
当前智能手机上的运动传感器由于对振动的敏感性已被用于监听音频。但由于两个公认的限制,此威胁被认为是低风险的:首先,与麦克风不同,运动传感器只能捕获通过固体介质传播的语音信号,因此先前唯一可行的设置是使用智能手机陀螺仪窃听放置在同一桌子上的扬声器;第二个限制来自常识,即由于200Hz的采样上限,这些传感器只能捕获语音信号的窄带(85-100Hz)。在本文中将重新探讨运动传感器对语音隐私的威胁,并提出了一种新型侧信道攻击AccelEve,它利用智能手机的加速度计来窃听同一智能手机中的扬声器。
具体来说,它利用加速度计的测量值来识别扬声器发出的语音并重构相应的音频信号。本研究的设置允许语音信号通过共享母板在加速度计测量中始终产生强大的响应,从而成功解决了第一个局限,并使这种攻击渗透到现实生活中。关于采样率的限制,与普遍认知的相反,在最近的智能手机中观察到高达500Hz的采样率,几乎覆盖了成人语音的整个基本频带(85-255Hz)。
在这些关键性观察的基础上,本文提出了一种新颖的基于深度学习的系统,该系统学会了从加速度信号的频谱图表示中识别和重构语音信息。该系统在具有跳跃和连接的深度神经网络上采用自适应优化,使用健壮且可泛化的损失函数来实现稳健的识别和重构性能。评估表明,在各种情况下AccelEve攻击都具有有效性和高精度。
0x01 Introduction
智能手机已作为与世界其他地区必不可少的通信接口渗透到日常生活中。在所有不同的通信方式中,语音通信始终被视为首选。由于其重要性,默认情况下,在大多数操作系统中,麦克风使用的系统许可级别是最高的。以往的大量研究集中在如何通过利用通信协议的漏洞或通过植入后门以访问使用麦克风的权限来窃听用户的电话。
本文考虑了在不要求敏感系统权限的情况下,通过侧信道攻击在智能手机中的扬声器上进行监听的问题。通过分析同一智能手机上运动传感器的测量结果,可以识别并重构智能手机扬声器发出的语音信号,而无需侵入操作系统并获得广告管理者权限。此攻击可能是由于以下原因引起的。首先,由于加速度计和陀螺仪被认为是低风险的,因此通常将它们设置为零许可传感器,并且可以在不警告智能手机用户的情况下对其进行访问。其次,运动传感器可以响应外部振动,从而使它们能够捕获某些音频信号。此外,人类语音的基本频率与智能手机传感器的采样频率之间存在重叠。因此,理论上可以通过零许可运动传感器捕获语音信号。
在本文中,通过提出一种新颖而实用的设置以及基于深度学习的语音识别和重构系统,克服了以前工作的局限性,其性能优于所有类似的研究。在设置中,攻击者是一个间谍App,其目的是窃听同一部智能手机中的扬声器。当扬声器发出语音信号时(例如在通话期间),间谍App会在后台收集加速度计测量值,并利用收集到的信号来识别和重构播放的语音信号。值得注意的是,间谍App可以伪装成任何类型的移动应用程序,因为访问加速计不需要任何许可。
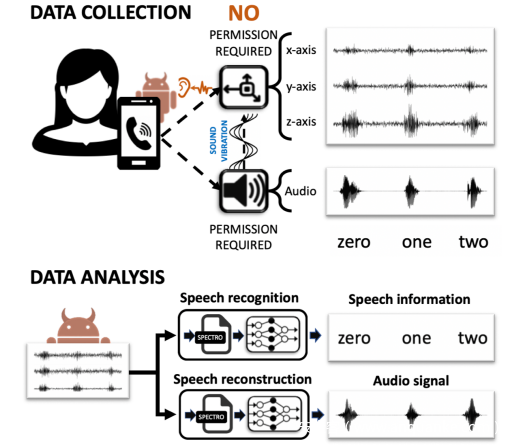
所提出的系统的主要目的是从加速度计的测量结果中识别并重构语音信号。由于原始加速度信号通常会捕获多个“单词”,并且可能因人的动作而严重失真,因此系统首先实现了预处理模块,以自动消除加速度信号中的明显失真,并将长信号切成单个单词段。然后将每个单词加速信号转换为其频谱图表示形式,并将其传递给识别模块和重构模块,以进行进一步分析。
识别模块采用DenseNet作为基础网络,以识别由加速度信号的频谱图携带的语音信息(文本)。广泛的评估表明,识别模块可以在不同的设置下获得最新的最新结果。特别是,当将智能手机放在桌子上时,识别模块在识别10位数字时具有78%的精度,在识别20位讲话者时具有70%的精度,而先前的SOTA结果在数字任务中的准确度为26%,在识别时为50%只有10位讲话者。此外,在不同嘈杂环境条件下的评估也证明了识别模型的健壮性。
除了数字和字母,识别和重构模型可用于识别电话中的热门(敏感)单词。借助讲话者识别模型,广告客户可以通过将在多个电话中识别出的热词链接到特定的呼叫者,来获取呼叫者联系人的多条敏感信息。此外还基于现实世界会话中的识别模型实现了端到端攻击。
在重构模块中,实现了一个重构网络,该网络可学习加速器测量值与智能手机扬声器播放的音频信号之间的映射。由于高频段中的大多数语音信息都是基频的谐波,因此重构模块可以将加速度信号转换为具有增强采样率(1500Hz)的音频(语音)信号。根据实验结果,重构模块能够恢复几乎所有的元音信息,包括低频段的基频分量和高频段的谐波。清音辅音无法恢复,因为这些分量在2000Hz以下的频带中没有分布的信息。
0x02 Background
A. MEMS运动传感器
现代智能手机通常配备三轴加速度计和三轴陀螺仪。这些传感器对设备的运动高度敏感,并已广泛应用于感测方向,振动,冲击等。
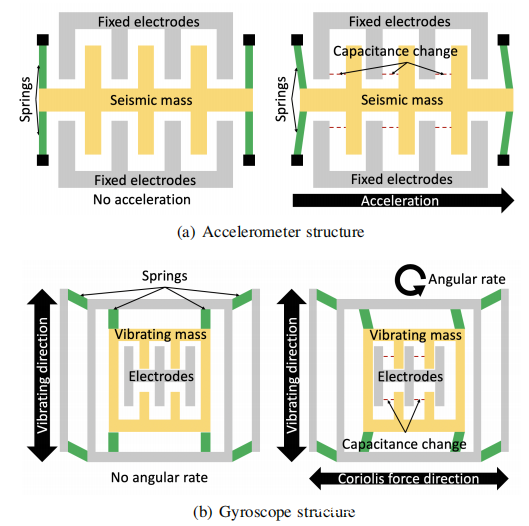
加速度计:三轴加速度计是一种装置,可捕获其人体沿三个传感轴的加速度。每个轴通常由一个传感单元处理,该传感单元包括一个可移动的地震质量,几个固定电极和几个弹簧腿,如上图(a)所示。当加速度计沿传感轴经历加速度时,相应的震动质量将向相反的方向移动,并导致电极之间的电容发生变化。这种变化产生了一个模拟信号,然后将其映射到加速度测量值。
陀螺仪:智能手机上的陀螺仪通常利用科里奥利力(Coriolis force)来测量围绕三个轴的角速度。如上图(b)所示,每个轴的感应单元都具有与加速度计相似的结构,除了质量始终在振动并且可以沿两个轴移动之外。当陀螺仪经历外部角速度时,由于科里奥利效应,质量块趋于在同一平面内继续振动,并在垂直于质量块的旋转轴和运动方向的方向上施加科里奥利力。该力产生质量的位移并改变电极之间的电容。通过测量电容变化,可以获得器件的角速率。
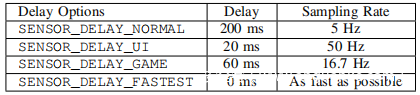
实际上,运动传感器捕获的信息不仅取决于其对周围环境的敏感性,还取决于采样频率。在Android驱动的智能手机上,可以使用上表中列出的四个延迟选项来访问运动传感器。每个选项指定将传感器测量值发送到应用程序的时间间隔。特别是,如果应用程序选择SENSOR_DELAY_FASTEST,则传感器测量值将尽快发送到该应用程序,而实际采样率将主要由智能手机的性能决定。根据奈奎斯特采样定理,2014年,实际采样率达到200Hz,这使运动传感器能够准确捕获100 Hz以下的频率分量。
