前言
本篇文章介绍了fuzz闭源PDF阅读器时出现的典型问题以及解决这些问题可能的方法。在这里着重于介绍了两点:最小化输入和适时终止目标程序。
正文
模糊PDF阅读器的核心思想非常简单:只需要拿一个PDF文件,稍微破坏(修改部分PDF二进制流字节)它并检查它是否会使阅读器崩溃。这听起来非常简单,但要正确而且有效地完成却非常困难。PDF文件格式是目前使用最多且最重要的格式之一。因此,PDF阅读器的漏洞曾被广泛的利用并且在2018年依旧有很多exp被开发。通过查看报告给主流PDF阅读器的bug数量显示,现在仍有许多强化需要做。因此,我想为这两者—PDF阅读器的安全性和模糊测试社区做出一些贡献。
Fuzz PDF阅读器时通常会遇到的问题如下:
- 在什么情况下Fuzzer可以确定没有发生崩溃?
- PDF阅读器从不显示它已完成解析或呈现给定的PDF。应用程序何时可以关闭?
- 应选择哪些PDF作为突变模板?
- 所选PDF应尽可能多地覆盖到目标代码。如果无法获得源代码,如何有效地计算代码覆盖率?
问题:无法终止程序
正常Fuzzee的终止是向Fuzzer发出信号,表示它已完成处理并且没有发生崩溃。这对于Fuzzer很重要,因为这表示现在可以开始下一次测试迭代。而PDF阅读器的问题在于它们从不自行终止,因此Fuzzers缺少一个度量标准来确定何时可以启动下一个测试用例。
大多数现有的Fuzzers所做的事情大概就两种,他们要么使用硬编码检测超时,如果没有发生崩溃就会杀死应用程序,或者他们不断地轮询目标的CPU周期量并假设程序在低于某个阈值时可以被关闭 。
对于这两者:超时和阈值必须精确的确定,但或多或少是可以猜测的。对于Fuzzer来说,这意味着它可能太早(可能会丢失崩溃)或太迟(浪费时间)关闭应用程序。
方法:如何终止程序
我们的想法是找到阅读器的最后一个基本块,当它被赋予有效输入时执行。这里的假设是,只有当目标阅读器完全解析并呈现给定的PDF时,才会执行此基本块。从下一个输入开始,必须以终止程序的方式修补此块。
为了找出程序中哪些基本块已在运行时执行,研究人员利用了一个名为Program Tracing(程序跟踪)的概念。我们的想法是让目标生成有关其执行(踪迹)的附加信息,例如内存使用,采用分支或执行的基本块。由于目标不是创建这些信息,因此必须向其添加说明。此过程称为“Program Instrumentation(程序检测)”。在开源环境中,目标程序可以简单地使用其他编译器扩展(例如AddressSanitizer(ASAN))进行重新编译,这些扩展将负责在编译时添加检测。显然,这对于闭源PDF阅读器来说是不可能的。
幸运的是,我们有一个令人惊奇的框架“DynamoRIO”,应用此工具不需要任何源代码,因为它是在运行时检测程序的(动态二进制检测)。
