
在本系列的第一部分中,我解释了如何开始对 Apache HTTP 进行模糊测试,如何在 AFL++ 中实现自定义突变器,以及如何定义您自己的 HTTP 语法
在第二部分中,我将重点介绍如何构建我们自己的自定义 ASAN 拦截器,以便在实现自定义内存池时捕获内存错误,以及如何拦截文件系统系统调用以检测目标应用程序中的逻辑错误
让我们继续吧!
一、人工中毒
让我们首先快速回顾一下 Address Sanitizer (ASAN) 影子内存和中毒是如何工作的
ASAN维护了一个影子内存,用于跟踪实际内存中的每个字节,并可以确定内存中的任何给定字节是否可地址访问。无效内存区域中的字节称为红色区域或中毒内存
因此,当您使用 Address Sanitizer 编译您的程序时,它会检测每个内存访问并为其添加一个检查前缀。然后,ASAN 将跟踪程序,如果程序尝试写入无效的内存区域,ASAN 将停止执行并生成诊断报告。否则,它将允许程序继续运行。这允许您检测各种无效的内存访问和内存管理不善等问题
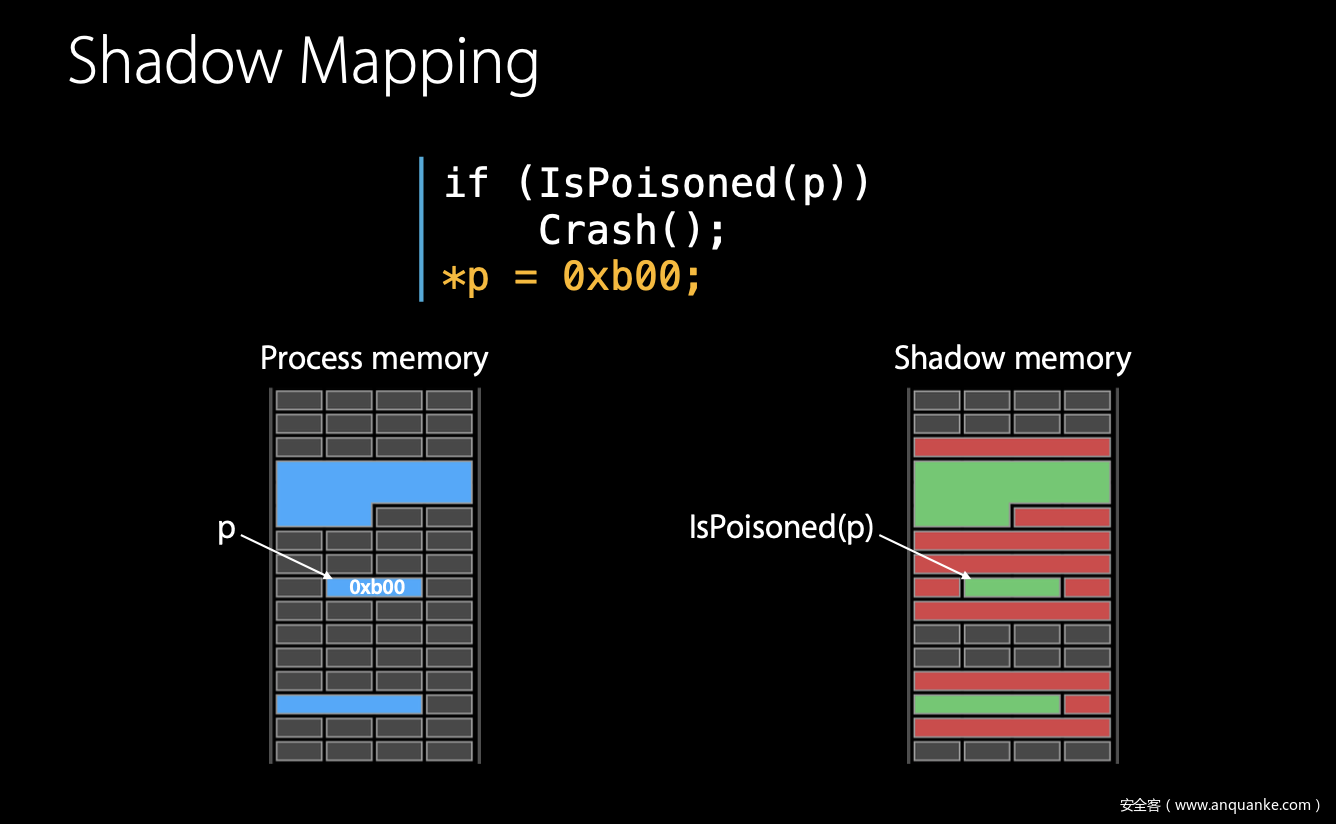
在某些情况下,对中毒内存有更自由的控制权限对开发人员和安全研究人员很有用。例如,在一个自定义函数中,您以一种ASAN无法捕获的方式处理内存。这就是为什么 ASAN 还提供了手动内存中毒外部 API,允许用户手动对内存区域进行中毒和解除中毒。
我们可以通过在程序里导入包含了这些外部 ASAN 接口的ASAN 库来使用这些功能:
#include <sanitizer/asan_interface.h>
然后我们可以在分别调用malloc和free时用ASAN_POISON_MEMORY_REGION和ASAN_UNPOISON_MEMORY_REGION宏。典型的工作流程是首先毒害整个内存区域,然后解除分配的内存块毒害,在它们之间留下毒害的红色区域。
这种方法相对简单,易于实现,但每当我们针对一个新程序时,都会遇到“重新实现轮子”的问题。如果我们能像ASAN那样,简单地拦截某一组功能,那就太好了。
出于这个原因,我将展示另一种方法:自定义拦截器
二、自定义拦截器
2.1 动机
在这篇博文的开头,我谈到了需要实现自定义拦截器来处理自定义内存池实现,就像Apache HTTP的情况一样。所以我们要问自己的问题是“为什么我们需要实现自定义拦截器?”
让我们看一个例子来更好地理解
例如,考虑以下代码片段,其中调用了apr_palloc以分配内存:

在这种情况下,第二个参数的值为 126 ( in_size = 126) ,换句话说,我们的目标是在g->apr_pool这个内存池中分配 126 个字节。由于内存对齐要求,这 126 个字节将向上舍入为 128 个字节。这很清楚
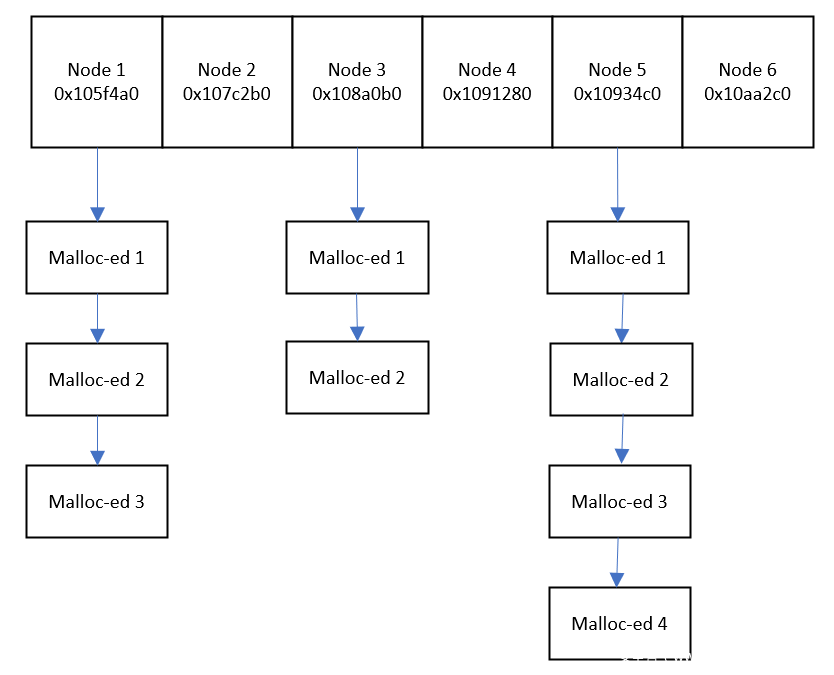
如果您看过我们之前的ProFTPd博客文章,您可以找到有关内部如何实现 ProFTPd 内存池的知识。这个内存池实现是基于 Apache HTTP 的,所以在这种情况下,两者的实现是几乎相同的。Apache HTTP 内存池由内存节点的链表组成,如下所示:
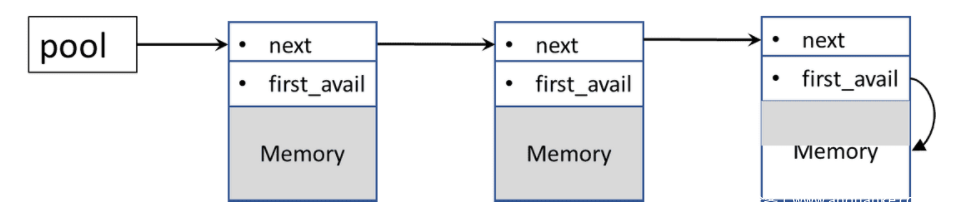
然后,程序将在需要额外空间时向此链表添加新节点。当一个节点的空闲空间不足以满足apr_palloc需求时,则调用allocator_alloc函数。该函数将负责创建一个新节点并将其添加到链表中。然而,正如我们在下图中看到的,这样的分配大小总是向上舍入到MIN_ALLOC字节。因此,这些节点中的每一个的最小大小为MIN_ALLOC
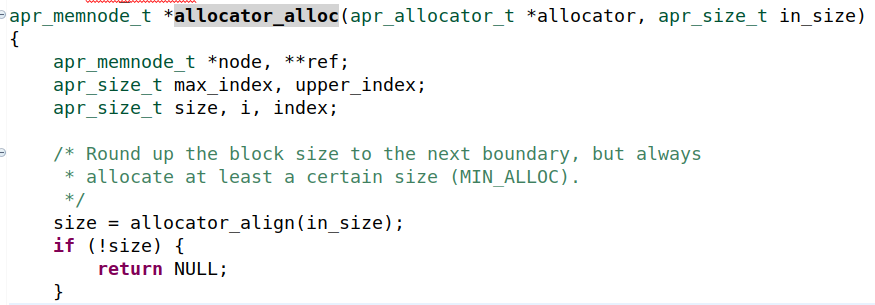
稍后,在这个函数中调用malloc,目的是为这个节点分配新的内存。在下图中,您可以观察到size=8192的malloc调用是如何执行的:
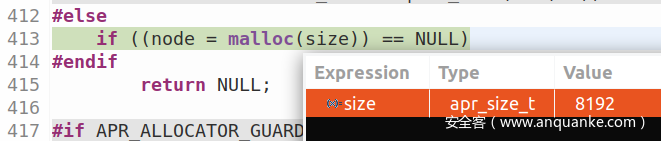
我们发现自己面临这样一个场景:我们以 size = 126调用了apr_palloc…

……但是 ASAN 已经毒害了一个大小为 8192 的内存区域:

最终的结果是总共8192-126 = 8066字节被ASAN标记为可写,而实际上它不是真正分配的内存,而是节点中的空闲空间。因此,一个后续的memcpy(np, source, 5000)调用将导致一个超出范围的写操作,覆盖节点的其余内存。然而,我们不会看到任何ASAN警报消息,这将导致我们错过内存损坏错误,即使我们已经将ASAN启用
此类错误可能导致漏洞,例如我一年前在 ProFTPD 中发布的漏洞:CVE-2020-9273
2.2 准备步骤
接下来,我将解释如何从源代码构建 LLVM sanitizer。这是将我们自己的自定义ASAN拦截器添加到 ASAN库所必需的步骤
首先,您应该知道 LLVM sanitizer 运行时是所谓的“compiler-rt”运行时库的一部分。就我而言,我下载了 compiler-rt 源代码的 9.0.0 版,因为它是我之前在 Linux 发行版中安装的版本。您可以从以下链接下载这些源代码:
https://releases.llvm.org/9.0.0/compiler-rt-9.0.0.src.tar.xz
您可以使用以下方法构建它:
cd compiler-rt-9.0.0.src
mkdir build-compiler-rt
cd build-compiler-rt
cmake ../
make
在compiler-rt构建过程完成后,您必须将下一个环境变量添加到Apache的构建过程中:
LD_LIBRARY_PATH= /Downloads/compiler-rt-9.0.0.src/build-compiler-rt/lib/linux
CFLAGS="-I/Downloads/compiler-rt-9.0.0.src/lib -shared-libasan”
最后,你需要设置环境变量LD_LIBRARY_PATH,如下所示:
LD_LIBRARY_PATH=/Downloads/compiler-rt-9.0.0.src/build-compiler-rt/lib/linux
2.3 ASAN拦截器内部结构
正如我们前面看到的,ASAN需要拦截malloc和free等函数来跟踪内存使用情况。这要求首先加载运行时,然后再加载导出这些函数的库。因此,当我们添加链接器标志-fsanitize=address时,编译器按照符号搜索中查找到的顺序会首先设置libasan
如果我们检查代码,可以看到entry函数被称为__asan_init。这个函数依次调用AsanActivate和AsanInternal函数。大部分初始化步骤都发生在第二个函数中,也就是调用InitializeAsanInterceptors的地方。最后一个函数对于我们的目的来说是最重要的:
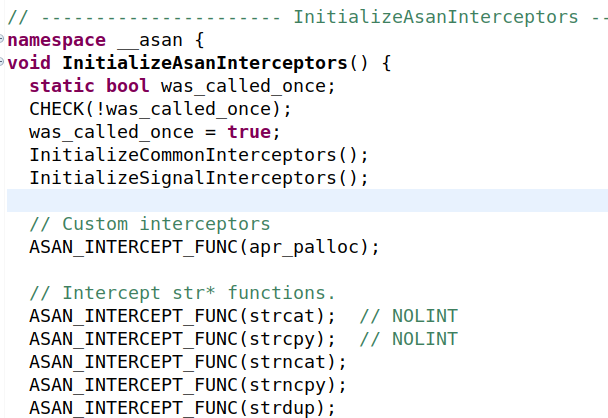
如上所示,ASAN默认拦截的每个函数都有一个ASAN_INTERCEPT_FUNC调用。ASAN_INTERCEPT_FUNC是一个宏,在Linux系统上被翻译成INTERCEPT_FUNCTION_LINUX_OR_FREEBSD。这个宏最终会调用InterceptFunction函数,该函数将执行所有实际的函数挂钩逻辑
#define ASAN_INTERCEPT_FUNC(name) do { \
if (!INTERCEPT_FUNCTION(name) && flags()->verbosity > 0) \
