
AESNI是Intel开发的一种x64架构的SIMD指令集,专门为AES加密算法提供硬件加速,对SIMD有一定了解的人基本都知道AESNI的存在。但由于AES本身的不对称结构,以及AESNI的特殊设计,在实际使用AESNI时,还是有很多细节和理论知识需要了解,才能写出正确的代码。以N1CTF 2021中的easyRE为例,总结了一下自己对AESNI的理解,若有不对的地方敬请指正。
AES的结构
以AES128为例,其结构是10轮4×4排列置换网络,尾轮相较普通轮缺少一个MixColumns变换。
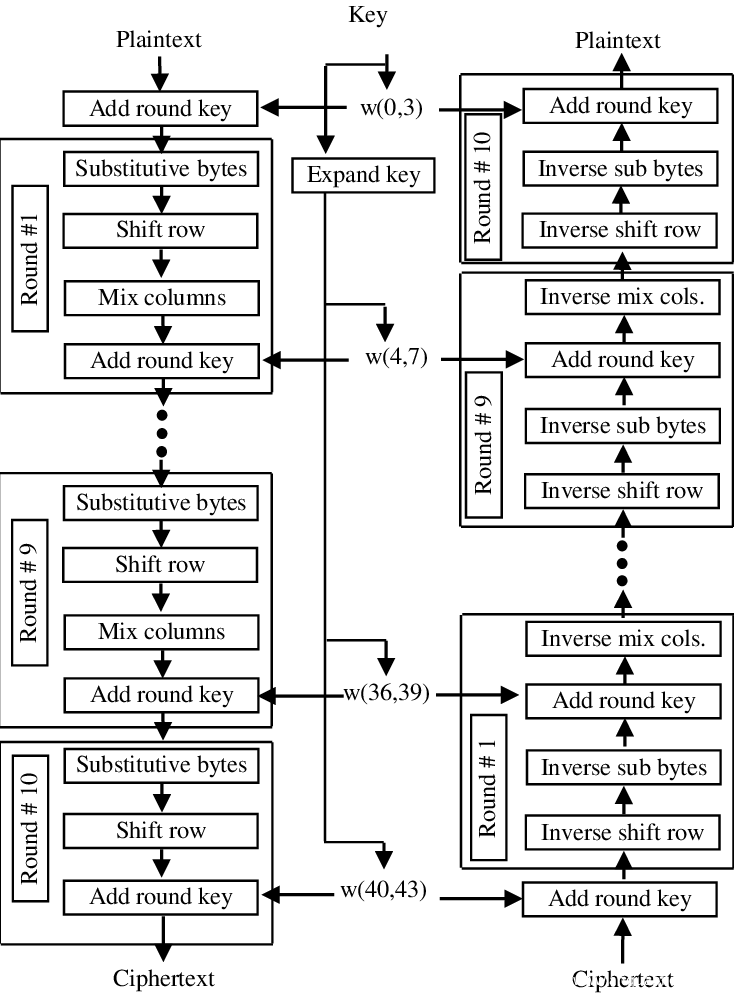
需要注意的是虽然轮数是10,但是仔细看左上角可以发现进入首轮之前还有一个AddRondKey操作,所以共有11个轮密钥。加密的开头和结尾均为AddRondKey,这种设计叫做白化。白化的用意也容易理解,由于其它3种操作不涉及密钥,仅为固定变换,如果放在加密的开头或结尾,任何人都可以直接进行逆变换解除之,这些操作的存在不能提升算法的安全性,因此没有意义。
AESENC和AESENCLAST
这两条指令是AESNI中用于加密的指令,也是最容易理解的指令。任何SIMD指令都可以参考Intel® Intrinsics Guide,AESENC对输入依次进行ShiftRows,SubBytes,MixColumns,AddRoundKey操作。其中SubBytes是对字节的操作,因此可以和ShiftRows互换,与上面的图比较,可以发现AESENC恰好是上图的一个普通轮加密。
AESENCLAST对输入依次进行ShiftRows,SubBytes,AddRoundKey操作,相当于上图的尾轮加密。
第0个轮密钥异或操作可以用PXOR指令完成,因此一个完整的AES加密过程如下(pt是明文,k[x]是轮密钥,ct是密文):
pxor pt, k[0]
aesenc pt, k[1]
aesenc pt, k[2]
...
