
前言
最近发现高质量比赛越来越多使用glibc-2.29的环境了,为了赶上出题人逐渐高(变)明(态)的出题思路,趁机学习一波glibc-2.29源码,看看对比2.27多了哪些保护措施,又有哪些利用手段失效了,并提出本人能想到的相应的应对方法。 本文讨论的都是基于64位环境,32位环境的结构体、偏移等需要相应变化。
tcache结构和成员函数变化
//glibc-2.29
typedef struct tcache_entry
{
struct tcache_entry *next;
/* This field exists to detect double frees. */
struct tcache_perthread_struct *key;
} tcache_entry;
//glibc-2.27
typedef struct tcache_entry
{
struct tcache_entry *next;
} tcache_entry;glibc-2.29在tcache_entry结构体中加上一个8字节指针key。
//glibc-2.29
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
assert (tc_idx < TCACHE_MAX_BINS);
/* Mark this chunk as "in the tcache" so the test in _int_free will
detect a double free. */
e->key = tcache; //new
e->next = tcache->entries[tc_idx];
tcache->entries[tc_idx] = e;
++(tcache->counts[tc_idx]);
}
tcache_get (size_t tc_idx)
{
tcache_entry *e = tcache->entries[tc_idx];
assert (tc_idx < TCACHE_MAX_BINS);
assert (tcache->entries[tc_idx] > 0);
tcache->entries[tc_idx] = e->next;
--(tcache->counts[tc_idx]);
e->key = NULL; //new
return (void *) e;
}
//glibc-2.27
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
assert (tc_idx < TCACHE_MAX_BINS);
e->next = tcache->entries[tc_idx];
tcache->entries[tc_idx] = e;
++(tcache->counts[tc_idx]);
}
tcache_get (size_t tc_idx)
{
tcache_entry *e = tcache->entries[tc_idx];
assert (tc_idx < TCACHE_MAX_BINS);
assert (tcache->entries[tc_idx] > 0);
tcache->entries[tc_idx] = e->next;
--(tcache->counts[tc_idx]);
return (void *) e;
}在将chunk放入tcache之后,会将chunk->key设置为tcachestruct,即是heap的开头,来表示该chunk已经放入了tcache。而将chunk从tcache取出来后则将chunk->key设置为NULL清空。 总体上对tcache的改动是在tcacheentry结构指针中增加了一个变量key,来表明该chunk是否处于tcache的状态。
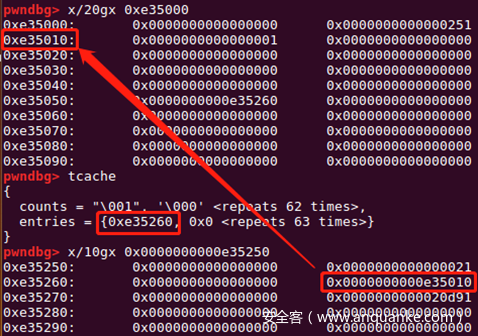
intfree函数
//glibc-2.29
{
size_t tc_idx = csize2tidx (size);
if (tcache != NULL && tc_idx < mp_.tcache_bins)
{
/* Check to see if it's already in the tcache. */
tcache_entry *e = (tcache_entry *) chunk2mem (p);
/* This test succeeds on double free. However, we don't 100%
trust it (it also matches random payload data at a 1 in
2^<size_t> chance), so verify it's not an unlikely
coincidence before aborting. */
if (__glibc_unlikely (e->key == tcache))
{
tcache_entry *tmp;
LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
for (tmp = tcache->entries[tc_idx];
tmp;
tmp = tmp->next)
if (tmp == e)
malloc_printerr ("free(): double free detected in tcache 2");
/* If we get here, it was a coincidence. We've wasted a
few cycles, but don't abort. */
}
if (tcache->counts[tc_idx] < mp_.tcache_count)
{
tcache_put (p, tc_idx);
return;
}
}
}
//glibc-2.27
{
size_t tc_idx = csize2tidx (size);
if (tcache//free+172
&& tc_idx < mp_.tcache_bins
&& tcache->counts[tc_idx] < mp_.tcache_count)
{
tcache_put (p, tc_idx);
return;
}
}glibc-2.29中增加了一个check:chunk在放入tcache之前会检查chunk->key是否为tcache,表示是否已经存在于tcache中,如果已经存在于tcache,则会检查tcache链中是否有跟他相同的堆块。 这对double free造成了很大的障碍。我认为绕过的一种方法是:如果有存在UFA漏洞或者形成堆重叠等情况,可以篡改chunk->key,使其e->key != tcache,就能不进行下面的check。
例题
int main()
{
long* p1 = malloc(0x10);
long* p2 = malloc(0x10);
free(p1);
free(p2);
//*(p1+1)=0xdeadbeef;
free(p1);
return 0;
}
正常情况下,glibc-2.29会检测到tcache上的double free。
int main()
{
long* p1 = malloc(0x10);
long* p2 = malloc(0x10);
free(p1);
free(p2);
*(p1+1)=0xdeadbeef;
free(p1);
return 0;
}如果将其e->key修改后,通过调试可以发现能绕过e->key==tcahce的检查,从而实现double free。
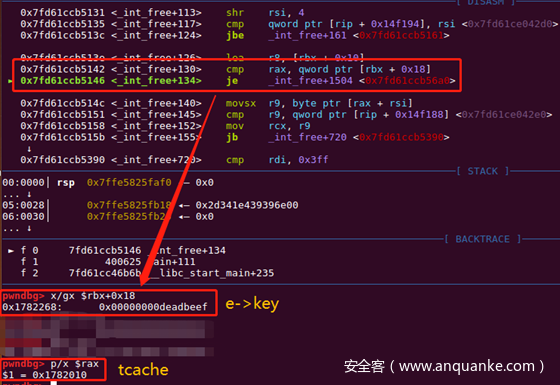
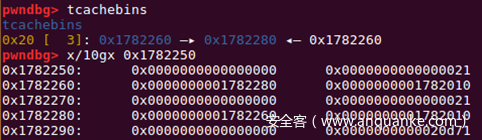
但是这种绕过方法本身利用的堆溢出漏洞往往是可以修改fd的,这个时候其实也就没有必要修改e->key,可以直接篡改e->next(即fd)来实现任意地址写。因此要绕过这种保护机制本身又需要其他漏洞,利用起来比较麻烦。
unlink
//glibc-2.29
if (!prev_inuse(p)) {
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
if (__glibc_unlikely (chunksize(p) != prevsize)) //new
malloc_printerr ("corrupted size vs. prev_size while consolidating");
unlink_chunk (av, p);
}
//glibc-2.27
if (!prev_inuse(p)) {
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(av, p, bck, fwd);
}glibc-2.29在unlink操作前增加了一项检查:
要合并的size和本来要释放的chunk的prevsize是否相等
这种利用方式常见于off by one,修改prev_inuse表示位为0,然后通过修改prevsize使得合并指定偏移的chunk,而size基本上都是不等于伪造的presize的,这对off by one的利用提出更高的要求。
一种方法是如果off by one溢出的那个字节可以控制,需要将合并的chunk的size改大,使其越过在其下面若干个chunk,满足size==prevsize的条件,还是可以形成chunk overlapping的。但因为off by null只可能把size改小,所以如果不能控制溢出的字节,就无法构造chunk overlapping了。
intmalloc函数
unsortedbin
//glibc-2.29
mchunkptr next = chunk_at_offset (victim, size);
if (__glibc_unlikely (chunksize_nomask (next) < 2 * SIZE_SZ)
|| __glibc_unlikely (chunksize_nomask (next) > av->system_mem))
malloc_printerr ("malloc(): invalid next size (unsorted)");
if (__glibc_unlikely ((prev_size (next) & ~(SIZE_BITS)) != size))
malloc_printerr ("malloc(): mismatching next->prev_size (unsorted)");
if (__glibc_unlikely (bck->fd != victim)
|| __glibc_unlikely (victim->fd != unsorted_chunks (av)))
malloc_printerr ("malloc(): unsorted double linked list corrupted");
if (__glibc_unlikely (prev_inuse (next)))
malloc_printerr ("malloc(): invalid next->prev_inuse (unsorted)");这段代码是glibc-2.29新增的检查,有4项检查内容:
1、下一个chunk的size是否在合理区间
2、下一个chunk的prevsize是否等于victim的size
3、检查unsortedbin双向链表的完整性
4、下一个chunk的previnuse标志位是否为0
其中第三项检查内容对unsortedbin attack来说阻碍很大,因为unsortedbin attack目的是往目标地址中写入main_arena地址,需要修改victim->bk也即bck。如果还想这么利用,就需要在目标地址上写上victim的地址(通常是heap地址,因此需要提前知道heap地址),而且还有一点是不能修改victim->fd的值,除非在篡改victim->bk的时候不覆盖掉victim->fd或者已知libc地址。也就是说,在大多数情况下,除非你已知heap和libc的地址,否则很难在利用unsortedbin attack了。
use_top
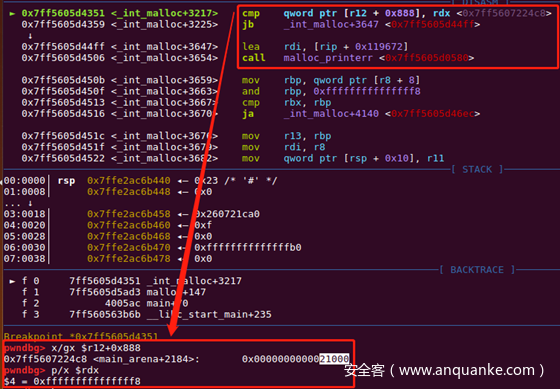
//glibc-2.29
if (__glibc_unlikely (size > av->system_mem))//0x21000
malloc_printerr ("malloc(): corrupted top size");glibc-2.29在使用top chunk的时候增加了检查:
size要小于等于system_mems
因为House of Force需要控制top chunk的size为-1,不能通过这项检查,所以House of Force在glibc-2.29以后就载入史册了。
示例
将top chunk的size写为-1后 显然无符号比较-1>0x21000,不能通过检查。
结语
glibc-2.29增加了不少的保护措施,不学习就跟不上时代潮流了。笔者通过大致阅读常用的几个函数,发现以上与安全相关的变化,主要涉及到tcache、unlink、top chunk、unsortedbin这四类结构或功能的变化。glibc-2.29可能还有其他新的机制还没有被发现,可能也有其他的绕过方式,希望各路大佬多多指导指导!