
联名作者:gyyyy & 图南
今年先知大会上p牛分享了一些关于GraphQL安全的内容,我正好有使用GraphQL,于是想写一些我对GraphQL安全的一些理解和看法,和好基友
@gyyyy说了这个想法之后一拍即合,于是联手写了这篇文。我俩水平有限,不足之处请批评指正。
说在前面的话
本文以GraphQL中一些容易让初学者与典型Web API(为了便于理解,下文以目前流行的RESTful API为例代指)混淆或错误理解的概念特性进行内容划分,由@gyyyy 从安全的角度抛出GraphQL应该注意的几点安全问题,而我则会更多的从开发的角度给出自己在实际使用过程中总结的最佳实践。
另外,需要提前声明的是,本文中我使用的是Node.js,@gyyyy 使用的后端开发语言是Go,前端统一为React(GraphQL客户端为Apollo),请大家自行消化。
Let’s Go!
GraphQL简介
有些同学是不是根本没听过这个玩意?我们先来看看正在使用它的大客户们:

是不是值得我们花几分钟对它做个简单的了解了?XD
什么是GraphQL
简单的说,GraphQL是由Facebook创造并开源的一种用于API的查询语言。

再引用官方文案来帮助大家理解一下GraphQL的特点:
1.请求你所要的数据,不多不少
向你的API发出一个GraphQL请求就能准确获得你想要的数据,不多不少。GraphQL查询总是返回可预测的结果。使用GraphQL的应用可以工作得又快又稳,因为控制数据的是应用,而不是服务器
2.获取多个资源,只用一个请求
GraphQL查询不仅能够获得资源的属性,还能沿着资源间引用进一步查询。典型的RESTful API请求多个资源时得载入多个URL,而GraphQL可以通过一次请求就获取你应用所需的所有数据
3.描述所有的可能,类型系统
GraphQL基于类型和字段的方式进行组织,而非入口端点。你可以通过一个单一入口端点得到你所有的数据能力。GraphQL使用类型来保证应用只请求可能的数据,还提供了清晰的辅助性错误信息
GraphQL核心组成部分
1.Type
用于描述接口的抽象数据模型,有Scalar(标量)和Object(对象)两种,Object由Field组成,同时Field也有自己的Type
2.Schema
用于描述接口获取数据的逻辑,类比RESTful中的每个独立资源URI
3.Query
用于描述接口的查询类型,有Query(查询)、Mutation(更改)和Subscription(订阅)三种
4.Resolver
用于描述接口中每个Query的解析逻辑,部分GraphQL引擎还提供Field细粒度的Resolver
(想要详细了解的同学请阅读GraphQL官方文档)
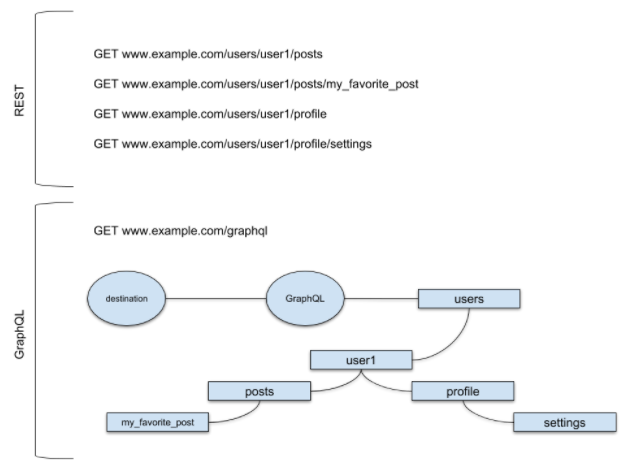
GraphQL VS. RESTful
GraphQL没有过多依赖HTTP协议,它有一套自己的解析引擎来帮助前后端使用GraphQL查询语法。同时它是单路由形态,查询内容完全根据前端请求对象和字段而定,前后端分离较明显。
用一张图来对比一下:
身份认证与权限控制不当
@gyyyy:
前面说到,GraphQL多了一个中间层对它定义的查询语言进行语法解析执行等操作,与RESTful这种充分利用HTTP协议本身特性完成声明使用的API设计不同,Schema、Resolver等种种定义会让开发者对它的存在感知较大,间接的增加了对它理解的复杂度,加上它本身的单路由形态,很容易导致开发者在不完全了解其特性和内部运行机制的情况下,错误实现甚至忽略API调用时的授权鉴权行为。
在官方的描述中,GraphQL和RESTful API一样,建议开发者将授权逻辑委托给业务逻辑层:
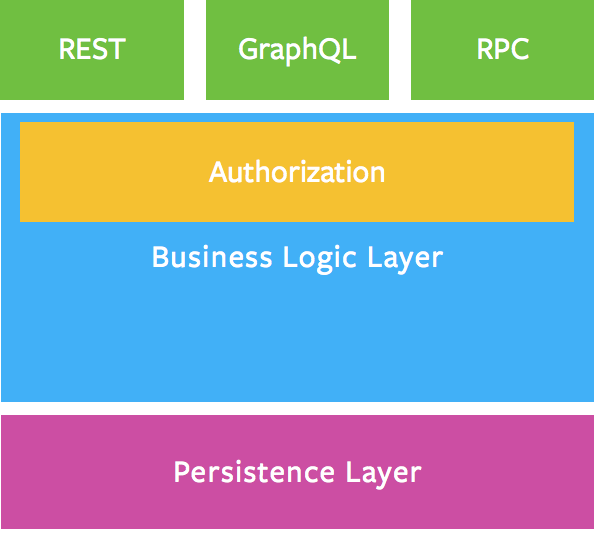
在没有对GraphQL中各个Query和Mutation做好授权鉴权时,同样可能会被攻击者非法请求到一些非预期接口,执行高危操作,如查询所有用户的详细信息:
query GetAllUsers {
users {
_id
username
password
idCard
mobilePhone
email
}
}
这几乎是使用任何API技术都无法避免的一个安全问题,因为它与API本身的职能并没有太大的关系,API不需要背这个锅,但由此问题带来的并发症却不容小觑。
信息泄露
对于这种未授权或越权访问漏洞的挖掘利用方式,大家一定都很清楚了,一般情况下我们都会期望尽可能获取到比较全量的API来进行进一步的分析。在RESTful API中,我们可能需要通过代理、爬虫等技术来抓取API。而随着Web 2.0时代的到来,各种强大的前端框架、运行时DOM事件更新等技术使用频率的增加,更使得我们不得不动用到如Headless等技术来提高对API的获取覆盖率。
但与RESTful API不同的是,GraphQL自带强大的内省自检机制,可以直接获取后端定义的所有接口信息。比如通过__schema查询所有可用对象:
{
__schema {
types {
name
}
}
}
通过__type查询指定对象的所有字段:
{
__type(name: "User") {
name
fields {
name
type {
name
}
}
}
}
这里我通过graphql-go/graphql的源码简单分析一下GraphQL的解析执行流程和内省机制,帮助大家加深理解:
- GraphQL路由节点在拿到HTTP的请求参数后,创建
Params对象,并调用Do()完成解析执行操作返回结果:params := graphql.Params{ Schema: *h.Schema, RequestString: opts.Query, VariableValues: opts.Variables, OperationName: opts.OperationName, Context: ctx, } result := graphql.Do(params) - 调用
Parser()把params.RequestString转换为GraphQL的AST文档后,将AST和Schema一起交给ValidateDocument()进行校验(主要校验是否符合Schema定义的参数、字段、类型等) - 代入AST重新封装
ExecuteParams对象,传入Execute()中开始执行当前GraphQL语句
具体的执行细节就不展开了,但是我们关心的内省去哪了?原来在GraphQL引擎初始化时,会定义三个带缺省Resolver的元字段:
SchemaMetaFieldDef = &FieldDefinition{ // __schema:查询当前类型定义的模式,无参数
Name: "__schema",
Type: NewNonNull(SchemaType),
Description: "Access the current type schema of this server.",
Args: []*Argument{},
Resolve: func(p ResolveParams) (interface{}, error) {
return p.Info.Schema, nil
},
}
TypeMetaFieldDef = &FieldDefinition{ // __type:查询指定类型的详细信息,字符串类型参数`name`
Name: "__type",
Type: TypeType,
Description: "Request the type information of a single type.",
Args: []*Argument{
{
PrivateName: "name",
Type: NewNonNull(String),
},
},
Resolve: func(p ResolveParams) (interface{}, error) {
name, ok := p.Args["name"].(string)
if !ok {
return nil, nil
}
return p.Info.Schema.Type(name), nil
},
}
TypeNameMetaFieldDef = &FieldDefinition{ // __typename:查询当前对象类型名称,无参数
Name: "__typename",
Type: NewNonNull(String),
Description: "The name of the current Object type at runtime.",
Args: []*Argument{},
Resolve: func(p ResolveParams) (interface{}, error) {
return p.Info.ParentType.Name(), nil
},
}当resolveField()解析到元字段时,会调用其缺省Resolver,触发GraphQL的内省逻辑。
自动绑定(非预期和废弃字段)
GraphQL为了考虑接口在版本演进时能够向下兼容,还有一个对于应用开发而言比较友善的特性:『API演进无需划分版本』。
由于GraphQL是根据前端请求的字段进行数据回传,后端Resolver的响应包含对应字段即可,因此后端字段扩展对前端无感知无影响,前端增加查询字段也只要在后端定义的字段范围内即可。同时GraphQL也为字段删除提供了『废弃』方案,如Go的graphql包在字段中增加DeprecationReason属性,Apollo的@deprecated标识等。
这种特性非常方便的将前后端进行了分离,但如果开发者本身安全意识不够强,设计的API不够合理,就会埋下了很多安全隐患。我们用开发项目中可能会经常遇到的需求场景来重现一下。
假设小明在应用中已经定义好了查询用户基本信息的API:
graphql.Field{
Type: graphql.NewObject(graphql.ObjectConfig{
Name: "User",
Description: "用户信息",
Fields: graphql.Fields{
"_id": &graphql.Field{Type: graphql.Int},
"username": &graphql.Field{Type: graphql.String},
"email": &graphql.Field{Type: graphql.String},
},
}),
Args: graphql.FieldConfigArgument{
"username": &graphql.ArgumentConfig{Type: graphql.String},
},
Resolve: func(params graphql.ResolveParams) (result interface{}, err error) {
// ...
},
}小明获得新的需求描述,『管理员可以查询指定用户的详细信息』,为了方便(也经常会为了方便),于是在原有接口上新增了几个字段:
graphql.Field{
Type: graphql.NewObject(graphql.ObjectConfig{
Name: "User",
Description: "用户信息",
Fields: graphql.Fields{
"_id": &graphql.Field{Type: graphql.Int},
"username": &graphql.Field{Type: graphql.String},
"password": &graphql.Field{Type: graphql.String}, // 新增 用户密码 字段
"idCard": &graphql.Field{Type: graphql.String}, // 新增 用户身份证号 字段
"mobilePhone": &graphql.Field{Type: graphql.String}, // 新增 用户手机号 字段
"email": &graphql.Field{Type: graphql.String},
},
}),
Args: graphql.FieldConfigArgument{
"username": &graphql.ArgumentConfig{Type: graphql.String},
},
Resolve: func(params graphql.ResolveParams) (result interface{}, err error) {
// ...
},
}如果此时小明没有在字段细粒度上进行权限控制(也暂时忽略其他权限问题),攻击者可以轻易的通过内省发现这几个本不该被普通用户查看到的字段,并构造请求进行查询(实际开发中也经常容易遗留一些测试字段,在GraphQL强大的内省机制面前这无疑是非常危险的。如果熟悉Spring自动绑定漏洞的同学,也会发现它们之间有一部分相似的地方)。
故事继续,当小明发现这种做法欠妥时,他决定废弃这几个字段:
// ...
"password": &graphql.Field{Type: graphql.String, DeprecationReason: "安全性问题"},
"idCard": &graphql.Field{Type: graphql.String, DeprecationReason: "安全性问题"},
"mobilePhone": &graphql.Field{Type: graphql.String, DeprecationReason: "安全性问题"},
// ...接着,他又用上面的__type做了一次内省,很好,废弃字段查不到了,通知前端回滚查询语句,问题解决,下班回家(GraphQL的优势立刻凸显出来)。
熟悉安全攻防套路的同学都知道,很多的攻击方式(尤其在Web安全中)都是利用了开发、测试、运维的知识盲点(如果你想问这些盲点的产生原因,我只能说是因为正常情况下根本用不到,所以不深入研究基本不会去刻意关注)。如果开发者没有很仔细的阅读GraphQL官方文档,特别是内省这一章节的内容,就可能不知道,通过指定includeDeprecated参数为true,__type仍然可以将废弃字段暴露出来:
{
__type(name: "User") {
name
fields(includeDeprecated: true) {
name
isDeprecated
type {
name
}
}
}
}
而且由于小明没有对Resolver做修改,废弃字段仍然可以正常参与查询(兼容性惹的祸),故事结束。
正如p牛所言,『GraphQL是一门自带文档的技术』。可这也使得授权鉴权环节一旦出现纰漏,GraphQL背后的应用所面临的安全风险会比典型Web API大得多。
@图南:
GraphQL并没有规定任何身份认证和权限控制的相关内容,这是个好事情,因为我们可以更灵活的在应用中实现各种粒度的认证和权限。但是,在我的开发过程中发现,初学者经常会忽略GraphQL的认证,会写出一些裸奔的接口或者无效认证的接口。那么我就在这里详细说一下GraphQL的认证方式。
独立认证终端(RESTful)
如果后端本身支持RESTful或者有专门的认证服务器,可以修改少量代码就能实现GraphQL接口的认证。这种认证方式是最通用同时也是官方比较推荐的。
以JWT认证为例,将整个GraphQL路由加入JWT认证,开放两个RESTful接口做登录和注册用,登录和注册的具体逻辑不再赘述,登录后返回JWT Token:
// ...
router.post('/login', LoginController.login);
router.post('/register', LoginController.register);
app.use(koajwt({secret: 'your secret'}).unless({
path: [/^/public/, '/login', '/register']
}));
const server = new ApolloServer({
typeDefs: schemaText,
resolvers: resolverMap,
context: ({ctx}) => ({
...ctx,
...app.context
})
});
server.applyMiddleware({app});
app.listen({
port: 4000
}, () => console.log(`? Server ready at http://localhost:4000${server.graphqlPath}`),);
// ...
设置完成后,请求GraphQL接口需要先进行登录操作,然后在前端配置好认证请求头来访问GraphQL接口,以curl代替前端请求登录RESTful接口:
curl -X POST http://localhost:4000/login -H 'cache-control: no-cache' -H 'content-type: application/x-www-form-urlencoded' -d 'username=user1&password=123456'
{"message":"登录成功","token":"eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJkYXRhIjp7Il9pZCI6IjViNWU1NDcwN2YyZGIzMDI0YWJmOTY1NiIsInVzZXJuYW1lIjoidXNlcjEiLCJwYXNzd29yZCI6IiQyYSQwNSRqekROOGFQbEloRzJlT1A1ZW9JcVFPRzg1MWdBbWY0NG5iaXJaM0Y4NUdLZ3pVL3lVNmNFYSJ9LCJleHAiOjE1MzI5MTIyOTEsImlhdCI6MTUzMjkwODY5MX0.Uhd_EkKUEDkI9cdnYlOC7wSYZdYLQLFCb01WhSBeTpY"}
以GraphiQL(GraphQL开发者调试工具,大部分GraphQL引擎自带,默认开启)代替前端请求GraphQL接口,要先设置认证请求头:

在GraphQL内认证
如果GraphQL后端只能支持GraphQL不能支持RESTful,或者全部请求都需要使用GraphQL,也可以用GraphQL构造login接口提供Token。
如下面例子,构造login的Query Schema, 由返回值中携带Token:
type Query {
login(
username: String!
password: String!
): LoginMsg
}
type LoginMsg {
message: String
token: String
}
在Resolver中提供登录逻辑:
import bcrypt from 'bcryptjs';
import jsonwebtoken from 'jsonwebtoken';
export const login = async (_, args, context) => {
const db = await context.getDb();
const { username, password } = args;
const user = await db.collection('User').findOne({ username: username });
if (await bcrypt.compare(password, user.password)) {
return {
message: 'Login success',
token: jsonwebtoken.sign({
user: user,
exp: Math.floor(Date.now() / 1000) + (60 * 60), // 60 seconds * 60 minutes = 1 hour
}, 'your secret'),
};
}
}
登录成功后,我们继续把Token设置在请求头中,请求GraphQL的其他接口。这时我们要对ApolloServer进行如下配置:
const server = new ApolloServer({
typeDefs: schemaText,
resolvers: resolverMap,
context: ({ ctx }) => {
const token = ctx.req.headers.authorization || '';
const user = getUser(token);
return {
...user,
...ctx,
...app.context
};
},
});
实现getUser函数:
const getUser = (token) => {
let user = null;
const parts = token.split(' ');
if (parts.length === 2) {
const scheme = parts[0];
const credentials = parts[1];
if (/^Bearer$/i.test(scheme)) {
token = credentials;
try {
user = jwt.verify(token, JWT_SECRET);
console.log(user);
} catch (e) {
console.log(e);
}
}
}
return user
}
配置好ApolloServer后,在Resolver中校验user:
import { ApolloError, ForbiddenError, AuthenticationError } from 'apollo-server';
export const blogs = async (_, args, context) => {
const db = await context.getDb();
const user = context.user;
if(!user) {
throw new AuthenticationError("You must be logged in to see blogs");
}
const { blogId } = args;
const cursor = {};
if (blogId) {
cursor['_id'] = blogId;
}
const blogs = await db
.collection('blogs')
.find(cursor)
.sort({ publishedAt: -1 })
.toArray();
return blogs;
}
这样我们即完成了通过GraphQL认证的主要代码。继续使用GraphiQL代替前端请求GraphQL登录接口:
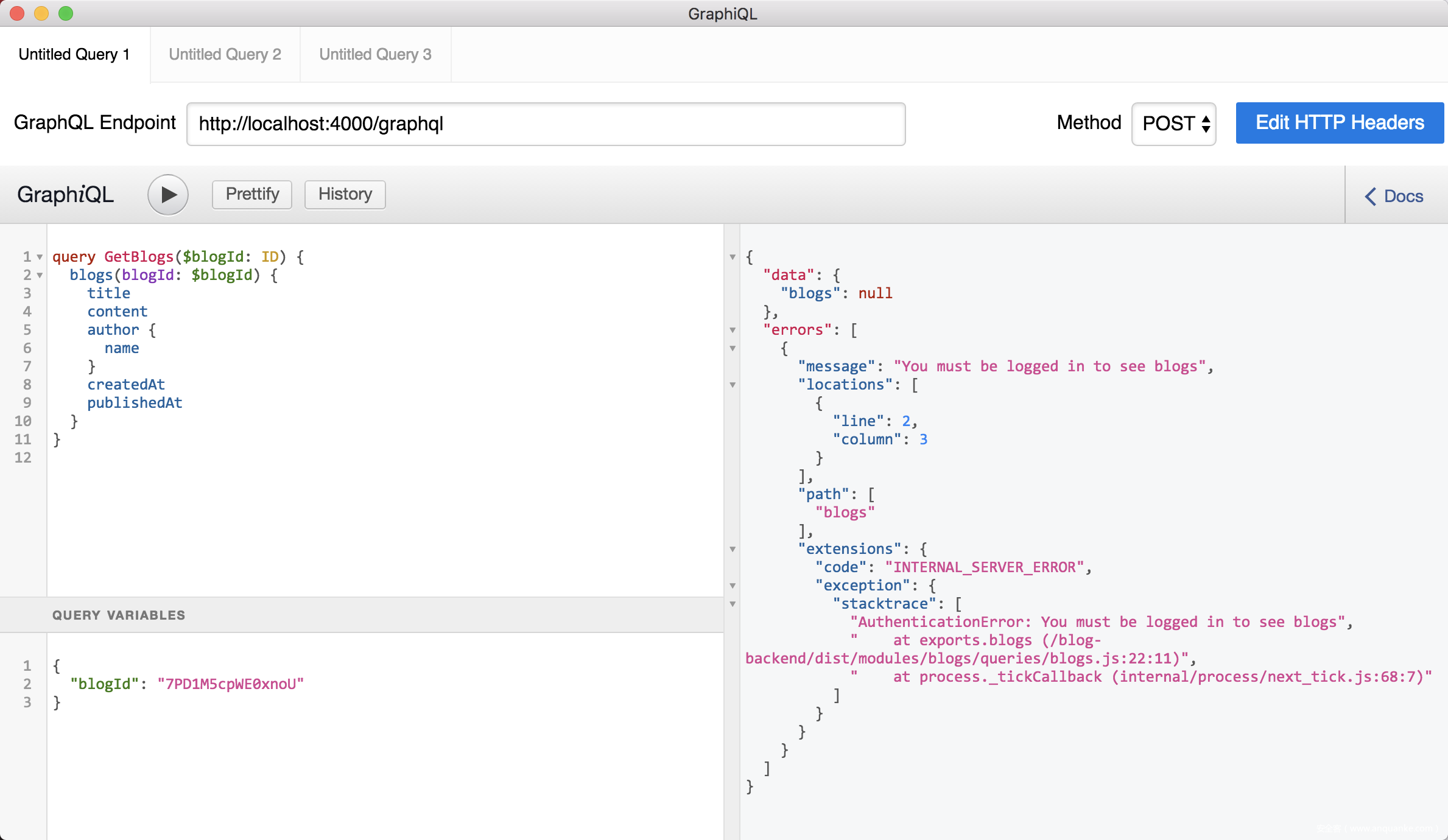](https://p3.ssl.qhimg.com/t01a24b27022e5f729a.png)
得到Token后,设置Token到请求头 完成后续操作。如果请求头失效,则得不到数据:
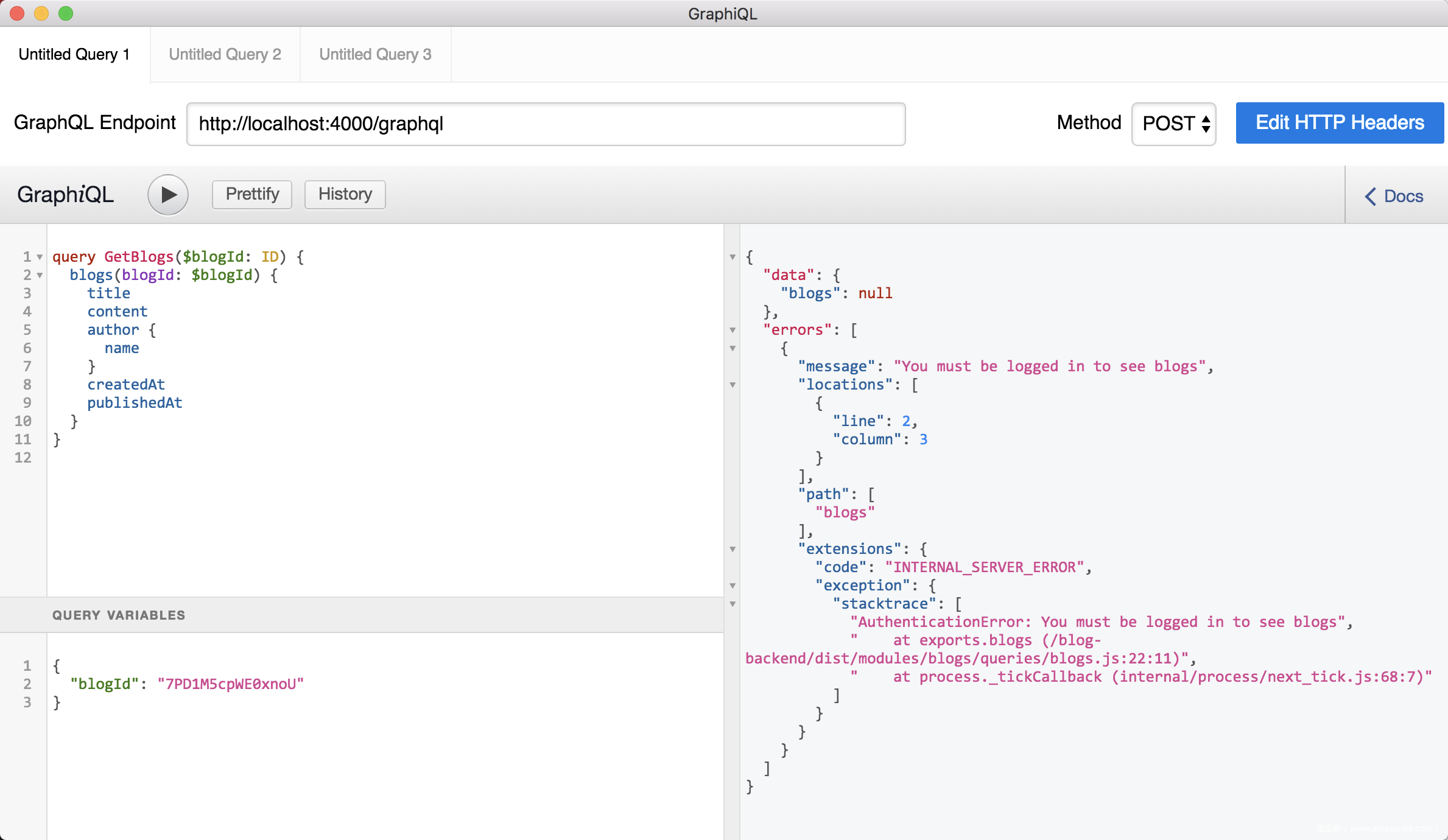
权限控制
在认证过程中,我们只是识别请求是不是由合法用户发起。权限控制可以让我们为用户分配不同的查看权限和操作权限。如上,我们已经将user放入GraphQL Sever的context中。而context的内容又是我们可控的,因此context中的user既可以是{ loggedIn: true },又可以是{ user: { _id: 12345, roles: ['user', 'admin'] } }。大家应该知道如何在Resolver中实现权限控制了吧,简单的举个例子:
users: (root, args, context) => {
if (!context.user || !context.user.roles.includes('admin'))
throw ForbiddenError("You must be an administrator to see all Users");
return User.getAll();
}
GraphQL注入
@gyyyy:
有语法就会有解析,有解析就会有结构和顺序,有结构和顺序就会有注入。
前端使用变量构建带参查询语句:
const id = props.match.params.id;
const queryUser = gql`{
user(_id: ${id}) {
_id
username
email
}
}`
name的值会在发出GraphQL查询请求前就被拼接进完整的GraphQL语句中。攻击者对name注入恶意语句:
-1)%7B_id%7Dhack%3Auser(username%3A"admin")%7Bpassword%23
可能GraphQL语句的结构就被改变了:
{
user(_id: -1) {
_id
}
hack: user(username: "admin") {
password #) {
_id
username
email
}
}
因此,带参查询一定要保证在后端GraphQL引擎解析时,原语句结构不变,参数值以变量的形式被传入,由解析器实时赋值解析。
@图南:
幸运的是,GraphQL同时提供了『参数』和『变量』给我们使用。我们可以将参数值的拼接过程转交给后端GraphQL引擎,前端就像进行参数化查询一样。
例如,我们定义一个带变量的Query:
type Query {
user(
username: String!
): User
}
请求时传入变量:
query GetUser($name: String!) {
user(username: $name) {
_id
username
email
}
}
// 变量
{"name": "some username"}
拒绝服务
@gyyyy:
做过代码调试的同学可能会注意过,在观察的变量中存在相互关联的对象时,可以对它们进行无限展开(比如一些Web框架的Request-Response对)。如果这个关联关系不是引用而是值,就有可能出现OOM等问题导致运算性能下降甚至应用运行中断。同理,在一些动态求值的逻辑中也会存在这类问题,比如XXE的拒绝服务。
GraphQL中也允许对象间包含组合的嵌套关系存在,如果不对嵌套深度进行限制,就会被攻击者利用进行拒绝服务攻击。
@图南:
在开发中,我们可能经常会遇到这样的需求:
- 查询所有文章,返回内容中包含作者信息
- 查询作者信息,返回内容中包含此作者写的所有文章
当然,在我们开发的前端中这两个接口一定是单独使用的,但攻击者可以利用这它们的包含关系进行嵌套查询。
如下面例子,我们定义了Blog和Author:
type Blog {
_id: String!
type: BlogType
avatar: String
title: String
content: [String]
author: Author
# ...
}
type Author {
_id: String!
name: String
blog: [Blog]
}
构建各自的Query:
extend type Query {
blogs(
blogId: ID
systemType: String!
): [Blog]
}
extend type Query {
author(
_id: String!
): Author
}
我们可以构造如下的查询,此查询可无限循环下去,就有可能造成拒绝服务攻击:
query GetBlogs($blogId: ID, $systemType: String!) {
blogs(blogId: $blogId, systemType: $systemType) {
_id
title
type
content
author {
name
blog {
author {
name
blog {
author {
name
blog {
author {
name
blog {
author {
name
blog {
author {
name
blog {
author {
name
blog {
author {
name
# and so on...
}
}
}
}
}
}
}
}
}
}
}
}
}
title
createdAt
publishedAt
}
}
publishedAt
}
}
避免此问题我们需要在GraphQL服务器上限制查询深度,同时在设计GraphQL接口时应尽量避免出现此类问题。仍然以Node.js为例,graphql-depth-limit就可以解决这样的问题。
// ...
import depthLimit from 'graphql-depth-limit';
// ...
const server = new ApolloServer({
typeDefs: schemaText,
resolvers: resolverMap,
context: ({ ctx }) => {
const token = ctx.req.headers.authorization || '';
const user = getUser(token);
console.log('user',user)
return {
...user,
...ctx,
...app.context
};
},
validationRules: [ depthLimit(10) ]
});
// ...
添加限制后,请求深度过大时会看到如下报错信息:
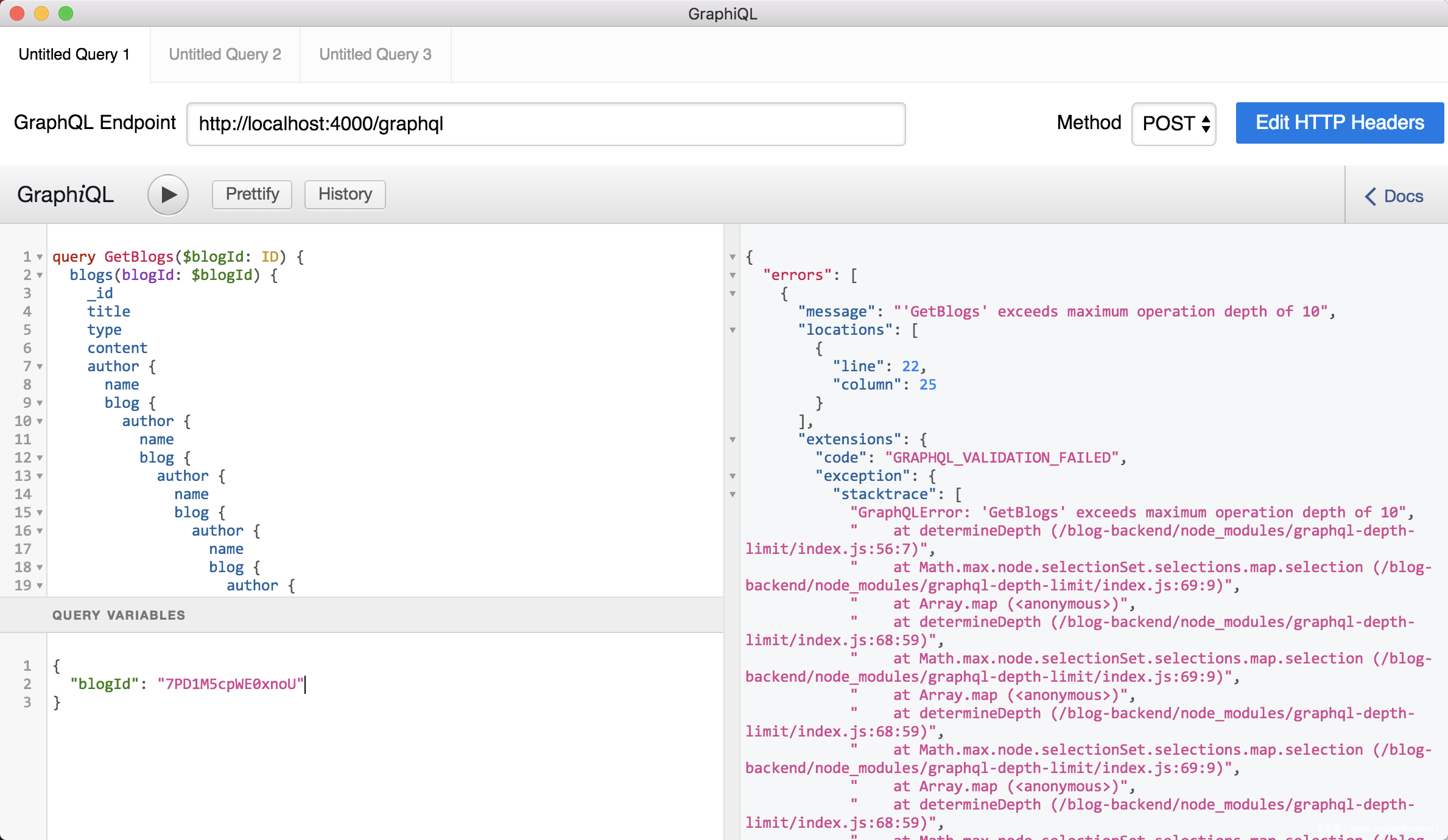
它只是个接口
@gyyyy:
作为Web API的一员,GraphQL和RESTful API一样,有可能被攻击者通过对参数注入恶意数据影响到后端应用,产生XSS、SQL注入、RCE等安全问题。此外,上文也提到了很多GraphQL的特性,一些特殊场景下,这些特性会被攻击者利用来优化攻击流程甚至增强攻击效果。比如之前说的内省机制和默认开启的GraphiQL调试工具等,还有它同时支持GET和POST两种请求方法,对于CSRF这些漏洞的利用会提供更多的便利。
当然,有些特性也提供了部分保护能力,不过只是『部分』而已。
@图南:
GraphQL的类型系统对注入是一层天然屏障,但是如果开发者的处理方式不正确,仍然会有例外。
比如下面的例子,参数类型是字符串:
query GetAllUsers($filter: String!) {
users(filter: $filter) {
_id
username
email
}
}
假如后端没有对filter的值进行任何安全性校验,直接查询数据库,传入一段SQL语句字符串,可能构成SQL注入:
{"filter": "' or ''='"}
或者JSON字符串构成NoSQL注入:
{"filter": "{"$ne": null}"}
结语
GraphQL真的只是一个API技术,它为API连接的前后端提供了一种新的便捷处理方案。无论如何,该做鉴权的就鉴权,该校验数据的还是一定得校验。
而且各GraphQL引擎在编程语言特性、实现方式等因素的影响下,都一定会有细微的差异。除了文章里提到的这些内容,还可以对每个引擎内部的执行流程、语法解析、校验和数据编解码等环节进行审计,发掘更多有意思的内容。
不过我们的文章就先到这了,感谢阅读!