
很多网络防御系统正在被开发成可以自动提取网络威胁情报(CTI),包含半结构化数据或文本以填充知识图谱。但是潜在的风险是,虚假的CTI可能会通过开源情报(OSINT)社区或在Web上生成和传播,从而对这些系统造成数据投毒攻击。攻击者可以使用虚假CTI数据集作为训练输入以破坏网络防御系统,从而迫使模型学习不正确的输入来满足其恶意需求。
在本文中,使用Transformer自动生成虚假CTI文本。给定一个初始提示语句,具有微调的公共语言模型(如GPT-2)可以生成具有破坏网络防御系统能力的合理CTI文本。利用生成的虚假CTI文本对网络安全知识图谱(CKG,Cybersecurity Knowledge Graph)和网络安全语料库进行数据投毒攻击。投毒攻击会导致返回不正确的推理输出。本研究使用传统方法进行评估,并与网络安全专业人员和威胁猎人进行实验研究。根据这项研究,专业威胁猎人同样有可能认为生成的虚假CTI是真实的。
0x01 Introduction
社交媒体,暗网,安全博客和新闻来源等开源平台在为网络安全社区提供网络威胁情报(CTI)方面发挥着至关重要的作用。这种基于OSINT的威胁情报通过分析野外发现的恶意软件以及情报界获得的恶意软件,对IBM,Virtustotal或Mandiant等公司收集的资源进行了补充。 CTI是与网络安全威胁和威胁行为者有关的信息,与分析人员和系统共享以帮助发现和减轻威胁事件。可以使用诸如结构化威胁信息表达式(STIX,Structured Threat Informatione Xpression)和开源威胁情报和共享平台(MISP,Malware Information Sharing Platform)之类所定义的文本字段,以文本或半文本数据的形式共享CTI。最近的研究表明,文本分析方法可用于将普通文本的威胁信息转换为结构更清晰的格式,甚至被纳入防御系统中以进行检测。
尽管开源威胁情报有许多明显的好处,但是在这些平台上处理和处理错误信息已成为人们日益关注的问题。安全社区的错误信息风险是攻击者可能散布虚假的CTI,企图破坏手机和使用CTI信息的系统。 2021年1月,Google威胁分析小组发现了一个针对安全研究人员的持续攻击。由各种国家政府支持的攻击者创建了虚假的账户和博客文章,其中包含有关各种漏洞利用的文本网络安全性信息,企图将安全研究人员从可靠的CTI引入歧途。
虚假CTI的传播主要影响依赖这些信息以跟踪最新威胁趋势网络分析人员,以及收集CTI以采取正确防护措施的网络防御系统。现在有很多正在开发的下一代网络防御系统,自动从开源CTI中提取数据并填充知识图谱,然后将其用于检测潜在的攻击或作为机器学习系统的训练数据。

攻击者可以将虚假的CTI用作网络防御系统的恶意训练输入。这种类型的攻击通常称为数据投毒攻击。许多依赖此数据的网络防御系统会自动从常见来源收集CTI数据流。攻击者可以跨开源发布虚假CTI,从而轻松渗透到基于AI的网络防御系统的训练语料库中。这些虚假的信息对网络分析师而言是正常的,但实际上,它们具有与真实数据相矛盾的虚假成分。从上表中的样本可以看出,可以生成令人信服的虚假CTI,它提供有关攻击所利用的漏洞或其后果的错误信息。这可能会导致分析人员在采取何种措施应对威胁方面感到困惑。在收集CTI的自动化系统网络防御系统中,这也可能会完全破坏推理和学习过程,或者迫使模型学习错误的输入以服务于攻击者的恶意目标。针对开源CTI演示的技术也可以应用于某些机密数据,例如属于特定公司或政府实体的专有信息。在这种情况下,潜在的攻击策略将很有可能被归类为内部威胁,而攻击者将希望利用内部系统的员工。
