
在上一篇文章中,我们为读者解释了ROP链的创建过程,以及执行任意代码的实现过程,在本文中,我们继续为读者介绍针对SEH劫持技术的一种强大的防御机制,即SEHOP。
SEHOP
实际上,在Windows中还有一种更为强大的SEH劫持缓解机制,称为SEH覆写保护(SEH Overwrite Protection,SEHOP),它可以抗衡这里描述的方法。引入SEHOP的目的,是为了既可以检测EXCEPTION_REGISTRATION_RECORD损坏,又无需重新编译应用程序或依靠每个模块的漏洞利用缓解方案,如SafeSEH。为此,SEHOP将在SEH链的底部引入一个额外的链接,并在异常发生时通过检查是否可以通过遍历SEH链而到达该链接,来实现SEH劫持的防御机制。由于EXCEPTION_REGISTRATION_RECORD的NSEH字段存储在handler字段之前,因此,在通过堆栈溢出破坏现有的SEH handler时,必然会破坏NSEH,以及破坏整个链(原理上类似于堆栈金丝雀(stack canary),其中金丝雀就是NSEH字段本身)。SEHOP是在Windows Vista SP1(在默认情况下禁用)和Windows Server 2008(在默认情况下启用)中引入的,在过去的十年中,SEHOP一直处于这种半启用状态(在工作站上禁用,在服务器上启用)。值得注意的是,最近随着Windows 10 v1709的发布,这种情况已经发生了变化:SEHOP已经成为默认启用的漏洞缓解功能了。
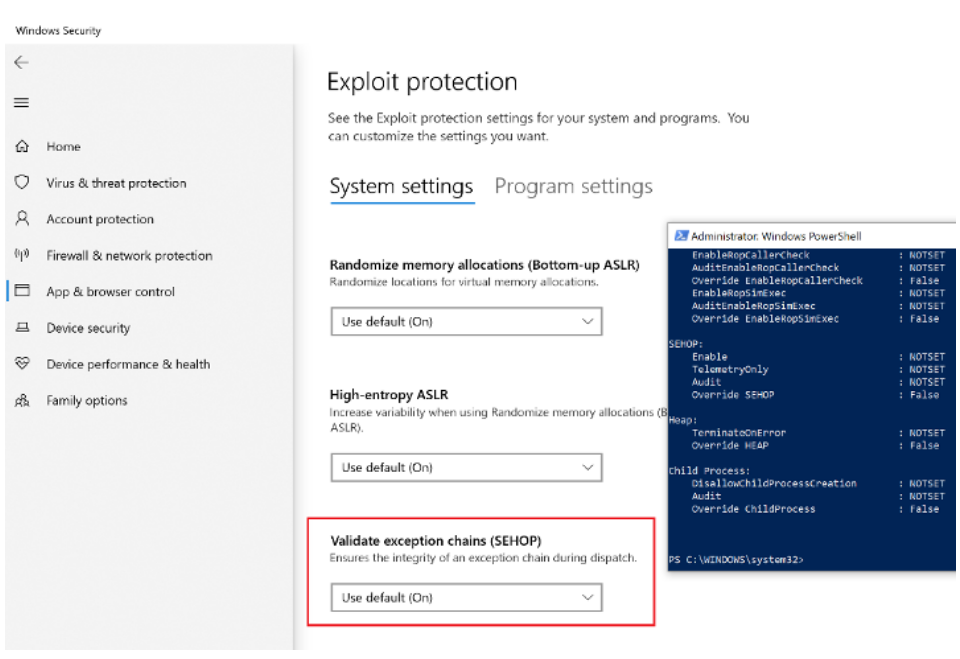
图27 来自WIndows 10上的Windows安全中心的SEHOP设置
这似乎与上一节在Windows 10虚拟机上探讨的SEH劫持溢出情况相矛盾。为什么SEHOP没有能够在exploit的初始阶段阻止EIP重定向到堆栈pivot?虽然我们还不是十分清楚,然而这似乎是微软方面配置错误的问题。当我对之前探索溢出所用EXE程序单独进行设置,并手动点选“Override system settings”框后,SEHOP机制就开始发挥威力:堆栈pivot将无法执行。令人费解的是,在默认情况下,系统已经在该进程上启用了SEHOP机制。

图28 在用于演示堆栈溢出漏洞的EXE程序上设置SEHOP
这有可能是微软方面有意的配置,只是在上面的截图中被曲解了。由于SEHOP与第三方应用程序(如Skype和Cygwin)不兼容,因此,SEHOP在历史上一直被广泛禁用(微软在这里讨论了这个问题)。当SEHOP与本文中讨论的其他漏洞缓解措施一起正确启用时,在没有链式内存泄漏(任意读取)或任意写入原语的情况下,SEH劫持将无法用于利用堆栈溢出漏洞。任意读取原语可以允许NSEH字段在溢出前被泄漏,这样就可以制作溢出数据,以便在EIP劫持期间不破坏SEH链。通过任意写入原语(在下一节讨论),攻击者可以覆盖存储在栈上的返回地址或SEH handler,而不会破坏NSEH或堆栈金丝雀的值,从而绕过SEHOP和堆栈Cookie缓解措施。
任意写入&局部变量破坏
在某些情况下,攻击者根本就不需要溢出函数堆栈帧的末尾来触发EIP重定向。如果他们可以在不需要覆盖堆栈Cookie的情况下成功地获得代码执行权限,那么堆栈Cookie验证检查就可以轻松绕过。为此,有一种方法是使用堆栈溢出来破坏函数中的局部变量,以便让应用程序将我们选择的值写入我们选择的地址。下面的示例函数包含可以用这种方式利用的逻辑。
uint32_t gdwGlobalVar = 0;
void Overflow(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
char Buf[16];
uint32_t dwVar1 = 1;
uint32_t* pdwVar2 = &gdwGlobalVar;
memcpy(Buf, pInputBuf, dwInputBufSize);
*pdwVar2 = dwVar1;
}图29假设存在任意写栈溢出漏洞的函数
从根本上讲,我们要利用的是一个非常简单的代码模式:
- 函数必须包含一个容易发生堆栈溢出的数组或结构。
- 该函数必须包含至少两个局部变量:一个解引用的指针和一个用于写入该指针的值。
- 函数必须使用局部变量写入解引用的指针,并在堆栈溢出发生后执行这个操作。
- 函数必须以这样的方式进行编译:即溢出的数组在堆栈上存储的位置比局部变量低。
最后一点是一个值得进一步研究的问题。我们希望MSVC(Visual Studio 2019使用的编译器)以这样的方式编译图29中的代码:Buf的16个字节被放在分配给栈帧内存的最低区域(当包含堆栈Cookie时,应该是总共28个字节),然后是最高区域的dwVar1和pdwVar2。这个顺序与源代码中声明这些变量的顺序是一致的;这允许Buf向前溢出到更高的内存中,并用我们选择的值覆盖dwVar1和pdwVar2的值,从而使我们用于覆盖dwVar1的值被放在我们选择的内存地址上。然而在现实中,情况并非如此,编译器给出的汇编代码如下所示:
push ebp
mov ebp,esp
sub esp,1C
mov eax,dword ptr ds:[<___security_Cookie>]
xor eax,ebp
mov dword ptr ss:[ebp-4],eax
mov dword ptr ss:[ebp-1C],1
mov dword ptr ss:[ebp-18],
mov ecx,dword ptr ss:[ebp+C]
push ecx
mov edx,dword ptr ss:[ebp+8]
push edx
lea eax,dword ptr ss:[ebp-14]
push eax
call
add esp,C
mov ecx,dword ptr ss:[ebp-18]
mov edx,dword ptr ss:[ebp-1C]
mov dword ptr ds:[ecx],edx
mov ecx,dword ptr ss:[ebp-4]
xor ecx,ebp
call <preciseoverwrite.@__security_check_Cookie@4>
mov esp,ebp
pop ebp
ret图30 图29中假设含有漏洞的函数的编译结果
从上面的反汇编代码中我们可以看到,编译器已经在EBP-0x4和EBP-0x14之间的最高内存部分中选择了一个对应于Buf的区域,并且已经在EBP-0x1C和EBP-0x18的最低内存部分中分别为dwVar1和pdwVar2选择了一个区域。这种排序使易受攻击的函数免受局部变量通过堆栈溢出而损坏的影响。也许最有趣的是,dwVar1和pdwVar2的排序与它们在源代码中相对于Buf的声明顺序相矛盾。这最初让我觉得很不解,因为我认为MSVC会根据变量的声明顺序来排序,但进一步的测试证明事实并非如此。实际上,进一步的测试证明,MSVC并不是根据变量的声明、类型或名称的顺序来排序,而是根据它们在源代码中被引用(使用)次数来排序:引用次数多的变量将优先于那些引用次数少的变量。
void Test() {
uint32_t A;
uint32_t B;
uint32_t C;
uint32_t D;
B = 2;
A = 1;
D = 4;
C = 3;
C++;
}图31 用于演示反直觉变量排序的C语言代码
因此,我们可以预期这个函数的编译会按以下方式排列变量:C、B、A、D。这符合变量引用(使用)次数的顺序,而不是它们被声明的顺序。其中,C将被放在第一位(内存中最高地址处,距离EBP的偏移量最小),因为它被引用了两次,而其他变量都只被引用了一次。
push ebp
mov ebp,esp
sub esp,10
mov dword ptr ss:[ebp-8],2
mov dword ptr ss:[ebp-C],1
mov dword ptr ss:[ebp-10],4
mov dword ptr ss:[ebp-4],3
mov eax,dword ptr ss:[ebp-4]
add eax,1
mov dword ptr ss:[ebp-4],eax
mov esp,ebp
pop ebp
ret图32 图31的C代码对应的汇编代码
果然,我们可以看到,变量都已经按照我们预测的顺序排列,其中,C位于EBP – 4处,也就是排在第一位。尽管如此,MSVC使用的排序逻辑与我们在图30中看到的情况相矛盾。毕竟,dwVar1和pdwVar2的引用次数(各两次)都比Buf高(在memcpy中只有一次),而且都是在Buf之前引用的。那么这是怎么回事呢?GS包含了一个额外的安全缓解功能,它试图安全地对局部变量进行排序,以防止由于堆栈溢出而导致可利用的局部变量破坏。
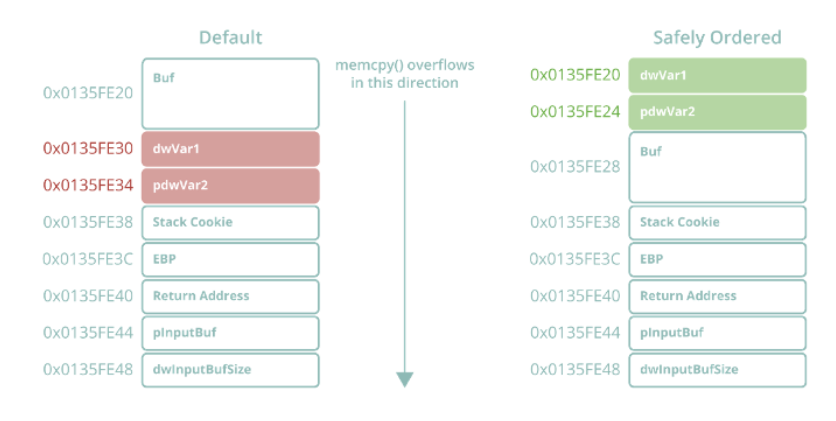
图33 在GS机制下生成的具有安全变量顺序堆栈布局
绕过在项目设置中禁用GS,会产生以下代码:
push ebp
mov ebp,esp
sub esp,18
mov dword ptr ss:[ebp-8],1
mov dword ptr ss:[ebp-4],
mov eax,dword ptr ss:[ebp+C]
push eax
mov ecx,dword ptr ss:[ebp+8]
push ecx
lea edx,dword ptr ss:[ebp-18]
push edx
call
add esp,C
mov eax,dword ptr ss:[ebp-4]
mov ecx,dword ptr ss:[ebp-8]
mov dword ptr ds:[eax],ecx
mov esp,ebp
pop ebp
ret图34图29中的源代码在没有使用/GS标志的情况下的编译结果
仔细对比上图34中的汇编代码和图30中的原始(安全)汇编代码,大家就会发现,从这个函数中删除的可不仅仅是堆栈Cookie检查。事实上,MSVC已经完全重新排列了堆栈上的变量,使其与正常规则一致,因此将Buf数组放在了内存的最低区域(EBP – 0x18)。因此,这个函数现在很容易通过堆栈溢出导致局部变量损坏。
在用多种不同的变量类型(包括其他数组类型)测试了同样的逻辑后,我得出如下结论:MSVC对数组和结构体(GS缓冲区)有一个特殊的规则,即总是将它们放在内存的最高区域,以防止编译后的函数的局部变量因堆栈溢出而遭到破坏。了解到这些信息后,我开始尝试评估这个安全机制的复杂程度,并设法通过边缘案例(edge cases)来绕过它。我发现了多个,下面是我认为最显著的例子。
首先,让我们来看看如果图29中的memcpy被移除会发生什么情况。
void Overflow() {
uint8_t Buf[16] = { 0 };
uint32_t dwVar1 = 1;
uint32_t* pdwVar2 = &gdwGlobalVar;
*pdwVar2 = dwVar1;
}图35 包含未引用数组的函数
我们希望MSVC的安全排序规则总是将数组放置在内存的最高区域,以为函数提供安全保护,然而汇编代码表明,事情并非如此。
push ebp
mov ebp,esp
sub esp,18
xor eax,eax
mov dword ptr ss:[ebp-18],eax
mov dword ptr ss:[ebp-14],eax
mov dword ptr ss:[ebp-10],eax
mov dword ptr ss:[ebp-C],eax
mov dword ptr ss:[ebp-8],1
mov dword ptr ss:[ebp-4],
mov ecx,dword ptr ss:[ebp-4]
mov edx,dword ptr ss:[ebp-8]
mov dword ptr ds:[ecx],edx
mov esp,ebp
pop ebp
ret图36 图35中的源代码对应的汇编代码
如您所见,MSVC已经从函数中删除了堆栈Cookie。同时,MSVC还将Buf数组放在了内存的最低区域,这违背了其典型的安全策略;如果缓冲区未被引用,它将不考虑GS缓冲区的安全重排序规则。这样就提出了一个有趣的问题:何谓引用?令人惊讶的是,答案并不像我们所期望的那样(引用就是函数中对变量的任何使用)。针对某些类型的变量使用并不能算作引用,因此不会影响变量的排序。
void Test() {
uint8_t Buf[16]};
uint32_t dwVar1 = 1;
uint32_t* pdwVar2 = &gdwGlobalVar;
Buf[0] = 'A';
Buf[1] = 'B';
Buf[2] = 'C';
*pdwVar2 = dwVar1;
}图37 一个被引用了3次的数组和两个被引用了2次的局部变量
在上面的例子中,我们希望Buf被放置在内存的第一个(最高)槽(slot)中,因为它被引用了三次,而dwVar1和pdwVar2各只被引用了两次。这个函数的汇编代码与此相矛盾。
push ebp
mov ebp,esp
sub esp,18
mov dword ptr ss:[ebp-8],1
mov dword ptr ss:[ebp-4],
mov eax,1
imul ecx,eax,0
mov byte ptr ss:[ebp+ecx-18],41
mov edx,1
shl edx,0
mov byte ptr ss:[ebp+edx-18],42
mov eax,1
shl eax,1
mov byte ptr ss:[ebp+eax-18],43
mov ecx,dword ptr ss:[ebp-4]
mov edx,dword ptr ss:[ebp-8]
mov dword ptr ds:[ecx],edx
mov esp,ebp
pop ebp
ret图38 图37中的源代码对应的汇编代码
尽管Buf是一个数组,而且比其他任何一个局部变量使用得更多,但是,它却被保存在栈内存的最低处EBP–0x18。上面的汇编代码的另一个有趣的细节是,MSVC没有给图38中的函数添加安全Cookie检查。这就意味着,该返回地址仍会受到经典堆栈溢出以及任意写入漏洞的影响。
#include
#include
uint8_t Exploit[] =
"AAAAAAAAAAAAAAAA"// 16 bytes for buffer length
"\xde\xc0\xad\xde"// New EIP 0xdeadc0de
"\x1c\xff\x19\x00"; // 0x0019FF1c
uint32_t gdwGlobalVar = 0;
void OverflowOOBW(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
uint8_t Buf[16];
uint32_t dwVar1 = 1;
uint32_t* pdwVar2 = &gdwGlobalVar;
for (uint32_t dwX = 0; dwX < dwInputBufSize; dwX++) {
Buf[dwX] = pInputBuf[dwX];
}
*pdwVar2 = dwVar1;
}图39 越界写入漏洞
编译并执行上面的代码会导致一个没有堆栈Cookies和没有进行安全的变量排序的函数,这样的话,攻击者就可以通过精确覆盖0x0019FF1c处的返回地址来劫持EIP(在本例中,我已经禁用了ASLR)。
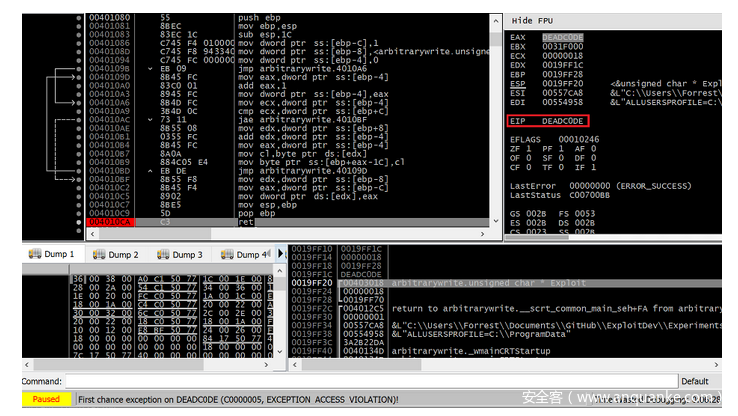
图40通过越界写入漏洞覆盖返回地址实现EIP劫持
根据这些实验,我们可以得出如下所示的结论:
- MSVC中存在一个安全漏洞:错误地评估了一个函数对堆栈溢出攻击的潜在敏感性。
- 这个安全漏洞源于MSVC使用某种形式的内部引用次数来决定变量顺序,而当一个变量的引用次数为零时,它被排除在常规的安全排序和堆栈Cookie安全缓解措施之外(即使它是一个GS缓冲区)。
- 按索引读/写数组不计入引用次数。因此,以这种方式访问数组的函数将缺乏针对堆栈溢出漏洞的保护。
对于可能无法适当防止堆栈溢出的代码模式,我还有几个其他的想法,首先是结构体/类的概念。虽然函数栈帧内的变量排序没有标准化或约定俗成(完全由编译器决定),但对于结构体来说,情况就不一样了;编译器必须精确地遵循源代码中声明变量的顺序。因此,如果一个结构体中包含一个数组,后面还有额外的变量,这些变量就无法安全地重新排序,因此,可能会因溢出而被破坏。
struct MyStruct {
