
作者:JiaYu 转自公众号:信口杂谈
1. 概述
在 360Netlab 的旧文 《“双枪”木马的基础设施更新及相应传播方式的分析》 中,提到了 双枪 木马传播过程中的一个恶意驱动程序 kemon.sys ,其中有经过自定义加密的 Ascii 字符串和 Unicode 字符串 100+ 条:

这在 双枪 木马的传播链条中只是一个很小的技术点,所以文中也没说具体是什么样的加密算法以及怎样解密,供分析员更方便地做样本分析工作。但这个技术点还算有点意思,尤其是对逆向入门阶段的朋友来说,可以参考一下解法。最近又碰到了这个驱动程序的最新变种,跟团队的老司机讨教了一番,索性写篇短文记录一下。
感谢老司机们解惑。也欢迎各路师傅不吝赐教,提一些更快准狠的解法。
2. 样本概况
MD5: b001c32571dd72dc28fd4dba20027a88
2.1 字符串加密情况
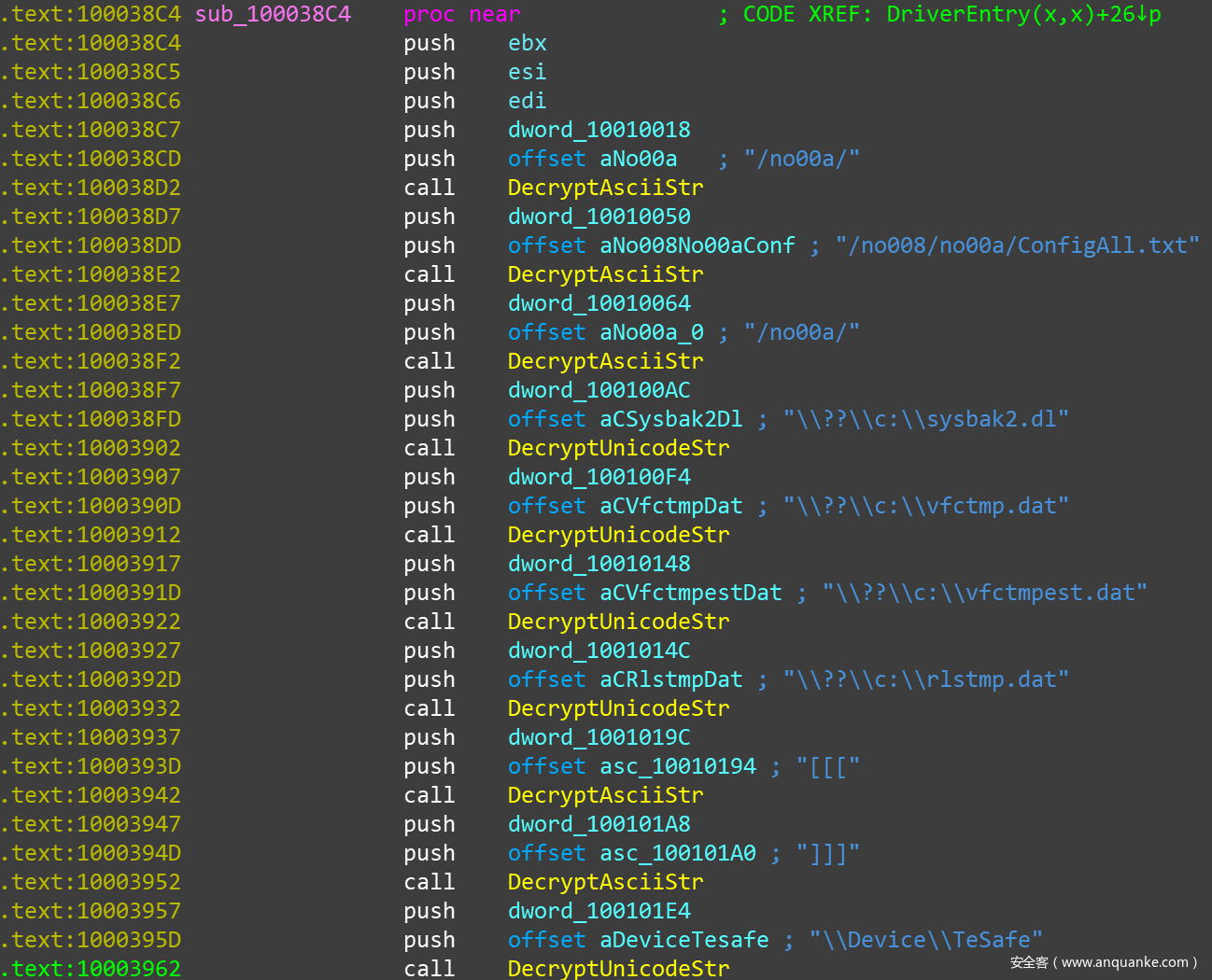
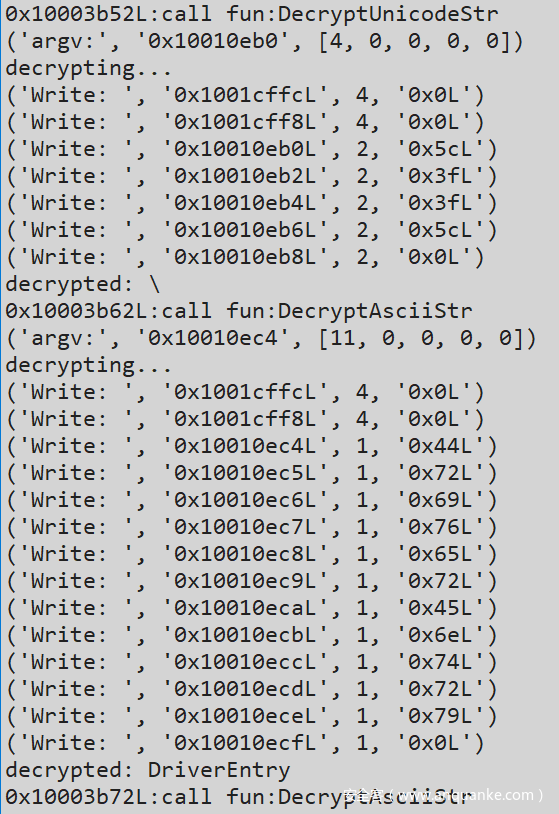
驱动程序中用到的 100+ 条字符串都做了自定义加密处理,在设置完各 IRP 派遣函数和卸载例程之后,第一步操作就是依次解密这些字符串。IDA 中打开样本,部分解密过程如下:
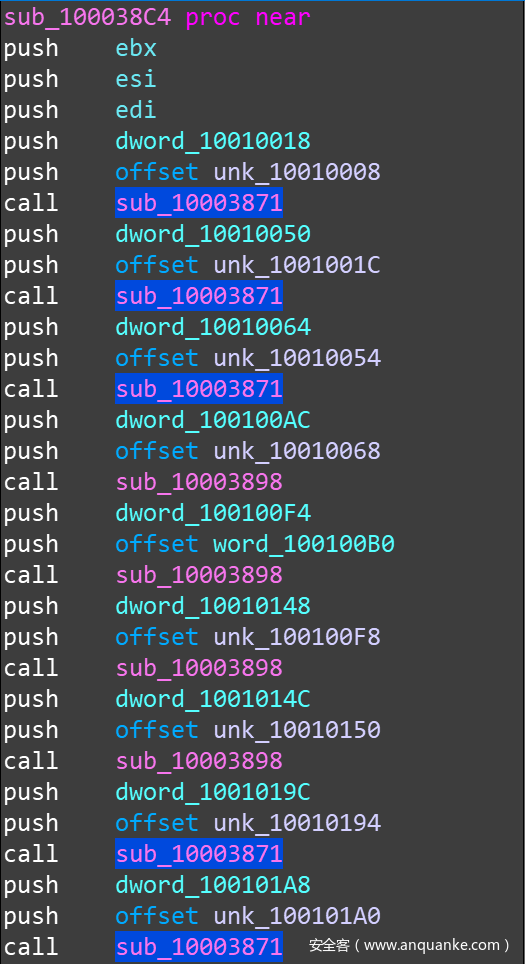