Report("AddressSanitizer: failed to intercept '" #name "'\n"); \
} while (0)
# define INTERCEPT_FUNCTION(func) INTERCEPT_FUNCTION_LINUX_OR_FREEBSD(func)
#define INTERCEPT_FUNCTION_LINUX_OR_FREEBSD(func) \
::__interception::InterceptFunction( \
#func, \
(::__interception::uptr *) & REAL(func), \
(::__interception::uptr) & (func), \
(::__interception::uptr) & WRAP(func))
在这个函数中,它调用GetFuncAddr函数,而GetFuncAddr函数又调用dlsym()。Dlsym允许程序检索该符号(被拦截的函数)加载到内存中的地址
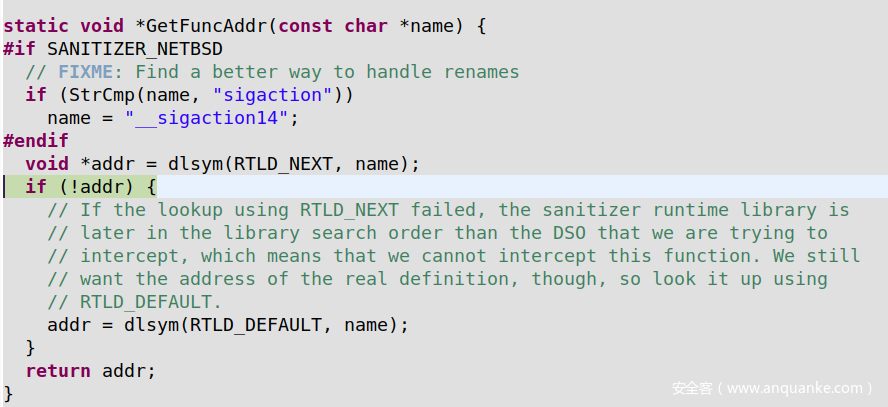
稍后它将此函数的地址存储到ptr_to_real指针中
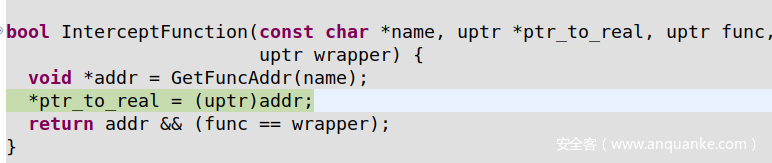
所以,总而言之,要定义我们自己的ASAN拦截器,我们需要执行以下步骤:
- 定义
INTERCEPTOR(int, foo, const char *bar, double baz){…},其中foo是我们想要拦截的函数的名称 - 在第一次调用
foo函数之前调用ASAN_INTERCEPT_FUNC (foo)(通常来自InitializeAsanInterceptors函数)
现在,我将展示如何拦截 APR(Apache Portable Runtime)库的函数的真实示例
2.4 apr_palloc示例
如前所述,Apache使用自定义内存池来改进程序动态内存的管理。这就是为什么如果我们想在内存池中分配内存,我们应该调用apr_palloc而不是malloc
首先,我将展示我的INTERCEPTOR(void*, apr_palloc,…)实现:

ENSURE_ASAN_INITED()宏在继续执行之前会首先检查ASAN是否已经初始化。GET_STACK_TRACE_MALLOC宏检索当前堆栈跟踪,以便在捕获异常时将其显示在ASAN报告中。作为一般规则,我们将尽可能早地在拦截器中检索堆栈跟踪,因为我们不希望堆栈跟踪包含来自ASAN内部的函数
