
最近又在读有关Fuzz研究的论文,读到了一篇标题为《NEUZZ: Efficient Fuzzing with Neural Program Smoothing》的论文,是基于机器学习的梯度引导的Fuzz,看了看原理虽然有点难懂,但是工程实践上还是比较简单的,遂撰写了这篇笔记,以供交流心得
结构图感谢B站的小姐姐UP主:爱吃红豆沙の诸葛晴画,她的NEUZZ论文解读视频也很好
https://b23.tv/FsXwhr
一、简介
NEUZZ就是采用了一种程序平滑技术,这种技术使用前向反馈神经网络,能够逐步学习去平滑地模拟复杂实际应用的分支行为,然后提出了一种gradient-guided搜索策略,这种策略能利用平滑模拟函数去找到那些能使发现漏洞数最大化的突变位置
其核心思想就是:
- 从本质上讲模糊测试本身就是一个优化问题,目标就是在给定时间的测试中对于给定数量的输入能够最大化在程序中找到的漏洞数量,基本上是没有任何约束函数的无约束优化问题
- AFL为代表的进化遗传变异算法也就是针对这个底层问题的一种优化,由于安全漏洞往往是稀疏且不稳定地分布在整个程序中,大多数模糊者的目标是通过最大化某种形式的代码覆盖(例如边缘覆盖)来尽可能多地测试程序代码。然而,随着输入语料库的增大,进化过程在到达新的代码位置方面的效率越来越低
- 进化优化算法的一个主要限制是它们不能利用潜在优化问题的结构(即梯度或其他高阶导数)。梯度引导优化(例如梯度下降)是一种很有前途的替代方法,它在解决不同领域的高维结构优化问题(包括气动计算和机器学习)方面明显优于进化算法
- 然而,梯度引导优化算法不能直接应用于模糊化现实世界的程序,因为它们通常包含大量的不连续行为(梯度无法精确计算的情况),因为不同程序分支的行为差异很大。这个问题可以通过创建一个光滑(即,可微)的代理函数来解决,该代理函数逼近目标程序相对于程序输入的分支行为
- 而神经网络理论上带有一个非线性函数的网络能够拟合任意函数
- 基于前馈神经网络(NNs)的程序平滑技术,它可以逐步学习复杂的、真实的程序分支行为的光滑逼近,即预测由特定输入执行的目标程序的控制流边缘。我们进一步提出了一种梯度引导搜索策略,该策略计算并利用平滑近似(即神经网络模型)的梯度来识别目标突变位置,从而最大限度地增加目标程序中检测到的错误数量
简而言之就是,NEUZZ就是通过一组神经网络利用梯度信息评价变异哪些位置对提升覆盖率有帮助
二、安装与使用
NEUZZ的安装与使用还是比较简单的
2.1 初始准备
首先需要安装一些必备的包,根据官网readme所介绍的,他们的测试环境是:
- Python 2.7
- Tensorflow 1.8.0
- Keras 2.2.3
我决定采用的是Aconda来建立一个虚拟环境来运行
2.1.1 安装Aconda
先安装一些必备的库
$ sudo apt-get install python3 python3-pip python3-dev git libssl-dev libffi-dev build-essential
然后从官网里面下载Anaconda的安装脚本
$ wget https://repo.anaconda.com/archive/Anaconda3-2020.11-Linux-x86_64.sh
然后给脚本赋予执行权限
$ chmod +x Anaconda3-2020.11-Linux-x86_64.sh
然后运行安装脚本即可
$ ./Anaconda3-2020.11-Linux-x86_64.sh
这里不建议使用root权限安装,如果你自己使用的用户就不是root账户的话
这里如果出现找不到conda命令的情况可能需要手动修改shell的环境配置
$ sudo vim ~/.bashrc
然后就修改为类似这样的实际安装路径
