
0x00 前言
之前我们简单介绍了一下扫描器中爬虫的部分,接下来将继续介绍一下扫描器中一些我们认为比较有趣的技巧。
0x01 编码/解码/协议
在很久以前有人提问 AMF 格式的请求怎么进行检测,或者有什么工具可以检测。
既然我们要讲解的是 Web 漏洞扫描器,那么就先假设是 AMF over HTTP (这里并不需要你了解 AMF,你只需要知道 AMF 是一种数据格式类型就行)
假设我们需要测试一个 AMF 格式数据的 SQL 注入问题,那么按照通常的思路就是在 SQL 注入模块中
- 先解析 HTTP 中 AMF 格式数据
- 然后在测试参数中填写 payload
- 重新封装 AMF 格式数据
- 发送 HTTP 请求
伪代码如下:
req = {"method": "POST", "url": "http://fatezero.org", "body": "encoded data"}
data = decode_amf(req["body"])
for key, value in data.items():
d = copy.deepcopy(data)
d[key] = generate_payload(value)
body = encode_amf(d)
requests.request(method=req["method"], url=req["url"], body=body)
整个流程下来没什么问题,但是如果又来了一个 X 协议(X over HTTP),那么我们就得继续修改 SQL 注入模块以便支持这种 X 协议,
但是扫描器中可不是只有 SQL 注入检测模块,还有其他同类模块,难道每加一个新协议我还得把所有检测模块都改一遍?
所以我们需要把这些协议解析和封装单独抽出来放在一个模块中。
伪代码如下:
# utils.py
def decode(data):
if is_amf(data):
data = decode_amf(data)
if is_X(data):
data = decode_X(data)
# 递归 decode
for i in data:
data[i] = decode(data[i])
return data
# detect_module.py
req = {"method": "POST", "url": "http://fatezero.org", "body": "encoded data"}
data = decode(req["body"])
for key, value in data.items():
d = copy.deepcopy(data)
d[key] = generate_payload(value)
body = encode(d)
requests.request(method=req["method"], url=req["url"], body=body)
上面的递归 decode 主要是为了解码某种格式的数据里面还有另外一种格式的数据,虽然看起来这种场景比较少见,
但是仔细想一下 multipart 带着 json,json 里的字符串是另外一个 json 字符串,是不是又觉得这种情况也并不少见。
那 encode/decode 剥离出来就可以了吗?请注意到上面伪代码使用了 requests.request 发送请求,
那如果某天需要我们去测试 websocket 协议,那是不是又得在检测模块中多加一套 websocket client 发送请求?
所以我们也需要将具体的网络操作给剥离出来,具体的协议类型直接由上面来处理,检测模块只需要关注具体填写的 payload。
伪代码如下:
for key, value in x.items():
data.reset()
x[key] = generate_payload(value)
x.do() # 负责将数据重新组装成原来的格式,并按照原始协议发送
# check
因为每个检测模块的检测依据大致就几种:
- 返回内容
- 消耗时间 (time based)
- 另外一条信道的数据 (比方说 dnslog)
所以即便是我们将网络操作剥离出来也不会影响检测的效果。
在编写检测模块的时候,编写者可以不用关心基础协议是什么,怎么对数据编码解码,只用关心根据 value 生成 payload 并填写到相对应的 key 中,
假如某天出现了这么一种流行编码格式 http://www.a.com/key1,value1,key2,value2,那我们所有的检测模块也无需修改,