aesenc pt, k[n-1]
aesenclast pt, k[n]
movdqa ct, pt
AES是9轮AESENC+1轮AESENCLAST这一点很容易记住,但第0个轮密钥是直接PXOR这一点很容易被忽视掉,需要多加注意。
AES的解密算法和等价解密算法
AES的不对称设计十分具有迷惑性,再仔细观察上图右侧的解密过程,可以发现解密时也是白化+9轮普通轮+1轮尾轮。
这里要注意,如果直接按照加密的逆过程来考虑,那么解密应该是先解密尾轮,再解普通轮,然而上图显然不是这样。
如果不考虑轮的划分,只看分开的4种操作的话,解密的操作恰为加密操作的逆序。但若想将一系列的操作划分成不同的轮,就有很多种划分方式。上图是最常见的划分方式,其中解密轮并不是加密轮的逆运算,这一划分方式是AES的设计中第一个违反直觉的地方。
在上图的划分中,一个解密轮包括InvShiftRows,InvSubBytes,AddRoundKey,InvMixColumns操作,尾轮同样是移除InvMixColumns操作。
AES原名Rijndael,在Rijndael最初的提案中,设计者另外给出了一种“等价解密算法”(参见5.3.3 The equivalent inverse cipher structure),在等价解密中,解密轮的AddRoundKey和InvMixColumns操作顺序互换,形成了一种和加密轮相同,AddRoundKey均在最后的对称结构(InvSubBytes和InvShiftRows本身可以互换顺序):

这一交换并非等价变换,InvMixColumns是对每一列的4个字节在GF(2^8)上乘上一个4×4矩阵,得到一个新的1×4向量,而AddRoundKey是对每个字节进行异或操作。在GF(2^8)上,异或操作即为加法运算,根据乘法分配律就可以推出,若将AddRoundKey移至InvMixColumns后,新的RoundKey应为原RoundKey乘上同样的4×4矩阵,才能保证运算结果不变。
再仔细观察解密的流程图,第0个轮密钥直接异或,最后一个轮密钥在解密的尾轮中,这两个轮密钥均不涉及InvMixcolumns的交换,因此在等价解密的过程中,除了需要将加密的轮密钥逆序外,第1~第n-1个轮密钥应先进行InvMixColumns,变换成解密用密钥。
AES加密和等价解密的轮之间具有一种奇特的对称美学,但轮密钥不同,这是AES的设计中第二个违反直觉的地方。
AESDEC,AESDECLAST和AESIMC
根据AESNI的设计白皮书,Intel同样采用了等价解密,参考Intel® Intrinsics Guide,注意AESDEC指令不是AESENC指令的逆过程,AESDECLAST同样不是AESENCLAST的逆过程。一个完整的AES解密过程如下(pt是明文,k[x]是轮密钥,ct是密文):
pxor ct, k[n]
aesdec ct, k'[n-1]
aesdec ct, k'[n-2]
...
aesdec ct, k'[1]
aesdeclast ct, k[0]
movdqa pt, ct
其中k[0]和k[n]和加密密钥相同,而k’[1]~k’[n-1]是加密密钥k[1]~k[n-1]经InvMixColumns变换的结果。为此,Intel特意提供了AESIMC指令,该指令即为进行单个的InvMixColumns操作。
AESKEYGENASSIST和PCLMULQDQ
AESKEYGENASSIST用在密钥扩展中,具体的用法可以参考[设计白皮书]19页。
PCLMULQDQ全称Carry-Less Multiplication Quadword,是对两个GF(2^128)域上的多项式相乘。PCLMULQDQ本身并不属于AESNI指令集,但除了用于加速CRC32外,PCLMULQDQ还能计算GCM的GMAC,因此经常出现在SIMD加密算法中。Libsodium中的AES-256-GCM实现就是一个完美的示例。
AESNI的进阶用法
分离AES的4种操作
最初尝试AESNI时曾经十分不解,为什么Intel要采用等价加密,使得生成解密密钥还要额外加上AESIMC操作,后来读完了白皮书才搞懂这一精巧的设计。
白皮书第34页给出了用AESNI单独实现AES的4种操作的方法:
Isolating ShiftRows
PSHUFB xmm0, 0x0b06010c07020d08030e09040f0a0500
Isolating InvShiftRows
PSHUFB xmm0, 0x0306090c0f0205080b0e0104070a0d00
Isolating MixColumns
AESDECLAST xmm0, 0x00000000000000000000000000000000
AESENC xmm0, 0x00000000000000000000000000000000
Isolating InvMixColumns
AESENCLAST xmm0, 0x00000000000000000000000000000000
AESDEC xmm0, 0x00000000000000000000000000000000
Isolating SubBytes
PSHUFB xmm0, 0x0306090c0f0205080b0e0104070a0d00
AESENCLAST xmm0, 0x00000000000000000000000000000000
Isolating InvSubBytes
PSHUFB xmm0, 0x0b06010c07020d08030e09040f0a0500
AESDECLAST xmm0, 0x00000000000000000000000000000000
ShiftRows可以直接用SSSE3的PSHUFB指令完成,而SubBytes则是先反向shuffle,再用0密钥进行尾轮加密,消掉尾轮的另外两种操作。MixColumns则结合加密和解密,利用尾轮的特性将MixColumns保留下来。这个神奇的拼接方式令人啧啧称奇。
