
说明
360代码卫士与国家互联网应急中心CNCERT合作,对国外知名互联网公司开源软件代码的安全缺陷情况进行了分析,以下为报告全文。本文转自国家互联网应急中心CNCERT。
前言
随着软件技术飞速发展,开源软件已在全球范围内得到了广泛应用。数据显示,从2012年起,已有超过80%的商业软件使用开源软件。开源软件的代码一旦存在安全问题,必将造成广泛、严重的影响。为了解开源软件的安全情况,CNCERT持续对广泛使用的知名开源软件进行源代码安全缺陷分析,并发布季度安全缺陷分析报告。
本期报告聚焦国际知名互联网公司的软件安全开发现状,通过检测公司旗下多款开源软件产品的安全缺陷,评估各公司的代码安全控制情况。针对国际知名互联网公司,选取关注度高的开源项目,结合缺陷扫描工具和人工审计的结果,对各公司的项目安全性进行评比。
1 被测开源软件
参考Github机构排名,本期报告聚焦国际知名互联网公司Google、Facebook、Twitter,综合考虑用户数量、受关注程度等情况,选取了这些公司旗下的12款具有代表性的开源项目。本次被测的开源软件项目的概况如下:
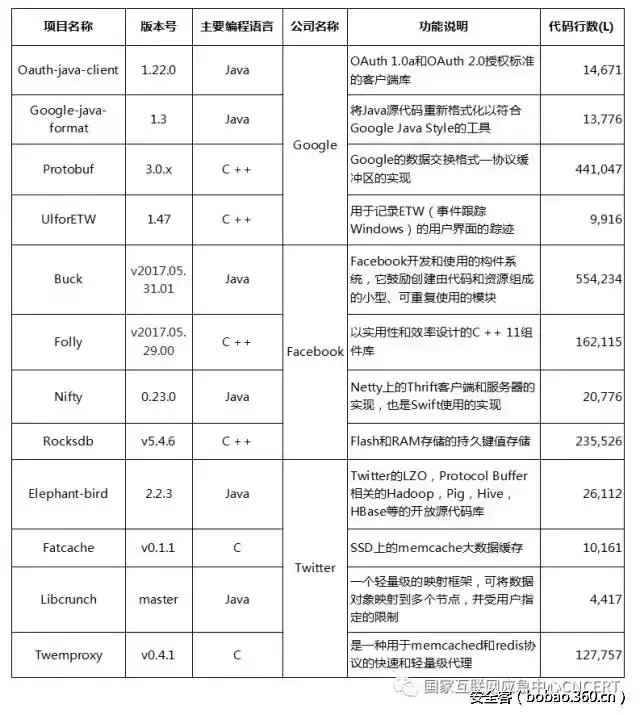
表1 被测开源软件项目概览
2 测试内容
安全缺陷种类
本次测试涵盖各类常见安全缺陷。根据缺陷形成的原因、被利用的可能性、造成的危害程度和解决的难度等因素进行综合考虑,可以将常见的安全缺陷分为八类:
1)输入验证与表示(Input Validation and Representation)
输入验证与表示问题通常是由特殊字符、编码和数字表示所引起的,这类问题的发生是由于对输入的信任所造成的。这些问题包括:缓冲区溢出、跨站脚本、SQL注入、命令注入等。
2) API误用(API Abuse)
API是调用者与被调用者之间的一个约定,大多数的API误用是由于调用者没有理解约定的目的所造成的。当使用API不当时,也会引发安全问题。
3) 安全特性(Security Features)
该类别主要包含认证、访问控制、机密性、密码使用和特权管理等方面的缺陷。
4) 时间和状态(Time and State)
分布式计算与时间和状态有关。线程和进程之间的交互及执行任务的时间顺序往往由共享的状态决定,如信号量、变量、文件系统等。与分布式计算相关的缺陷包括竞态条件、阻塞误用等。
