
一、前言
在我此前发布的文章( https://landave.io/2017/06/avast-antivirus-remote-stack-buffer-overflow-with-magic-numbers/ )中,有两个和7-Zip有关的Bitdefender漏洞,我在文章中明确提到了Igor Pavlov开发的7-Zip版本没有受到影响。然而,本次所发现的漏洞,该版本则受到了影响。
在我对一个优秀防病毒产品进行分析的过程中,我发现了这些漏洞。目前厂商暂未发布补丁程序,因此一旦确认有哪些产品受到影响,我会及时对本文进行更新,补充受影响产品的名称。由于Igor Pavlov已经发布了7-Zip的修复后版本,并且在7-Zip上更容易利用这些漏洞,所以我认为应该尽快发布这篇文章。
二、简介
在本文中,我将描述两个7-Zip漏洞,该漏洞影响18.00版本前的所有版本,包括p7zip。第一个漏洞(RAR的PPMd算法)较为严重,我们会重点进行分析。第二个漏洞(ZIP Shrink)没有第一个漏洞那么严重,也比第一个漏洞更容易理解。
三、RAR PPMd内存损坏漏洞(CVE-2018-5996)
7-Zip的RAR部分代码主要基于最新的UnRAR版本。对于RAR格式的第3版本,可以使用PPMd算法,该算法是Dmitry Shkarin的PPMII压缩算法的具体实现。如果大家想了解更多关于PPMd和PPMII算法的细节,建议阅读Shkarin关于PPM的论文:http://ieeexplore.ieee.org/document/999958/ 。
有趣的是,7z压缩格式也可以使用PPMd算法,7-Zip使用与RAR3相同的代码。事实上,在Bitdefender使用了一种非常特别的PPMd实现方式,会导致基于栈的缓冲区溢出( https://landave.io/2017/07/bitdefender-remote-stack-buffer-overflow-via-7z-ppmd/ )。
从实质上来看,这个漏洞是由于7-Zip的RAR3处理程序中异常处理不正确所导致的。因此,大家可能会说,这并不是PPMd代码本身的漏洞,也不是UnRAR解压缩代码中的漏洞。
3.1 漏洞描述
在RAR处理程序中,有一个NArchive::NRar::CHandler::Extract2函数,其中包含一个如下所示的循环(该循环过程非常简单):
for (unsigned i = 0;; i++, /*OMITTED: unpack size updates*/) {
//OMITTED: retrieve i-th item and setup input stream
CMyComPtr<ICompressCoder> commonCoder;
switch (item.Method) {
case '0':
{
commonCoder = copyCoder;
break;
}
case '1':
case '2':
case '3':
case '4':
case '5':
{
unsigned m;
for (m = 0; m < methodItems.Size(); m++)
if (methodItems[m].RarUnPackVersion == item.UnPackVersion) { break; }
if (m == methodItems.Size()) { m = methodItems.Add(CreateCoder(/*OMITTED*/)); }
//OMITTED: solidness check
commonCoder = methodItems[m].Coder;
break;
}
default:
outStream.Release();
RINOK(extractCallback->SetOperationResult(NExtract::NOperationResult::kUnsupportedMethod));
continue;
}
HRESULT result = commonCoder->Code(inStream, outStream, &packSize, &outSize, progress);
//OMITTED: encryptedness, outsize and crc check
outStream.Release();
if (result != S_OK) {