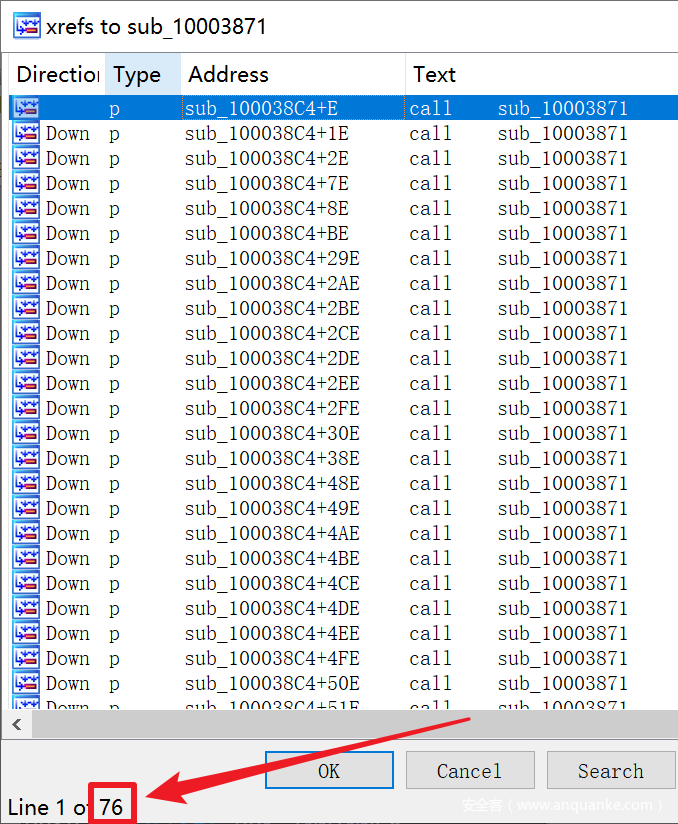
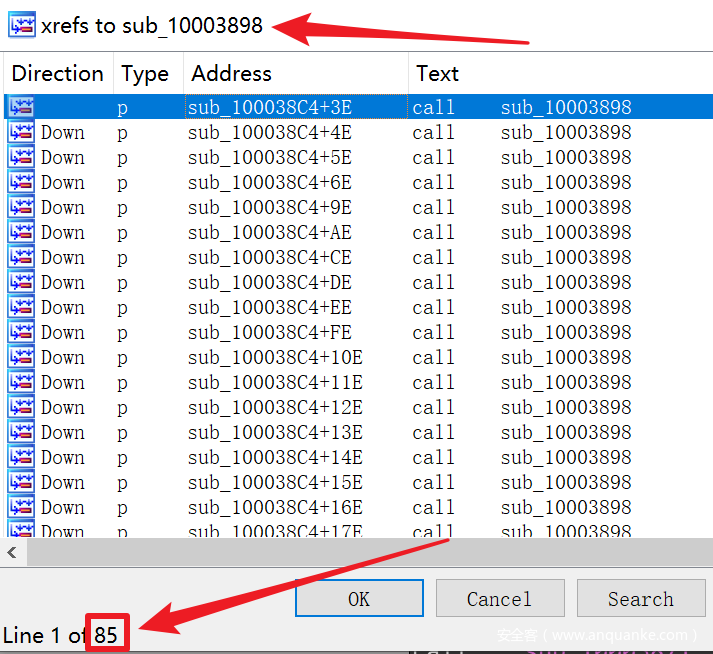
整个解密过程的函数是 sub_100038C4 ,里面会多次调用两个具体的解密函数:sub10003871 和 sub_10003898。前者解密 Ascii 字串,后者解密 Unicode 字串,都有两个参数:arg1—>要解密的字符串地址;arg2—>字符串长度。后面会把着两个函数分别命名为 DecryptAsciiStr 和 DecryptUnicodeStr 。这两个函数在 IDA 中看到的 xrefs 状况如下:
2.2 加密算法
前面说了,算法不复杂。以 DecryptAsciiStr 函数为例:
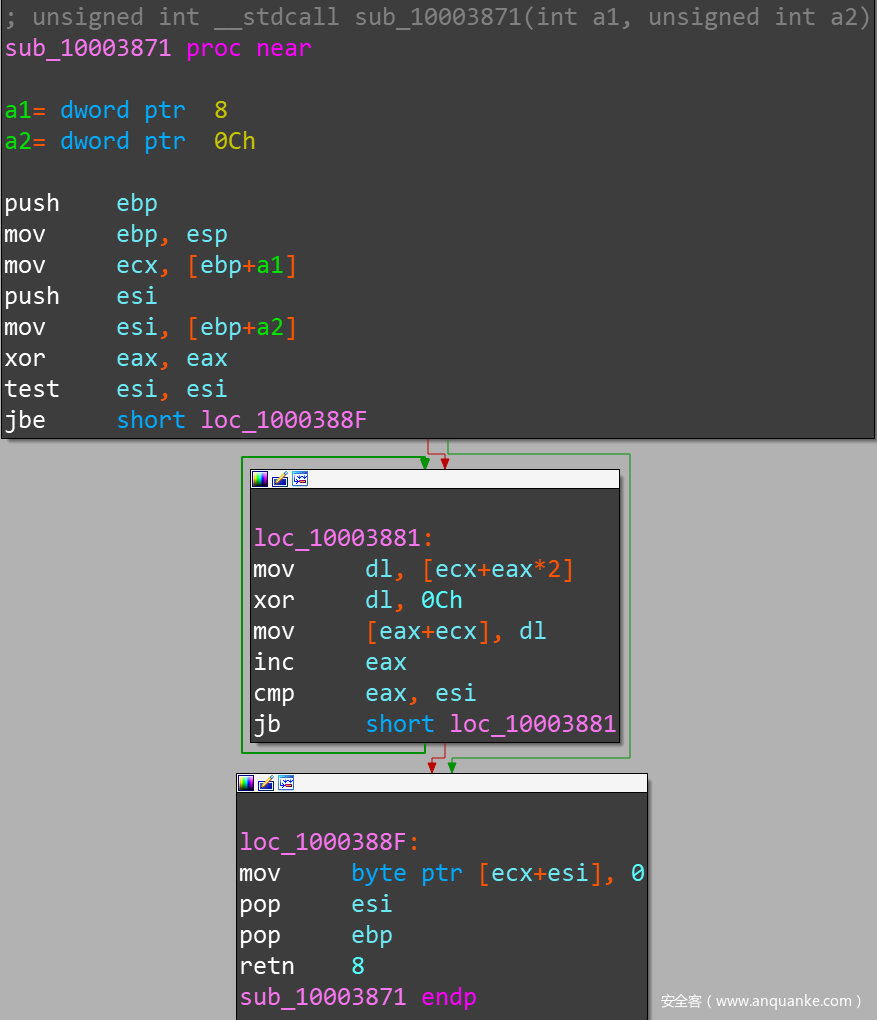
反编译看看:
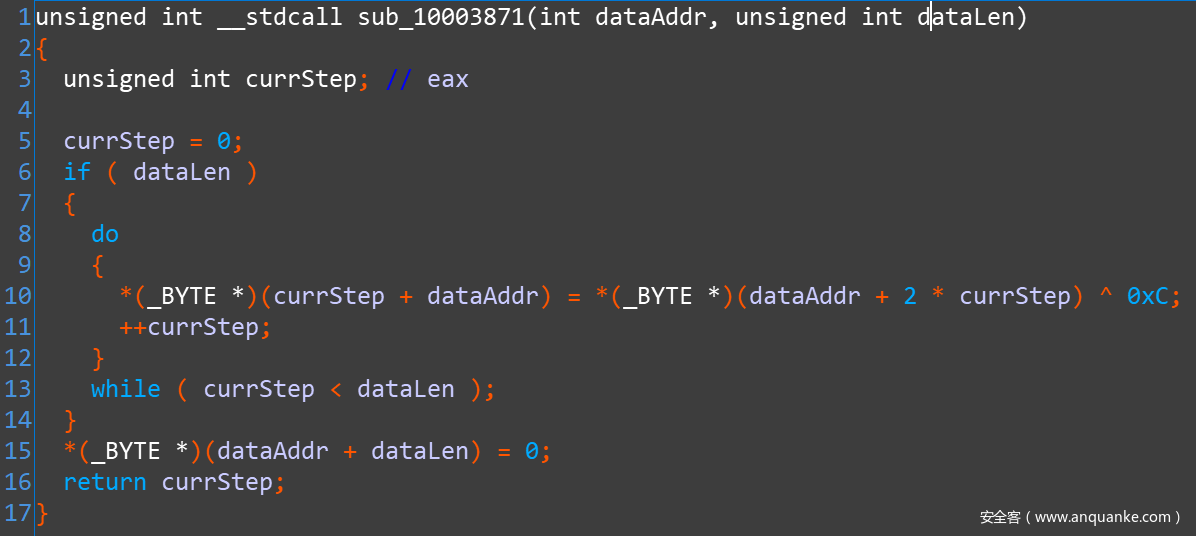
DecryptUnicodeStr 算法其实相同,只是因为字节构成不同,所以是两个解密函数分开写:
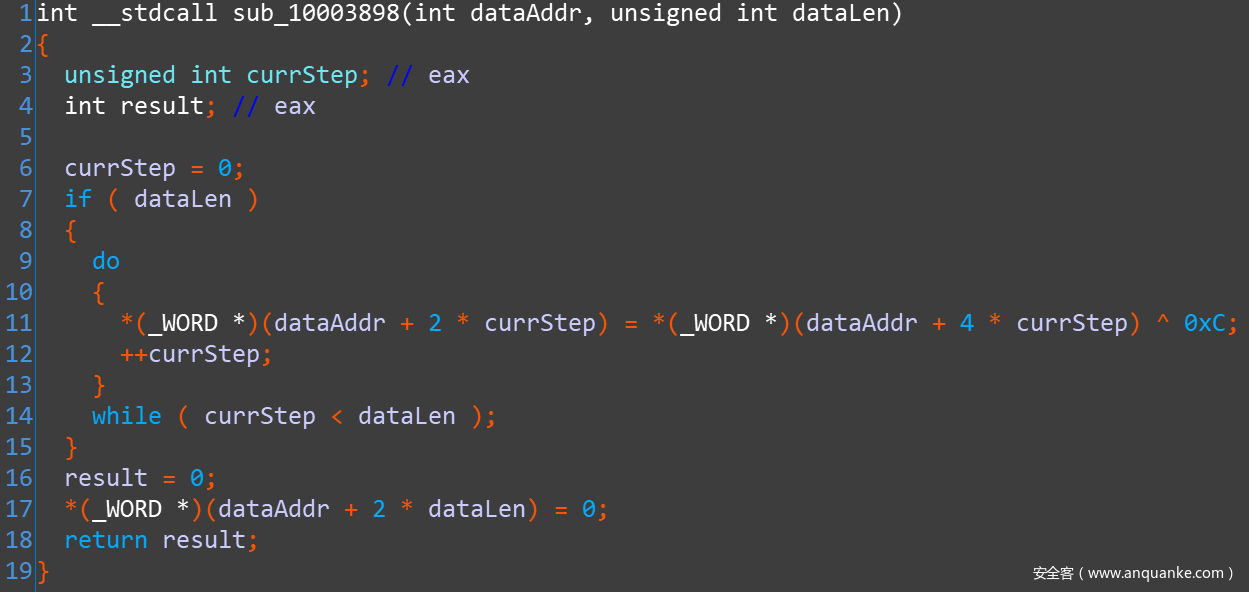
简单总结起来,这套解密过程其实就是:把当前字节后面特定偏移处的字节与 0xC 异或,然后替换掉当前字节,把解密后的字节写入到当前位置,即完成解密。本人对密码学不熟,不知道这是不是已有名号的加密算法,看起来像是 凯撒密码 的变形加强版?对此有了解的朋友欢迎指教。
