
19年的时候写过好多fuzzer原理分析和实践的文章,很长一段时间没搞,前一阵子挖洞的重心才又开始转向fuzz。研究pe-afl的时候写了一点笔记,发出来和大家交流交流。
pe-afl是通过静态插桩实现针对Windows闭源程序的覆盖引导的fuzzer,由Lucas Leong在BlueHat IL 2019上发布。
代码:https://github.com/wmliang/pe-afl
Video:https://www.youtube.com/watch?v=OipNF8v2His
使用方法还是比较清晰明了的。比如说想要fuzz msjet40.dll,使用方法是首先在IDA中打开msjet40.dll,运行ida_dumper.py得到msjet40.dll.dump.txt,再运行python pe-afl.py -m msjet40.dll msjet40.dll.dump.txt得到插桩后的msjet40.instrumented.dll,用它替换掉原来的msjet40.dll,然后就可以用修改后的AFL.exe fuzz了。
作者最新发布的是一个支持IDA 7.2的版本。目前不支持fuzz 64位程序,并且因为插桩是针对VS编译的二进制文件做的,所以如果目标二进制文件是用其他方式编译的可能会失败。
我们先看看ida_dumper.py。这里用的ida_dumper.py来自https://github.com/assafcarlsbad/pe-afl/blob/master/ida_dumper.py,以便能够兼容IDA 7.4的API。当然你也可以改一下IDA的配置文件让它兼容之前的API。