本文生成的虚假CTI成功地迷惑了专业的威胁猎人,并导致他们将几乎所有虚假的CTI标记为真实。然后还使用生成的虚假CTI数据集来演示对CKG和网络安全语料库的数据投毒攻击。
A.Transformer模型
编码器-解码器配置给了当前最新的语言模型灵感,例如GPT和BERT,它们利用了Transformer体系结构。类似于基于递归神经网络(RNN)的序列到序列(Seq2Seq)模型,Transformer编码器将输入序列映射到抽象的高维空间中。解码器将向量转换为输出序列。与Seq2Seq不同,Transformer不使用任何RNN,而仅依赖于注意力机制来生成序列。
Seq2Seq体系结构依靠LSTM单元一次处理一个词的输入序列。在Transformer模型中,所有输入字都是并行处理的。因此,Transformer引入了位置编码的概念,以便在每个单词的n维向量中捕获词排序信息。Transformer的编码器和解码器组件还包含 multi-head注意力机制。可以使用以下公式显示:
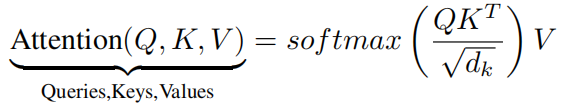
其中Q代表查询,K代表键,V代表值。 在编码器的开头,y为初始句子表示形式。当它穿过编码器的每一层时,y会被不同的编码器层更新。输入y用于计算上式中的Q,K和V。通过将矩阵点积QK的转置除以并除以这些键的维数的平方根√dk来计算注意力。最后,使用注意力权重,找到值V的加权和。解码器注意机制的工作方式与编码器类似,但是采用了masked multihead注意力。还添加了线性和softmax层,以产生每个单词的输出概率。在本文中,专注于专门使用解码器模块的GPT-2模型。
B.基于Transformer的用例
Transformer模型具有许多用例,例如机器翻译,问答和文本摘要生成。生成的Transformer模型的一个流行用例是OpenAI GPT。近年来,还开发了GPT-2和GPT-3模型(在撰写本文时,仅可通过Paywall API访问GPT-3,并且该模型及其其他组件不可用)。跨代的GPT模型在使用的数据集大小和添加的参数数量方面彼此不同。例如,用于训练GPT-2的WebText数据集包含八百万个文档。
在本文实验中使用了GPT-2。未标记的数据用于为一般任务预训练无监督的GPT模型。对通用的预训练模型进行微调是扩展体系结构以完成更具体任务的一种常用方法。Transformer已被用来检测和产生错误信息。错误信息通常可以归类为谎言,虚假信息,无根据的事实,误解和过时的事实。 还可以利用基于BERT的Transformer来检测围绕COVID-19的虚假信息。
C.基于AI的网络系统和知识图谱
下一代网络防御系统使用各种知识表示技术,例如单词嵌入和知识图谱,以改善对潜在攻击的系统推理。 CTI的使用是此类系统不可或缺的组成部分。以前已经使用网络安全知识图来表示各种实体,源CTI已用于构建CKG和其他代理,以帮助在组织中工作的网络安全分析师。例如 Cyber-All-Intel和CyberTwitter,它们利用各种知识表示形式来扩充和存储CTI。
D.对抗机器学习和投毒攻击
对抗机器学习(AML,Adversarial Machine Learning)是一种通过向模型提供欺骗性输入来破坏ML系统的技术。攻击者使用这些方法来操纵基于AI的系统学习,以改变受保护的行为并达到自己的恶意目标。对抗技术有几种类型,例如逃避,模型提取,反演和投毒攻击。在本文中,将重点放在数据投毒攻击策略上。数据投毒攻击是通过污染训练数据集而直接损害基于AI的系统的学习过程完整性的方法的样本。这些方法严重依赖于合成或不正确的输入数据的使用。基于AI的网络防御系统可能会将虚假数据包含到他们的训练语料库中。攻击者通过确保系统学习到虚假输入并对实际数据进行错误处理,从而控制了未来的输出。