3. 解密
了解了上面的情况之后,就该着手解密这百十多条字符串了。既然是用 IDA 来分析这个样本,理想的状况应该是把这些字串批量解出来,直接在 IDA 中呈现,然后就可以进行后续分析了。既然是要自动化批量解密,写 IDAPython 应该算是最便捷的做法了。最终效果如图:
3.1 姿势 1——自行实现解密算法
首先想到的思路是:就两个解密算法,而且不复杂,不妨直接写个 IDAPython 脚本,实现这两个解密算法。解密之后把明文字串直接写到 IDB 文件中,在 IDA 中呈现。两个解密算法的 Python 版本分别如下(附带对 IDB 的 Patch 操作):
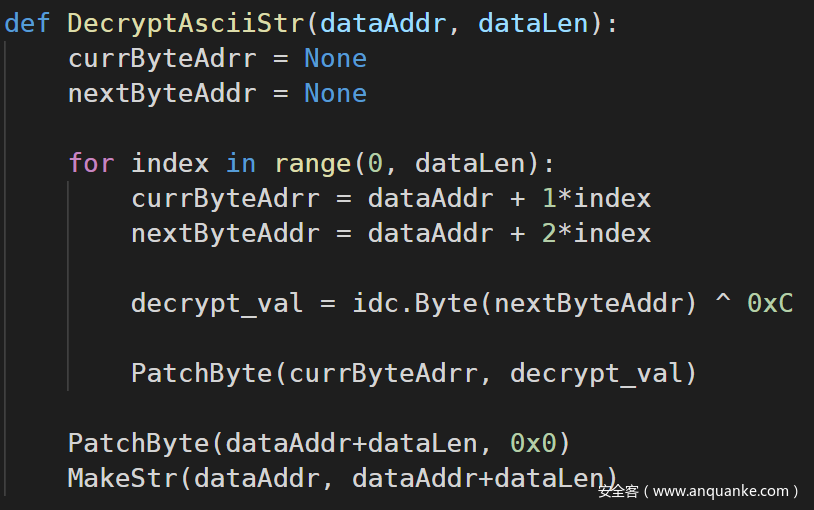
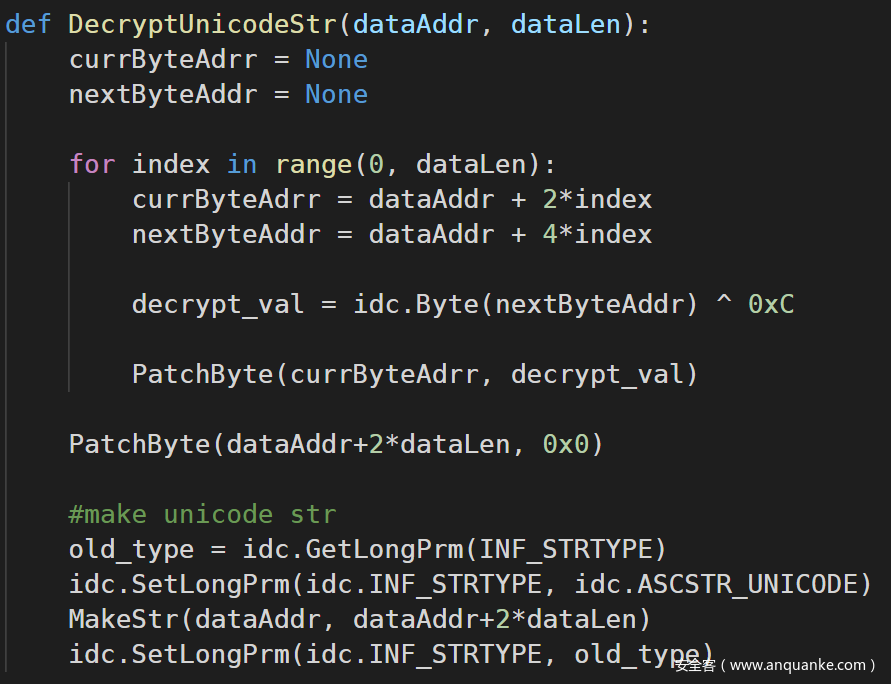
这里稍微解释一下 make unicode str 时的操作:
old_type = idc.GetLongPrm(INF_STRTYPE)
idc.SetLongPrm(idc.INF_STRTYPE, idc.ASCSTR_UNICODE)
idc.MakeStr(argv[0], argv[0]+(argv[1]*2))
idc.SetLongPrm(idc.INF_STRTYPE, old_type)