上一节提到由加密密钥变换为等价解密密钥要经过AESIMC操作,但如果已知等价解密密钥,如何获得加密密钥?AESNI里没有直接的MixColumns操作,但根据上文,可以用AESDECLAST和AESENC组合产生。
而查询Intel® Intrinsics Guide,发现Skylake微架构上,AESIMC的Latency和Throughput均是AESENC的两倍,因此斗胆猜测AESIMC内部也是AESENCLAST和AESDEC的拼接。
用AESNI加速其它算法
AESNI的灵活设计使得它可以用来实现更大的排列置换网络,前文提到AES原名Rijndael,而参考Rijndael的提案,Rijndael实际上有块大小(不是密钥大小)为128,192,256的三种变种,只有128大小的Rijndael被选为AES。白皮书则给出了AESNI实现的其它Rijndael,例如Rijndael-256:
#include <emmintrin.h>
#include <smmintrin.h>
void Rijndael256_encrypt(unsigned char* in,
unsigned char* out,
unsigned char* Key_Schedule,
unsigned long long length,
int number_of_rounds) {
__m128i tmp1, tmp2, data1, data2;
__m128i RIJNDAEL256_MASK =
_mm_set_epi32(0x03020d0c, 0x0f0e0908, 0x0b0a0504, 0x07060100);
__m128i BLEND_MASK =
_mm_set_epi32(0x80000000, 0x80800000, 0x80800000, 0x80808000);
__m128i* KS = (__m128i*)Key_Schedule;
int i, j;
for (i = 0; i < length / 32; i++) { /* loop over the data blocks */
data1 = _mm_loadu_si128(&((__m128i*)in)[i * 2 + 0]); /* load data block */
data2 = _mm_loadu_si128(&((__m128i*)in)[i * 2 + 1]);
data1 = _mm_xor_si128(data1, KS[0]); /* round 0 (initial xor) */
data2 = _mm_xor_si128(data2, KS[1]);
/* Do number_of_rounds-1 AES rounds */
for (j = 1; j < number_of_rounds; j++) {
/*Blend to compensate for the shift rows shifts bytes between two
128 bit blocks*/
tmp1 = _mm_blendv_epi8(data1, data2, BLEND_MASK);
tmp2 = _mm_blendv_epi8(data2, data1, BLEND_MASK);
/*Shuffle that compensates for the additional shift in rows 3 and 4
as opposed to rijndael128 (AES)*/
tmp1 = _mm_shuffle_epi8(tmp1, RIJNDAEL256_MASK);
tmp2 = _mm_shuffle_epi8(tmp2, RIJNDAEL256_MASK);
/*This is the encryption step that includes sub bytes, shift rows,
mix columns, xor with round key*/
data1 = _mm_aesenc_si128(tmp1, KS[j * 2]);
data2 = _mm_aesenc_si128(tmp2, KS[j * 2 + 1]);
}
tmp1 = _mm_blendv_epi8(data1, data2, BLEND_MASK);
tmp2 = _mm_blendv_epi8(data2, data1, BLEND_MASK);
tmp1 = _mm_shuffle_epi8(tmp1, RIJNDAEL256_MASK);
tmp2 = _mm_shuffle_epi8(tmp2, RIJNDAEL256_MASK);
tmp1 = _mm_aesenclast_si128(tmp1, KS[j * 2 + 0]); /*last AES round */
tmp2 = _mm_aesenclast_si128(tmp2, KS[j * 2 + 1]);
_mm_storeu_si128(&((__m128i*)out)[i * 2 + 0], tmp1);
_mm_storeu_si128(&((__m128i*)out)[i * 2 + 1], tmp2);
}
}
Rijndael-256是8×4排列置换网络,SubBytes,AddRoundKey是字节层面变换,可以正常工作,而MixColumns是对每列的1×4向量进行变换,同样正常工作,只有ShiftRows需要利用SSE4.1的PBLENDB和SSSE3的PSHUFB调整偏移。8×4排列置换网络是4×4的两倍,因此每一轮需要两个AESENC指令,结尾同样两个AESENCLAST。这种错落有致又不失美感的代码正是计算机吸引入的地方。
