
在事务内存中,没有人能听到你的呼喊——Intel事务同步扩展攻击
在过去几年中,Capture The Flag(CTF)比赛的复杂性和创造性越来越成熟。每个人都在正致力于推动这一趋势,与此同时,活跃社区(the active community)的技术水平也越来越高。游戏与现实之间的界限逐渐模糊,CTF比赛对现实社会产生的影响也越来越多。
上个月,在DEFCON CTF 2019资格赛中,出现了Intel的事务性同步扩展(Transactional Synchronization Extensions,TSX)中的不对称行为。本文将讨论如何利用这一微妙问题执行简单但新颖的CPU级攻击。
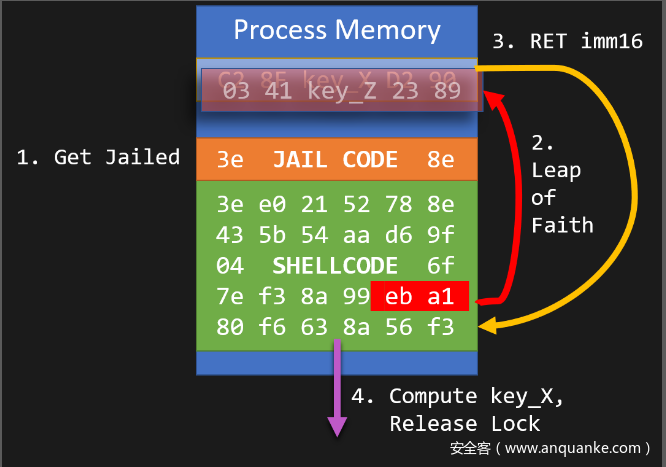
基于TSX机器码‘监狱’(TSX-based machine-code jail)逃逸的CPU攻击模型
挑战
DEFCON CTF是一项年度计算机安全竞赛,吸引了全球最优秀的黑客,他们要在48小时内解决各种复杂的挑战。
今年,Davide Balzarotti的“shellcoding”挑战引起了我们的注意。通过使用Intel的TSX指令,创造性地实了一个机器码“监狱”,可以用来安全地执行用户提供的shellcode。挑战的目标是逃离这个“监狱”并在系统上开启一个shell。
Hotel-California,DEFCON Quals 2019的一项挑战
该挑战提供了在Internet远程服务器上运行的二进制程序。当连接到服务时,它会显示欢迎消息并提示用户输入任意shellcode:

连接到服务器
在运行用户输入的shellcode之前,服务器会执行一系列经过精心构造的指令,用于限制正在执行的线程。实际上,构造的指令用于在进入事务性执行上下文(transactional execution context)之前销毁逃脱“监狱”所需的“密钥”。
下面的代码块中,我们提供了“监狱”的执行过程,它在内存页面的RWX上给shellcode添加了前缀。理解此片段对理解本文内容非常有用。
loc_F70:
lea rdi, loc_F70
sub rdi, 0x14
mov eax, [rdi]
mov [rdi], eax ; eax = key_X, ebx = key_Y
xor rax, rax ; 清空key_X
xor rcx, rcx
xor rdx, rdx
xor rsi, rsi
xacquire lock xor [rdi], ebx ; 进入事务性状态, key_Z = key_X ^ key_Y
xtest
jnz short loc_F95
retn
loc_F95:
xor rbp, rbp
xor rsp, rsp
xor rdi, rdi
xor rbx, rbx ; 清空key_Y
user_shellcode:
... ; 开始执行用户输入的shellcode
在更详细地分析这个挑战之前,必须对“事务性执行上下文”有一定的了解。“事务性内存系统”(transactional memory system)是一个非常深奥的课题,我们将尽力提供这些概念的详细概述,因为它们与此挑战有关。
事务内存(Transactional Memory)
事务内存是一种并发编程结构,允许自动执行一组读或写内存操作。Intel将TSX实现简述为“推测式锁定”(speculative locking)。简单的说,这些功能有点像高性能CPU级锁,可确保安全地访问共享内存空间。
TSX为x86指令集增加了许多新指令。本文只关注TSX的硬件事务内存锁(Hardware Lock Elision, HLE)指令前缀XACQUIRE和XRELEASE:
xacquire lock mov [rax], 1 ; 写入数据以上锁
...
xrelease lock mov [rax], 0 ; 恢复原始数据以解锁
XACQUIRE指令前缀用于指定“事务区域(transactional region)”(或关键部分)的开始。当线程遇到此前缀时,它将获取处理器状态的快照并开始推测性地执行。这就是我们所谓的“事务执行上下文”或“事务状态”。
在事务执行时,CPU将记录所有内存操作,如下所示:
...
mov rbx, [rax + 8]
mov rcx, [rax + 32]
add [rax + 32], 1
...
