
0x00 前言
eBPF是Linux内核中的一个模块,主要作用是实现包过滤功能。由于eBPF提供了一种从用户面到Linux内核的接口,用户编写的eBPF程序可以在内核提供的虚拟机中执行,因此eBPF也是一个重要的内核提权的攻击面。本文将详细叙述eBPF的基本原理和实现方法,对eBPF内核提权漏洞CVE-2020-8835的Root Cause进行详细的分析。通过本文,期望即使对eBPF模块不熟悉的同学也能够理解该漏洞的原理。本文会对必要的eBPF原理进行介绍但是不会沉溺eBPF细节,更主要的是想向大家介绍eBPF是一个理想的内核提权攻击面。
0x01 eBPF背景知识
为了能够对eBPF安全有个总体的了解,我们既需要对eBPF本身的设计以及实现有所了解,同时最好佐以漏洞实例进行分析,从而对eBPF这个内核攻击面建立更加具象的理解。
eBPF程序的基本功能
linux 官方文档对eBPF模块有个详细的介绍,可以配合本文进行理解。
eBPF是对BPF的扩展,BPF即为 Berkeley Packet Filter,顾名思义这个东西主要是用来对网卡进入的数据包进行过滤和拷贝到用户层的。eBPF对BPF很多功能进行了扩展,可以对更多的数据进行过滤,二者的编码方式有所不同,但是基本原理都一样。
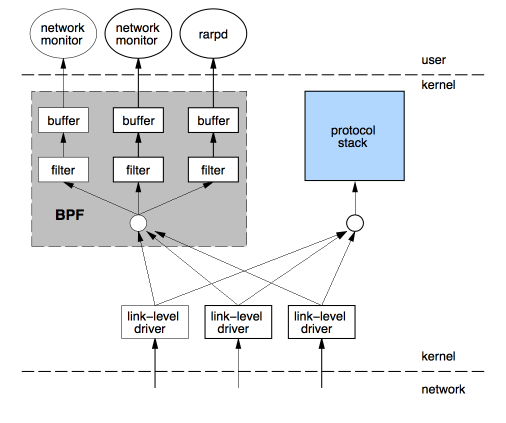
eBPF程序本身包含了一些过滤规则,例如验证包是IP包还是ARP包。 tcpDump这个程序底层就是通过BPF实现的包 过滤功能的。
eBPF是如何在内核中运行的
eBPF程序是使用一种低级的机器语言编写的,类似于汇编指令,例如下面这样
BPF_MOV64_REG(BPF_REG_2, BPF_REG_10),
BPF_ALU64_IMM(BPF_ADD, BPF_REG_2, -8),
BPF_LD_MAP_FD(BPF_REG_1, 0),
BPF_RAW_INSN(BPF_JMP | BPF_CALL, 0, 0, 0, BPF_FUNC_map_lookup_elem),
BPF_EXIT_INSN(),
但是他并不会被编译器提前编译为可执行文件然后交给内核执行,而是直接以这种类似汇编形式的语言经过一些编码(非编译)交给内核中的虚拟机执行。
内核中是实现了一个小型的虚拟机负责动态的解析这些eBPF程序。也许有同学会思考为什么要用一个虚拟机去动态执行解析这些eBPF程序,而不是提前编译,直接执行编译好的过滤程序。
对于这个问题我也搜了很多资料,但是并没有直接解答这个疑问的,在这里我提出自己的理解,不能保证正确,欢迎大家批评指正:
BPF这种通过内核虚拟机执行包过滤规则的设计架构也是参考了别的包过滤器的。动态执行这种设计更加适合包过滤这种业务场景,由于包过滤的规则变化很快,而且可以很复杂,而且逻辑执行深度和数据包本身的字段内容强相关的,如果提前编译,可能有很大一块逻辑都不会执行,那么编译是完全浪费时间的,如果能够根据包本身的信息,对过滤代码动态编译就会节省很多时间,也更加灵活,所以最终采用了内核虚拟机动态解析过滤规则的方式实现BPF。
一个具体的BPF程序对数据包类别判断的例子
例如下面这段代码
ldh [12]
jne #0x800, drop
ret #-1
drop: ret #0