if (result == S_FALSE) { opRes = NExtract::NOperationResult::kDataError; }
else if (result == E_NOTIMPL) { opRes = NExtract::NOperationResult::kUnsupportedMethod; }
else { return result; }
}
RINOK(extractCallback->SetOperationResult(opRes));
}
在这个函数中,需要关注的是,函数最多只会为每个RAR解压缩版本创建一个编码器。如果压缩包中包含多个使用相同RAR解压缩版本压缩的项目,那么这些项目将使用相同的编码对象(Coder Object)进行解码。
此外,还要注意的是,Code方法的调用可能会失败,并返回S_FALSE这一结果,由于回调(Callback)函数没有捕获到成功的结果,所以已经创建的编码器将会被下一个项目重新使用。接下来,让我们看看错误代码S_FALSE可能来源于哪里。简化后的NCompress::NRar3::CDecoder::Code3方法如下所示:
STDMETHODIMP CDecoder::Code(ISequentialInStream *inStream, ISequentialOutStream *outStream,
const UInt64 *inSize, const UInt64 *outSize, ICompressProgressInfo *progress) {
try {
if (!inSize) { return E_INVALIDARG; }
//OMITTED: allocate and initialize VM, window and bitdecoder
_outStream = outStream;
_unpackSize = outSize ? *outSize : (UInt64)(Int64)-1;
return CodeReal(progress);
}
catch(const CInBufferException &e) { return e.ErrorCode; }
catch(...) { return S_FALSE; }
}
其中,CInBufferException非常有趣。顾名思义,这个异常可能会在从输入流读取时被抛出。在对RAR3压缩文件进行操作的过程中,非常容易触发这一异常,从而导致返回错误代码S_FALSE。我建议有兴趣的读者自行尝试研究其具体原理和细节。
那么,我为什么说它非常有趣呢?原因在于,在使用PPMd算法的RAR3的情况下,这个异常可能会在PPMd模型更新过程中被抛出,从而使得整个模型状态的健全性(Soundness)受到威胁。回想一下上面的工作原理,即使抛出了错误代码为S_FALSE的CInBufferException,下一个项目也还会使用相同的编码器。
另外需要注意的是,RAR3解码器会保存PPMd的模型状态。通过大致浏览NCompress::NRar3::CDecoder::InitPPM3方法的代码,我们可以发现这样一个事实:如果一个项目对其发起明确的请求,这个模型状态就会被重新初始化。这其实是一个用于允许在不同的项目之间,借助收集的概率启发式(Collected Probability Heuristics)来保持模型相同的功能特性。但这也意味着,我们可以做到以下几点:
- 构建RAR3压缩文件的第一个项目,以便在PPMd模型更新的过程中触发错误代码为S_FALSE的CInBufferException。实际上,这意味着我们可以调用任意Ppmd7_DecodeSymbol4错误中使用的范围解码器(Range Decoder)的Decode方法,从而跳出PPMd代码。
- 压缩文件的后续项目没有设置重置位,可能导致模型的重新初始化。因此,PPMd代码可能在被破坏后还持续运行。
到目前为止,可能大家觉得还不是太糟糕。为了理解攻击者如何将这一漏洞转化为内存损坏漏洞并利用,我们还需要了解更多有关于PPMd模型状态,并且需要具体了解该模型更新的过程。3.2 PPMd预处理
所有PPM压缩算法的核心思想,都是建立一个有限D阶的马尔可夫模型。在PPMd的具体实现中,模型状态本质上是一个最大深度为D的256元上下文树(Context Tree),其中从根到当前上下文节点会被解释为字节符号的序列。特别地,其中的父子关系(Parent Relation)将被转化为后缀关系(Suffix Relation)。此外,每个上下文节点都会存储与后继上下文节点相连接的频率统计,该频率用于记录其可能的后继符号。
