
作者: @v1ll4n
安全研发工程师,现就职于长亭科技,喜欢喵喵
本文的内容可能是大家最期待的部分,但是可能并不推荐大家直接阅读本篇文章,因为太多原理性和整体逻辑上的东西散见前两篇文章,直接阅读本文可能会有一些难以预料的困难。:)
0x00 前言
上一篇文章,我们介绍了页面相似度算法以及 sqlmap 对于页面相似的判定规则,同样也跟入了 sqlmap 的一些预处理核心函数。在接下来的部分中,我们会直接开始 sqlmap 的核心检测逻辑的分析,主要涉及到以下方面:
- heuristicCheckSqlInjection 启发式 SQL 注入检测(包括简单的 XSS FI 判断)
- checkSqlInjection SQL 注入检测
0x01 heuristicCheckSqlInjection
这个函数位于 controller.py 的 start() 函数中,同时我们在整体逻辑中也明确指明了这一个步骤:
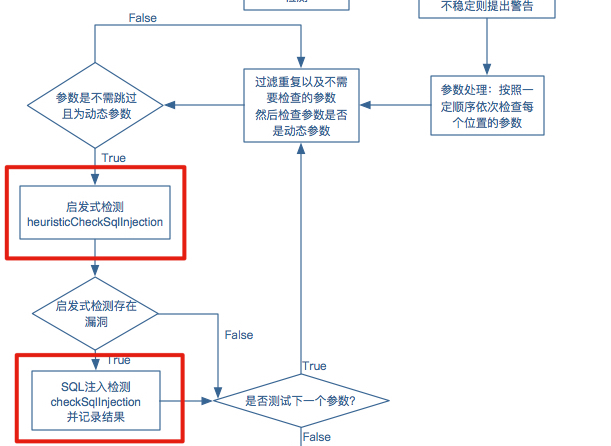
这标红的两个步骤其实就是本篇文章主要需要分析的两个部分,涉及到 sqlmap 检测 sql 注入漏洞的核心逻辑。其中 heuristicCheckSqlInjection 是我们本节需要分析的问题。这个函数的执行位置如下:
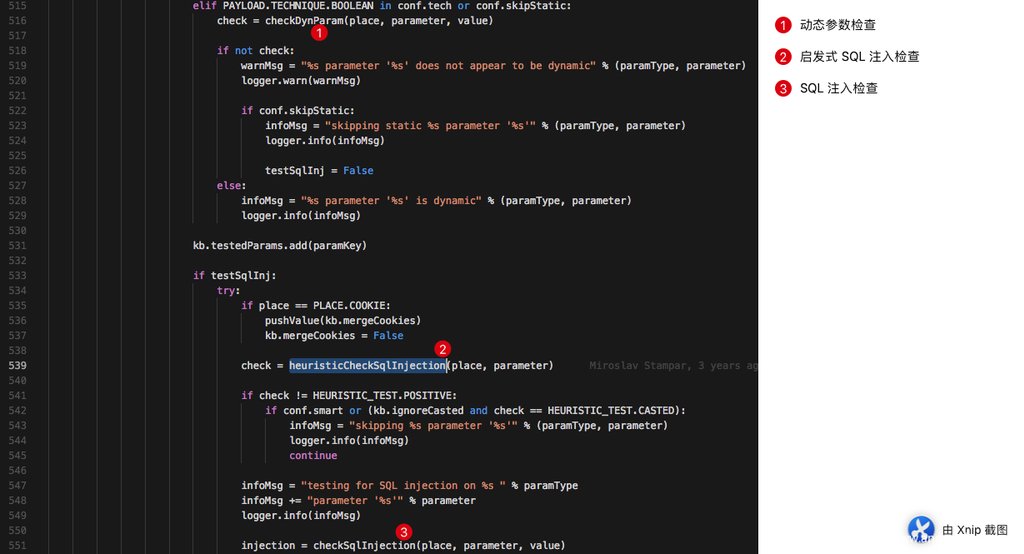
再上图代码中,2标号为其位置。
启发式 sql 注入检测整体逻辑
通过分析其源代码,笔者先行整理出他的逻辑:
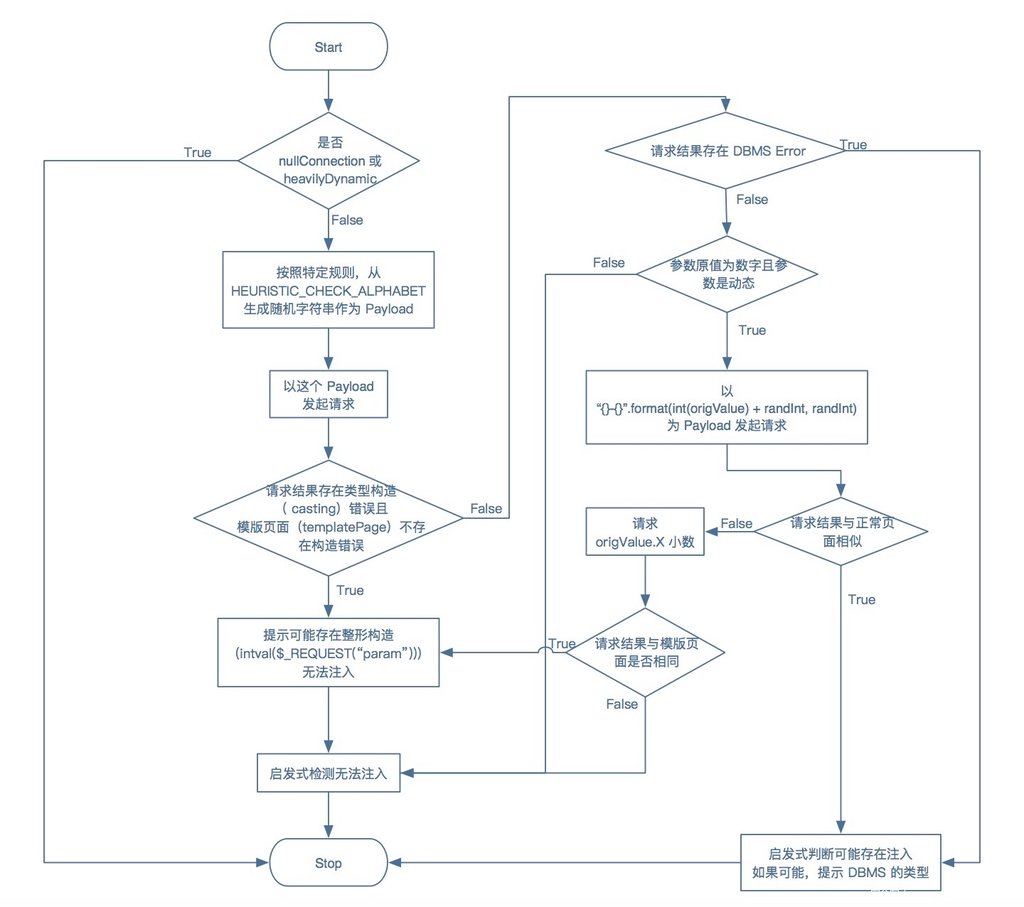
根据我们整理出的启发式检测流程图,我们做如下补充说明。
- 进行启发式 sql 注入检测的前提条件是没有开启 nullConnection 并且页面并不是 heavilyDynamic。关于这两个属性,我们在第二篇文章中都有相关介绍,对于 nullConnection 指的是一种不需要知道他的具体内容就可以知道整个内容大小的请求方法;heavilyDynamic 指的是,在不改变任何参数的情况下,请求两次页面,两次页面的相似度低于 0.98。
- 在实际的代码中,决定注入的结果报告的,主要在于两个标识位,分别为:casting 与 result。笔者在下方做代码批注和说明:
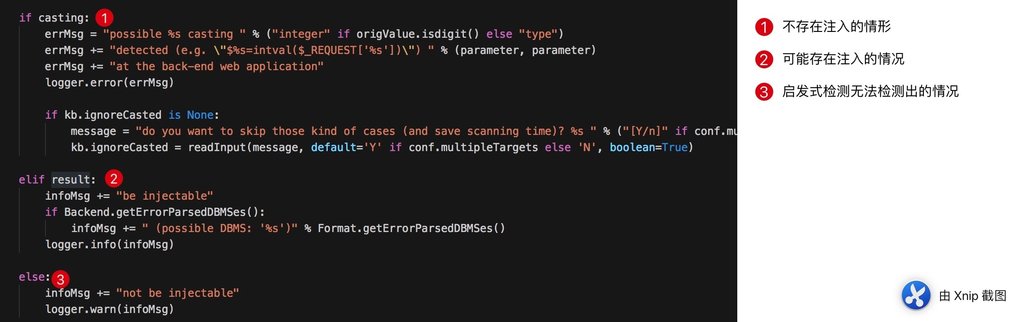
- casting 这个标识位主要取决于两种情况:第一种在第一个请求就发现存在了特定的类型检查的迹象;第二种是在请求小数情况的时候,发现小数被强行转换为整数。通常对于这种问题,在不考虑 tamper 的情况下,一般很难检测出或者绕过。
- result 这个标识位取决于:如果检测出 DBMS 错误,则会设置这个标识位为 True;如果出现了数据库执行数值运算,也置为 True。
XSS 与 FI
实际上在启发式 sql 注入检测完毕之后,会执行其他的检测:
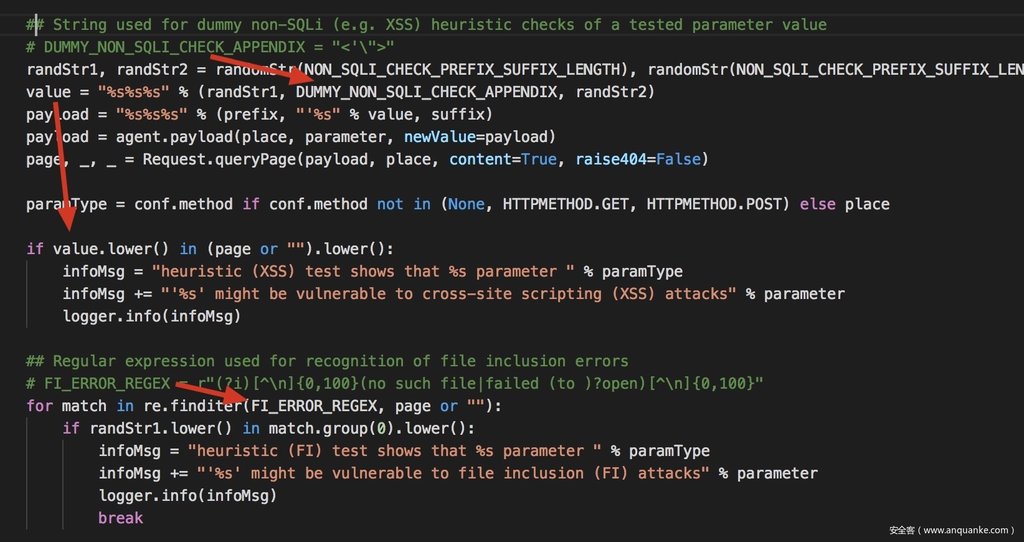
- 检测 XSS 的方法其实就是检查 “<‘\”>”,是否出现在了结果中。作为扩展,我们可以在此检查是否随机字符串还在页面中,从而判断是否存在 XSS 的迹象。
- 检测 FI(文件包含),就是检测结果中是否包含了 include/require 等报错信息,这些信息是通过特定正则表达式来匹配检测的。
0x02 checkSqlInjection
这个函数可以说是 sqlmap 中最核心的函数了。在这个函数中,处理了 Payload 的各种细节和测试用例的各种细节。
大致执行步骤分为如下几个大部分:
- 根据已知参数类型筛选 boundary
- 启发式检测数据库类型 heuristicCheckDbms
- payload 预处理(UNION)
- 过滤与排除不合适的测试用例
- 对筛选出的边界进行遍历与 payload 整合
- payload 渲染
- 针对四种类型的注入分别进行 response 的响应和处理
- 得出结果,返回结果
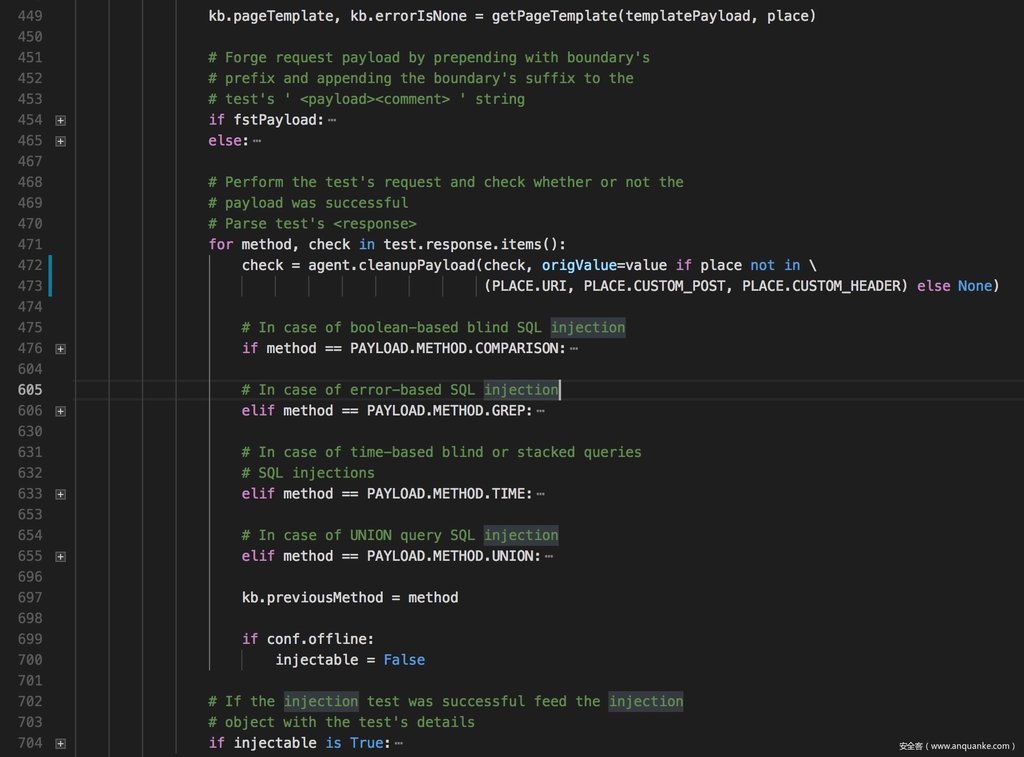
