
作者:LoRexxar’@知道创宇404实验室
前言
自从人类发明了工具开始,人类就在不断为探索如何更方便快捷的做任何事情,在科技发展的过程中,人类不断地试错,不断地思考,于是才有了现代伟大的科技时代。在安全领域里,每个安全研究人员在研究的过程中,也同样的不断地探索着如何能够自动化的解决各个领域的安全问题。其中自动化代码审计就是安全自动化绕不过去的坎。
这一次我们就一起聊聊自动化代码审计的发展史,也顺便聊聊如何完成一个自动化静态代码审计的关键。
自动化代码审计
在聊自动化代码审计工具之前,首先我们必须要清楚两个概念,漏报率和误报率。
- 漏报率是指没有发现的漏洞/Bug
- 误报率是指发现了错误的漏洞/Bug
在评价下面的所有自动化代码审计工具/思路/概念时,所有的评价标准都离不开这两个词,如何消除这两点或是其中之一也正是自动化代码审计发展的关键点。
我们可以简单的把自动化代码审计(这里我们讨论的是白盒)分为两类,一类是动态代码审计工具,另一类是静态代码审计工具。
动态代码审计的特点与局限
动态代码审计工具的原理主要是基于在代码运行的过程中进行处理并挖掘漏洞。我们一般称之为IAST(interactive Application Security Testing)。
其中最常见的方式就是通过某种方式Hook恶意函数或是底层api并通过前端爬虫判别是否触发恶意函数来确认漏洞。
我们可以通过一个简单的流程图来理解这个过程。
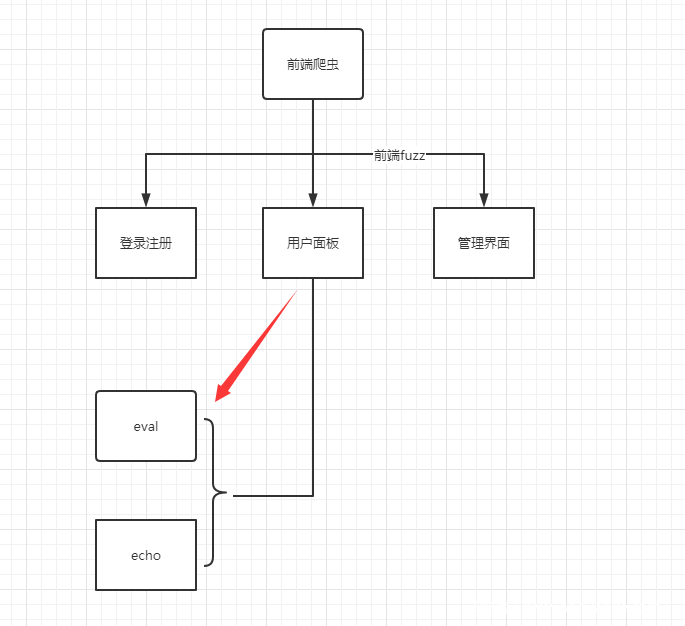
在前端Fuzz的过程中,如果Hook函数被触发,并满足某种条件,那么我们认为该漏洞存在。
这类扫描工具的优势在于,通过这类工具发现的漏洞误报率比较低,且不依赖代码,一般来说,只要策略足够完善,能够触发到相应恶意函数的操作都会相应的满足某种恶意操作。而且可以跟踪动态调用也是这种方法最主要的优势之一。
但随之而来的问题也逐渐暴露出来:
(1) 前端Fuzz爬虫可以保证对正常功能的覆盖率,却很难保证对代码功能的覆盖率。
如果曾使用动态代码审计工具对大量的代码扫描,不难发现,这类工具针对漏洞的扫描结果并不会比纯黑盒的漏洞扫描工具有什么优势,其中最大的问题主要集中在功能的覆盖度上。
一般来说,你很难保证开发完成的所有代码都是为网站的功能服务的,也许是在版本迭代的过程中不断地冗余代码被遗留下来,也有可能是开发人员根本没有意识到他们写下的代码并不只是会按照预想的样子执行下去。有太多的漏洞都无法直接的从前台的功能处被发现,有些甚至可能需要满足特定的环境、特定的请求才能触发。这样一来,代码的覆盖率得不到保证,又怎么保证能发现漏洞呢?