上下文节点的类型为CPpmd7_Context,定义如下:typedef struct CPpmd7_Context_ { UInt16 NumStats; UInt16 SummFreq; CPpmd_State_Ref Stats; CPpmd7_Context_Ref Suffix; } CPpmd7_Context;NumStats字段存储Stats数组所包含元素的数量。类型CPpmd_State定义如下:
typedef struct { Byte Symbol; Byte Freq; UInt16 SuccessorLow; UInt16 SuccessorHigh; } CPpmd_State;至此,我们对其有了一定程度的了解。关于模型更新的过程,我们不会详细描述细节,而是抽象地描述一个新符号的解码过程,具体如下:
- 当Ppmd7_DecodeSymbol被调用时,假设是在健全模型的状态下,当前上下文是p->MinContext,它等同于p->MaxContext。
- 从范围解码器读取阈值。该值将用于在当前上下文p->MinContext的Stats数组中找到相应的符号。
- 如果没有找到相应的符号,则会将p->MinContext向上移动(在后缀链接之后),直至找到(严格意义上)具有更大Stats数组的上下文。然后,读取一个新的阈值并在当前Stats数组中找到相应的值,忽略之前访问过的上下文符号。重复这一过程,直到找到一个符合要求的值。
- 最后,调用范围解码器的解码方法,将找到的状态写入p->FoundState之中,并调用一个Ppmd7_Update函数来更新模型。作为该过程的一部分,UpdateModel函数会将找到的符号添加到p->MaxContext和p->MinContext之间的每个上下文的Stats数组中。
更新机制试图建立的一个关键不变量是:每个上下文的Stats数组所包含的256个符号不能发生重复,每个符号至多只能出现一次。然而,这个属性仅仅进行了归纳,当插入一个新符号时并没有进行重复检查。通过上文描述的漏洞,我们很容易发现向Stats数组添加重复符号的方法: - 创建第一个RAR3项目,创建几个上下文节点,随后函数Ppmd7_DecodeSymbol会将p->MinContext向上移动至少一次,直到找到相应的符号。然后,对范围解码器的解码方法的后续调用失败,触发CInBufferException。
- 下一个RAR3项目没有设置重置位,所以我们可以继续使用以前创建的PPMd模型。
- Ppmd7_DecodeSymbol函数使用新的范围解码器,在p->MinContext != p->MaxContext的情况下执行。它会立即在p->MinContext中找到相应的符号,但现在这个找到的符号,很可能已经在p->MaxContext和p->MinContext之间的上下文中出现过。当UpdateModel函数被调用时,这一符号会被重复添加到p->MaxContext 和p->MinContext之间每个上下文的Stats数组中。
好的,现在我们已经知道如何将重复的符号添加到Stats数组中。接下来,让我们看看如何利用它来造成实际上的内存损坏。3.3 触发栈缓冲区溢出
以下是Ppmd7_DecodeSymbol的部分代码,其作用是将p->MinContext指针向上移动到上下文树中:
CPpmd_State *ps[256]; unsigned numMasked = p->MinContext->NumStats; do { p->OrderFall++; if (!p->MinContext->Suffix) { return -1; } p->MinContext = Ppmd7_GetContext(p, p->MinContext->Suffix); } while (p->MinContext->NumStats == numMasked); UInt32 hiCnt = 0; CPpmd_State *s = Ppmd7_GetStats(p, p->MinContext); unsigned i = 0; unsigned num = p->MinContext->NumStats - numMasked; do { int k = (int)(MASK(s->Symbol)); hiCnt += (s->Freq & k); ps[i] = s++; i -= k; } while (i != num);MASK是一个宏,用于访问每个符号索引处字节数组的值,如果该符号已经使用过,那么值为0x00,否则值为0xFF。显然,其目的在于,用所有指向未使用过符号状态的指针,来填充栈缓冲区ps。