在 IDA 的 UI 界面中,可以选择生成的字符串的类型(如下图),快捷键只有一个 A,对应的 idc 函数是 idc.MakeStr(0。然而 ida.MakeStr() 函数默认是生成 Ascii 字串的,要想生成 Unicode 字串,就需要调用 idc.SetLongPrm() 函数设置一下字符串的类型。
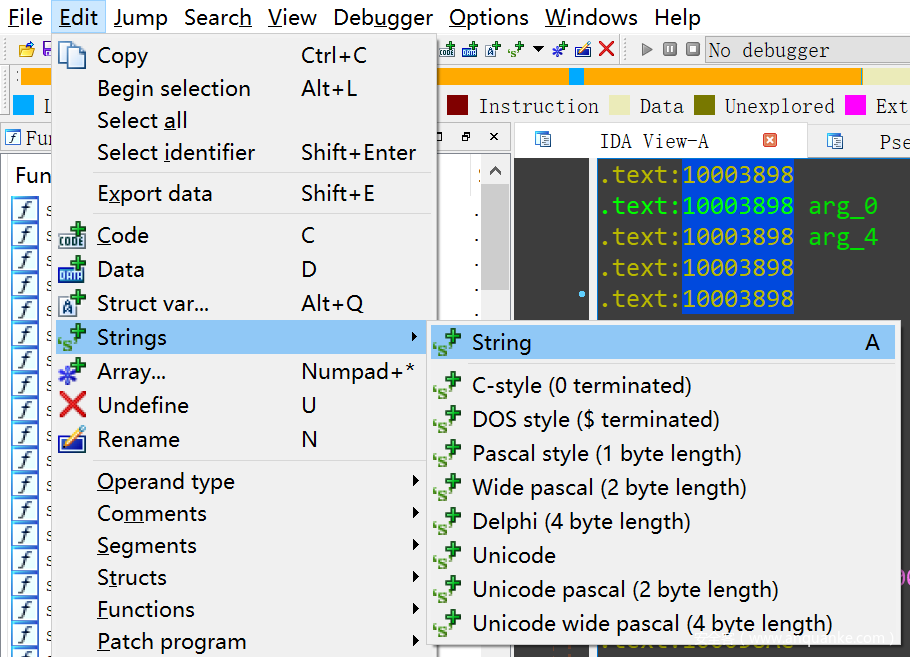
IDA 中支持的字符串类型如上图,相应地,在 idc 库中的定义如下:
ASCSTR_C = idaapi.ASCSTR_TERMCHR # C-style ASCII string
ASCSTR_PASCAL = idaapi.ASCSTR_PASCAL # Pascal-style ASCII string (length byte)
ASCSTR_LEN2 = idaapi.ASCSTR_LEN2 # Pascal-style, length is 2 bytes
ASCSTR_UNICODE = idaapi.ASCSTR_UNICODE # Unicode string
ASCSTR_LEN4 = idaapi.ASCSTR_LEN4 # Pascal-style, length is 4 bytes
ASCSTR_ULEN2 = idaapi.ASCSTR_ULEN2 # Pascal-style Unicode, length is 2 bytes