内存操作由L1缓存(L1 cache)中称为“读取集(read-set)”和“写入集(write-set)”的两个私有结构记录。这些集合有点像底层进程内存的“面纱”。例如,当指令尝试从事务执行上下文中的内存中读取时,CPU将首先尝试从写入集中获取所需的内存。写入集是CPU用来存储尚未提交给后备进程的“推测性内存修改(speculative memory modifications)”的地方。

写入集拦截事务性内存读取的伪可视化示例
要退出临界区并将事务状态提交到正常执行上下文,必须在将锁恢复为其原始值的指令上使用XRELEASE前缀。在此阶段,完成的事务将自动提交推测执行的读/写操作。
事务中止
在事务上下文中执行时,很难保证事务区域在实际中能够执行完,线程必须遵守一套严格的规则,不遵守这些建议,将导致事务中止。
具体而言,以下内容Intel将发出警告(warns):
受保护的关键部分不应与缓存行粒度冲突。
受保护的临界区应足够短,以免受中断或上下文切换的影响。
受保护的关键部分不应执行系统调用。
受保护的关键部分不应触及比L1缓存更多的数据。
推测可能存在嵌套限制。
此外,还有一些必须注意的警告和限制:
异步事件(
NMI,SMI,IPI,...)可能导致事务中止。
同步事件(信号)可能导致事务中止。
无效的内存访问将导致事务中止。
特殊指令(CPUID,x87,MMX,...)将导致事务中止。
尝试使用不正确的值释放锁定将中止。
尝试使用其他地址释放锁定将中止。
在没有XRELEASE的情况下写入锁将导致中止。
特定的条件可能导致中止。
后台系统活动可能导致中止。
…
如果你尝试执行除了最基本的指令以外的其他操作,事务可能会中止。
当事务中止时,CPU将恢复到执行XACQUIRE指令前的检查点。将恢复所有寄存器,并丢弃在事务状态中发生的所有推测性写入。
创建事务“监狱”过程分析
了解了“事务内存”的概念之后,我们现在来分析一下这个CTF挑战。具体来说,我们将讨论此程序是如何使用事务指令创建机器码“监狱”的。
在进入事务状态之前,程序会生成两个32位随机数。本文中,我们将这些值称为key_X和key_Y:

从/dev/urandom中随机生成32位密钥
在描述指令前缀XACQUIRE和XRELEASE如何工作时,我们声明它们只能使用写入锁的指令。(写入锁是将线程转入和转出事务执行上下文的常用操作)
释放锁需要事务线程使用XRELEASE前缀的指令恢复原始锁定值。这是因为HLE将锁的值视为“标签”或“句柄”。但是,若不知道原始锁定值是什么,会发生什么?这正是这个挑战所提供的场景:
...
mov [rdi], eax ; eax = key_X, ebx = key_Y
xor rax, rax ; 清除key_X
xor rcx, rcx
xor rdx, rdx
xor rsi, rsi
xacquire lock xor [rdi], ebx ; 进入事务状态, key_Z = key_X ^ key_Y
...
要进入事务状态,程序将原始锁定值key_x与key_y异或。这会将线程放入事务执行上下文中,并将key_Z(异或的结果)作为获取的锁定值。
然后,程序要确保清除内存和寄存器中所有的key_X和key_Y。只有这样才可能在超脆弱事务执行上下文(super-fragile transactional execution context)中执行我们的shellcode:
...
xor rbp, rbp
xor rsp, rsp
xor rdi, rdi
xor rbx, rbx ; 清除key_Y
user_shellcode:
... ; 开始执行用户输入的shellcode
如果没有key_X或key_Y,就无法“解密”key_Z来恢复原始锁定值。如果没有原始锁定值,就无法释放锁定。如果无法释放锁,shellcode就无法执行系统调用或启动shell。
CPU漏洞
我们多次尝试了在事务CPU状态(transactional CPU state)下执行代码,证实了出题人并不允许我们通过欺骗CPU进行系统调用。我们将重点转向如何优雅地释放锁以逃离事务。
此程序恰好将“锁”放在与我们的shellcode有相同RWX属性的页面上,我们猜测原始的key_X可能仍然存在于CPU的指令高速缓存中。由于现代CPU架构通常拥有独立于典型的数据高速缓存的指令高速缓存,使得相比于数据缓存,更容易从指令缓存中获取CPU执行流水线。
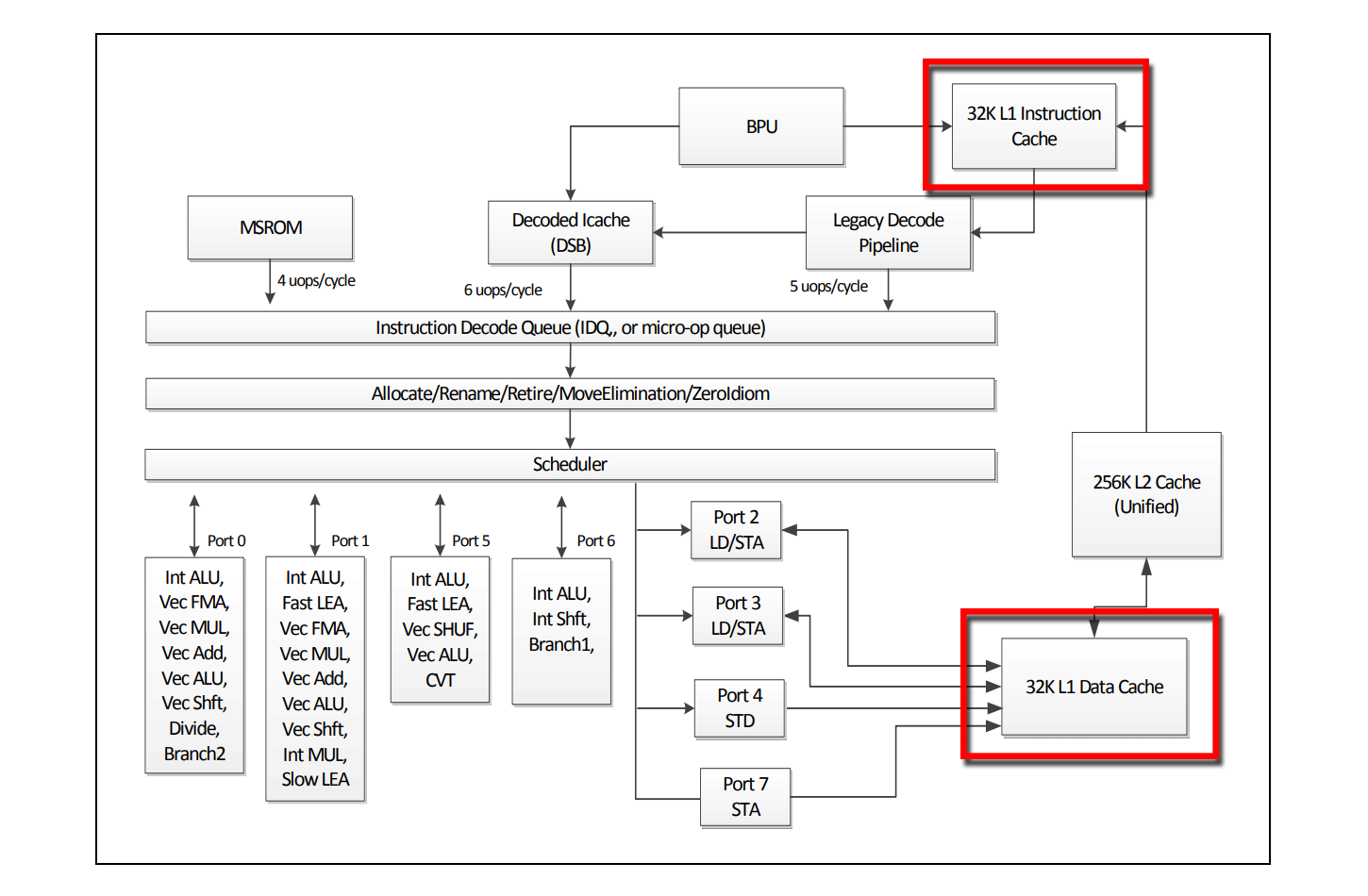
Skylake微体系结构的CPU核心流水线功能
通过对CPU的黑盒测试,我们测试和确认了这一假设。
从测试情况来看,Intel的TSX实现并没有将事务读取集、写入集、锁定值写入指令缓存器。当指令解码流水线从指令高速缓存中取出时,它不会陷入活跃的事务内存集中。
信仰之跃(Leap of Faith)
如何从指令缓存器中“泄漏”32位的key_X呢?读者可以尝试一下。
综合考虑,我们攻击的基础相当有限。进入事务状态后,我们将使用我们的shellcode执行跳转指令,跳转到key_Z。
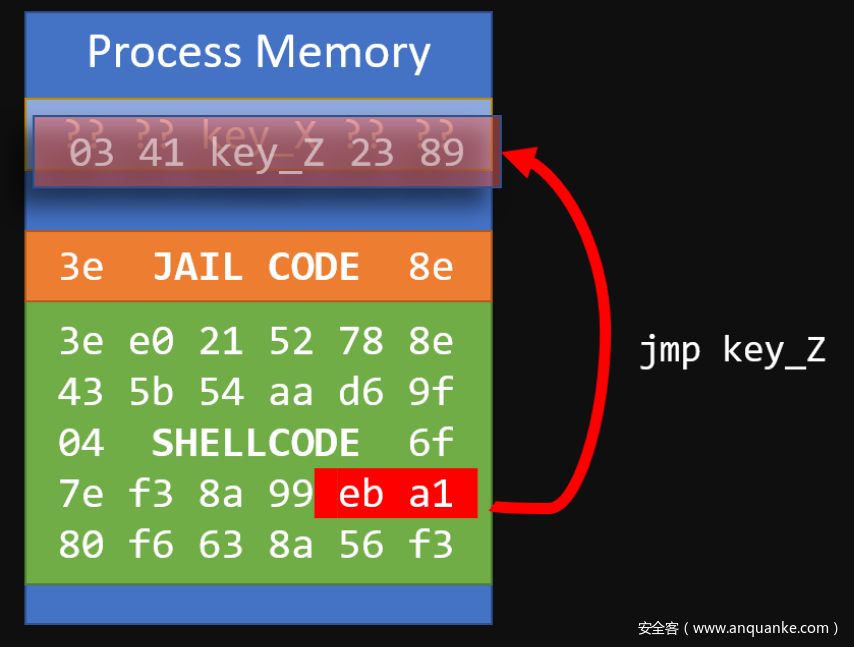
直接跳转到key_Z处
如果我们使用事务监控的shellcode尝试读取此位置的32位数,我们将获得用于绕过锁的值key_Z。尝试执行绕过锁的操作,从指令高速缓存器中取出key_X的原始值,解码,然后执行。
我们跳转的是随机的、不可观察的值,所以称之为“信仰之跃”。
难题的解决
解决这一挑战需要我们使用“信仰之跃”来推断key_X的真实值。但想仅通过静态编码来推断不可观察的且仅在运行时存在的数据几乎是不可能的。幸运的是,不可观察的32位key_X值是随机的,这意味着我们可以使用暴力破解的方法控制不可观察的内存或者代码。
Brute Force / Random
6A XX EB YY -- push XX ; jmp YY
66 B8 XX XX -- mov ax, XX XX
C2 XX XX 90 -- retn XX XX ; NOP
...
我们可以使用的空间非常有限,只用四个字节,而真正能控制的只有四个中的两个。最佳的解决方案是使用RET imm16(16位立即数)指令,爆破key_X值大约需要执行64k次(16位)C2 XX XX 90。
当程序跳转到这个爆破的值时,会立即从堆栈中pop一个地址作为“返回”地址(我们将其设置为指向我们shellcoded的地址)并跳转到该地址。RET imm16指令将16位立即数(XX XX)加rsp作为返回地址。
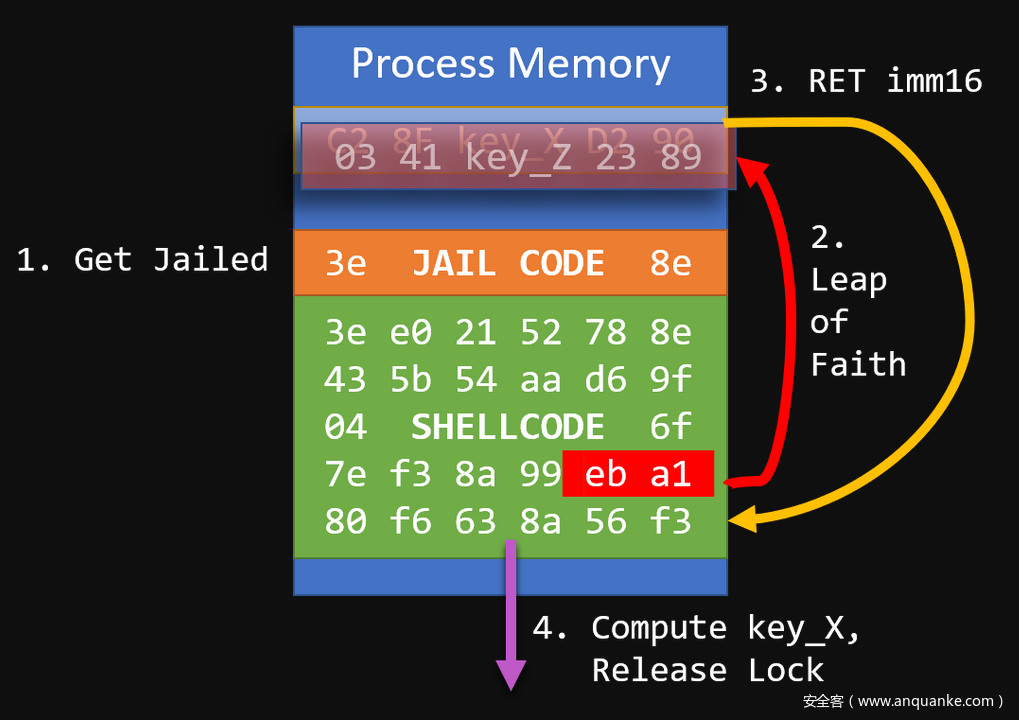
基于TSX的Hotel-California exploit运作方式
回到我们的shellcode后,可以从刚刚执行的RET imm16指令中提取imm16,将修改后的rsp值还原,就能恢复出key_X的值。
; 还原RSP的值并存放到rax
sub rsp, r10
mov rax, rsp
; 将与key_X相关的部分存放到ecx中
mov cl, 0x90 ; ecx = 0x90
shl ecx, 16
or ecx, eax ; ecx = 0x90XXXX
shl ecx, 8
mov cl, 0xC2 ; ecx = 0x90XXXXC2
利用key_X,我们将能够异或出key_Z的值,从而得到key_Y。恢复key_X和key_Y后,就可以释放锁并逃脱事务的限制。
; 解密key_Z并解锁
mov ebx, [r8]
xor ebx, ecx ; ebx = key_Z ^ key_X
xrelease lock xor [r8], ebx ; lock = key_Z ^ key_Y
至此,我们已经逃脱了事务监狱,并可以自由地进行系统调用。在我们的exploit中加入标准的execve()shellcode,剩下的就是让脚本运行得到flag:
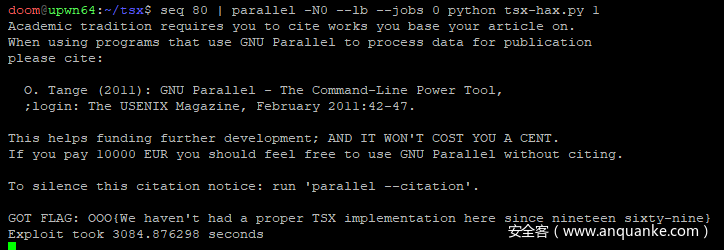
最终的exploit需要对一个16位的数进行暴力破解,要与服务器建立约65k次的连接。测试中,每秒能进行大于20次的尝试,能够在一两个小时内获得shell。
flag: OOO{We haven't had a proper TSX implementation here since nineteen sixty-nine}
补充
虽然我们的解决方案与shellcoding challenge的精神一致,但它并不是官方的解题思路。与题目作者Davide交流过,他不知道有没有解决这一问题的替代方案。知识面的不断拓展,让我们忽略了挑战的本意,尝试突破CPU进行攻击,解决问题才是王道。
结论
在这篇文章中,我们演示了如何利用Intel实现TSX中被事务内存逻辑掩盖的非对称行为泄漏内存。并利用这种通用的CPU级攻击作为DEFCON 2019 Qualifier CTF的解题方法。
此CTF题目模拟的场景独特,不太可能对实际应用程序构成风险。我们希望文本可以为那些希望进一步研究现代CPU中缓存不一致性问题的人们提供新的思路。
特别感谢sliden和adc为发现此解决方案做的贡献。