调用ida_dumper.py得到的xxx.dumper.txt中有以下数据:
rip_inst列表,暂时没有用到。
idata列表,可执行的idata段。
bb列表,识别基本块basic block的方法是将条件跳转的下一条指令地址和跳转的目的地址加入bb列表,最后去重排序。
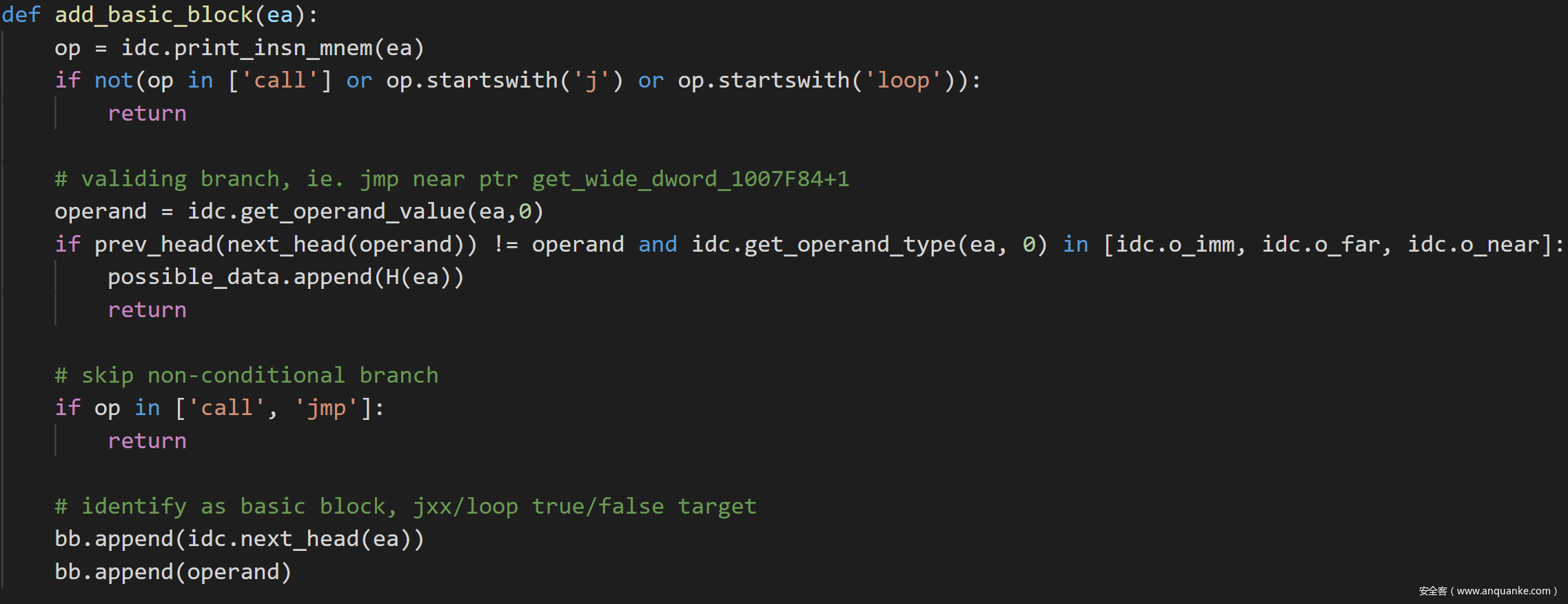
relative字典,key是条件跳转指令的地址,value是跳转的目的地址,操作码,操作数长度,操作码和操作数总长度。例如对于0x40E00B处的这条指令,key是0x40E00B,value是0x40DFE0,0x74(JZ),1,2。
stk_frame字典,查找mov edi,edi,push ebp,mov ebp,esp,sub esp,XXXh这样的代码,key是代码的地址,value是最后一条sub esp,XXXh指令的长度和XXX的值。例如对于下面这样的代码,key就是0x40C973,valve就是3和0x20。

code_loc字典,因为通常会出现代码和数据混合的情况,所以需要标记代码的位置,key是指令的开始,valve是指令的结束。例如对于下面这样的代码,key就是0x4028FC,valve就是0x402913。

接下来看看pe-afl.py。主要是调用了instrument.py中的inject_code注入代码。对于每一个bb列表中的地址,注入的代码如下所示:

来看看instrument.py,分析一下具体是怎么实现的。首先是一些初始化的工作,移除DOS_STUB,移除数字签名,为text段新建一个raw属性,存放其中的数据。
接下来看到process_pe函数,首先是新建.cov段和.tex2段。
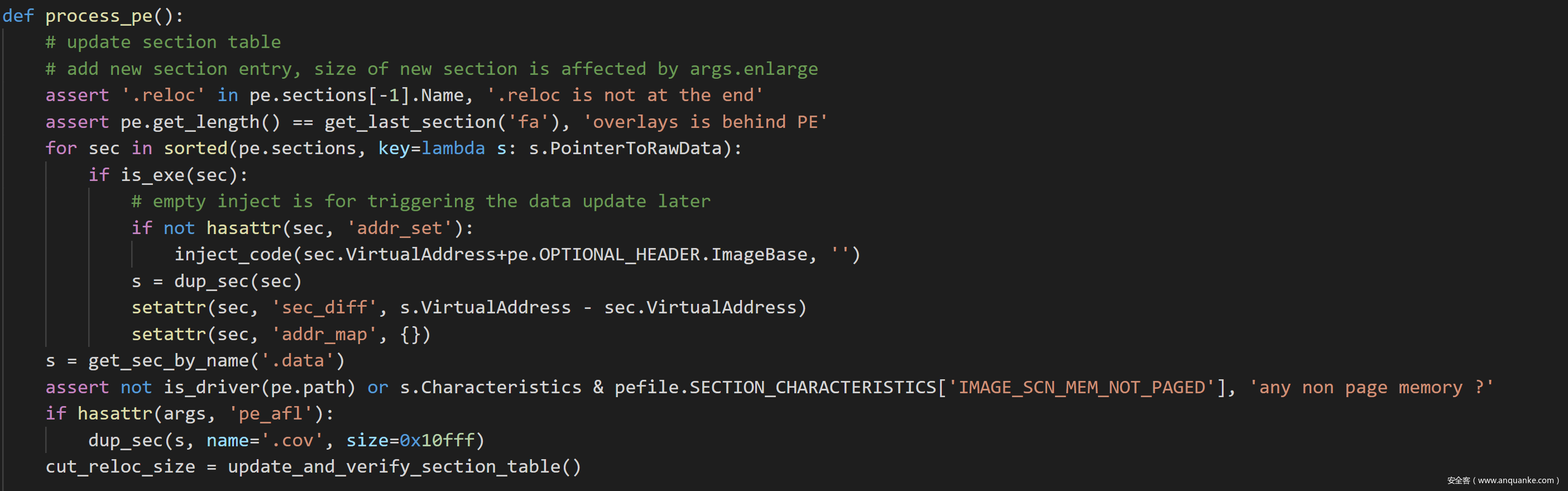
创建的新段是放在.reloc段之前的。创建的时候是直接创建在最后,全部创建完了再修改.reloc段的属性。

用cff explorer看看原始文件的段和插桩之后的段。
我们可以看到在代码中给text段设置了三个属性,addr_set,addr_map和sec_diff。sec_diff是tex2段和text段虚拟地址之间偏移,addr_set是需要插入代码在文件中的位置的列表,addr_map是一个集合,key就是addr_set中的成员,valve的两个值加起来是i+diff+tlen,也就是插入代码之后在文件中的位置。


接下来需要将short jmp扩展成long jmp,因为我们插入了代码之后地址偏移增加很有可能就会出现short jmp用不了的情况。
首先是得到一个jmp_map字典,对于一条短跳转指令,将指令所在地址作为valve,指令所在地址和跳转目的地址之间的地址作为key。如果有一个key的地址需要插入指令,那么就把对应的valve加入expand_list。还要再遍历expand_list,如果其中的一个短跳转指令所在的地址正好也在另外一个短跳转指令所在地址和跳转目的地址之间,那么另外这个短跳转指令所在地址也需要加入expand_list。对于这些指令添加0x00占位。