export PATH="/home/ubuntu/anaconda3/bin:$PATH"
然后刷新重新运行
$ source ~/.bashrc
2.1.2 安装环境包
首先建立虚拟环境
$ conda create -n neuzz python=2.7
激活虚拟环境
$ conda activate neuzz
安装Tensorflow
$ pip install --upgrade tensorflow==1.8.0
安装Keras
$ pip install --upgrade keras==2.2.3
2.2 安装编译NEUZZ
下载NEUZZ源码:
$ git clone https://github.com/Dongdongshe/neuzz.git && cd neuzz
编译neuzz
$ gcc -O3 -funroll-loops ./neuzz.c -o neuzz
2.3 使用
这里我们以测试readelf为例子,首先还是安装一些必备包
$ sudo dpkg --add-architecture i386
$ sudo apt-get update
$ sudo apt-get install libc6:i386 libncurses5:i386 libstdc++6:i386 lib32z1
然后拷贝nn.py和neuzz到工作目录
$ cp neuzz ./programs/readelf/
$ cp nn.py ./programs/readelf/
然后设置一些内核参数
cd /sys/devices/system/cpu
echo performance | tee cpu*/cpufreq/scaling_governor
echo core >/proc/sys/kernel/core_pattern
然后建立种子文件夹
$ mkdir seeds
然后运行nn.py作为服务器端
$ python nn.py ./readelf -a
然后在另外一个终端里面运行neuzz
# -l, file len is obtained by maximum file lens in the neuzz_in ( ls -lS neuzz_in|head )
$ ./neuzz -i neuzz_in -o seeds -l 7507 ./readelf -a @@
三、NN.py
整个NEUZZ的结构图如下,高清图片地址:
https://gitee.com/zeroaone/viking-fuzz/raw/master/%E7%BB%93%E6%9E%84%E5%9B%BE.png
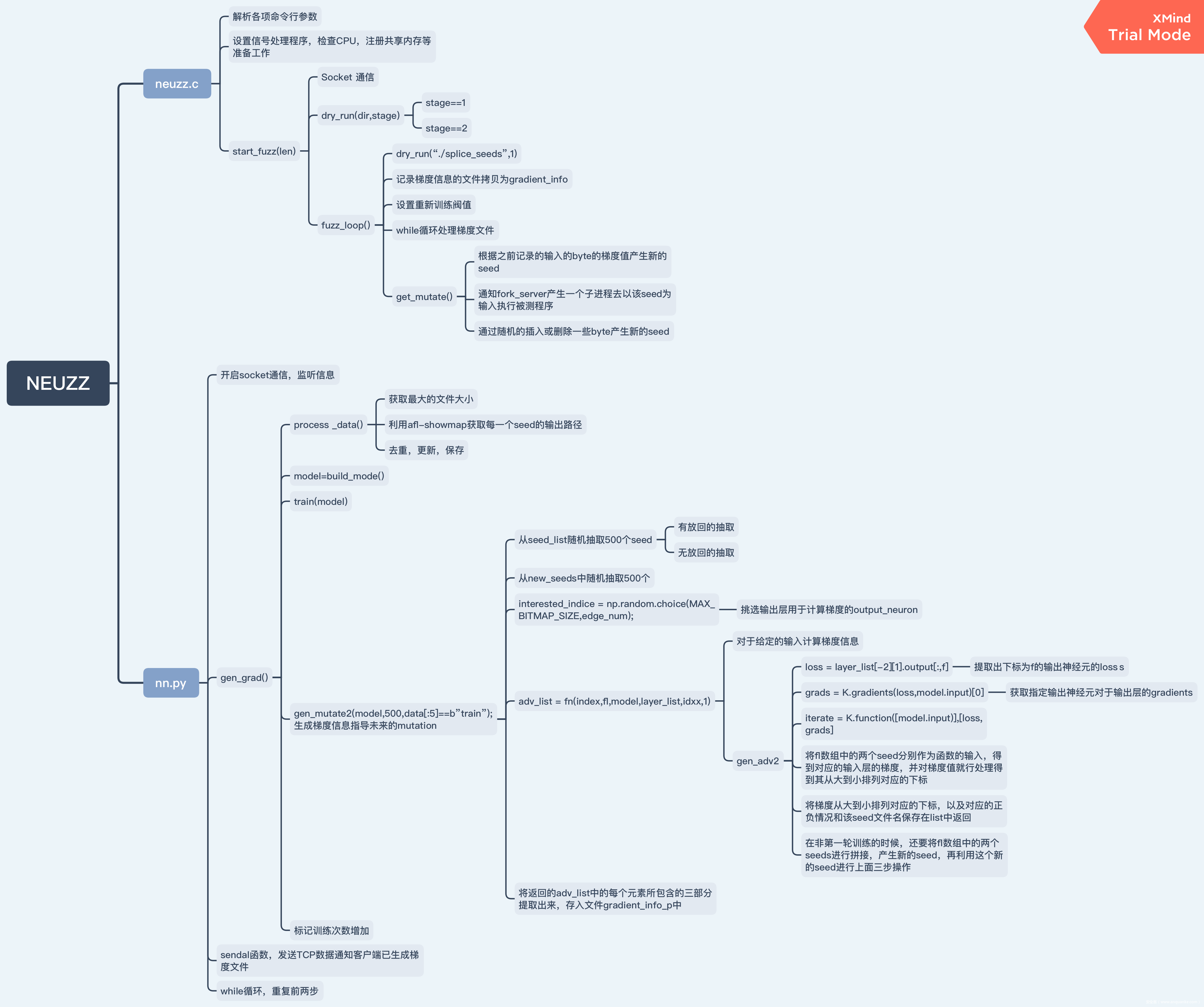
3.1 setup_server
我们首先来看看nn.py的源码结构
我们先从main函数看起
if __name__ == '__main__':
setup_server()
可以看到调用了setup_server()函数:
def setup_server():
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind((HOST, PORT))
sock.listen(1)
conn, addr = sock.accept()
print('connected by neuzz execution moduel ' + str(addr))
gen_grad(b"train")
conn.sendall(b"start")
while True:
data = conn.recv(1024)
if not data:
break
else:
gen_grad(data)
conn.sendall(b"start")
conn.close()
这段代码不难看懂,就是开启一个socket通信,开始监听信息,然后就开始一个循环,不断训练数据,发送客户端梯度信息已经生成,直到没接收到客户端的信号
3.2 gen_grad
现在的关键是我们看到gen_grad()函数
def gen_grad(data):
global round_cnt
t0 = time.time()
process_data()
model = build_model()
train(model)
# model.load_weights('hard_label.h5')
gen_mutate2(model, 500, data[:5] == b"train")
round_cnt = round_cnt + 1
print(time.time() - t0)
这里round_cnt是记录了一共训练了几次梯度信息
然后process_data主要目的是利用afl-showmap获取每一个seed的输出路径,然后对其进行去重、更新保存
然后model = build_model()就是建立神经网络模型,train(model)顾名思义就是训练模型,然后gen_mutate2就是生成梯度信息指导未来的变异
3.3 process_data
这是整个源码里面比较大的模块了,
# process training data from afl raw data
def process_data():
global MAX_BITMAP_SIZE
global MAX_FILE_SIZE
global SPLIT_RATIO
global seed_list
global new_seeds
# shuffle training samples
seed_list = glob.glob('./seeds/*')
seed_list.sort()
SPLIT_RATIO = len(seed_list)
rand_index = np.arange(SPLIT_RATIO)
np.random.shuffle(seed_list)
new_seeds = glob.glob('./seeds/id_*')
call = subprocess.check_output
# get MAX_FILE_SIZE
cwd = os.getcwd()
max_file_name = call(['ls', '-S', cwd + '/seeds/']).decode('utf8').split('\n')[0].rstrip('\n')
MAX_FILE_SIZE = os.path.getsize(cwd + '/seeds/' + max_file_name)
# create directories to save label, spliced seeds, variant length seeds, crashes and mutated seeds.
os.path.isdir("./bitmaps/") or os.makedirs("./bitmaps")
os.path.isdir("./splice_seeds/") or os.makedirs("./splice_seeds")
os.path.isdir("./vari_seeds/") or os.makedirs("./vari_seeds")
os.path.isdir("./crashes/") or os.makedirs("./crashes")
# obtain raw bitmaps
raw_bitmap = {}
tmp_cnt = []
out = ''
for f in seed_list:
tmp_list = []
try:
# append "-o tmp_file" to strip's arguments to avoid tampering tested binary.
if argvv[0] == './strip':
out = call(['./afl-showmap', '-q', '-e', '-o', '/dev/stdout', '-m', '512', '-t', '500'] + argvv + [f] + ['-o', 'tmp_file'])
else:
out = call(['./afl-showmap', '-q', '-e', '-o', '/dev/stdout', '-m', '512', '-t', '500'] + argvv + [f])
except subprocess.CalledProcessError:
print("find a crash")
for line in out.splitlines():
edge = line.split(b':')[0]
tmp_cnt.append(edge)
tmp_list.append(edge)
raw_bitmap[f] = tmp_list
counter = Counter(tmp_cnt).most_common()
# save bitmaps to individual numpy label
label = [int(f[0]) for f in counter]
bitmap = np.zeros((len(seed_list), len(label)))
for idx, i in enumerate(seed_list):
tmp = raw_bitmap[i]
for j in tmp:
if int(j) in label:
bitmap[idx][label.index((int(j)))] = 1
# label dimension reduction
fit_bitmap = np.unique(bitmap, axis=1)
print("data dimension" + str(fit_bitmap.shape))
# save training data
MAX_BITMAP_SIZE = fit_bitmap.shape[1]
for idx, i in enumerate(seed_list):
file_name = "./bitmaps/" + i.split('/')[-1]
np.save(file_name, fit_bitmap[idx])
我们这里先来看几个常量
MAX_FILE_SIZE = 10000
MAX_BITMAP_SIZE = 2000
SPLIT_RATIO = len(seed_list)
seed_list = glob.glob('./seeds/*')
new_seeds = glob.glob('./seeds/id_*')
大概就是分别记录了最大的文件大小,最大的BITMAP大小,切割率,已经存在的种子列表,新生成的种子列表
程序一开始首先就是对这些值进行了初始化操作,切割率直接取的就是已有种子文件的个数
# shuffle training samples
seed_list = glob.glob('./seeds/*')
seed_list.sort()
SPLIT_RATIO = len(seed_list)
rand_index = np.arange(SPLIT_RATIO)
np.random.shuffle(seed_list)
new_seeds = glob.glob('./seeds/id_*')
call = subprocess.check_output
然后程序开始获取最大的种子文件的大小,大致就是调用了ls指令的方法
# get MAX_FILE_SIZE
cwd = os.getcwd()
max_file_name = call(['ls', '-S', cwd + '/seeds/']).decode('utf8').split('\n')[0].rstrip('\n')
MAX_FILE_SIZE = os.path.getsize(cwd + '/seeds/' + max_file_name)
然后就是建立四个文件夹
# create directories to save label, spliced seeds, variant length seeds, crashes and mutated seeds.
os.path.isdir("./bitmaps/") or os.makedirs("./bitmaps")
os.path.isdir("./splice_seeds/") or os.makedirs("./splice_seeds")
os.path.isdir("./vari_seeds/") or os.makedirs("./vari_seeds")
os.path.isdir("./crashes/") or os.makedirs("./crashes")
- bitmaps:用来存放每个种子文件的路径覆盖率信息
- splice_seeds:用来存放被切割的种子
- vari_seeds:用来存放变长的种子
- crashes:用来存放产生crashes的种子
然后就是利用afl-showmap获取每一个seed的原始输出路径覆盖率信息
# obtain raw bitmaps
raw_bitmap = {}
tmp_cnt = []
out = ''
for f in seed_list:
tmp_list = []
try:
# append "-o tmp_file" to strip's arguments to avoid tampering tested binary.
if argvv[0] == './strip':
out = call(['./afl-showmap', '-q', '-e', '-o', '/dev/stdout', '-m', '512', '-t', '500'] + argvv + [f] + ['-o', 'tmp_file'])
else:
out = call(['./afl-showmap', '-q', '-e', '-o', '/dev/stdout', '-m', '512', '-t', '500'] + argvv + [f])
except subprocess.CalledProcessError:
print("find a crash")
for line in out.splitlines():
edge = line.split(b':')[0]
tmp_cnt.append(edge)
tmp_list.append(edge)
raw_bitmap[f] = tmp_list
counter = Counter(tmp_cnt).most_common()
我们先来回顾一下afl-showmap的用法
afl-showmap [ options ] -- /path/to/target_app [ ... ]
Required parameters:
-o file - file to write the trace data to
Execution control settings:
-t msec - timeout for each run (none)
-m megs - memory limit for child process (0 MB)
-Q - use binary-only instrumentation (QEMU mode)
-U - use Unicorn-based instrumentation (Unicorn mode)
-W - use qemu-based instrumentation with Wine (Wine mode)
(Not necessary, here for consistency with other afl-* tools)
Other settings:
-i dir - process all files in this directory, must be combined with -o.
With -C, -o is a file, without -C it must be a directory
and each bitmap will be written there individually.
-C - collect coverage, writes all edges to -o and gives a summary
Must be combined with -i.
-q - sink program's output and don't show messages
-e - show edge coverage only, ignore hit counts
-r - show real tuple values instead of AFL filter values
-s - do not classify the map
-c - allow core dumps
This tool displays raw tuple data captured by AFL instrumentation.
For additional help, consult /usr/local/share/doc/afl/README.md.
Environment variables used:
LD_BIND_LAZY: do not set LD_BIND_NOW env var for target
AFL_CMIN_CRASHES_ONLY: (cmin_mode) only write tuples for crashing inputs
AFL_CMIN_ALLOW_ANY: (cmin_mode) write tuples for crashing inputs also
AFL_CRASH_EXITCODE: optional child exit code to be interpreted as crash
AFL_DEBUG: enable extra developer output
AFL_FORKSRV_INIT_TMOUT: time spent waiting for forkserver during startup (in milliseconds)
AFL_KILL_SIGNAL: Signal ID delivered to child processes on timeout, etc. (default: SIGKILL)
AFL_MAP_SIZE: the shared memory size for that target. must be >= the size the target was compiled for
AFL_PRELOAD: LD_PRELOAD / DYLD_INSERT_LIBRARIES settings for target
AFL_QUIET: do not print extra informational output
可以看到NEUZZ使用的afl-showmap的开启选项主要是:
- -q:关闭沉程序的输出,不显示消息
- -e:仅显示边缘覆盖率,忽略命中率
- -o:写入覆盖率的文件路径
- -m:对于子进程的内存限制
- -t:超时时间
如果afl-showmap错误退出,就会说明找到了一个可以触发Crash的种子文件,然后借用splitlines方法,tmp_cnt可以得到边缘覆盖个数。raw_bitmap[f] = tmp_list可以得到原始的bitmap
起始阶段 fuzzer 会进行一系列的准备工作,为记录插桩得到的目标程序执行路径,即 tuple 信息
-
trace_bits记录当前的tuple信息 -
virgin_bits用来记录总的tuple信息 -
virgin_tmout记录fuzz过程中出现的所有目标程序的timeout时的tuple信息 -
virgin_crash记录fuzz过程中出现的crash时的tuple信息
AFL为每个代码块生成一个随机数,作为其“位置”的记录;随后,对分支处的”源位置“和”目标位置“进行异或,并将异或的结果作为该分支的key,保存每个分支的执行次数。用于保存执行次数的实际上是一个哈希表,大小为MAP_SIZE=64K
# save bitmaps to individual numpy label
label = [int(f[0]) for f in counter]
bitmap = np.zeros((len(seed_list), len(label)))
for idx, i in enumerate(seed_list):
tmp = raw_bitmap[i]
for j in tmp:
if int(j) in label:
bitmap[idx][label.index((int(j)))] = 1
之后就是本轮训练出来的每个bitmap保存到对应的numpy标签矩阵里面,方便以后训训练
# label dimension reduction
fit_bitmap = np.unique(bitmap, axis=1)
print("data dimension" + str(fit_bitmap.shape))
之后就是unique函数去除其中重复的元素,也就是去除会产生相同路径信息的种子,并按元素由大到小返回一个新的无元素重复的所有的bitmap
# save training data
MAX_BITMAP_SIZE = fit_bitmap.shape[1]
for idx, i in enumerate(seed_list):
file_name = "./bitmaps/" + i.split('/')[-1]
np.save(file_name, fit_bitmap[idx])
之后就是保存对应的bitmaps
3.4 build_model
def build_model():
batch_size = 32
num_classes = MAX_BITMAP_SIZE
epochs = 50
model = Sequential()
model.add(Dense(4096, input_dim=MAX_FILE_SIZE))
model.add(Activation('relu'))
model.add(Dense(num_classes))
model.add(Activation('sigmoid'))
opt = keras.optimizers.adam(lr=0.0001)
model.compile(loss='binary_crossentropy', optimizer=opt, metrics=[accur_1])
model.summary()
return model
这里就是很简单的利用Tensorflow和Keras构建的一个网络模型,其基本结构是Sequential序贯模型,序贯模型是函数式模型的简略版,为最简单的线性、从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠。我们可以通过将层的列表传递给Sequential的构造函数,来创建一个Sequential模型, 也可以使用.add()方法将各层添加到模型中,这里采用的就是.add()方法
模型需要知道它所期待的输入的尺寸(shape)。出于这个原因,序贯模型中的第一层(只有第一层,因为下面的层可以自动的推断尺寸)需要接收关于其输入尺寸的信息,后面的各个层则可以自动的推导出中间数据的shape,因此不需要为每个层都指定这个参数。有以下几种方法来做到这一点
这里我们使用一个2D 层 Dense,通过参数 input_dim 指定输入尺寸,Dense层就是所谓的全连接神经网络层
之后跟的是以relu函数的一个激活函数层。之后又跟了一个大小为MAX_BITMAP_SIZE的全连接层。最后又跟了一个以sigmoid为函数的一个激活函数层
神经网络模型由三个完全连接的层组成。隐藏层使用ReLU作为其激活函数。我们使用sigmoid作为输出层的激活函数来预测控制流边缘是否被覆盖。神经网络模型训练了50个阶段(即整个数据集的50次完整通过),以达到较高的测试精度(平均约95%)。由于我们使用一个简单的前馈网络,因此所有10个程序的训练时间都不到2分钟
在训练模型之前,我们需要配置学习过程,这是通过compile方法完成的,他接收三个参数:
-
优化器 optimizer:它可以是现有优化器的字符串标识符,如
rmsprop或adagrad,也可以是 Optimizer 类的实例 -
损失函数 loss:模型试图最小化的目标函数。它可以是现有损失函数的字符串标识符,如
categorical_crossentropy或mse,也可以是一个目标函数 -
评估标准 metrics:对于任何分类问题,你都希望将其设置为
metrics = ['accuracy']。评估标准可以是现有的标准的字符串标识符,也可以是自定义的评估标准函数
这里我们使用了优化器keras.optimizers.Adam(),在监督学习中我们使用梯度下降法时,学习率是一个很重要的指标,因为学习率决定了学习进程的快慢(也可以看作步幅的大小)。如果学习率过大,很可能会越过最优值,反而如果学习率过小,优化的效率可能很低,导致过长的运算时间,所以学习率对于算法性能的表现十分重要。而优化器keras.optimizers.Adam()是解决这个问题的一个方案。其大概的思想是开始的学习率设置为一个较大的值,然后根据次数的增多,动态的减小学习率,以实现效率和效果的兼得
我们这里使用了一个参数lr=0.0001表示学习率
看参数我们使用了binary_crossentropy函数作为损失函数,也就是二进制交叉熵
使用keras构建深度学习模型,我们会通过model.summary()输出模型各层的参数状况
至此我们的网络模型构建完毕
3.5 train
在构建完模型后,我们就开始了训练的过程
def train(model):
loss_history = LossHistory()
lrate = keras.callbacks.LearningRateScheduler(step_decay)
callbacks_list = [loss_history, lrate]
model.fit_generator(train_generate(16),
steps_per_epoch=(SPLIT_RATIO / 16 + 1),
epochs=100,
verbose=1, callbacks=callbacks_list)
# Save model and weights
model.save_weights("hard_label.h5")
都是常规的训练设置,最后将获得的模型保存到一个叫hard_label.h5的文件中,save_weights()保存的模型结果,它只保存了模型的参数,但并没有保存模型的图结构,可以节省空间与提高效率
3.6 gen_mutate2
这又是整个程序中一个巨大且重要的模块,主要用途是利用生成的梯度信息指导未来的种子变异
# grenerate gradient information to guide furture muatation
def gen_mutate2(model, edge_num, sign):
tmp_list = []
# select seeds
print("#######debug" + str(round_cnt))
if round_cnt == 0:
new_seed_list = seed_list
else:
new_seed_list = new_seeds
if len(new_seed_list) < edge_num:
rand_seed1 = [new_seed_list[i] for i in np.random.choice(len(new_seed_list), edge_num, replace=True)]
else:
rand_seed1 = [new_seed_list[i] for i in np.random.choice(len(new_seed_list), edge_num, replace=False)]
if len(new_seed_list) < edge_num:
rand_seed2 = [seed_list[i] for i in np.random.choice(len(seed_list), edge_num, replace=True)]
else:
rand_seed2 = [seed_list[i] for i in np.random.choice(len(seed_list), edge_num, replace=False)]
# function pointer for gradient computation
fn = gen_adv2 if sign else gen_adv3
# select output neurons to compute gradient
interested_indice = np.random.choice(MAX_BITMAP_SIZE, edge_num)
layer_list = [(layer.name, layer) for layer in model.layers]
with open('gradient_info_p', 'w') as f:
for idxx in range(len(interested_indice[:])):