请注意,栈缓冲区ps的大小固定为256,并且没有溢出检查机制。这意味着,如果Stats数组多次存储同一个使用过的符号,我们就可以造成该数组越界,从而使ps缓冲区溢出。
通常情况下,针对这样的缓冲区溢出,攻击过程非常困难,因为我们不能控制所读取的内存。但是,在PPMd算法的场景下,上述攻击过程并不存在困难,因为从该算法的实现上来看,仅仅在堆上分配了一个大池,然后利用自己的内存分配器来分配该池中的所有上下文和状态结构。尽管这样的方式,能确保快速分配,并且占用的内存非常低,但却也允许攻击者轻松地控制对该池内结构的越界读取,并且这一过程是独立于系统的堆实现的。例如,我们可以构建第一个RAR3项目,从而将所需的数据填充到池中,避免未初始化前提下的越界读取。
最后,请注意,攻击者还可以利用指向自定义数据的指针,来实现栈缓冲区溢出。3.4 触发堆缓冲区溢出
在前一节的基础上,我们接下来尝试触发堆缓冲区溢出。我们也可以在不溢出栈缓冲区ps的前提下读取Stats数组,从而让s指针指向含有攻击者控制的数据的CPpmd_State。由于p->FoundState可能是ps状态之一,并且模型更新过程会假定p->MinContext的Stats数组及其后缀上下文中包含符号p->FoundState->Symbol。
下面是UpdateModel函数中的部分代码:
do { s++; } while (s->Symbol != p->FoundState->Symbol);
if (s[0].Freq >= s[-1].Freq) {
SwapStates(&s[0], &s[-1]);
s—;
}
同样,在Stats数组上没有进行边界检查,所以指针很容易移动到分配的堆缓冲区的末尾。在理想情况下,我们会构建一个输入,使得s越出界限,并保证s-1在分配的池内,从而允许攻击者控制堆溢出。3.5 攻击者的控制、漏洞利用过程及其缓解方法
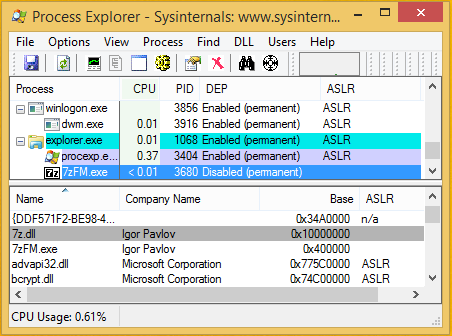
Windows系统的7-Zip二进制文件都不附带/NXCOMPAT和/DYNAMICBASE标志, 这就意味着在Windows上运行的7-Zip都没有ASLR(缓冲区溢出保护)机制,而DEP(数据执行保护)又只在Windows x64或Windows 10 x86上存在。如下图所示,是在更新版本的Windows 8.1 x86上运行最新的7-Zip 18.00:
![]()
此外,7-Zip编译时没有/GS标志,因此也没有Stack Canaries(栈金丝雀保护)机制。
由于可以用各种方式来破坏栈和堆,并且能够由攻击者完全对其进行控制,所以要实现远程代码执行就非常简单,特别是在没有DEP保护的情况下。
我与Igor Pavlov讨论过这一问题,并尝试说服他加上这三个标志。但是,他坚持拒绝启用/DYNAMICBASE,因为他更希望在没有重定位表的情况下传送二进制文件从而使二进制文件尽可能小。此外,他也不太想启用/GS,因为可能其会影响运行速度及二进制文件大小。但他表示,会在下一个版本中尝试启用/NXCOMPAT。目前没有启用的原因是7-Zip连接了一个不支持该标志的过时连接器。3.6 结论
我们所描述的堆、栈内存损坏,都是漏洞利用的一个最简单方式。实际上,很可能还有其他的漏洞利用方法,甚至可以让攻击者完全控制,从而导致内存损坏。
通过该漏洞,我们意识到将外部的代码集成到现有代码库是一件非常困难的事情。特别是如何正确处理异常,以及如何理解它们所引发的控制流,这是两件非常有挑战性的工作。
在关于BitDefender的PPMd栈缓冲区溢出的帖子( https://landave.io/2017/08/bitdefender-heap-buffer-overflow-via-7z-lzma/ )中,我已经明确表示,PPMd的代码是非常脆弱的。如果发生了一个API的轻微误用,或者是将其集成到另一个代码库时,都有可能会导致多重危险的内存损坏漏洞。
