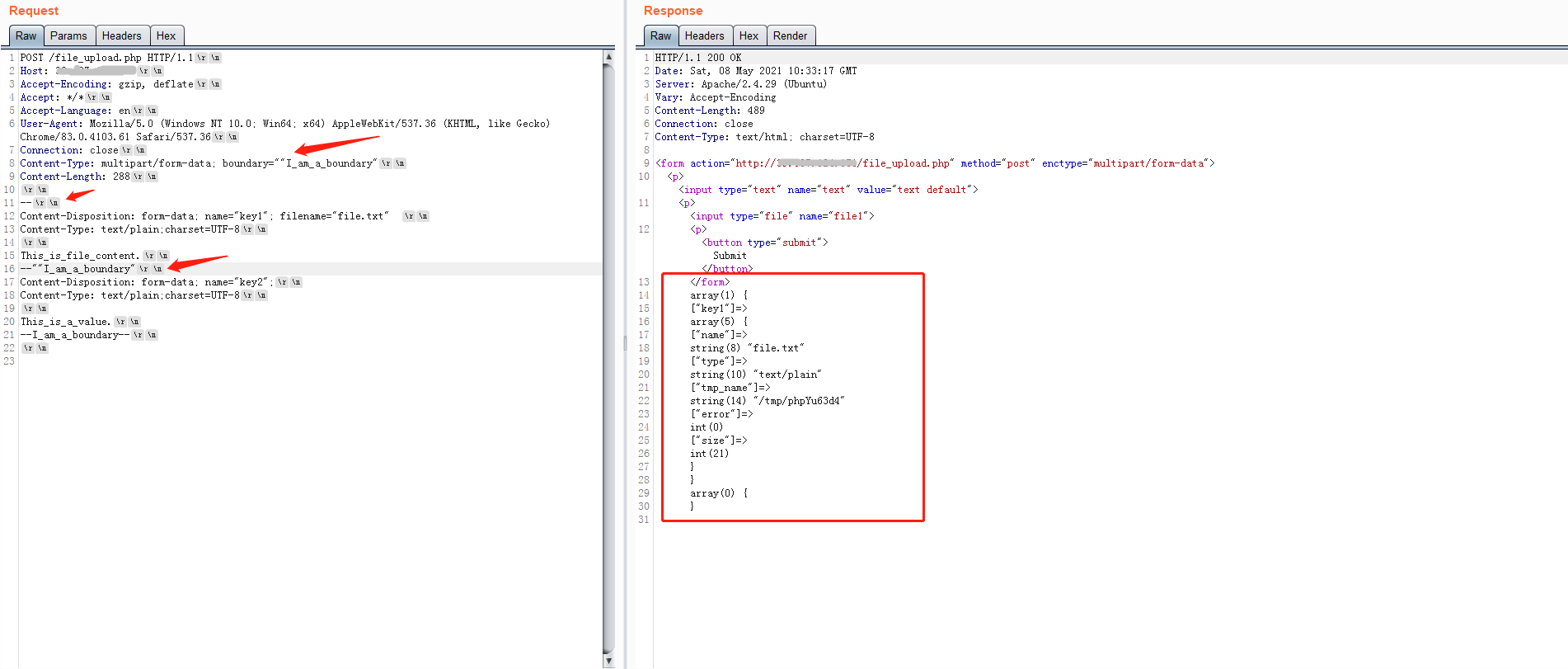
大多数waf应该会认为这是一个不符合规范的boundary,从而导致解析multipart/form-data失败,所以这种绕过waf的方式显得更加粗暴。
对于flask来说,可以看下解析boundary的正则werkzeug/http.py:L79。
_option_header_piece_re = re.compile(
r"""
;\s*,?\s* # newlines were replaced with commas
(?P<key>
"[^"\\]*(?:\\.[^"\\]*)*" # quoted string
|
[^\s;,=*]+ # token
)
(?:\*(?P<count>\d+))? # *1, optional continuation index
\s*
(?: # optionally followed by =value
(?: # equals sign, possibly with encoding
\*\s*=\s* # * indicates extended notation
(?: # optional encoding
(?P<encoding>[^\s]+?)
'(?P<language>[^\s]*?)'
)?
|
=\s* # basic notation
)
(?P<value>
"[^"\\]*(?:\\.[^"\\]*)*" # quoted string
|
[^;,]+ # token
)?
)?
\s*
""",
这个正则可以解释本文的大多数flask解析结果产生的原因,这里看到flask对于boundary两边的空格是做了处理的,对于双引号的处理,都会取第一对双引号内的内容作为boundary的值,对于非闭合的双引号,会处理成token形式,将双引号作为boundary的一部分,并不会像php一样解析boundary失败。
从上面正则也能看出,对于最后一种Content-Type的情况,flask也会取空值作为boundary的值,但是这不会同过flask对boundary的正则验证,导致boundary取值失败,无法解析,下文会提及到。
转义符号
以flask的正则中quoted string和token作为区分是否boundary为双引号内取值,测试两种转义符的位置会怎样影响解析。
- a.