(2) 动态代码审计对底层以及hook策略依赖较强
由于动态代码审计的漏洞判别主要依赖Hook恶意函数,那么对于不同的语言、不同的平台来说,动态代码审计往往要针对设计不同的hook方案。如果Hook的深度不够,一个深度框架可能就无法扫描了。
拿PHP举例子来说,比较成熟的Hook方案就是通过PHP插件实现,具体的实现方案可以参考。
由于这个原因影响,一般的动态代码审计很少可以同时扫描多种语言,一般来说都是针对某一种语言。
其次,Hook的策略也需要许多不同的限制以及处理。就拿PHP的XSS来举例子,并不是说一个请求触发了echo函数就应该判别为XSS。同样的,为了不影响正常功能,并不是echo函数参数中包含<script>就可以算XSS漏洞。在动态代码审计的策略中,需要有更合理的前端->Hook策略判别方案,否则会出现大量的误报。
除了前面的问题以外,对环境的强依赖、对执行效率的需求、难以和业务代码结合的各种问题也确切的存在着。当动态代码审计的弊端不断被暴露出来后,从笔者的角度来看,动态代码审计存在着原理本身与问题的冲突,所以在自动化工具的发展过程中,越来越多的目光都放回了静态代码审计上(SAST).
静态代码审计工具的发展
静态代码审计主要是通过分析目标代码,通过纯静态的手段进行分析处理,并挖掘相应的漏洞/Bug.
与动态不同,静态代码审计工具经历了长期的发展与演变过程,下面我们就一起回顾一下(下面的每个时期主要代表的相对的发展期,并不是比较绝对的诞生前后):
上古时期 – 关键字匹配
如果我问你“如果让你设计一个自动化代码审计工具,你会怎么设计?”,我相信,你一定会回答我,可以尝试通过匹配关键字。紧接着你也会迅速意识到通过关键字匹配的问题。
这里我们拿PHP做个简单的例子。