国密SM4算法中的“非线性变换τ”实际上也是一个二进制域GF(2^8)上的S盒,和AES的S盒相比,只有生成多项式p不同。根据群论知识,这两个GF(2^8)是同构的(若有不对请指正),两个域上的元素可通过代数运算互相变换。Markku-Juhani O. Saarinen据此设计了利用AESNI加速的SM4实现。参见sm4ni。
N1CTF 2021 easyRe
题目位于这里,加密函数的主要逻辑是对xmm0中的明文进行一系列的加密和打乱操作:
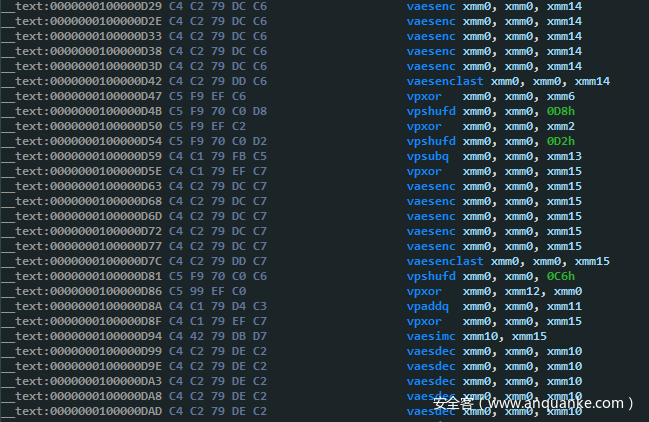
虽然程序是v开头的AVX2指令集,但只用到了xmm寄存器,可以只用SSE写出解密算法。先利用capstone解析一遍函数体,生成一个表达式树,该树的一个叶节点是输入,而该树的根节点是密文。再对该树进行变换,通过左右旋转,设法将输入节点转至最顶端根部,此时该树对应的表达式就是解密表达式。
在旋转过程中,VPXOR,VPADDQ,VPSUBQ很容易求出逆运算,VPSHUFD是对xmm0里的4个32位值重新排列,同样用VPSHUFD可以排列回去。遇到VAESENC指令时,首先将整个VAESENC+VAESENCLAST块提取出来,对中间的轮密钥VAESIMC求逆,再生成相反的解密树。注意前文提到过AES加密的第0个轮密钥是直接VPXOR异或,碰到VAESENC指令前不是VPXOR时,可以看作是异或了一个全0密钥,那么解密树的最后一条指令VAESDECLAST的轮密钥就是0。遇VAESDEC解密块时处理方法类似,但要使用前文提到的VAESDECLAST+VAESENC合成出MixColumns操作,对轮密钥进行变换。
根据表达式树写出了一个JIT,JIT产生的代码编译后运行就能得到flag:
import sys
import capstone
import binascii
sys.setrecursionlimit(0x100000)
class Node:
def __init__(self):
self.emitted = False
self.parent = None
def __str__(self):
return "v"+hex(id(self))
def emit(self, f):
if self.emitted:
return
self.emitted = True
self.do_emit(f)
class Constant(Node):
def __init__(self, c):
super().__init__()
self.c = c
def do_emit(self, f):
if self.c == 0:
f.write("__m128i {}=_mm_setzero_si128();\n".format(self))
else:
f.write("__m128i {}=_mm_set_epi64x({}ULL,{}ULL);\n".format(
self, hex(self.c >> 64), hex(self.c & ((1 << 64)-1))))
class Binary(Node):
def __init__(self, a, b):
super().__init__()
self.a = a
self.b = b
a.parent = self
b.parent = self
class Add(Binary):
def __init__(self, a, b):
super().__init__(a, b)
def do_emit(self, f):
self.a.emit(f)
self.b.emit(f)
f.write("__m128i {}=_mm_add_epi64({},{});\n".format(
self, self.a, self.b))
class Sub(Binary):
def __init__(self, a, b):
super().__init__(a, b)
def do_emit(self, f):
self.a.emit(f)
self.b.emit(f)
f.write("__m128i {}=_mm_sub_epi64({},{});\n".format(
self, self.a, self.b))
class Xor(Binary):
def __init__(self, a, b):
super().__init__(a, b)
def do_emit(self, f):
self.a.emit(f)
self.b.emit(f)
f.write("__m128i {}=_mm_xor_si128({},{});\n".format(
self, self.a, self.b))
class Aes(Node):
def __init__(self, base, key, is_enc, is_last):
super().__init__()
self.base = base
self.key = key
self.is_enc, self.is_last = is_enc, is_last
base.parent = self
key.parent = self
def do_emit(self, f):
self.base.emit(f)
self.key.emit(f)
f.write("__m128i {}=_mm_aes{}{}_si128({},{});\n".format(
self, "enc" if self.is_enc else "dec", "last" if self.is_last else "", self.base, self.key))
class Aesimc(Node):
def __init__(self, a, is_imc):
super().__init__()
self.a = a
self.is_imc = is_imc
a.parent = self
def do_emit(self, f):
self.a.emit(f)
if self.is_imc:
f.write("__m128i {}=_mm_aesimc_si128({});\n".format(self, self.a))
else:
f.write("__m128i {}=_mm_aesenc_si128(_mm_aesdeclast_si128({},zero),zero);\n".format(
self, self.a))
class Shuffle(Node):
def __init__(self, a, x):
super().__init__()
self.a = a
self.x = x
a.parent = self
def do_emit(self, f):
self.a.emit(f)
f.write("__m128i {}=_mm_shuffle_epi32({},{});\n".format(
self, self.a, hex(self.x)))
def flip(root):
parent = root.parent
if isinstance(parent, Constant):
return parent
elif isinstance(parent, Xor):
if root == parent.a:
return Xor(parent.b, flip(parent))
else:
return Xor(parent.a, flip(parent))
elif isinstance(parent, Add):
if root == parent.a:
return Sub(flip(parent), parent.b)
else:
return Sub(flip(parent), parent.a)
elif isinstance(parent, Sub):
if root == parent.a:
return Add(flip(parent), parent.b)
else:
return Sub(parent.a, flip(parent))
elif isinstance(parent, Shuffle):
x = parent.x
shuffle = []
for i in range(4):
shuffle.append(x & 3)
x >>= 2
assert set(shuffle) == set({0, 1, 2, 3})
x = 0
for i in range(4):
x <<= 2
x += shuffle.index(3-i)
return Shuffle(flip(parent), x)
elif isinstance(parent, Aesimc):
return Aesimc(flip(parent), not parent.is_imc)
elif isinstance(parent, Aes):
keys = [parent]
p = parent.parent
while True:
if isinstance(p, Aes):
keys.append(p)
if p.is_last:
break
p = p.parent
else:
raise ValueError
keys.reverse()
r = Xor(flip(p), keys[0].key)
r_keys = {}
for i in range(1, len(keys)):
if id(keys[i].key) not in r_keys:
r_keys[id(keys[i].key)] = Aesimc(keys[i].key, keys[i].is_enc)
r = Aes(r, r_keys[id(keys[i].key)],
not keys[i].is_enc, False)
return Aes(r, Constant(0), not keys[0].is_enc, True)
else:
raise ValueError
xmmnames = ['xmm{}'.format(i) for i in range(16)]
xmm = [None for i in range(16)]
target = Node()
xmm[0] = target
memory = {}
c = ['2f0fc4f2839a1d5401ead9842fc23d00',
'24e1c94761c31694cdb7d3a38fb0c100',
'2af5fcb6d4373ceac4590d4f86956d00',
'cbc6b50249b0b519a2620a3cc73d9200',
'60a876c1193162a02a1531a79d6a5900',
'd083cfb2f3a048c4cf47af9bcaaefa00',
'eb93d59f3756816e2671cd0d1c73bf00',
'c32de58cdbcf9fdd7de74f364a594b00',
'6055580a46572c4e6a591ddd77c0ce00',
'13bf3e7536d86ce89d81348f6f10e000', ]
for i in range(len(c)):
memory[0x620-i *
0x10] = Constant(int.from_bytes(binascii.a2b_hex(c[i]), 'little'))
c = capstone.Cs(capstone.CS_ARCH_X86, capstone.CS_MODE_64)
c.detail = True
it = c.disasm(open('easyRe', 'rb').read()[0xc4d:0x19d90], 0x100000C4D)
for ins in it:
if ins.mnemonic == 'vmovdqa':
a, b = ins.op_str.split(',')
a, b = a.strip(), b.strip()
if a in xmmnames and b not in xmmnames:
assert b.startswith('xmmword ptr [rbp - ')