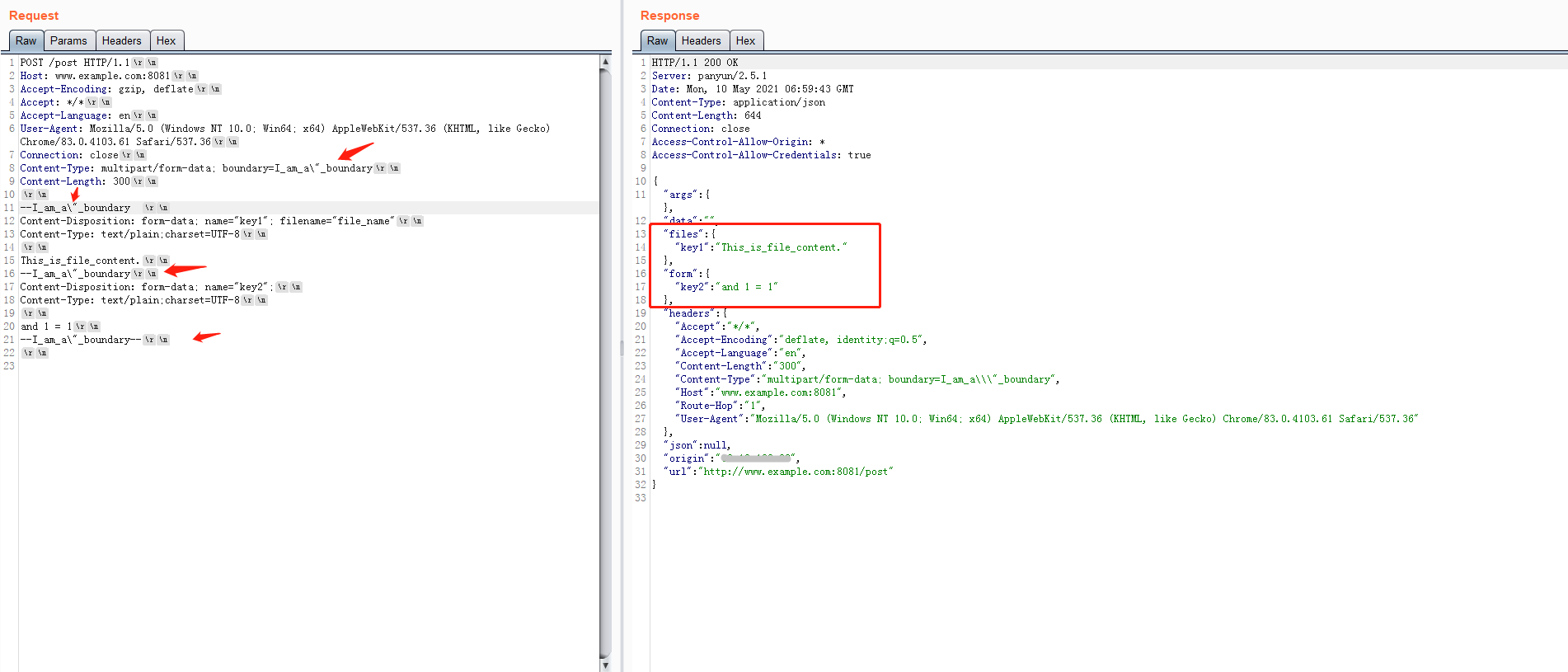
\在token中Content-Type: multipart/form-data; boundary=I_am_a\"_boundary这种形式的boundary,flask和php都会将
\认定为一个字符,并不具有转义作用,并将整体的I_am_a\"_boundary内容做作为boundary的值。![]()
- b.
\在quoted string中Content-Type: multipart/form-data; boundary="I_am_a\"_boundary"对于flask来说,在双引号的问题上,
werkzeug/http.py:L431中调用一个处理函数,就是取双引号之间的内容作为boundary的值。![]()
可以看到,在取完boundary值之后还做了一个
value.replace("\\\\", "\\").replace('\\"', '"')的操作,将转义符认定为具有转义的作用,而不是单单一个字符,所以最终boundary的值是I_am_a"_boundary。![]()
对于php来说,依旧和
token类型的boundary处理机制一样,认定\只是一个字符,不具有转义作用,所以按照上文双引号中提到的,由于遇到第二个双引号就会直接闭合双引号,忽略后面内容,最终php会取I_am_a\作为boundary的值。![]()

空格 & 双引号
上文提到使用空格对解析的影响,既然可以使用双引号来指定boundary的值,那么如果在双引号外或者内加入空格,后端会如何解析呢?