char Buf[16];
uint32_t dwVar1;
uint32_t *pdwVar2;
};
void OverflowStruct(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
struct MyStruct TestStruct = { 0 };
TestStruct.dwVar1 = 1;
TestStruct.pdwVar2 = &gdwGlobalVar;
memcpy(TestStruct.Buf, pInputBuf, dwInputBufSize);
*TestStruct.pdwVar2 = TestStruct.dwVar1;
}图41 通过结构体实现任意写入的堆栈溢出
上面用于结构体的概念同样也适用于C++类,前提是它们被声明为局部变量并在堆栈上分配内存空间。
class MyClass {
public:
char Buf[16];
uint32_t dwVar1;
uint32_t* pdwVar2;
};
void OverflowClass(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
MyClass TestClass;
TestClass.dwVar1 = 1;
TestClass.pdwVar2 = &gdwGlobalVar;
memcpy(TestClass.Buf, pInputBuf, dwInputBufSize);
*TestClass.pdwVar2 = TestClass.dwVar1;
}图42 通过类实现任意写入的堆栈溢出
当涉及到类时,一个额外的攻击手法是破坏其vtable指针。这些vtable包含指向可执行代码的其他指针,这些可执行代码可以在RET指令之前通过被破坏的类的方法进行调用,从而提供了一种通过破坏局部变量来劫持EIP的新方法,而无需使用任意写入原语。
最后一个容易被局部变量破坏的代码模式的例子是使用运行时堆栈分配函数,如_alloca。由于这类函数的内存分配过程,是在函数的栈帧已经建立后,通过减去ESP来实现的,因此,这类函数分配的内存将始终处于较低的栈内存中,所以无法重新排序或免受此类攻击的威胁。
void OverflowAlloca(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
uint32_t dwValue = 1;
uint32_t* pgdwGlobalVar = &gdwGlobalVar;
char* Buf = (char*)_alloca(16);
memcpy(Buf, pInputBuf, dwInputBufSize);
*pgdwGlobalVar = dwValue;
}图43 易受_alloca局部变量破坏问题影响的函数
请注意,尽管上面的函数中没有数组,但MSVC足够聪明,它知道只要使用了_alloca函数就有必要在生成的函数代码中放入堆栈Cookie。
这里讨论的技术代表了一种现代Windows的堆栈溢出的攻击面,到目前为止,还没有明确的安全缓解措施。然而,它们的可靠利用依赖于这里讨论的特定代码模式以及(在任意写入的情况下)一个链式内存泄漏原语。
小结
对于堆栈溢出漏洞,虽然现代的操作系统已经提供了许多防御机制,但在今天的Windows应用程序中仍然存在并且可被利用。如果存在非Safeseh模块,那么利用这种溢出漏洞就比较容易,因为还没有哪种默认的安全缓解机制强大到可以防止局部变量破坏而导致的任意写入攻击。就目前来说,防御这类攻击的最强机制是ASLR,为了绕过这种机制,攻击者需要借助于非ASLR模块或内存泄漏漏洞。正如我们在这篇文章中所展示的那样,非Safeseh模块和非ASLR模块在如今的Windows 10系统以及许多第三方应用程序中仍不乏足迹。
与过去相比,尽管堆栈溢出漏洞的利用技术变得愈加复杂,但与堆中的其他内存破坏类型的漏洞相比,堆栈溢出是最容易理解的一个。在本系列的未来文章中,我们将继续深入探讨现代的Windows堆破坏漏洞,并希望对大家的学习有所帮助。