然后,我们使用REAL(apr_palloc)调用原始的apr_palloc函数,以便为内存池创建所有的内部结构。apr_palloc函数本身调用allocator_alloc函数,该函数负责在需要时分配内存。我们所做的是用__libc_malloc替换malloc调用(被ASAN拦截)。这使我们能够避免对节点的整个内存进行清理
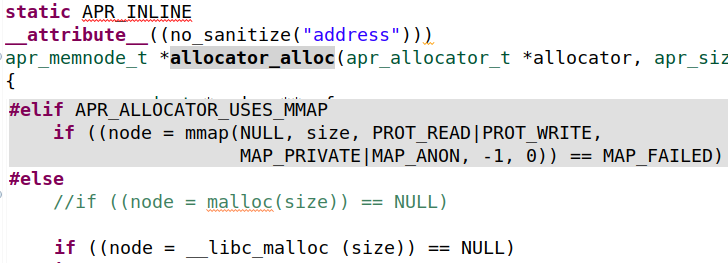
当程序从apr_palloc函数返回后,我们用与APR相同的方式对“in_size”整数进行对齐。这将使两个内存大小相同,然后调用asan_malloc来分配一个大小为“in_size”的新内存块。这个新分配的内存将由ASAN处理
最后,我们将libc_malloc和asan_malloc的内存地址存储在一个数组中,这样当节点被销毁时,我们就能够释放asan-malloc的内存块
就像我们处理malloc一样,我们也可以更改与释放节点相关的对free()的调用。在本例中,我们将修改allocator_free和apr_allocator_destroy函数。此外,我们必须释放之前用asan_malloc分配的内存。为此,我遍历存储地址的“addr”数组,并释放链接到该节点的所有内存块。最后,我使用__libc_free(node)语句直接调用free()函数
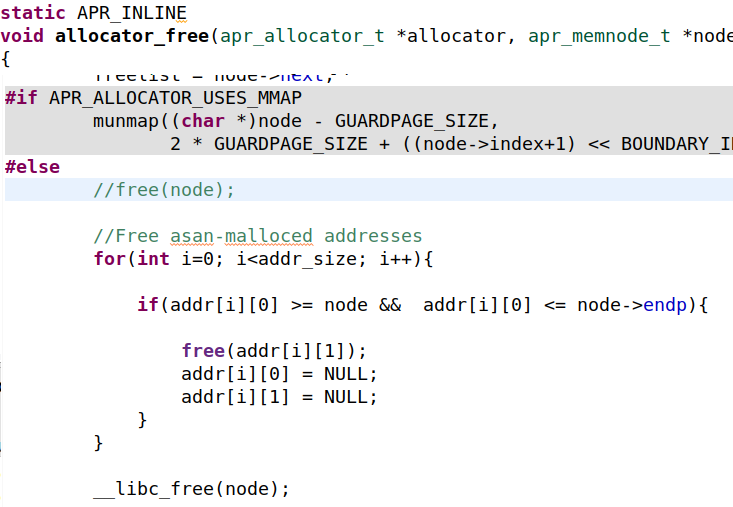
我使用这种方法是因为它简单且易于解释,但它的效率非常低,因为它意味着遍历整个“addr”数组。更好的方法是将节点地址存储到一个唯一的(向量)unique(vector)或std::set中,并将每个这些地址指向一个asan_malloc-ed地址的链表
三、文件监视器
当我们模糊一个文件服务器,如FTP服务器或HTTP服务器时,我们发送多个请求,这些请求将被转换为远程服务器中的文件系统调用(open()、write()、read()等)。这可能会触发与文件访问权限相关的逻辑漏洞,如访问绕过、业务流绕过等
然而,在大多数情况下,使用AFL这样的模糊器检测此类漏洞是一项复杂的任务。这是因为这种类型的fuzzer更倾向于检测内存管理漏洞(堆栈溢出、堆溢出等)。正是由于这个原因,我们需要实现新的检测方法来捕获这些漏洞
下面的文件监控方法是一种基本的方法,它基于拦截和保存文件系统调用信息以供以后分析。驱动分析的主要思想是将文件系统调用与它们的高级对等对象进行比较,并检查被调用的系统调用是否确实是它们本身,以及调用顺序和参数是否正确。