继续之前先看一下几个相关的函数。首先是get_text_diff和get_data_diff,他们的参数分别是代码和数据在文件中的位置,这两个函数含义就是获得插桩后的位置相对于原来位置的偏移(不计算段的偏移)。

然后是get_relative_diff函数,参数是跳转指令和目标地址在文件中的位置,返回他们之间的偏移。考虑两种情况,在同一个段和不在同一个段。
在同一个段diff的计算方法是:
diff = get_text_diff(to_fa) – get_text_diff(from_fa)
即插桩后两者之间新增的偏移。
不在同一个段diff的计算方法是:
diff = (to_fa+get_text_diff(to_fa)-to_s.PointerToRawData) – (from_fa+get_text_diff(from_fa)-from_s.PointerToRawData)
即两者插桩后的位置相对于段的偏移的差。
对于在同一个段的情况返回to_fa + diff,减去from_fa就是即插桩后两者之间新增的偏移加上原来的偏移,即插桩后两者之间的偏移。
对于不在同一个段的情况返回from_fa + diff + sec_diff,减去from_fa就是两者插桩后的位置相对于段的偏移的差加上段的偏移,即插桩后两者之间的偏移。
听上去有点绕,特别是不在同一个段的情况,画个图应该就能明白了。
然后就可以用这个算出来的偏移更新跳转指令。
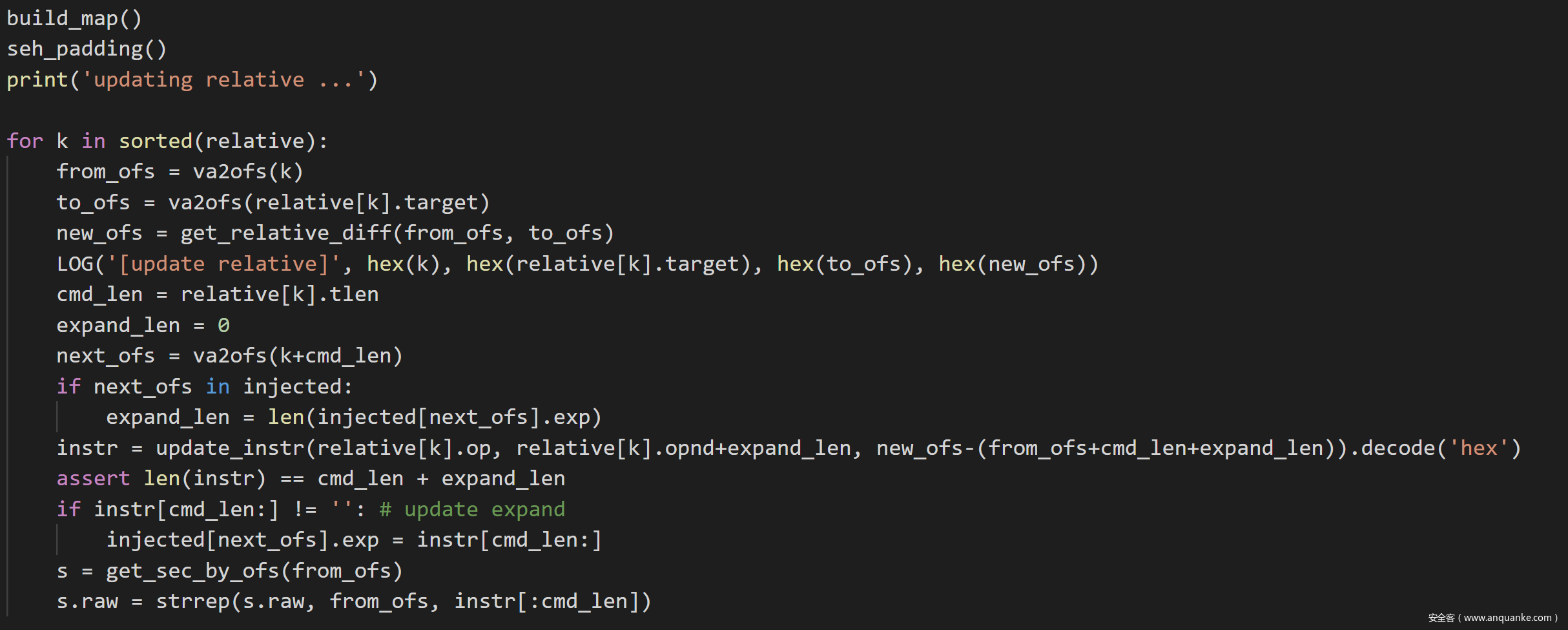