这段代码的意思是从数据包的偏移12个字节的地方开始读取一个half word就是16个字节,然后判断这个值是否是0x806,如果不是,就执行drop,否则执行返回-1。
这个代码就是实现了判断包是否是IPv4包的功能,我们通过wireshark抓包可以发现
在数据包偏移12字节的地方就是以太网头中Type字段。通过这个例子我们可以更加具体的了解BPF程序的工作原理。
eBPF程序是如何交给内核执行的
eBPF程序虽然是有内核的虚拟机负责执行的,但是eBPF程序的编写确实完全由用户定义的,因此这也是eBPF模块是一个理想的内核提权攻击面的根本原因。
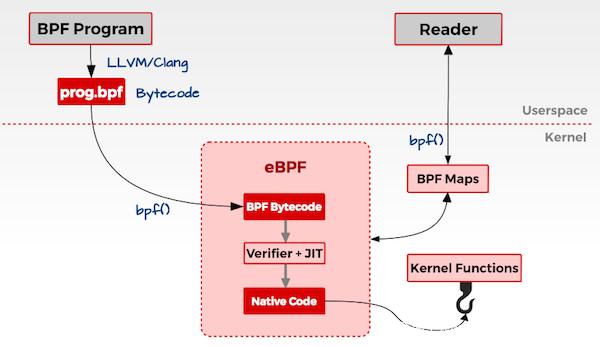
eBPF程序通过BPF系统调用,cmd为BPF_PROG_LOAD就可以将eBPF程序发送给内核,还可以通过cmd为BPF_MAP_CREATE系统调用创建一个map数据结构,这个map数据结构就是用户侧运行的程序与内核中运行的eBPF程序进行数据交互的地方。其简要原理图为
0x02 漏洞分析
通过上面对eBPF程序的设计架构和运行原理介绍之后,我们就可以对一个具体的eBPF提权漏洞CVE-2020-8835进行分析,披露这个漏洞的文章也出现了很多,本文更加侧重对漏洞原理的解释,希望读者能够掌握漏洞原理,能够对eBPF这个攻击面的安全性有更深入的思考,最好是也能挖到类似的漏洞。
漏洞位置
CVE-2020-8835漏洞所涉及的函数为
static void __reg_bound_offset32(struct bpf_reg_state *reg)
{
u64 mask = 0xffffFFFF;
struct tnum range = tnum_range(reg->umin_value & mask,
reg->umax_value & mask); // ----->1
struct tnum lo32 = tnum_cast(reg->var_off, 4);
struct tnum hi32 = tnum_lshift(tnum_rshift(reg->var_off, 32), 32);
reg->var_off = tnum_or(hi32, tnum_intersect(lo32, range));
}
初看这个函数,很难理解tnum,mask,tnum_range,tnum_cast这些函数的作用,尽管ZDI博文中给了相关的解释,但我觉着还是对不了解eBPF模块的人不够友好,读完还是让人无法理解。由于这个漏洞和业务逻辑强相关,因此要想掌握漏洞原理,就必须能够理解代码的逻辑功能是什么,而代码中的tnum结构的数据类型是阻碍理解逻辑功能的关键。下面,本文将围绕tnum这个数据结构对此漏洞的根因进行分析。
Verifier
漏洞函数__reg_bound_offset32所在文件为verifier.c,verifier.c文件实现了上图中Verifier的功能。eBPF是用户侧编写的程序,但是却在内核虚拟机中执行,这显然是非常危险的,为了能够保障内核数据不被篡改和泄露,eBPF在真正被虚拟机执行之前都会被Verifier检查,Verifier会对eBPF指令的类型,跳转,是否有循环,以及操作数的取值范围进行检查,只有通过检查的eBPF的指令才可以被执行。
那么Verifier到底是如何保证不会有OOB这种情况发生的呢?