drrun.exe -t drcov -dump_text -- Program.exe
创建的程序跟踪看起来像这样:
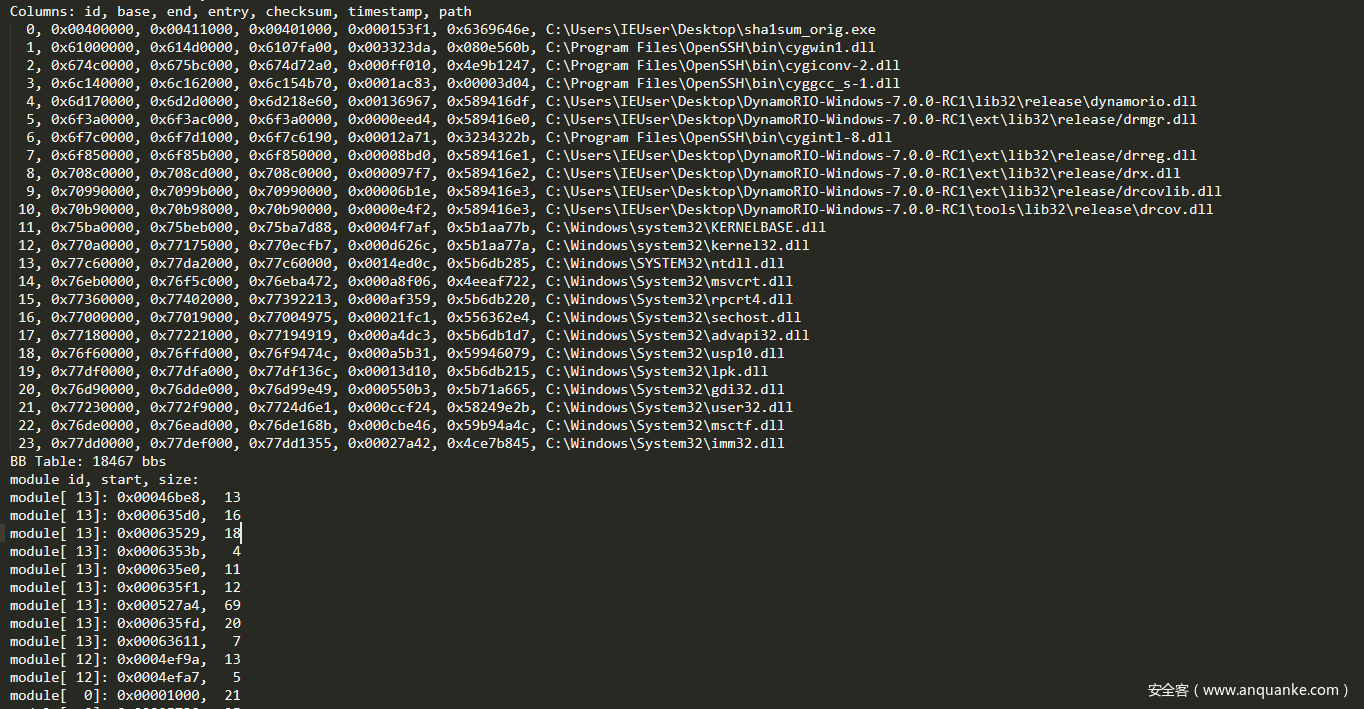
可以看出,跟踪显示了哪个模块的基本块已经执行,并且它保留了基本块的顺序,这使得确定最后一个基本块变得相当容易。因此,找出目标PDF阅读器执行的最后一个基本块,通过向其提供不同但有效的PDF文件来创建多个跟踪。然后我们会发现很明显,在靠近追踪链路末端的某处通常存在一个共同的基本块,这是必须被检测的块。
不幸的是,只有在程序退出后才会将跟踪写入磁盘,因此必须在此处使用(高)硬编码超时。
现在找到了最后一个公共基本块,需要对其进行修补,以便终止程序。这可以通过覆盖基本块来实现:
Xor eax, eax
push eax
Push Address_Of_ExitProcess
ret
这里问题是它需要9个字节来表示这些指令。如果基本块的大小不是9个字节,则后续指令将被破坏。 为了解决这个问题,可以在PE文件中添加一个新的可执行部分,其中包含上面的指令。因此,可以通过跳转到新添加的部分来修补基本块:
push SectionAddress
ret
为了修补目标,可以使用框架LIEF,这使得更改给定的PE文件变得相当容易。
不过很显然,使用断点修补基本块要容易得多,这是一个单字节指令。许多现有的Fuzzers依赖于程序终止的情况,因此不能用于定位PDF阅读器。这里可应用退出检测。
该方法是自动化的,并成功用于多个PDF和图像查看器:
- FoxitReader
- PDFXChangeViewer
- XNView
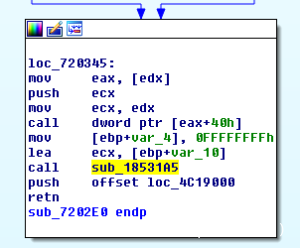
下面的屏幕截图给出了在汇编层面上的补丁。请注意,修补后的版本将返回到新添加的部分。

输入最小化
Fuzzing的成功在很大程度上取决于初始输入集(语料库)。因此,必须确保语料库尽可能多地覆盖目标代码,因为这增加了在其中发现bug的机会。此外,必须避免语料库中的冗余,以便每个PDF触发目标的独特行为。
对此的常见方法是称为“语料库蒸馏”(Corpus Distillation)。这样做的核心思想是首先收集大量有效的输入。然后,对于每个输入,测量基本块的代码覆盖,如果输入仅触发先前输入已经访问过的基本块,则将其从集合中移除。
corpus = []
inputs = [I1, I2, .... In]
for input in inputs:
new_blocks = execute(program, input)
if new_blocks:
corpus.append(input)
同样,需要创建程序跟踪。由于没有源代码,动态二进制检测似乎是测量基本块代码覆盖率的唯一选择。
这里的问题是动态二进制检测似乎会产生无法接受的开销。
