
最近一年,AI领域出现了很多迁移学习(transfer learning)和自学习(self-learning)方面的文章,比较有名的有MoCo,MoCo v2,SimCLR等。这些文章一出现,就受到了很多研究人员的追捧,因为在现实任务上,标签数据是非常宝贵的资源,受制于领域标签数据的缺失,神经网络在很多场景下受到了很多限制。但是迁移学习和自学习的出现,在一定程度上缓解甚至解决了这个问题。我们可以在标签丰富的场景下进行有监督的训练,或者在无标签的场景下,进行神经网络无监督的自学习,然后把训练出来的模型进行迁移学习,到标签很少的场景下,利用这种方式来解决领域标签数据少的问题。
我们在维阵产品中,设计针对漏洞检测的图神经网络的时候,大量使用了自学习和迁移学习。
今天分享一篇谷歌大脑的文章《Rethinking Pre-training and Self-training》,希望能对大家的研究有帮助。
视觉任务往往具有一定的通用性,例如在某个分类任务数据集上训练的模型,在迁移到别的分类任务上时,只需要重新训练分类层以及对其他层权重进行微调便能获得不俗的结果。所以在面对下游任务时,采用经过别的任务训练后的模型叫做预训练技术。预训练方法通常分为监督、半监督、无监督法。
最常用的监督预训练技术是:首先在带有标注的大型数据集上训练模型,之后将该模型当作预训练模型执行下游任务。例如在目标检测任务上通常会采用在Imagenet数据集上经过训练的模型当作特征提取网络。
半监督方法的代表是自训练,其使用少量的标记数据和大量的未标记数据对模型进行联合训练。自训练可以分为5个步骤:
1.使用少量带有标签的数据训练模型
2.使用步骤1中得到的模型对未标记数据进行预测,预测结果作为伪标签
3.将标记数据和未标记数据结合标签和伪标签一起训练模型
4.在测试集上评估模型
5.重复1-4步,对模型迭代
无监督方法在无标签的数据集上训练,通过对比损失、互信息最大化等方法获得对数据的通用表示。