# kears's would stall after multiple gradient compuation. Release memory and reload model to fix it.
if idxx % 100 == 0:
del model
K.clear_session()
model = build_model()
model.load_weights('hard_label.h5')
layer_list = [(layer.name, layer) for layer in model.layers]
print("number of feature " + str(idxx))
index = int(interested_indice[idxx])
fl = [rand_seed1[idxx], rand_seed2[idxx]]
adv_list = fn(index, fl, model, layer_list, idxx, 1)
tmp_list.append(adv_list)
for ele in adv_list:
ele0 = [str(el) for el in ele[0]]
ele1 = [str(int(el)) for el in ele[1]]
ele2 = ele[2]
f.write(",".join(ele0) + '|' + ",".join(ele1) + '|' + ele2 + "\n")
这里我们输入了三个参数:
- model:训练好的网络模型
- edge_num:边的数量
- sign:信号
# select seeds
print("#######debug" + str(round_cnt))
if round_cnt == 0:
new_seed_list = seed_list
else:
new_seed_list = new_seeds
if len(new_seed_list) < edge_num:
rand_seed1 = [new_seed_list[i] for i in np.random.choice(len(new_seed_list), edge_num, replace=True)]
else:
rand_seed1 = [new_seed_list[i] for i in np.random.choice(len(new_seed_list), edge_num, replace=False)]
if len(new_seed_list) < edge_num:
rand_seed2 = [seed_list[i] for i in np.random.choice(len(seed_list), edge_num, replace=True)]
else:
rand_seed2 = [seed_list[i] for i in np.random.choice(len(seed_list), edge_num, replace=False)]
这里就是从seed_list中随机抽取500个seed
if len(new_seed_list) < edge_num:
rand_seed1 = [new_seed_list[i] for i in np.random.choice(len(new_seed_list), edge_num, replace=True)]
else:
rand_seed1 = [new_seed_list[i] for i in np.random.choice(len(new_seed_list), edge_num, replace=False)]
如果len(new_seed_list) < edge_num,则为又放回的抽取,体现为replace=True,可以抽取同样的内容,反正则为不放回的抽取replace=False
从seed_list中随机抽取500个seed作为rand_seed1,从new_seed1中随机抽取500个作为rang_seed2,
# function pointer for gradient computation
fn = gen_adv2 if sign else gen_adv3
根据信号不同选择不同的梯度计算的函数
# select output neurons to compute gradient
interested_indice = np.random.choice(MAX_BITMAP_SIZE, edge_num)
layer_list = [(layer.name, layer) for layer in model.layers]
这里就是挑选输出层用于计算梯度的output_neuron
with open('gradient_info_p', 'w') as f:
for idxx in range(len(interested_indice[:])):
# kears's would stall after multiple gradient compuation. Release memory and reload model to fix it.
if idxx % 100 == 0:
del model
K.clear_session()
model = build_model()
model.load_weights('hard_label.h5')
layer_list = [(layer.name, layer) for layer in model.layers]
print("number of feature " + str(idxx))
index = int(interested_indice[idxx])
fl = [rand_seed1[idxx], rand_seed2[idxx]]
adv_list = fn(index, fl, model, layer_list, idxx, 1)
tmp_list.append(adv_list)
for ele in adv_list:
ele0 = [str(el) for el in ele[0]]
ele1 = [str(int(el)) for el in ele[1]]
ele2 = ele[2]
f.write(",".join(ele0) + '|' + ",".join(ele1) + '|' + ele2 + "\n")
这一大段代码的主要功能就是将返回的adv_list中的每个元素所包含的三部分提取出来,存入文件gradient_info_p中。接下来我们将深入这个函数内部探究其功能
if idxx % 100 == 0:
del model
K.clear_session()
model = build_model()
model.load_weights('hard_label.h5')
layer_list = [(layer.name, layer) for layer in model.layers]
这里主要是多次梯度计算后,kears会失速。需要我们手动释放内存并重新加载模型以对其进行修复
adv_list = fn(index, fl, model, layer_list, idxx, 1)
这个是关键的函数,这里输入了我们挑选的输出层,和对应的随机种子,模型网络层列表,idxx。这里就是对于给定的输入计算梯度信息
3.7 gen_adv2
计算给定输入的梯度
# compute gradient for given input
def gen_adv2(f, fl, model, layer_list, idxx, splice):
adv_list = []
loss = layer_list[-2][1].output[:, f]
grads = K.gradients(loss, model.input)[0]
iterate = K.function([model.input], [loss, grads])
ll = 2
while fl[0] == fl[1]:
fl[1] = random.choice(seed_list)
for index in range(ll):
x = vectorize_file(fl[index])
loss_value, grads_value = iterate([x])