ASCSTR_ULEN4 = idaapi.ASCSTR_ULEN4 # Pascal-style Unicode, length is 4 bytes
ASCSTR_LAST = idaapi.ASCSTR_LAST # Last string type
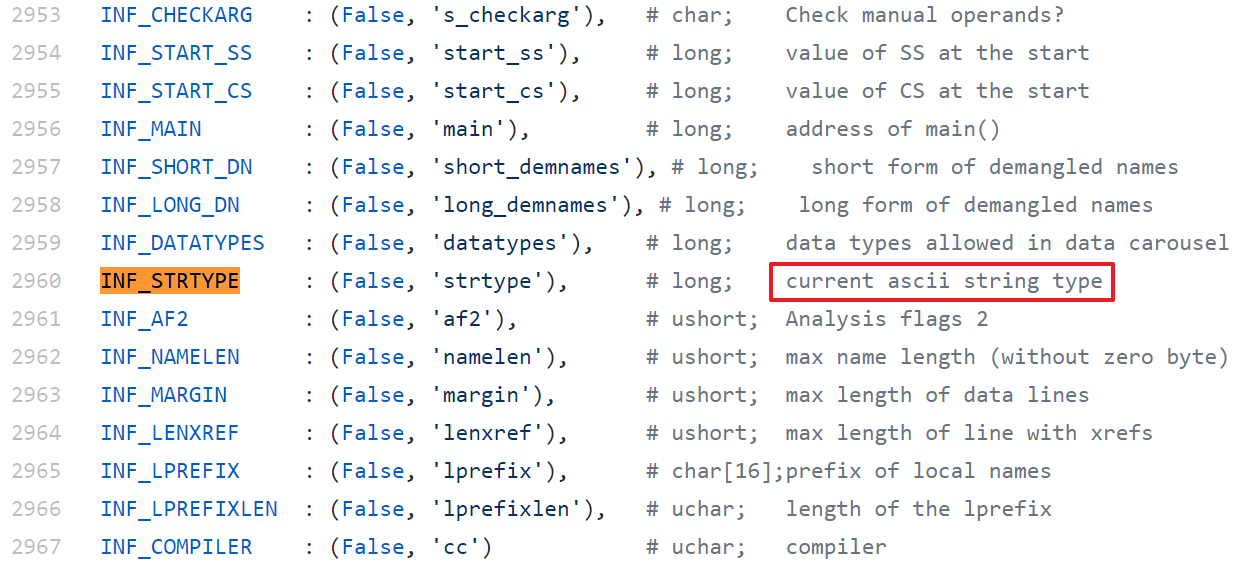
所以,要生成 Unicode 格式的字串,需要先用 idc.SetLongPrm() 函数设置一下字符串类型。其中 idc.INF_STRTYPE 即代表字符串类型的常量,在 idc 库中的定义如下:
用 Python 实现了解密函数之后,如何模拟这一波解密过程把这 100+ 条字串依次解密呢?这里可以结合 IDA 中的 xrefs 和 idc.PrevHead() 函数来实现:
- 先通过 xrefs 找到调用两个解密函数的位置;
- 再通过 idc.PrevHead() 定位到两个解密函数的参数地址,并解析出参数的值;
- 执行解密函数,将解密后的明文字串写回 IDB 并 MakeStr。
3.2 姿势 2——指令模拟
这个样本中的字串解密算法并不复杂,所以可以轻松写出 Python 版本,并直接用 IDAPython 脚本在 IDA 中将其批量解密。那如果字串解密算法比较复杂,用 Python 实现一版显得吃力呢?