B.通过运动传感器进行语音识别
人类语音信号的基本频率会携带重要的语言和非语言信息,例如自然性,情感和讲话者特质。它被定义为声带的振动速率,并根据年龄,性别,个体生理状况等而广泛变化。通常,成年男性和成年女性的基本频率分别在85-180Hz和165-255Hz的范围内。由于此基本频率的频率范围与智能手机传感器的频率范围部分重叠,因此已经开发了加速度计和陀螺仪来捕获低频带中一小部分语音信号。
0x03 Problem Formulation
在本文中考虑了对智能手机扬声器发起侧信道攻击的新问题:通过利用同一设备上的加速度计来识别和重构智能手机扬声器播放的语音信号。攻击主要针对Android系统,因为它作为开源移动操作系统盛行(不考虑其变体)。请注意,由于iOS中加速度计的最大采样率还取决于硬件支持的最大频率,因此所建议的方法也可以扩展为攻击iOS。之所以喜欢使用加速度计是因为它比陀螺仪对振动更敏感。陀螺仪和加速度计之间的比较如下图所示。
A.威胁模型
假设受害者使用高端智能手机。智能手机播放包含私人信息的语音信号。在本文中重点研究由数字,字母和热词组成的私人信息,例如社会保险号,密码,信用卡号等。智能手机可以放在桌子上或用户的手中。
语音信号中包含的私人信息。间谍App会在后台连续收集加速度计的测量值,并尝试在智能手机扬声器播放音频信号时(例如,在通话或语音消息期间)提取语音信息。可以通过检查收集的加速度计测量值的高频成分来实现对游戏活动的检测。尽管加速度计也可能会受到日常活动的影响,但这些活动很少会影响80Hz以上的频率分量。
对于私人信息的提取,本研究实现了基于加速度计的语音识别和语音重构。语音识别将加速度信号转换为文本。它使攻击者能够从加速度计的测量结果中识别出预训练的数字,字母和热门单词。语音重构从加速信号中重构语音信号。它使攻击者可以用人耳仔细检查识别结果。由于重构模型主要学习信号之间的映射而不是语义信息,因此与识别模型相比,它更适用于未经训练的单词。
间谍App可能会伪装成智能手机上运行的任何应用程序,因为访问加速计不需要任何许可。在不失一般性的前提下,在本文中,通过在后台运行的第三方Android应用程序AccDataRec收集了加速度计读数(信号)。此应用程序需要零权限才能记录三轴加速度计读数以及时间戳。本文不考虑耳扬声器和耳机,因为它们几乎不会影响加速度计。
B.攻击场景
本文所述的侧信道攻击使攻击者可以通过分析其加速度计测量值来识别智能手机发出(播放)的预训练热词。这种攻击不仅会影响智能手机的所有者,还会影响他/她的联系人。
对于智能手机所有者,智能手机上的间谍应用可能会窃取以下信息:
1)语音备忘录:当用户收听其语音备忘录时,间谍应用可以捕获经过预先训练的关键字。由于语音备忘录通常用于记录重要的私人信息(例如密码,电话号码和邮政编码),因此暴露某些关键字可能会导致严重的隐私泄露。
2)位置信息:由于当前智能手机上的大多数导航应用程序都支持语音导航,因此间谍应用程序可能会通过分析智能手机扬声器发出的地理信息来跟踪用户位置。
3)音乐和视频偏好设置:攻击可以扩展到检测智能手机播放的音乐或视频,然后可以对其进行进一步分析以建立用户的收听和观看习惯。
间谍应用还可以窃听远程呼叫者,这些远程呼叫者会拨打电话或向受害者的智能手机发送语音消息。例如,Alice(受害人)打了个电话给Bob,并要求提供带有CVV号码的信用卡号。由于Bob的声音将由Alice的智能手机播放,因此Alice手机上的间谍应用程序将能够提取语音数字和流行词。在这种攻击中,攻击者只能窃听远程呼叫者,因为智能手机所有者的声音将不会被他/她的智能手机播放。尽管在一个电话中收听对话的一侧可能会丢失重要的上下文信息,但攻击者可以通过分析加速度计的测量值来进一步识别远程呼叫者。
这使攻击者可以将在多个电话中提取的私人信息链接到特定的呼叫者。一旦攻击者收集了特定联系人的多条信息(例如,社会安全号码,信用卡号,电话号码,密码等),该联系人的隐私将受到严重威胁。
0x04 Feasibility Study
如前所述,核心思想是利用智能手机上的加速度计作为零许可麦克风来窃听同一设备的扬声器。现在,从三个方面展示实验验证,以证明这种攻击的可行性(严重性):重要性,有效性和健壮性。
A.重要性
这种攻击背后的核心是同一设备的加速器和扬声器将始终与同一块板物理接触,并且彼此非常靠近,从而使语音信号在加速度计测量中始终能够产生显着的响应。
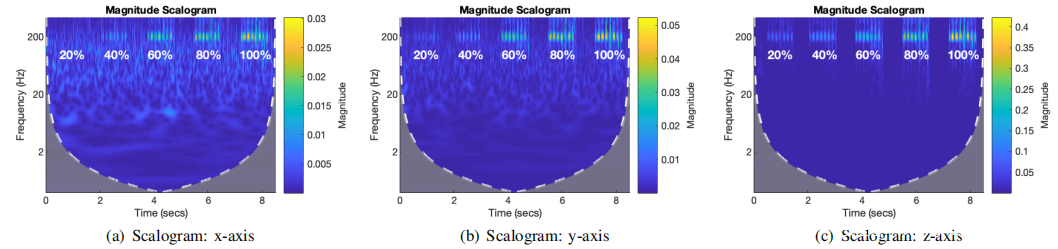
为了验证这一假设,评估了智能手机的加速度计在不同音量下对其扬声器的响应。具体来说,会产生200 Hz的单音信号,并在Samsung S8上以智能手机支持的最高音量的20%,40%,60%,80%和100%播放它。对于每种设置,将智能手机放在桌子上并播放语音信号一秒钟。通过在后台运行的AccDataRec APP同时收集加速度计读数。
记录加速度信号后,计算每个轴的连续小波变换并生成相应的比例图,这些比例图显示了频率分量的大小如何随时间变化。所获得的比例图如下图所示,其中比例图中较亮的区域表示频率分量更强。可以看到,从最高音量的20%的音量水平开始,大约200 Hz的区域变得更亮(尤其是对于z轴),这表明加速度计成功捕获了扬声器发出的语音信号。
为了便于在不同设置下对加速度计的响应进行定量比较,将加速度计的音频响应进一步量化为:
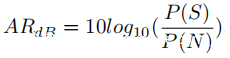
其中P是平方和的总和,S和N是在有语音信号和没有语音信号(由扬声器播放)的情况下记录的两个加速度信号。该ARdB类似于信噪比(SNR)的定义,只是此处的信号(S)是捕获的语音信号和噪声的混合。在噪声信号随时间变化保持恒定的理想情况下,音频响应ARdB高于零表示正在研究的语音信号已影响加速度计。但是,由于噪声的变化性质,从纯噪声信号(没有任何音频信息)计算出的ARdB也可能在零附近的小范围内波动。通过研究来自多个智能手机加速度计的纯噪声信号,观察到三个阈值可以有效地确定加速度计是否已受到语音信号的显着影响。