为了说明这一点,我将展示一个包含三个不同 WebDav 请求的示例:
- PUT
- MOVE
- DELETE
您可以在以下链接中下载包含这些请求的文件
https://github.com/antonio-morales/Apache-HTTP-Fuzzing/blob/main/WebDav/testWebDav.txt
首先,我将识别处理这些HTTP方法所涉及的高级函数。在PUT情况下,MOVE和DELETE分别为:
static int dav_method_put(request_rec *r)
static int dav_method_copymove(request_rec *r, int is_move)
static int dav_method_delete(request_rec *r)
然后,我将在每个函数的开头插入一个对log_high函数的调用:

同样,我们可以在每个函数的末尾插入一个ENABLE_LOG = 0;。log_high函数代码如下:

现在,正如我们在前一节中演示的那样,我们将使用ASAN拦截器来拦截文件系统系统调用。在Apache的环境下,我拦截了以下系统调用:
openrename-
unlink![]()

这是输出文件的示例:

在获得输出文件之后,我们需要分析它。在我的例子中,我使用Elasticsearch执行了一个后推理分析。如何执行实际的分析超出了这篇文章的范围,但我将在不久的将来在另一篇文章中分享我如何使用Elasticsearch进行API日志分析。我还将解释如何使用AFL++执行实时分析
四、待续…
在本系列的最后一篇文章中,我将使用第1部分和第2部分中概述的方法详细介绍在Apache HTTP中发现的漏洞。由于这也是我的“fuzzing sockets”系列的最后一篇文章,我将总结一些我的主要经验,并向您介绍我的下一个研究课题
请继续关注第三部分!
五、参考
- llvm.org
- Compiler-rt source code: https://developer.apple.com/videos/play/wwdc2015/413/
- Advanced Debugging and the Address Sanitizer – Mike Swingler, Anna Zaks
- https://jonasdevlieghere.com/sanitizing-python-modules/