5) 错误和异常处理缺陷(Errors)
这类缺陷与错误和异常处理有关,最常见的一种缺陷是没有恰当的处理错误(或者没有处理错误)从而导致程序运行意外终止,另一种缺陷是产生的错误给潜在的攻击者提供了过多信息。
6) 代码质量问题(Code Quality)
低劣的代码质量会导致不可预测的行为。对于攻击者而言,低劣的代码使他们可以以意想不到的方式威胁系统。常见的该类别缺陷包括死代码、空指针解引用、资源泄漏等。
7) 封装和隐藏缺陷(Encapsulation)
合理的封装意味着区分校验过和未经检验的数据,区分不同用户的数据,或区分用户能看到和不能看到的数据等。常见的缺陷包括隐藏域、信息泄漏、跨站请求伪造等。
8) 代码运行环境的缺陷(Environment)
该类缺陷是源代码之外的问题,例如运行环境配置问题、敏感信息管理问题等,它们对产品的安全仍然是至关重要的。
前七类缺陷与源代码中的安全缺陷相关,它们可以成为恶意攻击的目标,一旦被利用会造成信息泄露、权限提升、命令执行等严重后果。最后一类缺陷描述实际代码之外的安全问题,它们容易造成软件的运行异常、数据丢失等严重问题。
安全缺陷级别
我们将源代码的安全问题分为三种级别:高危(High)、中等(Medium)和低(Low)。衡量级别的标准包括两个维度,置信程度(confidence)和严重程度(severity)。置信程度是指发现的问题是否准确的可能性,比如将每个strcpy函数调用都标记成缓冲区溢出缺陷的可信程度很低。严重程度是指假设测试技术真实可信的情况下检出问题的严重性,比如缓冲区溢出通常是比变量未初始化更严重的安全问题。将这两个因素综合起来可以准确的为安全问题划分级别,如下图所示:
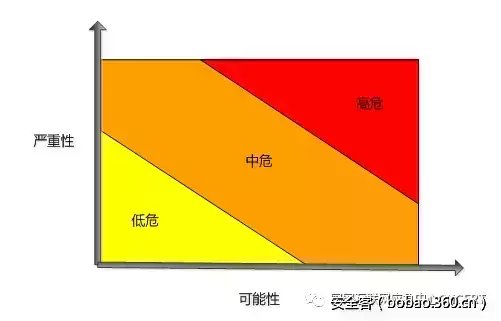
图1 缺陷级别与严重程度、置信程度的关系
3 开源软件项目的安全缺陷情况
本报告仅针对检出的高危、中危缺陷进行统计和分析。本部分首先展示从被测项目中检出安全缺陷的数量,并由此对三大互联网公司的产品安全性进行比较。然后进一步讨论各公司被测项目中安全缺陷的分布情况,了解各公司出现较多的缺陷类型。
安全缺陷情况概况