上表列出了根据每个特定设置计算出的音频响应。可以观察到,加速度计的音频响应随轴而显着变化,并且随着音量的增大而增加。沿x轴,y轴和z轴的传感单元能够分别捕获高于60%,60%和20%音量水平的语音信号。一个重要的观察结果是,对于所研究的每个语音信号,被测试的加速度计始终在z轴上响应最强,其次是y轴,然后是x轴。实际上,无论智能手机是放在桌子上还是用手拿着,这种关系都保持不变。这种一致性可以通过加速度计传感单元的结构来解释。对于每个传感单元,地震质量仅沿其传感轴振动,因此对来自其他方向的振动信号不太敏感。由于智能手机扬声器产生的振动将始终通过智能手机的主板传播,并从同一方向“撞击”智能手机加速度计,因此加速度计在同一轴上将始终具有最显着的音频响应。这种一致性很重要,因为它有助于确定从每个感应轴捕获的语音信息部分。在本文中将响应最强的轴称为智能手机的主导轴。
B.有效性
以前常识是在Android驱动的智能手机中加速度计和陀螺仪的采样率不能超过200 Hz,由于成年男性和成年女性的典型基本频率分别在85-180Hz和165-255Hz的范围内,这种常识意味着传感器只能在很小的范围内捕获人类语音。在85-100 Hz频段(根据奈奎斯特定理),因此攻击的有效性受到限制。但是,如前文所述,如果Android应用程序选择SENSOR_DELAY_FASTEST,则官方文档声称传感器测量值将尽快发送到该应用程序。在这种情况下,假设最近的智能手机型号的最快采样率可能会超过200Hz。
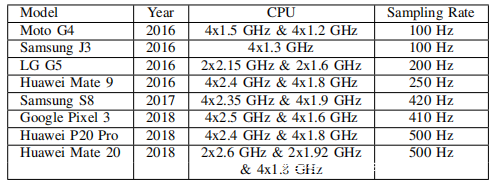
为了验证上述假设,测试了不同年份发布的八款智能手机,并在上表中列出了加速度计的实际采样率。结果证实,随着智能手机型号的发展,加速度计的实际采样率会迅速增加。对于2017年之后发布的高端智能手机,其加速度计已达到400 Hz以上的采样频率,因此应该能够捕获相当大范围的人类语音。特别是对于华为P20 Pro和Mate 20,其加速度计的采样率已高达500 Hz,这使它们能够捕获高达250 Hz的频率分量。由于成人语音的最高基本频率仅为255 Hz,因此这两款智能手机几乎可以覆盖成人语音的整个基本频带。运动传感器对语音隐私的威胁已成为一个严重的问题,并且由于智能手机型号的快速改进而将继续增长。
C.健壮性
智能手机上的加速度计对环境噪声高度敏感。在调查中的对抗设置中,噪声可能来自以下来源:硬件失真,声音噪声,人为活动,自噪声和表面振动。研究了所有这些噪声,发现除了智能手机扬声器播放的音频信号中包含的声学噪声外,这些噪声中的大多数要么不太可能影响加速度计读数,要么可以被有效消除。
硬件失真是制造缺陷导致的系统性失真。机电结构的微小变化(例如,固定电极之间的间隙和地震质量的柔韧性)会导致测量值略有不同。为了说明起见,将四个智能手机放在同一张桌子上,并记录它们在六个方向(+ x,-x,+ y,-y,+ z,-z)上对重力的响应。
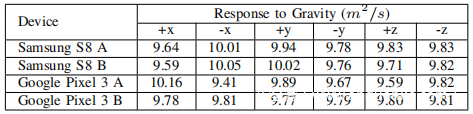
如上表所示,沿不同方向测得的重力略有不同,这表明存在硬件失真。给定特定的加速度计,其沿第i轴的实际测量值可以建模为:
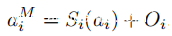
其中ai是实际加速度,Si和Oi分别代表增益和失调误差。因此,沿第i轴的实际加速度信号可以通过以下方式恢复:
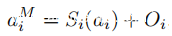
其中Si和Oi是通过分析加速度计对重力的响应来计算的。
在提出的攻击中,攻击者甚至没有必要恢复实际的加速度信号。这是因为由加速度计捕获的语音信息主要分布在85 Hz以上的频率分量中,而偏移误差仅会影响DC(0 Hz)分量。对于增益误差,它仅影响捕获的语音信号的“响度”,因此不会使其频谱失真。因此,仅通过消除捕获信号的直流分量来解决硬件失真。
声音噪声是指周围环境中所有不想要的声音信号,可能来自语音,音乐,车辆,工业来源等。对于本文提出的攻击,声音噪声主要来自受害者的周围环境。智能手机和播放的音频的噪声成分,即远程呼叫者周围的噪声。
对于受害者智能手机周围的声音,声音将通过空气传播,到达加速度计。即使在高声压水平下,机载语音信号也不会对加速度计的测量产生任何明显的影响。为了研究其他噪声信号的影响,首先将智能手机带入了三个嘈杂的环境(酒吧,拥挤的公交车站和地铁站),并收集了30秒的加速度计测量值。对于所有三种环境,都观察到对加速度计的测量没有显着影响,并且沿z轴的ARdB值分别仅为0.1900、0.0724和-0.0431。
然后评估共振频率的影响,加速度计的质量弹簧系统的共振频率通常在几kHz到数十kHz的范围内。在MEMS运动传感器的谐振频率附近的空中音频信号会影响其在高声压级下的测量。为了找出共振频率对系统的影响,以机载音频信号在1000Hz至22000Hz的正常频率范围内测试了Samsung S8,Google Pixel 3和Huawei P20的音频响应。对于正在调查的每款智能手机,都会以配置为最高音量的Huawei Mate 20扬声器来刺激其加速度计。扬声器和加速度计放在两个不同的桌子上,相距10厘米,以消除表面振动的影响并最大程度地增加加速度计上的声压。音频信号是一系列两秒钟的单音信号,范围从1000Hz到22000Hz,步进频率为50Hz。
计算加速度计在每个频率下的音频响应,并绘制获得的ARdB值的分布图(上图(a))。所得的ARdB值似乎正好分配给每个智能手机,并且没有明显的异常值。大多数记录的加速度信号的ARdB低于3。三星S8,Google Pixel 3和华为P20分别在4150 Hz(z轴),9450Hz(z轴)和11450Hz(x轴)时达到最高ARdB值。上图(b),(c)和(d)显示了在这些频率下记录的加速度信号的比例图。对于Samsung S8和Google Pixel 3,加速度计在任何特定频率下均没有恒定响应,这表明高ARdB值是由环境振动的变化引起的。对于华为P20,其加速度计似乎在20Hz时具有恒定但较弱的响应。用相同的刺激信号重复该实验10次,但尚未成功再现响应,这表明ARdB值是由环境振动引起的。根据这些实验结果,可以得出结论,在常规频率(低于22000Hz)和声压级下的机载声噪声不太可能使加速度计的测量值失真。拟议的攻击将不受受害智能手机周围声音的影响。
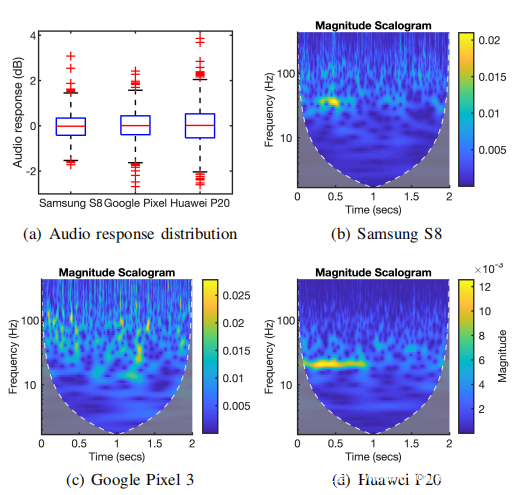
对于远程呼叫者周围的声音噪声,因为噪声信号将进入呼叫者的智能手机并由受害设备播放,所以受害智能手机的加速度计可能会受到影响。为了研究此类噪音的影响,将受害者的智能手机设置为最高音量,并在六个具有不同噪音水平的真实环境中拨打电话给志愿者:1)安静的房间,2)可以与人交谈的实验室,3)可以播放音乐的酒吧,4)拥挤的公交车站,5)列车正在运行的地铁站,6)没有列车在运行的地铁站。对于每种环境,都会收集30秒的加速度计测量值,并计算沿z轴的平均ARdb。从六个环境获得的ARdb为-0.85、1.67、9.15、13.87、12.18、4.89。下图绘制了收集的加速度计测量值的时域和频域。可以观察到,环境3、4和5中的噪声信号已显着影响加速度计测量的所有频率分量。环境1、2和6中的噪声信号对加速度计的测量影响较小,并且主要影响加速度信号的低频段,因此可以通过高通滤波器显着抑制。由于远程呼叫者周围的噪声会严重影响加速度计的测量,
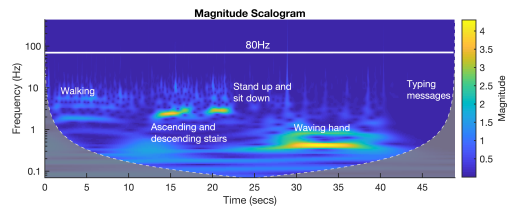
人类活动会严重影响智能手机加速度计的测量,因此可能会使攻击者推断出的语音信息失真。为了评估人类活动的影响,研究了加速度计对五种人类活动的反应:走路,上楼梯和下楼梯,站起来坐下,挥手和键入消息。在每次测试过程中,用户都握有在后台运行AccDataRec的Samsung S8,并进行大约10秒钟的活动。因为加速度计沿三个轴表现出非常相似的响应,所以将获得的加速度信号连接起来,并在下图中显示y轴的比例图。可以观察到,每个测试的活动都会产生一个相对唯一且恒定的模式。加速度信号。但是,这些活动都不会对80 Hz以上的频率分量产生重大影响。由于成人语音信号的典型基本频率为85Hz至255Hz,因此具有80Hz截止频率的高通滤波器可以消除人类活动引起的大部分失真(如图所示)。剩余的失真主要以非常短的时间脉冲存在于高频域中,根据观察,实际上对识别/重构的影响很小,但会影响分割方式。
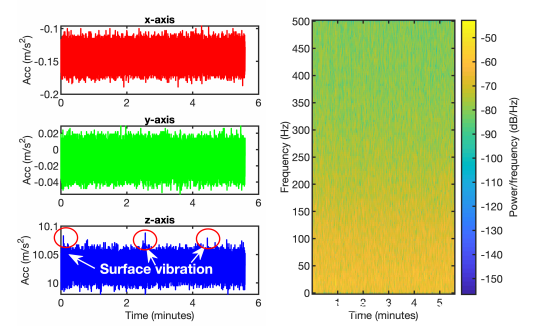
自噪声和表面振动:自噪声是指在没有外部刺激的情况下,智能手机的加速度计输出的噪声信号。该噪声是加速度计本身的固有特征,并且对所提出系统的主要噪声成分有所贡献。因为几乎不可能将加速度计保持在没有任何外部刺激的状态下,所以研究了自噪声和表面振动的综合作用。将智能手机放在桌子上时,表面振动可能会影响加速度计沿z轴的测量。为了测量这两个噪声源的影响,将三星S8放在桌子上并记录其加速度计的测量值330秒钟。桌子的固体表面可以有效地将振动传递给智能手机,并且被放置在正在建造的建筑物中。加速度计的输出信号如图下图(a)所示。可以看出,加速度计沿x轴和y轴具有恒定的噪声输出。加速度计的自噪声是这些噪声输出的主要来源。对于z轴,加速度计输出恒定的噪声信号以及表面振动。沿三个轴的加速度信号的频率分布相似。为了说明起见,下图(b)沿z轴绘制了信号的频谱图(去除了DC偏移)。在此频谱图中,约57%的能量分布在80Hz以下。因为成人语音的典型基本频率是从85Hz到255Hz,所以通过消除80 Hz以下的频率分量来解决自噪声和表面振动。
0x05 The Proposed System
在本节中将详细介绍提出的系统,该系统主要包括三个模块,即预处理模块,识别模块和重构模块。
A.预处理
系统的主要目的是识别并重构由智能手机加速度计捕获的语音信息。与分析原始波形数据相比,识别语音信号的一种更为普遍和优雅的方法是分析其频谱图表示。这样的表示显示了信号的频率分量以及它们的强度如何随时间变化。在基于常规音频信号的语音识别任务中,通常会在Mel刻度上进一步处理频谱图,以计算梅尔频率倒谱系数倒谱系数(MFCC)。这是因为梅尔刻度模仿了人耳的非线性感知特性,并且有利于丢弃多余和多余的信息。但是在系统中,梅尔刻度表示几乎没有帮助,因为现代智能手机中的加速度计只能捕获低频段的语音信号。因此,在提出的系统中,将加速度信号预处理成声谱图以进行语音识别和重构。频谱图表示法可以在频域中明确反映信号的多尺度信息,并可以使用计算机视觉任务中广泛使用的某些网络结构,例如ResNet和DenseNet。
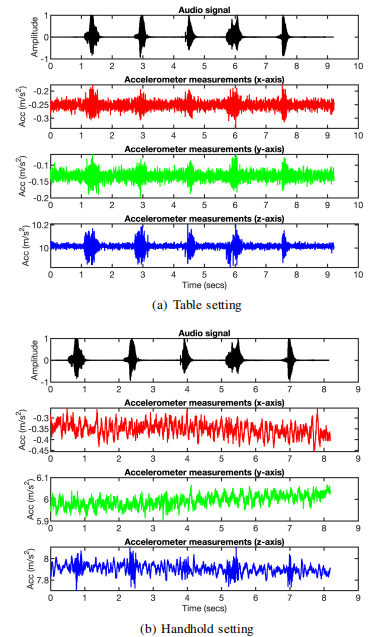
在不失一般性的前提下,现在使用三星S8来帮助说明如何从原始加速度测量中生成频谱图。上图(a)和上图(b)显示了从两个不同设置收集的原始加速度信号。在设置中将智能手机放在桌上,并通过扬声器播放五个孤立数字(从零到四个)的语音信号。通过此设置收集的加速度信号在所有轴上均显示出强烈的音频响应。对于手持设备设置,手持的智能手机播放相同的语音信号。由于手的意外移动,加速度信号严重失真。原始加速度信号存在三个主要问题:
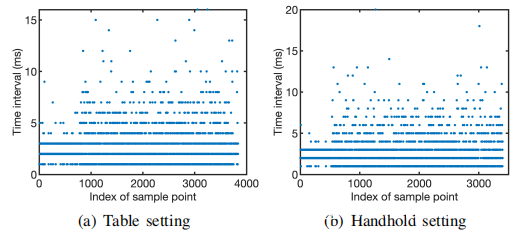
1)由于系统配置为将加速度计测量结果尽快发送到应用程序,因此原始加速度计测量值不会以固定间隔进行采样(上图)。
2)原始加速度计的测量值可能会因人为移动而严重失真。
3)原始加速度计测量值已捕获多个数字,需要进行细分。
为了解决这些问题,使用以下步骤将原始加速度信号转换为频谱图。
插值:首先使用线性插值来处理加速度计测量的不稳定间隔。因为传感器测量的时间戳具有毫秒精度,所以解决不稳定间隔的一种自然方法是将加速度计的测量值上采样到1000 Hz。因此,首先使用时间戳来定位所有没有加速度计测量的时间点,然后使用线性插值法来填充丢失的数据。产生的信号具有1000 Hz的固定采样率。注意到这种内插(上采样)过程不会增加加速度信号的语音信息。其主要目的是生成具有固定采样率的加速度信号。
高通滤波器:然后使用高通滤波器消除因重力,硬件失真(偏移误差)和人为活动引起的严重失真。特别是首先使用短时傅立叶变换(STFT)将沿每个轴的加速度信号转换为频域。它将长信号分为等长段(有重叠),并分别计算每个段的傅立叶变换。然后将截止频率以下的所有频率分量的系数设置为零,并使用反STFT将信号转换回时域。由于成年男性和女性的基本频率通常高于85 Hz,并且人类活动很少影响80 Hz以上的频率分量,语音识别的截止频率设置为80Hz,因此噪声分量的影响可以最小化。对于语音重构,由于重构网络主要学习加速度信号和音频信号之间的映射,因此使用20 Hz的截止频率来保留更多的语音信息。下图(b)和(a)显示了截止频率为20 Hz的滤波后的加速度信号。所有加速度信号均偏移为零均值,这表示偏移误差和重力(对于z轴)已成功消除。对于在手持设置下收集的加速度信号,高通滤波器还消除了手运动的影响。在该步骤之后获得的滤波信号主要由目标语音信息和加速度计的自身噪声组成。
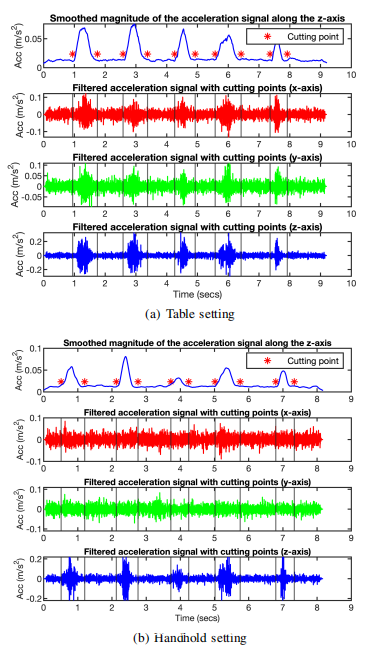
分割:由于沿三个轴的加速度信号完全同步,使用第四节中描述的主导轴(z轴)来定位切割点,然后使用获得的切割点沿三个轴对滤波后的加速度信号进行分割。切割点的位置如下:给定沿主轴的加速度信号,首先通过另一轮截止频率为160 Hz的高通滤波对信号进行消毒。通过研究从嘈杂的实验装置中收集的信号,观察到该截止频率可以消除大量的噪声成分,包括由人体运动引起的短时间脉冲。通常,仅当智能手机经历外部振动或剧烈运动时才需要执行此过程。然后计算经过净化的信号的幅度(绝对值),并使用两轮移动平均值对获得的幅度序列进行平滑处理。第一轮和第二轮的滑动窗口分别为200和30。两种设置的平滑幅度序列如上图所示。接下来,找到平滑幅度序列的最大值Mmax和最小值Mmin。在此过程中,第一个和最后一个100个幅度值将被丢弃,因为它们没有足够的相邻样本进行平均。所获得的最小值大约是噪声信号的大小。之后遍历平滑的幅度序列,并找到幅度大于0.8Mmin + 0.2Mmax阈值的所有区域。每个定位的区域指示语音信号的存在。为了确保分段的信号将覆盖整个语音信号,然后将每个定位区域的起点和终点分别向前和向后移动100和200个样本。从每个设置计算出的切入点在上图中标记。最后,使用获得的切入点将滤波后的加速度信号分段为多个短信号,每个短信号对应一个单词。
信号到频谱图的转换:为了生成单个单词信号的频谱图,首先将信号分成固定重叠的多个短段。段的长度和重叠的长度分别设置为128和120。然后,用汉明窗口对每个片段进行窗口化,并通过STFT计算其频谱,STFT为每个片段生成一系列复数系数。现在,沿每个轴的信号被转换成STFT矩阵,该矩阵记录了每个时间和频率的幅度和相位。最后,二维频谱图可以通过:
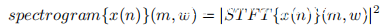
其中x(n)和|STFT{x(n)}(m,w)|分别表示单轴加速度信号及其对应的STFT矩阵的大小。因为沿三个轴都有加速度信号,所以每个单字信号可以获得三个频谱图。为了说明起见,下图绘制了每个设置的第一个单字信号的频谱图(z轴)。由于高通滤波过程,低于20 Hz的频率分量接近于零。
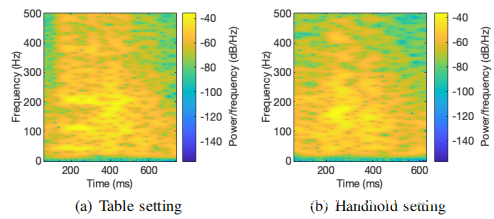
频谱图图像:为了将频谱图直接馈送到计算机视觉任务中使用的神经网络,进一步将信号的三个二维频谱图转换为一个PNG格式的RGB图像。为此首先将三个m×n频谱图拟合为一个m×n×3张量。然后取张量中所有元素的平方根,并将获得的值映射到0到255之间的整数。取平方根的原因是原始二维频谱图中的大多数元素都非常接近零。将这些元素直接映射到0到255之间的整数将导致相当多的信息丢失。最后将m×n×3张量导出为PNG格式的图像。在所获得的频谱图图像中,红色,绿色和蓝色通道分别对应于加速度信号的x轴,y轴和z轴。对于识别任务,将频谱图图像裁剪到80 Hz至300 Hz的频率范围,以减少自噪声的影响。下图绘制了每个设置的第一个单词信号的频谱图。较亮的区域表示在该时间段内该频率范围内的加速度信号具有较强的能量。可以观察到在这两种设置下,蓝色通道(沿z轴的加速度信号)提供最多的语音信息。

B.识别
通过上述预处理操作,可以将调整后的加速度频谱图图像输入到各种标准的神经网络中,例如VGG,ResNet ,Wide-ResNet和DenseNet。现在,详细介绍识别模块的设计。
调整频谱图:图像的大小要将这些频谱图图像输入到标准化的计算机视觉网络中,最好将其大小调整为n×n×3个图像。注意,细粒度的信息和加速度谱图的相关性可能会影响识别结果,尤其是讲话者识别的结果。为了保留足够的信息,将频谱图图像的大小调整为224×224×3。
网络选择:通常选择DenseNet作为所有识别任务的基础网络。与VGG和ResNet等传统深度网络相比,DenseNet在每层与其之前的所有层之间引入了连接,即L层网络中总共(L + 1)L/2个连接。例如,如DenseNet中的公共方框图所示(下图(a)),第一到第四层都直接链接到第五层。换句话说,第l个将从第0层(输入图像)到第(l-1)层的特征图的级联作为输入,这可以用数学方式表示为:
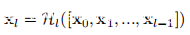
H1和x1分别表示第l层的功能和特征图。 [x0,x1,…,xl-1]表示第0层到第1-1层的特征图的并置。这些直接连接使所有层都可以接收和重用其先前层中的功能,因此,DenseNet不必使用某些冗余参数或节点来维护来自先前层的信息。因此,DenseNet可以使用更少的节点(参数)来实现与VGG和ResNet相当的性能。此外,整个网络中改进的信息流和梯度流也减轻了梯度消失的趋势,并使DenseNet易于训练。根据经验发现在识别任务中DenseNet确实以更少的参数和更少的计算成本(与VGG和ResNet相比)实现了最佳的准确性。下图(b)展示了利用的整体网络结构,它由下图(a)所示的多个密集块组成。
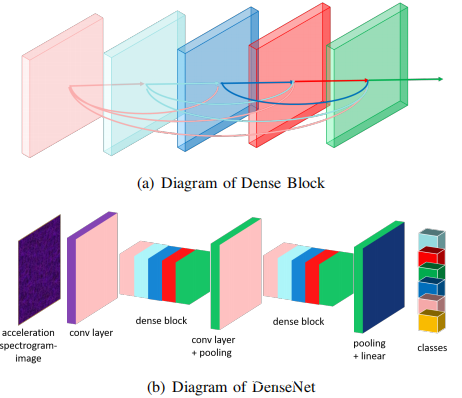
训练过程:在训练阶段,使用交叉熵作为训练损失,并通过分段动量优化器优化模型权重,以学习更多可概括的特征并促进收敛。具体地,自适应动量优化过程首先以较大的步长(例如0.1)执行以学习可概括的特征,然后通过较小的步长进行微调以促进收敛。还将体重下降添加到训练损失中,并将辍学率设置为0.3,以增强通用性。
C.重构
除了识别以外,从相应的加速度信号(频谱图)重构语音信号也是系统中的一项功能,因为该功能可用于仔细检查识别结果。请注意,尽管当前智能手机中的加速度计只能捕获低频分量,但高频带中的许多分量主要是这些基本频率分量的谐波,这有可能以更高的采样率重构语音信号。为了实现语音信号重构,首先通过以下重构网络重构语音频谱图,并以加速度频谱图图像作为输入。然后,语音信号由Griffin-Lim算法根据重构的语音频谱图进行估计。接下来将详细介绍重构网络和语音信号估计方法。
1)重构网络:重构网络由三个子网络组成,即一个编码器,残余块和一个解码器。重构网络的输入是一个128×128×3的频谱图图像,覆盖20至500 Hz的频率分量。每个通道对应于加速度信号的一个轴。但是,这里标准化输入大小的问题是,由于来自不同扬声器的语音信号的时间长度不同,因此加速度信号可能具有不同的时间长度,但是由于时标的原因,此处不需要调整频谱图图像的大小。在重构过程中最好保留信息。一种简单的解决方案是重复语音信号,直到达到预定的时间长度为止。该解决方案是有效的,因为与上面的识别模块的输入必须是单个单词的频谱图图像不同,重构任务对语音/加速信号(频谱图)的内容不施加任何限制。重构网络的输出是384×128灰度图像,代表相应的语音频谱图,因为语音信号只有一个轴。由于加速度计的采样率有限,重构网络仅旨在重构语音信号从0到1500 Hz的频率分量。
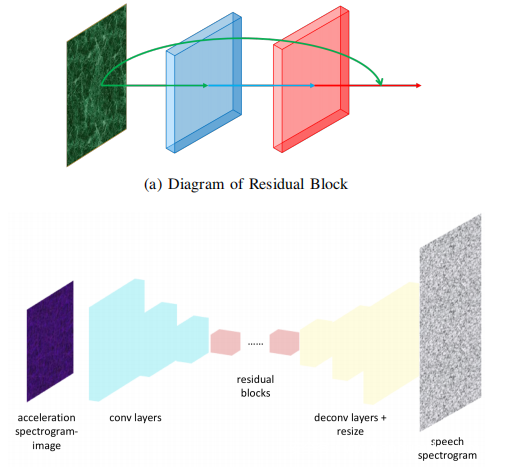
编码器:第一个子网是用于编码加速度频谱图图像(即上图(b)中的转换层)的编码器。编码器从具有32个9×9×3内核的卷积层开始以学习大规模特征,然后是两个具有64个3×3×32内核的卷积层和128个3×3×64内核的卷积层分别学习小规模功能。此外,在前两层上应用了跨度为2的步长以进行下采样。在编码器之后添加了五个残差块(如上图(a)所示),以明确让特征适合残差映射H(·),即
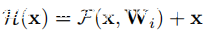
其中F(x,Wi)是卷积层学习的非线性映射。考虑到加速度和语音信号的频谱图之间的结构相似性,很有可能身份映射是建立某些特征连接的最佳/接近最佳映射。当最佳映射等于或接近恒等函数时,比未引用的块F更容易优化H。这是因为将F的参数推入零应该比将F优化为恒等映射更容易。因此,在重构网络的中间添加了多个残差块H(即上图(b)中的残差块)。
解码器:最后,由解码器(即上图(b)中的反变换层)从由编码器学习的特征和残差块对语音频谱图进行解码。解码器还包含3个反卷积层,分别具有64个3×3×128大小的内核,32个3×3×64大小的内核和3个9×9×32大小的内核。跨度为1/2。在前两层进行上采样。解码器的初始输出是128×128×3矩阵,并且该矩阵将进一步调整为384×128灰度图像,以表示相应的语音频谱图,如上所述。
训练过程:与识别相比,重构是一项任务,其训练过程更加不稳定且计算量大。由于频谱图的稀疏性,不稳定的问题可能是由训练小批量中的稀疏异常值引起的。为了解决这个问题,使用重构图像和目标图像之间的L1距离作为训练损失,而不是MSE损失。这是因为L1损失比MSE对离群值的损失更稳健。此外还对L1损失进行权重衰减以增强通用性。为了降低计算成本,通过对学习速率应用基于时间的衰减来加速优化过程。具体来说,将动量优化器与学习率调度程序配合使用,从而使每个训练时期的学习率降低0.9倍。
2)语音信号估计:Griffin-Lim算法是一种从频谱图估计信号的迭代算法。每个迭代包含两个步骤:第一步是通过频谱图修改当前信号估计的STFT;第二步是通过修改后的STFT来更新当前的信号估计。第二步是通过修改后的STFT更新当前信号估计。接下来将详细说明两个步骤。
修改STFT:给定第i次迭代中语音信号xi [n]的当前估计以及重构幅度(频谱图的平方根)kY(m,w)k,xi [n]的STFT Xi(m,w)]修改为:
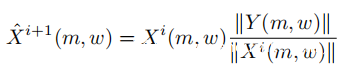
更新信号估计:
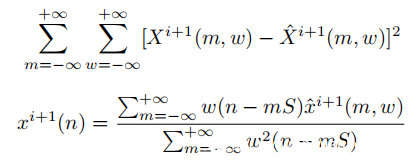
0x06 Implementation and Evalution
A.实验设置和数据集
主要从三星S8收集的加速度计测量结果评估本文系统。对于每个特定设置,都会在智能手机上播放一系列语音信号,并通过在后台运行的第三方Android应用程序AccDataRec收集加速度计读数。
语音信号主要来自两个数据集。第一个数据集由来自AudioMNIST数据集2的20个扬声器的10k个数字信号组成。此数据集中的信号被连接为间隔为0.1秒的长音频信号,以模拟受害人告诉他人他/她的密码的情况。第二个数据集包含从志愿者那里收集的36×260位数字+字母的语音信号。从大学招募志愿者,并在实验室中收集数据。志愿者被要求拿着智能手机,并阅读一系列数字和字母以及他们用来告诉他人密码的语速。共有36个班级,包括10位数字(0-9)加26个字母(A-Z),每个班级包含从10位演讲者那里收集的260个样本。从这两个语音源收集加速度计读数,并在不同的设置下评估拟议的系统。本文介绍的所有实验结果均与用户无关。对于所调查的每个设置,将所有收集到的信号随机分为80%的训练数据和20%的测试数据。在下文中,仅报告测试准确性。
B.识别