下图是笔者折叠无关代码之后剩余的最核心的循环和条件分支,我们发现他关于 injectable 的设置完全是通过 if method == PAYLOAD.METHOD.[COMPARISON/GREP/TIME/UNION] 这几个条件分支去处理的,同时这些条件显然是 sqlmap 针对不同的注入类型的 Payload 进行自己的结果处理逻辑饿和判断逻辑。
数据库类型检测 heuristicCheckDbms
我们在本大节刚开始的时候,就已经说明了第二步是确定数据库的类型,那么数据库类型来源于用户设定或者自动检测,当截止第二步之前还没有办法确定数据库类型的时候,就会自动启动 heuristicCheckDbms 这个函数,利用一些简单的测试来确定数据库类型。
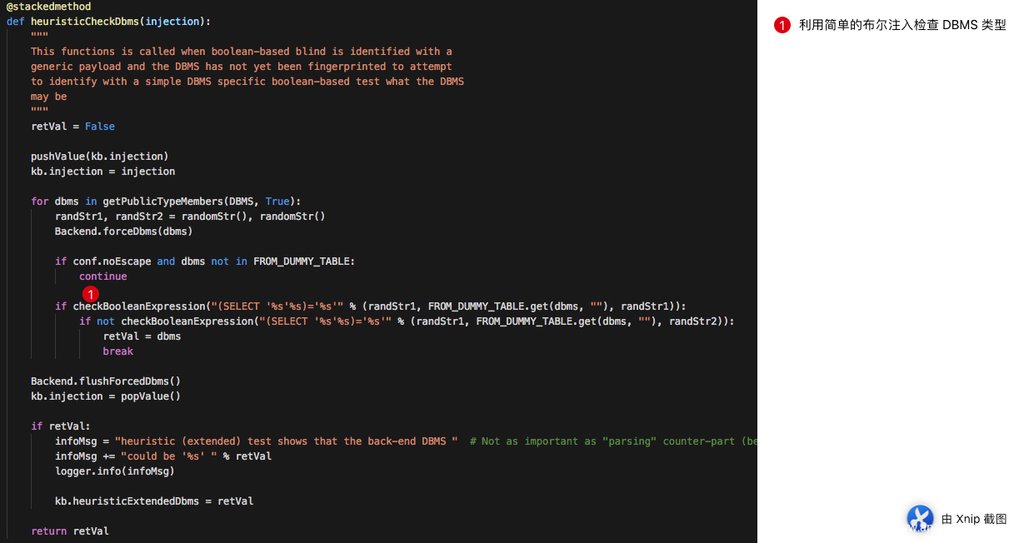
其实这个步骤非常简单,核心原理是利用简单的布尔盲注构造一个 (SELECT “[RANDSTR]” [FROM_DUMMY_TABLE.get(dbms)] )=”[RANDSTR1]” 和 (SELECT ‘[RANDSTR]’ [FROM_DUMMY_TABLE.get(dbms)] )='[RANDSTR1]’ 这两个 Payload 的请求判断。其中
FROM_DUMMY_TABLE = {
DBMS.ORACLE: " FROM DUAL",
DBMS.ACCESS: " FROM MSysAccessObjects",
DBMS.FIREBIRD: " FROM RDB$DATABASE",
DBMS.MAXDB: " FROM VERSIONS",
DBMS.DB2: " FROM SYSIBM.SYSDUMMY1",
DBMS.HSQLDB: " FROM INFORMATION_SCHEMA.SYSTEM_USERS",
DBMS.INFORMIX: " FROM SYSMASTER:SYSDUAL"
}例如,检查是否是 ORACLE 的时候,就会生成
(SELECT 'abc' FROM DUAL)='abc'
(SELECT 'abc' FROM DUAL)='abcd'这样的两个 Payload,如果确实存在正负关系(具体内容参见后续章节的布尔盲注检测),则表明数据库就是 ORACLE。
当然数据库类型检测并不是必须的,因为 sqlmap 实际工作中,如果没有指定 DBMS 则会按照当前测试 Payload 的对应的数据库类型去设置。
实际上在各种 Payload 的执行过程中,会包含着一些数据库的推断信息(<details>),如果 Payload 成功执行,这些信息可以被顺利推断则数据库类型就可以推断出来。
测试数据模型与 Payload 介绍
在实际的代码中,checkSqlInjection 是一个接近七百行的函数。当然其行为也并不是仅仅通过我们上面列出的步骤就可以完全概括的,其中涉及到了很多关于 Payload 定义中字段的操作。显然,直到现在我们都并不是特别了解一个 Payload 中存在着什么样的定义,当然也不会懂得这些操作对于这些字段到底有什么具体的意义。所以我们没有办法在不了解真正 Payload 的时候开始之后的步骤。
因此在本节中,我们会详细介绍关于具体测试 Payload 的数据模型,并且基于这些模型和源码分析 sqlmap 实际的行为,和 sql 注入原理的细节知识。 ·
<test> 通用模型
关于通用模型其实在 sqlmap 中有非常详细的说明,位置在 xml/payloads/boolean_blind.xml中,我们把他们分隔开分别来讲解具体字段对应的代码的行为。
首先我们必须明白一个具体的 testcase 对应一个具体的 xml 元素是什么样子:
<test>
<title></title>
<stype></stype>
<level></level>
<risk></risk>
<clause></clause>
<where></where>
<vector></vector>
<request>
<payload></payload>
<comment></comment>
<char></char>
<columns></columns>
</request>
<response>
<comparison></comparison>
<grep></grep>
<time></time>
<union></union>
</response>
<details>
<dbms></dbms>
<dbms_version></dbms_version>
<os></os>
</details>
</test>关于上面的一个 <test> 标签内的元素都是实际上包含的不只是一个 Payload 还包含
Sub-tag: <title>
Title of the test. 测试的名称,这些名称就是我们实际在测试的时候输出的日志中的内容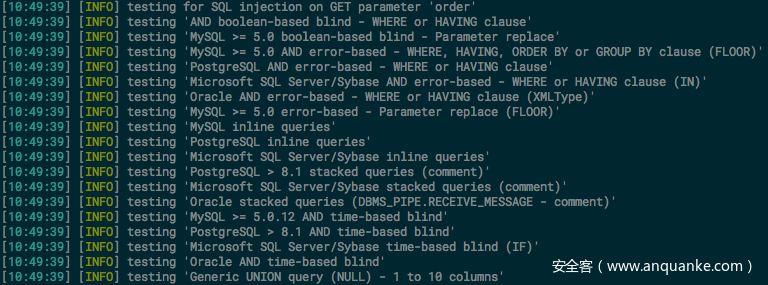
上图表示一个 <test> 中的 title 会被输出作为调试信息。
除非必要的子标签,笔者将会直接把标注写在下面的代码块中,
Sub-tag: <stype>
SQL injection family type. 表示注入的类型。
Valid values:
1: Boolean-based blind SQL injection
2: Error-based queries SQL injection
3: Inline queries SQL injection
4: Stacked queries SQL injection
5: Time-based blind SQL injection
6: UNION query SQL injection
Sub-tag: <level>
From which level check for this test. 测试的级别
Valid values:
1: Always (<100 requests)
2: Try a bit harder (100-200 requests)
3: Good number of requests (200-500 requests)
4: Extensive test (500-1000 requests)
5: You have plenty of time (>1000 requests)
Sub-tag: <risk>
Likelihood of a payload to damage the data integrity.这个选项表明对目标数据库的损坏程度,risk 最高三级,最高等级代表对数据库可能会有危险的•操作,比如修改一些数据,插入一些数据甚至删除一些数据。
Valid values:
1: Low risk
2: Medium risk
3: High risk
Sub-tag: <clause>
In which clause the payload can work. 这个字段表明 <test> 对应的测试 Payload 适用于哪种类型的 SQL 语句。一般来说,很多语句并不一定非要特定 WHERE 位置的。
NOTE: for instance, there are some payload that do not have to be
tested as soon as it has been identified whether or not the
injection is within a WHERE clause condition.
Valid values:
0: Always
1: WHERE / HAVING
2: GROUP BY
3: ORDER BY
4: LIMIT
5: OFFSET
6: TOP
7: Table name
8: Column name
9: Pre-WHERE (non-query)
A comma separated list of these values is also possible.在上面几个子标签中,我们经常见的就是 level/risk 一般来说,默认的 sqlmap 配置跑不出漏洞的时候,我们通常会启动更高级别 (level=5/risk=3) 的配置项来启动更多的 payload。
接下来我们再分析下面的标签
Sub-tag: <where>
Where to add our '<prefix> <payload><comment> <suffix>' string.
Valid values:
1: Append the string to the parameter original value
2: Replace the parameter original value with a negative random
integer value and append our string
3: Replace the parameter original value with our string
Sub-tag: <vector>
The payload that will be used to exploit the injection point.
这个标签只是大致说明 Payload 长什么样子,其实实际请求的 Payload 或者变形之前的 Payload 可能并不是这个 Payload,以 request 子标签中的 payload 为准。
Sub-tag: <request>
What to inject for this test.
关于发起请求的设置与配置。在这些配置中,有一些是特有的,但是有一些是必须的,例如 payload 是肯定存在的,但是 comment 是不一定有的,char 和 columns 是只有 UNION 才存在
Sub-tag: <payload>
The payload to test for. 实际测试使用的 Payload
Sub-tag: <comment>
Comment to append to the payload, before the suffix.
Sub-tag: <char> 只有 UNION 注入存在的字段
Character to use to bruteforce number of columns in UNION
query SQL injection tests.
Sub-tag: <columns> 只有 UNION 注入存在的字段
Range of columns to test for in UNION query SQL injection
tests.
Sub-tag: <response>
How to identify if the injected payload succeeded.
由于 payload 的目的不一定是相同的,所以,实际上处理请求的方法也并不是相同的,具体的处理方法步骤,在我们后续的章节中有详细的分析。
Sub-tag: <comparison>
针对布尔盲注的特有字段,表示对比和 request 中请求的结果。
Perform a request with this string as the payload and compare
the response with the <payload> response. Apply the comparison
algorithm.
NOTE: useful to test for boolean-based blind SQL injections.
Sub-tag: <grep>
针对报错型注入的特有字段,使用正则表达式去匹配结果。
Regular expression to grep for in the response body.
NOTE: useful to test for error-based SQL injection.
Sub-tag: <time>
针对时间盲注
Time in seconds to wait before the response is returned.
NOTE: useful to test for time-based blind and stacked queries
SQL injections.
Sub-tag: <union>
处理 UNION •注入的办法。
Calls unionTest() function.
NOTE: useful to test for UNION query (inband) SQL injection.
Sub-tag: <details>
Which details can be infered if the payload succeed.
如果 response 标签中的检测结果成功了,可以推断出什么结论?
Sub-tags: <dbms>
What is the database management system (e.g. MySQL).
Sub-tags: <dbms_version>
What is the database management system version (e.g. 5.0.51).