为了证明这一点,我们用自动退出方法修补了FoxitReader,并测量了FoxitReader自动终止的时间。
- Vanilla: 1,5 seconds
- DynamoRIO: 6,4 seconds
在这里,动态二进制检测会导致近5秒的开销,这太高而导致无法执行有效的语料库蒸馏。
解决方案
由于动态二进制检测太慢而无法执行语料库蒸馏,因此必须找到另一种方法来测量基本的块代码覆盖率。这个想法包含两部分:
- 静态二进制检测
- 创建一个处理检测的自定义调试器
首先,使用断点(一个字节指令(0xcc))对目标中的每个基本块进行修补。静态补丁应用于磁盘上的二进制文件。如果执行了任何基本块,它将触发断点事件(int3),该事件可由监督调试器获取。调试器获取int3事件,并在两者中(磁盘上的二进制文件和原始字节的地址空间中的二进制文件)覆盖断点。 最后,目标的指令指针递减1并恢复执行。
下面的屏幕截图显示了检测的基本块:

通过断点,调试器很容易识别哪些基本块已被执行。
为了评估这种方法的性能,FoxitReader所有的基本块都使用断点进行修补(1778291个基本块)
在第一次迭代中,FoxitReader花了16秒然后退出。这比DynamoRIO慢了10秒。但是由于断点在磁盘上的二进制文件中被撤消,它们将永远不会再触发int3事件。因此,可以假设在第一次迭代之后,大多数断点已经被恢复,因此开销应该是合理的。
- 第一次迭代:16秒(48323个断点)
- 第二次迭代:2秒(2212个断点)
- 第三和以下:~1.5秒(断点数少)
可以看出,在第一次迭代之后,检测产生了最小的开销,但是调试器仍然能够标识任何新访问的基本块。
这种方法在主要产品上进行了测试,并在所有方面完美运行:
- Adobe Acrobat Reader
- PowerPoint
- FoxitReader
Fuzzing
通过爬取互联网收集了80,000个PDF,并将该集合最小化为220个独特的PDF,耗时约1.5天。使用此最小化设置,执行模糊测试。结果非常好,并且所有崩溃都被推送到数据库中:
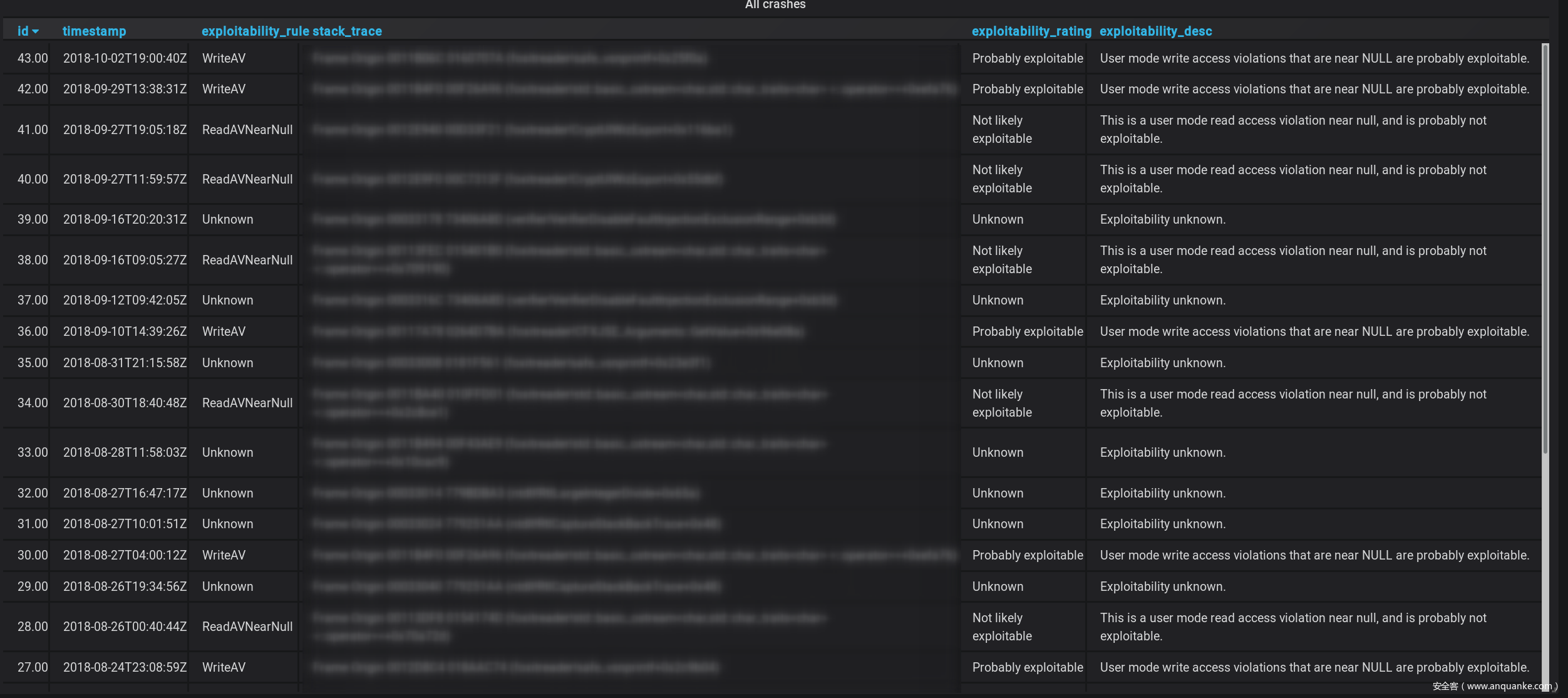
最终,Fuzzer在大约2个月的时间内发现了43个独特的崩溃,其中三个将其报告给了Zero Day Initiative。他们被分配了以下ID:
- ZDI-CAN-7423:Foxit Reader PDF解析的Out-Of-Bounds Read远程代码执行漏洞
- ZDI-CAN-7353:Foxit Reader PDF解析的Out-Of-Bounds Read信息泄露漏洞
- ZDI-CAN-7073:Foxit Reader PDF解析的Out-Of-Bounds Read信息泄露漏洞