McAfee Advanced Threat Research团队展示的VirusTotal投毒攻击就是这种攻击的一个例子。此攻击危害了几个收集VirusTotal数据的入侵检测系统。攻击者创建了勒索软件系列样本的变体,并将变体上载到VirusTotal平台。收集VirusTotal数据的入侵检测系统将突变文件归为特定的勒索软件系列。
0x02 Methodology
在本节中描述了虚假CTI生成流程。下图展示了整体方法。首先创建一个网络安全语料库。网络安全语料库包含来自各种OSINT来源的CTI的集合。然后,在网络安全语料库上对预训练的GPT-2模型进行微调。经过微调的模型能够自动生成大量的伪造CTI样本。最后评估模型并描述针对CTI的投毒攻击。
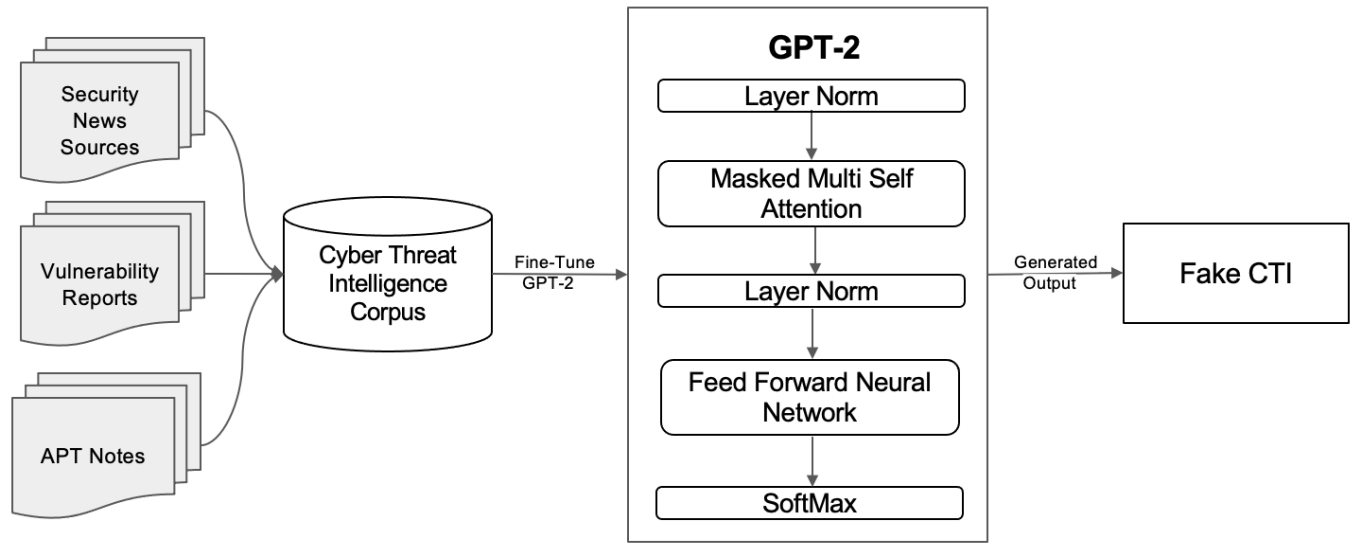
A.创建网络安全语料库
将CTI集合分为三个主要来源,如上图所示。收集安全新闻文章,漏洞数据库和高级持久威胁(APT)技术报告。安全新闻类别包含来自Krebs on Security和Cyberwire Daily的500篇文章。漏洞报告包含由MITER Corporation和国家漏洞数据库(NVD)在2019-2020年提供的16,000个常见漏洞和披露(CVE)记录。最后,从可用的APTNotes存储库中收集了500份有关APT的技术报告。
B.针对网络威胁情报数据的GPT-2微调
原始的GPT-2模型是使用WebText数据集训练的。虽然WebText数据集包含一些常规的网络安全文本,但它严重缺乏对安全社区有用的细粒度CTI信息。为了解决此问题,使用上述网络安全语料库对通用模型进行了微调。语料库中的各种CTI来源为GPT-2模型提供了各种样本,并具有适应网络安全领域多个方面的能力。像GPT-2这样的经过预训练的基于Transformer的语言模型很容易适应新的领域,例如网络安全。使用预先训练的参数来初始化模型,而不是从头训练和使用随机权重进行初始化。使用了公开发布的训练有素的GPT-2模型,其参数为117M。该模型由12层,786个维状态和12个注意力head组成。
在训练过程中,将语料库划分为35%的训练并进行测试拆分。将块大小设置为128,批处理大小设置为64,学习率设置为0.0001。利用高斯误差线性单元(GELU,Gaussian Error Linear Unit)激活函数。前图所示的GPT-2体系结构由归一化层,注意层,标准前馈神经网络和soft-max层组成。前馈神经网络包含786 * 4 size。对模型进行了23小时(20个epoch)的训练,并获得了35.9的困惑度(perplexity value)。下一部分将给出生成的CTI的样本以及有关实验的更多详细信息。
C.生成虚假CTI
使用经过微调的GPT-2模型来生成虚假的CTI示例,前表中显示了其中的三个样本。生成过程是用一个提示启动的,该提示作为对GPT-2模型进行微调的输入。该模型使用初始提示来生成虚假的CTI。生成过程如前图所示。将令牌化的提示传递给标准化层,然后传递给关注层的第一块。块输出还传递到归一化层,并馈送到前馈神经网络,前馈神经网络增加了激活函数和退出。它的输出通过softmax层,该层获得词汇表中概率最高的单词的位置编码。
第一个样本提供了有关APT组APT41的信息。在“APT41 is a state sponsored espionage group”的提示下,该模型能够对APT41进行部分虚假的叙述。 APT41是某国政府资助的间谍团体,而不是模型所指示的俄罗斯团体。尽管这是一个错误的事实,但是生成的CTI的后面部分是正确的。尽管有一些真实的信息,但围绕APT41的错误的国家信息仍然存在,并且如果被基于AI的网络防御系统吸收,则会增加相互冲突的情报。
在第二个样本中,提供了Krebs on Security文章的输入提示。该模型生成了虚假的CTI,该CTI声明将kill switch作为一项服务,而实际上,kill switch是指将网络与互联网断开连接的方法。此外,它将错误服务与Win32k框架相关联。这为虚假CTI提供了足够的信誉,并且对于网络分析师而言似乎是真实的。
最后,对于第三个样本,提供了2019 CVE记录中的输入提示。该模型生成了正确的输出,但是相关的版本和攻击类型不正确;真正的攻击是远程执行代码,而生成的攻击是特权升级。虽然远程执行代码攻击通常可以与特权升级攻击相关,但是使用跨站点请求虚假(CSRF)令牌来访问Survey.php的特定上下文对于该特定输出是不正确的。
D.评估生成的CTI
接下来,证明生成的虚假CTI是可信的。使用两种方法来证明这一点。首先,通过计算困惑度分数来评估微调模型预测测试数据的能力。接下来,进行威胁猎人评估研究。该研究要求一组网络安全专业人员和威胁猎人将一组生成的和实际的CTI样本标记为真或假。参与者的网络安全经验为2-30年(在操作环境中),平均经验为15年。这样做的目的是查看该领域的专业人员是否可以将真实的CTI与系统生成的虚假样本区分开。
在网络安全的背景下,与传统的方法(如困惑度)相比,对假CTI的现实用户评估更具指示性。生成虚假的CTI的主要目的是误导网络分析员,并绕过他们经常监视的情报管道。如果生成的CTI不具有明显格式错误的句子结构,较差的语法或难以理解的文本(明显的错误指示该文本是由机器生成的),可以假定它具有相当大的潜力让分析人员真正看到它。困惑度是通过将概率分配给测试集来确定语言模型中“不确定性”的一种常用方法。困惑度以指数平均对数损失来衡量,范围为0-100。困惑度越低,模型中存在的不确定性越小。微调的基本117M GPT-2模型的困惑度得分为24。通过在单独的测试集上计算困惑度来确保未对训练集中的文本进行模型评估,并获得了35.9的计算困惑度得分,这表明该模型具有很强的能力生成合理的文本。
为了评估在现实环境中生成的虚假CTI的潜在影响,对由十名网络安全专业人员和威胁猎人组成的小组进行了研究。为参与者提供了一组真实和虚假的CTI文本样本的评估集。参与者使用自己的专业知识,将语料库中的每个文本样本标记为真或假。通过收集来自各种来源的真实CTI的112个文本样本来创建评估集。通过将文本样本截断为前500个单词并消除部分最后的句子来对文本样本进行预处理。选择每个样本的第一句话作为微调GPT-2模型的初始提示,并生成一个不超过500个单词的伪造CTI示例。进一步将112个样本(56个真实的CTI及其生成的假样本)分为两个单独的注释集,以确保真实的CTI和直接假冒副本不属于同一注释任务的一部分。因此,每个注释任务包括28个真实文本样本和28个不重叠的生成假数据样本。将分配给参与者的每个注释任务中的数据随机化。
参与者单独工作,并将56个样本中的每个样本标记为真或假。参加者在标记每个样本时使用自己的判断,在评估过程中被禁止使用外部资源,例如搜索引擎。研究结果在混淆矩阵中提供。混淆矩阵显示560个CTI样本的真阳性,假阴性,假阳性和真阴性率(包括真假数据)。在总共560个被评估的样本中,准确度(36.8%)很低。威胁猎人错误地预测了52.5%(74个真实样本为错误,220个虚假样本为正确)和47.5%正确样本(206个真实样本为真实,60个虚假样本为错误)。尽管有他们的专长,威胁猎人还是只能将生成的样本中的60/280标记为虚假,并发现绝大部分(78.5%)的虚假样本为真。这些结果证明了所生成的CTI混淆安全专家的能力,并且如果广泛使用此类技术,也将带来麻烦。
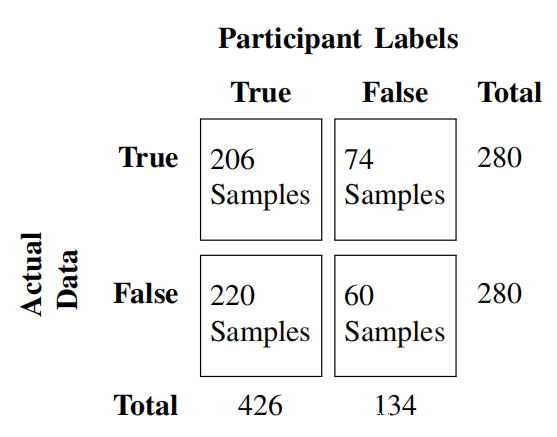
进一步调查了被正确标记为假的虚假样本,并且与被标记为真的虚假的样本相比,在文本中观察到了更多的语言错误。尽管大多数虚假的CTI包含彼此不相关的实体(例如产品和攻击媒介),但发现如果句子结构显示很少或没有语言缺陷,则数据可能被标记为真实。还注意到缺乏实质性上下文的消息源很可能被标记为错误。生成的虚假CTI不仅具有误导网络安全专业人员的能力,而且还具有渗透到网络防御系统的能力。在下一节中,将描述如何将生成的虚假CTI样本用于发起数据投毒攻击。
0x03 Data poisoning using fake CTI
使用前表中的伪造CTI样本,可以轻松地模拟数据投毒攻击,其中将伪造CTI用作训练输入,以破坏知识提取管道,攻击者可以在这里巧妙地将虚假CTI放置在多个OSINT来源上,例如Twitter,Stack Overflow,深网论坛和博客。
许多系统都包括本地爬虫和网络安全概念提取器,实体关系提取器以及知识表示技术,例如单词嵌入,张量和知识图谱。这些要么使用基于关键字的方法,要么依赖AI工具来收集和处理CTI。这些系统中的许多系统很容易被欺骗,将虚假的CTI数据与真实的CTI一起包含在网络安全语料库中。如果攻击者能够以“看上去与真实CTI非常相似”的方式制作虚假的CTI,则这尤其可能。然后,这些虚假的信息将由知识提取管道收集,该管道用于创建知识表示,例如CKG。使用虚假的CTI对语料库进行投毒可使攻击者污染各种AI系统的训练数据,以便在推理时获得所需的结果。通过影响CTI训练数据,攻击者可以指导AI模型的创建,其中任意输入将产生对攻击者有用的特定输出。
接下来,描述对涉及CKG的流行知识表示技术的攻击。由于已经可以访问输出CKG的完整CTI处理管道,因此选择演示投毒攻击对CKG的影响。一旦虚假的CTI以知识形式表示出来,就可以用来影响依赖于这些表示形式的其他AI系统。
A.处理虚假CTI
CKG包含网络实体及其现有关系。第一阶段是网络安全概念提取器,它采用CTI并提取各种网络实体。这是通过使用在网络安全语料库上受过训练的命名实体识别器(NER)来完成的。第二阶段是基于深度神经网络的关系提取器,该提取器将网络实体对的词嵌入作为输入并识别可能的关系。这导致可以声明到CKG中的实体关系集。作为运行示例,使用以下虚假的CTI文本作为提取管道的输入-
‘Malicious domain in SolarWinds hack turned into killswitch service where the malicious user clicks an icon (i.e., a cross-domain link) to connect the service page to a specific target.’
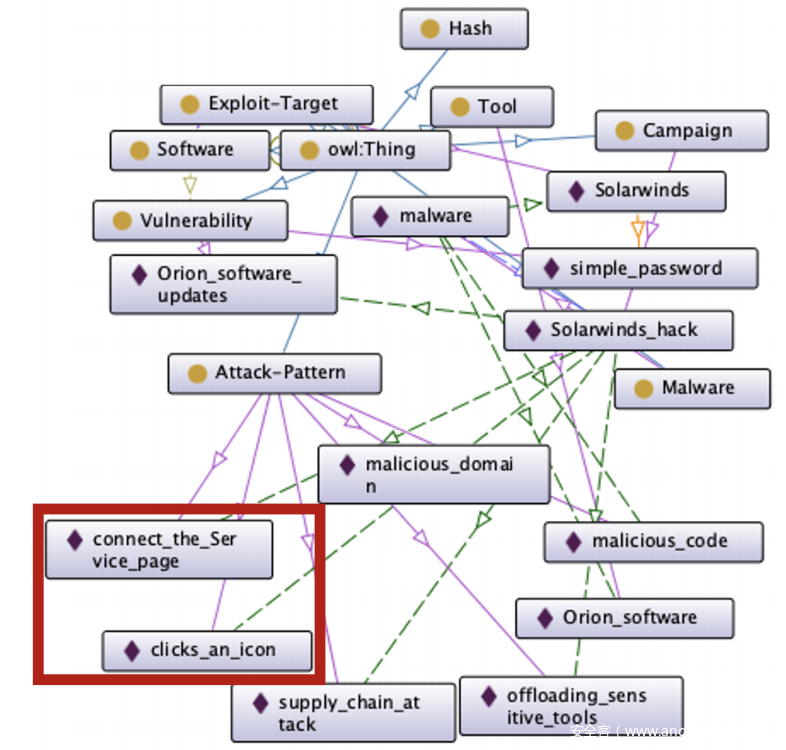
当管道接收到虚假的CTI时,网络安全概念提取器将输出服务于攻击者目标的分类。概念提取器将“clicks an icon”,“connect the service”分类为“攻击模式”。还将“ SolarWinds hack”归类为“恶意活动”。这些实体是从虚假的CTI中提取的,可能会毒害CKG。
关系提取器在处理上述虚假的CTI时,输出以下关系:
•“ Solarwinds hack”(恶意活动)-uses-“clicks an icon”(攻击模式)。
•“ Solarwinds hack”(恶意活动)-uses-“ connect the service”(攻击模式)。
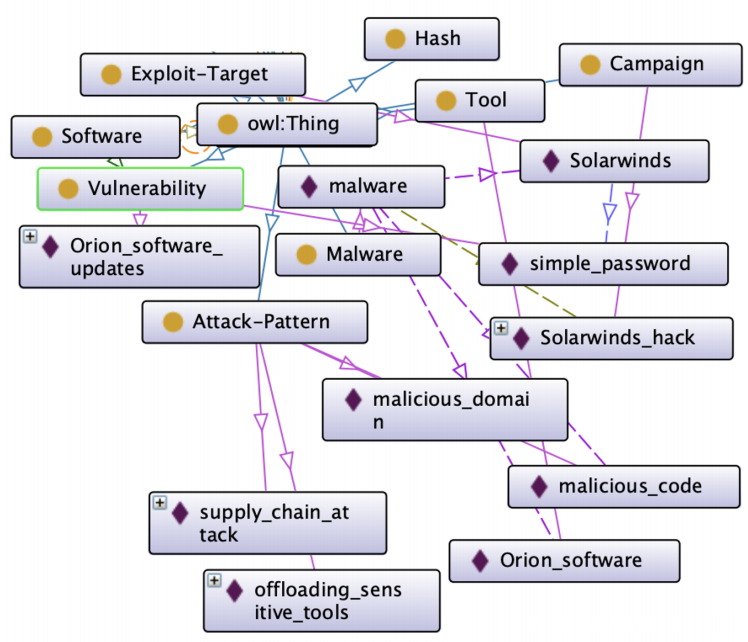
然后可以在CKG中声明提取的实体关系集。上图和下图描述了断从虚假CTI提取的知识之前和之后CKG的状态。上图包含从真实的CTI样本中提取的实体和关系,这些样本和描述定义了攻击活动“ SolarWinds hack”。可以看到诸如“Orion Software”之类的实体,被标识为“工具”,而“malicious code”之类的实体则被标识为“攻击模式”。这些实体由“ SolarWinds hack”中的恶意软件使用,并存在于真正的CTI中。还将“‘simple password”视为漏洞。下图包含从模型生成的虚假CTI中提取的其他信息。这些额外的实体和关系已与“ SolarWinds hack”实体一起声明,并用红色框标出。在此图中,可以看到CKG中捕获的其他“攻击模式”,例如 ‘connect the service page’ 和 ‘clicks an icon。这些实体是使用管道从虚假CTI中提取的,它们证明了如何将虚假CTI的投毒语料库摄入并在CKG中表示出来。
B.虚假CTI的影响
从非结构化CTI文本创建结构化知识图谱的目的是帮助安全专业人员进行研究。安全专家可以查询有关网络事件的以往知识,进行推理并在查询的帮助下检索信息。但是,如果CKG将生成的虚假信息作为数据投毒攻击的一部分吸收,则可能产生有害影响,例如返回错误的推理输出,不良的安全警报生成,造成模型损坏等。
例如,如果安全专业人员有兴趣知道哪些攻击活动使用了“click-baits”,那么他们将被“ Solarwinds hack”的结果所误导。由于虚假CTI已被吸收并以知识表示形式表示,在CKG上执行以下SPARQL查询时,

将产生以下值:
如果安全专业人员有兴趣了解有关“ Solarwinds-hack”的更多信息,则在执行适当的SPARQL查询后,他们也可能会收到不正确的信息:

该查询产生以下值:

尽管获得了一些真实的结果(来自真实CTI),但存在虚假CTI误导结果,例如 ‘connect the service page’ 和‘clicks an icon’ ,可能会误导安全专业人员。安全专业人员对网络安全攻击进行建模,并使用有关同一攻击或类似攻击的过去可用信息来生成网络/系统检测规则。他们还使用这些表示形式来生成有关未来攻击的警报。例如,利用“small password”进行“offlfloading sensitive tools”的“supply chainattack ”可能意味着SolarWinds黑客的新变种已经浮出水面。但是,如果先验知识包含与同一攻击有关的虚假CTI,则可能会生成错误的警报。
一旦这些知识表示被投毒,虚假的网络安全信息也可能对其他防御系统造成不利影响。例如,知识图谱生成的许多见解对其他系统很有用,例如,知识图生成的许多见解对于其他系统(例如基于AI的入侵检测系统或警报生成器)很有用,从而可以达到更大范围的链接系统和网络安全专业人员。
0x04 Conclusion
在本文中,使用富含CTI来源的网络安全语料库对GPT-2 Transfotmer进行了微调,从而自动生成了虚假的CTI文本描述。通过使用网络安全文本对GPT-2 Transfotmer进行微调,能够使通用模型适应网络安全领域。在最初提示的情况下,经过微调的模型能够生成逼真的虚假CTI文本样本。对网络安全专家的评估表明,生成的虚假CTI很容易误导网络安全专家。尽管有专业知识,网络安全专业人员和威胁猎人仍将大多数虚假的CTI样本标记为真实,这表明他们发现虚假的CTI样本非常逼真。使用虚假CTI来演示对知识提取系统的数据投毒攻击,该知识提取系统会自动提取开源CTI。通过比较数据投毒攻击之前和之后CKG的状态,举例说明了虚假CTI的影响。