off = int(b[19:b.index(']')], 16)
assert off in memory
xmm[xmmnames.index(a)] = memory[off]
elif b in xmmnames and a not in xmmnames:
assert a.startswith('xmmword ptr [rbp - ')
off = int(a[19:a.index(']')], 16)
memory[off] = xmm[xmmnames.index(b)]
else:
xmm[xmmnames.index(a)] = xmm[xmmnames.index(b)]
elif ins.mnemonic == 'vpxor':
a, b, c = ins.op_str.split(',')
a, b, c = a.strip(), b.strip(), c.strip()
if c in xmmnames:
xmm[xmmnames.index(a)] = Xor(
xmm[xmmnames.index(b)], xmm[xmmnames.index(c)])
else:
assert c.startswith('xmmword ptr [rbp - ')
off = int(c[19:c.index(']')], 16)
xmm[xmmnames.index(a)] = Xor(
xmm[xmmnames.index(b)], memory[off])
elif ins.mnemonic == 'vpaddq' or ins.mnemonic == 'vpsubq':
a, b, c = ins.op_str.split(',')
a, b, c = a.strip(), b.strip(), c.strip()
if c in xmmnames:
xmm[xmmnames.index(a)] = (Add if ins.mnemonic == 'vpaddq' else Sub)(
xmm[xmmnames.index(b)], xmm[xmmnames.index(c)])
else:
assert c.startswith('xmmword ptr [rbp - ')
off = int(c[19:c.index(']')], 16)
xmm[xmmnames.index(a)] = (Add if ins.mnemonic == 'vpaddq' else Sub)(
xmm[xmmnames.index(b)], memory[off])
elif ins.mnemonic == 'vpshufd':
a, b, c = ins.op_str.split(',')
a, b, c = a.strip(), b.strip(), c.strip()
c = int(c, 16)
xmm[xmmnames.index(a)] = Shuffle(
xmm[xmmnames.index(b)], c)
elif ins.mnemonic == 'vaesenc' or ins.mnemonic == 'vaesdec':
is_enc = ins.mnemonic == 'vaesenc'
a, b, c = ins.op_str.split(',')
a, b, c = a.strip(), b.strip(), c.strip()
xmm[xmmnames.index(a)] = Aes(xmm[xmmnames.index(b)],
xmm[xmmnames.index(c)], is_enc, False)
elif ins.mnemonic == 'vaesenclast' or ins.mnemonic == 'vaesdeclast':
is_enc = ins.mnemonic == 'vaesenclast'
a, b, c = ins.op_str.split(',')
a, b, c = a.strip(), b.strip(), c.strip()
xmm[xmmnames.index(a)] = Aes(xmm[xmmnames.index(b)],
xmm[xmmnames.index(c)], is_enc, True)
elif ins.mnemonic == 'vaesimc':
a, b = ins.op_str.split(',')
a, b = a.strip(), b.strip()
xmm[xmmnames.index(a)] = Aesimc(xmm[xmmnames.index(b)], True)
elif ins.mnemonic == 'movabs' or ins.mnemonic == 'mov':
pass
else:
print(ins)
raise ValueError
xmm[0].parent = Constant(0x79eeb3fa8c39dbd77bc066c7647d0b72)
target = flip(target)
f = open('a.c', 'w')
f.write('''
#include <immintrin.h>
#include <stdio.h>
int main(){
__m128i zero=_mm_setzero_si128();
''')
target.emit(f)
f.write('''char pt[16];
_mm_storeu_si128((__m128i*)pt, {});
fwrite(pt,16,1,stdout);
return 0;
}}
'''.format(target))
编译的时候加上-maes选项打开AESNI,会生成SSE指令集的程序,如果用-march=native再多打开一些指令集,还能自动编译出AVX2+VAES的程序,现在的编译器也是十分智能。
flag: n1ctf{Easy_AVX!}(一点都不easy)