
整个中文网络对semgrep的信息之少,竟然只找到一篇内容还过得去的文章:介绍semgrep扫描xss漏洞,而且读起来还像是翻译的。这般待遇实在是与semgrep的强大和在国外的流行完全匹配不上,再加上近期团队做安全编码规范的配套扫描工具建设,从而催生了本文。
简介
semgrep是一款基于Facebook开源SAST工具pfff中的sgrep组件开发的开源SAST工具,目前由安全公司r2c统一开发维护,走的是开源共建模式,主打轻量、定制化,slogan是Static analysis at ludicrous speed, Find bugs and enforce code standards(以极致的速度扫描发现bug并强化代码规范的落地)
原理
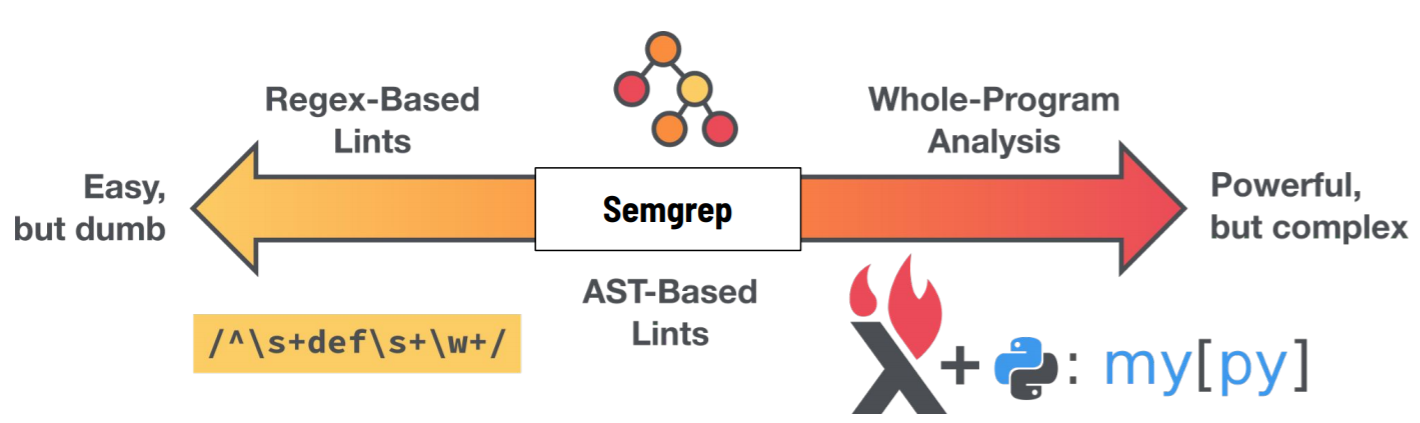
semgrep同时支持正则匹配和AST分析两种模式,跟国内前些年流行的开源SAST工具cobra原理比较相近,从技术演进的方向上看,semgrep大致位于中间地带:
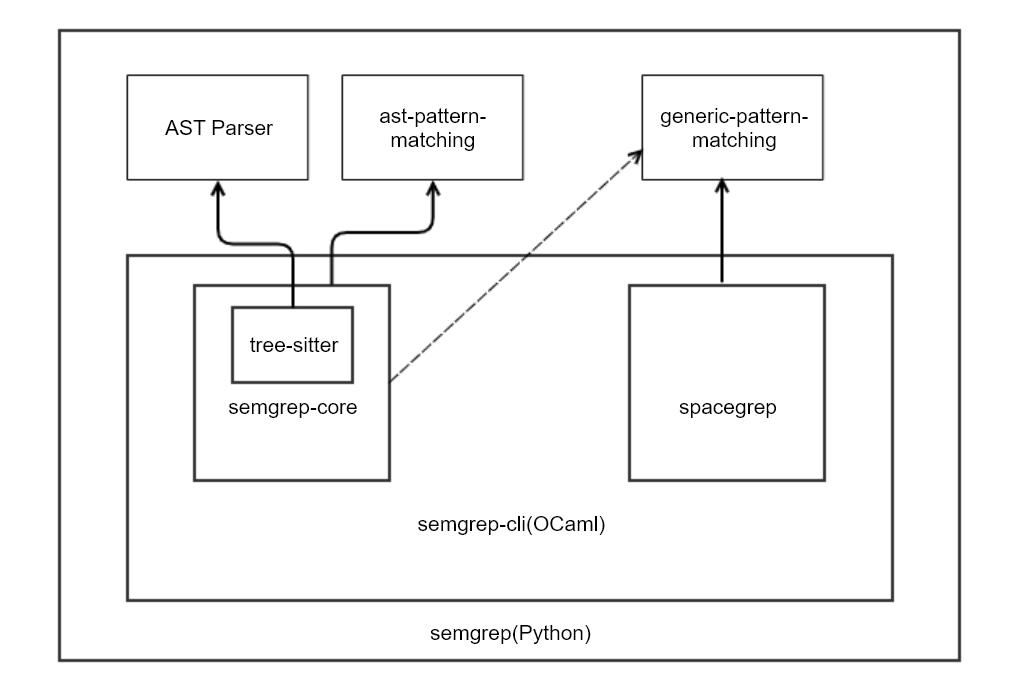
如下图所示,扫描器核心逻辑在semgrep-core,可以看到工具主要是由OCaml语言开发,然后通过python执行系统命令去调用semgrep-core,关于semgrep-core的具体实现另文介绍。
优点
- 支持语言丰富:目前已经支持go、java、js、python等17+种开发语言
- 开源扫描规则丰富:由社区共同开发维护的扫描规则超过1000条,完全覆盖各种主流开发语言的owasp top10相关漏洞。与此同时,也有多款开源SAST工具的扫描规则已经迁移到semgrep之上,例如gosec、nodejsscan、bandit等;
- 内置大量流行框架或ORM的支持
| 语言 | 框架 | 支持情况 |
|---|---|---|
| python | django/flask/boto/sqlalchemy | 一般 |
| java | spring | 较好 |
| go | gorilla/grpc/pgorm(目前我们还实现了xorm) | 一般 |
| js/tx | express/nest/vue/react/angular/sequelize | 一般 |
| php | laravel | 一般 |
| 其他 | … | 几乎没有 |
- 规则定制极简:采用
yaml配置文件编写扫描规则,语法简单,其中的核心语法不仅简单,而且表现能力非常强大,目前规则极少超过100行,通常只使用官方规则集r2c-security-audit即可; - 扫描极快:官方称扫描速度大约是每条规则20K-100K loc/sec,但他们正在优化以实现更高的扫描速度。
- 支持本地扫描:官方不仅提供了VSCode、IntelliJ IDEA、Vim的相关插件,还支持通过pre-commit的方式在代码提交前进行自动扫描。与此同时,更支持了docker扫描的方式。
- 生态良好:支持嵌入到几乎所有CI工具中。此外,semgrep也被多款知名开源SAST工具作为底层扫描引擎,例如nodejsscan、DefectDojo等。
- 支持自动修复:通过
AutoFix语法可自动修复存在安全风险的代码。 - 支持hook script对扫描结果进行增强:对于无法使用规则定制的方式进行扫描的问题可以通过python的hook script实现自己的扫描逻辑
缺点
数据流跟踪能力较弱:污点跟踪、常量传播等特性不强,目前还在实验阶段,且不支持过程间分析。
控制流分析能力较弱:虽然内置了一定的过滤器Sanitizer识别逻辑,但目前未明确介绍,需要看代码了解具体实现,例如在puppeteer任意跳转漏洞检测时,如果对传入的URL进行校验,一定程度上是可以识别,稍作改变即识别不出:

// ruleid:puppeteer-goto-injection
// modified for fp test
if (isValidUrl(userInput)) {
const newUrl = userInput;
} else {
const newUrl = ‘https://example.com‘;
// const newUrl = userInput;
}
// const newUrl = userInput;
await page.goto(newUrl);- 语言框架还不够多,特别是国内流行的开发框架,而且对框架缺乏系统性的支持:通常使用hardcode框架关键类、方法、属性等方法,再结合元变量
MetaVariables和省略号...来实现数据流跟踪能力,例如检测Django是否关闭csrf检测:
pattern: |
@django.views.decorators.csrf.csrf_exempt
def $R(...):
...
- 在漏洞检测上倾向于更多的发现不安全的写法:例如对于采用
select info from table where id=%d" % (request.id)的写法,尽管可以通过pattern-not-regrex的方式进行二次校验,但工具层面认为不符合安全编码标准,应当报出。
与其他SAST工具和Linter的区别
相信看了上面的介绍后,很多人会认为semgrep更像是一款很像SAST工具的Linter,但是谁又能说两者一定有严格的界限呢?例如用eslint或者pylint扫描安全风险的太常见了,所以下面也将从官方FAQ中针对这块稍作介绍,主要列举与SonarQube、CodeQL的对比。

测试
近期我们团队在对PCG开源代码仓库做安全编码规范扫描,目前已使用codeql编写了go sql拼接的相关规则,当时为了验证semgrep的扫描效果,我们也针对部分使用xorm框架的业务做了对比评测,涉及5套代码仓库、10万行代码,最终测试结果如下,可以发现semgrep在编码安全规范扫描这块的总体效果更好,已知问题还是准确率比codeql稍低一点,但也在95%以上。

规则定制难度
根据大概估算,查找、理解xorm sql执行的sink点大概需要20分钟,编写xorm拼接靶场代码需要20分钟,加上编写规则15分钟,全程花费在1个小时左右,而使用codeql开发,单纯编写规则就要0.5个人天,可以看到semgrep规则开发成本非常低。
准召率
针对xorm sql拼接的规则还比较粗糙,实际误报的场景如下:
84: return filepath.Join(table[1]+"_xxx", op)
90: ok, err := r.session.SQL(sql, vid).Get(t)
77: session.Where(fmt.Sprintf("%v %v ?", m["field"], m["op"]), value)
而从xorm sql注入的角度来看,该规则未优化前的误报率可能在50%左右,甚至更高。
扫描速度
单就go语言的扫描情况来看,每条规则可达到4500 loc/sec的扫描速度,效果还是非常理想的。
结论
综上所述,从工具定位、自定义规则提供的能力以及扫描速度来看,正如官方slogan所言,Static analysis at ludicrous speed, Find bugs and enforce code standards,semgrep是非常适合做安全编码规范扫描的。未来我们可能结合CI和IDE插件来实现semgrep在安全编码规范扫描的落地上,助力“默认安全”在企业安全研发流程高效落地。
下篇将分享semgrep具体实现逻辑,欢迎关注。