如果你使用的是Shkarin的PPMd实现,我强烈建议你尽可能全面地进行边界检查,同时要确保基本的模型不变量(Model Invariants)保持不变。而且,在发生异常时,可以在更新模型之前在模型中添加额外的错误标志并置为True,在更新成功后再将其置为False。这样,应该能够缓解破坏模型状态的风险。
如果有任何意见或建议,欢迎与我讨论,我的相关联系方式请参见:https://landave.io/about/ 。或者你也可以在HackerNews或/r/netsec上参与我们的讨论3.7 披露时间表
2018年1月6日 发现漏洞
2018年1月6日 报告漏洞
2018年1月10日 修复后版本7-Zip 18.00(测试版)发布
2018年1月22日 MITRE分配漏洞编号CVE-2018-5996
四、ZIP Shrink:堆缓冲区溢出漏洞(CVE-2017-17969)
接下来,让我们继续讨论另一个关于ZIP Shrink的漏洞。Shrink是Lempel-Ziv-Welch(LZW)压缩算法的一个实现。该算法在1993年PKWARE发布的PKZIP 2.0之前就已经被使用。事实上,这一算法非常古老,并且如今很少被使用。在2005年,Igor Pavlov写了7-Zip的Shrink解码器之后,他居然都很难找到一个压缩文件样本来测试它的代码。
实际上,Shrink是一个LZW之中9-13位之间的动态代码,并且它允许对一部分字典进行清除。
7-Zip的Shrink解码器非常简单易懂。实际上,该解码器只有200行代码。然而就在这200行代码之中,蕴含着一个缓冲区溢出漏洞。
4.1 漏洞描述
Shrink模型的状态,本质上只包含两个数组:_parents和_suffixes,这两个数组会尽可能节省空间以存储LZW字典。而且,还有一个当前序列写入的_stack缓冲区:
UInt16 _parents[kNumItems];
Byte _suffixes[kNumItems];
Byte _stack[kNumItems];
下面是NCompress::NShrink::CDecoder::CodeReal10方法中的部分代码:
unsigned cur = sym;
unsigned i = 0;
while (cur >= 256) {
_stack[i++] = _suffixes[cur];
cur = _parents[cur];
}
经过观察可以发现,其中i的值没有进行任何检查。
由此,我们可以构造一个序列的符号,来使_parents数组形成一个循环,从而造成堆缓冲区_stack的溢出。由于解码器只会确保父节点不链接到自身(长度为1的周期),因此上述方法是可行的。有趣的是,旧版本的PKZIP创建Shrink压缩文件时可能会出现这种自链接的情况,因此如果想要与其兼容,实际上应该接受这样的链接。在7-Zip 18.00版本中,已经修复了这一问题。
此外,使用特殊符号序列256,2,可以使得攻击者控制其清除父节点。清除后的父节点将被设置为kNumItems。由于没有对父项是否已被清除进行检查,所以父数组可以被越界访问。
综合上面的这些事实,我们可以构建压缩文件,使解码器越界写入攻击者控制的数据。然而,我并没有找到一个更简单的实现方法,并且该方法会产生一个死循环。这非常关键,因为每一次循环都会让索引i递增,所以死循环将很快导致段错误,让代码执行的利用变得非常困难。目前,我还没有在这方面进行更深入的研究,可能会有一种更好的方式,能在不进入死循环的前提下实现堆破坏。
4.2 结论
该漏洞已经在7-Zip中存在很长时间。我认为,该漏洞产生的一大原因是目前使用Shrink方式的ZIP压缩文件已经几乎不存在。
确实,该漏洞并没有RAR PPMd漏洞那么严重,但我认为这是一个非常有趣的漏洞。
如果你有能够避免死循环的方法,欢迎随时告诉我,我会非常感激。
4.3 披露时间表
2017年12月29日 发现漏洞
2017年12月29日 报告漏洞
2017年12月29日 MITRE分配漏洞编号CVE-2017-17969
2018年1月10日 修复后版本7-Zip 18.00(测试版)发布
五、致谢
在此,要感谢Igor Pavlov用极快的速度修复了上述这些漏洞。
原文链接:https://landave.io/2018/01/7-zip-multiple-memory-corruptions-via-rar-and-zip/