虽然我们匹配到了这个简单的漏洞,但是很快发现,事情并没有那么简单。

也许你说你可以通过简单的关键字重新匹配到这个问题。
\beval\(\$
但是可惜的是,作为安全研究员,你永远没办法知道开发人员是怎么写代码的。于是选择用关键字匹配的你面临着两种选择:
- 高覆盖性 – 宁错杀不放过
这类工具最经典的就是Seay,通过简单的关键字来匹配经可能多的目标,之后使用者可以通过人工审计的方式进一步确认。
\beval\b\(
- 高可用性 – 宁放过不错杀
这类工具最经典的是Rips免费版
\beval\b\(\$_(GET|POST)
用更多的正则来约束,用更多的规则来覆盖多种情况。这也是早期静态自动化代码审计工具普遍的实现方法。
但问题显而易见,高覆盖性和高可用性是这种实现方法永远无法解决的硬伤,不但维护成本巨大,而且误报率和漏报率也是居高不下。所以被时代所淘汰也是历史的必然。
近代时期 – 基于AST的代码分析
有人忽略问题,也有人解决问题。关键字匹配最大的问题是在于你永远没办法保证开发人员的习惯,你也就没办法通过任何制式的匹配来确认漏洞,那么基于AST的代码审计方式就诞生了,开发人员是不同的,但编译器是相同的。
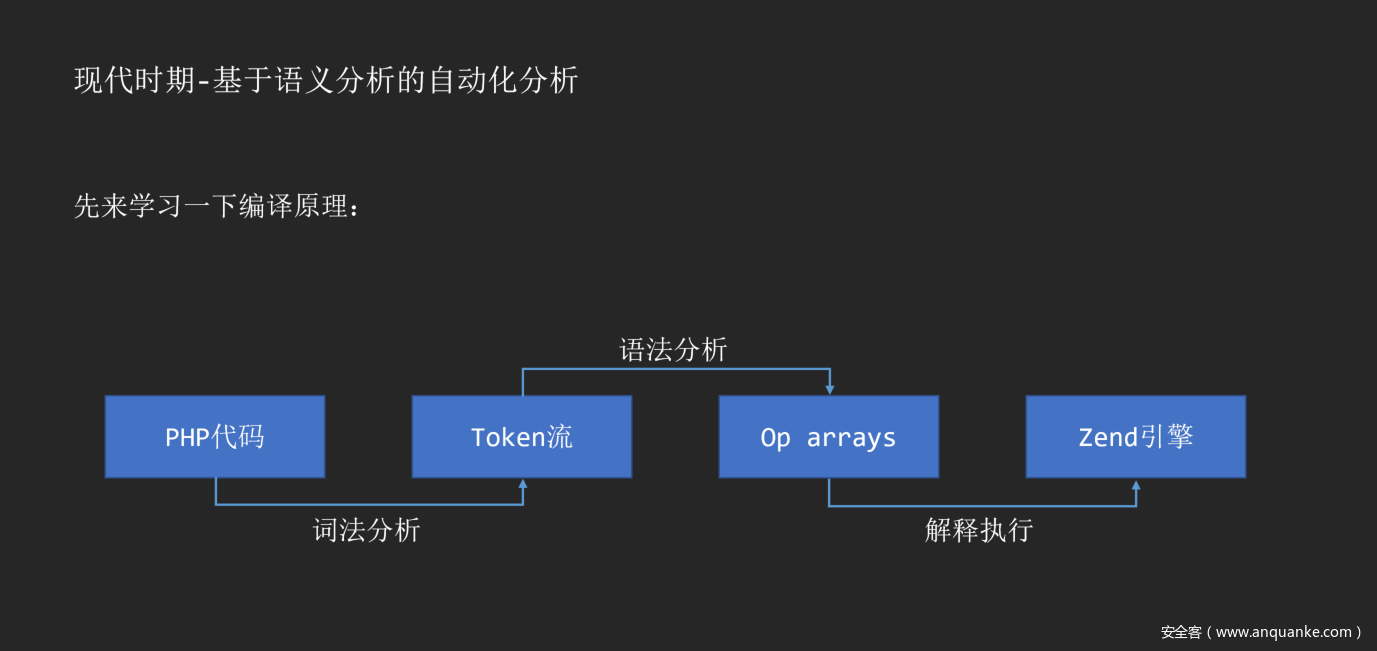
在分享这种原理之前,我们首先可以复现一下编译原理。拿PHP代码举例子:
随着PHP7的诞生,AST也作为PHP解释执行的中间层出现在了编译过程的一环。
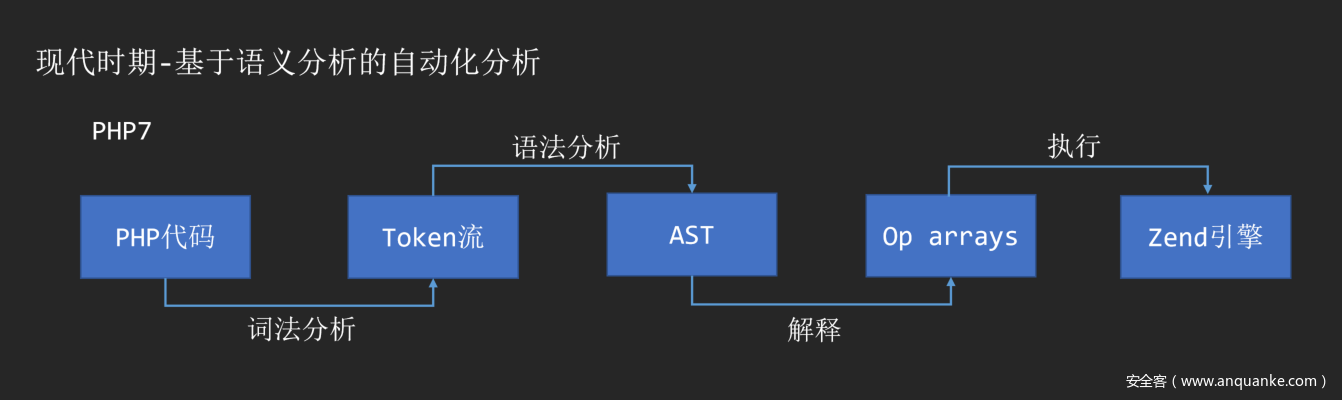
通过词法分析和语法分析,我们可以将任意一份代码转化为AST语法树。常见的语义分析库可以参考:
当我们得到了一份AST语法树之后,我们就解决了前面提到的关键字匹配最大的问题,至少我们现在对于不同的代码,都有了统一的AST语法树。如何对AST语法树做分析也就成了这类工具最大的问题。
在理解如何分析AST语法树之前,我们首先要明白information flow、source、sink三个概念,
- source: 我们可以简单的称之为输入,也就是information flow的起点
- sink: 我们可以称之为输出,也就是information flow的终点
而information flow,则是指数据在source到sink之间流动的过程。
把这个概念放在PHP代码审计过程中,Source就是指用户可控的输入,比如$_GET、$_POST等,而Sink就是指我们要找到的敏感函数,比如echo、eval,如果某一个Source到Sink存在一个完整的流,那么我们就可以认为存在一个可控的漏洞,这也就是基于information flow的代码审计原理。
在明白了基础原理的基础上,我举几个简单的例子:

在上面的分析过程中,Sink就是eval函数,source就是$_GET,通过逆向分析Sink的来源,我们成功找到了一条流向Sink的information flow,也就成功发现了这个漏洞。
ps: 当然也许会有人好奇为什么选择逆向分析流而不是正向分析流,这个问题会在后续的分析过程中不断渗透,慢慢就可以明白其关键点。
在分析information flow的过程中,明确作用域是基础中的基础.这也是分析information flow的关键,我们可以一起看看一段简单的代码

如果我们很简单的通过左右值去回溯,而没有考虑到函数定义的话,我们很容易将流定义为:
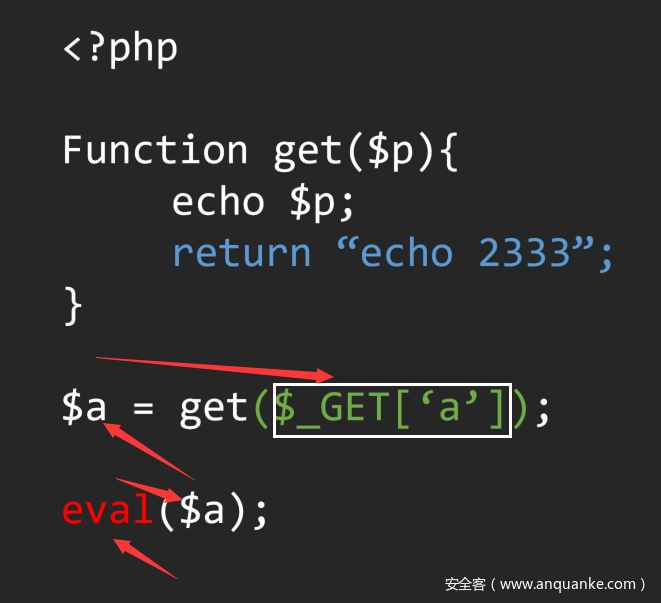