本部分展示被测项目查出缺陷的数量,由此对被测项目的安全性进行大致的评估。图2展示了各个项目高危、中危缺陷的数量,并按照高危缺陷数量对项目进行了排序,图中用蓝色折线图展示了每千行包含缺陷数。
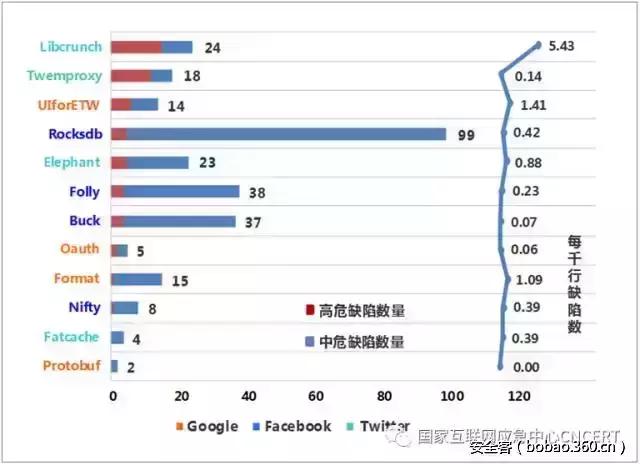
图2 开源软件项目缺陷情况
在本次被测软件中,来自Google的Protobuf(协议缓冲区)、来自Twitter的Fatcache(大数据缓存)不存在高危缺陷,同时中危缺陷的数量也相对较少。
来自Twitter的映射框架Libcrunch的高危缺陷数量居多,在15个高危缺陷中,存在9个路径遍历问题,5个空指针解引用缺陷和1个硬编码密码缺陷。
中高危缺陷总数最多的是来自Facebook的Rocksdb(持久键值存储库),包含94个中危缺陷,其中绝大多数也为代码质量类问题。例如,包含55个“类的构造函数未对成员进行初始化”缺陷,32个“位运算的两个操作数比特位数不同”缺陷。这些缺陷可能会导致程序发生不可预知的行为,甚至造成安全隐患,应当尽量避免。
由于项目的绝对缺陷数量可能与项目大小相关,因此本报告计算了每千行缺陷数,用该数据反映缺陷在项目中的分布密度。根据该数据,代码安全性最好的项目依次是来自Google的Protobuf(0.00)、Oauth-java-client(0.06)、来自Facebook的Buck(0.07),这些软件的每一千行代码的平均安全缺陷数量小于0.1个。而缺陷分布密度相对较高的项目是来自Twitter的Libcrunch(5.43)、来自Google的UlforETW(1.41)和Google-java-format(1.09),这些软件的每一千行代码平均包含 1个以上的安全缺陷。
各公司产品安全性对比
本部分对不同互联网公司的产品安全性概况进行对比,图3展示了每个公司在本次测试中检测出的高危、中危缺陷总数,以及以公司为单位统计的每千行缺陷数 。
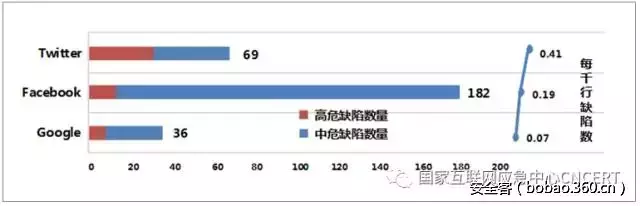
图3 互联网公司产品安全性对比图
由于每个公司的项目被检测出缺陷的绝对数量与项目数量、项目大小相关,不能直接反映公司的产品安全性,因此本部分重点关注每千行缺陷数。根据该数据,Google的总体产品安全性较高,平均每一千行代码仅包含0.07个安全缺陷。Twitter的总体产品安全性在3个公司中较差,平均每千行缺陷数量是Google本次抽样产品的近6倍。
各公司高危缺陷分布情况
本部分展示各公司高危缺陷的分布情况,了解各公司出现较多的高危缺陷类型。如图4所示,各公司的高危缺陷分布情况不尽相同。其中,普遍出现较多的高危缺陷是被污染的缓冲区 和空指针解引用。表2和表3分别列出了这两种缺陷在各公司项目中的分布情况。
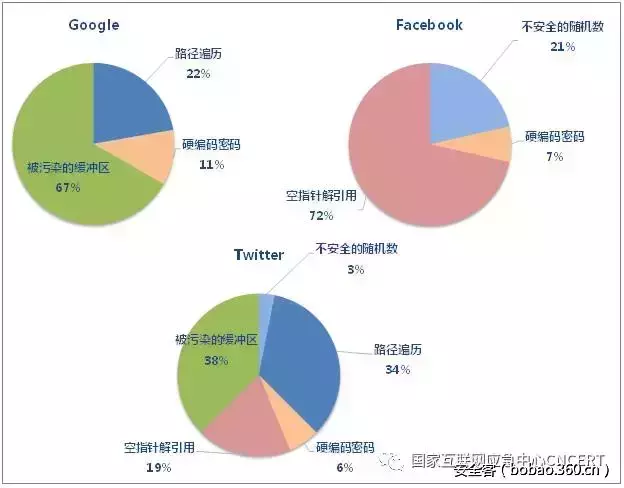
图4 各公司高危缺陷分布情况
表2 高危被污染的缓冲区分布情况

表3 高危空指针解引用分布情况

各公司中危缺陷分布情况
本部分继续展示各公司中危缺陷的分布情况,了解各公司出现较多的中危缺陷类型。如图5、图6、图7所示,各公司的中危缺陷分布情况不尽相同。由于中危缺陷的数量较多,为了方便展示,将仅出现1次的缺陷类型统一归入“其他”。
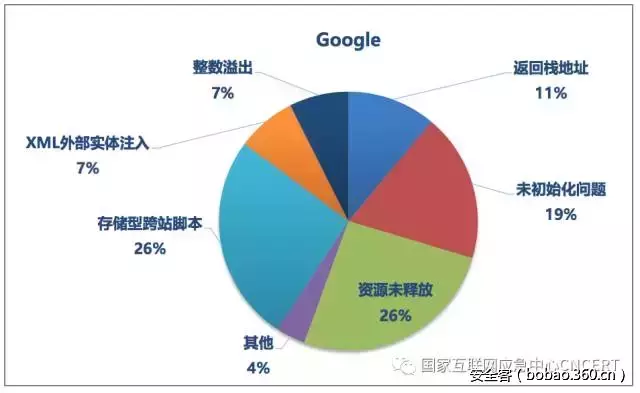
图5 Google中危缺陷分布情况
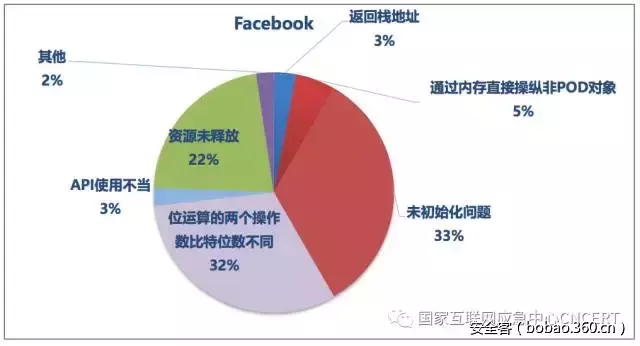
图6 Facebook中危缺陷分布情况
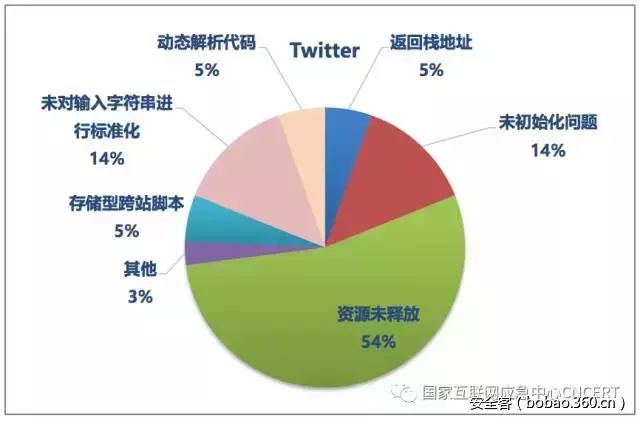
图7 Twitter中危缺陷分布情况
正如前文所述,3个公司软件的中危缺陷绝大多数都为代码质量类问题,而普遍出现较多的两类缺陷分别是“变量或参数等使用前未进行初始化”和“资源未及时释放”,也均属于代码质量类问题,这些缺陷虽然不易直接被攻击者利用,但确实会造成程序运行不稳定、性能下降甚至崩溃等问题。表4和表5分别列出了这两种缺陷在各公司项目中的分布情况。
表4 中危未初始化问题分布情况

表5 中危资源未释放缺陷分布情况

4 关于本报告的说明
1、本报告仅从代码角度进行缺陷分析。本报告中统计的缺陷是指由于代码编写不规范导致的有可能被攻击者利用的安全隐患。在实际系统中,由于软件实际部署环境、安全设备等的限制,部分缺陷可能无法通过渗透测试得到验证。
2、本报告中的缺陷仅适用于表1中列出的特定软件版本。当软件版本有任何更新、修改和优化时,本报告不再适用。
3、本报告由360代码卫士团队提供部分技术支持。