Sub-tags: <os>
What is the database management system underlying operating
system.在初步了解了基本的 Payload 测试数据模型之后,我们接下来进行详细的检测逻辑的细节分析,因为篇幅的原因,我们暂且只针对布尔盲注和时间盲注进行分析,
真正的 Payload
我们在前面的介绍中发现了几个疑似 Payload 的字段,但是遗憾的是,上面的每一个 Payload 都不是真正的 Payload。实际 sqlmap 在处理的过程中,只要是从 *.xml 中加载的 Payload,都是需要经过一些随机化和预处理,这些预处理涉及到的概念如下:
- Boundary:需要为原始 Payload 的前后添加“边界”。边界是一个神奇的东西,主要取决于当前“拼接”的 SQL 语句的上下文,常见上下文:注入位置是一个“整形”;注入位置需要单引号/双引号(‘/”)闭合边界;注入位置在一个括号语句中。
- –tamper:Tamper 是 sqlmap 中最重要的概念之一,也是 Bypass 各种防火墙的有力的武器。在 sqlmap 中,Tamper 的处理位于我们上一篇文章中的 agent.queryPage() 中,具体位于其对 Payload 的处理。
- “Render”:当然这一个步骤在 sqlmap 中没有明显的概念进行对应,其主要是针对 Payload 中随机化的标签进行渲染和替换,例如:[INFERENCE] 这个标签通常被替换成一个等式,这个等式用于判断结果的正负`Positive/Negative`
[RANDSTR] 会被替换成随机字符串
[RANDNUM] 与 [RANDNUMn] •会被替换成不同的数字
[SLEEPTIME] 在时间盲注中会被替换为 SLEEP 的时间
所以,实际上从 *.xml 中加载出来的 Payload 需要经过上面的处理才能真的算是处理完成。这个 Payload 才会在 agent.queryPage 的日志中输出出来,也就是我们 sqlmap -v3 选项看到的最终 Payload。
在上面的介绍中,我们又提到了一个陌生的概念,Boundary,并且做了相对简单的介绍,具体的 Boundary,我们在 {sqlmap_dir}/xml/boundaries.xml 中可以找到:
<boundary>
<level></level>
<clause></clause>
<where></where>
<ptype></ptype>
<prefix></prefix>
<suffix></suffix>
</boundary>在具体的定义中,我们发现没见过的子标签如下:
Sub-tag: <ptype>
What is the parameter value type. 参数•类型(参数边界上下文类型)
Valid values:
1: Unescaped numeric
2: Single quoted string
3: LIKE single quoted string
4: Double quoted string
5: LIKE double quoted string
Sub-tag: <prefix>
A string to prepend to the payload.
Sub-tag: <suffix>
A string to append to the payload.其实到现在 sqlmap 中 Payload 的结构我们就非常清楚了
<prefix> <payload><comment> <suffix>其中 <prefix> <suffix> 来源于 boundaries.xml 中,而 <payload> <comment> 来源于本身 xml/payloads/*.xml 中的 <test> 中。在本节中都有非常详细的描述了
针对布尔盲注的检测
在接下来的小节中,我们将会针对几种注入进行详细分析,我们的分析依据主要是 sqlmap 设定的 Payload 的数据模型和其本身的代码。本节先针对布尔盲注进行一些详细分析。
在分析之前,我们先看一个详细的 Payload:
<test>
<title>PostgreSQL OR boolean-based blind - WHERE or HAVING clause (CAST)</title>
<stype>1</stype>
<level>3</level>
<risk>3</risk>