这样我们就错误的把这段代码定义成了存在漏洞,但很显然并不是,而正确的分析流程应该是这样的:
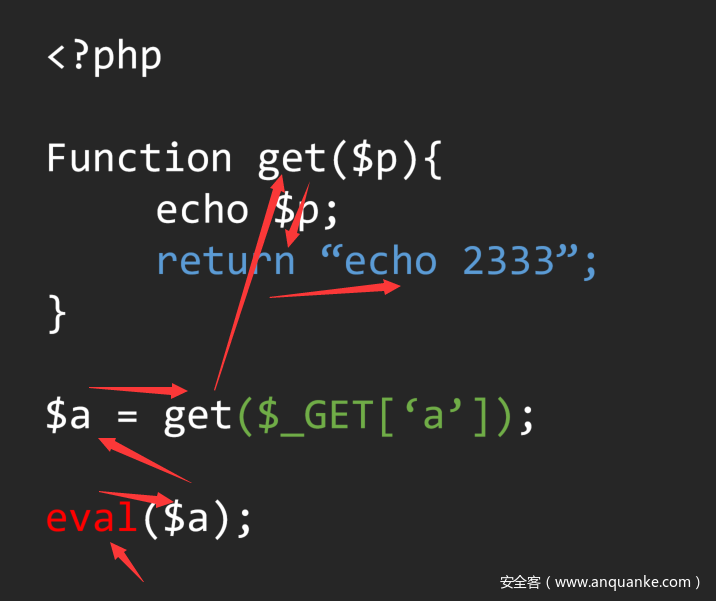
在这段代码中,从主语法树的作用域跟到Get函数的作用域,如何控制这个作用域的变动,就是基于AST语法树分析的一大难点,当我们在代码中不可避免的使用递归来控制作用域时,在多层递归中的统一标准也就成了分析的基础核心问题。
事实上,即便你做好了这个最简单的基础核心问题,你也会遇到层出不穷的问题。这里我举两个简单的例子
(1) 新函数封装

这是一段很经典的代码,敏感函数被封装成了新的敏感函数,参数是被二次传递的。为了解决,这样information flow的方向从逆向->正向的问题。

通过新建大作用域来控制作用域。
(2) 多重调用链

这是一段有漏洞的JS代码,人工的话很容易看出来问题。但是如果通过自动化的方式回溯参数的话就会发现整个流程中涉及到了多种流向。
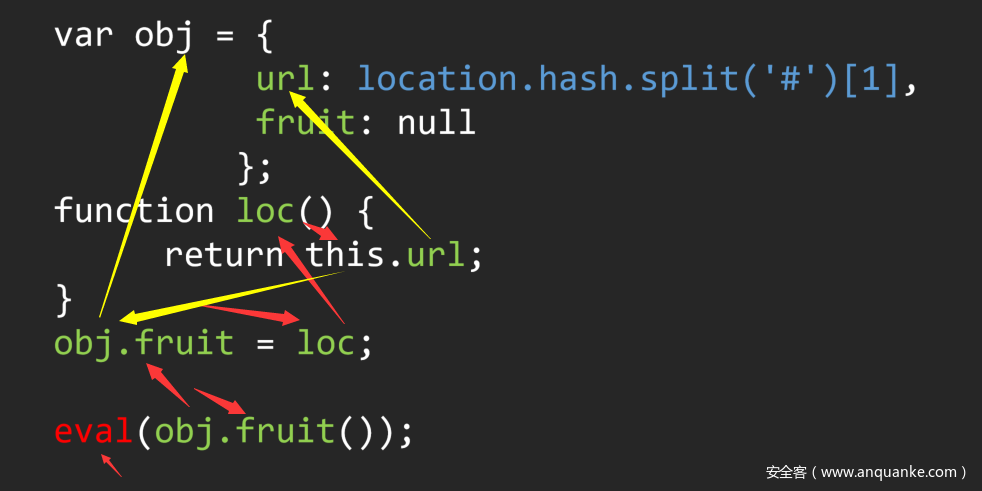
这里我用红色和黄色代表了流的两种流向。要解决这个问题只能通过针对类/字典变量的特殊回溯才能解决。
如果说,前面的两个问题是可以被解决的话,还有很多问题是没办法被解决的,这里举一个简单的例子。

这是一个典型的全局过滤,人工审计可以很容易看出这里被过滤了。但是如果在自动化分析过程中,当回溯到Source为$_GET['a']时,已经满足了从Source到sink的information flow。已经被识别为漏洞。一个典型的误报就出现了。
而基于AST的自动化代码审计工具也正是在与这样的问题做博弈,从PHP自动化代码审计中比较知名的Rips、Cobra再到我自己二次开发的Cobra-W.