在下游任务中,绝大多数采用经过预训练方法的骨干网络通常会使结果得到提升。例如在目标检测任务中,通过监督法得到的预训练模型因为其稳定、简单、容易获取而成为多数目标检测的骨干网络模型。但谷歌最新的研究表明,在数据量足够的情况下,至少在目标检测任务上,采用自训练得到的预训练模型对检测结果的提升要显著优于监督预训练与无监督预训练模型。
01 使用监督学习获得预训练模型
作为实验,研究者首先在Imagenet上训练分类网络作为预训练模型,之后监督得到的预训练模型作为骨干网络在COCO数据集上进行训练。此外,对训练集进行数据增强往往能获得更加通用的表征和更高的鲁棒性。所以研究者还研究了在不同强度的数据增强下得到的预训练模型对目标检测效果的影响。
对于使用监督算法得到的预训练模型,研究者分别在使用了四种不同强度的数据增强的Imagenet上分别训练了EfficientNet-B7,之后将这些模型当作骨干网络在COCO数据集上训练目标检测模型。

实验参数
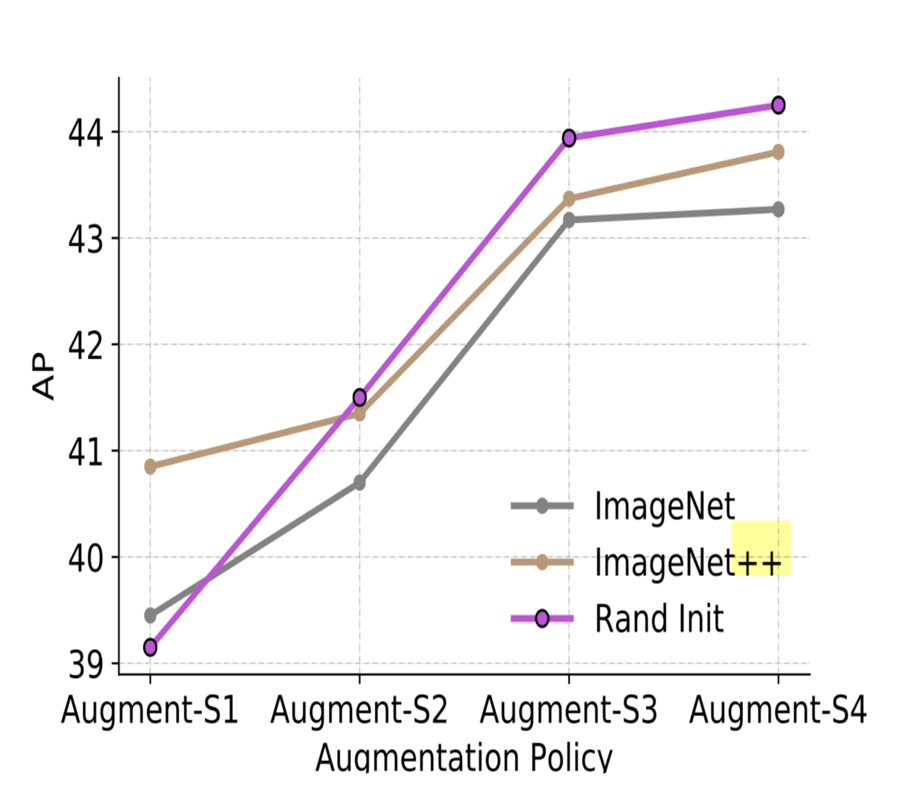
横轴为数据增强强度,纵轴为目标检测结果,Imagenet表示仅在Imagenet数据集上训练,Imagenet++表示使用了额外的数据扩充,Rand init表示骨干网络不使用预训练模型
通过结果表明,在监督环节进行数据增强可以得到更好的目标检测结果。在较低程度的数据增强下,使用监督预训练模型比不使用的效果要好。但随着数据增强的加大,使用预训练模型反而会损害结果。
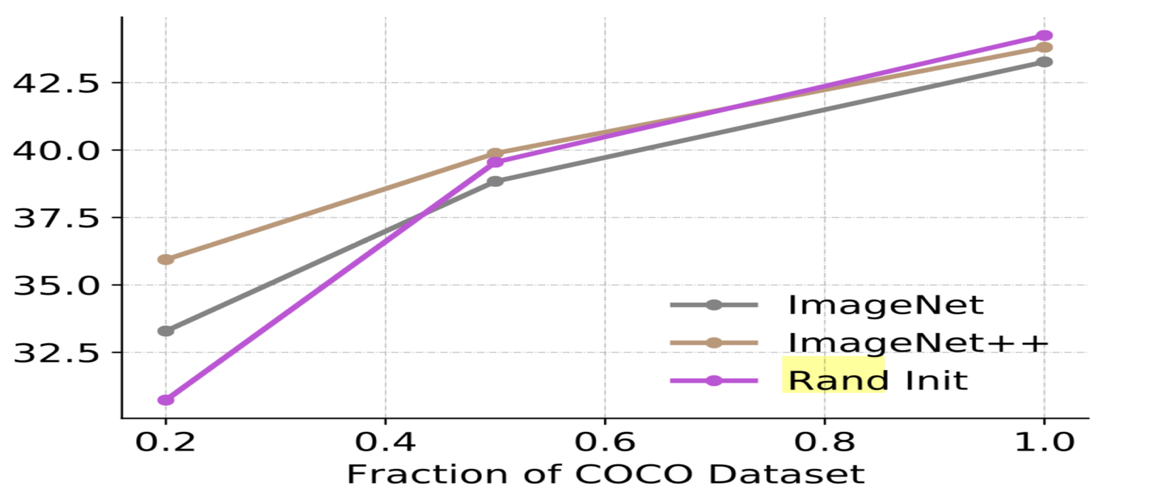
横轴-使用COCO数据集的比例
第二个实验表明,如果主任务(目标检测)的训练集尺寸较小,使用监督方式的预训练模型可以帮助提高检测结果,但随着主任务训练集的增大,使用监督法得到的预训练模型的收益越来越低,甚至最终会损害目标检测结果。
综上,研究者得到了在目标检测任务上使用由监督法得到的预训练模型并不能获得收益,且对数据增强不兼容的结论。