仅仅需要在上一层再添加一套 encode/decode 操作即可。假如某天出现了一种比较流行的协议,我们也仅需要在上一层提供一套 client 即可。
检测模块的工作就仅仅剩下生成并填写 payload。
0x02 PoC 分类
在 2014 年的时候,我做了大量的竞品分析,包括使用逆向工程逆向商业的 Acunetix WVS, HP Webinspect, IBM AppScan, Netsparker 扫描逻辑,也包括阅读开源的 w3af, arachni 代码。
如果不谈扫描质量,只关注整体项目设计以及产品中使用到的猥琐技巧,那么其中最让我眼前一亮的当属 AWVS,
接下来我将详细介绍一下我从 AWVS 中学习到的 PoC 分类。
PoC 分类:
| 类型 | 描述 |
|---|---|
| PerServer | 用于检测 Web Server 级别中存在的漏洞,比方说各种中间件,Web 框架的漏洞 |
| PerFile | 用于检测某个文件中是否存在漏洞,比如对应文件的备份,Bash RCE 等 |
| PerFolder | 用于检测某个目录中是否存在漏洞,比如敏感信息的泄漏,路径中的 SQL 注入等 |
| PerScheme | 用于检测某个参数中是否存在漏洞,比如 SQL 注入,XSS 等 |
| PostCrawl | 在爬虫结束之后启动,直接使用爬虫的资源进行检测 |
| PostScan | 在扫描结束之后启动,用于检测二阶注入,存储 XSS等 |
| WebApps | 用于检测比较常用的 Web 应用的漏洞 |
大致的流程图如下:
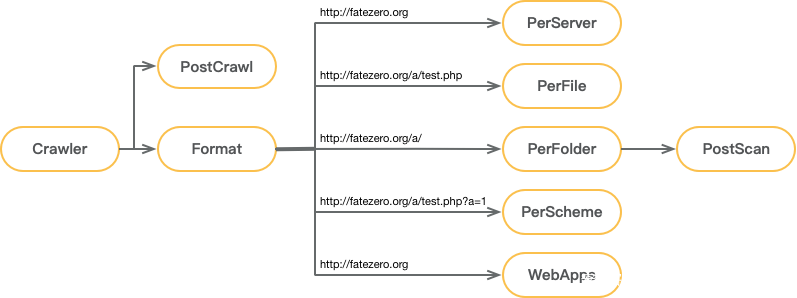
在获取到爬虫资产,对相关资产格式化之后,便下发到各个不同类型的 PoC 中进行检测,这样做的好处是分类明确,覆盖大多数检测阶段,
也避免为了减少重复请求的下发而需要额外记录中间状态的行为。
0x03 IAST
AWVS 有个比较有趣的功能 AcuMonitor,也就大家熟知的 dnslog、反连平台。在 2014 年看到 AWVS 的这个功能时,
就建议 WooYun 出个类似的功能,也就是 cloudeye,tangscan 也就算是国内比较早使用这种技术的扫描器,
当然后续又出现了各种类似 cloudeye 的项目,自然而然也出现了各种使用该技术的扫描器。
不过今天我们不打算继续介绍 AcuMonitor,而是介绍另外一个也很有趣的功能 AcuSensor。
AcuSensor 就是 IAST,只要稍微了解过 Web 漏洞扫描器的,都应该会知道 IAST 是干啥的。那为什么我要单独拎出来讲这个呢?
主要是因为 AcuSensor 的实现方式非常有趣。
AcuSensor 提供了 Java、.NET、PHP 这三个语言版本,其中比较有趣的是 PHP 版本的实现。
PHP 版本的 AcuSensor 使用方法是下载一个 acu_phpaspect.php 文件,然后通过 auto_prepend_file 加载这个文件,
众所周知,PHP 是不能改直接 hook PHP 内置函数的,那么单单依靠一个 PHP 脚本,AcuSensor 是如何做到类似 IAST 功能的呢?
很简单,直接替换所有关键函数。嗯,真的就那么简单。
我们来详细介绍一下这个过程,在 acu_phpaspect.php 中:
- 获取用户实际请求的文件内容
- 检查一下有没有相关 cache,如果有 cache 那么直接加载执行 cache,然后结束
- 使用
token_get_all获取所有 token - 遍历每一个 token,对自己感兴趣的函数或者语句使用自己定义的函数进行 wrap 并替换
- 将替换后的内容保存到 cache 中并使用 eval 执行
-
__halt_compiler中断编译
举个具体的例子:
<?php
$link = NULL;
$sql = "select * from user where user_id=".$_GET["id"];
mysqli_prepare($link, $sql);
经过 acu_phpaspect.php 转换之后:
<?php
$link = NULL;
$sql = "select * from user where user_id=".$_GET[_AAS91("hello.php", 4, "$_GET", "id")];
_AAS86("hello.php",6,"mysqli_prepare",Array($link, $sql));