- a. 双引号外对于flask来说,依旧和普通不加双引号的解析一致,会忽略双引号外(两边)的空格,直接取双引号内的内容作为boundary的值,php对于双引号后面有空格时,处理机制和flask一致,但是当双引号前面有空格时,会无法正常解析表单数据内容。
![]()
解析会和不带双引号的实现一致,此时php会将前面的空格和后面的双引号和双引号的内容作为一个整体,将之作为boundary的值,当然这虽然符合RFC规定的boundary可以以空格开头,但是把双引号当作boundary的一部分并不符合。
![]()
- b. 双引号内此时php会取双引号内的所有内容(非双引号)作为boundary的值,无论是以任意空格开头还是结束,其分隔行中boundary前后的空格数,要与Content-Type中双引号内boundary前后的空格个数一致,否则解析失败。
![]()
值得注意的是,flask解析的时候,如果双引号内的boundary值以空格开始,那么在分隔行中类似php只要空格个数一致,就可以成功解析,但是如果双引号内的boundary的值以空格结束,无论空格个数是否一致,都无法正常解析。
![]()
为什么出现这种状况,看下werkzeug是如何实现的,flask对boundary的验证可以在
werkzeug/formparser.py:L46看到。#: a regular expression for multipart boundaries _multipart_boundary_re = re.compile("^[ -~]{0,200}[!-~]$")这个正则是来验证boundary有效性的,比较符合RFC规定的,只不过在长度上限制更小,可以是空格开头,不能以空格结尾,但是用的不是全匹配,所以以空格结尾也会通过验证。
上图使用
boundary= " I_am_a_boundary ",所以boundary的值为" I_am_a_boundary "双引号内的内容,而且这个值也会通过boundary正则的验证,最终还是解析失败了,很是奇怪。上文空格中提到,对于flask来说,在非结束分隔行中boundary后可以加任意空格,不影响最终的解析。![]()
原因是解析multipart/form-data具体内容时,为了寻找分割行,将每一行数据都进行了一个
line.strip()操作,这样会把CRLF去除,当然会把结尾的所有空格也给strip掉,所以当boundary不以空格结尾时,在分隔行中可以随意在结尾加空格。但是这也会导致一个问题,当不按照RFC规定,用空格结尾作为boundary值,虽然过了flask的boundary正则验证,但是在解析body时,却将结尾的空格都strip掉,导致在body中分隔行经过处理之后变为了-- I_am_a_boundary,这与Content-Type中获取的boundary值(结尾含有空格)并不一致,导致找不到分隔行,解析全部失败。
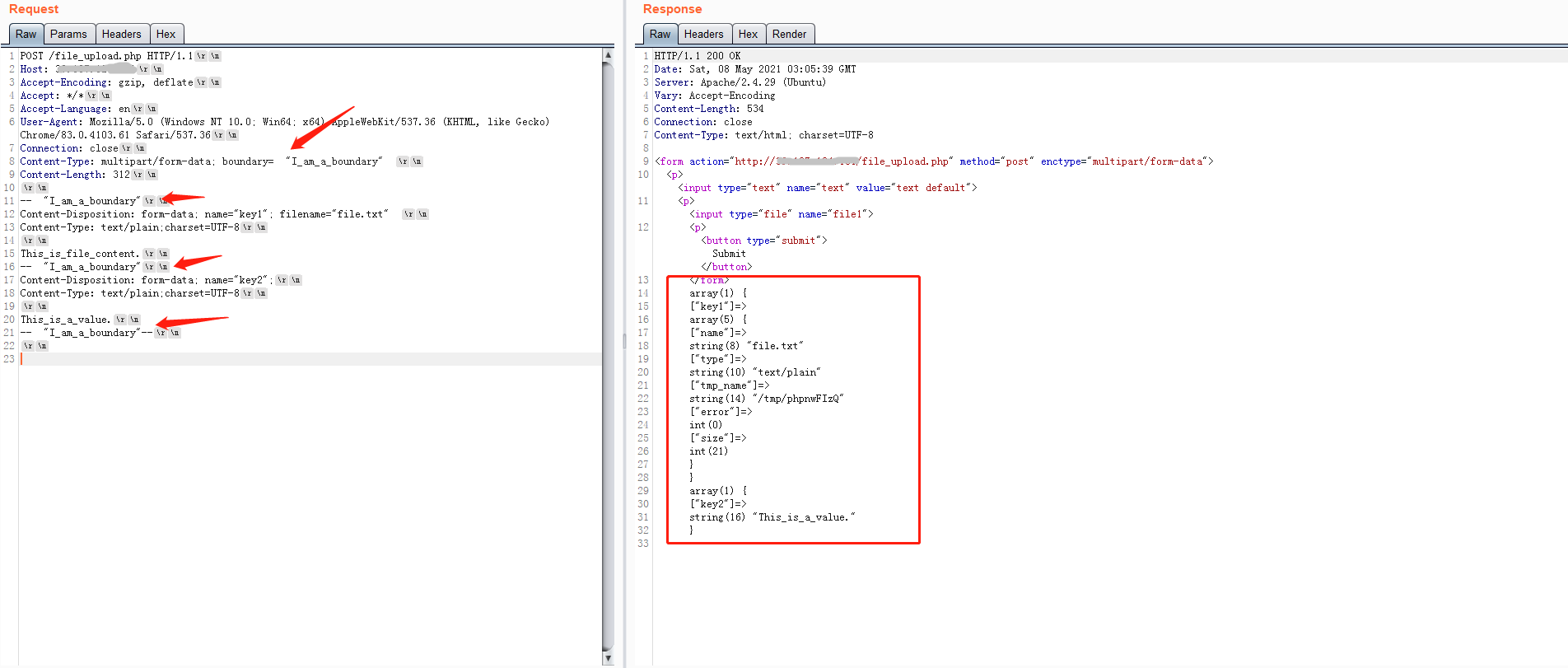
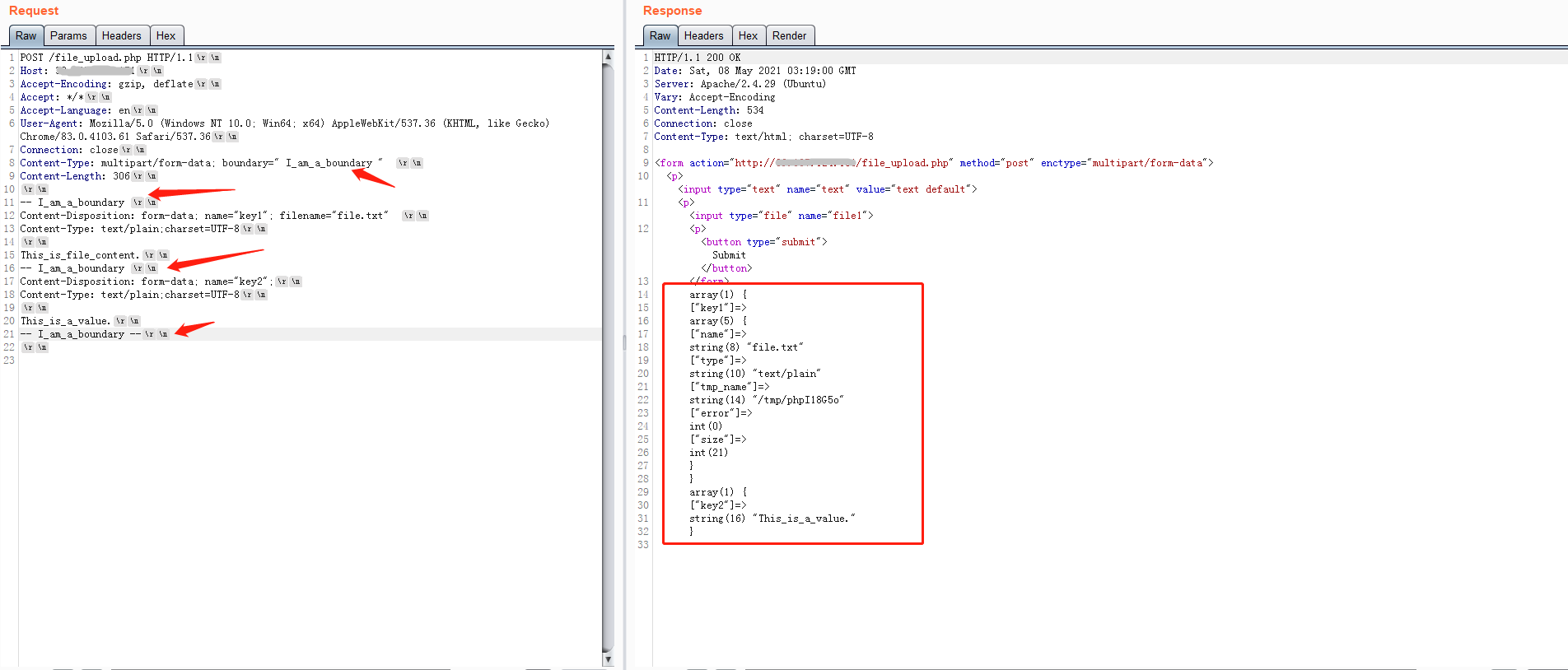
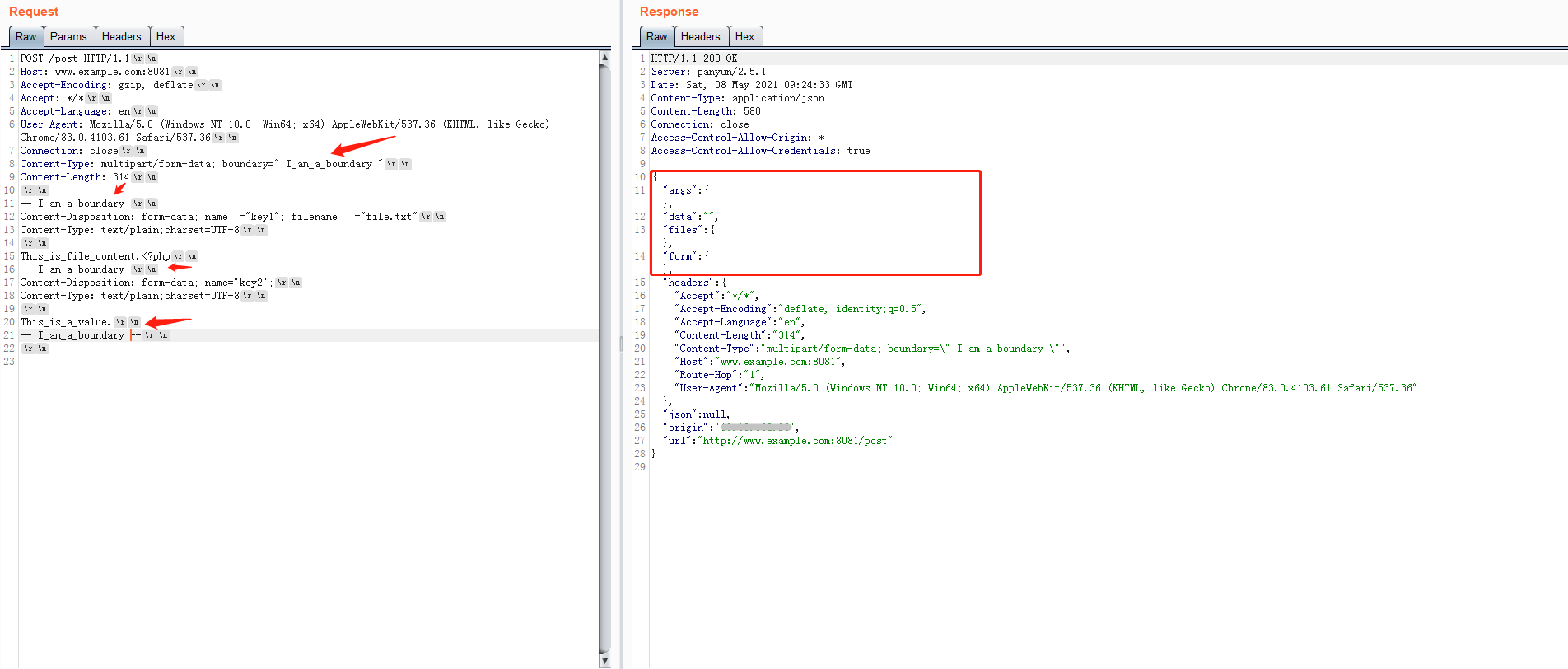

结束分隔行
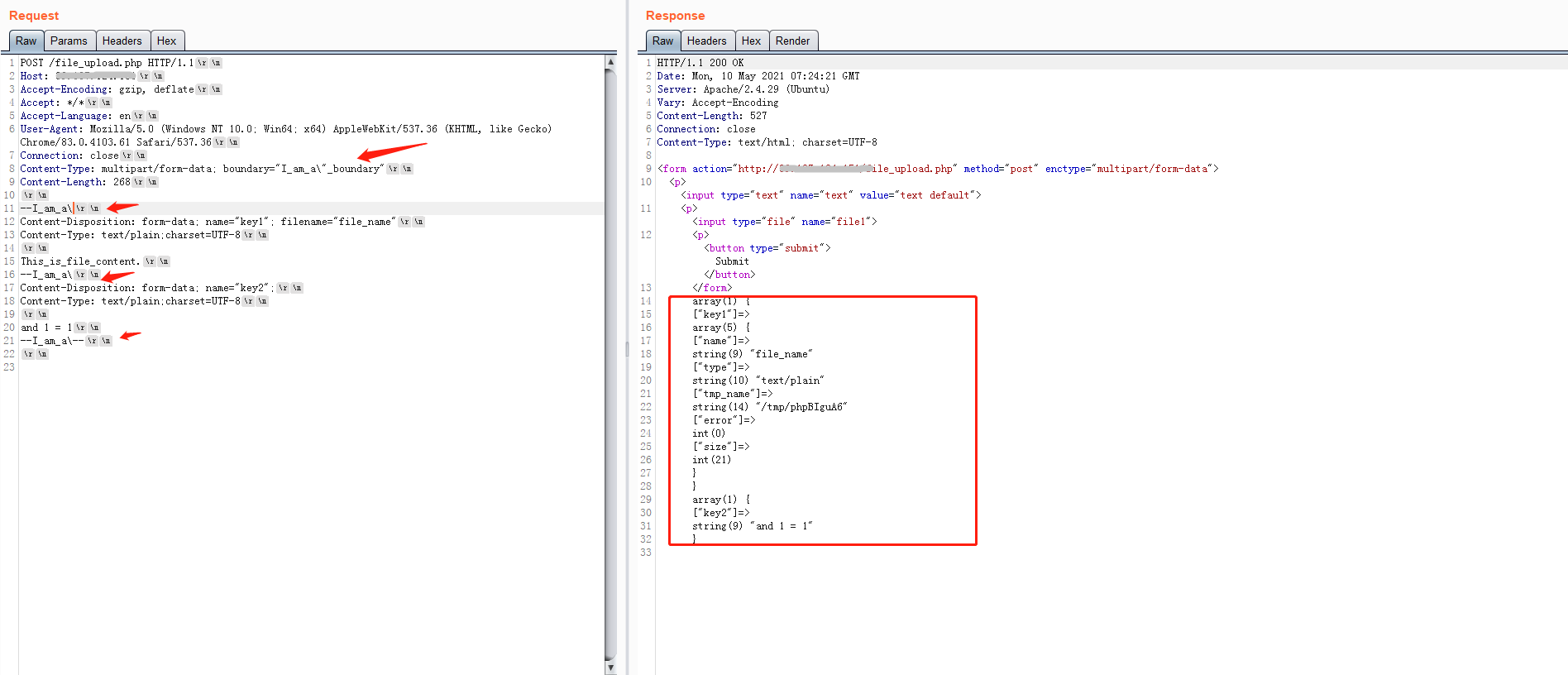
在上文空格内容中提到,php在结束分割行中的boundary后面加空格并不会影响最终的解析,其实并不是空格的问题,经测试发现,其实php根本就没把结束分隔行当回事。
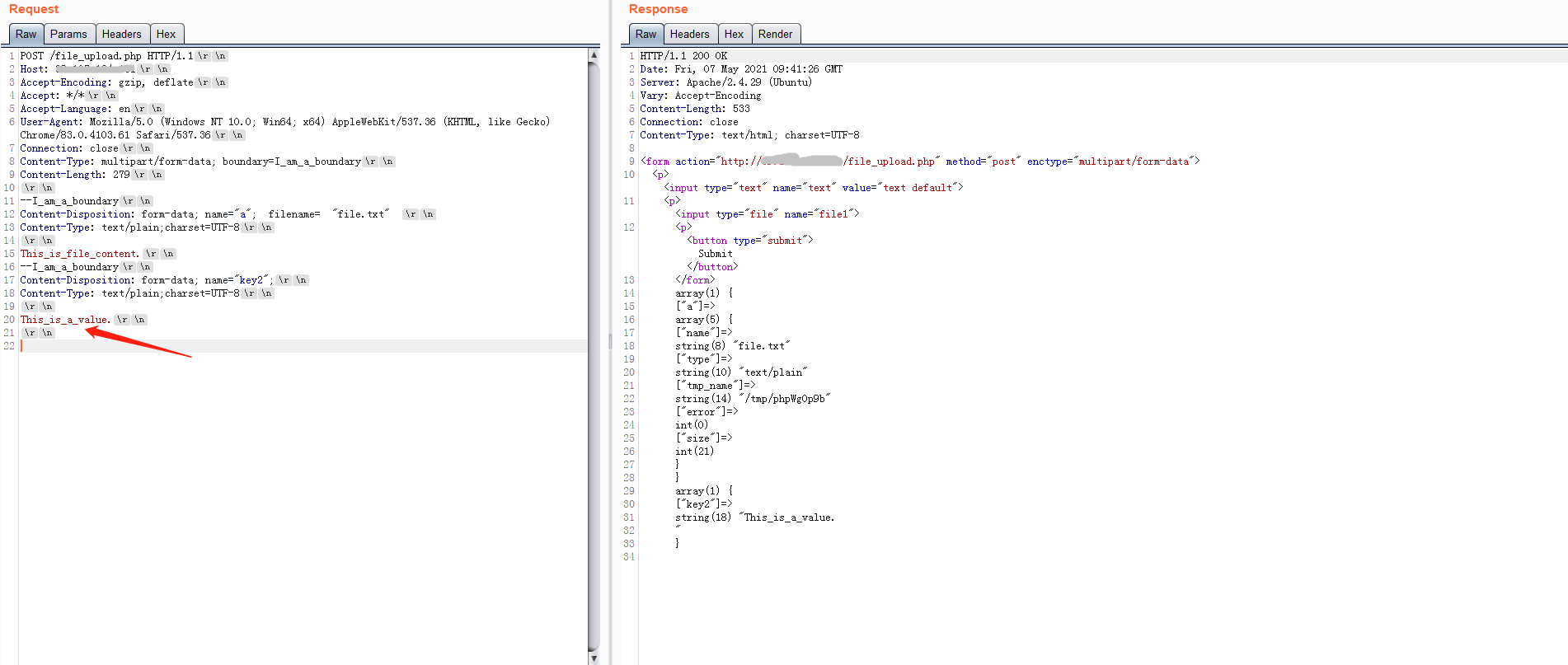
可以看到,没有结束分隔行,php会根据每一分隔行来分隔各个表单部分,并根据Content-Length来进行取表单最后一部分的内容的值,然而这是极不尊重RFC规定的,一般waf会将这种没有结束分隔行的视为错误的multipart/form-data格式,从而导致整体body解析失败,那么waf可以被绕过。
上文提到flask会对multipart/form-data的每一行内容进行strip操作,但是由于结束分隔行需要以--CRLF结尾,所以在strip的过程中只会将CRLFstrip掉,但是在解析boundary的时候,boundary是不能以空格为结尾的,最终会导致结束分隔行是严谨的--BOUNDARY--CRLF,当然如果使用双引号使boundary以空格结尾,那么结束分隔行是可以正确解析的,但是非结束分隔行无法解析还是会导致整体解析失败。
其他
从flask的代码能够看出来,支持参数名的quoted string形式,就是参数名在双引号内。
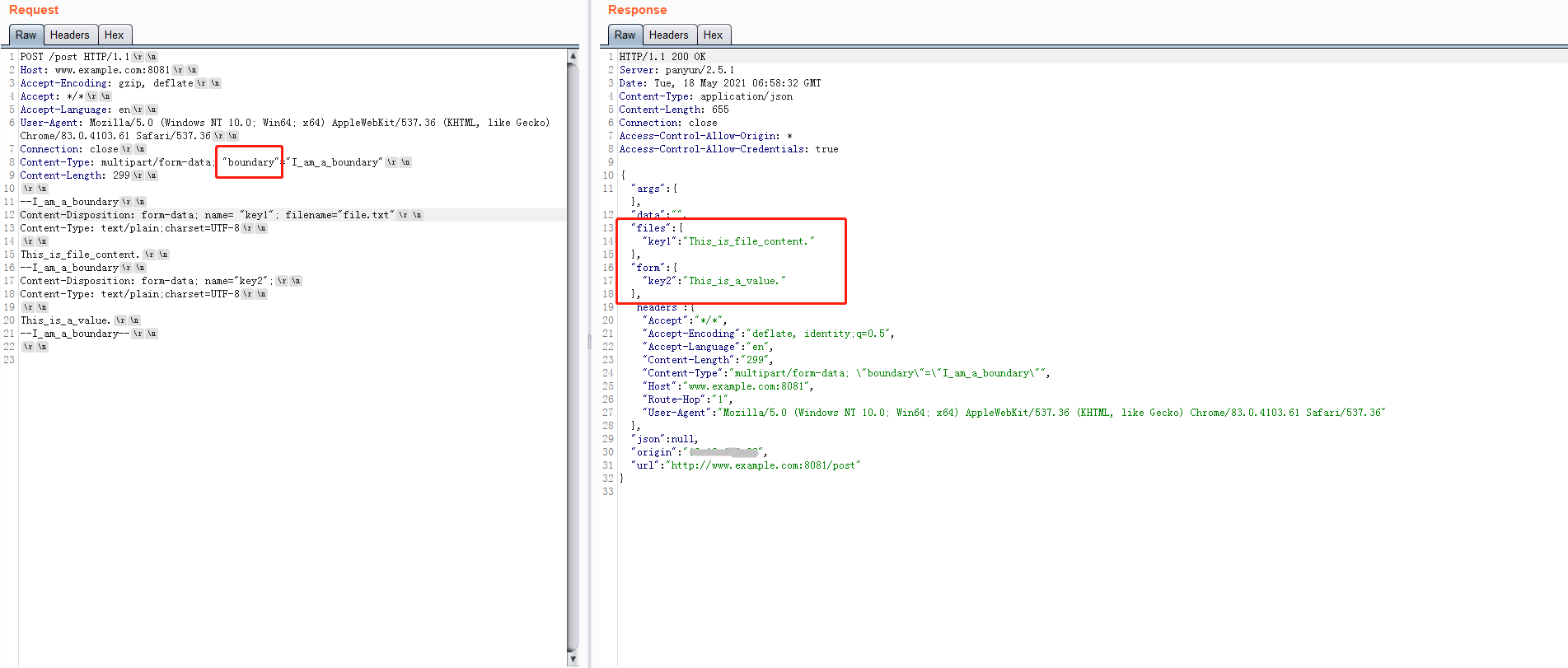
而对于Java来说,支持参数名的大小写不敏感的写法。
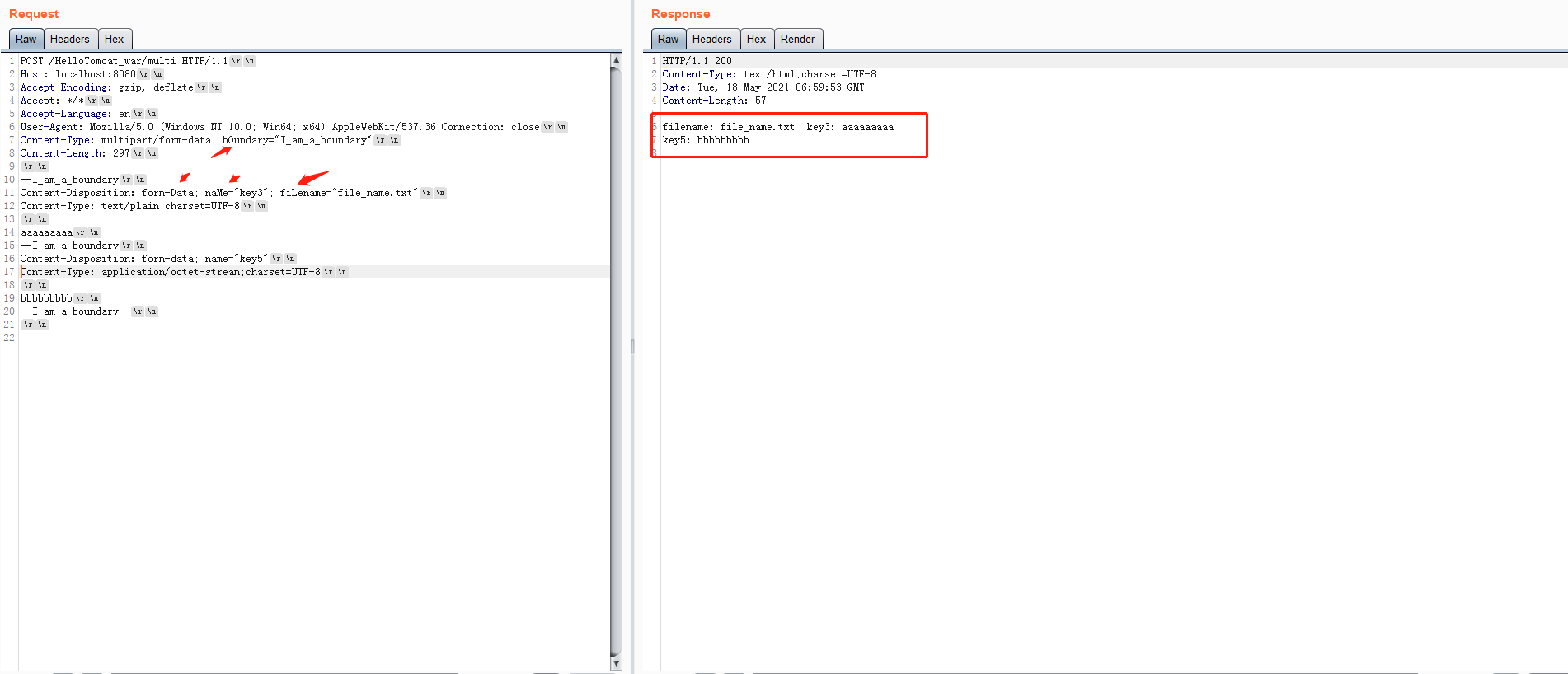
参考链接
https://github.com/postmanlabs/httpbin
https://www.ietf.org/rfc/rfc1867.txt
https://tools.ietf.org/html/rfc7578
https://tools.ietf.org/html/rfc2046#section-5.1
https://www.php.net/manual/zh/language.variables.external.php
https://www.cnblogs.com/youxin/archive/2012/02/13/2348551.html