02 使用自训练获得预训练模型
文中使用的自训练方法为noisy student training。在此使用Imagenet当作未标记的数据(不使用标签),而COCO数据集当作标记数据对预训练模型进行联合训练,以此更好的改善最终目标检测的效果。作为与监督预训练的对比结果如下:

不同数据增强模式下基线、监督式预训练、自训练式预训练下的目标检测结果对比
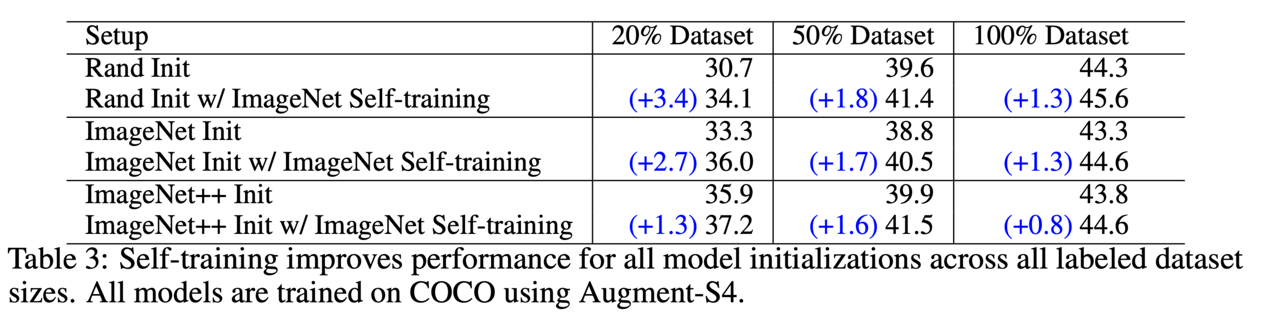
不同数据增强模式下基线、监督式预训练、自训练式预训练下的目标检测结果对比

统一实验条件下三种预监督方法对比
作为与监督预训练与无监督预训练的对比,对照实验表明使用自训练方法得到的预训练模型在各种数据增强模式,不同主任务训练集尺寸的情况下都能获得明显受益,且显著优于基线(不使用预训练模型)和监督式预训练方法。
在语义分割方面,研究者也证明了自训练的预训练方式比监督式预训练可以达到更好的效果:
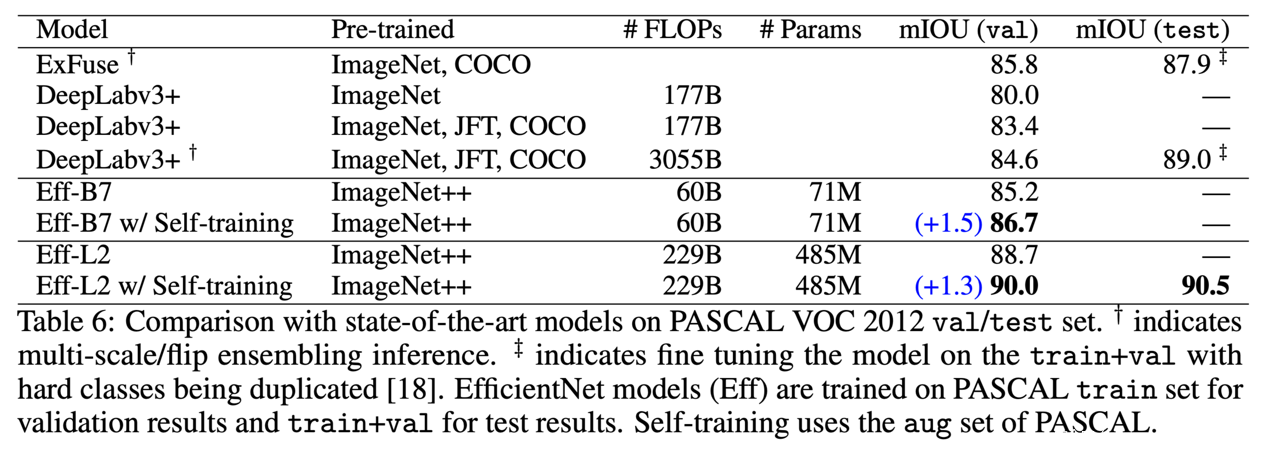
EfficientNet-B7 和L2进行自训练相比监督式预训练可以达到更高的精度
03 结论
通过以上一系列实验证明,监督预训练方法与无监督预训练方法对学习通用表示形式具有局限性,其原因研究者猜测,这两种预训练方法无法意识到当下要关注的任务,因此可能无法适应。切换到下游任务时通常需要根据任务对预训练的模型进行有目的的调整,例如COCO目标检测任务需要目标的位置信息,而在Imagenet分类模型上这些位置信息对分类可能没有帮助,以至于被模型抛弃。而自训练的预训练方法可以更加灵活的融合不同任务之间不同特性,所以其作为预训练的模型更加合适。
论文引用:
Zoph, Barret, et al. “Rethinking pre-training and self -training.” arXiv preprint arXiv:2006.06882 (2020).