整个过程简单粗暴有效,这样做的优点在于:
- 实现简单,只需要编写 PHP 即可
- 安装简单,无需安装扩展,只需修改配置文件可以
- 兼容性强,比较容易兼容性各种环境,各种版本 PHP
如果有意向去做 IAST 或者想做类似我的 prvd 项目,
但又不太喜欢写 PHP 扩展,那么我强烈建议你完整的看一遍 PHP 版本 AcuSensor 的实现,
如果对自己实现的检测逻辑效率比较自信的话,甚至可以基于这个原理直接实现一个 PHP 版本的 RASP 项目。
0x04 限速
在 Web 漏洞扫描器中,无论作为乙方的商业产品、甲方的自研产品,限速都是一个至关重要的功能,
甚至可以说如果你的扫描器没有限速功能,那压根就不能上线使用。接下来我们将介绍一下在扫描器中限速的几种方法。
代理
使用代理做限速功能,将所有执行扫描任务的 worker 的测试流量全转发到 proxy 服务器上:

由 proxy 服务器统一调度发送测试请求频率,直接使用 proxy 方案优点是可以兼容之前没做限速功能的扫描器,
缺点是所有基于 time based 的检测均无效(当然也可以让 proxy 返回真正的响应时间来进行判断,不过仍需要修改检测模块),也不允许在检测模块中加入超时设置。
双重队列
另外一种方法是使用双重队列实现限速功能,流程图如下:
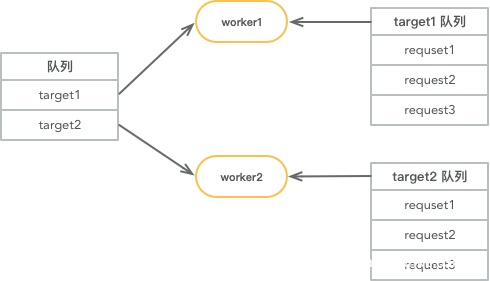
- worker1 从队列中取到名为 target1 的任务
- worker1 从 target1 队列中取出和 target1 相关的任务
- 默认单并发执行和 target1 相关任务,根据设置的 QPS 限制,主动 sleep 或者增加并发
这种方案的缺点是扫描器设计之初的时候就得使用这种方法,优点是每个并发可以稳定的和远程服务器保持链接,也不影响扫描功能。
0x05 漏洞检测
实际上这一节并不会讲具体某个漏洞检测方法,只是简单谈一下漏扫模块每个阶段该干的事情。
项目之初,没有相关积累,那么可以选择看一下 AWVS 的检测代码,虽然说网上公开的是 10.5 的插件代码,
但其实从 8.0 到 11 的插件代码和 10.5 的也差不多,无非新增检测模块,修复误漏报的情况,
也可以多看看 SQLMap 代码,看看检测逻辑,但是千万不要学习它的代码风格。从这些代码中可以学习到非常多的小技巧,
比如动态页面检测,识别 404 页面等。看代码很容易理解相关的逻辑,但我们需要去理解为什么代码这样处理,历史背景是什么,所以多用 git blame。
到了中期,需要提升漏洞检测的精准度,漏洞检测的精准度是建立在各种 bad case 上,误报的 case 比较容易收集和解决,
漏报的 case 就需要其他资源来配合。作为甲方如果有漏洞收集平台,那么可以结合白帽子以及自己部门渗透团队提交的漏洞去优化漏报情况。
如果扫描器是自己的一个开源项目的话,那么就必须适当的推广自己的项目,让更多的人去使用、反馈,然后才能继续完善项目,
从而继续推广自己的项目,这是一个循环的过程。总而言之,提升漏洞检测的精准度需要两个条件,1. bad case,2. 维护精力。
到了后期,各种常规的漏洞检测模块已经实现完成,也有精力持续提升检测精准度,日常漏洞 PoC 也有人员进行补充。那么事情就结束了么?
不,依旧有很多事情我们可以去做,扫描器的主要目标是在不影响业务的情况下,不择手段的发现漏洞,所以除了常规的资产收集方式之外,
我们还可以从公司内部各处获取资产相关的数据,比方说从 HIDS 中获取所有的端口数据、系统数据,从流量中或业务方日志中获取 url 相关数据等。
当然除了完善资产收集这块,还有辅助提升检测效果的事情,比如说上面提到的 AcuSensor,这部分事情可以结合公司内部的 RASP 做到同样效果,
还有分析 access log、数据库 log 等事情。总的来说,做漏扫没有什么条条框框限制,只要能发现漏洞就行。
以上都是和技术相关的事情,做漏扫需要处理的事情也不仅仅只有技术,还需要去搞定详细可操作的漏洞描述及其解决方案,汇报可量化的指标数据,
最重要的是拥有有理有据、令人信服的甩锅技巧。
0x06 总结
以上即是我认为在扫描器中比较有用且能够公开的小技巧,希望能够对你有所帮助。
另外如果你对 漏洞扫描 或者 IoT 自动化安全产品 感兴趣,并愿意加入我们,欢迎简历投递 fate0@fatezero.org
小米安全中心:https://sec.xiaomi.com/
微信号:
