
在本文中,我们将为读者介绍我们为justCTF竞赛中设计的一个挑战,标题为“PDF is broken, and so is this file”。通过该挑战,不仅可以帮助大家了解PDF文件格式的某些特性,同时,我们还会展示如何利用开源工具来轻松应对这些挑战。
在该挑战中,PDF其实是一个Web服务器,在其中托管自身的副本
实际上,该挑战中的PDF文件实际上已经被破坏,但是大多数PDF软件通常只会将其呈现为空白页,而不会引起任何怀疑。如果使用file命令扫描该挑战,得到的结果只是一些“数据”文件。在十六进制编辑器中打开该文件,看到的内容仿佛是一个Ruby脚本:
require 'json'
require 'cgi'
require 'socket'
=begin
%PDF-1.5
%ÐÔÅØ
% `file` sometimes lies
% and `readelf -p .note` might be useful later第5行的PDF头部被嵌入在从第4行开始的Ruby多行注释中,但它并非被破坏的部分!同时,几乎所有的PDF软件都会忽略%PDF-1.5头部之前的内容。第7行和第8行是PDF注释,它证实了我们从file命令中看到的内容,以及我们稍后会提到的readelf线索。
剩下的Ruby脚本被嵌入到PDF对象流中——第“9999 0 obj”行,其中可以包含被PDF忽略的所有数据。但是PDF的剩余部分呢?如何才能不影响Ruby脚本呢?
9999 0 obj
<< /Length 1680 >>^Fstream
=end
port = 8080
if ARGV.length > 0 then
port = ARGV[0].to_i
end
html=DATA.read().encode('UTF-8', 'binary', :invalid => :replace, :undef => :replace).split(/<\/html>/)[0]+"\n"
v=TCPServer.new('',port)
print "Server running at http://localhost:#{port}/\nTo listen on a different port, re-run with the desired port as a command-line argument.\n\n"
⋮
__END__Ruby有一个特性,词法分析器遇到__END__关键字就会停下来,并忽略之后的所有内容。果然,这个奇怪的PDF就含有这样一个符号,后面是封装PDF对象流的结尾和PDF的剩余部分。
很明显,这是一个Ruby/PDF的多语言混合体——您可以使用类似的方法将任何PDF变成这样的多语言混合体。如果您的脚本足够短,甚至不需要把它嵌入到一个PDF流对象中,这时只要将所有的脚本都放到%PDF-1.5头部之前即可。当然,对于有些PDF解析器来说,如果在文件的前1024字节内没有找到PDF头部的话,就会发出警告信息。
您不会认为事情就这么简单吧?
所以,让我们勇敢一点,试着把PDF当作一个Ruby脚本来运行。果然,它运行了一个网络服务器,并托管了一个带有“flag.zip”文件下载链接的网页。哇,这很容易,对吧?进一步检查Ruby脚本,您会发现下载的是PDF文件本身,并将其后缀改为.zip。是的,除了是一个Ruby脚本之外,这个PDF同时也是一个有效的ZIP文件。实际上,PoC||GTFO已经使用这一招多年了,通过在挑战PDF上运行binwalk -e命令也可以观察到这一点。
解压该PDF文件后,会得到两个文件:一个MμPDF mutool二进制文件,以及一个false_flag.md文件。对于后者,建议读者通过mutool二进制文件来运行这个已被破坏的PDF。
很明显,这个版本的mutool已经做了相应的修改,所以,它才能够正确地呈现这个已遭破坏的PDF。难道CTF参赛者应该逆向分析该二进制文件来找出哪些地方被修改?如果有人试过,或者试过上面作为PDF注释嵌入的readelf线索,他们可能会注意:
您应该做的第一件事是:用十六进制编辑器打开该PDF。如果要用普通的PDF阅读器解析该PDF文件的话,可能需要先“修复”它。至于如何进行修复,这需要对这个二进制文件进行逆向分析,但是,如果用它来渲染该PDF,寻找线索,并将原始的PDF对象的与“常规”PDF对象进行比较,可能要更轻松一些。此外,您还可以借助于“bbe”工具来修复它!
Binary Block Editor(bbe)是一种类似于sed的实用程序,用于编辑二进制序列。这意味着使用二进制正则表达式可以轻松修复导致PDF呈现为空白页面的任何内容。
进一步深究
当我们使用修改版的mutool软件来渲染PDF时,会产生这种让人摸不着头脑的蒙太奇效果:

使用修改版的mutool软件呈现的挑战中“受损的”PDF文件
通过在网上搜索字符串LMGTFY,我们会找到Didier Stevens撰写的一篇出色的文章,该文章详细描述了PDF流格式,包括PDF对象是如何编号和版本控制方式。其中,一个重要的知识点是两个PDF对象可以具有相同的编号,但版本却不必一致。
该页面上的第一个线索表明该PDF对象的编号为1337,因此,我们要记住这一点。如果将Stevens文章中的图表,与被破坏的PDF流对象的hexdump进行比对,就能弄清楚哪些内容发生了变化。