eBPF程序的每个操作数的属性都会被bpf_reg_state 数据结构进行追踪bpf_reg_state 的结构如下
enum bpf_reg_type type;
union {
u16 range;
struct bpf_map *map_ptr;
u32 btf_id;
unsigned long raw;
};
s32 off;
u32 id;
u32 ref_obj_id;
struct tnum var_off;
s64 smin_value;
s64 smax_value;
u64 umin_value;
u64 umax_value;
struct bpf_reg_state *parent;
u32 frameno;
s32 subreg_def;
enum bpf_reg_liveness live;
bool precise;
可以看到对于每一个操作数,它的类型,值,取值范围都有详细的变量在追踪。常见的操作类型有PTR指针类型,或者Scalar这种常量类型的数据,为了防止越界,Verifier禁止了很多类型的操作,比如禁止两个PTR类型的操作数运算,但是允许PTR类型与Scalar类型的操作数运算。即使允许PTR类型与Scalar类型操作,也不能保证安全性,因为如果Scalar比较大的话,还是可以导致OOB,所以Verifier通过设置取值范围的方式来进行校验,如果操作数在运算后超过了被设定的最大最小值范围,也会被禁止。
我们可以看到bpf_reg_state还定义了一个tnum变量,这个变量注释说是获得操作数各个位的信息的情况的,value,mask两个字段一起表达操作数各个位的0,1,或者未知的三种状态的。
tnum数据结构的逻辑意义
tnum是为了描述那些不能有明确值的操作数,那么什么情况下操作数的值是不能确定的呢,例如从一个packet中读取一个half word,这个值就是不能确定。而如果直接读取一个立即数,这种值就是确定的。对于这种不能确定的操作数,就可以用umax,umin,smax,smin这几种变量表示有符号和无符号的最大最小值,tnum描述他们的每个位的信息。总之配合最大最小值,tnum可以尽可能的对一个未知的变量进行预测。并且伴随着eBPF指令的执行,还会对tnum,最大最小值进行更新,举个例子
if reg_0 < 7 // 有符号比较
reg_1 = reg_0
else
reg_1 = 1
在这个例子中,reg_0这个操作数会被跟踪,如果它小于7,则可以对reg_0的最大值进行设置,最大值为7-1=6, 同时也得出高位都是0,所以也可以对tnum进行设置。本文的__reg_bound_offset32函数就是负责处理tnum与最大最小值同步更新的工作的。
tnum到底是如何描述未知值的?
假设拿到一个寄存器,这个寄存器就是不是一个确定值,用tnum表示他的位的状态,比如64位的一个数,那么某一位只可能三种状态,确定的0,确定的1,或者不知道是啥,就是这种数据结构是某个位有三种状态,而不是2种状态。
单纯的用一个64位的数据是不可能表达这种数据结构的,这种数据结构有3的64次方,而64位的二进制只有2的64方,但是如果有两个64位的数据就可以表达这个64位的三进制数据,2的128次方。
所以就需要一种编码方式,用2个64位数编码这个三进制的数。
而eBPF的tnum的编码方式就是能确定是1的位,就value标识为确定1,而能确定是0的位需要,value位0,并且mask对应位也为0,相当于用2位去表达这个状态,,所以本质是用2位去表达三种状态,就是x1,标识1,01标识0,00标识未知这种本质。
为了精确,模拟了一个mask和value的东西,就是value位能够决定某个位是1,对应mask位的值必须为0(有一个规定就是不能同时为1),而对于确定是0的位,则必须value位为0,mask也要为0,对于unknown的状态,需要value为0,而mask为1
所以最终的表达为
value mask 预测值
0 0 0
1 0 1
0 1 unknown
1 1 禁止出现
__reg_bound_offset32漏洞函数解析
除了__reg_bound_offset32还有一个__reg_bound_offset函数,这个函数功能更加简洁
static void __reg_bound_offset(struct bpf_reg_state *reg)
{
reg->var_off = tnum_intersect(reg->var_off,
tnum_range(reg->umin_value,
reg->umax_value));
}
__reg_bound_offset32是一种特殊情况,只有当操作数已经明知是32位的才会执行,而对于一般的是默认执行__reg_bound_offset操作,我们可以先从__reg_bound_offset去推测 __reg_bound_offset32的大概意义。tnum_intersect函数的输入是两个tnum的变量,根据名字和源码我们可以简要总结:当有两个tnum对同一个操作数进行描述的时候,可以结合两个tnum的信息,这样可以对这个操作数的描述更加精确,结合的规则就是,如果一个tnum的某个位已知,另外一个tnum的对应位为未知,那么结合后新tnum对应位则是已知的。
tnum_range 函数作用是,根据一个更新后的最大最小值得到一个tnum。这个tnum可以与目标操作数的tnum进行tnum_intersect,相当于融合了最大最小值的信息,这样可以实现对原来的操作数进行更准确的预测更新。
所以根据__reg_bound_offset的作用,我们知道了主要目的就是根据最大最小值对原来操作数的tnum进行更加准确的预测。那么__reg_bound_offset32又有什么不同呢?