如前所述,现有技术(SOTA)模型使用智能手机上的陀螺仪捕获放置在同一固体表面上的扬声器发出的语音信号。为了进行公平的比较,首先在类似的环境中评估模型的性能-即将智能手机放在桌子上。上表列出了系统在数字识别,数字+字母识别和说话者识别方面的top1,top3,top5(测试)准确性。前N个准确性是指正确的标签位于网络预测的前N个类别中的概率。值得注意的是,本文模型在与用户无关的设置中对数字识别的top1准确性甚至比在与用户相关的设置中的SOTA准确性高出13%。系统在识别10位数字和26个字母(总共36个类别)时,还达到55%的top1准确性和87%的top5准确性。在说话者识别方面,系统在对20个说话者进行分类时可达到70%的准确度,而以前的SOTA模型在对10个说话者进行分类时仅可达到50%的准确度。总体而言,模型在所有任务中均实现了新的SOTA结果。准确性的提高不仅是因为使用了先进的模型,还因为采样率的提高和建议的设置。设置允许语音信号对运动传感器产生更大的影响,因此与SOTA设置相比,加速度信号的SNR显着提高。如下表所示,随着加速度信号的SNR和加速度计的采样率,识别精度会平稳提高。

除了桌面设置外,系统还适用于其他设置,例如,更常见的情况-智能手机握在用户的手中。与桌面设置相比,手持设置中的加速度计将在x轴和y轴上显示出较低的SNR。因此,应将更多注意力(权重)分配给z轴。在下表中,在“Table”和“Hand-hold”设置中显示了模型的测试准确性。如下表所示,如果模型仅由“Table” 或“Hand-hold”训练集进行训练,则由于这两个设置之间存在上述差异,因此该模型在其他测试集上的占比不超过20% 。但是如果在“Table”+“Hand-hold”训练集上训练模型,则在两个测试集上的准确性都将提高到60%以上。

C.噪音影响
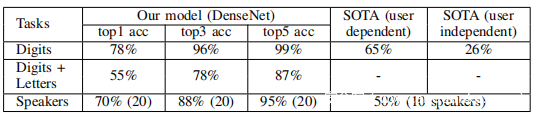
对于加速度计的自噪声,尽管此噪声分量在整个频段上的功率都在降低,但仍可能削弱加速度信号中的特征,从而降低识别精度。为了测试针对这种自噪声的识别模型的鲁棒性,利用高斯白噪声模拟该噪声并生成具有不同SNR的加速度信号。产生的信号模拟在较低音量下收集的加速度计测量值。前表显示了数字识别和说话者识别的结果。尽管精度随着SNR的降低而降低,但在SNR = 2数据上的数字识别精度甚至超过了原始数据上的SOTA精度的意义上,系统实际上非常健壮。
对于远程呼叫者周围的声音噪声,雇用了四名志愿者(两名女性和两名男性),并要求他们从四个具有不同噪声水平的真实环境中向受害智能手机发送语音消息:1)无噪声(安静的房间)。 2)低噪声(与人交谈的实验室)。 3)中等噪音(播放音乐的酒吧)。 4)高噪声(拥挤的公交车站)。这些环境是根据实验结果选择的。然后,在桌面设置下播放收到的语音消息,并记录加速度计的测量值。每个环境的数据集包含从四个说话者那里收集的200×10位数的频谱图。
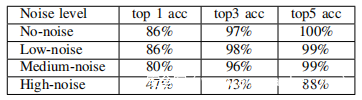
列出了数字识别的结果。出人意料的是,该识别模型在前三个环境中可达到80%以上的准确性。对于高噪声环境,由于分割算法几乎无法区分语音信号和突然的嘈杂声,因此识别精度大大降低。为了找出识别模型是否可以识别出分割良好的高噪声信号,手动调整信号的分割并重复实验。通过手动分割的信号,模型在高噪声环境中可达到78%的top 1精度,这表明识别模型对环境噪声非常鲁棒。由于建议的攻击可以在大多数环境中实现高精度,并且很少有人会在高噪声的环境中拨打电话,因此认为建议的攻击是切实可行的。
D.可扩展性
不同的智能手机可能具有不同的采样率和优势轴,这使得很难将从智能手机训练的识别模型推广到其他智能手机模型。为了研究所提议攻击的可扩展性,从三种不同型号的六款智能手机收集加速信号:1)三星S8:采样率为420 Hz,主轴为Z轴。 2)Huawei Mate 20:采样率为500 Hz,主轴为Z轴。 3)Oppo R17:采样率为410 Hz,并且智能手机在三个轴上具有相似的音频响应。从每种智能手机型号收集1万位数的加速度信号,并评估在全球范围内部署一个型号的可能性。观察到从华为Mate 20和Oppo R17收集的加速度信号比三星S8的噪声信号少得多。
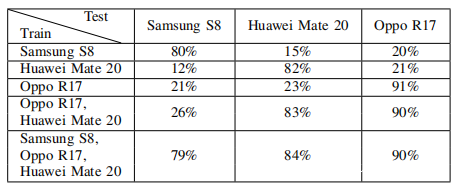
如上表所示,由于不同智能手机型号的硬件特性不同,将由智能手机模型中的数据训练的识别模型推广到其他智能手机并不容易。但是,当使用来自Oppo R17和Huawei Mate 20的数据训练识别模型时,仍然观察到Samsung S8的准确性提高了5%。因此推测,如果识别模型可以扩展到看不见的智能手机,通过来自足够智能手机模型的数据进行训练,可以捕获硬件功能的多样性。此外,上表还表明,识别模型的模型容量足以适应来自多个智能手机模型的数据,而不会损失准确性。
E.重构
重构网络的性能通过两个指标进行评估,即平均测试l1和均方误差。假设重构的语音频谱图为x’,而地面真实语音频谱图为x,则可以通过∑|xi’-xi |计算出’1误差,最终测试的l1误差接近1e3,即每个像素的绝对误差约为0.02(像素范围为[-1,1])。可以通过∑(xi’-xi)^2 N来计算均方误差,其中N是每个图像的像素数。最终测试的均方误差约为3.5e-3。这些结果表明,重构网络能够从误差很小的加速度频谱图中重构语音频谱图。
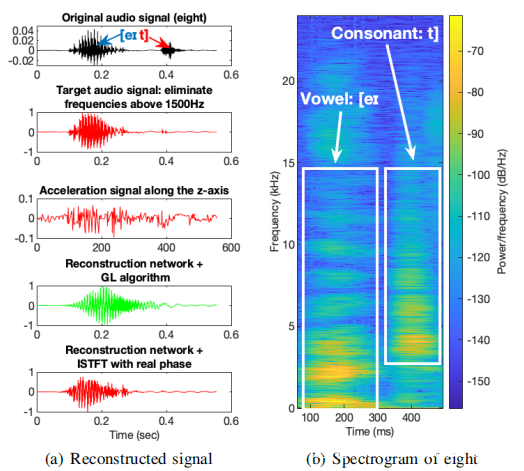
进一步使用Griffin-Lim(GL)算法从重构的频谱图中估计语音信号,并在上图(a)中演示了结果。为了进行比较,在第一行显示原始语音信号。第二行显示没有高于1500Hz频率分量的原始语音信号,这实际上是尝试重构的真(目标)音频信号。尽管此截止频率可能会导致某些辅音信息丢失,但由于加速度信号的频率范围有限,因此1500Hz几乎是此处可以为语音信号重构的最高(谐波)频率。第三行显示原始加速度信号,与截止音频信号相比,原始信号具有相似的结构,但细节完全不同,这表明从加速度信号重构语音信号应该是一项复杂的任务。在第四行中,演示了由重构网络和GL算法重构的语音信号,该算法已经捕获了截止语音信号的大多数结构和细节。重构信号和截止信号之间的剩余差异主要是由于GL算法引起的误差,因为如果简单地将截止语音信号的相位应用到由GL重构的幅度(频谱图)上,在重构网络中,几乎可以恢复与截断音频信号相同的信号,如第五行所示。