Didier Stevens的PDF流对象注释图
5 0 obj
<< /Length 100 >>^Fstream
⋮
endstream
endobj挑战赛给出的PDF中的PDF流对象
如线索所示,PDF规范只允许使用六种空格字符:\0、\t、\n、\f、\r和空格符。ZIP文件中的mutool工具,也已经被修改过了,以允许ACK(0x06)用作第七种空格字符!果然,在该文件的第十二行我们看到:
>>^Fstream其中,这里的“^F”是一个ACK字符,但是按照PDF规范的规定,这里应该是空格符!在这里,所有的PDF对象流都有类似的错误。不过,我们可以通过以下方法来解决这个问题:
bbe -e "s/\x06stream\n/\nstream\n/" -o challenge_fixed.pdf challenge.pdf
揭开谜底
修复该文件对于解决挑战是否绝对必要?并非如此,实际上我们可以使用十六进制编辑器在0x1337号PDF对象中找到旗标:
4919 0 obj
<< /Length 100 /Filter /FlateDecode >>^Fstream
x<9c>^MËA^N@0^PFá}OñëÆÊÊ<88>X;^Ba<9a>N<8c>N£#áöº~ßs<99>s^ONÅ6^Qd<95>/°<90>^[¤(öHû}^L^Vk×E»d<85>fcM<8d>^[køôië<97><88>^N<98> ^G~}Õ\°L3^BßÅ^Z÷^CÛ<85>!Û
endstream
endobj
4919 1 obj
<< /Length 89827 /Filter [/FlateDecode /ASCIIHexDecode /DCTDecode] >>^Fstream
…
endstream
endobj然后,我们可以手动解码流内容。Binwalk甚至能自动解码第一个流,因为它能对Flate压缩进行解码,其中包含:
pip3 install polyfile
Also check out the `--html` option!
But you’ll need to “fix” this PDF first!但是,Binwalk无法自动解码第二个流,因为它是用ASCIIHex和DCT PDF过滤器进行编码的。对于没有利用所有线索,同时还不熟悉PDF规范的普通参赛者来说,可能根本没有意识到0x1337号PDF流对象还存在另一个版本! 而旗标就是在这个版本中。当然,借助于一个PDF的解码器的快速实现,参赛者仍然可以从binwalk提取的几十个文件中找出这个旗标,甚至直接使用十六机制编辑器从流内容中找到旗标。但是,既然Polyfile可以帮你完成这些任务,为什么还要费这些劲呢?
Polyfile challenge_fixed.pdf -html challenge_fixed.html。

利用PolyFile处理挑战赛中的PDF文件后,得到的HTML输出
哦,嘿,那是PDF对象的分层表示,还有一个交互式的十六进制查看器!现在,让我们来看看0x1337号对象的数据流:

我们一眼就能看到PDF的0x1337号对象。
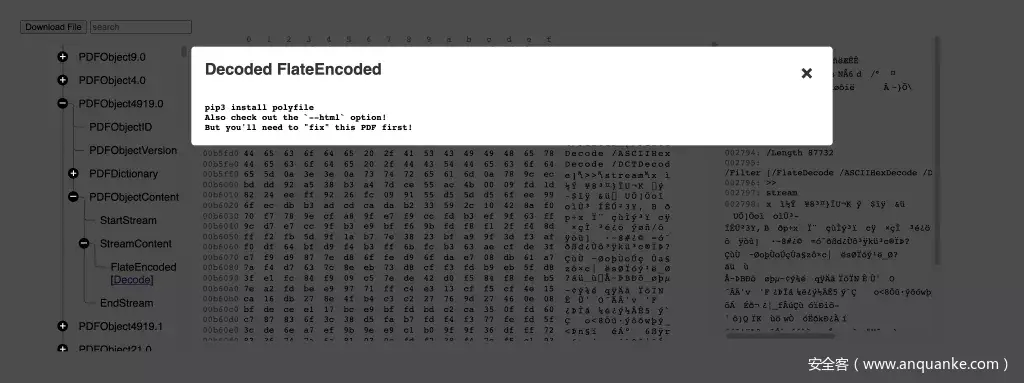
PolyFile可以自动对这些对象进行解码。
最后,让我们看看0x1337号对象的另一个版本,其中包含了经过多重编码的旗标:

PolyFile能够对分层的PDF过滤器进行解码,以生成旗标。

成功!
小结
PDF是一种非常灵活的文件格式。看上去受损的PDF,并不意味着它真的受损了。同时,即使一个PDF受损了,也不意味着PDF阅读器会指出它已经受损。PDF的本质是一种容器格式,它允许您对任意的二进制blob进行编码,甚至不要求这些blob对文档的渲染贡献任何内容。而这些blob可以进行多重编码,其中一些编码方式是PDF的定制功能。如果您对这些感兴趣,请观看我们关于“The Treachery of Files”的演讲,以及用于驯服它们的工具,如Polyfile与PolyTracker。