__reg_bound_offset32 源码如下:
static void __reg_bound_offset32(struct bpf_reg_state *reg)
{
u64 mask = 0xffffFFFF;
struct tnum range = tnum_range(reg->umin_value & mask,
reg->umax_value & mask); // ----->1
struct tnum lo32 = tnum_cast(reg->var_off, 4);
struct tnum hi32 = tnum_lshift(tnum_rshift(reg->var_off, 32), 32);
reg->var_off = tnum_or(hi32, tnum_intersect(lo32, range));
}
我们利用理解tnum_range函数的方法,可以推得tnum_cast,tnum_lshift,tnum_or的作用,可以感觉出整个函数的目的是同样根据最大最小值对已有的tnum值进行更新。而且,相比于__reg_bound_offset函数,__reg_bound_offset32还有一个隐藏的信息可以对操作数进行更加准确的预测:
32位数的最大最小值不会超过0xFFFFFFFF
这个隐藏条件的表达就是 标注1所做的工作,漏洞代码尝试用截断低32位的方式来表达32位数的最大最小值不会超过0xFFFFFFFF,但是实际上这个语句并不能表达这个功能。准确的表达是
new_umin_value = min(0xffffffff,umin_value)
new_umax_value = min(0xffffffff,umax_value)
range = tnum_range(new_umin_value, new_umax_value)
上面两句话是笔者自己理解的实现32位隐藏条件的代码。
漏洞根因
正是struct tnum range = tnum_range(reg->umin_value & mask, 这一条语句导致的漏洞,这句话实现的是截断功能,而不是对于超出32位的数直接取值为0xffff ffff的功能。
reg->umax_value & mask);
由于这个错误的实现导致Veifier并不能正确的验证eBPF指令的执行情况,所以对一些本应该禁止的OOB操作,Verifier还是通过了检查,最终可以实现对内核数据的越界读写。
0x03 小结
这个漏洞的Root Cause是和漏洞函数的业务功能逻辑强相关的,如果不理解代码的目的,很难对这个漏洞的根本原因理解,而由于eBPF的执行流程又比较特别,需要对背景知识,设计架构,运行机理有一定的了解才能够推理出漏洞函数的功能。为了能够让不熟悉eBPF的同学能够更加快速的了解eBPF,接触eBPF这一个理想的内核攻击面。eBPF程序由用户定义,但是在内核中执行,这是eBPF模块是一个值得重视的内核攻击面的根本原因。希望本文提供的思维路线,能够帮助到大家。
0x04 参考
1 https://www.kernel.org/doc/html/latest/networking/filter.html#networking-filter
2 https://www.thezdi.com/blog/2020/4/8/cve-2020-8835-linux-kernel-privilege-escalation-via-improper-ebpf-program-verification
3 https://www.anquanke.com/post/id/203416
4 https://colorlight.github.io/2020/10/10/捉虫日记漏洞总结/