- https://www.ripstech.com/
- https://github.com/WhaleShark-Team/cobra
- https://github.com/LoRexxar/Kunlun-M
都是在不同的方式方法上,优化information flow分析的结果,而最大的区别则是离不开的高可用性、高覆盖性两点核心。
- Cobra是由蘑菇街安全团队开发的侧重甲方的静态自动化代码扫描器,低漏报率是这类工具的核心,因为甲方不能承受没有发现的漏洞的后果,这也是这类工具侧重优化的关键。
在我发现没有可能完美的回溯出每一条流的过程之后,我将工具的定位放在白帽子自用上,从开始的Cobra-W到后期的KunLun-M,我都侧重在低误报率上,只有准确可靠的流我才会认可,否则我会将他标记为疑似漏洞,并在多环定制了自定义功能以及详细的log日志,以便安全研究人员在使用的过程中可以针对目标多次优化扫描。
对于基于AST的代码分析来说,最大的挑战在于没人能保证自己完美的处理所有的AST结构,再加上基于单向流的分析方式,无法应对100%的场景,这也正是这类工具面临的问题(或者说,这也就是为什么选择逆向的原因)。
基于IR/CFG的代码分析
如果深度了解过基于AST的代码分析原理的话,不然发现AST的许多弊端。首先AST是编译原理中IR/CFG的更上层,其ast中保存的节点更接近源代码结构。
也就是说,分析AST更接近分析代码,换句话就是说基于AST的分析得到的流,更接近脑子里对代码执行里的流程,忽略了大多数的分支、跳转、循环这类影响执行过程顺序的条件,这也是基于AST的代码分析的普遍解决方案,当然,从结果论上很难辨别忽略带来的后果。所以基于IR/CFG这类带有控制流的解决方案,是现在更主流的代码分析方案,但不是唯一。
首先我们得知道什么是IR/CFG。
- IR:是一种类似于汇编语言的线性代码,其中各个指令按照顺序执行。其中现在主流的IR是三地址码(四元组)
- CFG: (Control flow graph)控制流图,在程序中最简单的控制流单位是一个基本块,在CFG中,每一个节点代表一个基本块,每一个边代表一个可控的控制转移,整个CFG代表了整个代码的的控制流程图。
一般来说,我们需要遍历IR来生成CFG,其中需要按照一定的规则,不过不属于这里的主要内容就暂且不提。当然,你也可以用AST来生成CFG,毕竟AST是比较高的层级。
而基于CFG的代码分析思路优势在于,对于一份代码来说,你首先有了一份控制流图(或者说是执行顺序),然后才到漏洞挖掘这一步。比起基于AST的代码分析来说,你只需要专注于从Source到Sink的过程即可。
建立在控制流图的基础上,后续的分析流程与AST其实别无太大的差别,挑战的核心仍然维持在如何控制流,维持作用域,处理程序逻辑的分支过程,确认Source与Sink。
理所当然的是,既然存在基于AST的代码分析,又存在基于CFG的代码分析,自然也存在其他的种类。比如现在市场上主流的fortify,Checkmarx,Coverity包括最新的Rips都使用了自己构造的语言的某一个中间部分,比如fortify和Coverity就需要对源码编译的某一个中间语言进行分析。前段时间被阿里收购的源伞甚至实现了多种语言生成统一的IR,这样一来对于新语言的扫描支持难度就变得大大减少了。
事实上,无论是基于AST、CFG或是某个自制的中间语言,现代代码分析思路也变得清晰起来,针对统一的数据结构已经成了现代代码分析的基础。
未来 – QL概念的出现
QL指的是一种面向对象的查询语言,用于从关系数据库中查询数据的语言。我们常见的SQL就属于一种QL,一般用于查询存储在数据库中的数据。
而在代码分析领域,Semmle QL是最早诞生的QL语言,他最早被应用于LGTM,并被用于Github内置的安全扫描为大众免费提供。紧接着,CodeQL也被开发出来,作为稳定的QL框架在github社区化。
那么什么是QL呢?QL又和代码分析有什么关系呢?