idx = np.flip(np.argsort(np.absolute(grads_value), axis=1)[:, -MAX_FILE_SIZE:].reshape((MAX_FILE_SIZE,)), 0)
val = np.sign(grads_value[0][idx])
adv_list.append((idx, val, fl[index]))
# do not generate spliced seed for the first round
if splice == 1 and round_cnt != 0:
if round_cnt % 2 == 0:
splice_seed(fl[0], fl[1], idxx)
x = vectorize_file('./splice_seeds/tmp_' + str(idxx))
loss_value, grads_value = iterate([x])
idx = np.flip(np.argsort(np.absolute(grads_value), axis=1)[:, -MAX_FILE_SIZE:].reshape((MAX_FILE_SIZE,)), 0)
val = np.sign(grads_value[0][idx])
adv_list.append((idx, val, './splice_seeds/tmp_' + str(idxx)))
else:
splice_seed(fl[0], fl[1], idxx + 500)
x = vectorize_file('./splice_seeds/tmp_' + str(idxx + 500))
loss_value, grads_value = iterate([x])
idx = np.flip(np.argsort(np.absolute(grads_value), axis=1)[:, -MAX_FILE_SIZE:].reshape((MAX_FILE_SIZE,)), 0)
val = np.sign(grads_value[0][idx])
adv_list.append((idx, val, './splice_seeds/tmp_' + str(idxx + 500)))
return adv_list
loss = layer_list[-2][1].output[:, f]
这里就是提取出下标为f的输出神经元的loss信息
grads = K.gradients(loss, model.input)[0]
获取指定的输出神经元对于输出层的gradients,也就是梯度信息
iterate = K.function([model.input], [loss, grads])
这里我们利用Keras的backend根据给定的信息创造一个迭代器,这里我们使用Tensorflow作为张量计算的后端
for index in range(ll):
x = vectorize_file(fl[index])
loss_value, grads_value = iterate([x])
idx = np.flip(np.argsort(np.absolute(grads_value), axis=1)[:, -MAX_FILE_SIZE:].reshape((MAX_FILE_SIZE,)), 0)
val = np.sign(grads_value[0][idx])
adv_list.append((idx, val, fl[index]))
这里将fl数组中的两个seed分别作为函数的输入,得到对应的输入层的梯度,并对梯度值就行处理得到将其从大到小排列对应的下标
将梯度从大到小排列对应的下标,以及对应的正负情况和该seed文件名保存在list中返回
# do not generate spliced seed for the first round
if splice == 1 and round_cnt != 0:
if round_cnt % 2 == 0:
splice_seed(fl[0], fl[1], idxx)
x = vectorize_file('./splice_seeds/tmp_' + str(idxx))
loss_value, grads_value = iterate([x])
idx = np.flip(np.argsort(np.absolute(grads_value), axis=1)[:, -MAX_FILE_SIZE:].reshape((MAX_FILE_SIZE,)), 0)
val = np.sign(grads_value[0][idx])
adv_list.append((idx, val, './splice_seeds/tmp_' + str(idxx)))
else:
splice_seed(fl[0], fl[1], idxx + 500)
x = vectorize_file('./splice_seeds/tmp_' + str(idxx + 500))
loss_value, grads_value = iterate([x])
idx = np.flip(np.argsort(np.absolute(grads_value), axis=1)[:, -MAX_FILE_SIZE:].reshape((MAX_FILE_SIZE,)), 0)
val = np.sign(grads_value[0][idx])
adv_list.append((idx, val, './splice_seeds/tmp_' + str(idxx + 500)))
在非第一轮训练的时候,还要将fl数组中的两个seeds进行拼接,产生新的seed,再利用这个新的seed进行上面三步操作
gen_adv3和gen_adv2的情况差不多
3.8 splice_seed
这里就是提供了一个利用两个旧的种子产生一个新种子的方法
def splice_seed(fl1, fl2, idxx):
tmp1 = open(fl1, 'rb').read()
ret = 1
randd = fl2
while ret == 1:
tmp2 = open(randd, 'rb').read()
if len(tmp1) >= len(tmp2):
lenn = len(tmp2)
head = tmp2
tail = tmp1
else:
lenn = len(tmp1)
head = tmp1
tail = tmp2
f_diff = 0
l_diff = 0
for i in range(lenn):
if tmp1[i] != tmp2[i]:
f_diff = i
break
for i in reversed(range(lenn)):
if tmp1[i] != tmp2[i]:
l_diff = i
break
if f_diff >= 0 and l_diff > 0 and (l_diff - f_diff) >= 2:
splice_at = f_diff + random.randint(1, l_diff - f_diff - 1)
head = list(head)
tail = list(tail)
tail[:splice_at] = head[:splice_at]
with open('./splice_seeds/tmp_' + str(idxx), 'wb') as f:
f.write(bytearray(tail))
ret = 0
print(f_diff, l_diff)
randd = random.choice(seed_list)
3.9 vectorize_file
获取输入的矢量表示
# get vector representation of input
def vectorize_file(fl):
seed = np.zeros((1, MAX_FILE_SIZE))
tmp = open(fl, 'rb').read()
ln = len(tmp)
if ln < MAX_FILE_SIZE:
tmp = tmp + (MAX_FILE_SIZE - ln) * b'\x00'
seed[0] = [j for j in bytearray(tmp)]
seed = seed.astype('float32') / 255
return seed