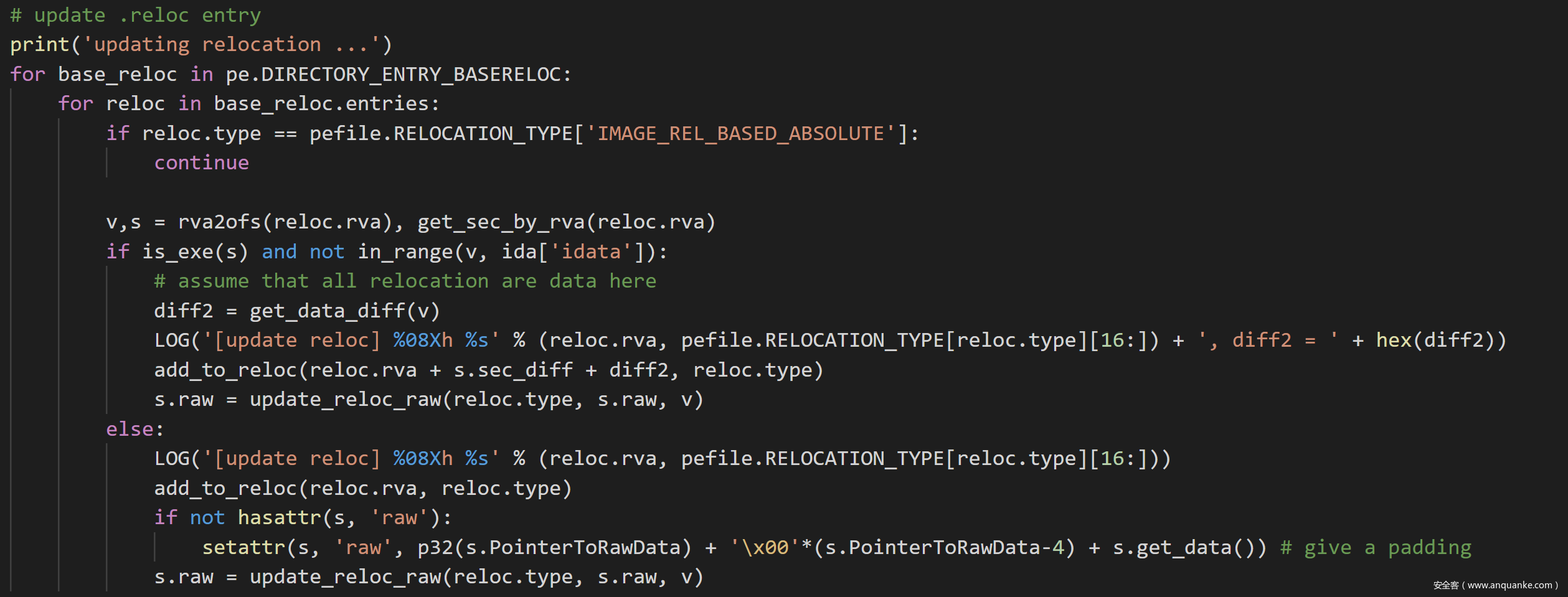
接下来调用add_to_reloc把需要重定位的地址加到新建的重定位表updated_reloc,调用update_reloc_raw更新需要重定位的地址中的数据。分两种情况,如果是text段中需要重定位的地址,因为有插桩的数据,所以新的位置要把偏移加上;如果是其它段比如rdata段中需要重定位的地址,因为没有插桩的数据,所以就不用。
更新插桩的数据中的M_PREV_LOC1,M_AREA_PTR和M_PREV_LOC2。M_PREV_LOC1和M_PREV_LOC2是新建的.cov段的末尾,M_AREA_PTR是新建的.cov段的开始。
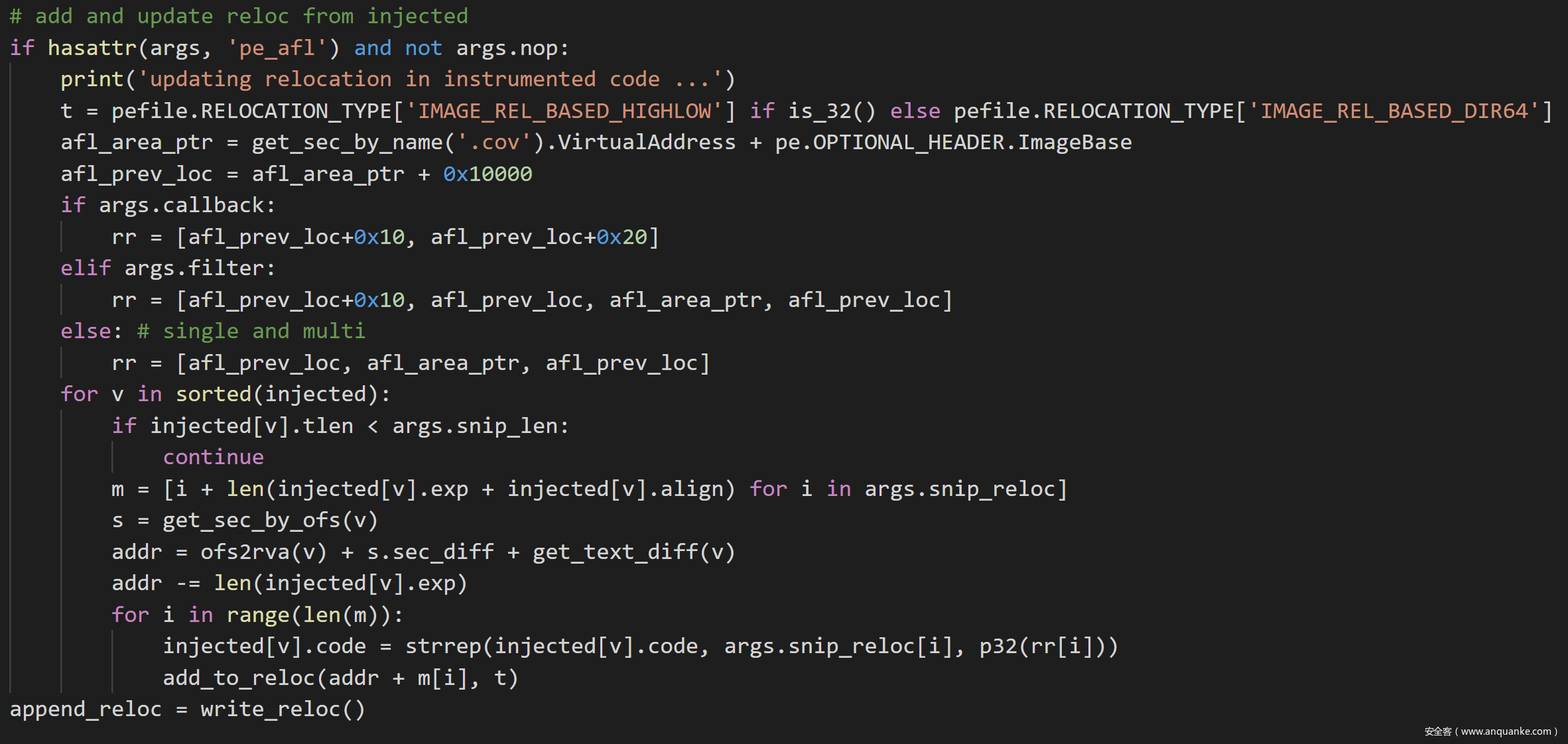
最后就是将数据添加到append,更新导出表/CFG表/SEH表等等,然后写进新的xxx.instrumented.dll/exe。

一些剩下的改动就无需再解释了,这样效果就相当于用AFL fuzz有源码的程序,在编译时插桩。当然不只是fuzz,我觉得对恶意代码分析这个项目也是有一些借鉴意义的,遇到一些复杂的混淆可能需要我们调整乱序的代码,删除垃圾指令等等,也可以用这里面的代码试试。因为我之前做恶意代码分析的时候也用python写过类似的代码,但是本人编程水平不怎么样,写的代码很糟糕,如果当时有pe-afl的话参考这里面的代码应该是能减少一些工作量的。至于具体fuzz效果怎么样我也还没来得及研究,有接触过的同学可以多多交流交流。