首先我们回顾一下基于AST、CFG这类代码分析最大的特点是什么?无论是基于哪种中间件建立的代码分析流程,都离不开3个概念,流、Source、Sink,这类代码分析的原理无论是正向还是逆向,都是通过在Source和Sink中寻找一条流。而这条流的建立围绕的是代码执行的流程,就好像编译器编译运行一样,程序总是流式运行的。这种分析的方式就是数据流分析(Data Flow)。
而QL就是把这个流的每一个环节具象化,把每个节点的操作具像成状态的变化,并且储存到数据库中。这样一来,通过构造QL语言,我们就能找到满足条件的节点,并构造成流。下面我举一个简单的例子来说:
<?php
$a = $_GET['a'];
$b = htmlspecialchars($a);
echo $b;
我们简单的把前面的流写成一个表达式
echo => $_GET.is_filterxss
这里is_filterxss被认为是输入$_GET的一个标记,在分析这类漏洞的时候,我们就可以直接用QL表达
select * where {
Source : $_GET,
Sink : echo,
is_filterxss : False,
}
我们就可以找到这个漏洞(上面的代码仅为伪代码),从这样的一个例子我们不难发现,QL其实更接近一个概念,他鼓励将信息流具象化,这样我们就可以用更通用的方式去写规则筛选。
也正是建立在这个基础上,CodeQL诞生了,它更像是一个基础平台,让你不需要在操心底层逻辑,使用AST还是CFG又或是某种平台,你可以将自动化代码分析简化约束为我们需要用怎么样的规则来找到满足某个漏洞的特征。这个概念也正是现代代码分析主流的实现思路,也就是将需求转嫁到更上层。
聊聊KunLun-M
与大多数的安全研究人员一样,我从事的工作涉及到大量的代码审计工作,每次审计一个新的代码或者框架,我都需要花费大量的时间成本熟悉调试,在最初接触到自动化代码审计时,也正是希望能帮助我节省一些时间。
我接触到的第一个项目就是蘑菇街团队的Cobra
这应该是最早开源的甲方自动化代码审计工具,除了一些基础的特征扫描,也引入了AST分析作为辅助手段确认漏洞。
在使用的过程中,我发现Cobra初版在AST上的限制实在太少了,甚至include都没支持(当时是2017年),于是我魔改出了Cobra-W,并删除了其中大量的开源漏洞扫描方案(例如扫描java的低版本包),以及我用不上的甲方需求等…并且深度重构了AST回溯部分(超过上千行代码),重构了底层的逻辑使之兼容windows。
在长期的使用过程中,我遇到了超多的问题与场景(我为了复现Bug写的漏洞样例就有十几个文件夹),比较简单的就比如前面漏洞样例里提到的新函数封装,最后新加了大递归逻辑去新建扫描任务才解决。还有遇到了Hook的全局输入、自实现的过滤函数、分支循环跳转流程等各类问题,其中我自己新建的Issue就接近40个…
为了解决这些问题,我照着phply的底层逻辑,重构了相应的语法分析逻辑。添加了Tamper的概念用于解决自实现的过滤函数。引入了python3的异步逻辑优化了扫描流程等…
也正是在维护的过程中,我逐渐学习到现在主流的基于CFG的代码分析流程,也发现我应该基于AST自实现了一个CFG分析逻辑…直到后来Semmle QL的出现,我重新认识到了数据流分析的概念,这些代码分析的概念在维护的过程中也在不断地影响着我。
在2020年9月,我正式将Cobra-W更名为KunLun-M,在这一版本中,我大量的剔除了正则+AST分析的逻辑,因为这个逻辑违背了流式分析的基础,然后新加了Sqlite作为数据库,添加了Console模式便于使用,同时也公开了我之前开发的有关javascript代码的部分规则。
KunLun-M可能并不是什么有技术优势的自动化代码审计工具,但却是唯一的仍在维护的开源代码审计工具,在多年研究的过程中,我深切的体会到有关白盒审计的信息壁垒,成熟的白盒审计厂商包括fortify,Checkmarx,Coverity,rips,源伞扫描器都是商业闭源的,国内的很多厂商白盒团队都还在起步,很多东西都是摸着石头过河,想学白盒审计的课程这些年我也只见过南京大学的《软件分析》,很多东西都只能看paper…也希望KunLun-M的开源和这篇文章也能给相应的从业者带来一些帮助。
同时,KunLun-M也作为星链计划的一员,秉承开放开源、长期维护的原则公开,希望KunLun-M能作为一颗星星链接每一个安全研究员。
星链计划地址: