
0-day Web攻击可以说是对Web安全的最严重威胁,但要检测起来非常具有挑战性,因为以前没有看到或知道它们,因此,广泛部署基于签名的Web应用程序防火墙(WAF)无法检测到它们。本文提出了一种无监督工具ZeroWall,该工具可以与现有WAF一起使用,有效地检测0-day Web攻击。 ZeroWall使用现有的基于签名的WAF允许的历史Web请求(其中大部分假定为良性),使用编码-解码递归神经网络(Encoder-Decoder RNN)训练自翻译机,以捕获良性请求的语法和语义模式。在实时检测中,自翻译器(self-translation machine)无法很好地理解的0-day攻击请求(WAF无法检测到该攻击)无法被机器翻译回其原始请求,因此被定义为攻击。在评估中,使用了8条真实的14亿个Web请求的真实记录,ZeroWall成功地检测了现有WAF错过的真实0-day攻击,并取得了0.98以上的高F1-score,这大大优于所有比较方法。
0x01 Introduction
为了防御Web攻击,已提出各种基于机器学习防御措施,但是大多数这些方法不能有效地检测0-day Web攻击。0-day Web攻击由于以下原因而特别难以检测:首先,由于以前从未出现过0-day Web攻击,因此大多数监督方法都是不合适的,因为这些方法始终需要标记数据进行训练,而与基于签名的Web应用程序防火墙(WAF)无关,例如Amazon的AWS WAF,阿里巴巴的Yundun WAF和F5 Networks的Silverline或机器学习模型。换句话说,无监督方法更适合0-day攻击检测。其次,可以通过单个恶意HTTP请求来进行Web攻击。也就是说,那些利用请求之间的上下文信息的方法并没有真正帮助检测此类攻击。因此,应该集中精力利用单个请求中的语法和语义来进行Web请求检测。第三,0-day Web攻击在大量Web请求中非常罕见。因此,那些基于集体和统计信息的无监督方法在检测0-day Web攻击方面无效。
本文提出了一种无监督检测工具ZeroWall,该方法可以与现有WAF一起使用,以有效地检测隐藏在单个Web请求中的0-day Web攻击。 ZeroWall背后的结果是,良性Web请求是遵循HTTP协议的字符串,可以将其视为“HTTP request language”中的一个句子,而恶意Web请求与良性Web请求没有一致的语法和语义模式。该方法的灵感来自于基于编码-解码递归神经网络的无监督自翻译器:当用一种语言A用足够的句子训练后,神经网络就足够“理解”该语言,从而可以翻译输入的句子。这样一个经过训练的网络可以判断A中的新句子s是否属于语言A。因此,如果翻译质量较高,则s属于语言A;否则,s不属于语言A。
通过将0-day Web攻击检测问题映射到机器翻译质量评估问题,ZeroWall可以有效地检测0-day Web攻击。在ZeroWall中,现有WAF允许的历史Web请求(其中绝大多数是良性的)用于训练编码-解码递归神经网络,该网络捕获良性请求的语法和语义模式。网络将良性输入Web请求“转换”为潜在表示(由编码器),然后将表示“转换”为输出Web请求(由解码器),该输出Web请求与原始请求接近。在实时检测中,自动翻译器无法很好地理解0-day攻击请求(WAF无法检测到该请求),无法将其转换回其原始请求,因此被视为攻击。
0x02 Core Idea and System Overview
A.设计目标
如q前所述,鉴于流行的基于签名的WAF部署,最好是0-day Web攻击检测机制可以与现有的WAF协同工作,而不是完全替代WAF。这是首要设计目标。如下图所示,ZeroWall用作WAF之后的旁路系统,这不会给Web服务造成额外的开销。 WAF将丢弃与某些WAFrules匹配的到达请求,从而有效地检测到那些已知的攻击;然后将这些不匹配的规则传递到服务器,并将流量镜像传递到ZeroWall,ZeroWall专注于检测0-day攻击。由于通常见到的恶意样本对无监督算法不友好,因此与WAF一起工作是另一个好处。现有的WAF可以过滤掉已知的攻击,这将提高无监督算法的性能,这也是防御诸如投毒攻击之类的回避行为的良好解决方案,这些攻击会在流量中注入大量攻击。
第二个设计目标是通过分析每个请求来检测HTTP请求中的0-day Web攻击。出于以下两个原因,选择使用无监督方法。首先,无监督方法不必事先知道攻击的确切模式,因此与有监督的方法相比,检测0-day攻击的潜力更大。其次,在到达WAF的HTTP请求中,良性到恶意的比率通常很高,并且在WAF根据规则丢弃已知攻击之后,该比率甚至更高(在数据集中为2811:1〜88863:1) (见下图)。这种极端的不平衡对于有监督的方法非常具有挑战性,但对无监督的方法自然是有利的。
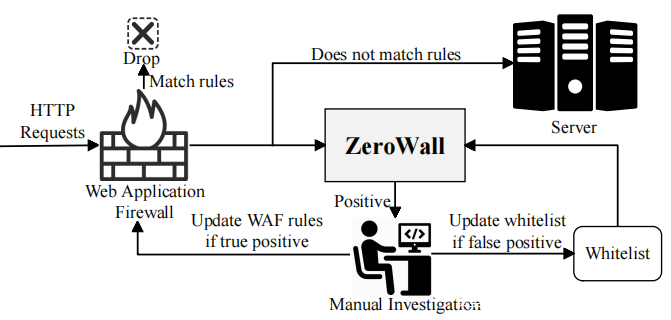
主张采用基于无监督的基于机器学习的0-day Web攻击检测方法来增强现有基于签名的WAF的上述通用框架。这种检测方法可立即部署并在现实世界中广泛应用。
B.无监督检测的核心思想
无监督0-day Web攻击检测方法基于异常检测, ZeroWall的训练数据是那些不符合任何WAF签名规则的历史Web请求(请参见下图的左上方)。使用编解码递归神经网络作为基本训练算法,它被广泛用于对顺序数据进行建模,包括机器翻译,语音识别,问题解答等。ZeroWall背后的主要观察结果是HTTP请求是遵循HTTP协议的字符串,可以将HTTP请求视为“ HTTP请求语言”中的句子。实际解决方案受到基于编码-解码递归神经网络的无监督自动翻译器的启发:当用一种语言A训练足够多的句子时,神经网络就会很好地“理解”该语言,从而可以翻译A语言中的输入句子神经网络训练的目的是使输出句足够接近输入句。可以使用这种训练有素的网络来判断新句子s是否属于语言A。0-day Web攻击(非常罕见)的翻译质量应比良性请求的翻译质量差很多,因此可以使用翻译质量阈值来声明攻击。本文是第一个将0-day Web攻击检测问题表达为神经网络翻译质量评估问题的方法。
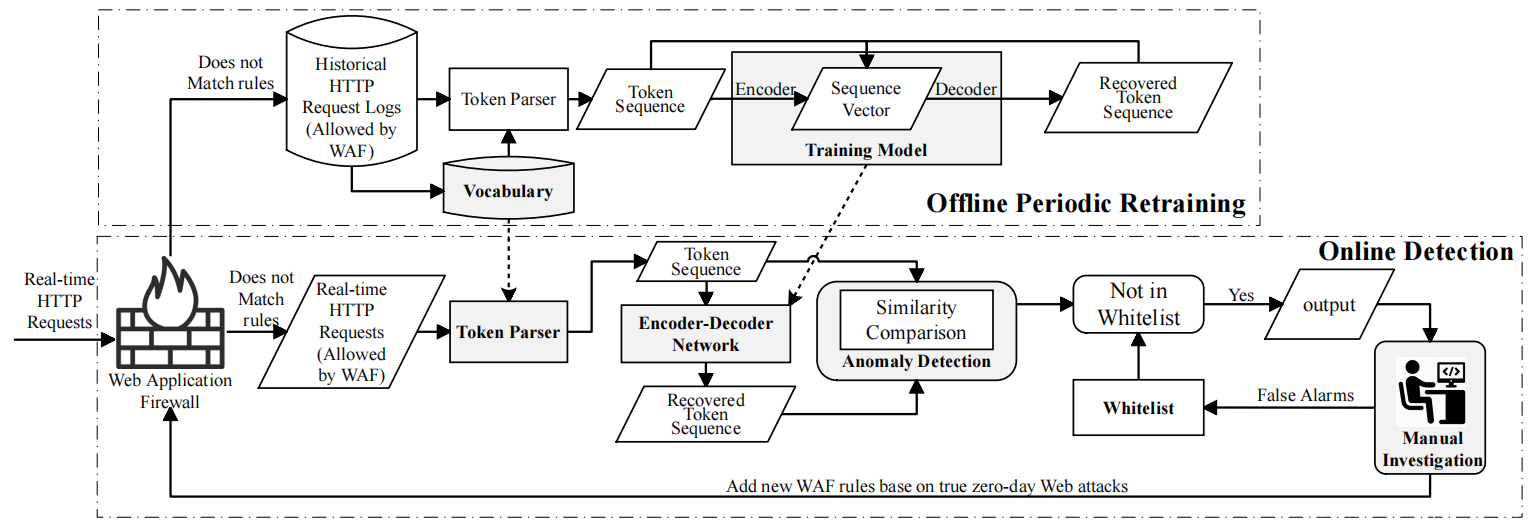
C.系统概述
如上图所示,ZeroWall可以分为两个阶段:离线定期重新训练和在线检测。(一)离线定期重新训练:离线训练是定期(例如每天)进行或手动触发,以利用由最新WAF规则过滤的最新请求数据(例如,新部署的API导致看不见的请求)。每轮离线再培训阶段都利用到目前为止的本次再培训时间(本文下文中称为再培训数据集)收集的HTTP请求日志的历史数据集(最新的WAF规则允许),该过程包括以下三个步骤:
1)建立词汇:ZeroWall使用令牌化技术从再训练数据集中提取单词,过滤不必要的单词(例如停用词),然后应用单词嵌入技术来表示单词。

2)然后ZeroWall的令牌解析器组件使用词汇表将训练数据集中的每个HTTP请求转换为令牌序列(上表和下表显示了两个示例)。

3)训练模型:ZeroWall使用先前生成的序列训练编码器-解码器神经网络。
训练完成后,词汇和模型将用作在线检测阶段的两个组成部分。
(二)在线检测:在线检测期间,ZeroWall将实时检测HTTP请求是否是恶意的(也就是WAF后面的数据集中的0-day攻击)。在此阶段,ZeroWall具有四个主要组件:令牌解析器,编码-解码网络,异常检测和手动调查。前两个组件是离线训练阶段的结果。给定一个HTTP请求作为输入,ZeroWall将首先使用离线构建的词汇表将请求分为一个令牌序列(有关示例,请参见上表)。一个递归神经网络(编码器)用于读取令牌序列并构建相应的序列向量,该序列向量表示令牌序列含义的数字序列。然后,根据序列向量使用另一个递归神经网络(解码器)来重建恢复的令牌序列。这通常被称为编码-解码体系结构。
第三部分是异常检测。异常检测的想法是受机器翻译中质量评估方法的启发。即,如果恢复的令牌序列与原始令牌序列相似,则该请求被认为是良性的。否则,它是恶意的,ZeroWall将对其进行标记并报告给安全工程师。在本文中,选择BLEU度量作为原始令牌序列和恢复令牌序列之间相似性的指标。 BLEU是用于确定句子之间相似性的度量标准,广泛用于机器翻译问题,用于将机器翻译结果与人工翻译的句子进行比较。
第四部分是人工调查。无监督的异常检测无法完全避免误报。例如,某些新请求的某些模式与以前看到的所有模式都非常不同,这可能是完全良性的。因此,安全工程师将手动调查被声明为“恶意”的请求。由安全工程师确认的虚假警报被合并到白名单中,用于避免由相同模式的请求引起的将来的虚假警报。这样的白名单可以提高ZeroWall的性能,由安全工程师确认的真正的0-day攻击被用来构成新的基于签名的规则,这些规则已合并到WAF中。鉴于真正的0-day攻击数量很少(因为在实践中很少见)和误报,因此手动调查的开销是可以接受的。总之,在线检测阶段具有以下步骤来处理一个HTTP请求:
1)令牌解析器:使用离线构建的词汇表将一个原始HTTP请求转换为令牌序列。
2)编码-解码网络:通过离线训练的神经网络重建恢复的令牌序列。
3)异常检测:计算两个序列的BLEU分数,并将其与阈值进行比较,以确定请求是良性还是恶意,然后将输出报告给安全工程师。
4)人工调查:将人工确认的错误警报和真正的0-day攻击分别纳入白名单和WAF。
请注意,由于传入通信量非常大,因此基于机器学习的Web攻击检测方法可能无法处理所有通信量。 为了解决此问题,利用哈希表来加快预解析的过程。 对于每个传入令牌序列,计算其哈希值以有效地验证它是否先前已被处理过。 此外,建立了一个表来存储所有处理过的信息,以避免重复计算。 该方法大大减少了处理开销,因此它可以处理所有流量。 实际上,可以在收集数据的同时使用多个前端服务器同时执行预解析任务。
0x03 Design Details
A.令牌解析器
如前所述,ZeroWall的第一步是将这些字符串转换为令牌序列。在本文中,将一个HTTP请求视为由单词组成的字符串。首先需要从每个给定请求中提取所有有用的单词(也称为令牌)。然后用整个标记集(又称词汇表)将每个字符串解析为标记序列。
1)词汇表:ZeroWall首先用标点符号和空格分割整个请求字符串集。之后,将从字符串中获取多个“words”。但是,并非所有单词都将包含在词汇表中,需要过滤无用和无意义的单词。这些无用的单词中的一种是变量。它们的值在训练中没有多大作用,应替换为占位符(例如_uid_)。这些无用的候选词中的另一种是停用词(例如the, and),尽管它们的频率很高,但它们为请求提供的信息很少。因此,在构建词汇表时,这些单词也会被占位符替换。通常,会根据它们的出现频率对单词进行过滤。频率过低或过高的单词都会被忽略,剩下的单词集称为词汇表。在词汇表中,每个单词都与一个令牌ID相关联。
2)令牌序列:建立词汇表后,可以将请求转换为令牌序列。此步骤由令牌解析器完成。简单地说,它仅保留词汇表中的单词并过滤其他单词。前表可以看到一些变量被占位符代替。
完成上述步骤后,能够将原始HTTP请求字符串转换为令牌序列,在本文中称为TokenSequence或Original Token Sequence。
3)令牌嵌入:请注意,每个令牌都由其词汇表中的ID表示,并且令牌ID忽略了令牌的含义。因此,使用标记之间的向量距离来表示它们的逻辑关系,从而添加一个嵌入层将这些标记ID映射为潜在向量。这也被称为单词嵌入或word2vec。
B.编码器-解码器网络
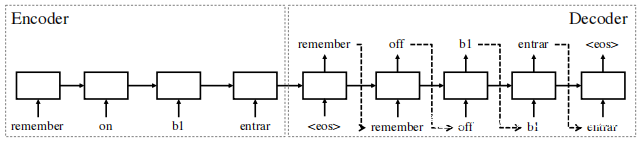
编码器-解码器网络的核心功能是将一个序列映射到另一个序列。在本文中,使用从上述步骤获得的令牌序列(称为原始令牌序列)作为输入。输出(称为恢复令牌序列)是编码器-解码器网络在学习数据后重建的序列。上图示出了一个示例中描述的编码-解码网络的典型结构。给定一个输入序列“ remember on b1 entrar EOF”,网络将输出另一个序列“ remember off b1 entrar EOF”。请注意,这些序列只是示例,结果在野可能有所不同,两个序列的长度可能不同是相同的。
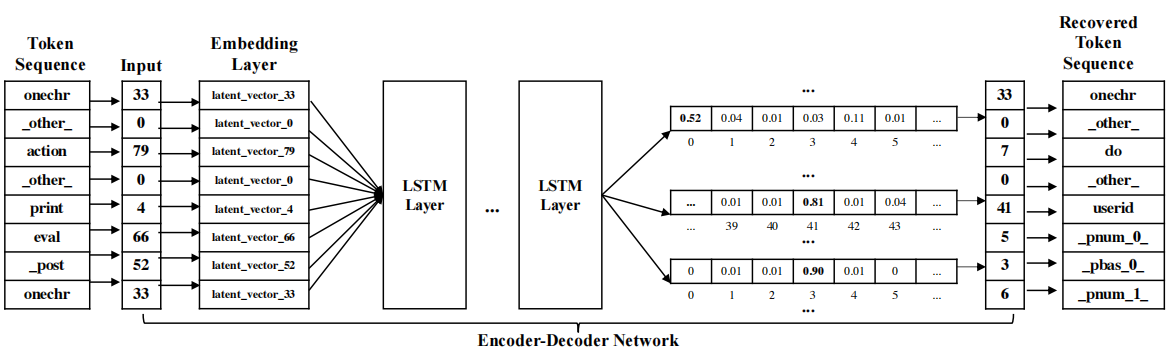
在ZeroWall中,编码器将读取令牌序列作为输入。上图示出了编码器-解码器如何工作。令牌序列(图中的第一列,也表示为[33、0、79、0、4、66、52、33],这些数字是词汇表中的令牌ID)被发送到嵌入层,进一步将令牌转换为潜在向量,将其移动到编码器网络。编码器网络是一个LSTM网络,它计算原始序列的表示形式(固定维向量)。
解码器是另一个使用表示法来计算输出序列概率的LSTM网络。解码器的输出是几个1×N向量(其中N是词汇中的令牌数量)(参见上图的最后第三列)。向量中的元素表示令牌的概率。对于每个输出向量,解码器将以最高概率选择令牌。之后,可以使用相同的词汇表获得被发现的令牌序列(请参见图的最后一列)。可以将整个处理描述为基于网络的学习来重建原始令牌序列。也就是说,神经网络正试图用表示相同信息的同一词汇中的令牌来重建令牌序列。
在上图所示的示例中,可以得到覆盖的序列“onechr _OTHER do _OTHER useridpnum 0__ pbas 0__ pnum 1_”。可以清楚地看到原始令牌序列和恢复的令牌序列是不同的(尤其是后半部分)。此示例是数据集中的一个恶意请求。这是因为编码-解码网络没有珍贵地看到此请求,因此无法很好地重构它。同时,良性请求示例中,恢复的令牌序列(第三行)显然类似于原始令牌序列(第二行)。
实际上,在WAF(训练集)允许的HTTP日志中,良性和恶意请求的比例非常不平衡,即,绝大多数Web日志都是良性请求。结果,恶意请求对系统中的编码-解码网络的学习几乎没有影响,正如稍后评估所证实的那样。
C.异常检测
如前所述,编码-解码网络的核心思想是基于这些序列的“理解”将一个序列映射到另一序列。编码-解码网络能够以较高的精度重建良性令牌序列。另一方面,当网络将0-day Web攻击请求作为输入(在数据集中很少见)时,输出将与输入有很大不同。

进行异常检测,如果在学习数据中普遍看到输入,则结果会很好;如果输入异常,则结果可能不好。为了判断此映射的结果,即HTTP请求的学习情况,可以比较令牌序列和已恢复令牌序列之间的相似性。然后将其用作检测中的异常指标。这些步骤的工作流程如上图所示。在本文中,使用BLEU度量来计算相似度。
前表中给出的示例显示了编码-解码网络的不同输出。在给定一些输入的情况下,恢复令牌序列与输入的令牌序列相似,而有时恢复的序列与原始的令牌序列有很大不同。为了获得序列映射的质量,在这里使用BLEU度量。简单来说,BLEU度量的范围是0到1,值越高表明源序列和目标序列之间的相似度越高。为了检测目的,将恶意得分1-BLEU定义为估计量。较大的恶意分数意味着编码器/解码器网络无法重构给定的序列,表明输入序列可能是恶意的。如上图所示,恶意得分将用于与某个阈值进行比较,以判断请求是否为恶意的或对进一步操作有益。

恢复的令牌序列与原始令牌序列几乎相同。这导致BLEU度量值很高(0.81),恶意分数也很小(0.19)。恶意请求最终在恢复的令牌序列中具有更多差异,从而导致BLEU值为0.15,恶意评分为0.85。上表代表了另一个例子。原始令牌序列的前半部分是正常且无害的,而其余令牌显然是在探索尝试。比较原始令牌序列和恢复的令牌序列,可以发现这两个序列的前半部分仍具有某些相似性。但是,其余部分明显不同。由于训练后的模型无法基于其对良性请求的了解来重建“原始”令牌,因此这会导致相对较小的BLEU值,即较大的恶意分数。结果将被输入到“手动调查”组件中进行验证,并分别用于更新白名单和WAF。
0x04 Evalution Using Real-World Traces
在本节中使用8条包含大量HTTP请求的真实记录来评估ZeroWall的0-day Web攻击检测性能,并将其性能与基准方法进行比较。
A.基准方法
在场景中,针对上下文和集体异常检测的方法是不合适的,因此未进行比较。从点攻击检测类别(ZeroWall也属于)中选择了以下代表性方法。这些方法可以进一步分为两种类型。堆叠式自动编码器方法(称为SAE),基于HMM的方法(称为Hmm-payl)和基于DFA的方法(称为DFA)是无监督方法。基于CNN的CNN-Token方法和基于RNN的RNN-Token方法是监督方法。还基于简单但流行的监督分类器决策树,实现了另一种监督方法DT-Token。 DT-Token将Web请求特征中的所有令牌作为特征并输出预测结果。
B.真实记录
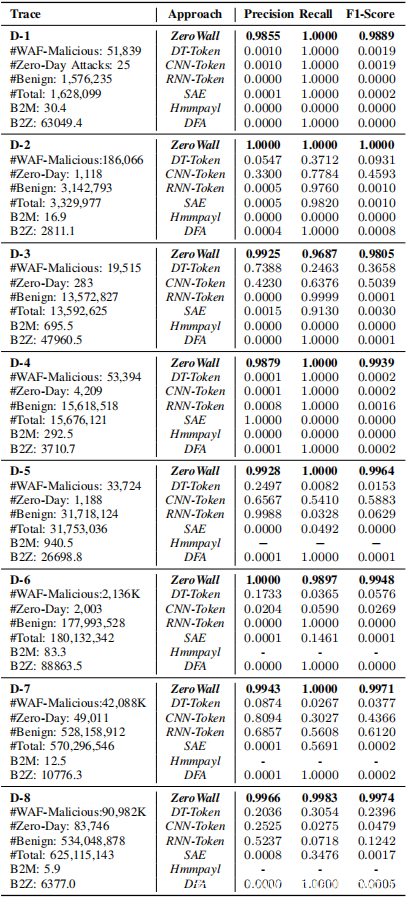
从一家顶级全球互联网公司I运营的WAF W获得了真实记录,该公司为数百家企业客户提供基于签名的WAF服务.2019年6月的第一周,收集了8个7天的记录。每个跟踪(用D-n表示)收集了特定企业客户的全部请求集,其不同的统计信息显示在上表的第一列中。此外,跟踪中的请求类型(不同服务的API)超过8、000,并且参数的数量和类型有所不同。因此,总体而言,这些记录提供了很好的多样性,可以评估ZeroWall在不同客户之间的稳健性。
C.标签,训练和测试
1)获取标签:使用的记录在WAF后面收集。符合WAF规则的请求将被WAF丢弃(在本节中称为WAF恶意请求),其他则被WAF允许。请注意,实践中不完善的WAF不能保证丢弃所有已知的Web攻击。对于允许WAF的请求,如果被ZeroWall或基准方法中的至少一种检测为0-day攻击并被安全工程师确认,则称为“0-day Web攻击”;上表的第一列显示了这些请求的计数,而B2M和B2Z分别表示良性与WAF恶意比率和良性与0-day比率。
2)训练和测试:将每个7天的跟踪记录按照时间分为两部分:第一天用于训练(训练集),其余时间用作在线检测(测试集)中的实时流量。这些数据集的体积和比率各不相同。基于这些,可以确定ZeroWall在不同现实情况下的性能。
在训练期间,无监督方法(包括ZeroWall)使用WAF允许的所有请求,而不使用任何标签;而有监督的方法则使用所有请求(允许和删除),并使用WAF的检测结果(允许/删除)作为标签。所有方法的输入都是ZeroWall的令牌解析器组件生成的令牌序列,而不是原始的HTTP请求。
在测试过程中,仅关注0-day Web攻击,而不考虑已知的攻击(WAF已将其丢弃)。因此,在测试中,正样本是指定义的跟踪中的0-day攻击请求,而负样本是良性请求。
D.评估指标
使用三种指标评估不同方法的效果:精度,召回率和F1-score。 对于每种方法,首先计算真阳性(TP),真阴性(TN),假阳性(FP)和假阴性(FN)。 真阳性是数据集中被正确检测为0-day攻击的0-day攻击请求,而真阴性是正确检测为良性的那些良性请求。 误报是那些被检测为0-day攻击的良性请求,而误报是那些被检测为良性的0-day攻击请求。 然后,按以下方式计算指标:准确率= T P/(T P + F P),召回率= T P/(T P + F N),F1-score = 2×准确率×召回率/(准确率+召回率)。
使用真实记录进行评估的主要挑战是,安全工程师需要手动标记(至少部分标记)大量请求,以获取实际情况。因此,只能大致获得基本事实:ZeroWalland检测为0-day攻击的请求以及所有基准方法都由安全工程师手动检查和纠正(如有必要)。请注意,上述方法可能仍会遗漏一些0-day攻击,但是工程师手动检查所有请求是不可行的。因此,在评估中以上述近似事实为基础,并理解所产生的召回率可能人为地高于基准(所有方法都会遗漏任何0-day攻击,然后才是FN)。但是结果的精度不会改变,因为所有的TP和FP都是手动检查的。请注意,这些0-day攻击基准标签仅用于评估目的。无监督方法不使用标签进行训练,监督方法直接使用WAF输出作为标签(与使用基准标签相反)进行训练。超参数(例如ZeroWall中的异常检测阈值)影响系统性能,因此获得并给出了最佳F1-score(在超参数空间中)及其相应的精度和召回率。
E.实验结果
最佳的F1-score及其相应的精度和召回率如前表所示。所有这些结果仅适用于0-day攻击。观察到,ZeroWall明显优于所有现有方法,在所有8条记录上均达到0.98以上的最佳F1-score。精度和查全率值也很高(接近0.99和1)。
这8条记录的数量,请求类型的数量和数据分布都不同。在所有方法中,ZeroWall在不同记录上的方差最稳定(即,最大和最小之间的差距最小)。受监督的方法DT-Token,CNN-Token和RNN-Token可以检测到一些0-day攻击(例如D- 3和D- 7),但性能非常不稳定。这些监督方法的不良检测性能主要是由于训练集。由于这些方法使用WAF标签进行训练,因此训练集中的阳性样本是WAF丢弃的那些WAF恶意请求,这可能与实际的0-day攻击有很大不同。
无人监督的基准方法SAE,Hmmpayl和DFA的效果也很差。它们的精度,召回率和F1-score均较低。在SAE中,编码器的降维会遗漏令牌序列中的重要特征,从而使其不适合处理具有复杂模式的长请求。 Hmmpayl的性能很差,因为它只能在状态数等于序列长度时才能很好地工作。但是,如果状态数很多,它就不能很好地处理请求。请注意,由于某些记录中的Hmmpayl结果用尽了其他记录,因此仅在某些记录中具有Hmmpayl的结果。 Hmmpayl从序列中提取滑动窗口。对于长度为1的序列(n表示窗口大小),它使用(ln + 1)×n,所消耗的内存几乎是原始序列的n倍。 DFA的效果也很差。各种类型的HTTP请求使自动机的构建变得过于复杂,并且建模的普遍化降低了其检测精度,因为数据量远远超出了其原始设计中的场景。

上面的观察结果可以用上表中的0-day攻击示例来最好地解释,该示例被ZeroWall,CNN-Token和RNN-Token检测到,但没有其他方法被发现。攻击隐藏在消息正文中(以粗体显示)是针对PHP服务器的注入攻击。该攻击旨在通过迫使服务器端程序执行来自攻击者的恶意代码来从服务器收集更多信息。 WAF中使用的注入检测规则通常基于关键字和正则表达式,例如eval,request,select和execute。但是,下表中的攻击不包含这些关键字,因此成功欺骗了WAF。另一方面,ZeroWall基于对良性请求的“理解”,而不必担心攻击会如何偏离良性模式。0-day攻击请求以上的结构更像是一种编程语言,它与通常传输数据的普通请求明显不同,因此ZeroWall能够成功检测到此攻击。 CNN-Token和RNN-Token能够检测到这种特定的0-day攻击,因为这种攻击的令牌恰巧与训练集中的某些令牌重叠。但是,并非所有0-day攻击都具有与已知攻击重叠的令牌,这说明CNN-Token和RNN-Token的性能比ZeroWall差。

F.WAF规则
除上表中的示例外,ZeroWall还检测其他许多0-day Web攻击。公司的安全工程师手动检查了ZeroWall的结果,发现141583个真正的0-day攻击。这些0-day攻击可以分为28类,包括Webshell,SQL注入,探测,特洛伊木马和针对特定应用程序的其他利用。对于每种类别,安全工程师已经制定了新的WAF规则,以在将来检测到这些攻击。
G.误报和白名单
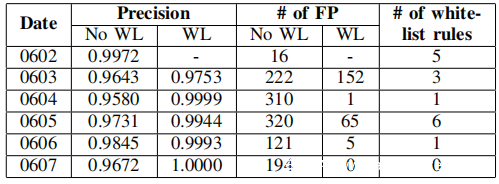
上表使用跟踪D-7的统计数据来显示ZeroWall的白名单机制的效果。在此实验中,白名单每天更新一次。白名单规则的数量指的是每天添加多少白名单规则,具体取决于当天标记的FP。例如,在手动调查0602的结果时发现了16个FP。基于这些FP,安全工程师组成了5个白名单规则并将其添加。将这5条规则应用于0603的数据,并将0603的FP减少70(222-152)。结果表明,白名单以较低的开销减少了FP的数量(规则数量非常少)。基于这些结果,认为ZeroWall在实际部署中是可行的。
H. ZeroWall的训练和测试开销
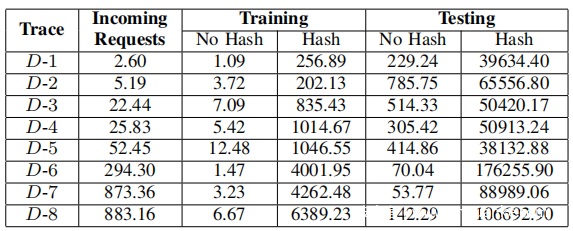
在具有以下配置的一台服务器上使用每秒处理的请求数来评估训练和检测速度:Intel(R) Xeon(R) Gold 6148 CPU 2.40GHz ∗ 2, 512GB RAM。请注意,实际上可以使用更多服务器。下表的结果表明,ZeroWall的开销很低,本文提出的哈希表机制可以将开销减少2-3个数量级。
0x05 Discussion
相似性度量:使用BLEU作为相似性度量,并演示了如何凭经验确定异常检测阈值。下图绘制了CDF,用于分配良性请求和0-day攻击的恶意分数,其中X轴表示恶意分数的值,Y轴表示累积分布。在BLEU BENIGN和BLEU ZERODAY曲线之间可以发现明显的差异:超过90%的良性请求的恶意分数小于0.3,而BLEU ZERODAY的恶意分数大多分布在0.95以上,这可以通过BLEU ZERODAY的CDF急剧增加0.95来证明。设置阈值的一种经验方法是自动扫描阈值并找到具有最大除法能力的阈值(例如,下图中的红色垂直线)。
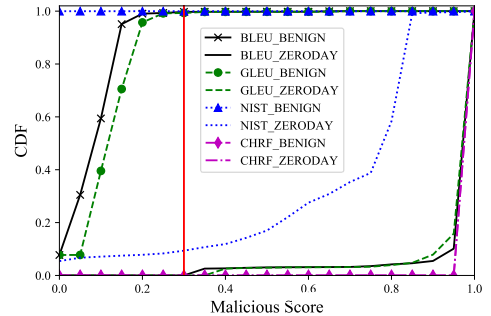
上图还证明了在神经机器翻译领域中从几种流行的指标(BLEU,GLEU,NIST ,CHRF)中选择BLEU作为相似性指标的合理性,因为良性和0-day BLEU曲线(在不同的D-n上)稳定地大于这些替代指标。 GLEU的性能稍差,其次是NIST,而CHRF的性能最差。
局限性:无监督方法的局限性之一是数据量太小会降低性能。作为基于神经网络的方法,训练数据的数量非常重要。而且一个小的数据集可能包含非常罕见(或没有)的0-day攻击,这使得评估本文方法变得困难。幸运的是,已经证明D-1每周跟踪请求量为160万个请求,已经相当不错。
防御:这种方法的基本假设是,大多数历史记录都是良性的。直观地讲,这种方法看起来像是投毒攻击的良好目标。在投毒攻击期间,攻击者会在正常流量中注入大量恶意样本,希望系统将从错误的数据集中学习。但是,投毒攻击对ZeroWall几乎没有影响,因为:ZeroWall被部署在WAF之后,这意味着中毒样本首先由WAF过滤,然后由ZeroWall读取。攻击者注入足够多的恶意样本是不现实的。
0x06 Conculsion
本文采用基于无监督机器学习的0-day Web检测工具来增强现有基于签名的WAF的通用框架。这种方法可以立即在现实世界中部署并广泛应用。本文是第一个将0-day Web攻击检测问题表达为神经机器翻译质量评估问题的方法,通过采用最新的算法(即编码-解码递归神经网络)来实现上述想法。在使用大规模真实世界记录进行的评估中,ZeroWall的F1得分达到0.98以上,大大优于现有方法。
88加成券.jpg