这时不妨考虑一下指令模拟器。
近几年,Unicorn 作为新一代指令模拟器在业界大火。基于 Unicorn 的 IDA 指令模拟插件也不断被开发出来,比如简捷的 IdaEmu 和 FireEye 开发的功能强大的 Flare-Emu。指令模拟器可以模拟执行一段汇编指令,而 IDA 中的指令模拟插件可以在 IDA 中模拟执行指定的指令片段(需要手动指定起始指令地址和结束指令地址,并设置相关寄存器的初始状态)。这样一来,我们就可以在 IDA 中,利用指令模拟插件来模拟执行上面的批量解密指令,解密字串的汇编指令模拟执行结束,字串也就自然都给解密了。
本文 Case 的指令模拟姿势基于 Flare-Emu。
不过,这个姿势需要注意两点问题:
- 指令模拟器无法模拟系统 API ,如果解密函数中有调用系统 API 的操作,那指令模拟这个姿势就要费老劲了。
- 所谓模拟指令执行,真的只是模拟,而不会修改 IDA 中的任何数据。这样一来,需要自己把指令模拟器执行结束后的明文字串 Patch 到 IDB 文件中,这样才能在 IDA 中看到明文字串。
3.2.1 hook api
第 1 点问题,IdaEmu 中需要自己实现相关 API 的功能,并对指令片段中相应的 API 进行 Hook,才能顺利模拟。比如下图示例中,指令片段里调用了 _printf 函数,那么就需要我们手动实现 _printf 的功能并 Hook 掉指令片段中的 _printf 才行:
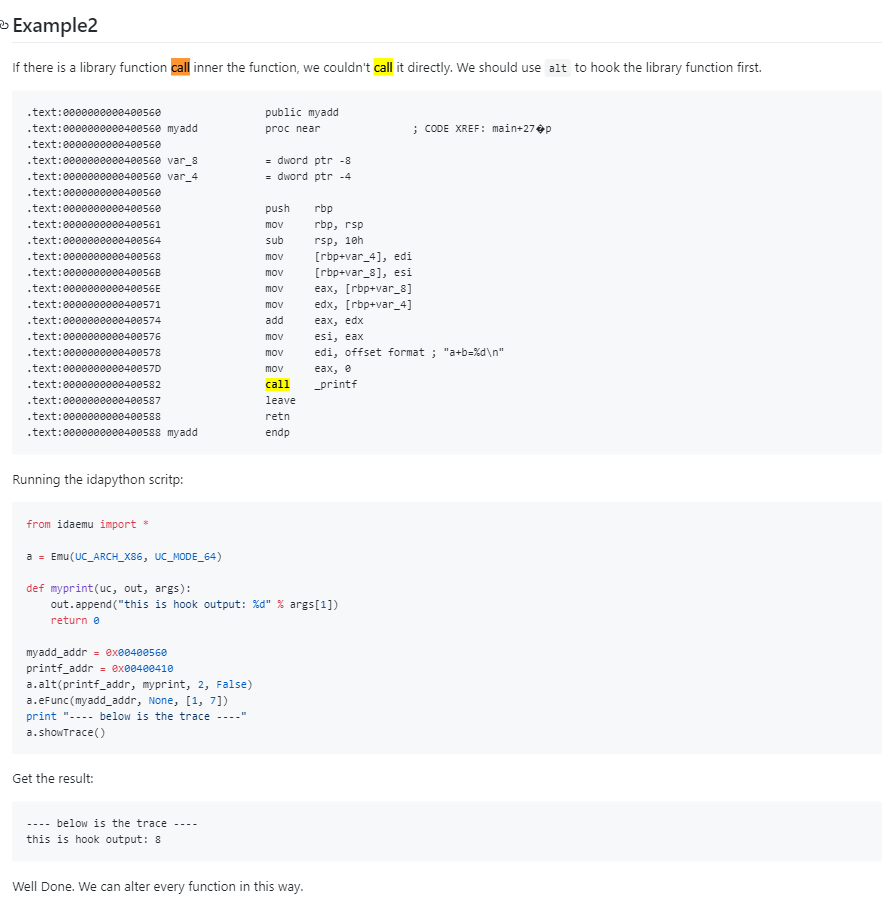
而 Flare-Emu 就做的更方便了,他们直接在框架中实现了一些基础的系统 API,而不用自己手动实现并进行 Hook 操作:

之所以提这么个问题,是因为这个 kemon.sys 样本中的批量解密字串的过程中,涉及了对 memcpy 函数的调用:
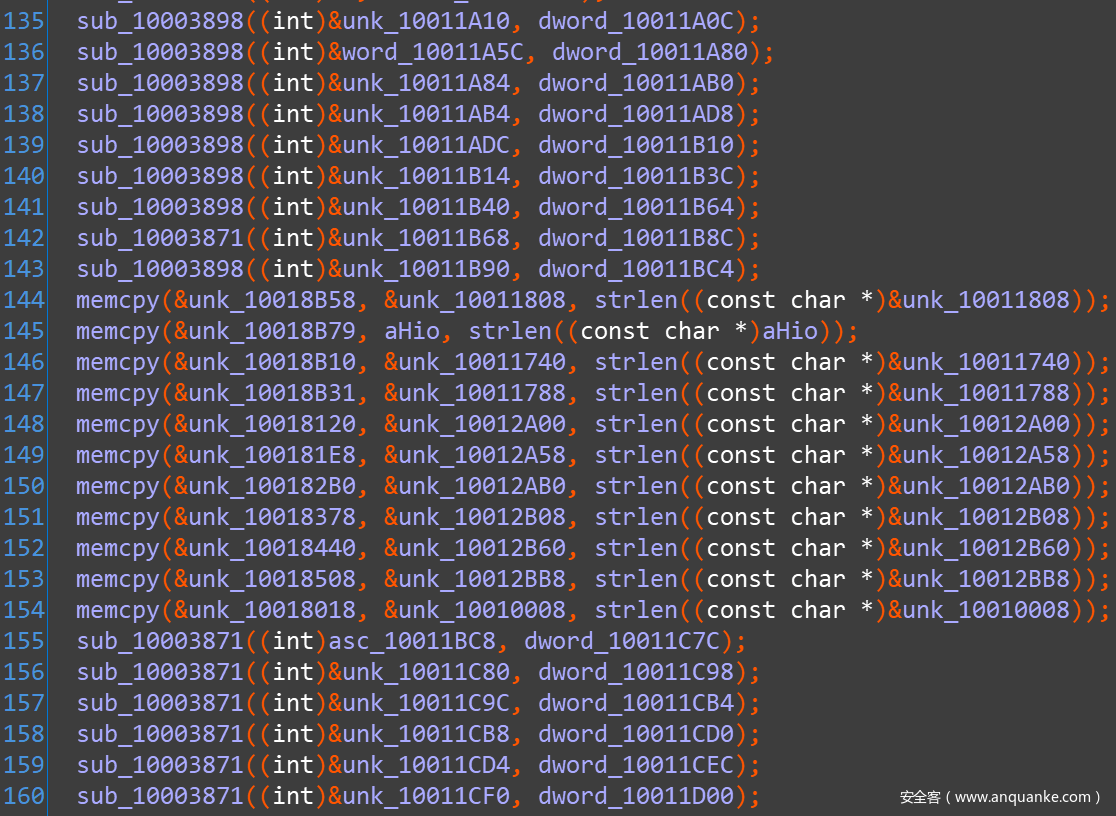
这样一来,直接用 Flare-Emu 来模拟执行应该是个更便捷的选项。
3.2.2 Patch IDB
第 2 点问题,将模拟结果写回 IDB 文件,在 IDA 中显示。
首要问题是如何获模拟执行成功后的结果——明文字符串。前面描述字串解密算法时说过,解密后的字节(Byte)会直接替换密文中的特定字节,把密文的前 dataLen 个字节解密出来,就是明文字串。这个字节替换的操作,其实对应 Unicorn 指令模拟器中定义的 MEM_WRITE 操作,即写内存,而且,字串解密过程中也只有这个字串替换操作会写内存 。恰好,Flare-Emu 中提供了一个 memAccessHook() 接口(如下图),可以 Hook 多种内存操作:
memAccessHook can be a function you define to be called whenever memory is accessed for reading or writing. It has the following prototype:
memAccessHook(unicornObject, accessType, memAccessAddress, memAccessSize, memValue, userData).