<clause>1</clause>
<where>2</where>
<vector>OR (SELECT (CASE WHEN ([INFERENCE]) THEN NULL ELSE CAST('[RANDSTR]' AS NUMERIC) END)) IS NULL</vector>
<request>
<payload>OR (SELECT (CASE WHEN ([RANDNUM]=[RANDNUM]) THEN NULL ELSE CAST('[RANDSTR]' AS NUMERIC) END)) IS NULL</payload>
</request>
<response>
<comparison>OR (SELECT (CASE WHEN ([RANDNUM]=[RANDNUM1]) THEN NULL ELSE CAST('[RANDSTR]' AS NUMERIC) END)) IS NULL</comparison>
</response>
<details>
<dbms>PostgreSQL</dbms>
</details>
</test>根据上一节介绍的子标签的特性,我们可以大致观察这个 <test> 会至少发送两个 Payload:第一个为 request 标签中的 payload 第二个为 response 标签中的 comparison 中的 Payload。
当然我们很容易想到,针对布尔盲注的检测实际上只需要检测 request.payload 和 response.comparison 这两个请求,只要这两个请求页面不相同,就可以判定是存在问题的。可是事实真的如此吗?结果当然并没有这么简单。
我们首先定义 request.payload 中的的请求为正请求 Positive,对应 response.comparison中的请求为负请求 Negative,在 sqlmap 中原处理如下:
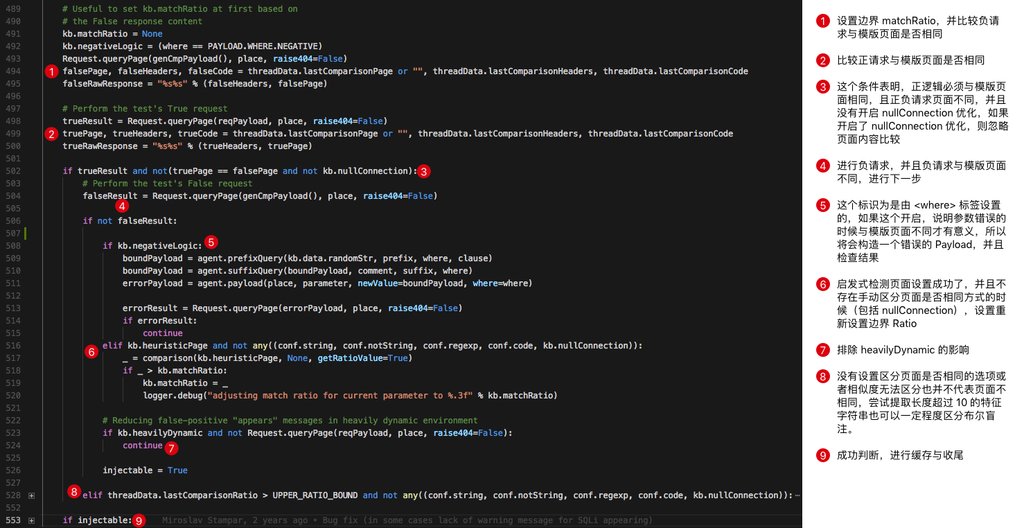
在代码批注中我们进行详细的解释,为了让大家看得更清楚,我们把代码转变为流程图:
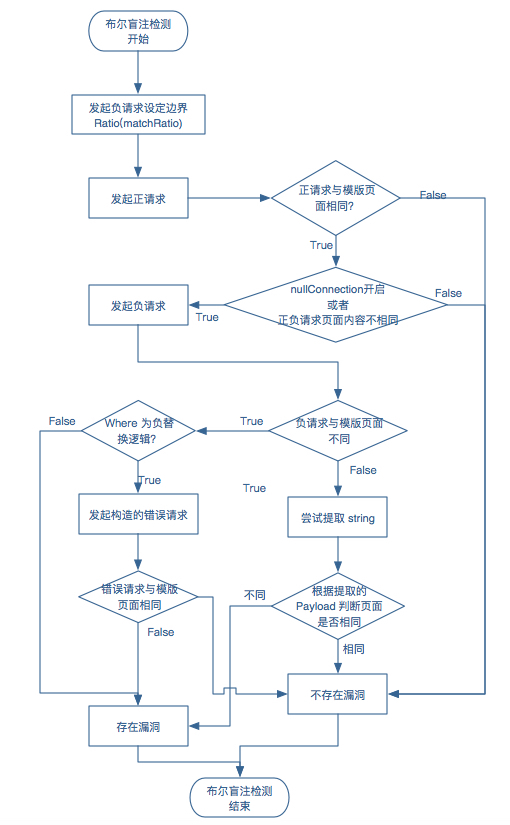
其中最容易被遗忘的可能并不是正负请求的对比,而是正请求与模版页面的对比,负请求与错误请求的对比和错误请求与模版页面的对比,因为广泛存在一种情况是类似文件包含模式的情况,不同的合理输入的结果有大概率不相同,且每一次输入的结果如果报错都会跳转到某一个默认页面(存在默认参数),这种情况仅仅用正负请求来区分页面不同是完全不够用的,还需要各种情形与模版页面的比较来确定。
针对 GREP 型(报错注入)
针对报错注入其实非常好识别,在报错注入检测的过程中,我们会发现他的 response 子标签中,包含着是 grep 子标签:
<test>
<title>MySQL >= 5.7.8 AND error-based - WHERE, HAVING, ORDER BY or GROUP BY clause (JSON_KEYS)</title>
<stype>2</stype>
<level>5</level>
<risk>1</risk>
<clause>1,2,3,9</clause>
<where>1</where>
<vector>AND JSON_KEYS((SELECT CONVERT((SELECT CONCAT('[DELIMITER_START]',([QUERY]),'[DELIMITER_STOP]')) USING utf8)))</vector>
<request>
<payload>AND JSON_KEYS((SELECT CONVERT((SELECT CONCAT('[DELIMITER_START]',(SELECT (ELT([RANDNUM]=[RANDNUM],1))),'[DELIMITER_STOP]')) USING utf8)))</payload>
</request>
<response>
<grep>[DELIMITER_START](?P<result>.*?)[DELIMITER_STOP]</grep>
</response>
<details>
<dbms>MySQL</dbms>
<dbms_version>>= 5.7.8</dbms_version>
</details>
</test>我们发现子标签 grep 中是正则表达式,可以直接从整个请求中通过 grep 中的正则提取出对应的内容,如果成功提取出了对应内容,则说明该参数可以进行注入。
在具体代码中,其实非常直观可以看到:
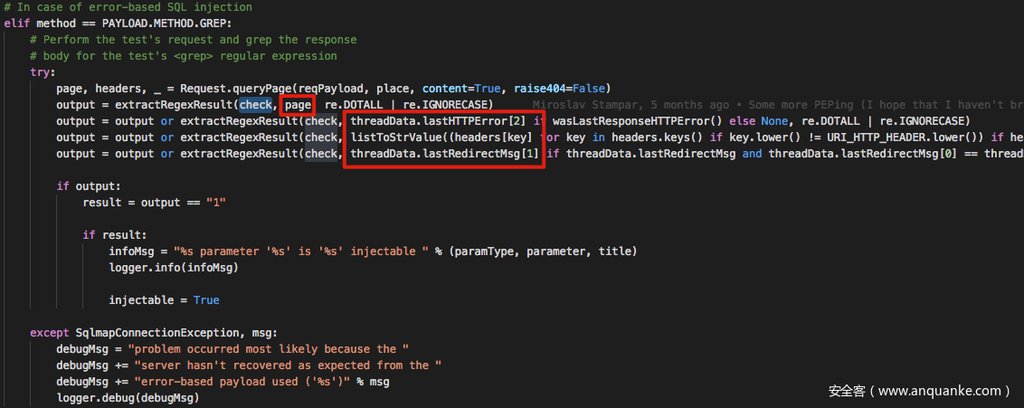
再 sqlmap 的实现中其实并不是仅仅检查页面内容就足够的,除了页面内容之外,检查如下项:
- HTTP 的错误页面
- Headers 中的内容
- 重定向信息
针对 TIME 型(时间盲注,HeavilyQuery)
当然时间盲注我们可以很容易猜到应该怎么处理:如果发出了请求导致延迟了 X 秒,并且响应延迟的时间是我们预期的时间,那么就可以判定这个参数是一个时间注入点。
但是仅仅是这样就可以了嘛?当然我们需要了解的是 sqlmap 如何设置这个 X 作为时间点(请看下面这个函数,位于 agent.queryPage 中):
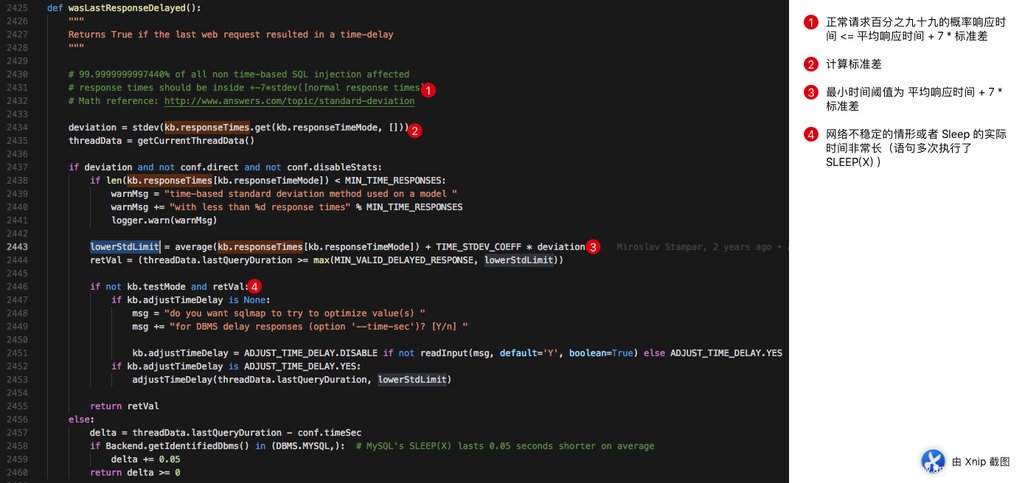
我们发现,它里面有一个数学概念:标准差
简单来说,标准差是一组数值自平均值分散开来的程度的一种测量观念。一个较大的标准差,代表大部分的数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。例如,两组数的集合{0, 5, 9, 14}和{5, 6, 8, 9}其平均值都是7,但第二个集合具有较小的标准差。述“相差k个标准差”,即在 X̄ ± kS 的样本(Sample)范围内考量。标准差可以当作不确定性的一种测量。例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。
根据注释和批注中的解释,我们发现我们需要设定一个最小 SLEEPTIME 应该至少大于 样本内平均响应时间 + 7 * 样本标准差,这样就可以保证过滤掉 99.99% 的无延迟请求。
当然除了这一点,我们还发现
delta = threadData.lastQueryDuration - conf.timeSec
if Backend.getIdentifiedDbms() in (DBMS.MYSQL,): # MySQL's SLEEP(X) lasts 0.05 seconds shorter on average
delta += 0.05
return delta >= 0这一段代码作为 mysql 的 Patch 存在 # MySQL’s SLEEP(X) lasts 0.05 seconds shorter on average。
如果我们要自己实现时间盲注的检测的话,这一点也是必须注意和实现的。
针对 UNION 型(UNION Query)
UNION 注入可以说是 sqlmap 中最复杂的了,同时也是最经典的注入情形。
其实关于 UNION 注入的检测,和我们一开始学习 SQL 注入的方法是一样的,猜解列数,猜解输出点在列中位置。实际在 sqlmap 中也是按照这个来进行漏洞检测的,具体的测试方法位于:
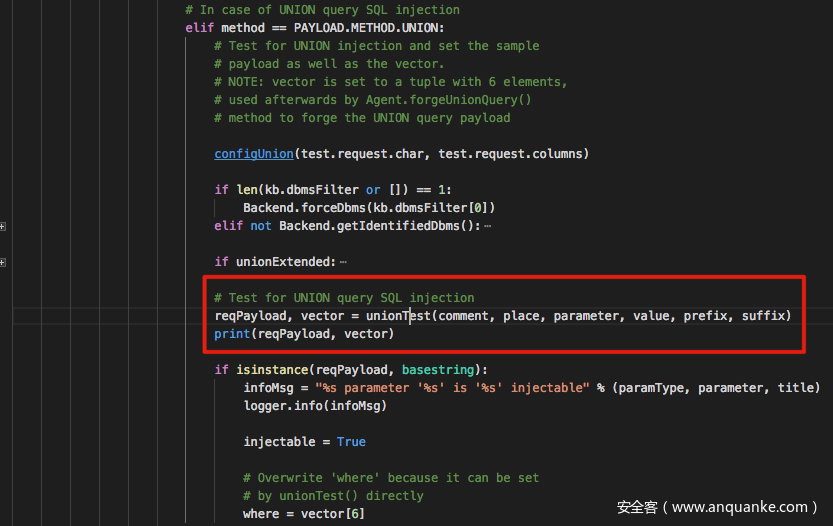
跟入 unionTest() 中我们发现如下操作
def unionTest(comment, place, parameter, value, prefix, suffix):
"""
This method tests if the target URL is affected by an union
SQL injection vulnerability. The test is done up to 3*50 times
"""
if conf.direct:
return
kb.technique = PAYLOAD.TECHNIQUE.UNION
validPayload, vector = _unionTestByCharBruteforce(comment, place, parameter, value, prefix, suffix)
if validPayload:
validPayload = agent.removePayloadDelimiters(validPayload)
return validPayload, vector最核心的逻辑位于 _unionTestByCharBruteforce 中,继续跟入,我们发现其检测的大致逻辑如下:
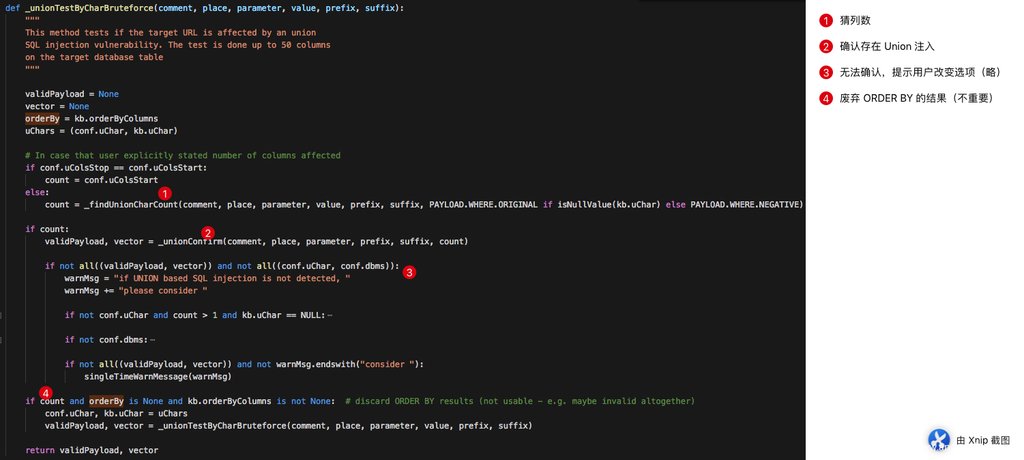
别急,我们一步一步来分析!