本研究的重构模块是从加速度信号重构语音信号的第一个尝试,在大多数结构和细节都可以大致恢复的意义上说,这是成功的。但是,仍然存在两个局限性:一是重构模块恢复的最大(谐波)频率为1500Hz,这可能导致辅音信息丢失。另一个限制来自GL算法,这可能不是补偿相位信息的最佳选择。
F.热词搜索:识别和重构
在本小节中,进行实验以表明模型也可以用于从句子中搜索热门(敏感)单词。在实验中首先使用热门单词搜索模型从句子中识别出经过预训练的热词。然后使用重构模型来重构音频信号,并仔细检查人耳识别的热词。实验是从四位志愿者(两名男性和两名女性)收集的200个简短句子中进行的。每个简短的句子包含几个不敏感的单词和下表中列出的1-3个热词。
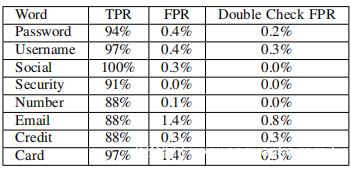
热词搜索模型基于识别模型,该模型可以区分八个热门单词(在上表中列出)和其他不敏感单词。为了训练该模型从志愿者那里收集了一个训练数据集,其中包含128 * 8个热词和2176个不敏感词(负样本)。可以观察到该数据集是类别不平衡的,因为每个热词类别中的样本数量远远少于否定样本的数量。为了解决这个问题,重新加权了这九类的损失。由于否定样本的总数是每个热词类别中样本数的17倍,因此用系数17α加权由热词样本计算的损失,并利用因数α加权由负样本计算的损失。 α是一个超参数,在训练过程中设置为0.1。然后将测试句子的加速度信号分割成单个单词的声谱图,并使用热词搜索模型对其进行识别。如上表所示,识别模型可以在这8个热词上平均获得90%以上的识别准确度,比10位数字上的识别准确度略高。注意到这是因为在此识别任务中只有九个类别,而且,与数字和字母相比,这八个热词的声谱图更具特色。
然后实现了一个重构模型,该模型可以从加速度信号中重构全句子音频信号。因为重构模型主要学习信号之间的映射而不是语义信息,所以它不需要信号分割,并且比识别模型更能推广到看不见(未经训练)的数据。为了训练这样的模型,收集了6480个加速度谱图和音频谱图,它们的句子与测试句子不同。加速度频谱图和音频频谱图的分辨率分别为128×1280×3和384×1280,这使得重构模型可以重构长达12秒的音频信号。使用此模型加上GL算法来重构所有测试句子的音频信号,并雇用两名志愿者来听取它们。在此过程中首先为每位志愿者提供基础培训,其中志愿者将听到20个句子的语音信号及其重构版本。然后要求志愿者聆听重构的信号(句子),并重新标记识别模型错误识别的热词。在此过程中,除非两个自愿者都同意更改热门词的标签,否则不会对其进行更改。事实证明,志愿者可以轻松判断热词是否被错误识别。所有热词的误报率都降低了1%,而真正的积极率没有改变。这主要是因为听完整的句子可以使攻击者利用有价值的上下文信息。
G.端到端案例研究:从电话交谈中窃取密码
现在通过电话对话中的端到端攻击来评估提出的模型。考虑一个真实的场景,即受害者在通话过程中打了一个远程电话给对方,并要求输入密码。攻击者的目的是从受害者的加速度计测量值中找到并识别密码。在这种攻击中,假设密码前面带有热词“ password(is)”
在实验中,使用受害人的智能手机在以下三种不同情况下拨打电话给四名志愿者(两名女性和两名男性):1)桌子:将受害人的智能手机放在桌子上。 2)手持坐式:受害者坐在椅子上,手持智能手机。 3)手持行走:受害者手持智能手机并四处走动。在每种情况下,每人进行16个脚本化对话和4个自由对话(即,总共240个对话)。在所有对话中,要求志愿者在短语“ password is”之后说出一个随机的8位数字密码。
在记录了对话的加速信号后,首先将加速信号转换为多个单个单词的频谱图,然后使用密码搜索模型来查找与热门单词“ pass word”相对应的频谱图。然后,使用数字识别模型来识别其后的8位密码。
密码搜索模型通过分类器在记录的加速度信号中搜索单词“ password”,该分类器可以区分“ password”和其他单词。为了训练这样的分类器,收集了一个训练数据集,其中包含200个“密码”和2200个否定样本,包括数字和其他一些单词。类别不平衡问题也可以通过如VI-F节中那样对损失重新加权来解决。具体来说,将系数为11α的“password”样本计算出的损失加权,并将因子为α的负样本加权计算出的损失加权。如果模型在对话中识别出多个“password”,则会报告置信度值最高的密码。使用此模型,成功找到了所有情况下超过85%对话的密码,如下表所示。

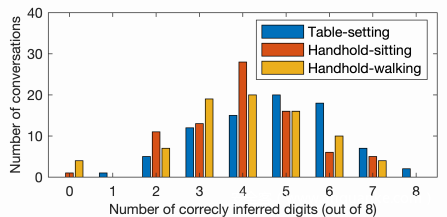
每个场景的数字识别模型都使用280×10位数的频谱图进行训练,表列出了识别模型的整体准确性。还计算了每次对话中正确推断出的数字的数量,并绘制了下图中的分布图。可以看出,与录制和播放场景相比,电话场景中的识别准确率较低。这主要是因为在电话呼叫期间发送的音频信号的质量比记录应用程序记录的音频信号的质量低。一个重要的观察结果是,在所有情况下,识别模型均达到了80%的前3个识别准确率。尽管所提议的攻击仅在几次对话中就可以识别出完整的密码,但这将极大地帮助攻击者缩小对受害者密码的搜索范围。
0x07 Conclusion
在本文中重新审视了零许可的运动传感器对语音隐私的威胁,并提出了针对智能手机扬声器的高度实用的侧信道攻击。提出两个基本观察,这些观察将基于运动传感器的音频窃听扩展到日常场景。首先,智能手机扬声器发出的语音信号将始终对同一智能手机的加速度计产生重大影响。其次,最近的Android智能手机上的加速度计几乎可以覆盖成人语音的整个基本频率范围。在这些关键的观察结果的基础上,提出AccelEve-一种基于学习的智能手机窃听攻击,无论智能手机放置在何处以及如何放置,它都可以识别和重构智能手机扬声器发出的语音信号。凭借深度学习,自适应优化器以及可靠且可概括的损失,攻击在所有识别和重构任务中的攻击性能始终显着优于基线和现有解决方案。特别是,AccelEve在数字识别方面的准确性达到了以前工作的三倍。对于语音重构,AccelEve能够以增强的采样率重构语音信号,该信号不仅覆盖了低频带中的基本频率成分(元音),而且还覆盖了其在高频带中的谐波。辅音无法恢复,因为它们的频率(高于2000Hz)远远超出了当前智能手机的采样率。