Unicorn 支持 Hook 的的内存操作有以下几个:
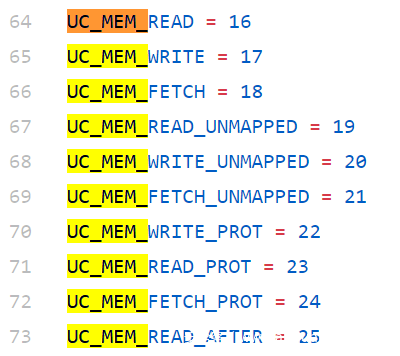
于是,我们 Hook 掉指令模拟过程中的 UC_MEM_WRITE 操作,即可获取解密后的字节,并将这些字节手动 Patch 到 IDB 中:
def mem_hook(unicornObject, accessType, memAccessAddress, memAccessSize, memValue, userData):
#if accessType == UC.UC_MEM_READ:
# print("Read: ", hex(memAccessAddress), memAccessSize, hex(memValue))
if accessType == UC.UC_MEM_WRITE:
#print("Write: ", hex(memAccessAddress), memAccessSize, hex(memValue))
if memAccessSize == 1:
idc.PatchByte(memAccessAddress, memValue)
elif memAccessSize == 2:
idc.PatchWord(memAccessAddress, memValue)
elif memAccessSize == 4:
idc.PatchDword(memAccessAddress, memValue)
Patch IDB 的基本操作当然是像前文中 IDAPython 脚本那样,调用 idc.PatchXXX 函数写入 IDB 文件。前面第一个姿势中,Patch IDB 文件,只调用了一个 idc.PatchByte() 函数。其实,idc 库中共有 4 个函数可以 Patch IDB:
idc.PatchByte(): Patch 1 Byte;
idc.PatchWord(): Patch 2 Bytes;
idc.PatchDword(): Patch 4 Bytes;
idc.PatchQword(): Patch 8 Bytes;
指令模拟器中执行 Patch 的操作,并不只有 PatchByte 这一项。根据我 print 出来的指令模拟过程中写内存操作的细节,可以看到共涉及 3 种 Patch 操作(如下图):1 byte、2 Bytes 和 4 Bytes,所有才有了上面 mem_hook() 函数中的 3 种 memAccessSize。
明确并解决了「系统 API Hook」和「捕获指令模拟结果并 Patch IDB」这两点问题,就可以写出准确无误的 IDAPython 脚本了。
3.2.3 Radare2 ESIL 模拟
r2 上也有强大的指令模拟模块,名为 ESIL( Evaluable Strings Intermediate Language):

在 r2 上用这个东西来模拟指令解密这一批字符串,就不用像 IDA 中那样还要自己动手写 IDAPython 脚本了,只需要通过 r2 指令配置好几个相关参数即可。下面两张图是在 r2 中通过指令模拟批量解密这些字符串的前后对比:
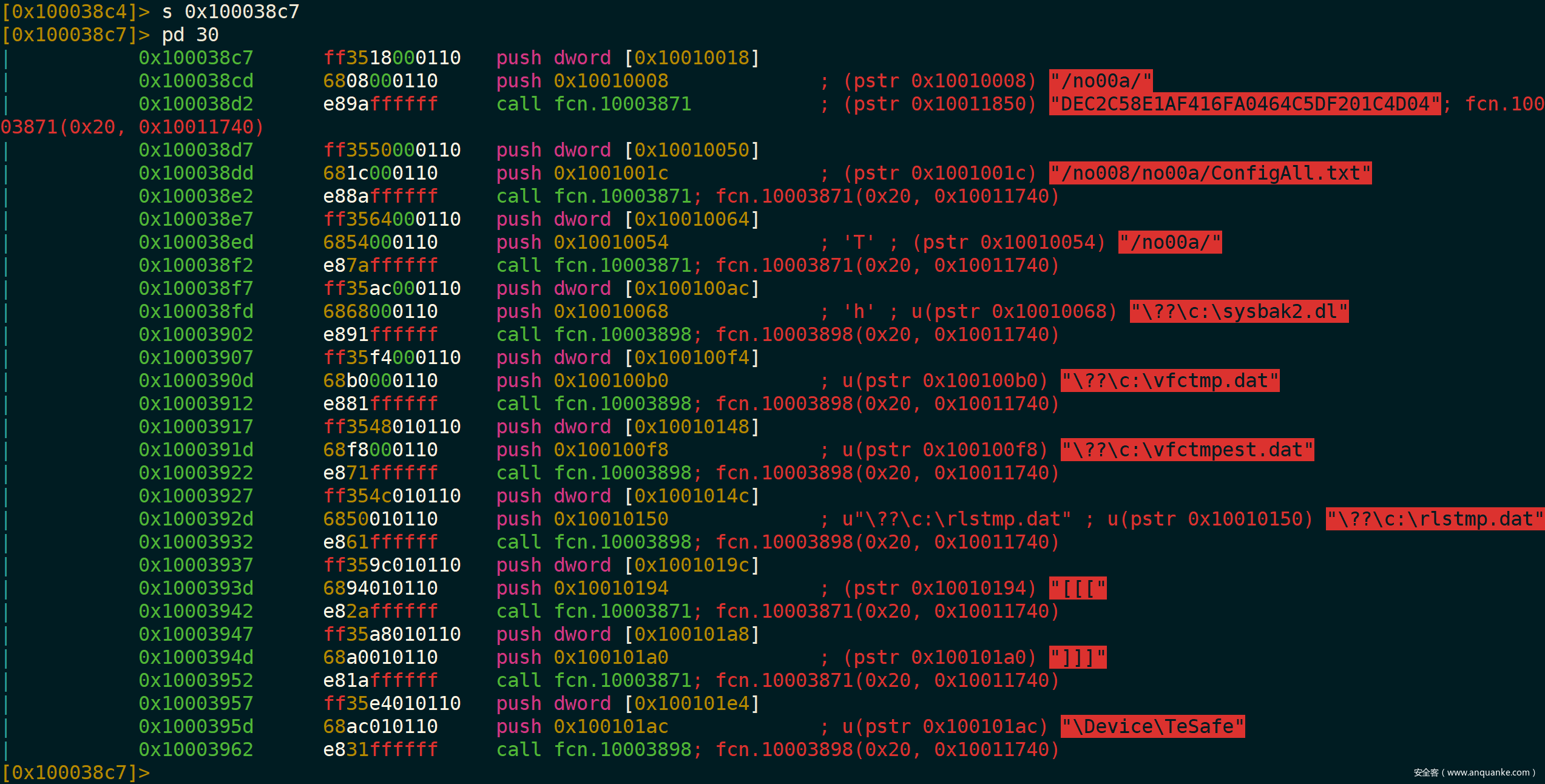
具体操作方法就不细说了,有兴趣的朋友可以自行探索。
4. 总结
文中介绍两种基本方法,在 IDA 中批量解密 双枪 木马传播中间环节的恶意驱动 kemon.sys 中的大量自定义加密字串:Python 实现解密函数和指令模拟解密函数。
原理都很简单,介绍的有点啰嗦,希望把每个关键细节都描述清楚了。
两种方法对应的 IDAPython 脚本,已上传到 Github,以供参考:
https://github.com/0xjiayu/decrypt_CypherStr_kemonsys
5. 参考资料:
- https://en.wikipedia.org/wiki/Caesar_cipher
- https://github.com/tmr232/idapython/blob/master/python/idc.py
- https://unicorn-engine.org
- https://github.com/36hours/idaemu
- https://github.com/fireeye/flare-emu
- https://github.com/unicorn-engine/unicorn/blob/master/bindings/python/unicorn/unicorn_const.py#L64