猜列数
我相信做过渗透测试的读者基本对这个词都非常非常熟悉,如果有疑问或者不清楚的请自行百度,笔者再次不再赘述关于 SQL 注入基本流程的部分。
为什么要把一件这么简单的事情单独拿出来说呢?当然这预示着 sqlmap 并不是非常简单的在处理这一件事情,因为作为一个渗透测试人员,当然可以很容易靠肉眼分辨出很多事情,但是这些事情在计算机看来却并不是那么容易可以判断的:
- 使用 ORDER BY 查询,直接通过与模版页面的比较来获取列数。
- 当 ORDER BY 失效的时候,使用多次 UNION SELECT 不同列数,获取多个 Ratio,通过区分 Ratio 来区分哪一个是正确的列数。
实际在使用的过程中,ORDER BY 的核心逻辑如下,关于其中页面比较技术我们就不赘述了,不过值得一提的是 sqlmap 在猜列数的时候,使用的是二分法(笔者看了一下,二分法这部分这似乎是七年前的代码)。
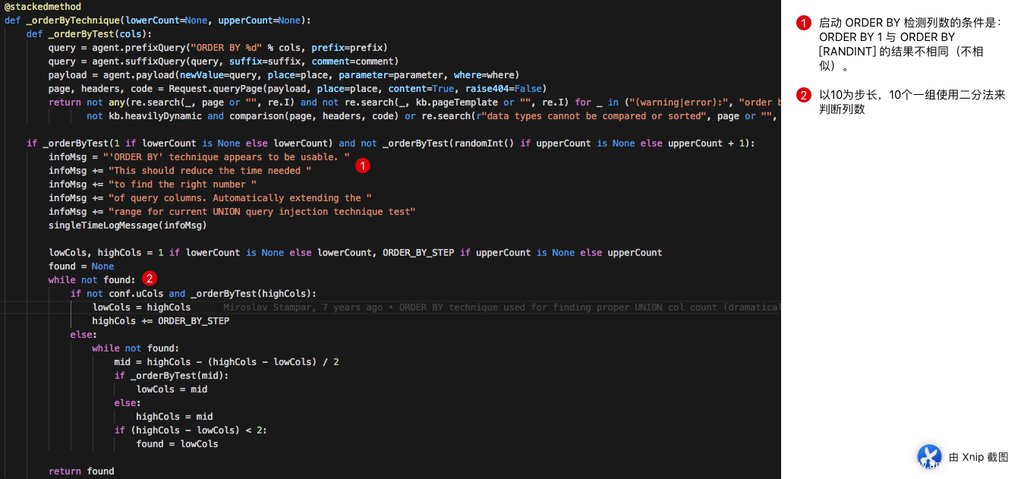
除此之外呢,如果 ORDER BY 失效,将会计算至少五个(从 lowerCount 到 upperCount)Payload 为 UNION SELECT (NULL,) * [COUNT],的请求,这些请求的对应 RATIO(与模版页面相似度)会汇总存储在 ratios 中,同时 items 中存储 列数 和 ratio 形成的 tuple,经过一系列的算法,尽可能寻找出“与众不同(正确猜到列数)”的页面。具体的算法与批注如下:
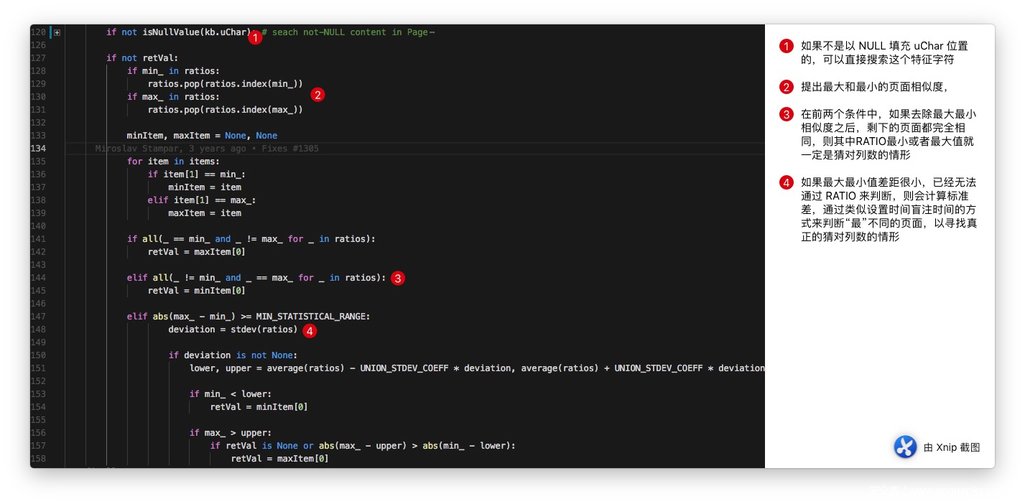
我们发现,上面代码表达的核心思想就是 利用与模版页面比较的内容相似度寻找最最不同的那一个请求。
定位输出点
假如一切顺利,我们通过上面的步骤成功找到了列数,接下来就应该寻找输出点,当然输出点的寻找也是需要额外讨论的。其实基本逻辑很容易对不对?我们只需要将 UNION SELECT NULL, NULL, NULL, NULL, … 中的各种 NULL 依次替换,然后在结果中寻找被我们插入的随机的字符串,就可以很容易定位到输入出点的位置。实际上这一部分的确认逻辑是位于下图中的函数的 _unionConfirm
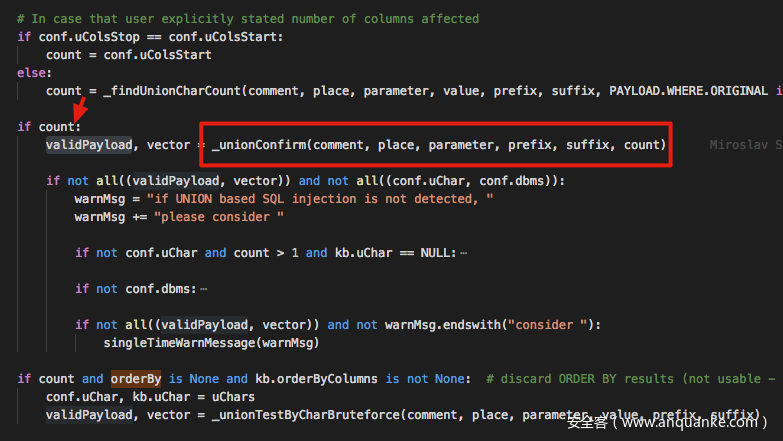
其中主要的逻辑是一个叫 _unionPosition 的函数,在这个函数中,负责定位输出点的位置,使用的基本方法就是我们在开头提到方法,受限于篇幅,我们就不再展开叙述了。
0x03 结束语
其实按笔者原计划,本系列文章并没有结束,因为还有关于 sqlmap 中其他技术没有介绍:“数据持久化”,“action() – Exploit 技术”,“常见漏洞利用分析(udf,反弹 shell 等)”。但是由于内容是在太过庞杂,笔者计划暂且搁置一下,实际上现有的文章已经足够把 sqlmap 的 SQL 注入检测最核心的也是最有意义的自动化逻辑说清楚了,我想读读者读完之后肯定会有自己的收获。